1. Introduction
Wheat, a widely cultivated staple crop across the globe, plays a vital role in ensuring global food security and driving the development of agricultural economies [
1]. The ongoing progress in digital agricultural technologies is driving a shift from labor-intensive practices to fully automated, unmanned intelligent systems across various stages of agricultural production. This transformation is progressively enabling the full automation and digitalization of agricultural processes, including tillage, sowing, management, and harvesting. The vigorous development of digital agriculture serves as a crucial strategy to foster high-quality socio-economic growth in rural areas, advance comprehensive rural revitalization, and contribute to the establishment of a digital China.
Traditional methods for identifying field wheat varieties mainly rely on morphological feature observation, but because it is difficult to distinguish wheat varieties from their appearance, these methods not only require substantial temporal and labor investments but also are susceptible to evaluator subjectivity. The application of deep learning technology for identifying and classifying field wheat varieties not only reduces operational costs and enables the automatic acquisition of crop variety information to enhance efficiency but also significantly improves classification accuracy, ultimately contributing to reducing operational costs and improving efficiency. On the other hand, different wheat varieties exhibit distinct nutritional and hydrological requirements. Accurate identification of wheat varieties in the field enables the development of customized fertilization and irrigation schemes. This approach not only meets the species-specific water and nutrient requirements of different wheat varieties but also enhances resource utilization efficiency and minimizes waste. During the harvest phase, it facilitates the improved collection and management of agricultural metadata, offers data-driven support for estimating crop yields and cultivated areas of individual farmlands, and establishes a valuable data repository for the development of agricultural big data systems, according to which researchers can conduct in-depth studies on the growth differences, disease resistance, climate adaptability, and other aspects of crop varieties. This provides a scientific basis for optimizing wheat variety breeding and improving both yield and quality. Additionally, it enhances the intelligence and precision of government agricultural management, facilitates the large-scale implementation of digital agriculture, and offers valuable insights for yield forecasting, policy adjustments, and agricultural resource allocation. Collectively, these advancements contribute to a significant improvement in agricultural productivity. In summary, this research not only enhances the efficiency of crop identification but also holds significant importance for optimizing agricultural production, promoting the sustainable utilization of agricultural resources, and advancing the development of digital agriculture.
Similar to crop disease and pest image recognition, the identification of wheat varieties at field maturity stages can also achieve efficient and precise classification through deep learning techniques. In traditional machine learning approaches, images require preprocessing, followed by feature extraction, which typically relies on manually designed algorithms [
2]. Experts must select appropriate feature extraction methods based on task-specific requirements, such as SIFT, HOG, LBP, etc. [
3], which primarily focus on low-level features, including color, texture, and shape. However, these conventional methods demonstrate limited generalization capabilities and are only suitable for tasks with distinct features and small datasets, such as simple object recognition or text classification, making them insufficient for meeting agricultural production demands. In contrast, deep learning employs a self-supervised manner to autonomously learn target features [
4]. Particularly, convolutional neural networks (CNNs), whose multi-layered architectures enable the progressive extraction of advanced image features—from edges to textures and shapes—ultimately forming high-level semantic understanding [
5]. Studies have demonstrated that CNNs trained on large-scale datasets can automatically extract complex image features and achieve high-accuracy crop classification [
6]. Furthermore, deep learning models exhibit superior performance in multi-task learning and large-scale dataset scenarios, demonstrating enhanced generalization capabilities [
7].
