1. Introduction
Autonomous underwater vehicles (AUVs) are untethered underwater vehicles that follow a pre-defined route or use a real-time adaptive mission control system [
1]. AUVs can also be defined as robotic systems equipped with a propulsion system and an on-board computer for decision making [
2]. AUVs can be utilised for various different tasks, including bathymetry surveys [
3], harbour inspections [
4], data mulling [
5], water quality analysis [
6], tracking of upwelling fronts [
7], or chemical plume tracing [
8,
9]. Detailed reviews on recent developments in the different AUV-related fields are given in [
2,
10,
11].
AUVs are suitable for accelerating the speed of surveys and allow the gathering of coherent data using side scan sonars, for example [
3]. Surveys carried out by human divers are often too dangerous, due to the imminent risk of shark or crocodile attacks [
12]. Schlüter et al. [
13] utilised an AUV during a survey on submarine groundwater discharge (SGD) sites in the Baltic sea. To create high-resolution benthic maps, the AUV utilised a side scan sonar. It was also equipped with a combined sensor to measure the conductivity, temperature, and the depth (CTD). However, the AUV was not able to detect freshwater from the SGD using the CTD [
13].
During their missions, AUVs usually follow a pre-defined path, such as a series of different transects defined by waypoints [
3,
12], or an adaptive sampling strategy [
10,
14], to achieve a given goal. Behaviour-based planning (BBP) is one instance of an adaptive sampling strategy. BBP is a bottom-up approach, tailoring intelligent behaviour utilising simple features [
8]. In BBP, the term behaviour describes an algorithm, which maps sensor inputs to a pattern of motor actions. Usually, different behaviours are implemented, requiring a coordinating mechanism to choose the right behaviour [
8]. BBP is regularly used for chemical plume tracking [
8,
15,
16,
17,
18,
19,
20]. Formation control methods, such as leader-follower approaches, are often used to control the behaviour of individual AUVs when a group of AUVs is utilised [
21].
Another possible solution is the application of population-based optimisation algorithms such as particle swarm optimisation (PSO) [
22] or ant colony optimisation (ACO) [
23] to guide a group of AUVs during a search mission [
24]. In recent research, PSO was proposed as a potential search algorithm for odour source localisation [
25,
26]. Different algorithms can be implemented on the AUVs and used as different behaviours in a BBP. However, in this case, a coordinating mechanism, deciding on the right search strategy, is required. Fuzzy logic [
27] can be used to decide on the right search algorithm.
Regularly, the approach suggested by Mamdani [
28] is used to build fuzzy logic systems. In his approach, the rule base, provided by an expert, is given as a set of if-then statements [
29]. The utilisation of fuzzy logic requires the definition of a number of membership functions (MFs) for all inputs and outputs, and a set of rules operating on the defined MFs of the input variables, calculating the output value. In the past, fuzzy logic was applied to a vast number of problems in a variety of different fields. This includes: control-theory [
28], crack detection in beams [
30], fire detection in engines and batteries [
31], pavement section classification [
32], characterisation of large changes in wind power [
33] path planning and obstacle avoidance of mobile unmanned robots [
34,
35], and analysing the effect of traffic noise on the human work efficiency [
29]. Recently, fuzzy logic has been used to detect SGD plumes from multi-sensor data [
36].
The term SGD covers any flow of water out across the seabed to the coastal ocean on continental margins, regardless of the composition and the driving force [
37,
38]. In general, groundwater can discharge either via submarine springs or via disseminated seepages [
37]. SGDs are recognised as important pathways for nutrients and pollutions to the marine environment [
39,
40]. Therefore, marine scientists are interested in the localisation and investigation of SGD sites.
Different methods, such as seepage meters [
41,
42,
43], tracer studies [
37], remote sensing [
44], or seismic surveys [
45,
46,
47], were utilised for SGD investigation in the past. The majority of these methods focused either on the aquifer or on the mixing of the discharged water on larger scales.
In a recent study [
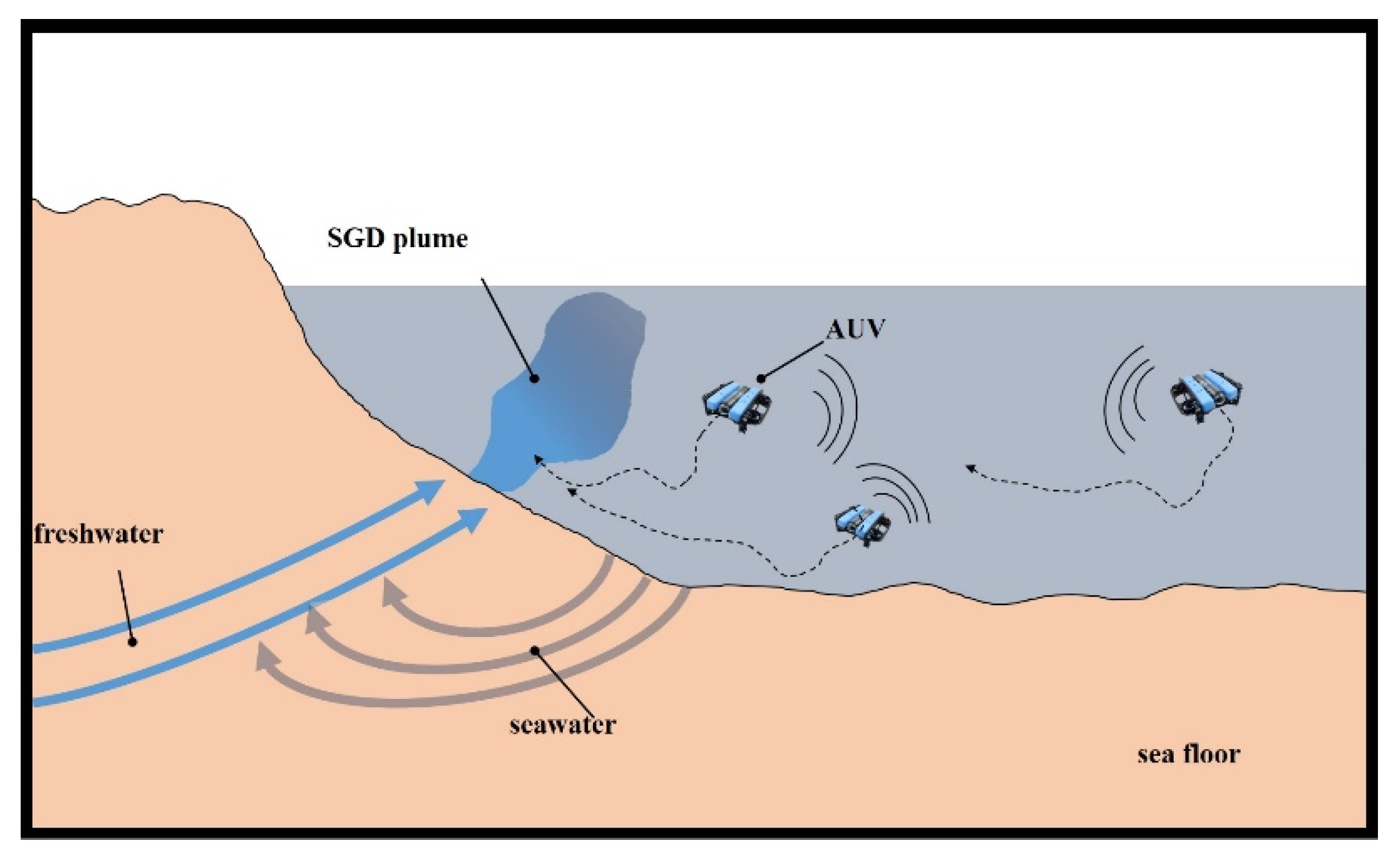
36], small underwater vehicles, guided by a human pilot, are utilised for the investigation of SGD sites. However, if a human pilot guides the vehicle, these investigations are labour-intensive. Hence, AUVs could be a potential tool for SGD investigations. Due to the sizes of the areas under investigation, utilising a small swarm of AUVs would potentially be more suitable than the application of a single AUV. Furthermore, the AUVs must be guided by a search strategy. As mentioned above, coverage path planning algorithms are usually utilised for these kinds of missions. However, artificial intelligence optimisation algorithms can be used to improve the search performance of a swarm of AUVs. In this paper, different search strategies for SGD detection are proposed and their performances are evaluated. It is assumed that population-based optimisation algorithms can improve the performance of a swarm of AUVs. These algorithms can be used to generate new waypoints based on the information gathered from the environment. In this study, the AUVs are independent agents, each following its own search pattern. However, the AUVs are able to communicate with the other entities in the swarm to exchange search information. Based on the search strategy, this information is utilised during the search. A sketch summarising the concept of a small swarm searching for a SGD plume is shown in
Figure 1.
