
Swift Transfer of Lactating Piglet Detection Model Using Semi-Automatic Annotation Under an Unfamiliar Pig Farming Environment


Abstract
1. Introduction
- (1)
- The development of a novel semi-automatic labeling methodology tailored for piglet identification.
- (2)
- The construction of comprehensive piglet target datasets from multiple commercial pig farms.
- (3)
- A systematic evaluation of the impact of diverse data compositions in piglet imagery on the performance metrics of object detection models.
- (4)
- The demonstration of the extensibility of this semi-automatic annotation approach to piglet segmentation tasks, highlighting its potential for broader applications in animal behavior analysis.
2. Materials and Methods
2.1. Data Collection
- (1)
- Data from the Jingjiang Pig Farm (abbreviated as “jj”) was acquired at Fengyuan Ecological Agricultural Park Limited Company, located in Jingjiang City, Jiangsu Province. The farm comprises two maternity pig rooms, each equal in size and segmented into six farrowing pens measuring 20 cm × 180 cm each. For surveillance and data collection, a total of 12 Hikvision DS-2CD3135F-l model cameras were installed. These cameras were mounted vertically overhead at a height of 3 m above each farrowing pen, capturing footage over a period from 24 April 2017 to 31 May 2017.
- (2)
- Data from the Suqian Pig Farm, denoted as “sq” in this study, was collected at the Zhengjie Pig Farm, situated in the Suyu District of Suqian City, Jiangsu Province. Data were collected from a single maternity pig room containing 48 farrowing pens, each measuring 220 cm × 190 cm. Out of these, 12 farrowing pens were equipped with cameras for surveillance. The Hikvision DS-2CD3346WD-I model cameras were mounted vertically overhead at a height of 2.2 m. Video data were recorded over a period from 9 June 2020 to 15 June 2020.
- (3)