Numerous domestic and international studies have implemented deep learning models in agricultural applications with promising outcomes [
8]. Ananda S. Paymode et al. [
9] investigated CNN applications in early disease detection for tomatoes and grapes, employing the Visual Geometry Group (VGG) [
10] for feature extraction and classification. The experimental results demonstrate classification accuracies of 98.40% and 95.71% for grape leaves and tomato leaves, respectively. Yuan Y et al. [
11] integrated transfer learning with AlexNet [
12] and VGGNet to classify eight crop diseases, achieving a mean accuracy of 95.93%, which surpassed existing methods, while demonstrating enhanced robustness. F Chen et al. [
13] integrated terahertz time-domain spectroscopy (THz-TDS) [
14] with CNN to achieve the identification of 12 wheat varieties, reporting classification accuracies of 98.7% and 97.8% on the calibration and prediction sets, respectively, indicating its potential for seed identification and quality assessment. Yang G et al. [
15] proposed a fine-grained crop disease classification model leveraging transfer learning. Utilizing a dataset comprising 58,200 leaf images, the NASNetLarge model enhanced with attention mechanisms achieved the highest F1-score of 93.05%, demonstrating a significant improvement in classification accuracy. Sardeshmukh, M et al. [
16] explored CNN applications in crop classification, where VGG-16 outperformed other models with over 98% accuracy, while ResNet-50 exhibited suboptimal performance. Hongxing, Peng et al. [
17] introduced the HQIP102 dataset and proposed MADN, a pest recognition model that integrates selective kernel units, representative batch normalization, and ACON activation functions [
18] to enhance the DenseNet architecture. The experimental results show that MADN improved the accuracy and F1-scores by 5.17% and 5.20%, respectively, compared to baseline DenseNet121, and outperformed ResNet-101 by 10.48% accuracy and 10.56% F1-score while reducing parameters by 35.37%. Deployed on mobile cloud servers, it facilitates real-time identification of crop diseases and pests, offering a practical approach to yield optimization and quality control. Mu, Y et al. [
19] introduced an enhanced weed recognition method based on DenseNet, incorporating local variance background segmentation and data augmentation to address overfitting issues. This approach was further strengthened by the integration of efficient channel attention mechanisms to improve feature extraction capabilities. The experimental results demonstrate 97.98% accuracy, significantly outperforming DenseNet, VGG-16, and ResNet-50, suggesting suitability for intelligent weeding devices. Jiang, M et al. [
20] proposed a DenseNet architecture optimized with SE-attention for rice disease recognition, integrating depthwise separable convolutions to improve parameter efficiency and accelerate training speed. The model achieved 99.4% average classification accuracy, surpassing the original DenseNet by 13.8% and outperforming ResNet, VGG, and Vision Transformer architectures. Feng, S et al. [
21] designed a CNN-based rapid classification model for crop diseases, incorporating SE modules into the DenseNet architecture to balance the importance of feature maps. Additionally, Leaky ReLU activation functions were utilized to enhance the model’s fitting capability. Experimental validation confirmed its strong potential for crop disease detection applications.