It was shown in this comprehensive study that the proposed algorithms offer the potential to enable automated explorations of SGD sites utilising AUVs. The remainder of this paper is structured as follows. In
Section 2, the dynamic simulation environment used as a testbed for the search is presented. The different search strategies investigated in this research are introduced in
Section 3. In
Section 4, the different simulations carried out are described. The results of the experiments are presented in
Section 5. A discussion of the findings can be found in
Section 6.
Section 7 draws this paper to a conclusion.
2. Environmental Simulation as Testbed for Search Algorithms
For the evaluation of the capabilities of search algorithms, an environmental simulation is required as fitness function. In recent research, different kinds of fitness functions, such as cellular automata [
24], static conductivity distributions [
48] or static plateau functions [
49], were used for evaluating the performance of different search strategies. However, all of these fitness functions lack similarity to the real world. Hence, in this study, a novel environmental simulation, based on real-world measurement data, was developed. The simulation is based on the findings of an environmental study, which took place in the Northern Harbour of the Woodman Point area near Perth (Western Australia). The area is connected to the Cuckburn Sound, a sheltered area between Garden Island and the Australian Mainland (
Figure 2a). The water depth in the Northern Harbour varies between two and ten metres. Starting from the north end of the harbour, the water depth remains relatively constant between two and four metres. However, at a distance between 80 m and 100 m from the shore, the water depth increases from a couple of metres to ten metres. Due to the change in the hydraulic conditions, this sharp brim is expected to facilitate the development of focused SGD spots. A bathymetry map of the harbour is presented in
Figure 2b.
The harbour was surveyed using an echo sounder-equipped skiff as well as a sensor equipped remotely operated vehicle (ROV). During the sonar survey, the area under investigation was covered by 13 transects (
Figure 2c). The data collection was focused on the area of the brim. During these transects, georeferenced acoustic backscatter data were recorded using an Humminbird 898 SI echo-sounder [
50]. The ROV was operated from three different positions to survey the whole harbour area. The positions are marked in
Figure 2d. In addition, the areas in which the ROV surveys took place are marked by polygons.
During the sonar transects, 23 plumes were identified as SGD plumes. Analysing the spatial appearance of these plumes showed that the discharged water did not reach the surface; rather, it remained in water depths between approximately 1.5 and 3.0 m (
Figure 3). Previous research conducted in the same harbour concludes that the discharged water was brackish, containing a huge portion of recirculating seawater [
46]. Therefore, the density difference between discharged water and seawater might be small. In addition, the temperature depth profile indicated a surface layer of warmer water starting from the sea surface to a water depth of 3 to 5 m [
36]. This higher temperature causes a lower density of the surface layer. This lower-density surface layer prevents the plumes from reaching the surface.
Furthermore,
Figure 4 shows that the detected plumes form a connected patch. The size of the patch was approximately 75 m × 40 m. It can be observed from
Figure 4 that Echograms from sonar transects passing near the patch did not show any evidence of a plume. Moreover, most plumes seem to be on the area of the brim, developing in the deeper part of the harbour.
If the plume is located at a specific depth, or at a constant distance from the seafloor, this information can be utilised during the search. The AUV, for instance, can be operated at a specific depth, using a pressure sensor, or at a specific altitude, using an echo sounder. Therefore, the search problem can be viewed as a two-dimensional search problem. Hence, a dynamical two-dimensional search space, covering the whole harbour area, was used in this study. Reducing the number of dimensions to simplify the search task of AUVs is a commonly used approach, both for simulations [
52,
53] and search missions in the real world [
8].
The distribution of the discharged water was modelled using a simplified time-based simulation. The implemented simulation needs to run several thousands of times during the different experiments. Therefore, due to computational limitations, neither a hydrodynamic model nor other computational fluid models were used in this study. The simulation was designed to build a dynamic search environment for testing different kinds of search strategies for AUVs. The shape of the search area was chosen as a polygon for a simplified representation of the real harbour. The size of the search space was 330 m × 200 m. In addition, an area of 79 m × 36 m was defined as the SGD area; e.g., in this area, SGDs could occur. The position of the left corner of the SGD area was (81 m, 57 m).
Figure 5 shows the shape and size of the designated search space, including the SGD area and the starting point of the AUVs.
Recent research revealed a dependency of SGD flowrates on the tidal cycle [
46,
54,
55]. Therefore, the simulation developed was extended by the time-dependent inflow rate of the SGDs. Furthermore, due to tide-introduced currents, the direction of the plumes is influenced by the tide; i.e., during rising tide, the plumes are directed north-westwards, while, during low-tide, the plumes are directed south-eastwards.
The simulation contains an adjustable number of SGD spots. Once the simulation is set up, the positions of the SGDs are chosen randomly within the designated SGD area. Later, the flowrate parameter
of each SGD is chosen randomly from the interval:
The water discharged in the area under investigation is brackish, containing a variable portion of fresh groundwater and recirculating seawater [
46]. The percentage of fresh groundwater can vary depending on different factors, such as precipitation, season or other effects [
56,
57]. The composition of the discharged water can also vary over time. Hence, in the simulation, the weight percentage of fresh groundwater
is chosen randomly for each SGD from the interval:
Next, the parameter values of the discharged water for each SGD are calculated as follows:
where
represents the parameter value of the discharged water,
denotes the parameter value of the fresh groundwater, and
represents the parameter value of the recirculating seawater. Equation (3) can be used to calculate discharge values for different parameters. However, in this study, dissolved oxygen (DO) is utilised as tracer for SGDs. DO is usually depleted in groundwater [
58,
59]. Hence, in this simulation, the DO value of fresh groundwater is set to
. However, enriched DO values in pore water samples, potentially caused by seawater intrusion, are reported in recent research [
60]. Therefore, the DO value of recirculating seawater is set to
. This value is equal the mean DO level measured during the ROV surveys [
36]. The aforementioned calculations are executed during the initialisation of the environment.
Figure 6 shows the pseudocode of the constructor of the environment class.
After initialisation, the environmental simulation offers a measurement interface, which allows the AUVs to sense the environment. The interface accepts a position, given as
x and
y coordinates, as input parameter. The current DO value for the given position is than calculated and returned by the environment class. The Euclidean distances
di and the angle
between the positons of the SGDs and the given position are calculated. Next, the flow direction of the plumes
is calculated as follows:
where
denotes the flow direction of the plumes and
denotes a Gaussian distributed random number with mean of zero and standard deviation of one. The standard values are chosen based on the position of the harbour entry (
Figure 2a). In the next step, calculated angles
are compared with the calculated flow direction
. The angles outside the flow area of the plume are set to 90°. The flow area is calculated based on the flow direction
and the flow angle
. The flow angle
changes over time, based on the tidal cycle. In addition, if the calculated distance
di is zero, the corresponding angle
is set to a value of zero. Furthermore, the inflow rate of the SGDs depends on the tidal cycle. Hence, a time factor
is calculated and used for the regulation of the inflow over time as follows:
where
T denotes the period of the tide,
t represents the current time of the simulation, and
denotes a turn of tide parameter. This parameter changes over time, adjusting the width of the plume around the turn of tide. The parameter
allows the dynamic change of the inflow over time, simulating the tide dependency.
Figure 7 depicts the development of the parameter
over time. It shows that the turn of tide parameter
only exerts an influence on the parameter
during the turn of the tide.
Based on the noise flag (
Figure 6), the base DO value
V0 is chosen to be:
where
denotes the mean DO value measured during the ROV survey,
denotes a Gaussian distributed random number with a mean of zero and a standard deviation of one, and
represents the standard error of the mean, based on the DO values measured during the ROV survey [
36]. Consequently, the DO value
V for the given position is calculated as follows:
The sensing procedure, described above, is summarised in the pseudocode, presented in
Figure 8.
