1. Introduction
The container ship stowage planning problem (CSPP) determines the specific location of a container on a ship. As an essential part of maritime container transportation, the CSPP is one of the problems that container terminals and shipping companies must face and solve every day [
1,
2]. The quality of stowage determines the safety and seaworthiness of a ship, which directly affects the berthing time of vessels and indirectly affects transportation efficiency. In addition, the quality of stowage is closely related to the shipping company’s efficiency and the cargo owner’s vital interests. When making a container stowage plan, the following aspects must be considered [
3,
4,
5].
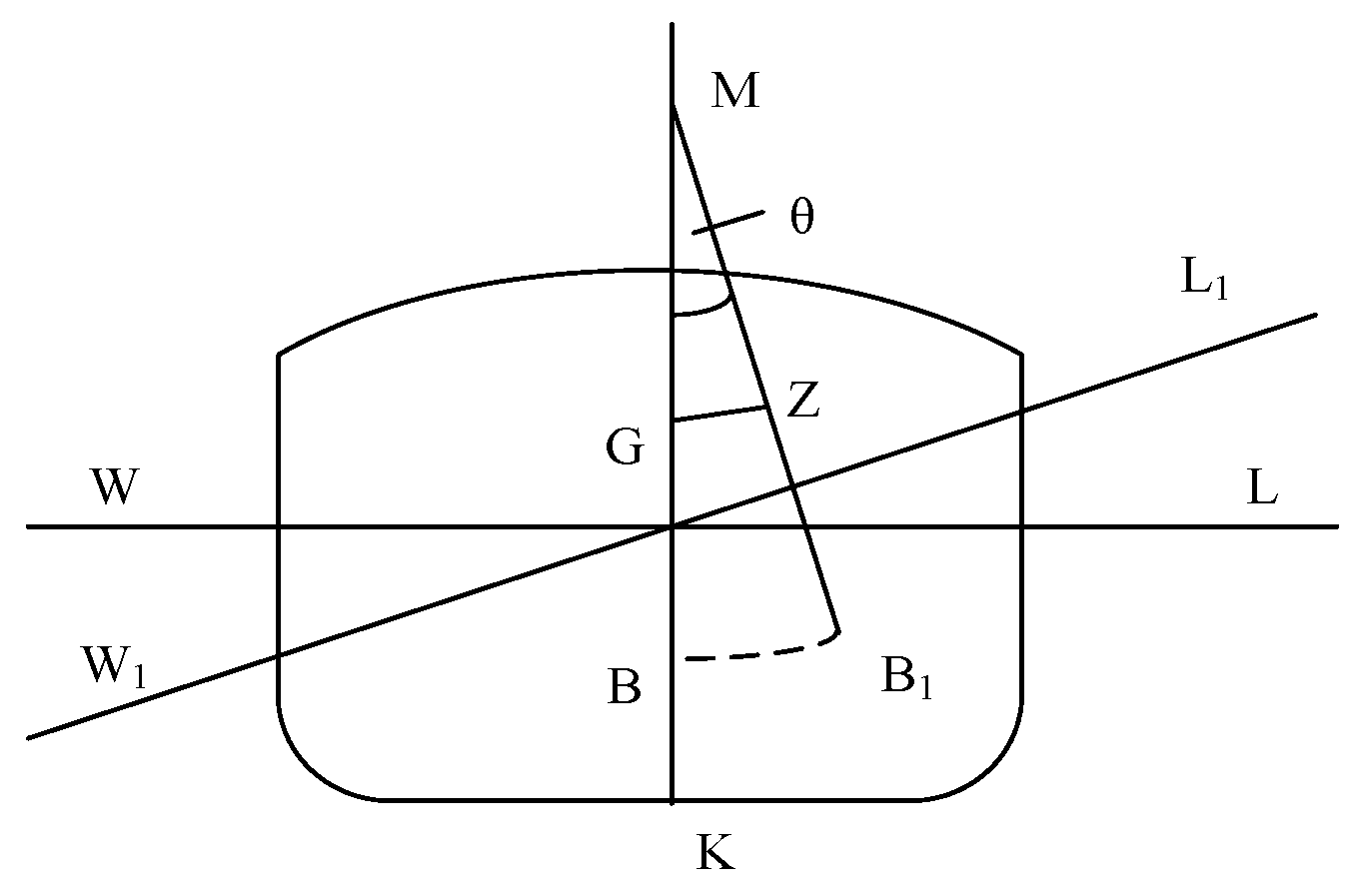
First, the seaworthiness and proper stability of the ship must be ensured. Because there are many containers on the deck, and the number of containers on the deck may even exceed the number of containers in the hold, container ships are different from other ship types. Container ships are prone to the characteristics of a sizeable wind-receiving area and a high center of gravity. During the whole process of loading and unloading and the entire process of sailing, it is necessary to ensure a certain initial metacentric height (GM), appropriate trim, and timely adjustments to the ship’s heeling, as well as to consider the influence of the blind area of the bridge’s sight. The initial metacentric height is significant for the navigation of ships, and at the same time represents a “sensitive” constraint. If its value is too small, the ship is prone to capsizing. Especially as the ship becomes larger and faster, the economic pressure of navigation in severe weather will tend to increase, thus increasing the risk of capsizing [
6]. A too-large value will shorten the rolling period, aggravate hull shaking, reduce crew comfort, and increase the lashing rope’s risk of loosening. In [
7], ship stability is regarded as a mandatory constraint. The ship’s operator can use ballast water to adjust non-critical stability issues [
8]; however, a good stowage plan needs to optimize the use of ballast water to reduce the ship’s trim in order to improve fuel efficiency.
Second, the limitations imposed by the physical structure of the containers must be met. Both the loading and unloading of containers follow the LIFO (last in, first out) policy [
9]. Special containers such as reefer containers, dangerous goods containers, and oversized containers have specific storage requirements. Due to corn fittings at the bottom, two 20-ft containers cannot stack on a 40-ft container.
Third, the container ship’s hull must have sufficient strength. Measures of the strength of a container ship’s hull includes shear force, transverse strength, torsional strength, local strength, and longitudinal strength. In loading, unloading, and transportation, stowage planning must meet the hull’s strength and safety requirements and extend the ship’s service life.
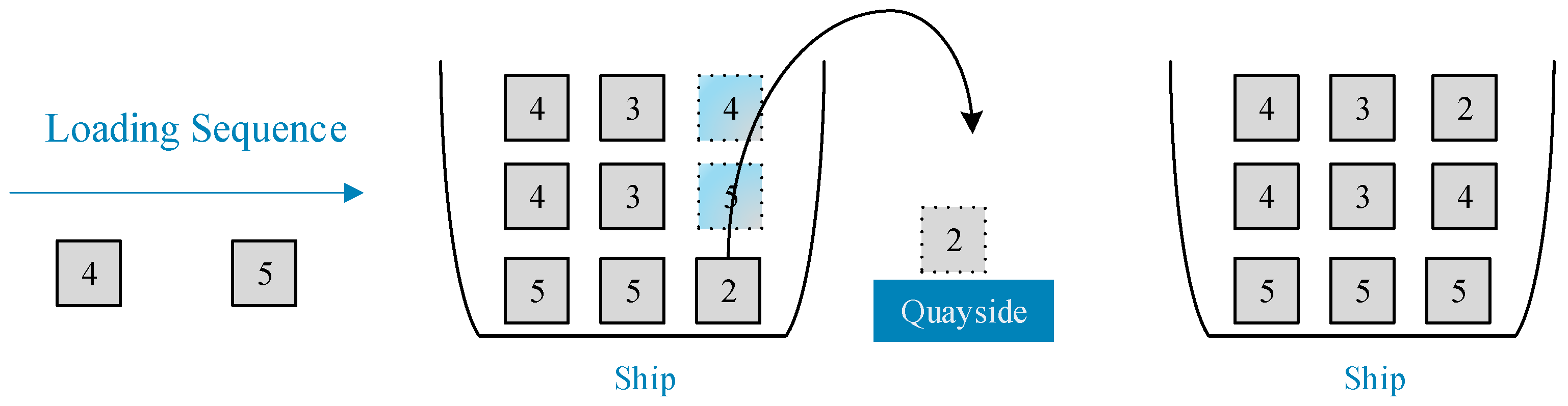
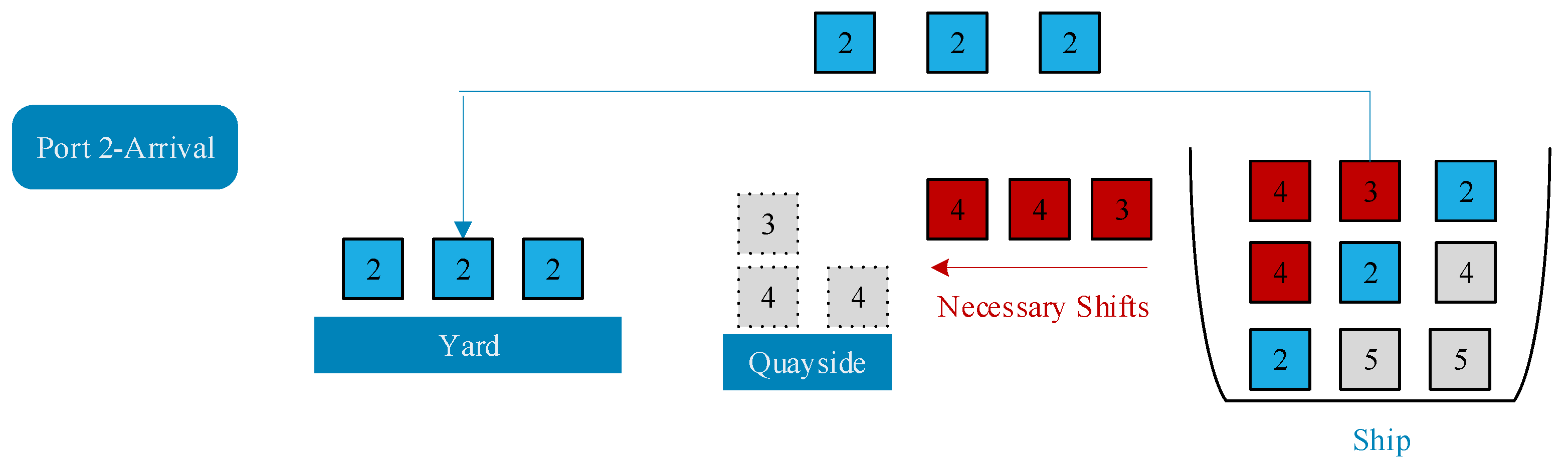
Fourth, the number of container shifts should be minimized. There are many ports of call and the loading and unloading of midway ports are more frequent, especially for transoceanic and global container liners. For this reason, when planning stowage an overall view of the whole route should be taken that carefully considers the order in which ships call and the information provided by each port of call. Earlier ports must be considered when planning for later ports. The starting port should lay the foundation for the entire route to avoid the situation of containers meant for earlier ports being blocked by those meant for later ports. Otherwise, container shifting will reduce the efficiency of loading and unloading, extend the turnaround time, and increase the cost. In addition, relocation will incur expensive additional loading and unloading costs (usually, a single loading and unloading costs tens to hundreds of US dollars) [
10,
11].
Finally, excessive concentration of containers in the same port of discharge is to be avoided. The makespan of quay cranes directly affects a ship’s turnaround time and port costs. Usually, two or more cranes simultaneously speed up the discharge process for large container ships [
12]. However, the quay crane cannot simultaneously lift the containers in two adjacent spaces on the container ship. In the case of the above situation, containers intended for the same discharge port should not be arranged in adjacent holds.
Based on the above discussion, the following two goals are crucial in container stowage.
- (a)
Ensure proper stability and trim of the ship;
- (b)
Minimize the amount of container relocation on the whole route.
Goal (a) relates to the safety of ships, while goal (b) relates to the profit and efficiency of shipping companies and port terminals. While each has its own merits, in actual operation there are often conflicts. For example, reducing the number of container shifts may come at the cost of reducing the ship’s stability. In engineering applications, this type of combinatorial optimization problem is called a multi-objective CSPP (MO-CSPP). In our research, the number of objectives exceeds three (i.e., six); thus, it is a many-objective CSPP (MaO-CSPP). As a remarkably realistic engineering problem in container transportation, MaO-CSPP has attracted the attention of more and more scholars. Multi-objective optimization is a common type of optimization decision-making problem which has been applied in many fields. The optimal solution is usually based on the trade-off between two or more conflicting objectives. To solve an MaO-CSPP according to different decision-making methods, two methods are typically used, namely, the a priori and a posteriori techniques [
13].
The a priori technique represents the basic idea behind solving multi-objective optimization problems in traditional mathematical programming. Before searching, the decision information is input and one solution is run to the decision-maker. The main methods include lexicographical, linear fitness, and nonlinear fitness methods. The objective functions of the MaO-CSSP are aggregated to obtain a single-objective optimization problem. Then, the single-objective optimization method is used to obtain a single Pareto-optimal solution. While the idea of this method is simple, in practical engineering applications it is difficult to determine the weighting preferences between the objectives. In MaO-CSPP, the stability and strength of the ship must be guaranteed within a specific range. However, it is difficult to determine the respective weights of the amount of container relocation and the ship’s stability and strength from the perspective of economic profit. Therefore, the priori technique is sometimes not suitable for solving MaO-CSPPs in this context.
In contrast, running the a posteriori technique generates solutions for decision-makers to choose from. This technique generates a representative subset of the global or local Pareto-optimal solutions. If at least one of its goals is not inferior to other solutions in the solution space, the solution is Pareto optimal. If it is not dominated by any other solutions in the solution space, it is Pareto optimal [
14]. Domination-based multi-objective optimization has been proven to be suitable for MaO-CSPPs.
A set of Pareto-optimal solutions can be obtained in a single run without prior information by using the a posteriori technique. Decision-makers can then weigh different goals and choose an ideal solution for actual implementation. The above studies on CSPPs seldom consider the principles of ship stability, strength, draught, etc., as they are conducted from a purely mathematical point of view and the yard optimization problem is not included. At the same time, most of the literature does not incorporate the characteristics of the full-route ports of call, instead using only a single port to design the stowage plan. On this basis, the present paper proposes a many-objective method that weighs safety and economic benefits from the perspective of both ship and port, and thereby enriches the research content regarding CSPPs. The rest of this article is organized as follows. In Part Two, a literature review is provided summarizing the latest progress on CSPPs and multi-objective evolutionary optimization algorithms; in Part Three, we introduce the CSPP; in Part Four, we present an algorithm that combines local search and genetic operators, and provide specific details to solve the problems raised in Part Three; in Part Five describes the many examples and experiments we conducted; finally, Part Six contains our conclusions along with prospects for future research.
2. Literature Review
CSPP is occasionally referred to as the master bay plan problem (MBPP) or ship stowage planning problem (SSPP) [
15]. In 1970, Webster and Van Dyke first studied CSPP [
16]. As their research only discussed simple issues, and did not conduct many experimental data tests, it is impossible to demonstrate the practical significance of their methods. Subsequently, in the 1980s Shields proposed the CAPS system (computer-aided pre-planning system) and applied it to the American President Line (APL) [
17]; this system uses Monte Carlo stochastic simulation technology to generate different stowage plans. Avriel et al., proved that the CSSP is an NP-hard problem and demonstrated its relationship with the graph coloring problem [
15], then established a 0–1 mathematical programming model and designed a “Suspensory Heuristic Procedure” in which the optimal solution for the small-scale stowage plan is automatically generated [
18]. Ambrosino et al., attempted to derive rules that determine a good stowage plan [
19]. The authors define and characterize the feasible solution space by satisfying certain constraints. The 0–1 linear programming model was then established to solve this combined optimization problem [
20,
21] using rules to develop a heuristic algorithm in which containers that have the same attribute should be placed in the same hold. However, the paper does not explicitly consider the issue of relocation related to the loading process. The authors expanded the original basic model by considering the influence of different container types (i.e., 20-ft and 40-ft containers) [
22,
23]. Imai et al., established an integer programming model intended to minimize the shift volume of the yard and the ship’s stability. However, the model did not consider the impact of hatch covers on stowage [
8]. It is difficult to estimate the number of shifts when the information left by the container truck is uncertain as to storage space. Therefore, Imai proposed an estimate of the expected number of shifts [
24]. Li et al., established a 0–1 mathematical programming model [
25] by maximizing container ship hold utilization while minimizing operating costs over the whole route. Cruz-Reyes et al., developed 0/1 IP and employed a constructive heuristic to find the solution [
26]. Petering et al., introduced a new mathematical formula for the block relocation problem by establishing an integer programming model. This method has been proven to produce fewer decision variables and better performance [
27]. N. Wang et al., established an integer programming model and solved it with a CPLEX solver [
28]. Fan et al., designed an effective algorithm to solve the optimization problem of the container stowage plan while considering many practical and operational constraints. However, no specific mathematical model has been set up to describe the optimization of container stowage plans [
29].