In summary, the feasibility of classifying crops through deep-learning-based image classification and recognition technology is demonstrated in this study; however, several challenges remain to be addressed. First, previous studies have primarily focused on crop diseases, pests, or wheat grain cultivars; to date, no research has specifically investigated the recognition of different wheat varieties at maturity. Second, to achieve reliable classification of field wheat varieties, it is imperative to utilize sufficiently large and diverse datasets that include adequate training samples, and these datasets should ideally encompass images of mature wheat captured from multiple viewpoints, representing various cultivars and developmental stages. Moreover, the rapid progress in deep learning has led to the development of numerous efficient network models specifically designed for image classification tasks; however, their recognition performance varies depending on the specific application. Therefore, the performance of the recognition system for field wheat varieties requires experimental validation, and whether the model’s accuracy can be further enhanced remains a critical research question.
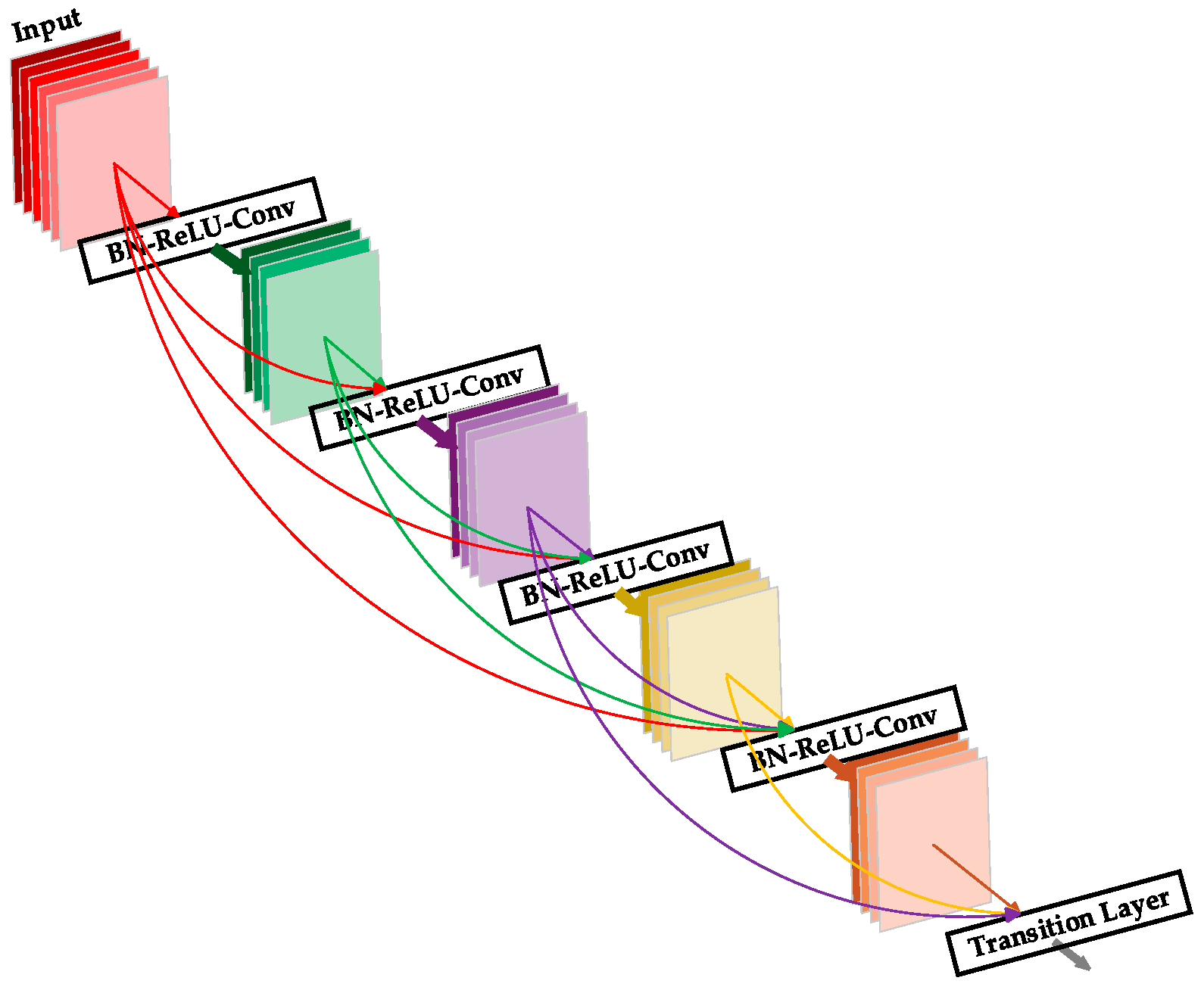
To address the aforementioned issues, a SECA-L-DenseNet network model has been developed for wheat variety recognition in the field. Building upon the original DenseNet network model, the dual attention mechanism—comprising the Squeeze-and-Excitation (SE) module [
22] and the Efficient Channel Attention (ECA) module [
23]—has been integrated into this approach. This approach enhances feature representation in the intermediate layers, thereby improving the overall feature extraction capability and recognition accuracy. This research aims to develop an efficient deep-learning-based model for wheat variety classification, with the goal of improving both accuracy and robustness in image recognition. This model seeks to offer an automated solution for wheat variety identification, thereby contributing to the advancement of smart agriculture.
3. Results and Analysis
3.1. Evaluation Index
In this study, precision, recall, F1-score, and accuracy were employed as evaluation metrics to assess the performance of each classification model. Additionally, a confusion matrix analysis was conducted to examine misclassification patterns among the eight categories.
Precision quantifies the proportion of correctly predicted positive samples relative to the total number of predicted positive cases. Recall measures the proportion of correctly predicted positive samples relative to the total number of actual positive samples. The F1-score, defined as the harmonic mean of precision and recall, ranges from 0 to 1, where higher values indicate superior model performance. Accuracy represents the proportion of correctly classified samples relative to the total number of samples. The corresponding mathematical formulations are provided in Equations (3)–(6).
True positives (TP) refer to the number of correctly predicted positive samples. False positives (FP) indicate the number of incorrectly predicted positive samples. False negatives (FN) represent the number of actual positive samples misclassified as negative, while true negatives (TN) denote the number of correctly predicted negative samples.
Additionally, considering the operational requirements of model deployment, it is essential to incorporate evaluation metrics that account for both the number of parameters and frames per second (FPS) to assess the feasibility of deploying enhanced models. The number of parameters directly influences memory consumption and computational complexity, while FPS serves as a critical metric for evaluating real-time inference performance in agricultural machinery applications.