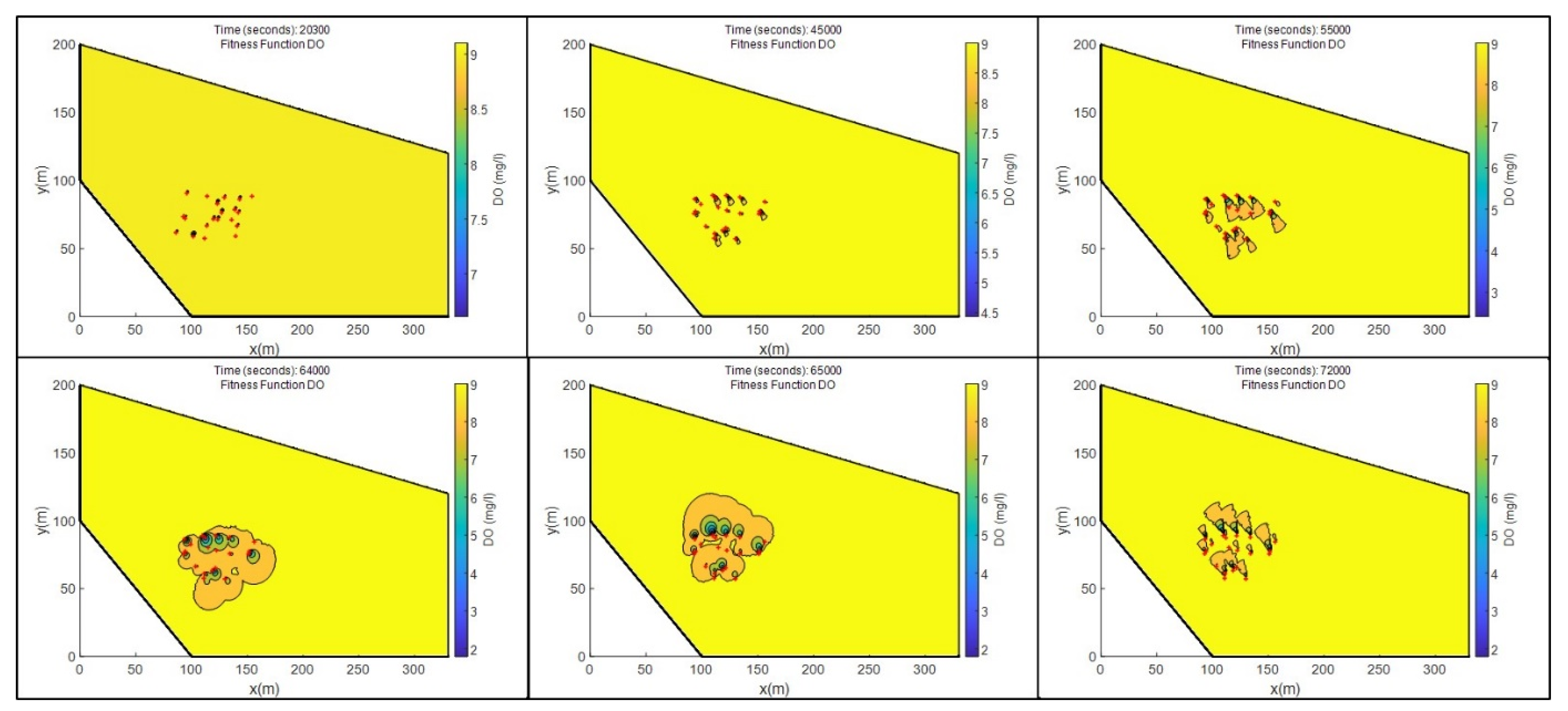
Figure 9 shows the development of the plumes over different time steps. It can be observed that the size of the different plumes varied over time. During the turn of the tide, the flow direction of the plumes changed. Furthermore, it can be observed that the plumes from the different SGDs differed in size and intensity, due to different values of the parameters
and
. In addition, a video of the simulation environment, covering a complete tidal cycle, can be found in
Supplementary Material Video S1.
2.1. Sensor Error Model
During the survey, the AUV was equipped with a low-cost sensor for measuring DO values [
36]. The measurement accuracy of the sensor, as given by the manufacturer, is
, while the measurement range of the sensor is 0.01 mg/L to 100 mg/L [
61]. The sensor operates at a measurement frequency of 1 Hz. In the simulation, the sensor reading
Vs is modelled as follows:
where
denotes the current concentration calculated following Equation (7),
generates a random number from the normal distribution with a mean of zero and a standard deviation of 1, and
denotes the measurement accuracy of the sensor.
2.2. Localisation Error Model
The use of AUVs requires a method for the robust, reliable, and accurate determination of an AUV’s position. Autonomous vehicles usually rely on the availability of global navigation satellite systems (GNSS) in order to estimate their global position. However, the electromagnetic signals of such satellite systems cannot be received by submerged AUVs [
62]. Different possible methods for the localisation of submerged AUVs have been proposed. These methods can be classified into inertial or dead reckoning methods, acoustic methods, and geophysical methods [
63]. All localisation methods are subject to error, whereby the respective magnitude of the error depends on both the method itself as well as other factors, for instance environmental factors. Therefore, it is not an easy task to estimate the magnitude of the localisation error. However, different strengths of localisation error can influence the performance of different search strategies [
64,
65]. Hence, two simplified localisation error models were used in this study, to study the impact of localisation errors on the performance of the search. The first model used a normal distributed error added to the current true position of the AUV as follows:
where
and
represent the estimated position,
and
denote the true position of the AUV,
is a random number generated from the standard normal distribution with a mean of 0 and a standard deviation of 1, and
represents the standard deviation of the localisation. Higher values of
increase the uncertainty of the localisation model. By only changing a single parameter, this model can be used to represent different localisation accuracies. Hence, the model is suitable for studying the impact of localisation errors on different search strategies.
However, with acoustic-based localisation methods, the localisation error is affected by the distance between the receivers and transmitters of the localisation system [
66,
67]. The influence of this distance is taken into account in the second model. Here the estimated position can be calculated as follows:
where
and
represent the estimated position,
and
denote the true position of the AUV,
is a random number drawn from the standard normal distribution,
represented the minimum standard deviation,
represents the distance based standard deviation of the localisation model, and
denotes the Euclidean distance between the AUV and the centre-point of the localisation system. This position was chosen to be at location (250, 130) m. This model was used in all the simulations, unless otherwise noted.
2.3. Communication Error Model
Underwater communication suffers from various detrimental physical effects, such as propagation loss, absorption loss, multi-path propagation, and temperature and pressure-dependent sound velocity [
68]. In a real underwater environment, the reliability of a communication link is also influenced by the currently three-dimensional orientation of each communication system (i.e., transmitting and receiving AUV) as the acoustic transducers exhibit a directional response pattern. Commercial acoustic modems apply spread spectrum techniques and OFDM (orthogonal frequency division multiplex) modulation schemes in order to cope with the frequency-selective impairments of multi-path propagation. These methods make it possible to maintain a reliable communication link. On the other hand, they potentially lead to a reduced data rate (automatic rate adaption).
An adapted version of the transmission loss function of underwater acoustic systems [
69] is used in this study. Here, the considered impairments are restricted to the propagation loss
LP:
where
denotes the damping coefficient,
denotes the Euclidean distance between two AUVs, and
represents the reference distance for normalising the path loss. Based on this loss, a probability
pcom for successful communication between two AUVs can be derived as follows:
It can be seen from Equation (11) that the probability of a successful communication only depends on the damping coefficient
and the normalising distance parameter
. Therefore, this model is suitable to study the impact of communication restrictions on the performance of different search strategies. The proposed model was used in previous research [
65].
Figure 10 shows the probability of a successful communication as function of the distance between two AUVs for a variation of
and for different values of
. It can be observed that the influence of the damping coefficient
is more dominant than the influence of different values of the normalisation factor
.
During the simulations, the AUVs are able to broadcast messages to the other members of the swarm. After an AUV sends a message, the environment computes whether the message will be received by another AUV or not. If the communication is successful, the message reaches the AUV in the next iteration. Otherwise the message is dropped. Due to bandwidth limitations, the sender does not receive any feedback about the success of the communication. The pseudocode of the communication method, implemented within the environment, is shown in
Figure 11. This function is called by an AUV during the search if it tries to send a message to its peers.
3. Search Strategies Used for SGD Detection
A swarm of AUVs must be guided by a search strategy [
70], which should be able to achieve the intended search goal within the limitations of the AUVs. For instance, the search strategy could exploit information gained from the environment to amend the planned search path of an AUV. However, the search strategies developed only generate waypoints for the AUV to visit. They are not responsible for other tasks, such as path planning, obstacle avoidance, or motion control.