All of the above-mentioned literature relies on traditional mathematical programming methods to deal with the problem of container stowage; this is only suitable for small-scale situations, and most applications are single-bay container stowage problems [
30], which do not have practical engineering significance. Therefore, scholars often adopt a multi-stage method when facing actual scale problems, i.e., the CSPP is decomposed into sub-problems that are easier to handle. The corresponding sub-problems are then dealt with separately, and the solutions of the sub-problems are spliced to obtain a solution. In addition, Monaco introduced a systematic classification scheme for CSPP [
31]. Wilson et al., designed a two-stage process for a container stowage plan in which the first stage is a global stowage strategy and the second stage is a partial stowage strategy [
32]. Kang and Kim decomposed the container stowage problem into two sub-problems. The first sub-problem allocates containers to different countermeasure holds, and the second sub-problem determines the specific placement of containers in each hold [
33]. Ambrosino et al., described the problem as an optimization problem [
22]. They defined the problem as a master bay plan problem (MBPP). In response to this problem, the author proposed a three-stage heuristic model to deal with the sub-problems of each stage separately and developed a basic 0–1 linear programming model to minimize the total loading time. The subsequent literature [
23] expanded the work of [
22] and achieved specific results. Based on their consideration of structural and operational constraints, Ambrosino et al., proposed a multi-port MBPP heuristic algorithm based on MIP to minimize ship berthing time [
34]. Later, they offered an MIP model to minimize the number of reprocessing and crane makespan which took into account such realistic constraints as six ports of call and both standard containers and reefer containers [
35]. In a recent study, the authors used a specific stowage principle to solve the CSPP in the presence of dangerous containers [
36]. Delgado et al., decomposed the ship stowage plan into two sub-problems, the main stowage plan and the location plan, using the calculation result of the main stowage plan as the input data of the location plan [
30]. Pacino et al., proposed a two-stage method for large container ships; the first stage deals with the multi-port main bay stowage plan and the second stage uses the constraint programming (CP) method and slot planning to allocate specific slots for each container [
37]. Iris Ç et al., presented a flexible container ship loading problem for seaport container terminals. They integrated the assignment and scheduling of transfer vehicles and container load sequencing with the assignment of specific containers to specific vessel positions [
38]. Gumus et al., developed a multi-stage heuristic of the CSPP by decomposing the problem into four stages, explaining many complex and realistic CSPPs [
39]. Zhang et al., deteriorated the full-route container stowage problem into a bay selection sub-problem and a slot plan sub-problem. The second sub-problem was then further subdivided into single destination port and a multi-destination port bay position optimization problem [
40]. Azevedo et al., studied the optimization of container stowage plans considering the operation of quay cranes, taking additional practical and operational constraints into account, and designed a new solution method to solve the problem. However, the related characteristics of the container crane and the container were simplified without considering different container weights and sizes or the additional productivity of the quay crane [
41]. Christensen et al., extended the liner shipping cargo mix problem by including the concepts of block stowage and draft restrictions and restricting the number of containers able to be selected, with the aim of determining the optimal cargo mix, not of creating a fully feasible stowage plan. Instead of assigning specific containers to specific slots on the vessel, containers are grouped by container type and assigned to blocks. Each container type represents several containers with the same properties [
42]. Yaagoubi et al., studied 3D container loading planning of inland navigation barges. They proposed a heuristic method based on the first fitting algorithm of the packing problem, which is able to deal with actual structural and operational constraints [
43]. According to inland container liner transportation characteristics, Li et al., decomposed the current port stowage planning problem into two sub-problems and proposed two heuristic algorithms for them [
44]. Iris et al., systematically reviewed the literature related to stowage planning, loading sequencing, and scheduling. From the perspective of the ship loading problem (SLP), the authors pointed out that the literature on integration efforts for the SLP was rather limited, that is, most literature focuses on optimizing partial SLP issues. These studies have contributed to solving the SLP by proposing new models or algorithms to find improved solutions to various aspects of the SLP [
45].
To enhance the practicality of the algorithm, scholars have gradually begun to apply heuristic or meta-heuristic methods to the field of ship stowage. Avriel et al., developed a Suspensory Heuristic Procedure to process CSPP that minimizes the number of container shifts without considering stability or strength [
18]. Based on [
18], Ding extended and enriched the Suspensory Heuristic Procedure [
46]. Dubrovsky et al., proposed compact coding technology to design a genetic algorithm (GA) suitable for the CSPP. The significant feature of this method is that it reduces the number of iterations [
47]. Jin et al., established an MIP model based on reality constraints, proposed an interactive hybrid algorithm consisting of a combination of a heuristic algorithm and a GA based on a pre-allocation strategy, and realized the visualization of stowage plans using the VB program [
48]. Sciomachen and Tanfani considered this model’s structural and operational constraints as they relate to containers and ships. They proposed a heuristic method that uses the relationship between MBPP and the three-dimensional packing problem to solve the MBPP problem [
49]. Parreño proposed a greedy randomized adaptive search procedure (GRASP) to solve the problem of container stowage slot planning [
3]. Similarly, they studied multi-port CSPP and proposed an IP model and a GRASP algorithm, generating a stowage plan with the smallest number of container shifts for large-scale problems [
50]. Araújo et al., proposed a Pareto clustering search algorithm to solve the double objective optimization model of container stowage (with the objectives of the number of movements necessary to load and unload the container ship and the stability of the ship in each port), designed a heuristic algorithm, grouped clustering through local search, and found the Pareto frontier to obtain the effective solution of the problem [
51]. Zhang studied a multi-objective CSPP, seeking to optimize the stability of the ship and the number of containers to be reprocessed at the same time. The author developed multiple heuristic algorithms to deal with both containers in the yard and containers in the bay of ships, then integrated these heuristic algorithms into a non-dominated sorting GA [
52]. Wilson and Roach used Tabu Search (TS) to generate CSPP solutions, and found that TS can gradually improve the location of containers [
53]. Yurtseven implemented two meta-heuristic algorithms, namely, GA and simulated annealing (SA), to solve the CSPP. Their results show that SA can reach near-optimal results faster than GA [
54]. Ambrosino et al., tested the performance of three methods to solve the MBBP, i.e., TS, a simple heuristic algorithm, and an ant-colony optimization (ACO) algorithm. Their results show that ACO is the best for large-scale instances, while TS is ideal for medium-sized cases [
23]. Bilican et al., proposed a two-stage heuristic solution method using IP and a swapping heuristic (SH), which effectively increases the scale of solvable problems [
6]. Junqueira et al., proposed an optimization model that combines the multi-port stowage planning problem with the container relocation problem. The author presented two heuristic methods to quickly generate feasible solutions [
55]. Ji et al., established a mixed-integer nonlinear programming model based on small feeder container ships’ “sensitive” characteristics to ensure navigation safety. The authors designed a heuristic algorithm to update branch routes through variable neighborhood search and GA in order to obtain the stowage plan [
56].
Although the literature mentioned above discusses several objectives of CSPP, most studies treat the CSPP as a single-objective optimization problem; there are few studies on the MO-CSPP or MaO-CSPP. Imai et al., considered two criteria with respect to the MO-CSSP, namely, ship stability and the number of rehandlings [
8]. However, they used a weighted sum method and designed a GA to handle single-objective CSSPs. Liu et al., considered five objectives, i.e., the number of container shifts, the quay cranes’ makespan, the number of stacks exceeding the weight limit, the number of stacks without containers, longitudinal stability, and transverse stability, then developed a random algorithm incorporating TS to find a set of Pareto-optimal solutions [
57].
In 1989, David Goldberg proposed using evolutionary algorithms (EA) to achieve multi-objective optimization technology. Multi-objective evolutionary algorithms (MOEA) have subsequently attracted widespread attention from many researchers, and many research results have emerged. When solving MO-CSSPs, to the best of our knowledge only Zhang et al., have used the MOEA [
52]. This paper proposes to use the concept of Pareto optimality according to the idea of non-dominated sorting to produce a set of solutions for decision-makers.
4. Multi-Objective Optimization Method
In this part, we describe the design of a variant based on the non-dominated sorting genetic algorithm III (NSGA-III) to solve the MaO-CSPP. The basic framework and overview of the algorithm is introduced in
Section 4.1. In
Section 4.2, a compact coding method is used to represent feasible solutions. The heuristic methods for the relocation problem of containers in the yard and for voluntary shifting are delivered in
Section 4.3 and
Section 4.4, respectively. The method of generating the initial solution is provided in
Section 4.5. The crossover and mutation of genetic operators is introduced in
Section 4.6. In
Section 4.7, local search is added to the designed algorithm. Finally, the neighborhood operators for local search and mutation are presented in
Section 4.8.
4.1. Framework of Optimization Method
The NSGA-III was proposed by Deb et al., in 2013; based on NSGA-II, it aimed to solve problems for which NSG-II was not competent due to increased objective dimensionality [
64]. Deb et al., proposed NSGA-II in 2000. NSGA-II can handle multi-objective optimization problems well [
65]. However, NSGA-II only shows good performance for low-dimensional optimization problems in which objective dimensionality is less than or equal to 3. The basic framework of NSGA-III is similar to that of NSGA-II. The significant change lies in the selection mechanism of the critical layer. In NSGA-II, the solution with a more substantial crowding distance in the essential layer, i.e., a solution with a smaller crowding density, will be selected first. However, the crowded distance metric is unsuitable for solving high-dimensional multi-objective optimization problems. Therefore, the crowding distance is no longer used in NSGA-III; instead, the reference point method is used to select individuals. In addition, in order to realize the individual’s self-learning in the life cycle a local search strategy known as memetic algorithms is introduced into the iterative process of NSGA-III, [
66].
The framework process of NSGA-III is provided in Algorithm 1.
| Algorithm 1. NSGA-III framework with local search |
| Input: H structured reference points Zs or supplied aspiration points Za, parent population Pt, population size N. |
| Output: Pt+1 |
| 1: P0 ← InitializePopulation () |
| 2: t ← 0 |
| 3: while termination criteria not reached do |
| 4: Qt ← Recombination + Mutation (Pt) |
| 5: Q’t ← LocalSearch (Qt) |
| 6: Rt ← Pt ∪ Qt ∪ Q’t |
| 7: Rt ← EliminateDuplicates (Rt) |
| 8: {F1, F2, …} ← FastNonDominatedSort (Rt) |
| 9: Pt+1 ← Ø |
| 10: i ← 1 |
| 11: while |Pt+1| + |Fi| < N do |
| 12: Pt+1 ← Pt+1 ∪ Fi |
| 13: i ← i + 1 |
| 14: end while |
| 15: Choose K members to form the last front Fi: K = N − |Pt+1| |
| 16: Pt + 1 ← Pt+1 ∪ Selection (Pt+1, Fi, K) |
| 17: t ← t + 1 |
| 18: end while |
First, the algorithm generates an initial population
P0 of size
N. For the specific details of the initial population
P0, please refer to
Section 4.5. Steps 4–18 are looped and iterated until the termination condition is met. In each generation of the algorithm, the current population
Pt, known as the parent population, generates a population of offspring
Qt of the same scale through recombination and mutation. Then, the local search strategy is used to perform a fine search of the progeny population
Qt to obtain an improved population,
Q’t; see
Section 4.8 for a specific introduction to the local search strategy. In Step 6, the populations
Pt,
Qt, and
Q’t are merged into a population
Rt; in addition, the size of
Rt is 2
N. Because
Rt may contain individuals with the same objective value, and this affects the search quality, in Step 7 further mutation operations are performed on repeated individuals. In Step 8, the fast nondominated sorting method is used to divide
Rt into different non-dominated layers {
F1,
F2, …}. Then, the non-dominated set with the highest priority is retained in the next generation. When |
F1 ∪
F2, …, ∪
Fi-1| and |
F1 ∪
F2, …, ∪
Fi−1| >
N,
Fi is defined as the critical layer and the critical layer selection method is used to select
K individuals into the next generation until the size of the offspring population is equal to
N. The critical layer selection method in Step 16 includes the determination of reference points, adaptive normalization, an association operation, and a niche-preservation operation. For additional details on NSGA-III, please refer to [
64].
4.2. Chromosome Encode
For the MaO-CSPP, each feasible solution
S corresponds to a complete loading plan
Lp which can determine the loading sequence
Ls of the container and the specific location of the container on the ship. The loading sequence
Ls of containers includes the set
CY of all containers to be loaded in the container yard and part of the set
CS (
V) of containers on board.
CS (
V) refers to a container undergoing voluntary shift. Once the loading sequence
Ls is determined, the container yard’s container relocation (
f21) can be calculated according to the method provided in [
63]. Simultaneously, voluntary shifts by quay cranes (
f22) can be made out. As the loading plan includes the specific location of the container on the ship, the container stowage map when the ship leaves the port can be obtained based on this; then, the ship stability-related results (
f11,
f12, and
f13) can be calculated based on the stowage map and necessary shifts at future ports (
f23) can be calculated at the same time. Therefore, a complete loading plan
Lp is regarded as a feasible solution, that is, a chromosome.
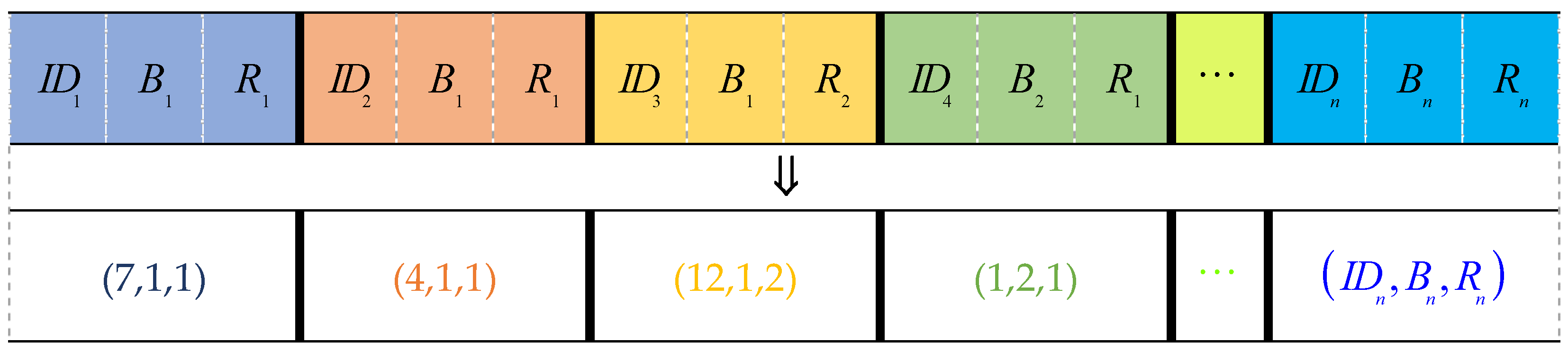
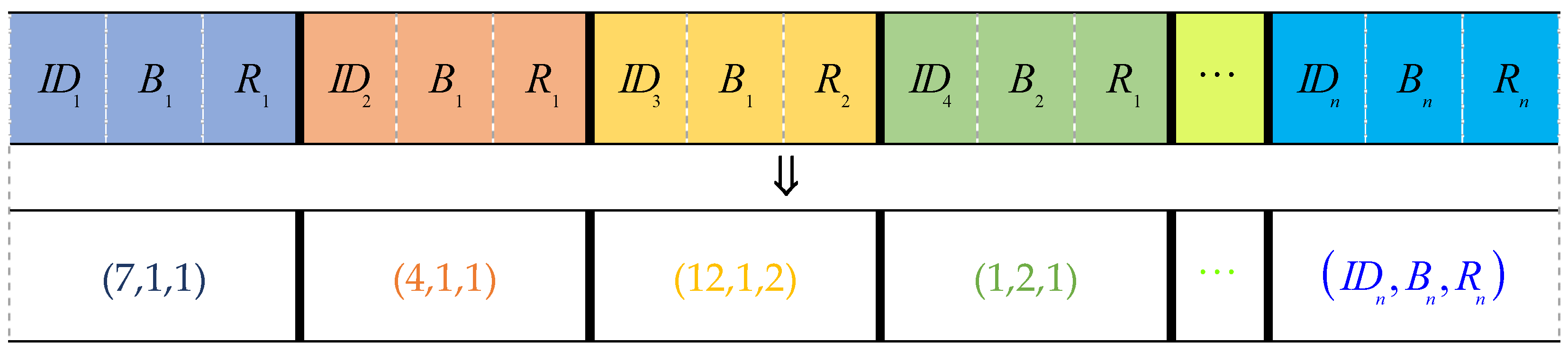
As mentioned above, a loading plan
Lp needs to include the loading sequence
Ls and specific location of a container on the ship. Then, each gene in the chromosome can be represented by a triplet (
IDi, Bi, Ri) where
I = 1,2,…,
n (with
n being the number of containers in a loading sequence
Ls, i.e.,
n = |
CY| + |
CS (
V)|) and 1 ≤
Bi ≤
bS, 1 ≤
Ri ≤
rS. A feasible solution is one in which a chromosome can be expressed, as shown in
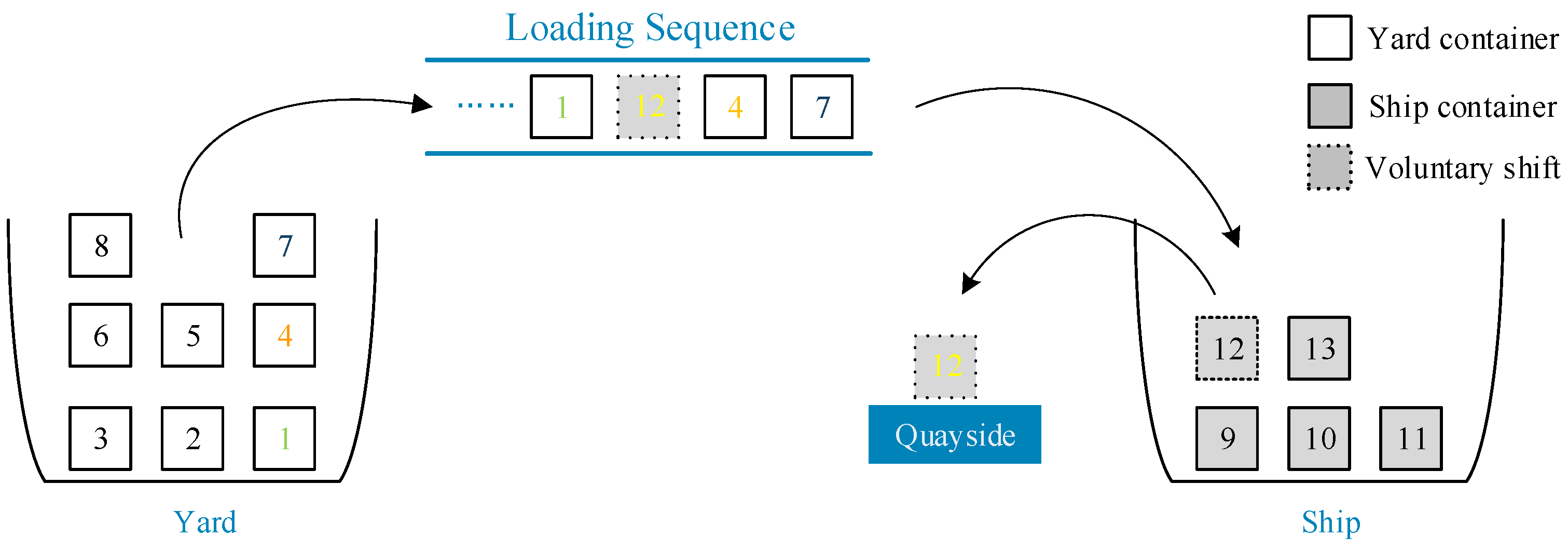
Figure 5.