3.2. Comparison Experiment of Different Classification Models
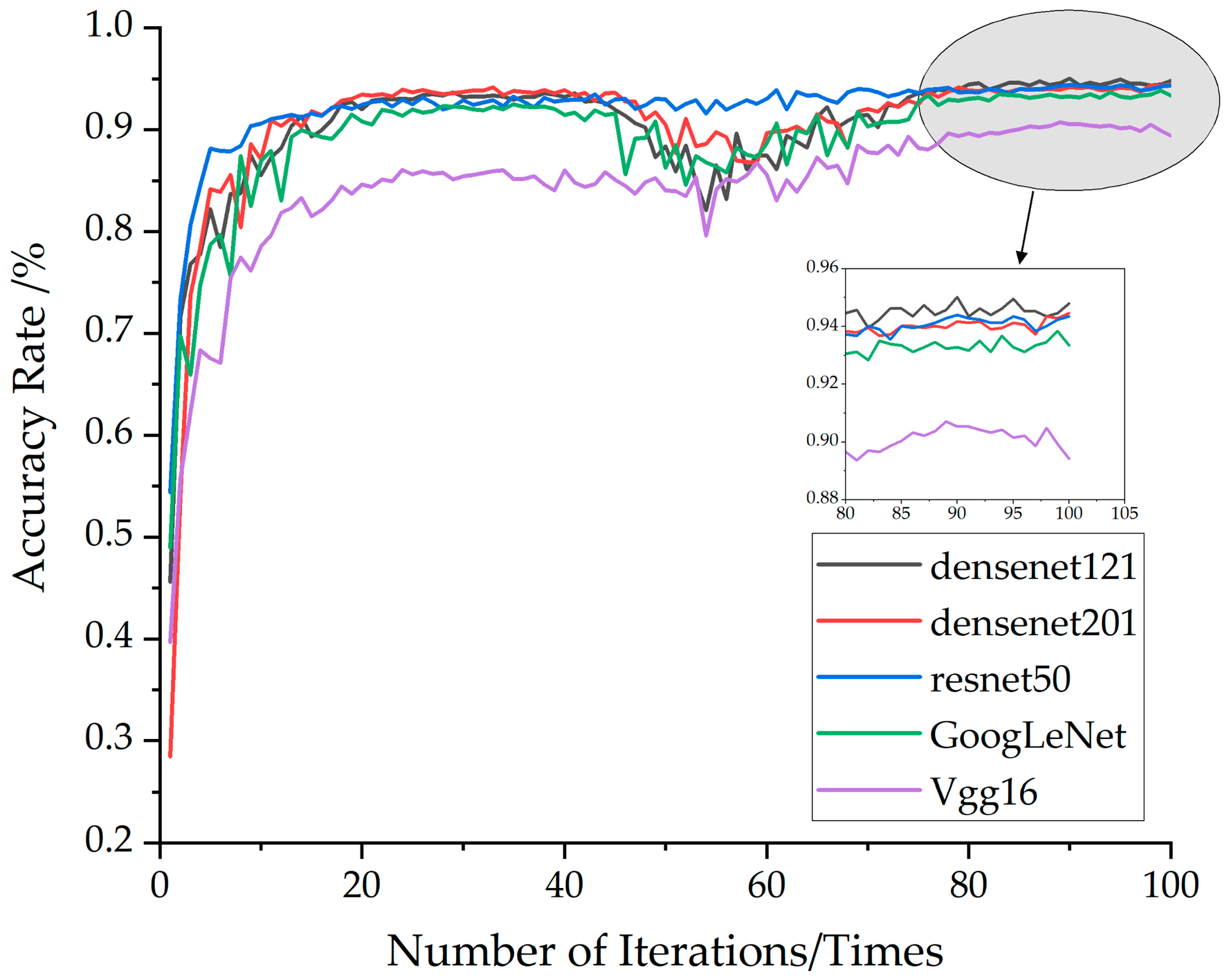
To evaluate the performance differences between DenseNet121 and other mainstream models, this study selected DenseNet201, ResNet50, GoogLeNet, and VGG16 as baseline models for comparison. Each model was trained for 100 epochs. To ensure robustness, each model underwent training five times with random initialization, and the mean accuracy was recorded.
Figure 6 illustrates the accuracy curves of the five models during the training process.