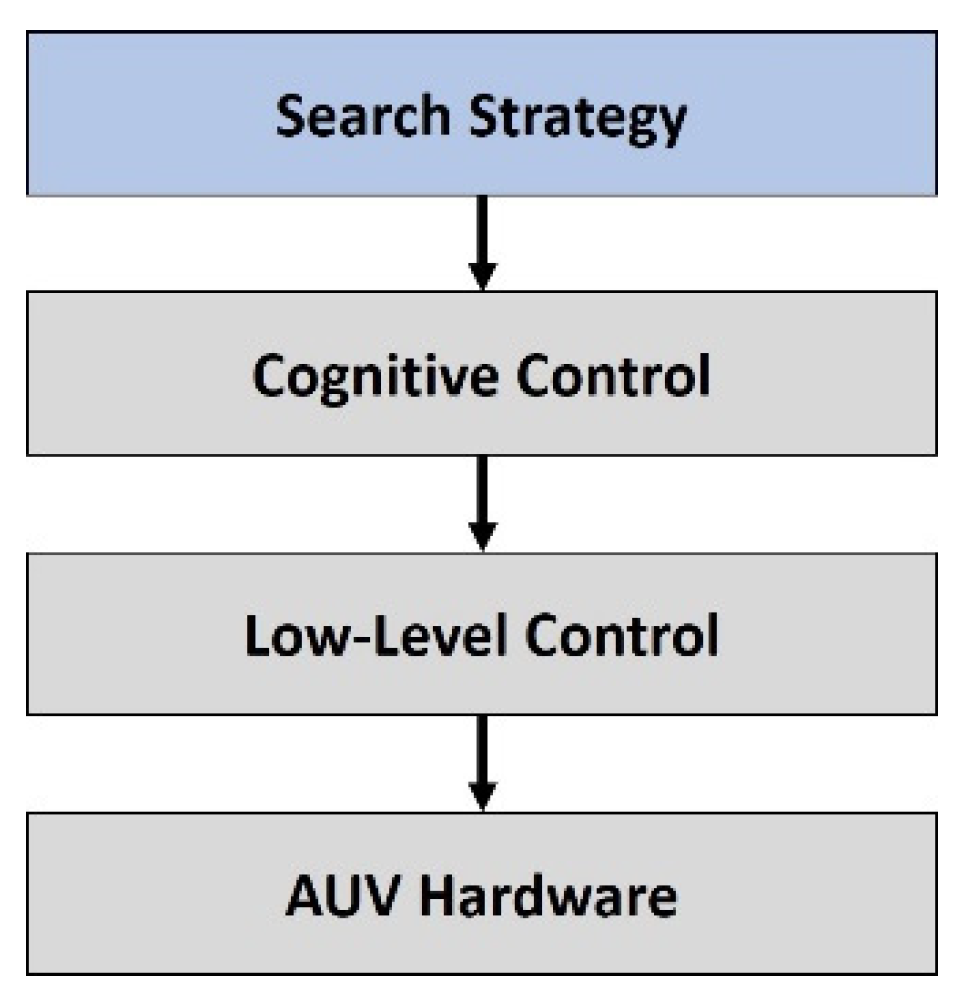
Figure 12 shows the different layers involved during an AUV search task. The lowest layer contains the AUV hardware, including, for example, hardware for propulsion, energy management or sensors. The next layer is the low-level control layer. This layer contains different controllers, for example, for depth or speed control. Different kinds of controllers, such as PID controllers or Fuzzy controllers, have been used [
2]. The inputs for the different low-level controllers are generated within the cognitive control layer. In addition, this layer is in charge of obstacle avoidance and optimal path planning of the AUV. The highest layer contains the search strategy, responsible for waypoint generation based on search strategies used and environmental information gained. This study contributes to this last layer; therefore, it is assumed that a swarm of AUVs, equipped with suitable systems for communication, self-localisation and environmental sensors, is available.
In this study, all the strategies are implemented to calculate new waypoints for the AUVs. During the simulations, in each iteration, the generated waypoints were used to calculate the desired course and speed of the AUV. These calculations are based on the estimated position of the AUV and the position of the current waypoint. Once an AUV reaches the current waypoint, the search strategies generate the next waypoint and returns it to the cognitive control layer of the AUV. In each iteration, an AUV first estimates its own position. Afterwards, it senses the environment and updates its own knowledge base, i.e., the best position found so far by the AUV (pbest) and the best position found so far by the entire swarm (gbest).
Next, the AUV processes incoming messages from the other AUVs. If the current waypoint is reached, a new position is calculated based on the search strategy used. Next, the new desired heading and speed of the AUV is calculated and the AUV moves. This behaviour continues until the maximum travel distance of all the AUVs is exceeded. During the simulations, all the AUVs in the swarm were operated simultaneously. The behaviour, described above, is summarised as pseudocode in
Figure 13.
Different search strategies have been proposed for locating points of interest utilising AUVs. In this study, six of these search strategies are studied.
3.1. Pre-Defined Path Planning
In this strategy, a pre-defined set of waypoints is assigned to each AUV. The AUVs then follow the paths defined by these waypoints. The waypoints are placed equally spaced on two opposite borders of the search space. The distance between two waypoints is chosen based on the size of the area under investigation and the estimated maximum travel distance of the AUV. Pre-defined path planning (PPP) algorithms were used in recent research as baseline strategy to assess the performance of search strategies developed [
48].
When utilising the proposed algorithm on multiple AUVs, some parts of the search area are covered several times. In order to avoid multiple coverage of areas, the search area could be split into different sub-areas, where each AUV is assigned a unique area. Such a procedure has been proposed as an optimal search strategy for full coverage path planning for autonomous vehicles in the case of guaranteed unrestricted communication between the vehicles [
71]. However, in this case, if one AUV fails, a certain part of the search area might be unexplored. The risk of operation failure is more likely when using AUVs; therefore, a new search strategy is proposed and used instead.
Figure 14 shows the paths of the three AUVs utilising the proposed PPP. It can be observed that all AUVs explore the search area with equal spaced transects. However, the AUVs do not further exploit promising regions of the search space.
3.2. Adapted Random Walk
In classical random walk, a new position is chosen randomly from the neighbourhood of the current solution, i.e., the step size is random. However, when using an AUV, different step sizes lead to acceleration and deceleration. This consumes energy and reduces the operating time. Ideally, the velocity of an AUV is kept constant and only the heading changes. Therefore, in this study, an adopted random walk algorithm was used. In addition, the velocity of an AUV is limited, hence the maximum step size of the particles was limited as well.
In the adopted random walk, the AUVs drive with their maximum speed during the whole search and in each iteration, the heading of the AUVs is chosen randomly. With a given heading, the velocity in each direction is calculated as follows:
where
vx and
vy denote the speed of the AUV in
x and
y direction, respectively,
vmax denotes the maximum speed of the AUV, and
θ denotes the randomly chosen heading of the AUV. The heading
θ is chosen from the range [0…360]°. The next waypoint is then calculated as follows:
where
denotes the new position of the AUV,
denotes the estimated current position of the AUV,
denotes the new velocity of the AUV, and
denotes the time step between two iterations. This adapted random walk has already been used as a search algorithm for AUVs in previous research [
24].
3.3. Particle Swarm Optimisation
Particle swarm optimisation (PSO) is modelled on the behaviour of collaborative real-world entities (particles), such as fish schools or bird flocks, which works together to achieve a common goal [
22,
72]. Each individual of the swarm searches for itself. However, the search progress of a swarm member also exerts an influence on the search behaviour of the other individuals in the swarm. This influence is referred to as the social aspect.
At the beginning of a search, each particle in the swarm starts at a random position and with a randomly chosen velocity for each direction of the
n-dimensional search space. After initialisation, all the particles move through the search space with an adjustable velocity. The velocity of a particle is based on its current fitness value, the best solution found so far by the particle (cognitive knowledge) and the best solution found so far by the whole swarm (social knowledge). The new velocity is calculated as follows:
where
and
are the new and the previous velocity vectors of the particle, respectively,
is a control parameter called inertia weight,
and
are scaling factors for cognitive and social behaviour,
and
are vectors of random numbers from the range [0, 1],
represents the best known position of the particle,
denotes the best known position of the swarm, and
represents the current position of the particle. The new position of the particle is calculated as follows:
where
denotes the new position of the particle,
denotes the estimated current position of the particle,
denotes the new velocity of the particle, and
denotes the time step between two iterations. Even if the time step features a value of one second, it is multiplied to the velocity vector in order to obtain consistency in the physical units [
70]. PSO was previously used successfully as a search strategy for a small swarm of AUVs [
24,
65]. PSO is a population-based search heuristic. The movement of the particles is achieved by changing the velocity of the particles in the different dimensions of the search space. AUVs are capable of carrying out the manoeuvres required to mimic the movements of particles in PSO. Thus, PSO was chosen as a search strategy for AUVs.
3.4. Inertia Levy-Flight
Biologists have observed that animals, such as sharks, bony fish, sea turtles, and penguins, often move in patterns that can be approximated by Levy flights [
73] following the Levy flight foraging hypotheses. This hypotheses states that natural selection should have led to adaptations for Levy flight foraging, because Levy flights can optimise search efficiencies [
74]. Since there is experimental evidence for inherent Levy search behaviour in foraging animals [
75], Levy flight has been used as a search strategy for a single AUV [
48,
76].