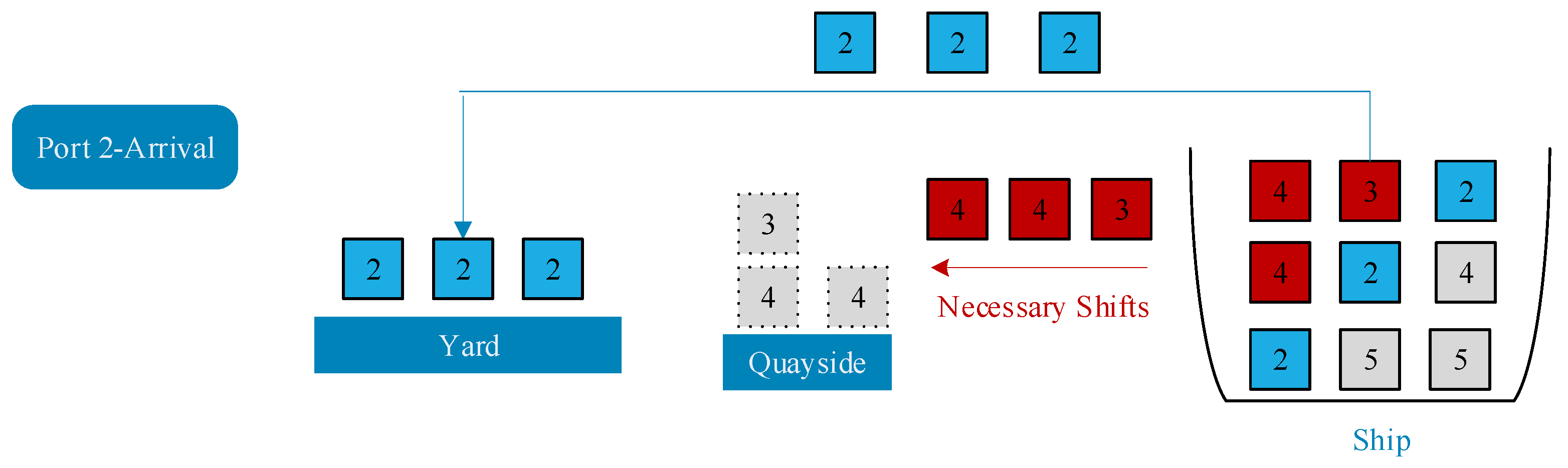
Figure 5 shows a legal chromosome code through which a complete loading plan can be obtained:
Lp = 〈(7,1,1), (4,1,1), (12,1,2), (1,2,1), …〉. The first triplet (7,1,1) represents that container_7 was first loaded on the ship and its location on the ship was (bay1, row1), then container_4 was loaded onto the ship, and its position is (bay1, row1) as well. Container_12 is the “voluntary shift” container, i.e., the container on the ship. It needs to be temporarily moved to the side of the dock for container relocation at a future port, and then is loaded onto the ship according to the “new” loading sequence. Then, the container will be loaded in position (bay1, row2) after container_4 is loaded. A schematic diagram of the loading process is shown in
Figure 6. The number in the figure represents the container number. The complete loading sequence is
Ls = 〈7,4,12,1,…〉 and the loading sequence for the yard container is
LYs = 〈7,4,1,…〉 (
LYs ⊆
Ls). This information is found in the loading plan;
Lp = 〈(7,1,1), (4,1,1), (12,1,2), (1,2,1), …〉 can be used to find the number of container shifts and the stowage plan, and the stability of the ship can then be calculated from the stowage plan. However, because container relocation is an NP-hard problem, the true value of the number of container shifts in the yard cannot be obtained in polynomial time when the loading plan
Lp is given. Based on the literature [
67], here we replace the optimal plan with a near-optimal plan based on a greedy heuristic. We have reason to adopt this approach, and it is in line with the actual production situation.
Containers arrive at the terminal yard before they are loaded. The advance time is usually more than ten hours or a few days. Therefore, there is sufficient time for processing of the yard containers, such as pre-marshalling, to meet the requirements of loading containers in order of loading sequence. In addition, the cost of container shifts in a container yard is lower than shifts on ships.
Different loading plans under the solution space many times must be verified and evaluated, and thus a fast and efficient heuristic is urgently needed.
4.3. Heuristic Rules for Relocation of Yard Containers
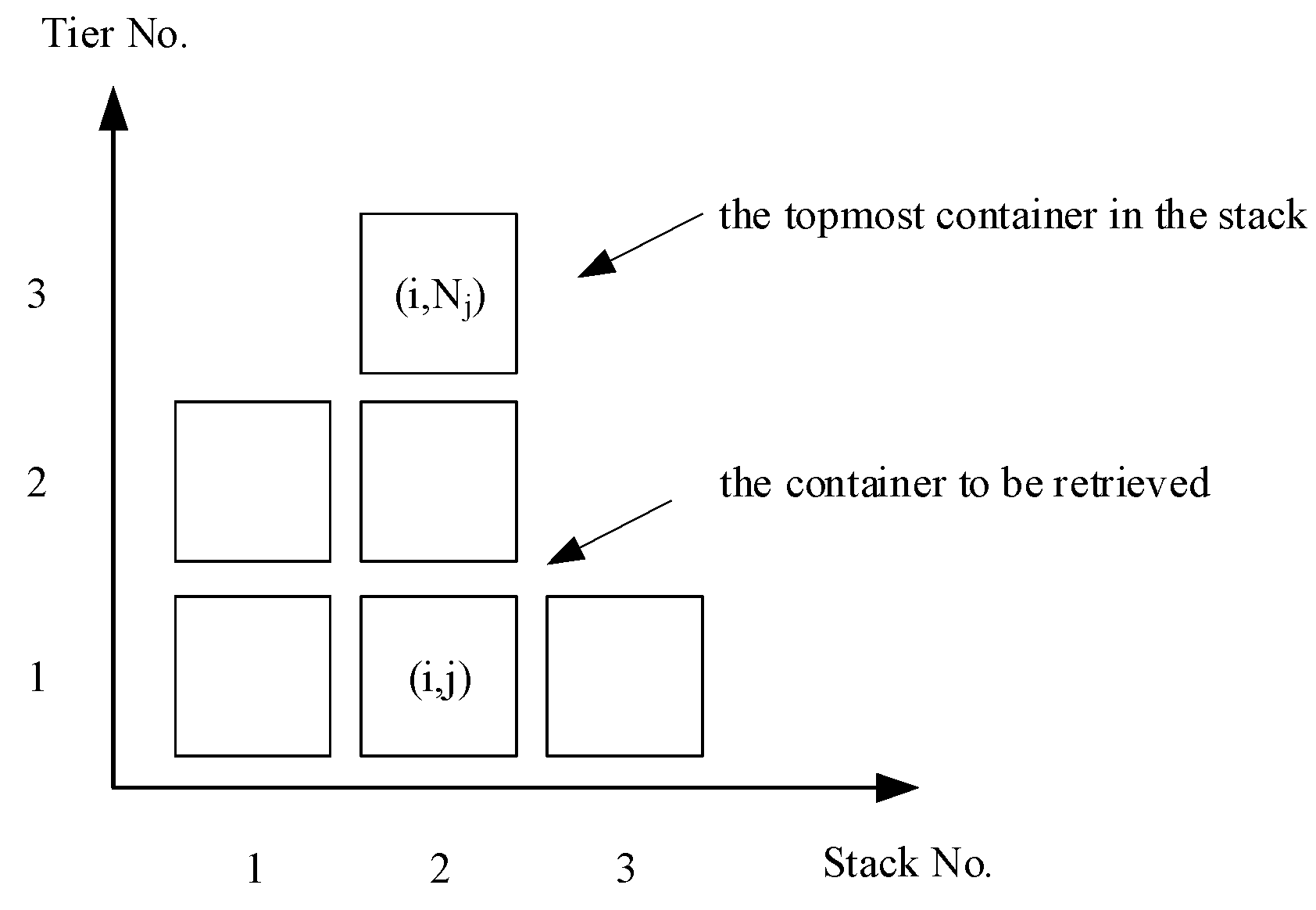
It is assumed that before the loading operation begins the storage status in the yard of the containers to be loaded and the loading sequence
LYs of the containers on the ship are both known. The shifting operation takes place in the same bay, and there are enough slots for relocation.
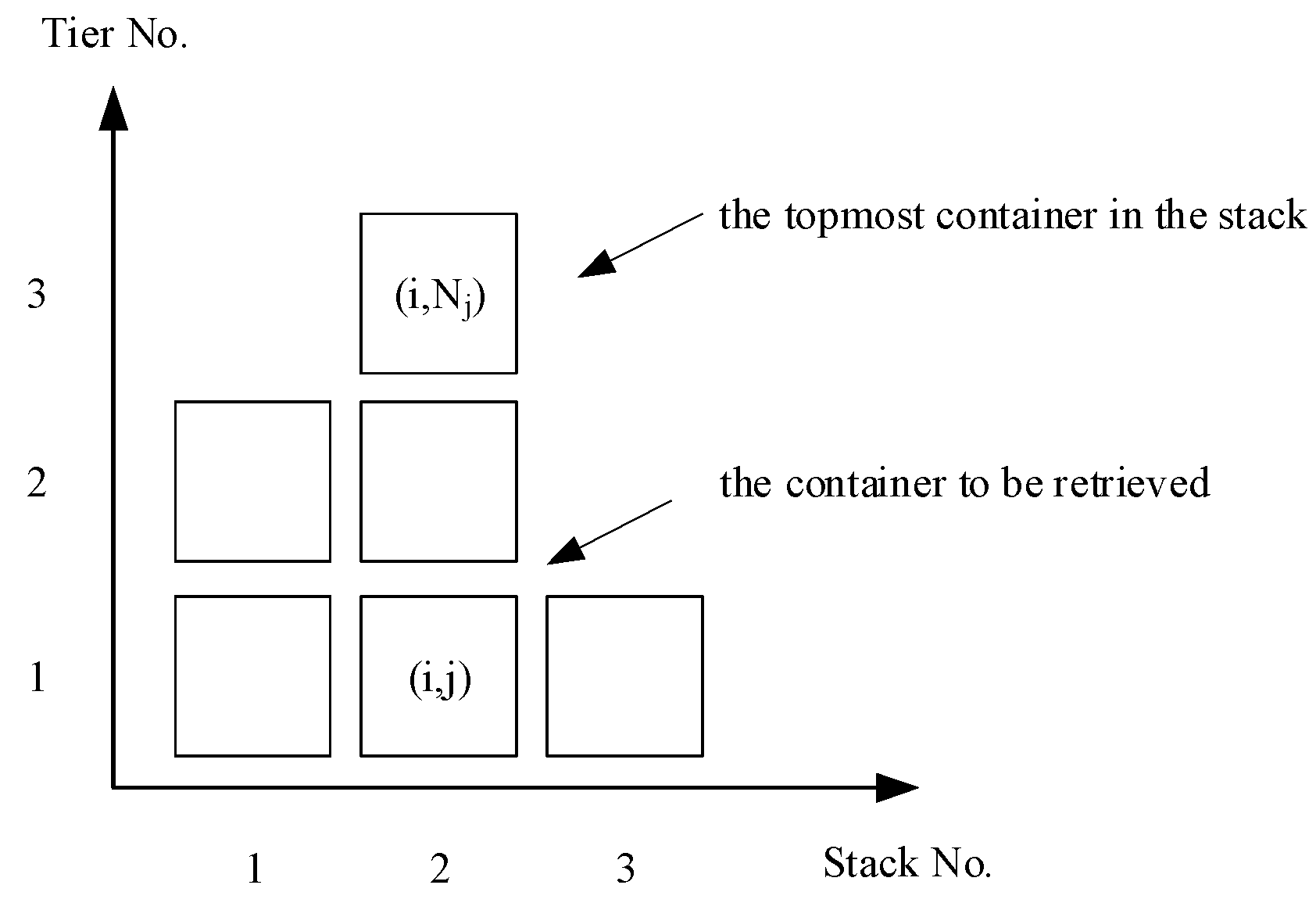
Figure 7 shows a schematic diagram of a yard bay layout. We define (
i,
j) as the position corresponding to the row and tier in the container yard.
RiN is defined as the total number of containers in stack
i; thus, the total number in all bay stacks can be expressed as
BN =
. We define the priority,
pi,j, according to the order of the destination port of container (
i,
j);
pi,j =
D represents the destination port of container (
i,
j) as
D. The later the destination port, i.e., the larger the value of
D, the earlier a container should be loaded on the ship. In other words, at the front end of the loading sequence the priority of a given container is higher.
Dimax is the maximum value of the destination port in the
i-th stack and
Dimin is the minimum value of the destination port in the
i-th stack, i.e.,
Dimax = max{
pi,j | 1 ≤
j ≤ RiN} and
Dimin = min{
pi,j | 1 ≤
j ≤ RiN}.
The idea of a greedy heuristic algorithm is proposed in [
67]. According to a given
LYs in the container loading sequence, a container (
i,
j) is the target container to be retrieved; the following operation strategy is then implemented until all containers are loaded on board.
STRATEGY:
j = RiN: a container (i, j) is located at the top of the i-th stack and is retrieved directly.
j ≠ RiN: there is a blocking container (i, b) (b = j + 1, …RiN) when the container (i, j) is retrieved, and the blocking container needs to be temporarily relocated to stack k (k ≠ i). There may be only one blocking container, i.e., the top container (i, RiN) (b = RiN) in the i-th stack, or several, i.e., (b = j + 1, …RiN). According to the following rules, each blocking container is relocated to k (k ≠ i). The selection of stack k (k ≠ i) follows the following rules.
RULE:
RkN < tY and pi,b ≥ Dkmax: RkN < tY means that stack k has space to accommodate blocking containers, and relocation will not block the containers in stack k. If there are multiple stacks to choose from, choose the smallest Dkmax. If there is a tie, select the nearest one.
RkN < tY and pi,b < Dkmax means that relocation will block the container in stack k. At this time, the smallest Dkmax should be selected. If there are multiple columns to choose from, choose the shortest column.
A feasible solution can be produced according to the above strategies and rules whenever there is a feasible solution.
4.4. Heuristic Rules for Container Voluntary Shifting
In
Section 3.3 above, we defined voluntary shifts as shifts that occurs when to reorder the sequence of containers on the ship in order to prevent container relocation in the future. This is called the Myopic Voluntary Shifting Rule in [
18,
46], and the specific details of these heuristic rules can be found in these two works.
4.5. Generating Initial Population
Drawing lessons from the actual production experience of the container stowage plan, when generating the initial population P0 of NSGA-III a two-stage method is used to generate the initial population of scale N.
Section 4.3 defines the priority,
pi,j, in the terminal yard. The farther away the destination port of container (
i,
j) is, the earlier the container will be loaded on the ship. At the same time, the larger the corresponding
D (
pi,j =
D) value, the higher the container’s priority. The concept of container priority is used in this section.
- Stage 1:
Randomly adopt the following two mechanisms to generate a loading sequence Ls for the feasible solution; pay attention to Ls = LYs at this time.
- 1.
Retrieve the top container with the highest priority among all the columns of the yard containers each time, i.e., retrieve {C_Topmost | Dimax, i ∈ all rows in the yard}. If there are more choices, choose the one with the highest quality.
- 2.
Retrieve the container with the highest priority in the current yard each time, i.e., retrieve {C_Dimax, i ∈ all rows in the yard}. If there are more choices, choose the one with the fewest blocking containers. If there is a tie, retrieve the heaviest one.
- Stage 2:
In Stage 1, we obtain a complete loading sequence. Each container C in this given loading sequence must now be assigned to a specific ship stack. Due to the particular physical structure of container ships, their stacked containers follow the LIFO policy. Now, operating according to the following mechanism, we can finally obtain a feasible solution. In the above two stages, the strategy of voluntary shifts is not used. Therefore, there are no container shifts in the initial population.
- 1.
Suppose a stack k satisfies RkN < tS and a container C does not block other containers in stack k, i.e., the priority of container C satisfies pC ≤ Dkmin; then, select this stack. If there are multiple choices, choose the one with the smallest Dkmin value.
- 2.
If a stack with the properties mentioned above does not exist and container C blocks other containers in stack k, i.e., pC > Dkmin, choose the one that satisfies RkN < tS and has the largest Dkmin value in stack k.
4.6. Genetic Operations
Genetic manipulation is used to generate individual offspring, including by crossover and mutation. Crossover operates on a pair of chromosomes, while mutation operates only on a single individual.