As training progressed, the overall performance difference between DenseNet121 and DenseNet201 remains relatively small. However, by the end of training, DenseNet121 achieved both a higher overall accuracy and a higher peak accuracy compared to DenseNet201. Among the five models, ResNet50 demonstrated the most stable performance throughout training, although its average accuracy was slightly lower than that of DenseNet121 in the final stages of training.
In summary, DenseNet121 outperformed the other four models among these five network models.
Table 2 presents the classification results of the five models. The metrics precision, recall, and F1-score represent the macro-averaged values of the respective performance metrics across all the categories. The results indicate that VGG16 achieved the lowest classification accuracy on the dataset, with a value of 90.71%. The accuracies of ResNet50 and DenseNet201 were nearly identical, at 94.40% and 94.46%, respectively. DenseNet121 attained the highest accuracy among the five models, reaching 95.02%. These findings suggest that among the five tested models, DenseNet121 exhibited the best overall training performance.
3.3. Wheat Variety Recognition Experiment
The evaluation metrics for the wheat variety recognition test are summarized in
Table 3. The SECA-L-DenseNet121 model achieved a recognition accuracy of 97.15%, demonstrating its ability to efficiently and accurately classify field-captured wheat images. This meets the objectives of model improvement and highlights its robust performance.
Specifically, the model exhibited the highest classification performance for wheat stubble, with all three evaluation metrics exceeding 99%. This superior performance may be attributed to the significant morphological differences between wheat stubble and mature wheat varieties. Among the seven wheat varieties, excluding wheat stubble, the proposed model achieved the best recognition results for Yudancheng 339, with an accuracy of 100%, a recall of 96.18%, and an F1-score of 98.05%.
Additionally, the model demonstrated high classification performance for Jinghua 11 and Jimai 38, while its recognition accuracy for Lanmai was relatively lower. This lower performance may be due to the lack of distinct external visual features in Lanmai, which makes differentiation more challenging.
Overall, the improved SECA-L-DenseNet121 model effectively enhances the accuracy of wheat variety classification and recognition, providing crucial support for field crop classification and recognition technologies.
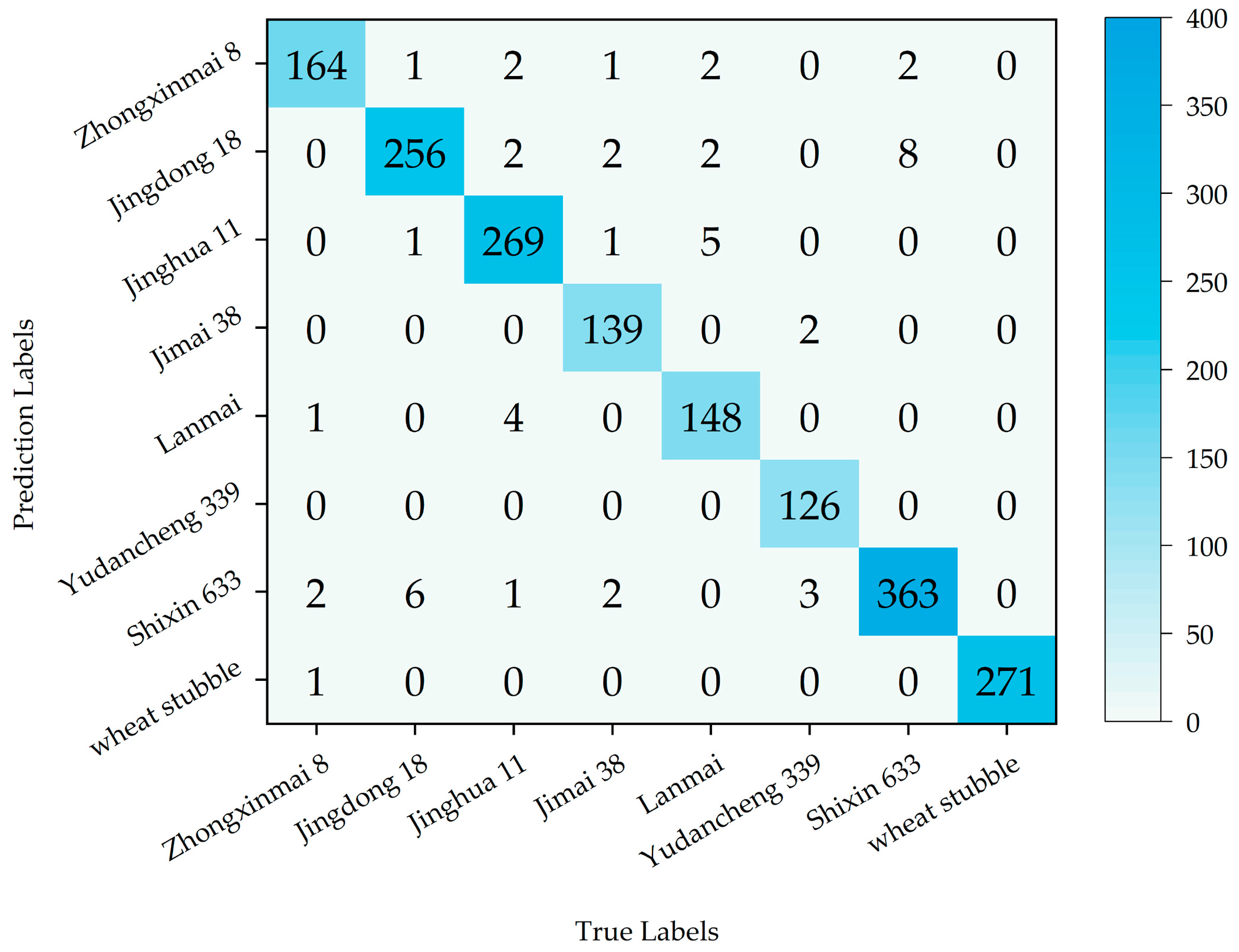
The confusion matrix is a fundamental tool for evaluating the performance of classification models in machine learning and statistical analysis. By comparing the model’s predicted outcomes with the actual labels, it provides a comprehensive assessment of classification effectiveness, enabling a deeper understanding of the model’s strengths and limitations. The confusion matrix for the SECA-L-DenseNet121 model is presented in
Figure 7. As shown in