While using Levy flight, the AUV must choose a random direction as well as a random step length for each iteration. The direction can be chosen from a uniform distribution in the range of 0 to 360 degrees. However, the chosen step length is based on a power law cumulative distribution function:
where
r is a random number from the range [0, 1] and
α is a control parameter from the range of [1, 2]. According to Equation (17), very small values of
r produce very high step size values. However, if the step size of an AUV is too large, the AUV will potentially leave the search space and energy resources are wasted. Hence, the maximum step size should be limited. This limitation was set by changing the range for random number selection to [
R, 1] where
R is calculated as follows:
where
S denotes the maximum step length. When using Levy-flight as a search algorithm, the value of
α must be chosen off-line before the search. The value of
α has a direct impact on the step length
s in each iteration. Therefore, the search behaviour of the AUV depends heavily on the chosen value of
α. Instead of manually tuning the value of
α, a self-adaptive scheme to tune this parameter
α can be used. The AUV calculates in each step the value of
α, based on the information gained from the environment as follows:
where
gc is the current fitness value,
gw is the worst fitness found so far, and
gb is the best fitness found so far. Furthermore, the AUV stores the fitness value of the previous iteration
gc-1 and compares this value with the fitness value in the actual time step
gc. If there is an improvement, the AUV keeps its direction. Otherwise, it chooses a new direction randomly. The new waypoint is then calculated as follows:
where
denotes the new position of the AUV,
denotes the current estimated of the AUV,
denotes the randomly chosen heading, and
denotes the chosen step length. The heading
θ is chosen from the range [0…360]°.
Figure 15 shows pseudocode of the inertia Levy flight (ILF) algorithm.
3.5. Self-Organising Migrating Algorithm
The self-organising migrating algorithm (SOMA) is a population-based algorithm, which mimics the social behaviour of a group of entities [
77]. While searching, all the entities in one SOMA move towards the leader; i.e., the entity with the best fitness in the population. The new position of the entity is calculated as follows:
where
denotes the new position of the entity,
denotes the estimated current position of the entity,
denotes the estimated current position of the leader,
denotes the size of the jumping step,
denotes a random integer from the interval (0,
imax), and
denotes a perturbation vector. The parameter
imax is a control parameter, which needs to be tuned. The perturbation vector contains as many elements as the search problem features dimensions. Each element of the vector is calculated as follows:
where
denoted the perturbation probability. AUVs are capable of carrying out the manoeuvres required to mimic the movements of agents in SOMA. Therefore, SOMA was chosen as a search strategy for AUVs [
78].
3.6. Bumblebee
The bumblebee (BB) search strategy is inspired by bumblebee flight paths [
79,
80] and was developed by Hwang et al. [
52]. It has been applied for oil plume detection and investigation utilising an AUV [
81]. The search strategy applies a combination of zigzag and double loops within the search space. In the first step, a specific number of waypoints is generated randomly and the shortest path is computed. Upon arrival at a waypoint, the AUV undertakes a bow-tie shaped path with two loops, while the direction of the loops is orthogonal to the prior trajectory of the AUV [
52]. In their research, Hwang et al. [
52] utilised a scanning sonar with a view angle of 45° and a scanning distance of 50 m. Hence, the directions of the loops are important for maximising the area covered by the scanning sonar. However, the sensors used in this study only measure local concentrations. Therefore, the direction of the loops is not important, because the loops only add local search behaviour. Hence, in this study, the direction of the loops is chosen randomly upon arrival. The radius
rLoop and the offset multiplier of the loops
dLoop can exert an influence on the performance of the search. Hence, these parameter values need to be tuned to maximise the search performance.
In addition, Hwang et al. calculated the number of waypoints based on the area under investigation and the predicted size of the plume [
52]. However, in this study, a maximum travel distance for each AUV is defined. Therefore the maximum number of waypoints, consuming the given travel distance, is generated to maximise the search capabilities. All the waypoints are chosen during a planning phase prior the performance of the search. During this planning phase, new waypoints are added iteratively to the paths until the expected path length is longer than the maximum travel distance of the AUV. The waypoint generation can be understood as a travelling salesman problem (TSP) [
82].
Figure 16 presents the pseudocode for the waypoint-planning algorithm.
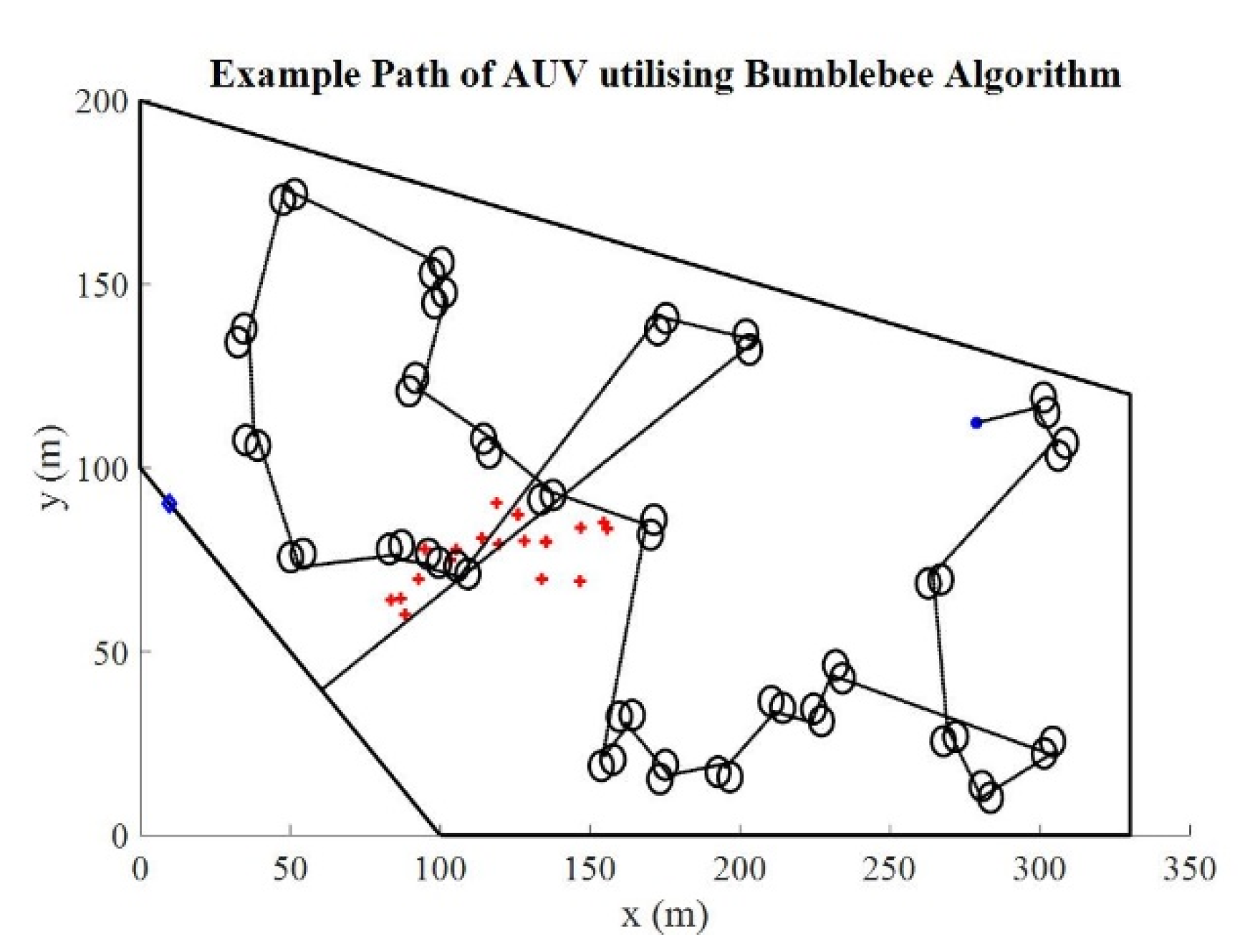
Figure 17 shows an example trajectory of a single AUV utilising the BB algorithm as the search strategy. It can be observed that the generated waypoints are spread over the whole search area, allowing the exploration of the entire area under investigation. However, it can further be seen that the search strategy does not exploit the information gained during the search for an adaption of the search path to exploit promising regions in more detail.
All search strategies, except the pre-defined strategy, require a randomised starting point for each AUV. However, in the real world, the system would be operated from a jetty or from a moored boat. In both cases, all AUVs start from the same fixed position somewhere within the search area. Therefore, in this study, prior the start of the search, a random start position is chosen for each AUV. To save energy, the vehicle travels from the jetty to the selected starting point surfaced. Therefore, only 80 percent of the travelled distance is counted for the travel distance of the AUV. An overview of all search strategies, including the number of tuneable parameters and the chosen start points of the AUVs is presented in
Table 1. 4. Experiments (Simulations)
Different search strategies for a small swarm of AUVs are presented above. To allow a comparison between the search strategies, different computer simulations were executed. In the first step, a parameter study was undertaken to investigate the influence of the control parameters on the different search strategies. Subsequently, the influence of communication errors, localisation errors, and limited travel distance on the performance was investigated. During these experiments, the whole swarm, which consisted of three AUVs, explored the search space using the same search strategy. In another set of experiments, each AUV was allowed to select a different search strategy and the performance of this static combination of search strategies was evaluated. In the last set of experiments, the performance of a dynamic search strategy selection approach utilising a Fuzzy Logic system was examined.