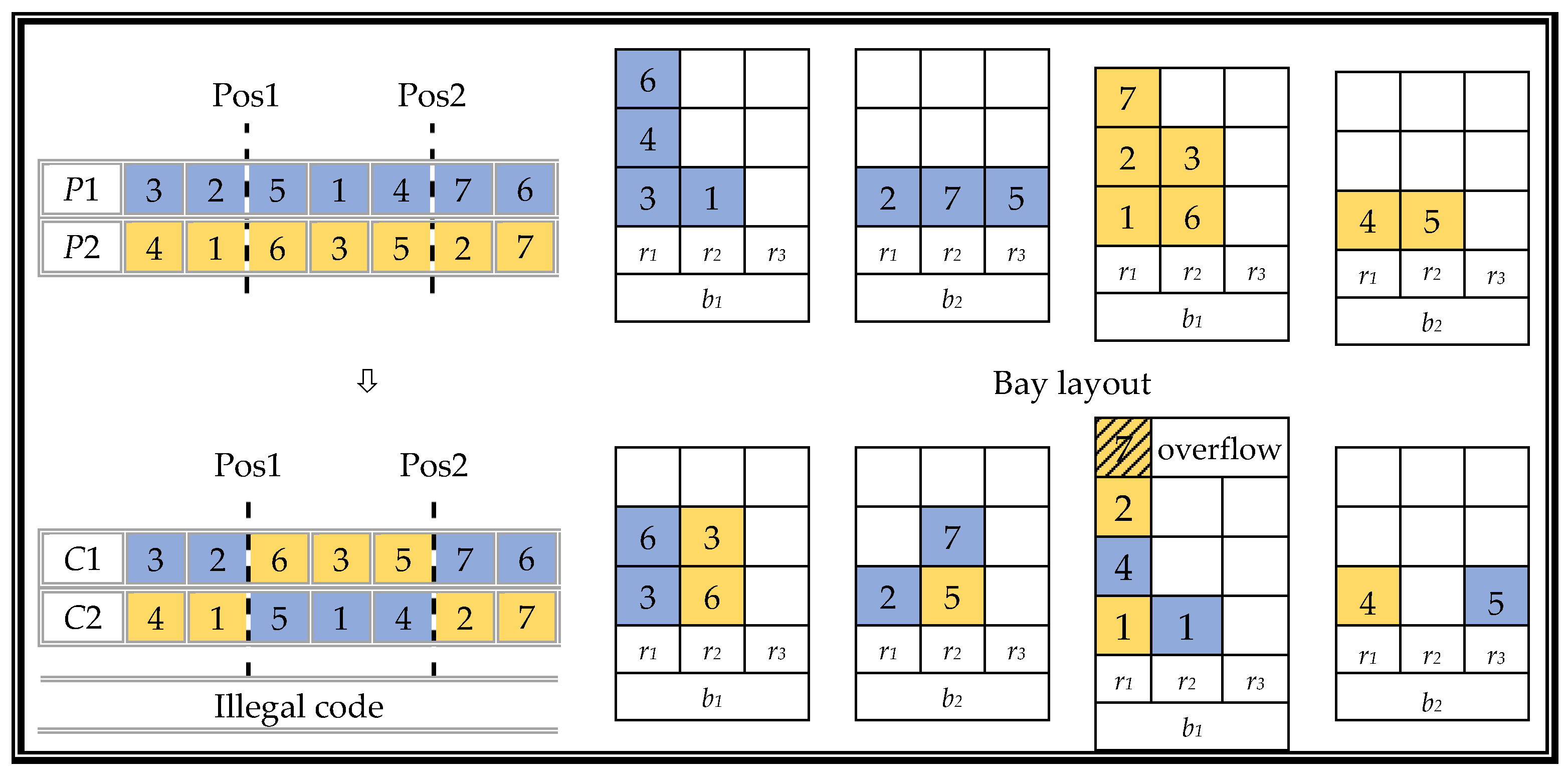
First, consider one chromosome of only the yard containers
CHY. Assuming that the chromosome contains only seven genes, that is, only seven yard containers (i.e., containers 1–7), set one parent chromosome as
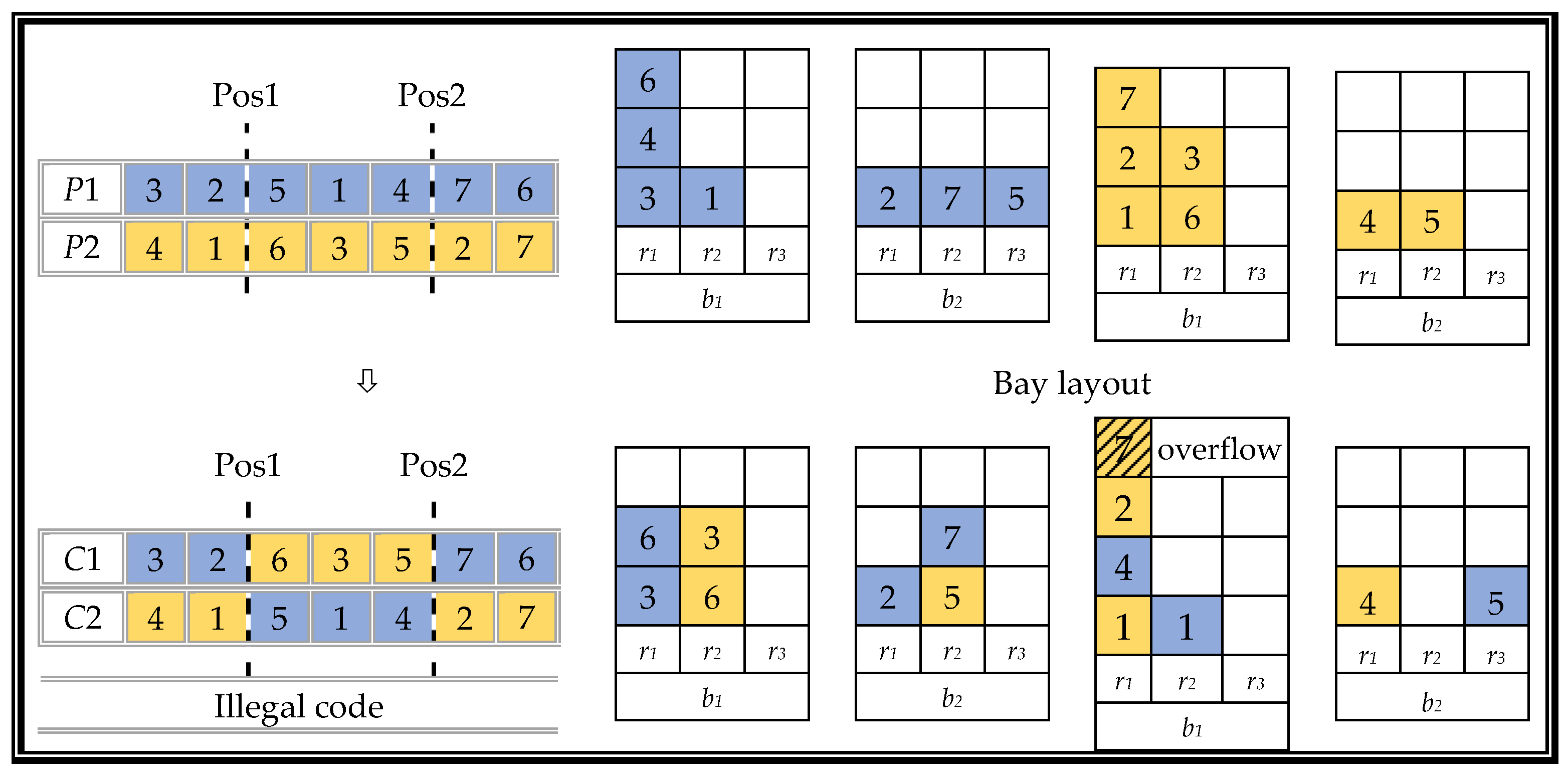
P1:〈(3,1,1), (2,2,1), (5,2,3), (1,1,2), (4,1,1), (7,2,2), (6,1,1)〉 and the other parent chromosome as
P2:〈(4,2,1), (1,1,1), (6,1,2), (3,1,2), (5,2,2), (2,1,1), (7,1,1)〉. In this example, the size of the container is set to
bS = 2,
rS = 3,
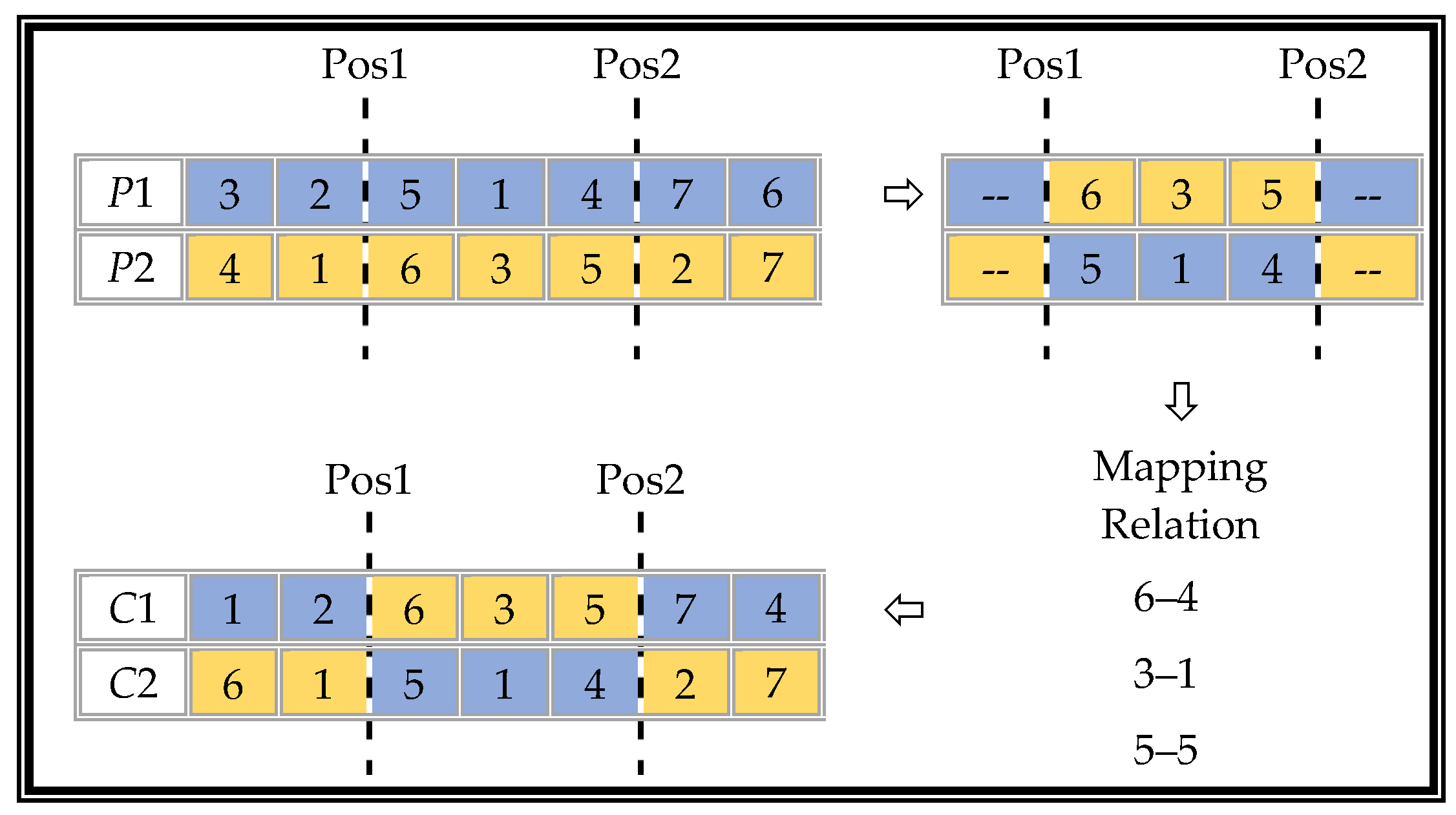
tS = 3. The crossover operation uses a double cut point crossover. In this example, the cut point positions are set to 2 and 5; the specific process of generating the two offspring chromosomes
C1 and
C2 is shown in
Figure 8.
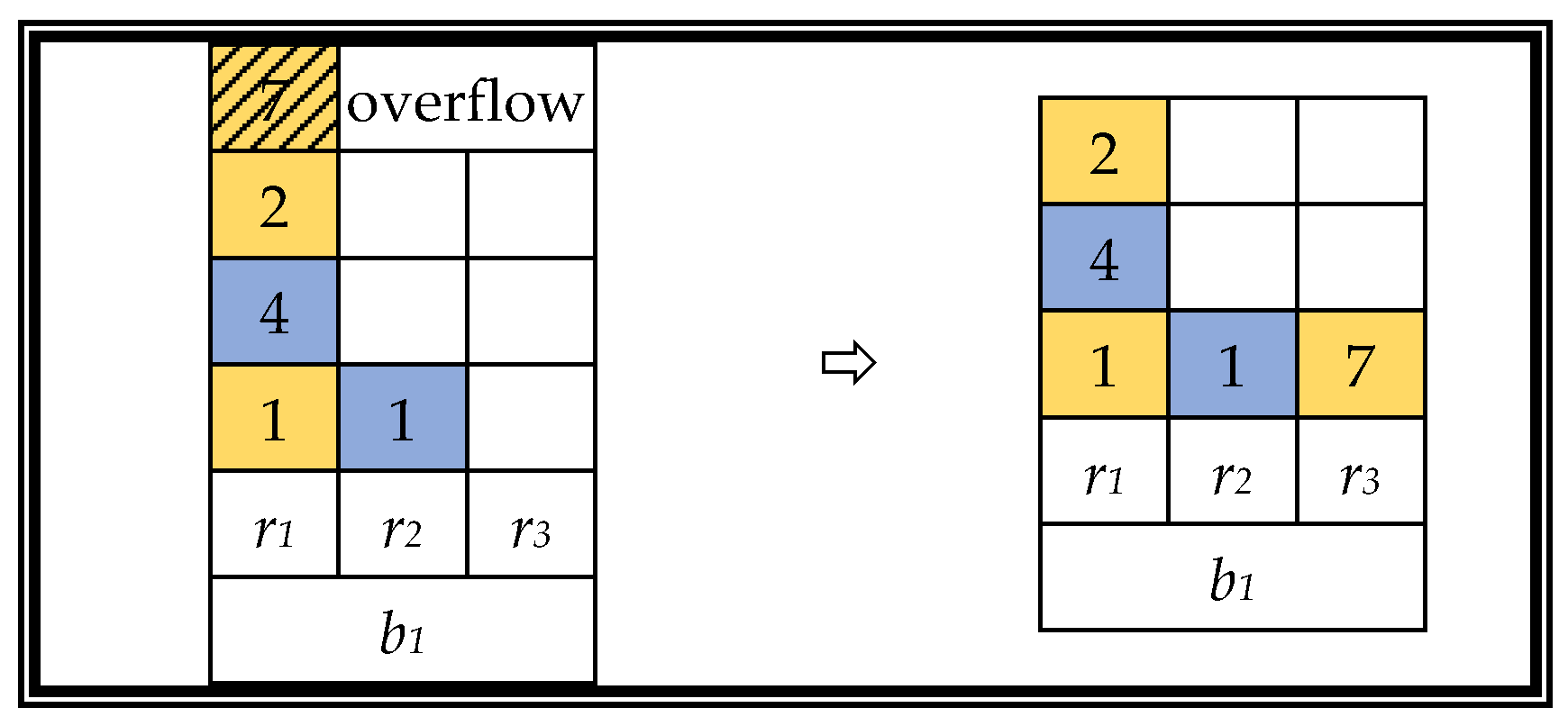
Two problems arise after the cross-recombination operation process. One is that the chromosome encoding of the offspring is illegal, and the other is that a certain row of containers exceeds its containment range, causing a stack overflow. In response to the above problems, we provide the following two renovations.
RENOVATION:
A partially mapped crossover (PMX) uses a unique repair program to solve the illegality caused by a simple double-point intersection. The specific steps are shown in
Figure 9.
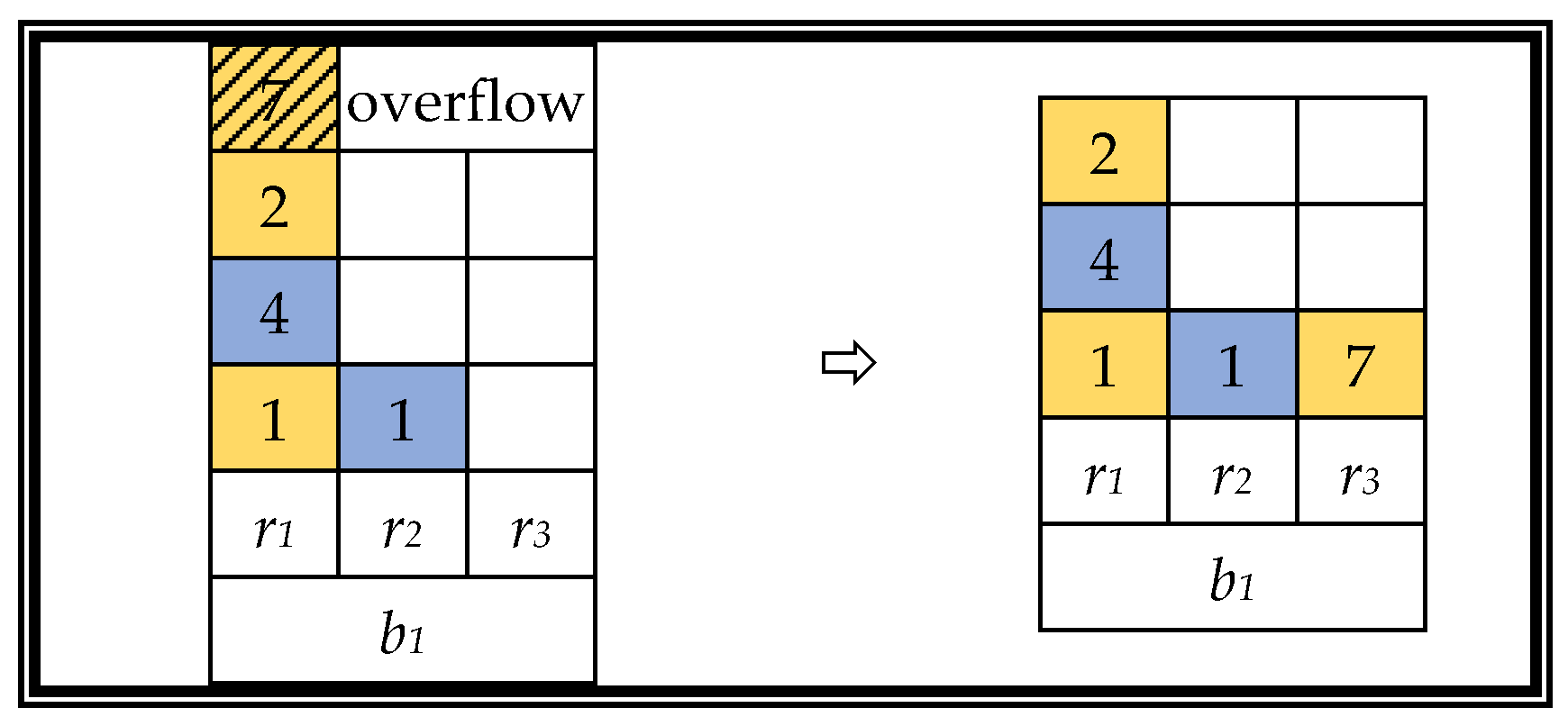
A greedy heuristic strategy is used to solve certain stack overflow problems, as follows. Load the container into the row with the least number of stacked containers in the same bay. If there are more choices, select the closest column. A schematic diagram of the stack overflow resolution strategy is shown in
Figure 10.
A complete loading plan includes both yard containers and ship containers that are voluntarily shifted. Consider the chromosome CH of both the yard container and the shipping container. This chromosome is added to five shipping containers (i.e., 8–12) based on the above CHY; thus, chromosome CH contains twelve genes. Due to voluntary shifts, the length of the chromosomes of the two parents will be different, i.e., the CY is the same and CS (V) is not, which in turn leads to different positions of the cut points when addressing them. We provide a third repair strategy, called the addressing strategy, in response to this problem.
RENOVATION:
- 3.
The addressing strategy is as follows. Mark the voluntary shifted containers in the loading sequence and record their relative positions. Ignore these containers; then, when determining the location of the tangent point, the chromosome gene will only contain the yard containers and will record the location of the tangent point at this time. The containers undergoing voluntary shifts can now be restored according to their previously-registered relative positions.
To obtain a complete chromosome, first determine the position of the tangent point of the double-point crossing according to the addressing strategy, then perform partial mapping and stack overflow repair, respectively, according to repair strategies 1 and 2 to obtain two legitimate offspring chromosomes.
After the crossover operation is performed, several offspring individuals in the population will be selected according to the mutation probability,
Pm, to perform mutation operations in order to increase the diversity of the population and avoid falling into the local optimum. We have designed three types of operators to introduce a small amount of perturbation into the offspring genes and expand the search space to find more promising neighborhoods for exploration. A detailed introduction to specific operation operators is provided in
Section 4.8.