Figure 7, the model correctly classified 1736 images, achieving an overall recognition accuracy of 97.15%. The predictions are densely clustered along the diagonal, indicating a high level of classification accuracy. Among all the categories, the model demonstrated the highest classification performance for wheat stubble, correctly identifying all 271 positive samples. Observing the misclassified samples, it is evident that the model encountered challenges in distinguishing Jingdong 18 and Shixin 633. This difficulty may stem from the similarities between these two wheat varieties and other varieties in terms of color, shape, and other morphological characteristics. Such similarities likely reduce the model’s ability to extract distinctive features, thereby increasing the likelihood of misclassification. Overall, the SECA-L-DenseNet121 model effectively identifies field wheat varieties and exhibits strong recognition performance across all the categories. The model demonstrates a high level of accuracy in distinguishing different wheat varieties, further supporting its practical application in automated wheat classification.
3.4. Ablation Experiment
An ablation study is a widely used method for evaluating the impact of different components in a model on its final performance. By systematically removing or modifying specific parts of the model and observing changes in performance, this approach helps identify the most influential components. To assess the effectiveness of the newly introduced modules in the SECA-L-DenseNet121 model, ablation experiments were conducted. The enhanced model was compared against the original model, as well as modified versions incorporating individual modules. By systematically replacing different attention mechanisms and activation functions, variations in classification accuracy were analyzed, providing insights into the contribution of each module to the model’s overall performance.
Figure 8 presents the results of the ablation experiments in a line chart format, systematically evaluating model variants by modifying key components and activation functions (as detailed in
Table 4). Each modified architecture was trained and evaluated under identical experimental conditions. As illustrated in
Figure 8, all the improved models exhibited similar accuracy trajectories during training. However, in the final training phase, the SECA-L-DenseNet121 model achieved significantly superior recognition accuracy compared to the other variants. A comprehensive quantitative evaluation of these models is summarized in
Table 4. The results indicate that replacing the Leaky ReLU activation function with the ReLU activation function in the DenseNet model improved classification accuracy by 0.34 percentage points. Incorporating only the SE attention mechanism increased accuracy by 1.17 percentage points, while introducing only the ECA attention mechanism resulted in a 0.22 percentage point improvement. Notably, when both the SE and ECA attention mechanisms were applied simultaneously, along with replacing the activation function with Leaky ReLU, the model achieved a classification accuracy of 97.15%, representing a 2.13 percentage point increase compared to the baseline DenseNet model.