For each experiment, a start time was chosen randomly between three hours before and three hours after low tide. As mentioned above, the maximum SGD inflow was expected to be during low tide. However, other constrains, such as survey during daytime or permissions from the authorities might require the surveys to take place at other times around low tide. The starting time window is depicted in
Figure 7.
A measure for success of a search strategy is needed for the best strategy selection. This measure should reflect which search strategy best fulfils the intended aims of the search. In this study, the environment contained
n SGDs with different flowrates. In the best case, the search strategy would be able to guide the swarm of AUVs to visit all the SGDs within the given maximum travel path lengths. Hence, the minimum distance between all members of the AUV swarm and all the SGDs is used for fitness evaluation. In addition, the flowrate of the different SGDs should be taken into account. This means it is more important to investigate SGDs with higher inflow, rather than visiting SGDs with lower inflow. Therefore, the performance of a search run is calculated as follows:
where
represents the performance of the search run,
denotes the number of SGDs in the environment,
represents the flowrate coefficient according to Equation (1), and
denotes the distances between all the AUVs and the SGD
i for all time steps {1…
t}. However, applying single objective optimisation algorithms requires a scalar fitness value. Therefore, the performance over all search runs needs to be further condensed. For instance, the average performance over all runs could be used to assess the performance of a particular search strategy. In addition, a search strategy that performs better in some search runs should be rewarded. Thus, the following fitness measure was used in this research:
where
denotes the fitness value used for performance measure and optimisation,
denotes the error values of all runs calculated according to Equation (23), and
represents the mean value of
.
4.1. Influence of Control Parameter Variation
Some of the proposed search strategies are based on stochastic optimisation algorithms. These algorithms usually feature a certain number of control parameters (
Table 1). Recent research revealed the performance dependency of such optimisations algorithms on the right choice of control parameter values [
24]. However, the right values of the control parameters usually depend on the optimisation problem at hand. Hence, in the first set of experiments, the influence of control parameters on the search performance of the different search strategies was investigated. For all the simulations, the distance-based localisation model (Equation (10)) with a basic standard deviation
and a distance-based standard deviation of
was used. The values are based on the accuracy of the short baseline localisation system (SBL) used during the ROV surveys [
83]. Within the simulations, the communication between the AUVs was error-affected, using the model described above. The damping coefficient was set to
, while the normalising distance parameter was set to
. The maximum travel distance of the AUVs was set to 2700 m. These settings are based on the actual AUV platform used.
The PSO algorithm includes three different control parameters [
84], the cognitive learning factor
c1, the social learning factor
c2, and the inertia factor
. However, in this implementation, the time constant
is added as additional control parameter [
70]. Within these experiments, all possible permutations of the four control parameters were evaluated using the following values:
ILF was developed to decrease the number of control parameters [
76]. For this algorithm, only one control parameter, i.e., the maximum step length
S needs to be tuned. For the experiments, the maximum travel distance was varied as follows:
The SOMA algorithm includes three control parameters [
77], the size of the jumping step
, the perturbation probability
, and the maximal random integer
. During the parameter study, these parameters were varied as follows:
The BB includes two control parameters [
52], the radius of the loops
and the distance between the loops
. This distance
was implemented as a multiplier of the radius of the loops
. Within the parameter study, both parameters were varied as follows:
The results of the experiments are presented in the results section of this paper. The optimal control parameter settings, found during the parameter study, were used for the subsequent experiments.
4.2. Influence of Localisation and Communication Error
Previous published research indicates an influence of localisation and communication errors on the performance of different search algorithms [
65]. Therefore, the influence of both errors on the performance of the search strategies was investigated in this study. Both errors were studied independently, utilising the aforementioned error models. The distance independent localisation error model was used. All the algorithms were tested with different parameter values for the standard deviation of the localisation and the damping coefficient. For each value, 10 different environment settings with randomly selected numbers and positions of SGDs were tested. For each setting, 10 search runs were carried out. For each run, the start time and the start positions of the AUVs were selected randomly as described above. The performance of each run (Equation (23)) was stored for analysis. The described procedure is summarised in the pseudocode presented in
Figure 18.
4.3. Influence of Maximal Travel Distance
The maximum distance an AUV can travel depends on the energy stored on the vehicle, the energy consumption for propulsion, and environmental effects, such as currents. It was shown in recent research that the maximum distance an AUV can travel has an influence on the success of a search [
85]. Hence, the influence of travel distance limitations on the proposed search strategies was examined. In the experiments, communication and self-localisation errors were modelled using the same parameters as for the control parameter study. For the experiments, the maximum travel distance
lmax for each AUV was varied between:
For each
lmax, 100 runs were carried out, following the procedure described in
Figure 18.
4.4. Combined Search Strategy
In general, in most search strategies, exploration and exploitation capabilities need to be balanced to achieve good results [
86,
87]. However, the balancing of exploration and exploitation of a single algorithm can be a challenge [
88]. Hence, a combination of different search strategies potentially accelerates the overall performance of a swarm. In a previous study, different algorithms were combined within a hyper heuristic to guide the AUVs’ search [
78]. In this study, the algorithms are used independently. However, potentially utilising different search strategies on each AUV can accelerate the search performance. During the search, all the AUVs shared their best-known position regardless of the chosen strategy. For comparison, all possible combinations of different search algorithms were tested. To evaluate the performance, 100 runs were conducted for each combination, following the procedure described in
Figure 18. During the experiments, communication and self-localisation error was modelled using the same parameters as for the control parameter study. The experiments were repeated three times.
4.5. Dynamic Search Strategy Selection
Another possible approach could be to select a suitable search strategy dynamically, based on the current status of the search. This dynamic selection can be viewed as BBP [
8]. However, switching between different search strategies usually requires the definition of thresholds to control the switching processes [
89]. The correct determination of thresholds can influence the search behaviour of the system.
In this study, a fuzzy logic approach [
27] was utilised for dynamic search strategy selection. MFs and rules were implemented as Mamdani fuzzy inference system [
90] utilising the “Fuzzy Logic Designer” from MATLAB’s Fuzzy Logic Toolbox [
91]. This toolbox was used to develop fuzzy logic systems in recent research [
29,
34]. Obtaining estimations from the fuzzy logic inference system (FIS) requires defuzzification [
92]. Here, the centroid defuzzification scheme was used.
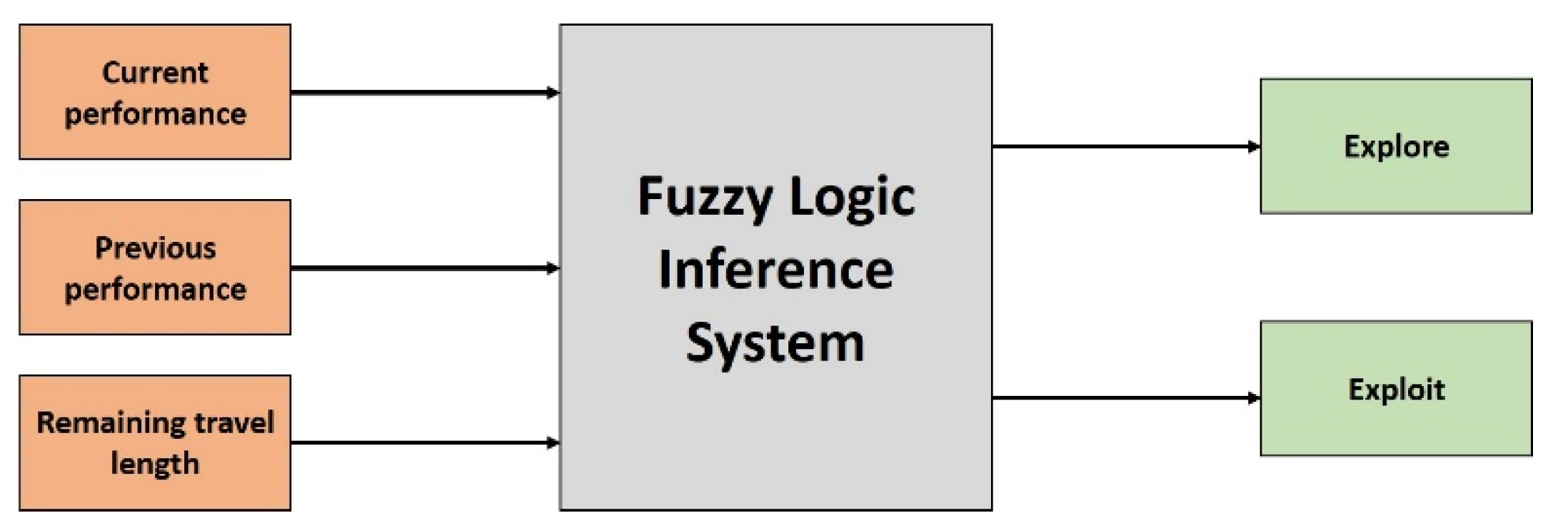
The dynamic selection is based on the current and the previous progress of the search. In addition, the remaining energy, available for travelling, is taken into account. Therefore, three inputs, current performance, previous performance, and remaining travel distance, were defined. The current performance indicator is calculated as follows:
where
denotes the performance indicator for the current time step,
pi denotes the current fitness,
gw represents the worst fitness found so far by the entire swarm, and
gb is the best fitness found so far by the entire swarm. For the previous performance indicator, the AUV stores the fitness every time it reaches a waypoint. The previous performance indicator is then calculated as follows:
where
denotes the performance indicator for the previous waypoint. The remaining travel distance indicator is calculated as follows:
where
represents the travel distance indicator,
denotes the currently remaining travel distance, and
represents the maximal travel distance of the AUV. These indicators are calculated every time an AUV reaches a waypoint. Subsequently, these values are fed into the FIS. The FIS than calculates the values for the two outputs, i.e., explore and exploit (
Figure 19). The calculation of the outputs is based on the defined MFs and the rule base system.