4.7. Local Search
The local search we propose here is a kind of memetic algorithm that uses a selection mechanism similar to that in [
68] to select certain individuals for local search. Local search is added to the framework of NSGA-III, that is, we introduce local search strategies into the iterative process of NSGA-III to realize the self-learning of individuals in the life cycle. After adding local search, NSGA-III uses local search to locally improve certain individuals, which can better balance the relationship between exploration and development in order to obtain a better solution with a higher probability.
First, we define the following aggregate function:
where λ = [λ
1,λ
2,…λ
6] is a weight vector, then the method of generating reference points in NSGA-III is used to generate a set of weight vectors that meet the constraints (as shown in Equation 12 and are uniformly distributed in the objective space. Therefore, the number of weight vectors is
. If we set ζ in the equation to be 5, 252 weight vectors are generated for six-objective optimization problems.
When selecting an individual for local search, we first randomly choose one from these weight vectors using the aggregate function (12) as the comparison index and choose an elite solution through the tournament selection method without replacement. Then, a local search is performed on the solution to obtain one or a set of improved solutions. Algorithm 2 shows the local search process.
| Algorithm2. Framework of local_search (Qt) |
| 1: Q’t ← Ø |
| 2: for i = 1 to do |
| 3: The weight vector λ is randomly selected from the set of weight vectors |
| 4: S ← Tournament Selection with Replacement (Q’t, λ) |
| 5: Ei ← Local Search for Individual (S, λ, l_ier) |
| 6: Q’t ← Q’t ∪Ei |
| 7: end for |
| 8: return Q’t |
Here, represents the number of offspring populations selected to perform a local search and/is the probability of a local search. In other words, the selection operation of “select the elite solution and apply the local search” is repeated/times. As is well-known, local search requires a great deal of calculation time; thus, only a portion of offspring individuals can be selected for local search. If a partial improvement is made to an individual offspring, three types of neighborhood operations that are similar to mutation operations are randomly selected and applied to each selected offspring. This operation is performed l_ier times.
4.8. Neighborhood Operator
There is one last key issue in the algorithm that needs to be explained, namely, the neighborhood operator applied to the mutation operator and how to search locally. In the variant of NSGA-III presented here, the proposed neighborhood calculation is directed at the loading plan, Lp, rather than the solution S, which helps to introduce knowledge related to the optimization problem of container stowage. Therefore, each generated neighborhood must be calculated.
In
Section 4.2., we defined a complete loading plan as consisting of a loading sequence
Ls and the specific location group of a given container on the ship, i.e.,
Lp = 〈(
ID1,
B1,
R1), (
ID2,
B2, R
2), …, (
IDn,
Bn,
Rn)〉. According to the scope and effect of the neighborhood operator, the neighborhood operator is divided into the following three categories.
- 1.
Operators applied to the loading sequenceLs: this type only acts on the loading sequence, including three operators.
- (1)
Forward shift operator: two indexes x and y (1 ≤ x < y ≤ n) are randomly generated, then the triplet (IDy,By,Ry) is shifted forward to the position of x−1. At this time, the loading plan is Lp = 〈(ID1,B1,R1), …, (IDy,By,Ry), (IDx,Bx,Rx),…, (IDn,Bn,Rn)〉.
- (2)
Backward shift operator: two indexes x and y (1 ≤ x < y ≤ n) are randomly generated, then the triplet (IDx,Bx,Rx) is shifted back to the position of y + 1. At this time, the loading plan is Lp = 〈(ID1,B1,R1), …, (IDy,By,Ry), (IDx,Bx,Rx),…, (IDn,Bn,Rn)〉.
- (3)
ID_swap operator: two indexes x and y (x ≠ y) are randomly generated, then the sequential positions of the two triplets of (IDx, Bx, Rx) and (IDy, By, Ry) are swapped.
The loading plan obtained after applying this type of operation operator remains feasible.
- 2.
Operators applied to the stack of the container ship: this operator will change the container stack information in the loading plan, mainly including the following two operators.
- (1)
Reassign operator: one index x (1 ≤ x ≤ n) and a container ship slot A are randomly generated; slot A satisfies tA ≤ tS and is not in the same position as a slot (Bx, Rx) corresponding to (IDx, Bx, Rx), i.e., (BA, RA) ≠ (Bx, Rx). Then, replace (IDx, Bx, Rx) with (IDx, BA, RA) in the former loading plan Lp to obtain a new neighbor loading plan.
- (2)
Container slot swap operator: two indexes x and y (1 ≤ x < y ≤ n) are randomly generated, then their slot position information is exchanged. At this time, the loading plan is Lp = 〈(ID1,B1,R1), …, (IDx,By,Ry),…, (IDy,Bx,Rx) …, (IDn,Bn,Rn)〉.
- 3.
Operators applied to voluntary shifts: As mentioned earlier, in order to reduce the number of container shifts in future ports certain containers CS (V) will be temporarily placed on the quay shore and on the containers in the yard before being loaded back onto the ship. Two operators are proposed to add or reduce containers for the set CS (V).
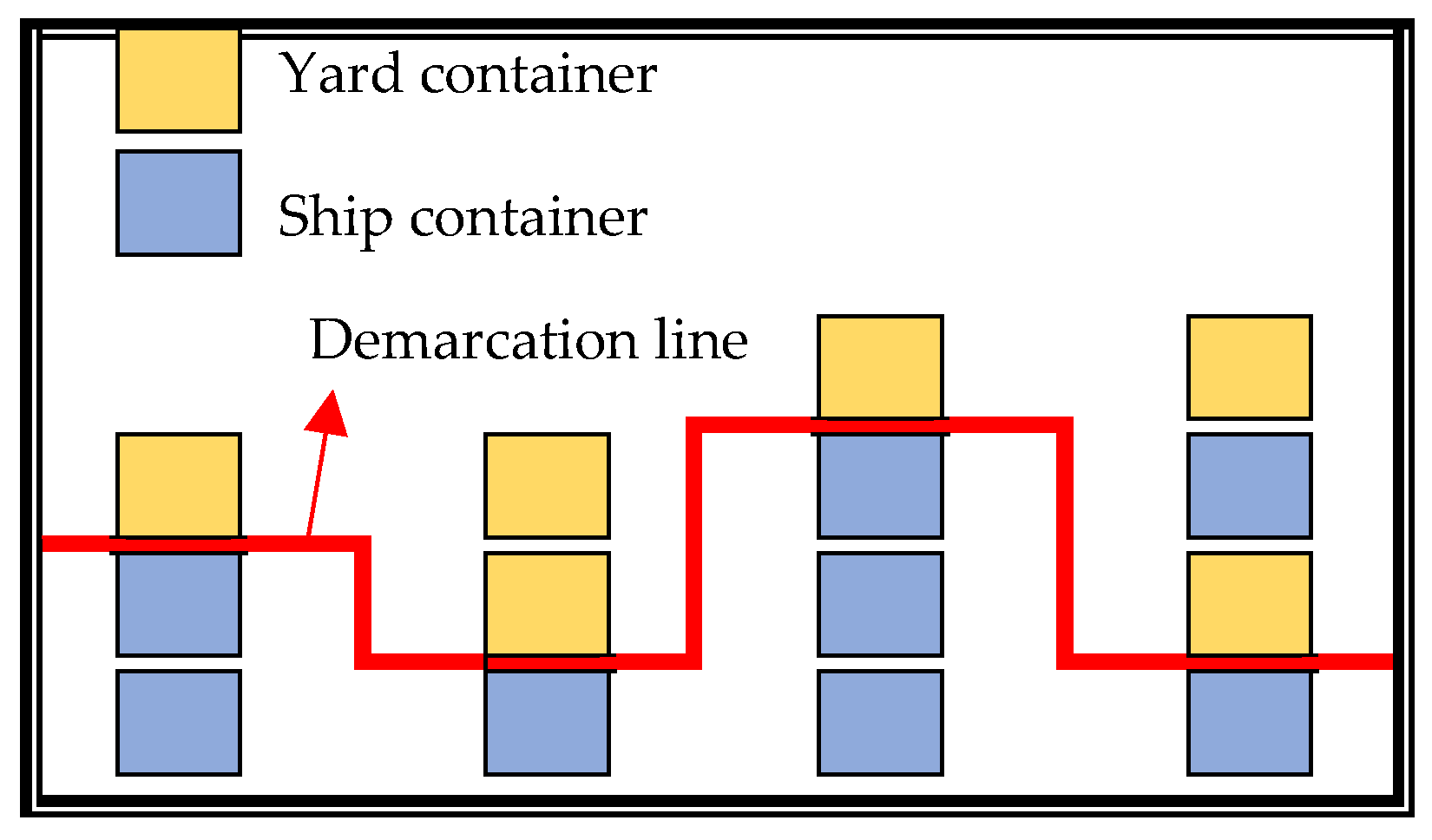
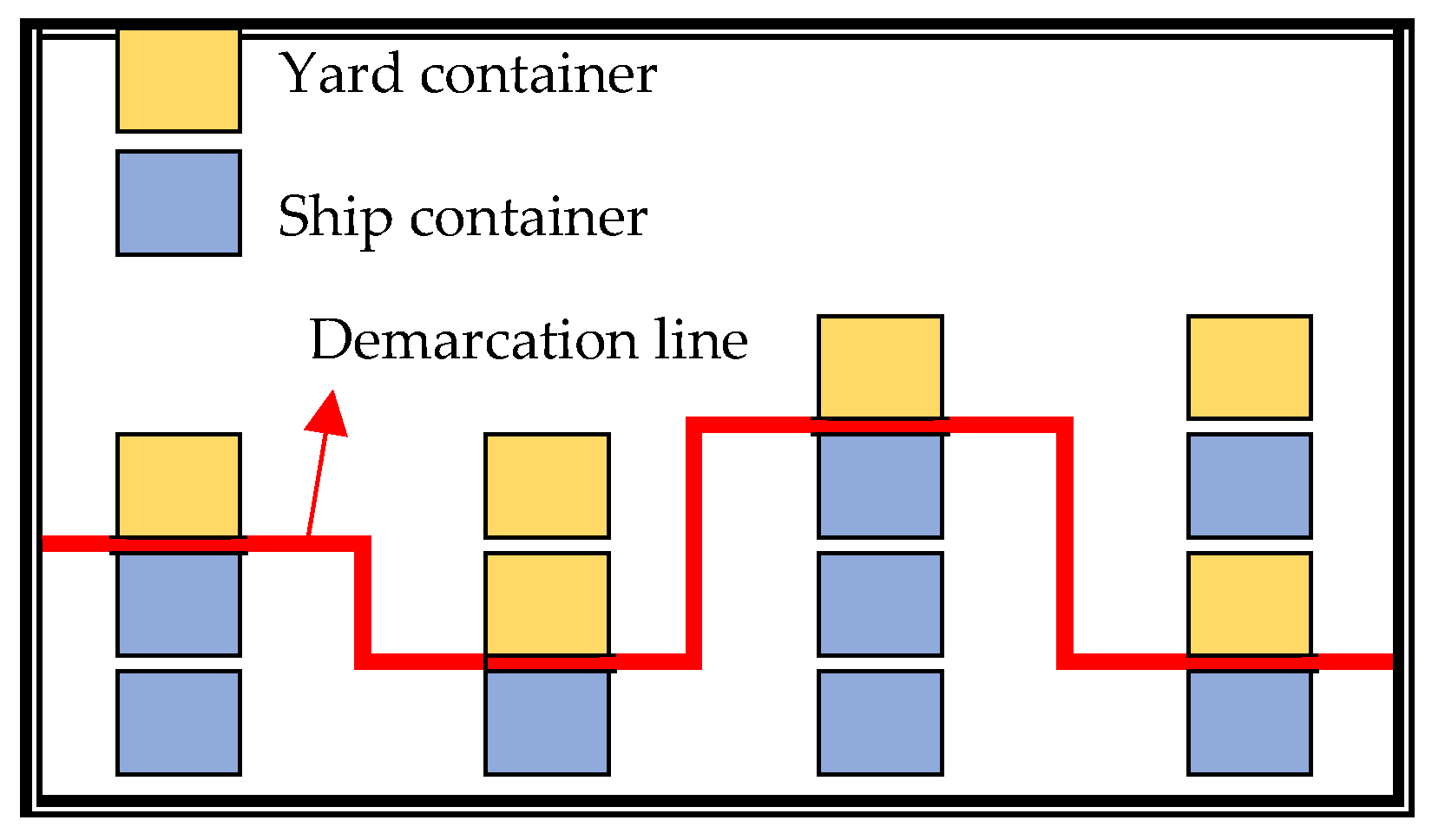
To better explain the following operating procedures, we first define the concept of the “demarcation line”. The “demarcation line” is a vertical partition that divides the final ship container layout into two parts. The upper part of the demarcation line consists of the yard container
CY and the voluntary shift container
CS (
V), i.e.,
CY ∪
CS (
V); the lower part is the container on the ship, i.e.,
CS\
CS (
V), except for the part undergoing the voluntary shift.
Figure 11 shows an example of the “demarcation line”.
- (1)
To add a voluntary relocation container, randomly select a container below the demarcation line and activate it as a voluntary shift container, IDs. The original position of the selected container should have two or more containers in the stack, and it should be at the uppermost position f of the lower part of the demarcation line. Then, randomly insert the container into the loading plan and randomly assign a position to it to obtain a neighborhood loading plan, i.e., 〈(ID1,B1,R1), …, (IDi-1,Bi-1,Ri-1), (IDs,Bs,Rs), (IDi,Bi,Ri)…, (IDn,Bn,Rn)〉.
- (2)
To remove a voluntary relocation container, randomly select a voluntary relocation container in the upper part of the dividing line and remove it from the loading plan.
5. Experiment and Analysis
In this section, we describe a series of numerical experiments used to test the effectiveness of the algorithm proposed in this paper and the design a comparative experiment involving other optimization methods. The experimental results are analyzed and discussed in the following sections. The test data are explained in
Section 5.1; a comprehensive evaluation index of the experimental results is provided in
Section 5.2; the parameter settings used in the experiment and the comparison experiment with other algorithms are provided in
Section 5.3; and
Section 5.4 lists the results of the test and the analysis of the results. The algorithm proposed in this paper was implemented in MATLAB R2019b (win64). All experiments were performed on a Windows server with 16.0 GB RAM and an Intel (R) Core (TM) i7 processor clocked at 3.0 GHz. The times used in the text are the CPU seconds of this machine.
5.1. Setting Data
To verify the effectiveness and practicability of our proposed algorithm, we set up 48 sets of calculation examples for the experiment according to the ship structure and stacking methods. The examples are summarized in
Table 3. All containers are 20 ft in size, the weight in group A is set to unit 1, and the weight of containers in group B ranges from unit 10 to unit 20.
bY,
rY,
tY, and
NY represent the number of bays, the number of stacks, the height of the layer, and the number of yard containers, respectively, in each group of calculation examples. Similar to the yard containers, the relevant values concerning the ship are set to
bS,
rS,
tS, and
NS. The value set indicates the different bay position structures, which ensures enough places to accommodate the containers.
A rectangular structure is adopted for the ship or yard bay structure and different layers and numbers of columns are set. Each type of bay structure has a different bay layout randomly generated according to certain principles. The principle of generating the bay position layout is as follows: the containers in the yard bay are 50~80% of the total amount of the bay capacity and the shipping container occupancy rate is 20~30%; according to different destinations, different priorities are generated according to which more distant destinations have higher priority. We set six different priorities in this article.