- Data from the Sheyang Pig Farm, referred to as “sy”, was obtained from a single maternity pig room at Kouda Food Co., Ltd., located in Sheyang County, Yancheng City, Jiangsu Province. This room consisted of 40 farrowing pens, each measuring 220 cm × 190 cm. Of these, 10 farrowing pens were outfitted with cameras for data collection purposes, specifically using the Hikvision DS-2CD3346WD-I model. These cameras were mounted vertically overhead at a height of 2.3 m, with video data being recorded from 27 December 2020 to 7 February 2021.
- (4)
- Data from the Danyang Pig Farm, denoted as “dy”, was gathered from two maternity pig rooms at the Silver Light Pig Farm in Danyang City, Jiangsu Province. Each room contained 24 farrowing pens, measuring 220 cm × 190 cm. Above each of these pens, a camera was installed, amounting to a total of 48 cameras, all of which were the Hikvision DS-2CD3346WD-I model. These cameras were set up vertically overhead at a height of 3 m, capturing video data from 1 June 2022 to 1 July 2022.
2.2. Experimental Environment
2.3. Dataset Creation
2.3.1. Manual Data Labeling
- (1)
- Pigs with more than 50% of their bodies covered and their heads obscured were excluded from the annotation.
- (2)
- Piglets with more than 80% of their bodies obscured were also not annotated.
2.3.2. Data Set Composition Method
2.3.3. Data Set Naming Convention
2.4. Piglet Detection Model Construction
2.5. Semi-Automatic Annotation of Piglet Labels
2.6. Evaluation Metrics for Model Detection Performance
3. Results
3.1. Automatic Video Splitting and Cleaning Results
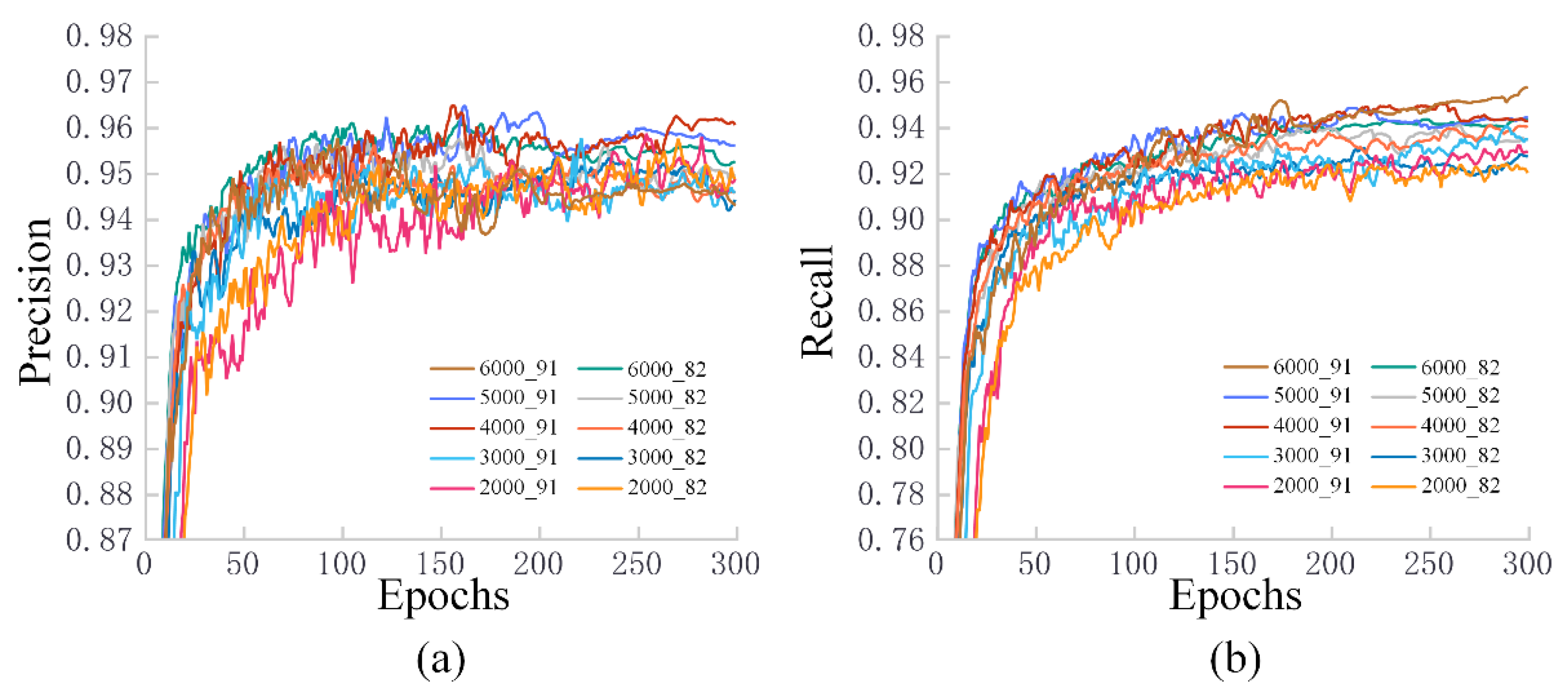
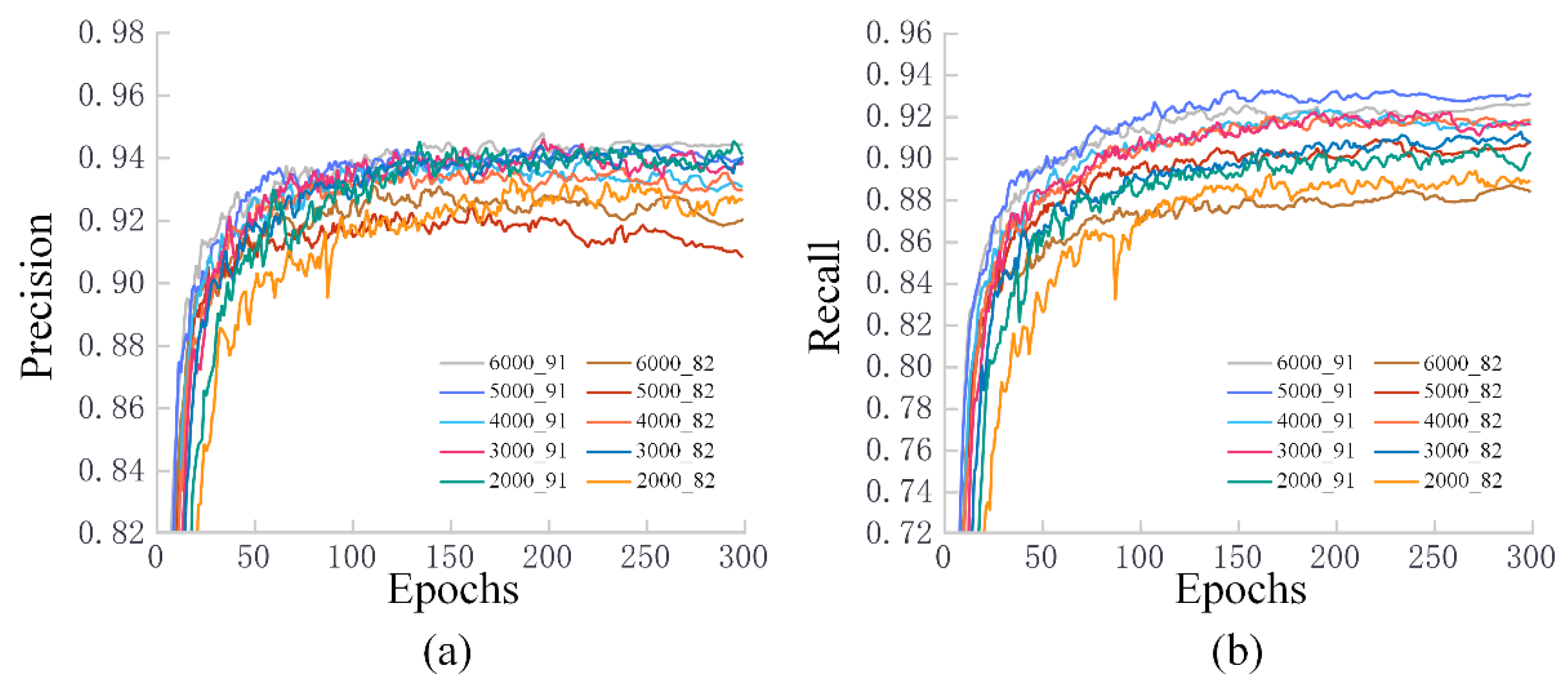
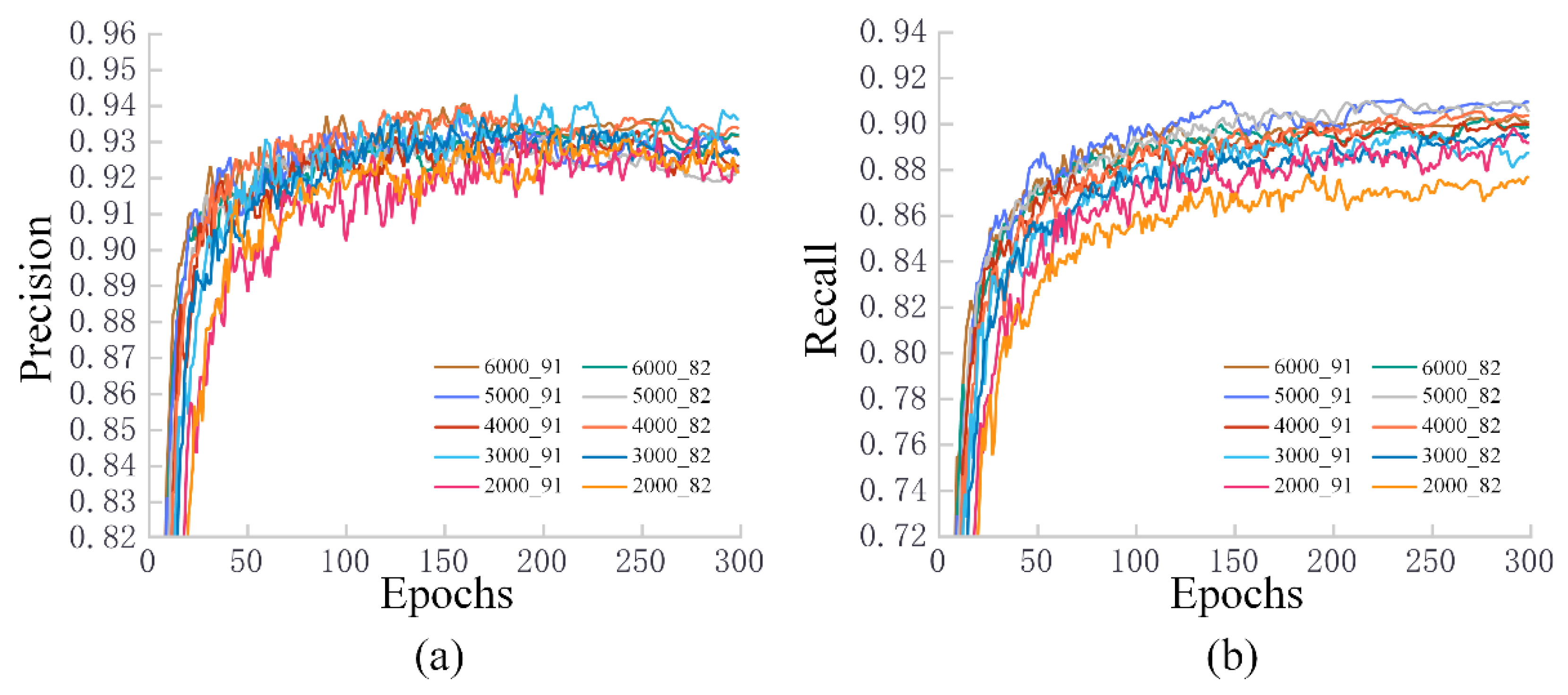
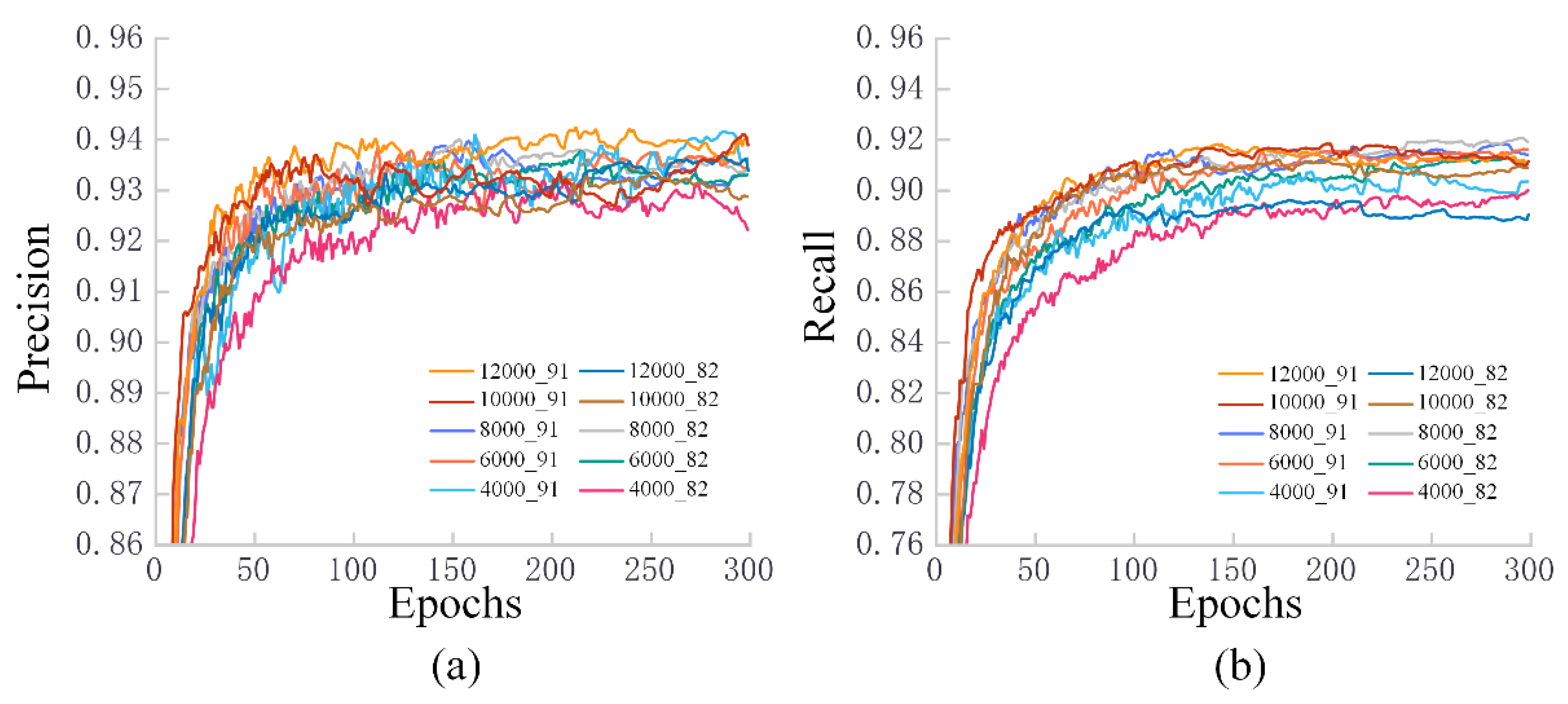
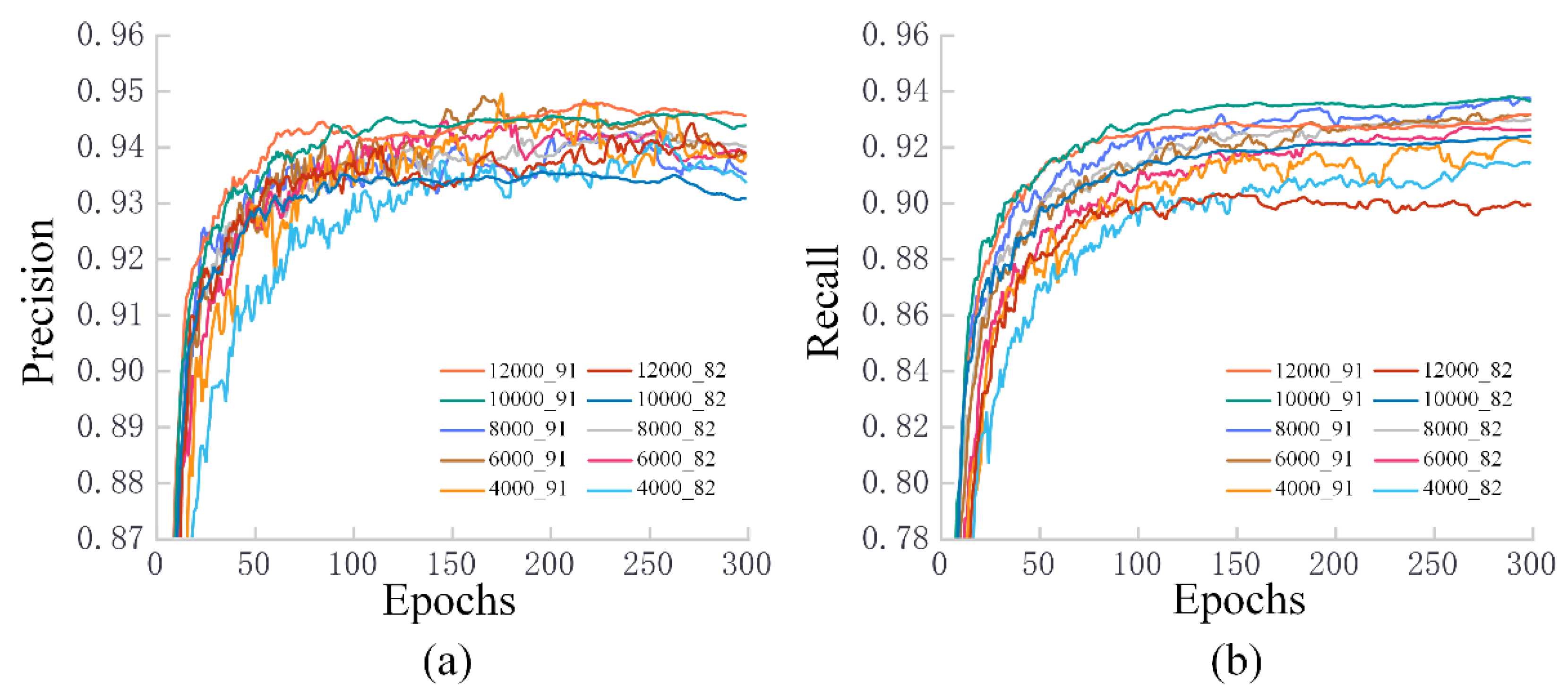
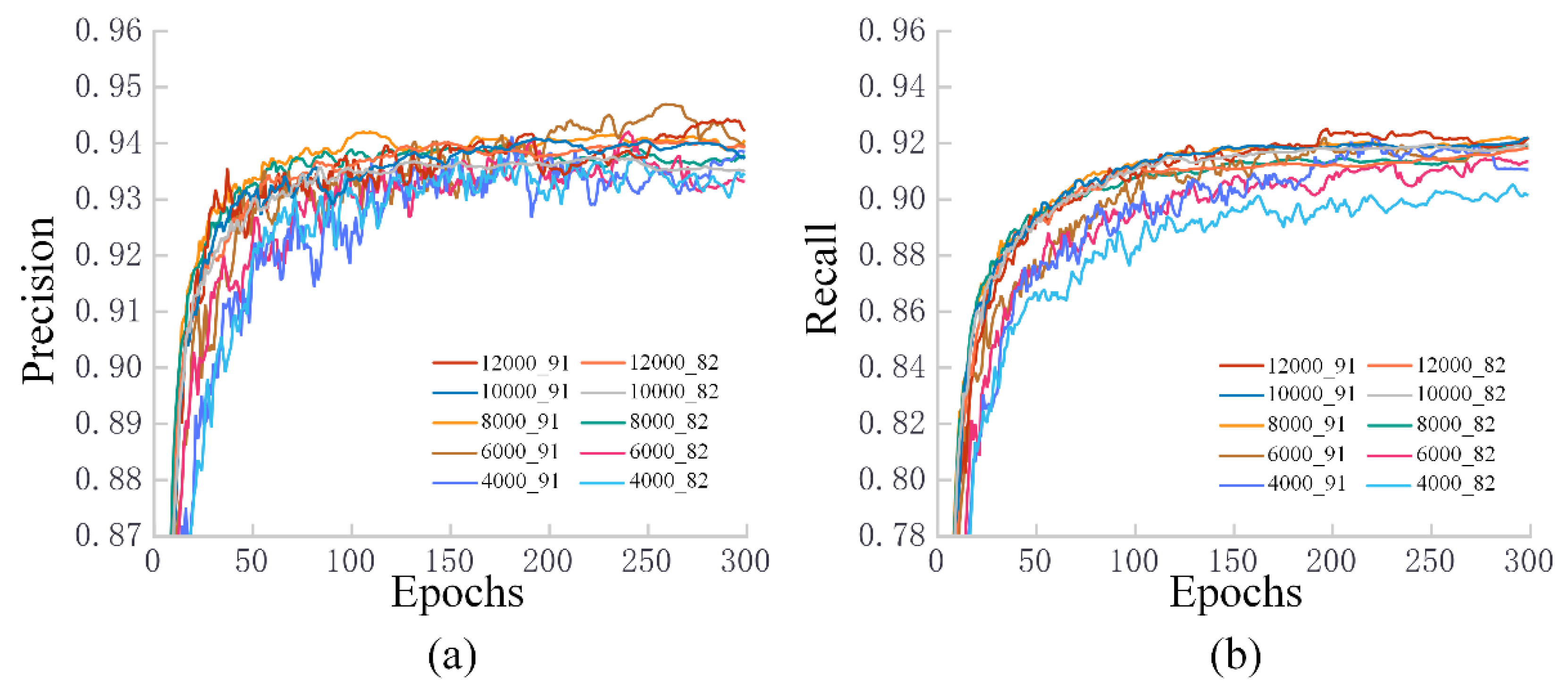
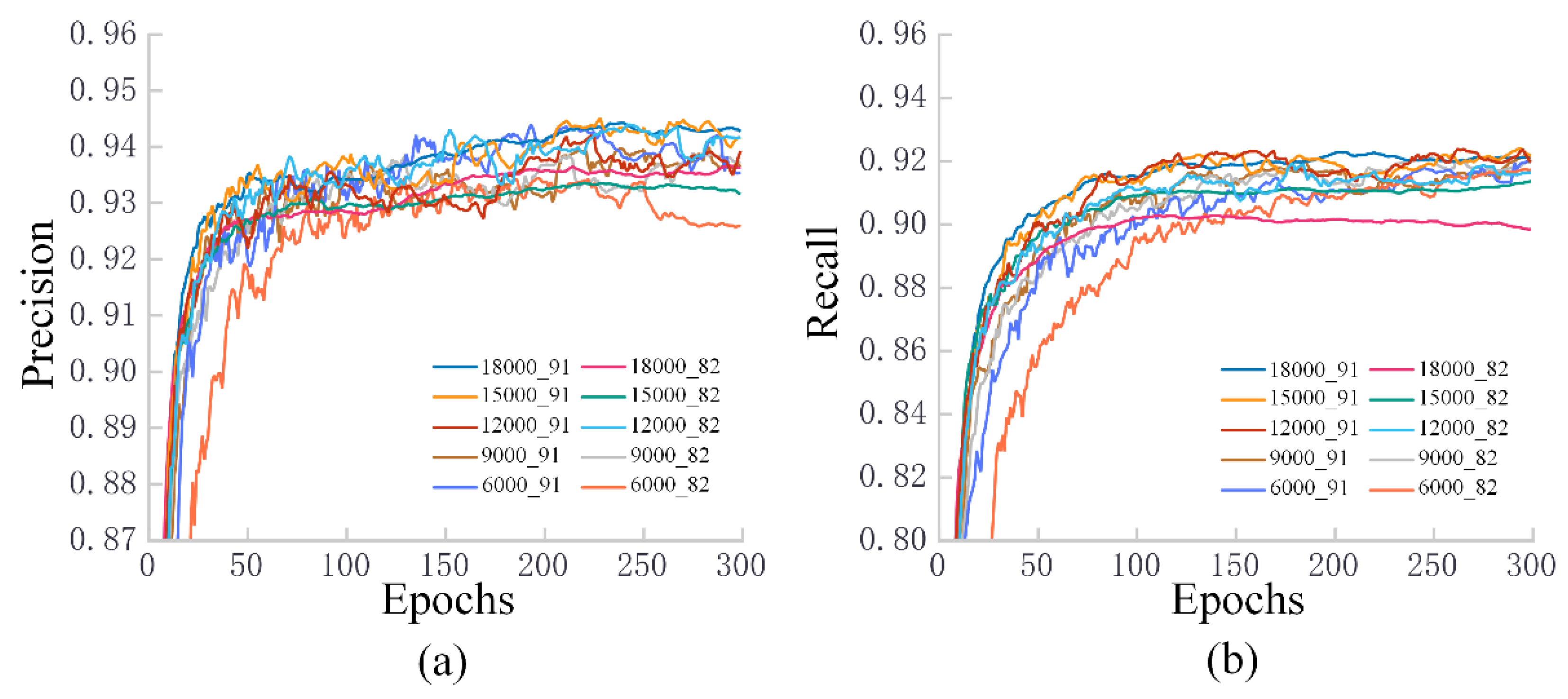
3.2. Training Results for Different Datasets
3.3. Test Results for Fresh Samples in Different Datasets
3.4. Training Results of the Semi-Automatic Labeling Model
4. Discussion
4.1. Reason for Damaged Images
4.2. The Impact of Different Piglet Datasets on Training Results
4.3. The Adaptation of Different Piglet Datasets to Unfamiliar Scenarios
4.4. The Potential for the Method in Piglet Segmentation
4.5. Shortcomings and Future Work
5. Conclusions
- (1)
- We propose a novel scene transfer approach for suckling piglet object detection that integrates semi-automatic labeling. This technique leverages frame difference analysis to assess the similarity between video frames, selectively incorporating low-similarity images into the training set to reduce data cleaning time. Initially, we employed a preliminary piglet annotation model based on the YOLOv5s network to pre-label new samples, which were subsequently refined through manual corrections. The optimized dataset was then used to retrain the YOLOv5s network, enabling rapid adaptation of the piglet detection model to new environments. It is worth noting that YOLOv5 is utilized solely as the object detector in our method and can be replaced by any superior object detection model.