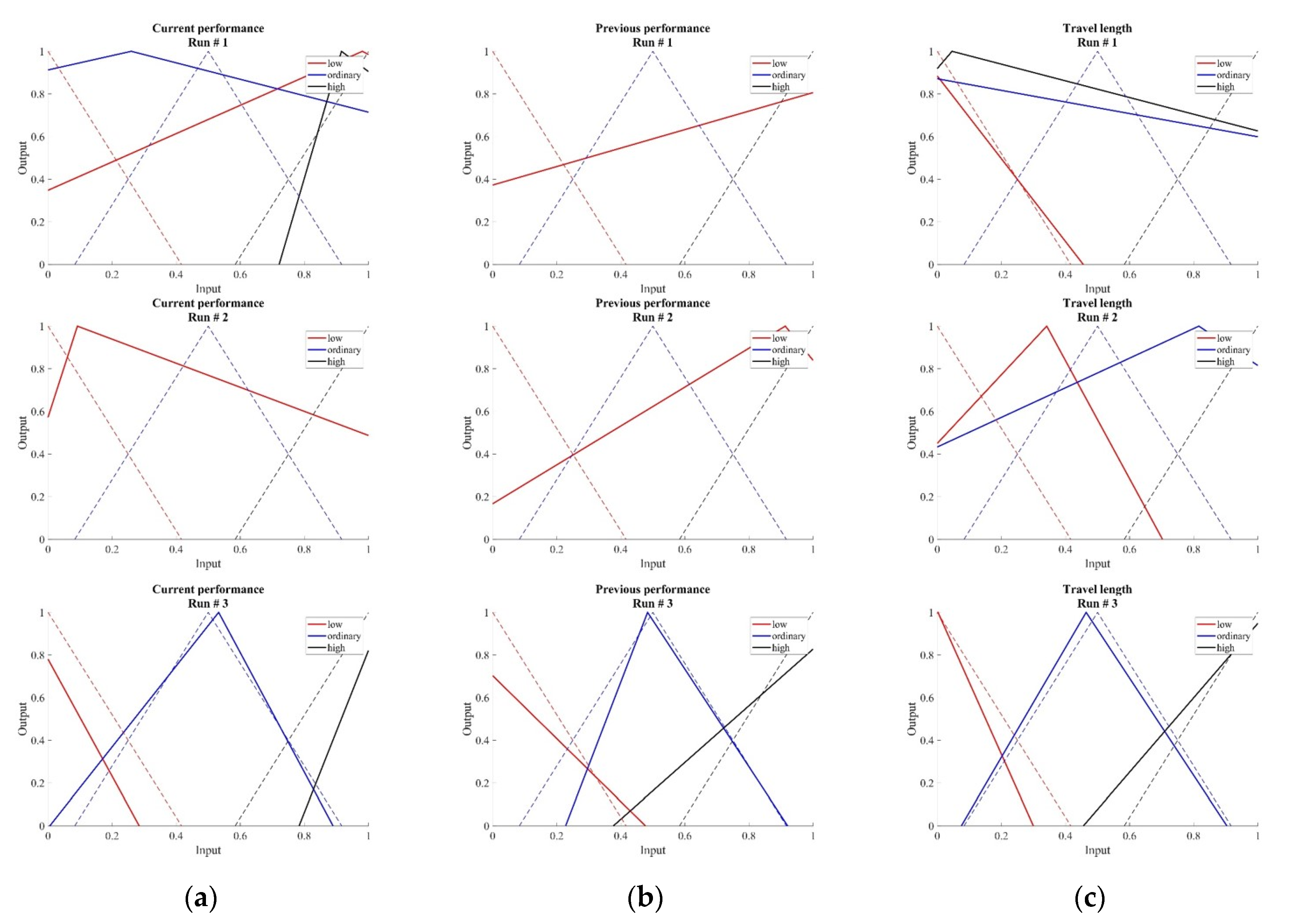
The utilisation of fuzzy logic requires the definition of MFs for any inputs and outputs of the fuzzy system. The MFs are used for the fuzzyfication of the inputs and the defuzzizication of the outputs. The number, shape, and location of the different MFs usually have an important impact on the performance of the FIS. However, the determination of the MFs requires some knowledge about the problem at hand, and, in addition, fine tuning of the parameters to optimise the performance of the FIS. Three MFs, named low, ordinary, and high, were defined for each input and each output. They were defined as triangle MFs. The low MFs start with an output of 1 at an input value of 0 and decreasing to an output value of 0 for the input value of 0.417. The ordinary MFs start with an output of 0 for the input of 0.083, increasing to a maximum output of 1 for the input of 0.5. For higher inputs, the output decreases until the output is 0 again for inputs of 0.917. The high MFs also start with an output value of 0 for an input value of 0.584. The output increases to the maximum value of 1 for the input value of 1. The shapes of the MFs are shown in the results section figure.
Rules in fuzzy logic are based on the knowledge of experts in the field to which fuzzy logic is applied [
29]. In a FIS, the rule base is given as a set of if-then statements [
29,
92]. Here, the desired behaviour of an AUV during the search was used to tailor the rule base of the FIS. If the current performance of the AUV is good, exploiting the area near the current position might lead to finding better positions. However, if the current performance of the AUV is poor, it might be more effective to explore other areas to find better places away from the current position of the AUV. In addition, the remaining energy of the AUV plays an important role. If the remaining energy is high, the AUV can potentially explore other areas even if the current performance is average. However, if the remaining energy of the AUV is low, it should avoid travelling longer distances to save energy. The aforementioned expected search behaviour was used to formulate the rule base system of the FIS. All the rules used in this research are summarised in
Table 2.