On the other hand, integrating the dual-attention mechanism led to a 0.5% increase in the model parameters and a 31.6% reduction in the frame rate (FPS) compared to the original architecture. However, considering the heightened accuracy requirements and the near-zero tolerance for misclassification in practical deployment scenarios—combined with the fact that both the increased parameter count and reduced FPS remain within operationally viable thresholds without compromising deployment feasibility—the SECA-L-DenseNet121 model proves to be the most effective choice when evaluated holistically.
Hyperparameters are parameters that are set prior to training and directly influence model performance, training speed, and convergence. Unlike model parameters, hyperparameters are manually selected and are typically optimized through empirical experimentation. Selecting appropriate hyperparameters is crucial for training efficient and accurate deep learning models.
Among all hyperparameters, the learning rate is one of the most critical in deep learning, as it determines the step size of parameter updates along the gradient direction. The learning rate not only affects whether the model can converge to an optimal solution but also impacts the speed and stability of convergence. A learning rate that is too high leads to excessive gradient updates, preventing stable convergence. Conversely, a learning rate that is too low results in slow convergence, potentially causing the training process to terminate prematurely before reaching the optimal solution and increasing the risk of overfitting.
To determine the optimal learning rate for improved performance, experiments were conducted using different learning rate settings to train the SECA-L-DenseNet121 model. The SGD optimizer was employed, with learning rates set to 0.05, 0.01, and 0.001, and weight decay coefficients were set to 0.001, 0.0001, and 0.00001, respectively. All possible combinations of these two hyperparameters were tested systematically during training.
The experimental results are presented in
Figure 9. As observed from the figure, the model achieved the best performance when the learning rate was set to 0.01 and the weight decay coefficient was set to 0.0001.
4. Discussion
The application of deep learning technology in the classification and identification of mature field wheat varieties significantly addresses the substantial time and resource consumption associated with manual classification. Moreover, it mitigates the issue of low accuracy caused by subjective human operations. Leveraging deep learning network models for wheat variety identification not only enhances efficiency but also achieves accuracy far superior to manual methods. Consequently, this technology plays a crucial role in wheat variety breeding, field resource management, and crop yield prediction.
Convolutional neural networks (CNNs) exhibit remarkable advantages in local image feature extraction, effectively capturing critical features from input images to enable precise image classification. Compared to other classification models, DenseNet distinguishes itself through its unique dense connectivity mechanism, which facilitates efficient feature reuse, enhances gradient propagation, mitigates gradient vanishing, and improves feature representation capability and computational efficiency, all while reducing the number of model parameters. These advantages collectively contribute to improved classification accuracy and generalization capability.
This study collected and constructed an image dataset comprising 8956 images of eight mature wheat varieties. To achieve more precise wheat variety identification, we enhanced the DenseNet model by integrating SE and ECA modules, thereby developing a dual-attention mechanism model named SECA-L-DenseNet. This enhancement enables adaptive reinforcement of critical inter-channel features while suppressing redundant information. Furthermore, we replaced ReLU with Leaky ReLU to effectively mitigate “neuron death” issues, thereby improving model training stability. Additionally, to address the challenge of a limited dataset size, we applied transfer learning by fine-tuning a pre-trained model, enhancing both the generalization ability and convergence speed. The experimental results indicate that the improved model achieved a 2.13 percentage point increase in recognition accuracy, demonstrating a significant improvement over the baseline model.
However, despite the SECA-L-DenseNet model achieving accurate and efficient wheat variety identification under field conditions, several limitations remain that require further refinement before practical deployment. First, for large-scale agricultural applications, it is imperative to expand the dataset by incorporating multispectral imagery from diverse crop types, cultivars, geographical regions, and phenological stages to enhance model robustness. Second, although the dataset was acquired under optimal weather and illumination conditions, real-world implementation necessitates onboard imaging systems installed on harvesters. Under operational conditions, complex interference factors, including dust contamination, illumination variations, and mechanical vibrations, may induce significant discrepancies between field-captured images and training data. While our preprocessing methods partially mitigate these disturbances, model performance degradation under extreme environmental scenarios remains a concern. Finally, given the intended deployment on resource-constrained mobile platforms, optimizing the model’s lightweight architecture without compromising recognition accuracy will be a critical focus of future research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}