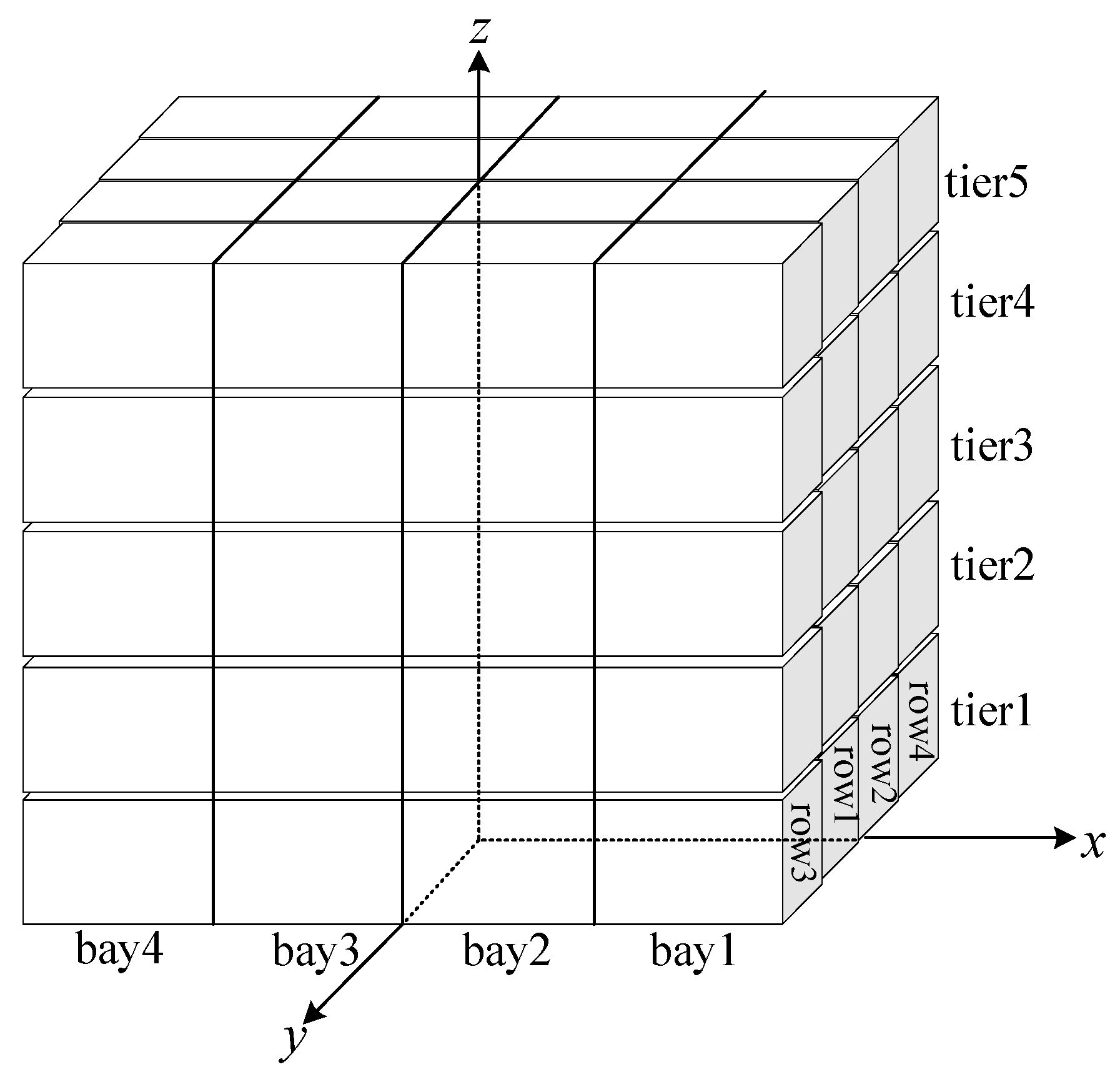
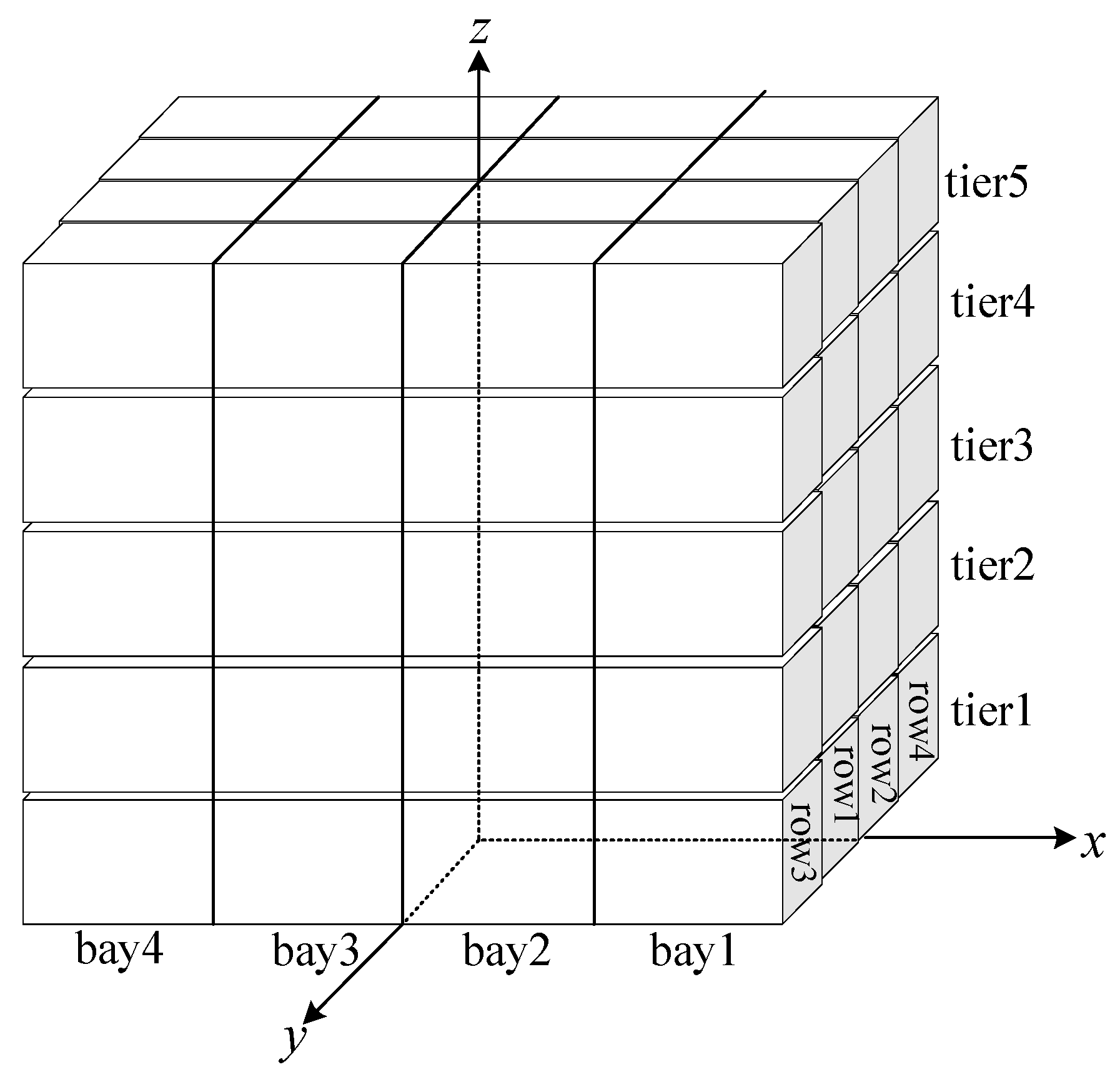
The establishment of the ship coordinate system is intended to accurately express the spatial position of any point on the ship, which is convenient for positional determinations and ship performance calculations. According to our assumptions the ship is considered as a box structure, and we use the
O-xyz rectangular coordinate system fixed on the ship, as shown in
Figure 12.
Assuming that the center of gravity of the container is at the geometric center, this is true in practice as well. As the container is a cube with a side length of 1, the coordinates of the center of gravity of each container can be obtained according to the coordinate system we have established. The ship in the example consists of four bays (bay1~bay4), each bay has four stacks (row1~row4), and each stack has five layers (tier1~tier5); thus, the coordinates of the center of gravity of each container in this example are as shown in
Table 4.
The essence of the stability calculation for different loading plans (i.e., different solutions) is the problem of “variation of weight in the ship”, which conforms to the attributes of the ship displacement and metacenter position (i.e., KM) invariants. According to the above settings, the three objective functions in the category of ship stability (i.e., the ship’s initial transverse metacentric height, heel angle, and trim) can be expressed as (1) ; (2) ; (3) where represents the weight of the i-container.
5.2. Performance Indicators
Researchers have proposed many methods for evaluating the performance of objective evolutionary algorithms, which can be summarized into three categories. The first type is used to assess the tightness between the computed set and the true Pareto-optimal surface, and is mainly used to evaluate the convergence of the algorithm. Here, we use the index of coverage between two solution sets (CS). The second category is used to assess the distribution of the solution set; here we use the maximum spread (MS). The third category allows for comprehensive consideration of the convergence and distribution of the solution set in order to evaluate the comprehensive performance of the solution. Here, we use the inverse generation distance (IGD).
In 2000, Zitzler proposed an evaluation method to compare the relative coverage of the two solution sets in the algorithm [
69]. Assuming that
P′ ⊆
P and
P″ ⊆
P are two solution sets in the objective space (with
P being the objective space solution set) and the coverage ratio is between
P′ and
P″ (two set coverage,
CS), the equation is as follows:
If all points in P′ dominate or are equal to all points in P″, then CS = 1 can be defined; otherwise, CS = 0. Suppose CS (P′, P″) > CS (P″, P′); in that case, the dominance relationship of P′ is considered to be better than that of P″. Generally speaking, the intersection of the two solution sets P′ and P″ is not empty CS (P′, P″), and therefore CS (P″, P′) must be considered together when evaluating an algorithm.
The Maximum Spread (
MS) evaluation method (known as the
D method) is used to measure the spreading performance of the solution set distribution of the algorithm. The larger the
MS value, the better the extension performance of a solution set. In particular, when the
MS is 1, the solution set completely covers the entire real Pareto front. Assuming that
P′⊆
P is a non-dominated solution set in the objective space, the for the
MS value is calculated as follows:
where
fimin and
fimax represent the minimum and maximum values of the
i-th goal (total
M) in the objective space solution.
Inverted Generational Distance (
IDG) is the inverse mapping of Generational Distance. It uses the average distance from the individual in the Pareto-optimal solution set,
P*, to the non-dominated solution set
P′ obtained by the algorithm. Therefore, it is calculated as follows:
where
d (
a’,
a*) represents the Euclidean distance between solutions
a’ and
a* in the objective space solution. The calculation expression is as follows:
If |P*| can represent the Pareto front fully, then IGD (P′, P*) can, in a certain sense, comprehensively measure the convergence and diversity of the solution set. Because the solution set P′ must be close enough to the Pareto front surface in the objective space in order to obtain a smaller value of IGD (P′, P*), that is, the smaller the value of IGD, the better, and any part of P* has a corresponding solution to represent in P′, in an ideal situation solving the algorithm is a process of continuously approaching the optimal boundary P* and finally reaching the optimal boundary. However, in practical applications it is often difficult to find the true Pareto optimal surface. Here, P* is the Pareto front of all solutions obtained in all comparison algorithms in our experiment.
5.3. Parameter Setting and Comparison Algorithm
The parameter settings of the numerical calculation are shown in
Table 5. Because the result of the calculation provides a set of Pareto optimal solutions, allowing the decision-maker to compromise the choice, we therefore set the population size to 100 based on experience. The algorithm uses the systematic method proposed by Das and Dennis to generate structured reference points. The number of reference points generated by this method depends on the number of objective functions
M and another positive integer
p, where
p represents the goal of evenly dividing each dimension into
p parts; the equation is
[
70]. According to [
64], the number of reference points should be equivalent to the population size. Therefore, we set the value of
p to be equal to 4 and the number of reference points to 126.
We used calculation examples 1A and 1B to find the optimal
Pc and
Pm by adjusting different crossover probabilities and recombination probabilities while keeping the other parameters unchanged. For each set of calculation examples, we performed 30 independent calculations and used average result as the final output value.
P* is the set of non-dominated solutions for all operations. The average
IGD of 30 operations is provided in
Table 6, and the best result (i.e., the smallest value 0.0106) is marked in bold. It can be seen from
Table 6 that the crossover probability,
Pc, has a more significant impact on the comprehensive performance of the algorithm. Therefore, we set the crossover probability to 100% and the mutation probability to 5%.
As described in
Section 4.8, we designed three kinds of neighborhood operators for local search and mutation. To verify the influence of neighborhood operators on the algorithm’s performance, we set up comparative experiments. The results of this comparative experiment are shown in
Table 7. The comprehensive version of the algorithm under each combination (i.e., average
IGD) is provided as well.
From
Table 7, it can be seen that the operator acting on the container stack (i.e., N2) has the most significant impact on the algorithm, the operator working on the loading sequence (i.e., N1) has the second-most, and the operator (i.e., N3) acting on the voluntary shifts has the least impact on the algorithm. When all operation operators are included, the algorithm’s overall performance is the best; thus, the neighborhood operator we proposed has a positive impact on the algorithm’s performance.
In our experiment, we designed six different algorithms; the related explanations of these algorithms are provided in
Table 8. As previously mentioned, in order to comprehensively evaluate the performance of the proposed algorithm it is necessary to obtain the true Pareto front. However, due to the complexity of the MaO-CSPP, the true Pareto front cannot be obtained in polynomial time. Therefore, the best possible approximate solution must be found. We compared the other five algorithms to obtain the best approximate solution
P*. In
Table 8, RWGA is a random weighted genetic algorithm, a better algorithm in the priori technology. Specific details regarding the algorithm can be found in [
54].
5.4. Results and Discussion
According to the parameter settings in
Section 5.3, we conducted experiments on each algorithm. Each algorithm was applied to the 48 instances generated in
Section 5.1, and each instance of examples of each algorithm was independently run 30 times. Then, according to the performance indicators set in
Section 5.2, the average value of each instance indicator was obtained. The average values of the indicators are summarized in
Table 9,
Table 10 and
Table 11, with the best results for each group in bold.
It can be seen from the results in
Table 9 that among the 48 examples, 31 instances of NSGA-III-L achieved the best results (i.e., the smallest
IGD), and 17 instances of NSGA-III-NL achieved the best results. This shows that the proposed local search significantly improves the performance of NSGA-III, making it more pertinent when solving MaO-CSPPs. It can be seen from the average value of
IGD in the 48 examples that the performance of NSGA-III is better than that of NSGA-II, and that of NSGA-II is better than RWGA. Although the performance of NSGA-III-NL is slightly worse than that of NSGA-III-L, it is generally better than the other four algorithms. The results show that NSGA-III is more suitable for handling MaO-CSPPs. For each type of algorithm, whether it is NSGA-III, NSGA-II, or RWGA, the performance of the algorithm itself improved after adding local search, making
IGD_ave (NSGA-III-L) <
IGD_ave (NSGA-III-NL),
IGD_ave (NSGA-II-L) <
IGD_ave (NSGA-II-NL), and
IGD_ave (RWGA-L) <
IGD_ave (RWGA-NL).
When calculating
CS, we considered only the pairwise comparison under the optimal performance of each algorithm, i.e., only the algorithm with local search. The experimental results for
CS are shown in
Table 10.
From the results in
Table 10, it can be seen that the solution produced by NSGA-III-L dominates most of the solutions produced by NSGA-II-L, i.e., in 47 out of 48 examples, and dominates approximately 92% (44 out of 48) solutions produced by RWGA-L; thus, the above calculation holds. From
Table 9, we can conclude that the overall performance of NSGA-II-L is better than that of RWGA-L. However, when comparing the
CS, the solutions produced by RWGA-L dominate most of the solutions produced by NSGA-II-L (44 out of 48 examples). This is because the solution space of each calculation example is vast. RWGA-L can generate solutions with the help of the previously-set weights. When comparing the coverage of the two algorithms, RWGA-L performs better than NSGA-II-L. This result reflects the limitations of NSGA-II-L in solving multi-objective optimization problems, that is, when the number of objective functions is greater than three its searchability for non-dominated solution sets decreases sharply.
Table 11 shows that we can obtain the
MS calculation results of each algorithm. These results show that NSGA-II-NL performs the best in terms of the extent of the target spatial distribution of solution sets, and NSGA-II-NL performs second. However, RWGA-L and RWGA-NL show poor results. Although NSGA-III is superior to RWGA, it is not as good as NSGA-II. The above results show that NSGA-II-NL and NSGA-II-L can better obtain the wide distribution of the entire solution set in the target space, and therefore can provide decision-makers with a more complete and extensive solution space.