- (2)
- The efficacy of pre-labeled datasets significantly impacts the efficiency of semi-automatic labeling, particularly in terms of time cost. To investigate this, we constructed seventy distinct datasets varying in scale, partition ratios, and combinations of data from different pig farms. These datasets were uniformly trained using a consistent deep-learning network, and new samples were evaluated to determine how various factors influenced test outcomes. The experiments demonstrated that strategically augmenting existing datasets, such as increasing the number of samples while enhancing their diversity, could markedly improve the performance of the piglet pre-labeling model. This enhancement, in turn, expedites the transfer process of the piglet detection model to new environments.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Hao, W.; Han, W.; Han, M.; Li, F. A Novel Improved YOLOv3-SC Model for Individual Pig Detection. Sensors 2022, 22, 8792. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Zhou, S.; Xu, A.; Ye, J.; Zhao, A. Automatic scoring of postures in grouped pigs using depth image and CNN-SVM. Comput. Electron. Agric. 2022, 194, 106746. [Google Scholar]
- Yang, Q.; Xiao, D. A review of video-based pig behavior recognition. Appl. Anim. Behav. Sci. 2020, 233, 105146. [Google Scholar] [CrossRef]
- Stukelj, M.; Hajdinjak, M.; Pusnik, I. Stress-free measurement of body temperature of pigs by using thermal imaging–Useful fact or wishful thinking. Comput. Electron. Agric. 2022, 193, 106656. [Google Scholar]
- Tran, D.D.; Thanh, N.D. Pig Health Abnormality Detection Based on Behavior Patterns in Activity Periods using Deep Learning. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, H.; Qiao, Y.; Jiang, S.; Lin, H.; Sun, Q. The Research Progress of Vision-Based Artificial Intelligence in Smart Pig Farming. Sensors 2022, 22, 6541. [Google Scholar] [CrossRef]
- Verdon, M.; Morrison, R.S.; Rault, J.L. Sow and piglet behaviour in group lactation housing from 7 or 14 days post-partum. Appl. Anim. Behav. Sci. 2019, 214, 25–33. [Google Scholar]
- Verdon, M.; Morrison, R.S.; Rault, J.L. The welfare and productivity of sows and piglets in group lactation from 7, 10, or 14 d postpartum. J. Anim. Sci. 2020, 98, skaa037. [Google Scholar]
- Blavi, L.; Solà-Oriol, D.; Llonch, P.; López-Vergé, S.; Martín-Orúe, S.M.; Pérez, J.F. Management and feeding strategies in early life to increase piglet performance and welfare around weaning: A review. Animals 2021, 11, 302. [Google Scholar] [CrossRef]
- Liu, C.; Zhou, H.; Cao, J.; Guo, X.; Su, J.; Wang, L.; Lu, S.; Li, L. Behavior Trajectory Tracking of Piglets Based on DLC-KPCA. Agriculture 2021, 11, 843. [Google Scholar] [CrossRef]
- Gan, H.; Ou, M.; Huang, E.; Xu, C.; Li, S.; Li, J.; Liu, K.; Xue, Y. Automated detection and analysis of social behaviors among preweaning piglets using key point-based spatial and temporal features. Comput. Electron. Agric. 2021, 188, 106357. [Google Scholar] [CrossRef]
- Ding, Q.A.; Chen, J.; Shen, M.X.; Liu, L.S. Activity detection of suckling piglets based on motion area analysis using frame differences in combination with convolution neural network. Comput. Electron. Agric. 2022, 194, 106741. [Google Scholar]
- Yang, A.; Huang, H.; Yang, X.; Li, S.; Chen, C.; Gan, H.; Xue, Y. Automated video analysis of sow nursing behavior based on fully convolutional network and oriented optical flow. Comput. Electron. Agric. 2019, 167, 105048. [Google Scholar]
- Wang, Y.; Li, R.; Wang, Z.; Hua, Z.; Jiao, Y.; Duan, Y.; Song, H. E3D: An efficient 3D CNN for the recognition of dairy cow’s basic motion behavior. Comput. Electron. Agric. 2023, 205, 107607. [Google Scholar]
- Bianco, S.; Ciocca, G.; Napoletano, P.; Schettini, R. An interactive tool for manual, semi-automatic and automatic video annotation. Comput. Vis. Image Underst. 2015, 131, 88–99. [Google Scholar]
- Mamat, N.; Othman, M.F.; Abdulghafor, R.; Alwan, A.A.; Gulzar, Y. Enhancing image annotation technique of fruit classification using a deep learning approach. Sustainability 2023, 15, 901. [Google Scholar] [CrossRef]
- Saifullah, S.; Dreżewski, R.; Dwiyanto, F.A.; Aribowo, A.S.; Fauziah, Y.; Cahyana, N.H. Automated text annotation using a semi-supervised approach with meta vectorizer and machine learning algorithms for hate speech detection. Appl. Sci. 2024, 14, 1078. [Google Scholar] [CrossRef]
- Su, H.; Yao, Q.; Xiang, L.; Hu, A. Semi-supervised temporal meta learning framework for wind turbine bearing fault diagnosis under limited annotation data. IEEE Trans. Instrum. Meas. 2024, 73, 3512309. [Google Scholar] [CrossRef]
- Liu, S.; Zhao, C.; Zhang, H.; Li, Q.; Li, S.; Chen, Y.; Gao, R.; Wang, R.; Li, X. ICNet: A Dual-Branch Instance Segmentation Network for High-Precision Pig Counting. Agriculture 2024, 14, 141. [Google Scholar] [CrossRef]