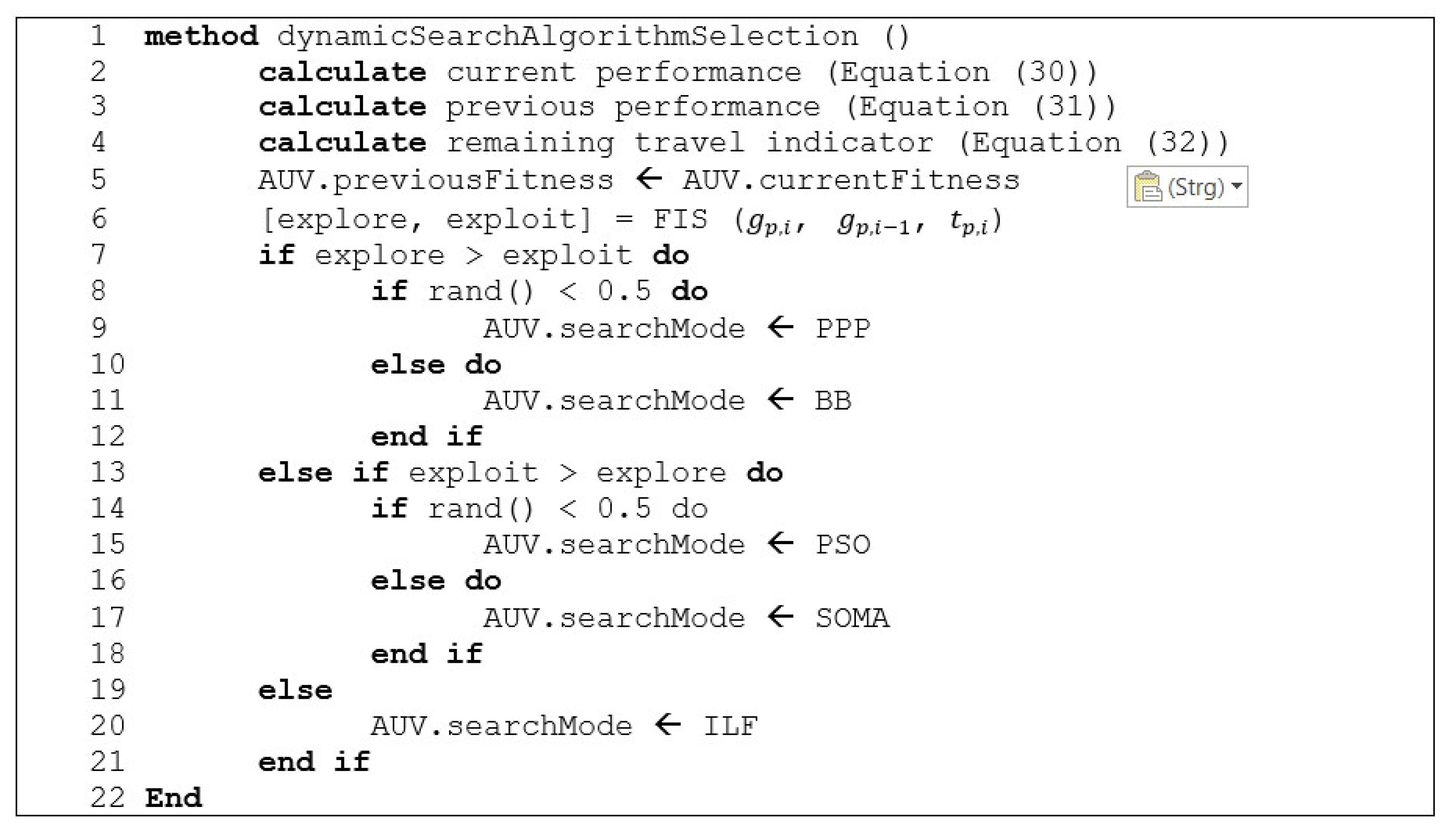
Based on the outputs of the FIS, an appropriate search strategy is chosen by the AUV. Therefore, the search strategies were divided into exploring and exploiting algorithms. PPP and BB were classified as exploring algorithms, while PSO and SOMA were defined as exploiting algorithms. ILF was used as fall-back algorithm for the case of equality between exploring and exploiting output of the FIS. RW was not used for the dynamic selection approach. The selection from the group of suitable algorithms was undertaken randomly. The procedure of dynamic selection of a suitable search strategy, described above, is summarised as pseudocode in
Figure 20.
The FIS was built on expert knowledge and the expected behaviour of the AUV during the search. The MFs of the different inputs and outputs were designed as regular triangle functions covering the whole input space. However, it cannot be guaranteed that these triangular shapes best solve the problem at hand. Therefore, the shapes of the input MFs were optimised utilising Simulated Annealing (SA) [
93]. For each input, three triangle-shaped MFs were defined. Each MF contained three parameters
An,
Bn, and
Cn. The value of the parameters can be chosen according to:
The total number of optimisation parameters is 27. The MFs defined above were chosen as starting point for the optimisation. In each iteration of the optimisation process, a new set of parameters was selected and evaluated. For this evaluation, the selected values were used to define the shapes of the MFs of the inputs. Utilising these MFs, 100 search runs, as described in
Figure 13 were conducted, and the fitness (Equation (24)) was calculated. The optimisation process is summarised as pseudocode in
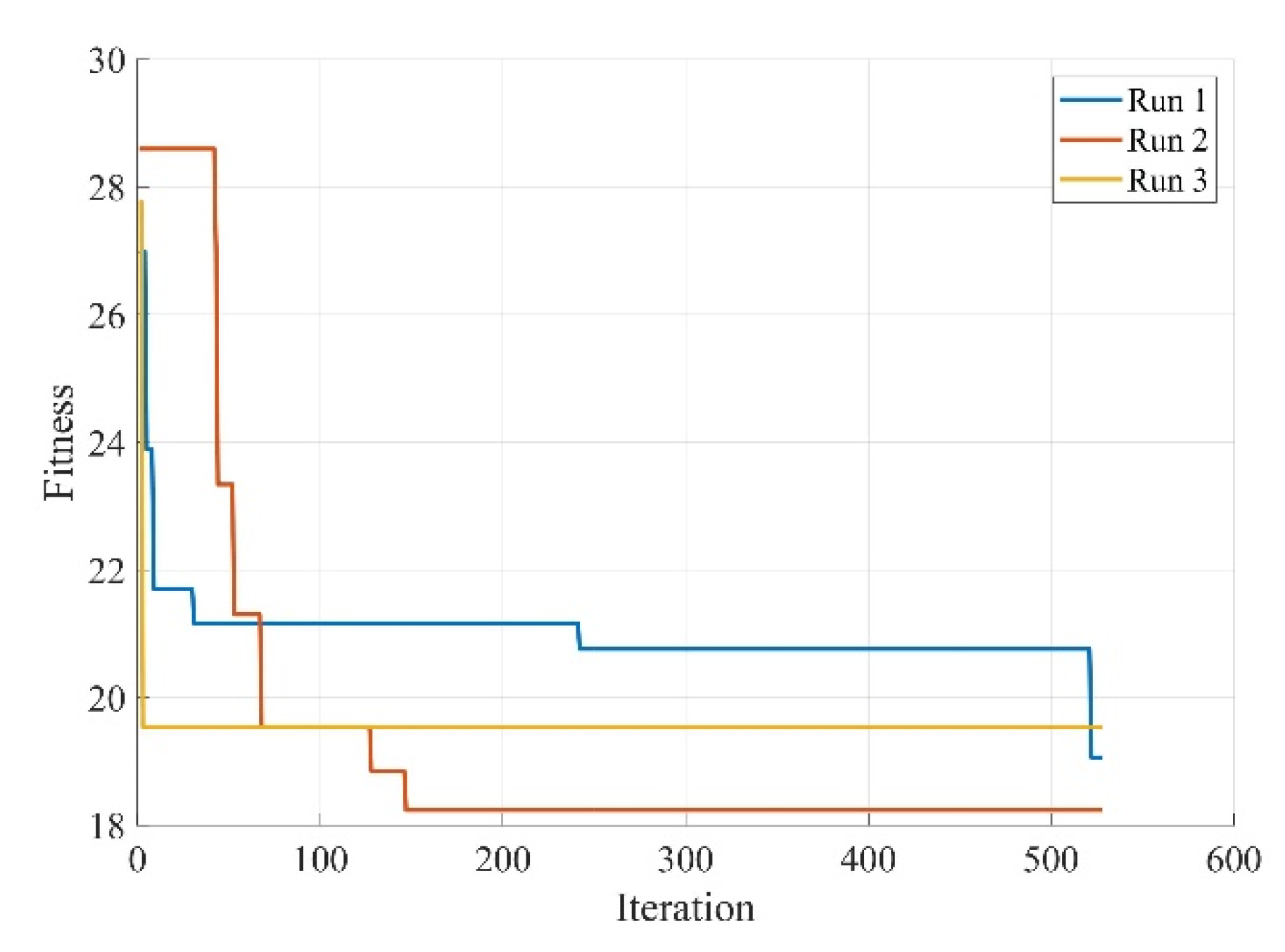
Figure 21. The whole optimisation process of the MFs was repeated three times.
7. Conclusions
In this study, the performance of different search strategies applied for SGD detection were investigated using computer simulations. The dynamic simulation environment was built on in situ DO measurements and sonar backscatter data from a survey in Western Australia.
The influence of different factors, such as error-prone self-localisation or restricted communication, on the performance of the proposed algorithms was investigated. It was demonstrated that PPP outperformed all the other algorithms when all the AUVs used the same search strategy. On the other hand, with different search strategies for each AUV, the search performance of the whole swarm was improved by incorporating population-based search strategies, such as PSO and SOMA, within the PPP scheme. The best performance was achieved for the static combination of two AUVs following PPP, while the third AUV utilised PSO for the search. The performance of this combination was 26.4% better than that of PPP, based on the fitness-over-travel-distance variation.
In addition, a novel mechanism for the dynamic selection of search strategy was proposed and evaluated. This mechanism uses fuzzy logic and a set of defined rules to select the most suitable search algorithm. For different maximum travel distances of the AUVs, this dynamic approach was able to perform at least as well as the PPP and the SOMA strategies. However, due to its better adaptation to the current situation, the overall performance, calculated based on the fitness over travel distance curve, the proposed dynamic search strategy selection was 32.8% better than PPP and 34.0% better than SOMA.
The computer simulations showed that both the static combination and the dynamic search strategy selection scheme offer potential ways to utilise Artificial Intelligence optimisation algorithms such as PSO or SOMA as search strategies for AUVs.
In future research, both schemes will be evaluated further, using other search environments and practical field tests.



































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}