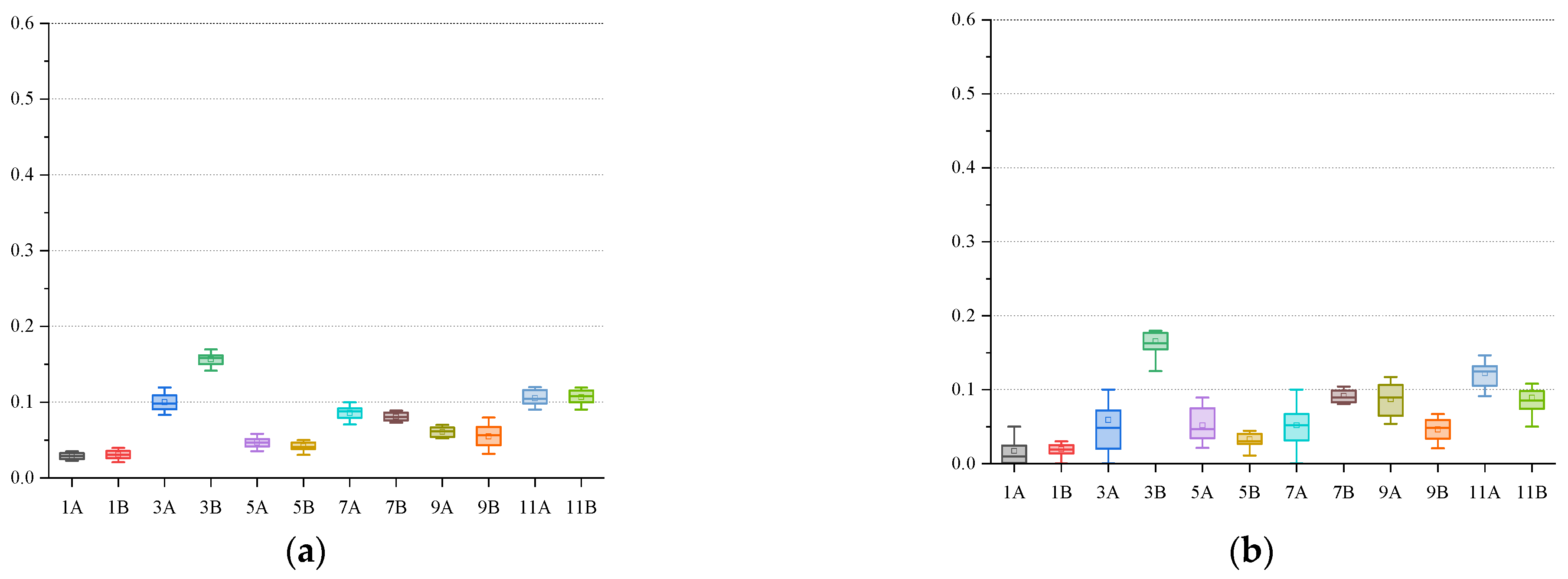
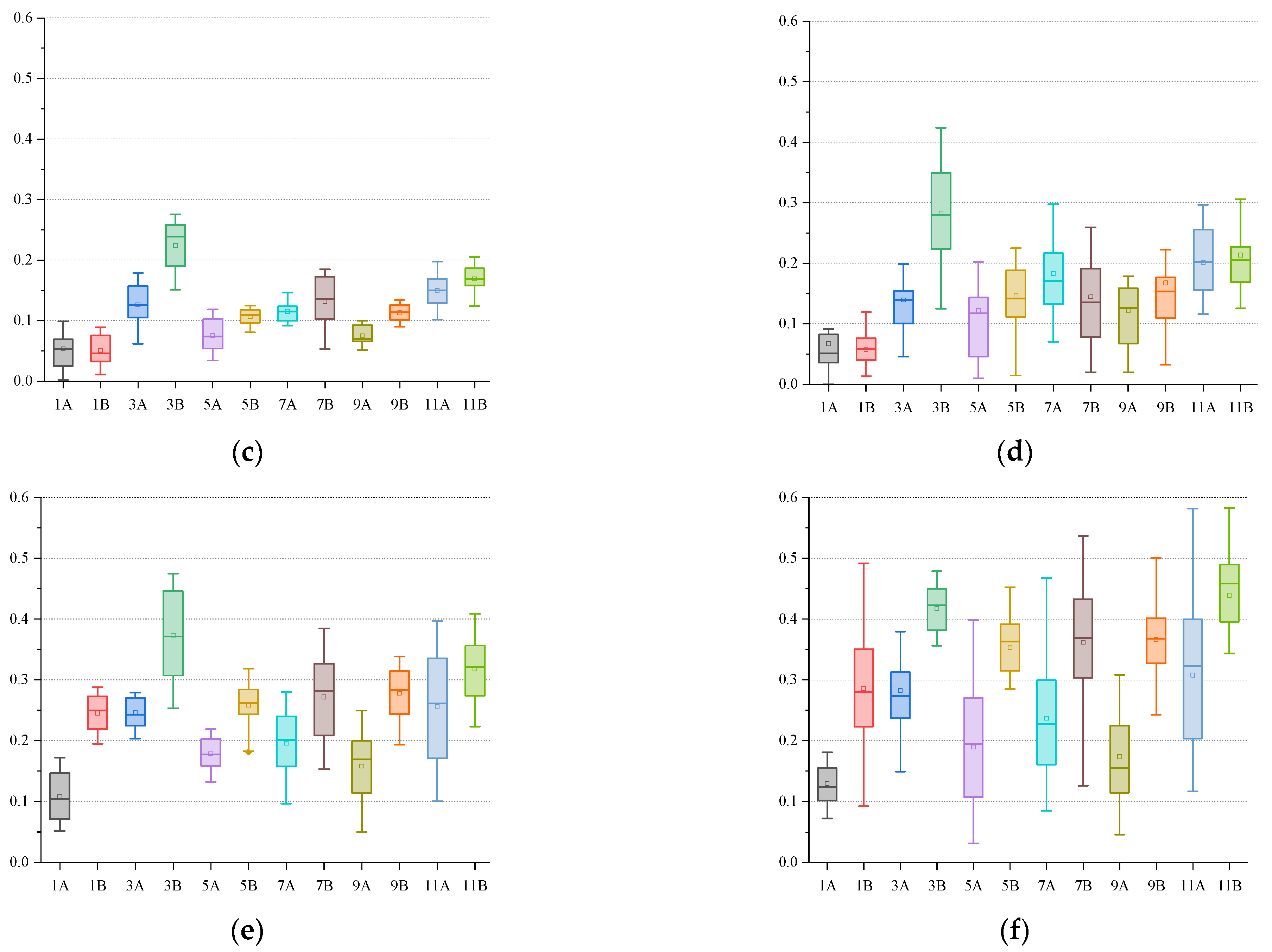
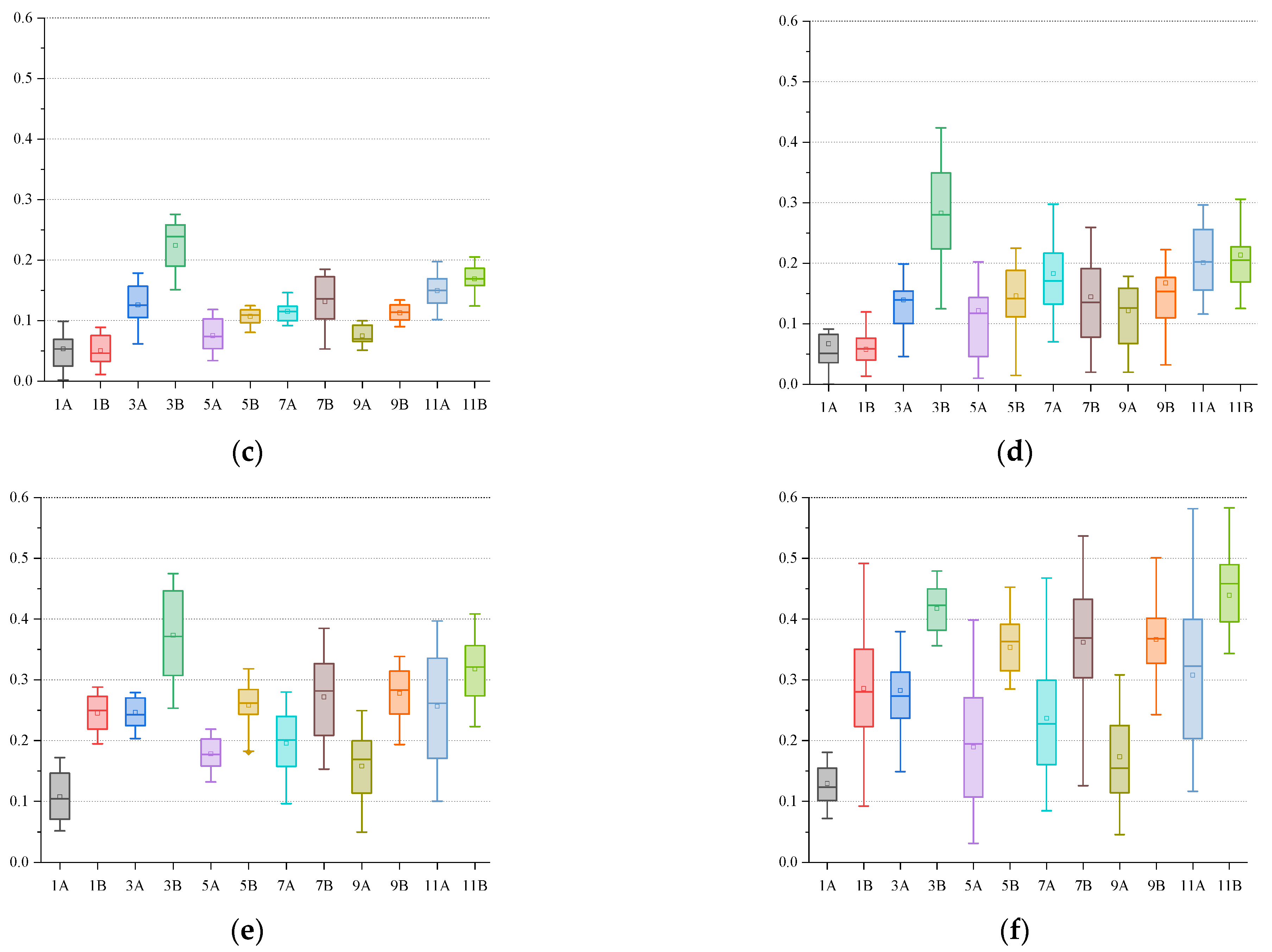
To better display the discrete distribution of the calculation results of each algorithm, we use the form of box plots for display. We selected twelve representative calculation instances (1A, 3A, 5A, 7A, 9A, 11A, 1B, 3B, 5B, 7B, 9B, 11B); each calculation example was independently run thirty times under each algorithm, and the data from those thirty runs are displayed in the form of box plots, as shown in
Figure 13.
The upper line of the box is the upper 1/4 median , the middle line of the box is the median , the lower line of the box is the lower 1/4 median , and the top and bottom short lines represent the largest observations. For the observation of the box plot, first, the value of the box must be within the convergence range to indicate that the individual has converged. Second, smaller box lengths are better, and mean that the individuals are more concentrated, leading to relatively more stable algorithm performance. In addition, the distribution of individuals can be seen from the position of the median line. Finally, the number of extremely discrete individuals is as small as possible.
It can be seen from
Figure 13 that NSGA-III can produce the most promising non-dominated solution. The individuals in the solution are relatively concentrated, the algorithm’s performance is stable, the convergence is good, and the robustness is strong.
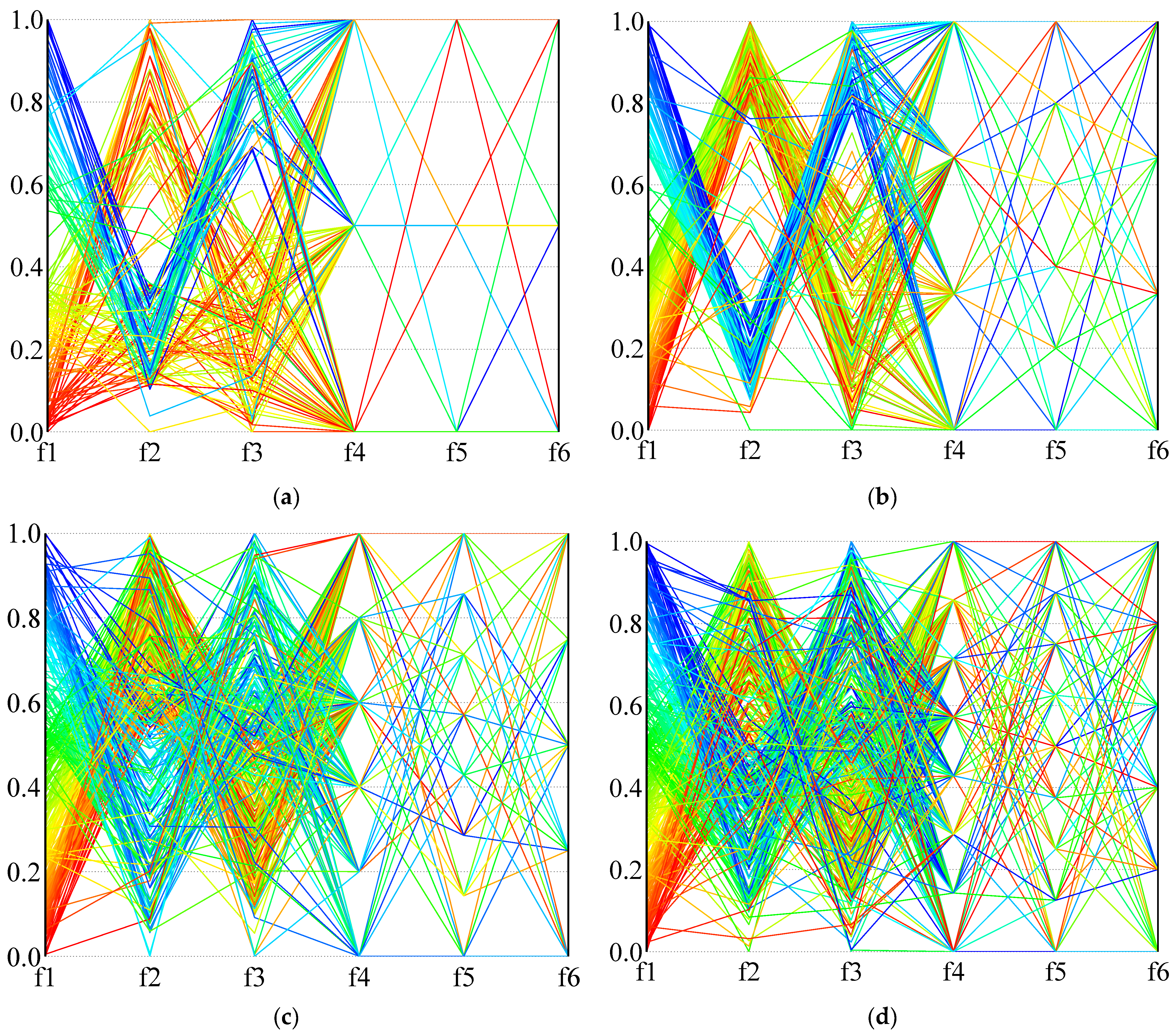
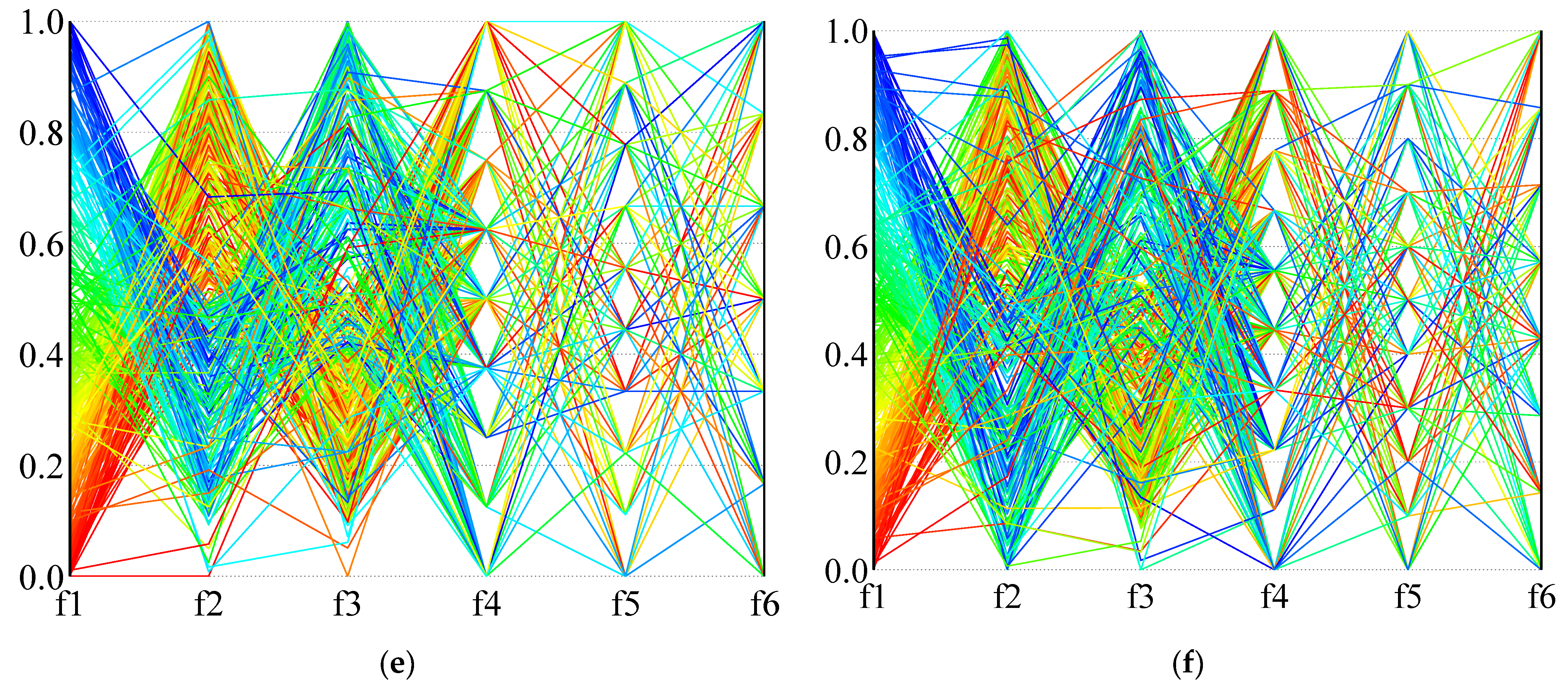
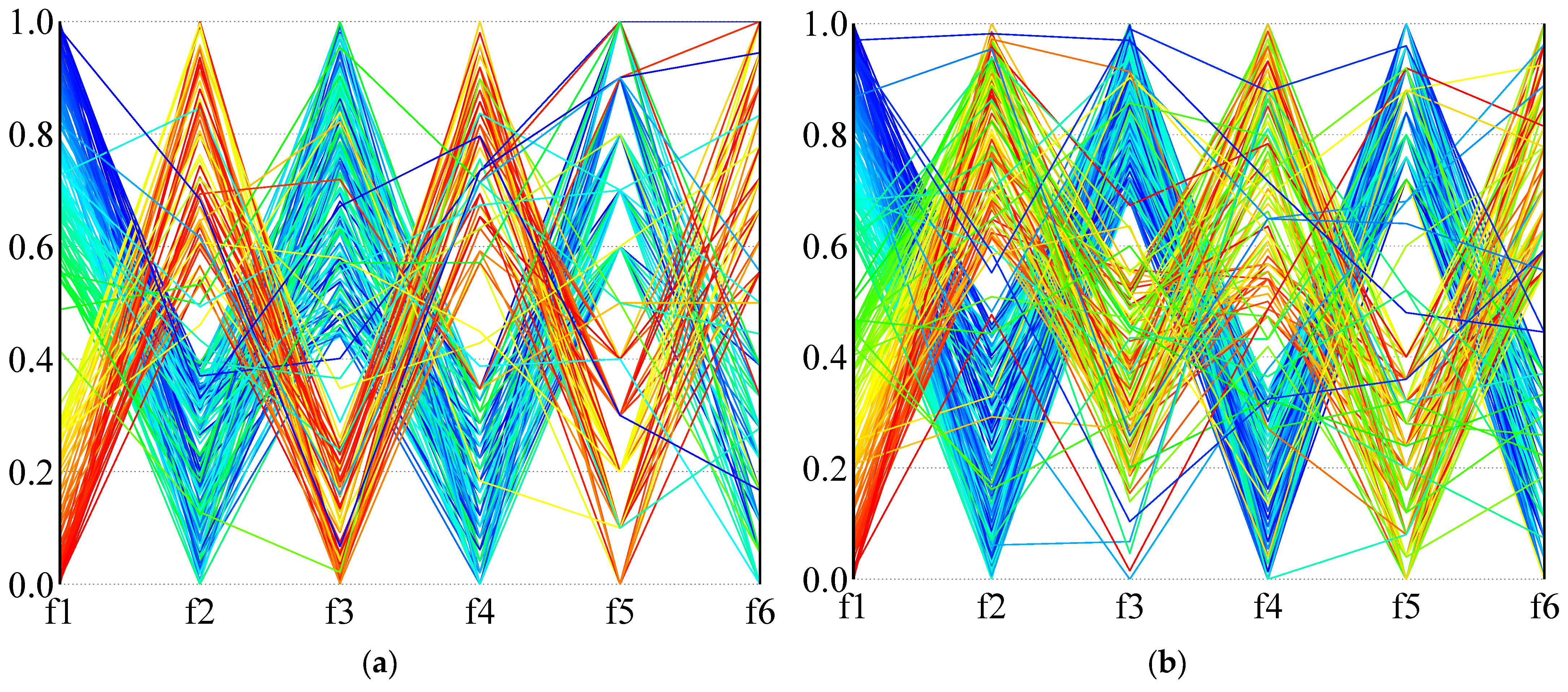
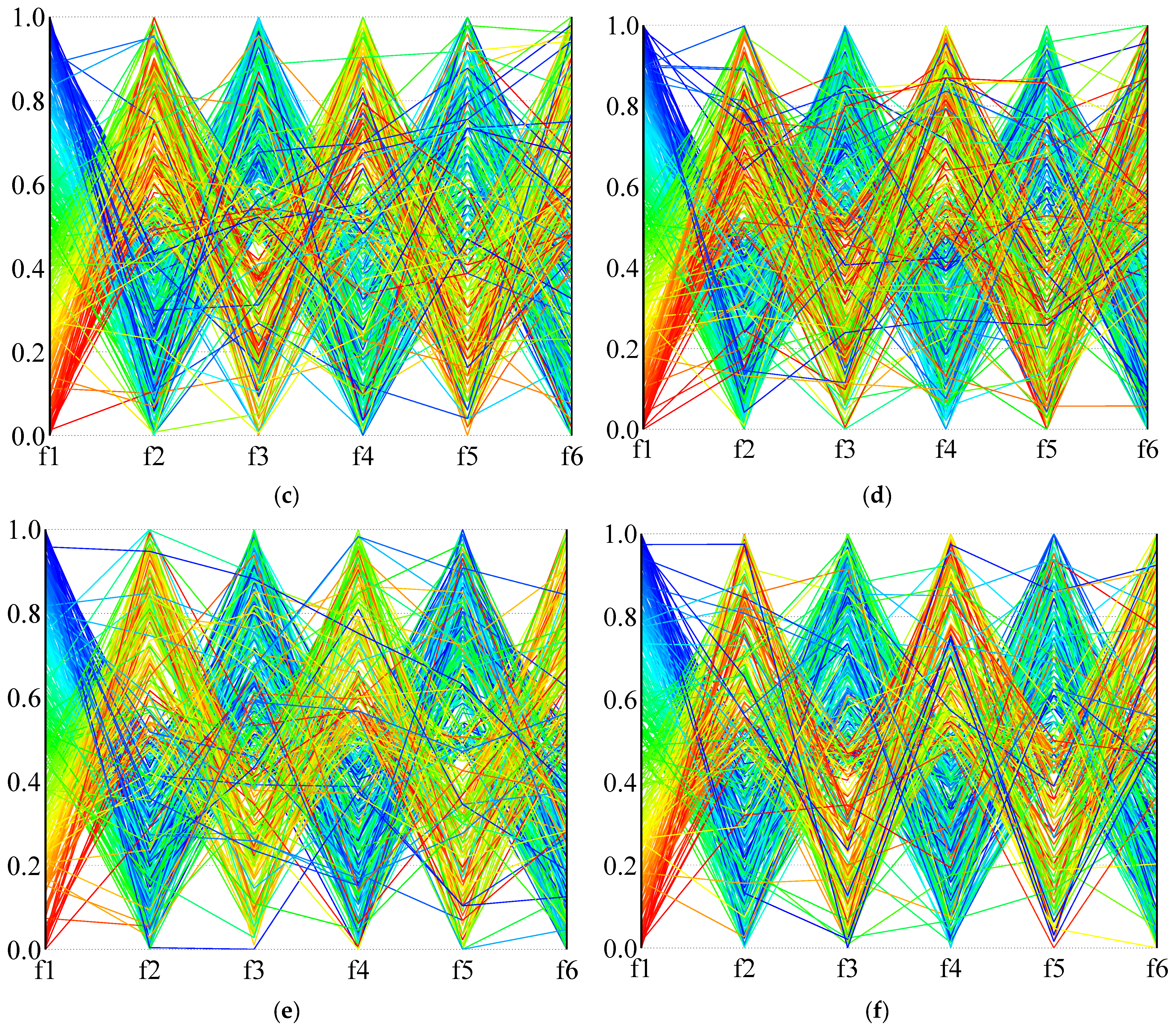
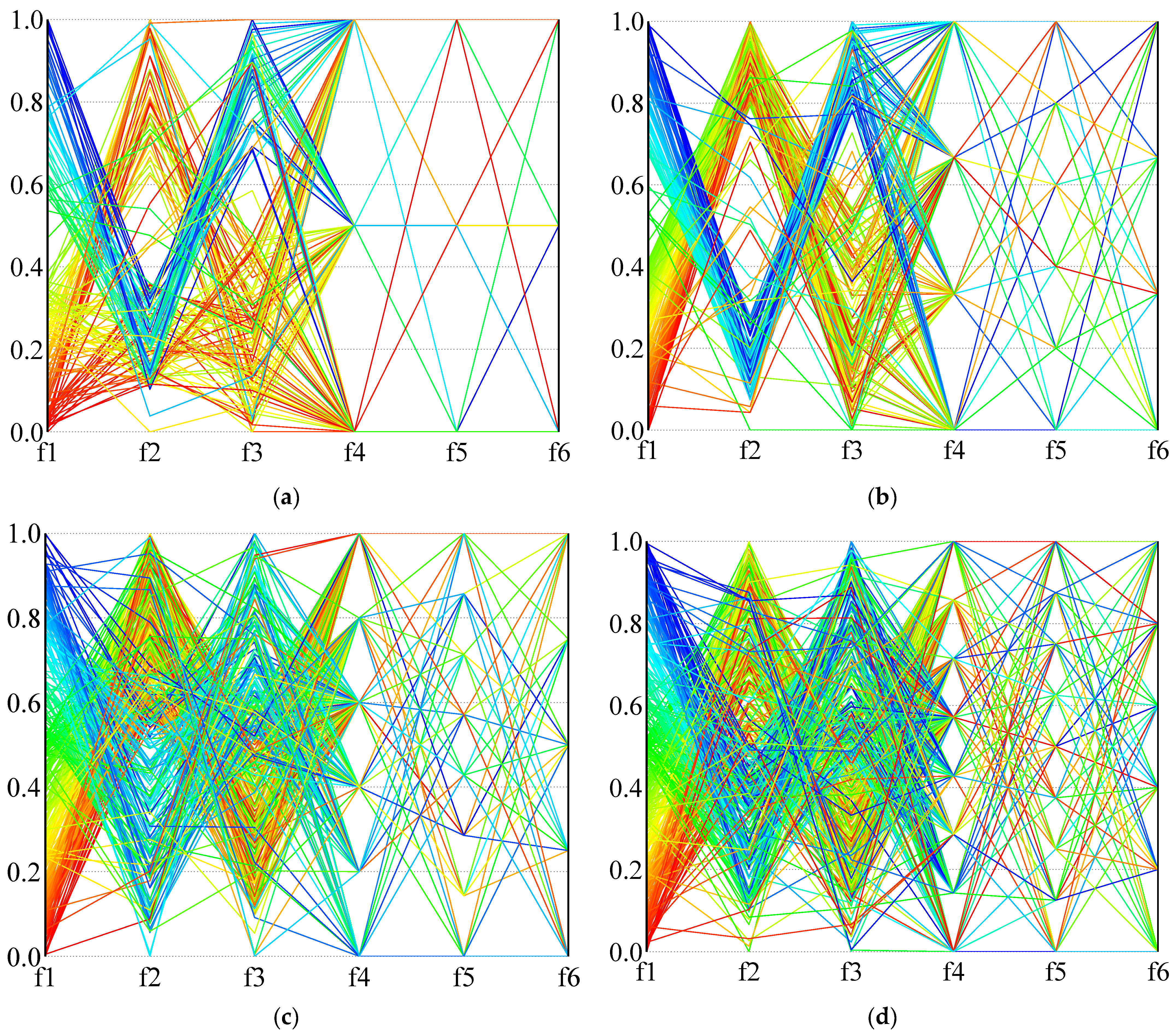
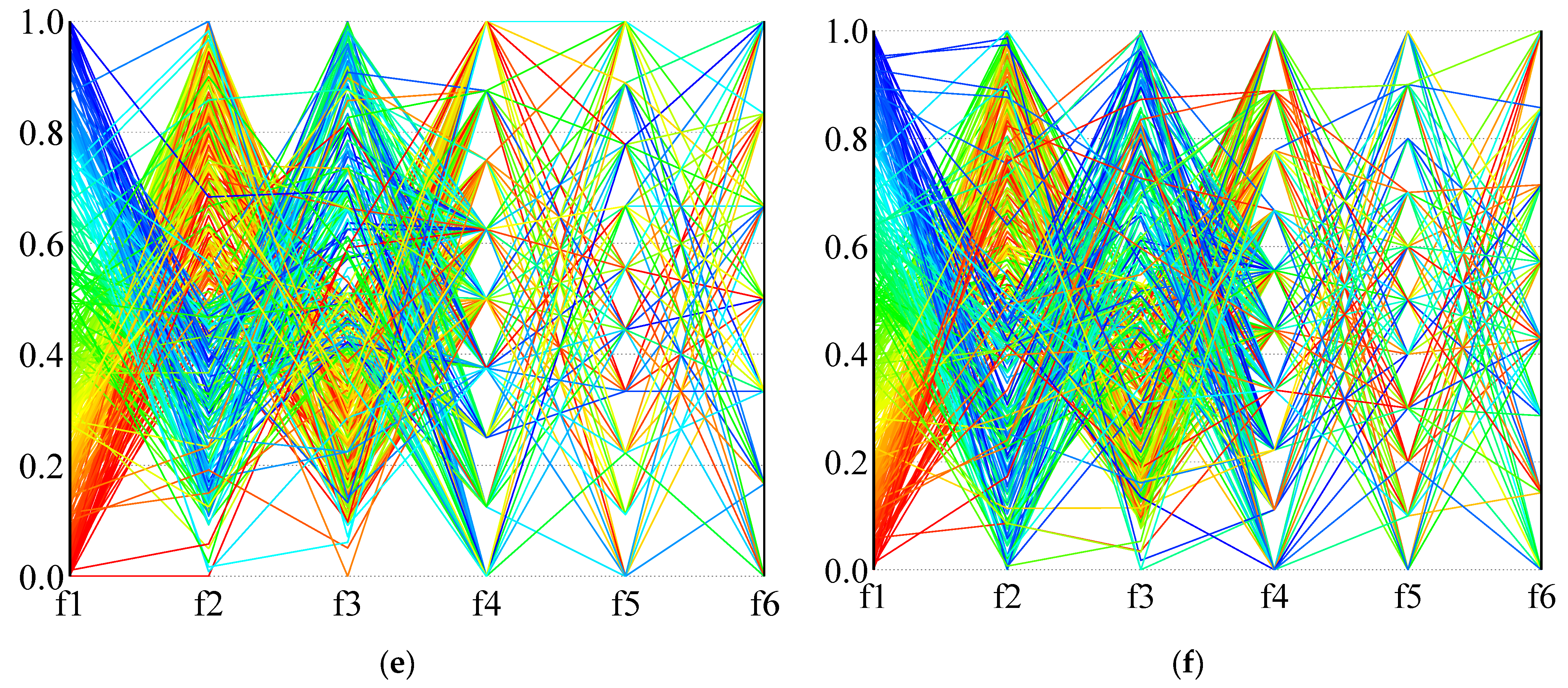
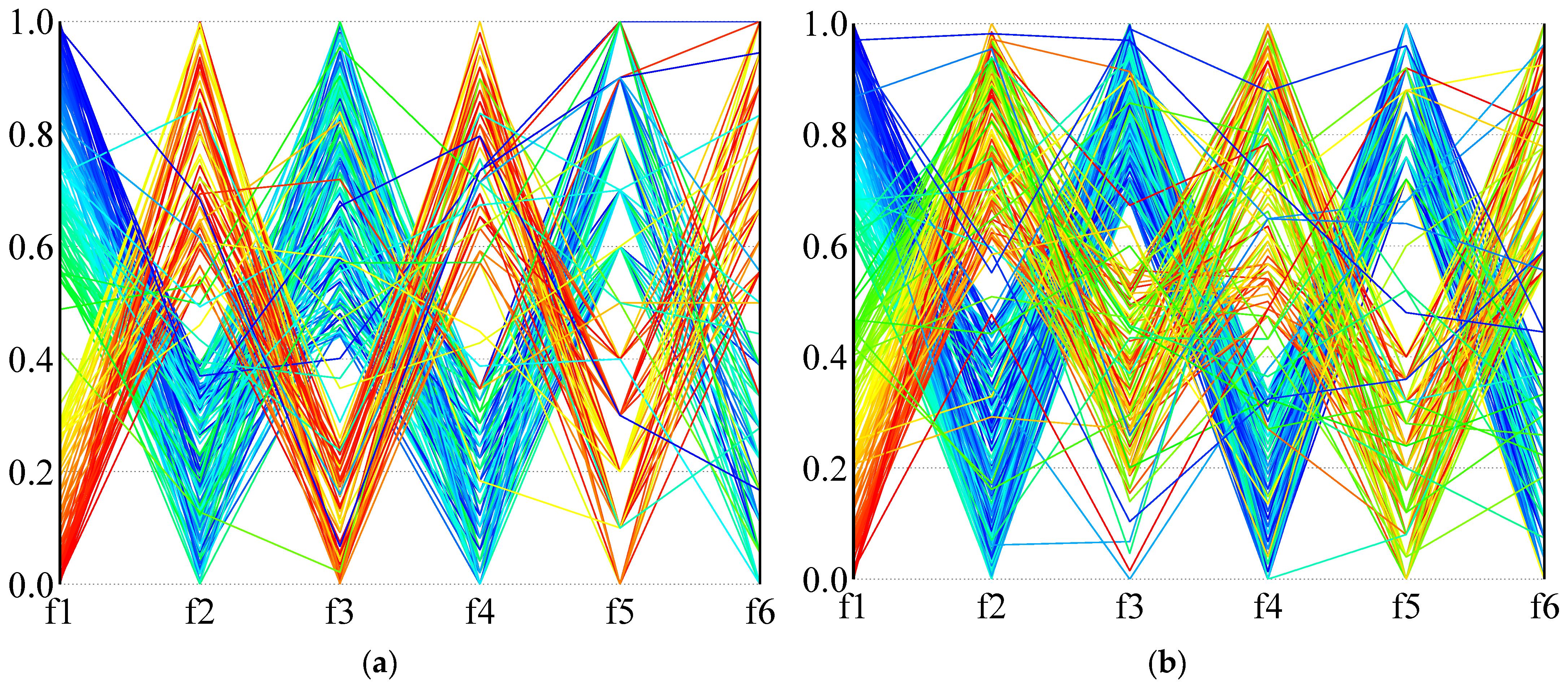
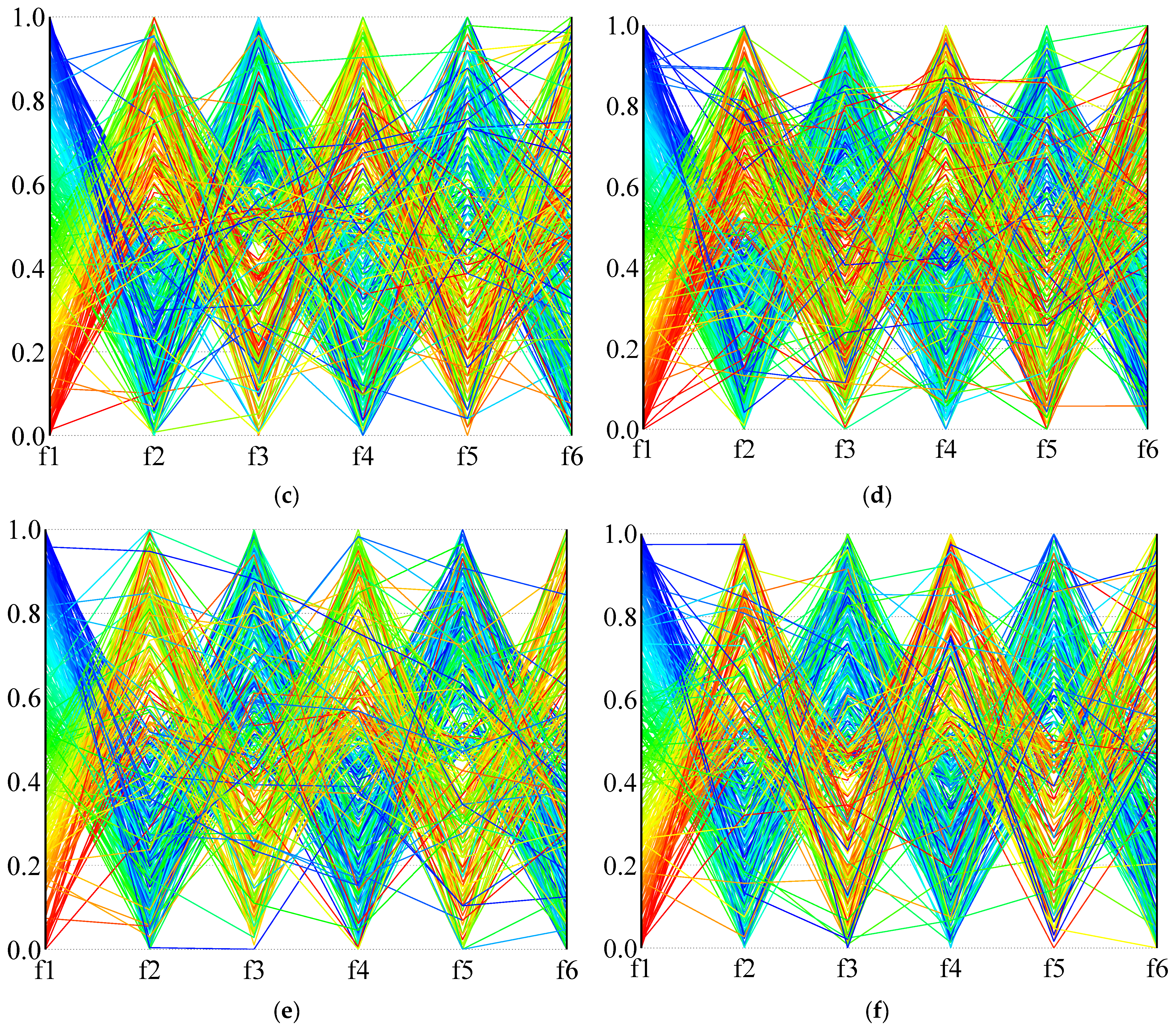
In order to more intuitively describe the distribution of the solution in the high-dimensional objective space,
Figure 14 and