- Xia, X.; Zhang, N.; Guan, Z.; Chai, X.; Ma, S.; Chai, X.; Sun, T. PAB-Mamba-YOLO: VSSM assists in YOLO for aggressive behavior detection among weaned piglets. Artif. Intell. Agric. 2025, 15, 52–66. [Google Scholar]
- Zhou, J.; Liu, L.; Jiang, T.; Tian, H.; Shen, M.; Liu, L. A Novel Behavior Detection Method for Sows and Piglets during Lactation Based on an Inspection Robot. Comput. Electron. Agric. 2024, 227, 109613. [Google Scholar]
- Luo, Y.; Lin, K.; Xiao, Z.; Lv, E.; Wei, X.; Li, B.; Lu, H.; Zeng, Z. PBR-YOLO: A lightweight piglet multi-behavior recognition algorithm based on improved yolov8. Smart Agric. Technol. 2025, 10, 100785. [Google Scholar] [CrossRef]
- Kim, J.; Suh, Y.; Lee, J.; Chae, H.; Ahn, H.; Chung, Y.; Park, D. EmbeddedPigCount: Pig counting with video object detection and tracking on an embedded board. Sensors 2022, 22, 2689. [Google Scholar] [CrossRef] [PubMed]
- Neyshabur, B.; Bhojanapalli, S.; McAllester, D.; Srebro, N. Exploring generalization in deep learning. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Advances in Neural Information Processing Systems. Volume 30. [Google Scholar]
- Northcutt, C.G.; Athalye, A.; Mueller, J. Pervasive label errors in test sets destabilize machine learning benchmarks. arXiv 2021, arXiv:2103.14749. [Google Scholar]
- Zhan, X.; Wang, Q.; Huang, K.H.; Xiong, H.; Dou, D.; Chan, A.B. A comparative survey of deep active learning. arXiv 2022, arXiv:2203.13450. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Nie, L.; Li, B.; Jiao, F.; Shao, J.; Yang, T.; Liu, Z. ASPP-YOLOv5: A study on constructing pig facial expression recognition for heat stress. Comput. Electron. Agric. 2023, 214, 108346. [Google Scholar]
- Zeng, F.; Li, B.; Wang, H.; Zhu, J.; Jia, N.; Zhao, Y.; Zhao, W. Detection of calf abnormal respiratory behavior based on frame difference and improved YOLOv5 method. Comput. Electron. Agric. 2023, 211, 107987. [Google Scholar]
- Xu, C.; Wang, Z.; Du, R.; Li, Y.; Li, D.; Chen, Y.; Li, W.; Liu, C. A method for detecting uneaten feed based on improved YOLOv5. Comput. Electron. Agric. 2023, 212, 108101. [Google Scholar]
- Shang, Y.; Xu, X.; Jiao, Y.; Wang, Z.; Hua, Z.; Song, H. Using lightweight deep learning algorithm for real-time detection of apple flowers in natural environments. Comput. Electron. Agric. 2023, 207, 107765. [Google Scholar]
- Cacciarelli, D.; Kulahci, M. A survey on online active learning. arXiv 2023, arXiv:2302.08893. [Google Scholar]
- Yu, W.; Zhu, S.; Yang, T.; Chen, C. Consistency-based active learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3951–3960. [Google Scholar]
- Gan, H.; Ou, M.; Li, C.; Wang, X.; Guo, J.; Mao, A.; Ceballos, M.C.; Parsons, T.D.; Liu, K.; Xue, Y. Automated detection and analysis of piglet suckling behaviour using high-accuracy amodal instance segmentation. Comput. Electron. Agric. 2022, 199, 107162. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Precision (Train|Test) | Recall (Train|Test) | Map 0.5 (Train|Test) | Map 0.95 (Train|Test) |
|---|---|---|---|---|
| jj2000 | 0.950|0.487 | 0.926|0.381 | 0.958|0.345 | 0.573|0.146 |
| jj3000 | 0.951|0.474 | 0.929|0.406 | 0.964|0.368 | 0.605|0.164 |
| jj4000 | 0.958|0.519 | 0.949|0.407 | 0.973|0.394 | 0.635|0.184 |
| jj5000 | 0.959|0.489 | 0.941|0.364 | 0.974|0.355 | 0.645|0.158 |
| jj6000 | 0.955|0.539 | 0.945|0.420 | 0.975|0.412 | 0.652|0.196 |
| sq2000 | 0.939|0.761 | 0.891|0.676 | 0.939|0.705 | 0.473|0.296 |
| sq3000 | 0.937|0.805 | 0.911|0.701 | 0.945|0.755 | 0.507|0.343 |
| sq4000 | 0.934|0.861 | 0.917|0.726 | 0.948|0.814 | 0.515|0.404 |
| sq5000 | 0.937|0.855 | 0.933|0.731 | 0.953|0.813 | 0.530|0.411 |
| sq6000 | 0.944|0.869 | 0.923|0.787 | 0.957|0.852 | 0.543|0.444 |
| sy2000 | 0.921|0.754 | 0.862|0.608 | 0.937|0.672 | 0.509|0.339 |
| sy3000 | 0.925|0.771 | 0.884|0.638 | 0.946|0.639 | 0.532|0.334 |
| sy4000 | 0.926|0.755 | 0.892|0.629 | 0.951|0.695 | 0.547|0.365 |
| sy5000 | 0.930|0.789 | 0.900|0.622 | 0.955|0.710 | 0.561|0.377 |
| sy6000 | 0.938|0.778 | 0.895|0.650 | 0.955|0.719 | 0.562|0.379 |
| Dataset | Precision (Train|Test) | Recall (Train|Test) | Map 0.5 (Train|Test) | Map 0.95 (Train|Test) |
|---|---|---|---|---|
| jj2000 | 0.942|0.544 | 0.923|0.394 | 0.955|0.385 | 0.573|0.157 |
| jj3000 | 0.949|0.563 | 0.925|0.418 | 0.960|0.428 | 0.612|0.195 |
| jj4000 | 0.949|0.486 | 0.935|0.390 | 0.968|0.361 | 0.625|0.158 |
| jj5000 | 0.950|0.517 | 0.937|0.373 | 0.969|0.373 | 0.628|0.165 |
| jj6000 | 0.954|0.480 | 0.944|0.416 | 0.973|0.372 | 0.643|0.172 |
| sq2000 | 0.928|0.809 | 0.884|0.707 | 0.929|0.763 | 0.458|0.361 |
| sq3000 | 0.934|0.807 | 0.898|0.716 | 0.941|0.765 | 0.485|0.369 |
| sq4000 | 0.935|0.811 | 0.917|0.726 | 0.945|0.778 | 0.511|0.361 |
| sq5000 | 0.919|0.835 | 0.904|0.744 | 0.934|0.813 | 0.479|0.401 |