Figure 15 use parallel coordinates to plot the non-dominated solutions generated by the different algorithms used in the two calculation examples (1A and 24B). For each algorithm and instance, we collected the non-dominated solutions (30 × 100 = 3000 solutions in total) generated by thirty independent runs and removed the dominated solutions. As the value of each objective function is not in the same dimension, the value of each dimension of the solution space is normalized, and the value in the figure is the normalized result.
Figure 14 is the result of calculation example 1A, and
Figure 15 is the result of calculation example 24B. It can be seen from the results that NSGA-III-L and NSGA-III-NL show the most vital convergence, especially in the face of complex situations (instance 24B), and result in better non-dominated solution sets. Although NSGA-II is not as convergent as NSGA-III when dealing with many-objective problems, it can provide a clear compromise solution. When RWGA deals with multi-objective problems, finding a convergent compromise solution is difficult. The results in
Figure 14 and
Figure 15 are consistent with the results in
Table 9,
Table 10 and
Table 11. When dealing with many-objective problems, the NSGA-III and NSGA-II methods can cover the objective space more completely and consistently than RWGA, and provide clearer compromise solutions for decision-makers to choose from.
In summary, considering the different evaluation indexes of the algorithm’s distribution, convergence, and versatility, it is impossible to find an algorithm that performs perfectly under every index. Although the comprehensive performance of NSGA-III is more outstanding in multiple calculation examples, it is not the only perfect algorithm. The results show that our proposed variant based on NSGA-III can provide decision-makers with excellent and satisfying diverse non-dominated solutions, especially when dealing with high-dimensional multi-objective container stowage planning problems. This algorithm can achieve a better compromise between convergence and diversity. In practice, therefore, we recommend using NSGA-III-L.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}