| sq6000 | 0.929|0.857 | 0.877|0.726 | 0.933|0.805 | 0.490|0.409 |
| sy2000 | 0.918|0.757 | 0.877|0.585 | 0.934|0.646 | 0.504|0.327 |
| sy3000 | 0.930|0.697 | 0.882|0.577 | 0.944|0.623 | 0.529|0.313 |
| sy4000 | 0.935|0.776 | 0.901|0.614 | 0.954|0.691 | 0.549|0.360 |
| sy5000 | 0.928|0.776 | 0.910|0.636 | 0.951|0.711 | 0.556|0.380 |
| sy6000 | 0.928|0.787 | 0.900|0.615 | 0.950|0.698 | 0.559|0.376 |
| Datasets | Precision (Train|Test) | Recall (Train|Test) | Map 0.5 (Train|Test) | Map 0.95 (Train|Test) |
|---|---|---|---|---|
| sqjj4000 | 0.943|0.811 | 0.915|0.685 | 0.953|0.755 | 0.534|0.382 |
| sqjj6000 | 0.945|0.836 | 0.927|0.758 | 0.956|0.819 | 0.557|0.454 |
| sqjj8000 | 0.940|0.847 | 0.931|0.760 | 0.958|0.827 | 0.562|0.465 |
| sqjj10000 | 0.946|0.872 | 0.936|0.753 | 0.964|0.836 | 0.601|0.475 |
| sqjj12000 | 0.946|0.889 | 0.928|0.792 | 0.965|0.871 | 0.608|0.506 |
| sqsy4000 | 0.931|0.890 | 0.899|0.796 | 0.946|0.871 | 0.513|0.495 |
| sqsy6000 | 0.936|0.899 | 0.911|0.805 | 0.951|0.887 | 0.537|0.518 |
| sqsy8000 | 0.938|0.897 | 0.909|0.824 | 0.953|0.895 | 0.546|0.523 |
| sqsy10000 | 0.933|0.914 | 0.915|0.817 | 0.955|0.890 | 0.549|0.510 |
| sqsy12000 | 0.938|0.909 | 0.916|0.838 | 0.960|0.911 | 0.563|0.529 |
| syjj4000 | 0.938|0.790 | 0.902|0.679 | 0.958|0.747 | 0.552|0.423 |
| syjj6000 | 0.930|0.842 | 0.914|0.687 | 0.959|0.773 | 0.583|0.438 |
| syjj8000 | 0.939|0.849 | 0.916|0.728 | 0.963|0.813 | 0.594|0.461 |
| syjj10000 | 0.939|0.855 | 0.918|0.686 | 0.965|0.797 | 0.618|0.472 |
| syjj12000 | 0.940|0.852 | 0.917|0.717 | 0.966|0.821 | 0.619|0.487 |
| sqsyjj6000 | 0.937|0.872 | 0.916|0.809 | 0.954|0.871 | 0.541|0.523 |
| sqsyjj9000 | 0.933|0.891 | 0.918|0.833 | 0.956|0.897 | 0.561|0.544 |
| sqsyjj12000 | 0.936|0.906 | 0.924|0.829 | 0.958|0.901 | 0.571|0.550 |
| sqsyjj15000 | 0.939|0.914 | 0.919|0.824 | 0.962|0.903 | 0.578|0.558 |
| sqsyjj18000 | 0.941|0.921 | 0.920|0.840 | 0.964|0.919 | 0.604|0.562 |
| Datasets | Precision (Train|Test) | Recall (Train|Test) | Map 0.5 (Train|Test) | Map 0.95 (Train|Test) |
|---|---|---|---|---|
| sqjj4000 | 0.935|0.823 | 0.910|0.728 | 0.944|0.789 | 0.521|0.414 |
| sqjj6000 | 0.942|0.821 | 0.922|0.707 | 0.953|0.771 | 0.549|0.393 |
| sqjj8000 | 0.939|0.869 | 0.928|0.767 | 0.958|0.841 | 0.562|0.464 |
| sqjj10000 | 0.935|0.812 | 0.920|0.721 | 0.955|0.772 | 0.573|0.432 |
| sqjj12000 | 0.937|0.873 | 0.901|0.783 | 0.952|0.859 | 0.582|0.496 |
| sqsy4000 | 0.927|0.876 | 0.896|0.802 | 0.939|0.869 | 0.500|0.493 |
| sqsy6000 | 0.933|0.894 | 0.899|0.808 | 0.948|0.877 | 0.525|0.503 |
| sqsy8000 | 0.939|0.887 | 0.908|0.822 | 0.953|0.893 | 0.543|0.533 |
| sqsy10000 | 0.929|0.885 | 0.908|0.817 | 0.949|0.891 | 0.533|0.530 |
| sqsy12000 | 0.931|0.918 | 0.890|0.820 | 0.948|0.903 | 0.536|0.523 |
| syjj4000 | 0.938|0.782 | 0.895|0.661 | 0.950|0.734 | 0.549|0.411 |
| syjj6000 | 0.933|0.813 | 0.906|0.701 | 0.957|0.772 | 0.576|0.437 |
| syjj8000 | 0.935|0.831 | 0.914|0.720 | 0.959|0.805 | 0.588|0.462 |
| syjj10000 | 0.937|0.840 | 0.916|0.682 | 0.961|0.787 | 0.612|0.466 |
| syjj12000 | 0.940|0.858 | 0.911|0.693 | 0.961|0.801 | 0.613|0.482 |
| sqsyjj6000 | 0.932|0.878 | 0.909|0.801 | 0.947|0.868 | 0.533|0.521 |
| sqsyjj9000 | 0.933|0.877 | 0.912|0.834 | 0.956|0.884 | 0.555|0.545 |
| sqsyjj12000 | 0.934|0.896 | 0.911|0.790 | 0.954|0.877 | 0.566|0.560 |
| sqsyjj15000 | 0.933|0.886 | 0.911|0.804 | 0.956|0.888 | 0.579|0.572 |
| sqsyjj18000 | 0.935|0.921 | 0.901|0.824 | 0.957|0.910 | 0.585|0.582 |
| Datasets | Precision (Train|Test) | Recall (Train|Test) | Map 0.5 (Train|Test) | Map 0.95 (Train|Test) |
|---|---|---|---|---|
| dy5000_91 | 0.967|0.966 | 0.949|0.941 | 0.977|0.977 | 0.689|0.678 |
| dy5000_82 | 0.968|0.963 | 0.952|0.938 | 0.979|0.977 | 0.696|0.678 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Q.; Zheng, F.; Liu, L.; Li, P.; Shen, M. Swift Transfer of Lactating Piglet Detection Model Using Semi-Automatic Annotation Under an Unfamiliar Pig Farming Environment. Agriculture 2025, 15, 696. https://doi.org/10.3390/agriculture15070696
Ding Q, Zheng F, Liu L, Li P, Shen M. Swift Transfer of Lactating Piglet Detection Model Using Semi-Automatic Annotation Under an Unfamiliar Pig Farming Environment. Agriculture. 2025; 15(7):696. https://doi.org/10.3390/agriculture15070696
Chicago/Turabian StyleDing, Qi’an, Fang Zheng, Luo Liu, Peng Li, and Mingxia Shen. 2025. "Swift Transfer of Lactating Piglet Detection Model Using Semi-Automatic Annotation Under an Unfamiliar Pig Farming Environment" Agriculture 15, no. 7: 696. https://doi.org/10.3390/agriculture15070696
APA StyleDing, Q., Zheng, F., Liu, L., Li, P., & Shen, M. (2025). Swift Transfer of Lactating Piglet Detection Model Using Semi-Automatic Annotation Under an Unfamiliar Pig Farming Environment. Agriculture, 15(7), 696. https://doi.org/10.3390/agriculture15070696