
Detection Model for Cotton Picker Fire Recognition Based on Lightweight Improved YOLOv11

Abstract
1. Introduction
- In the backbone module, the MobileNetV2 module is introduced to replace the original backbone blocks, achieving model lightweighting. Compared to the original model, this reduces the parameter count by 0.96 million.
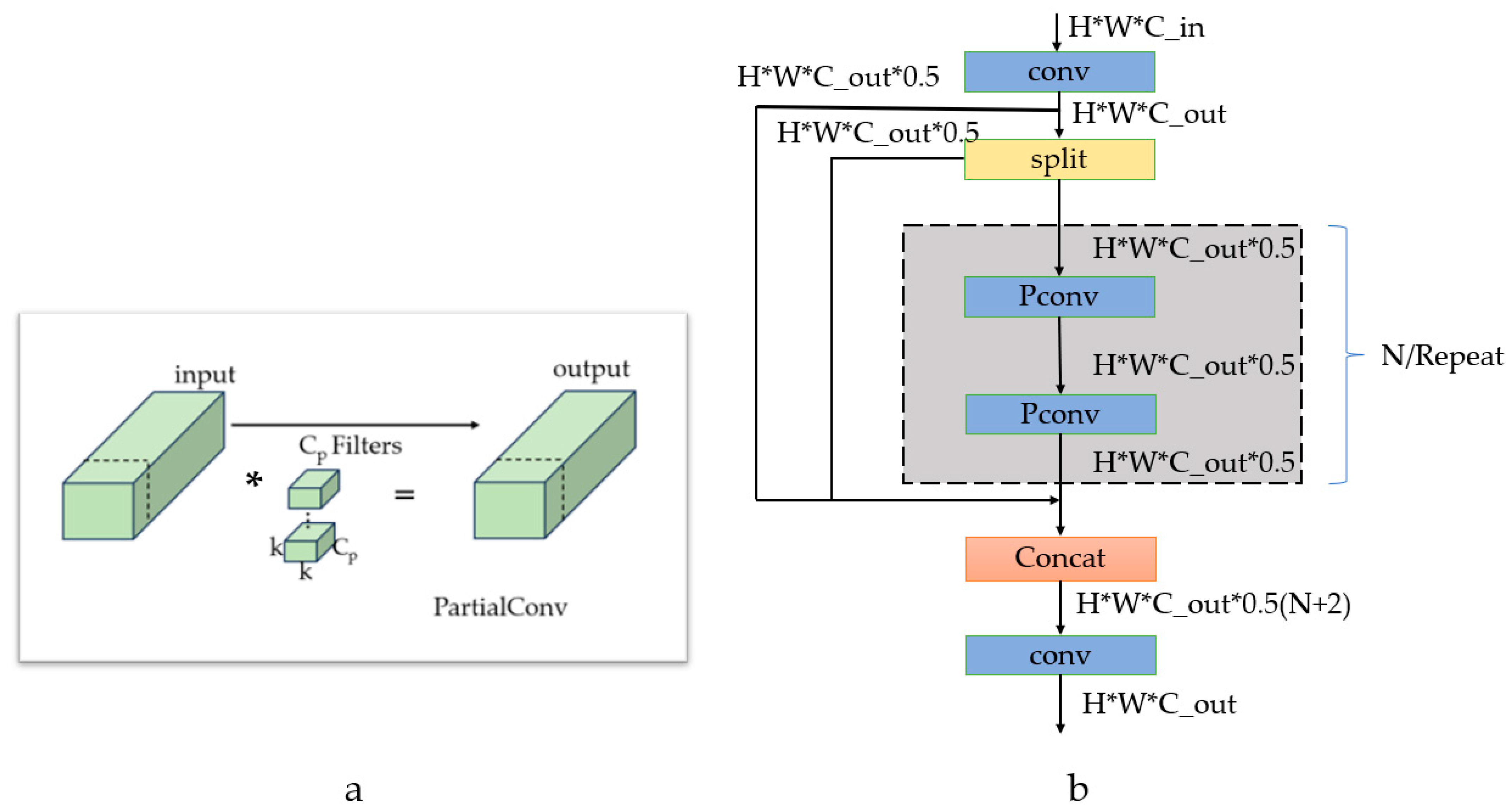
- The original convolutions in the neck module are replaced with partial convolutions (PartialConv) to enhance the model’s feature extraction capabilities. After incorporating these convolutions, the detection accuracy for smoldering and open flames in cotton increases by 1.8% and 1.3%, respectively.
- The integrated CBAM-ECA (Convolutional Block Attention Module-Efficient Channel Attention) mechanism is introduced to enhance the model’s feature extraction capability, improving the model’s accuracy in detecting smoldering and open flames by 1.1% and 1.3%, respectively.
- An improved loss function is adopted to enhance the model’s precise localization of cotton fire situations.
2. Materials and Methods
2.1. Materials
2.2. Methods
2.2.1. Optimized YOLOv11
- Replace the backbone part of the network with MobileNetV2 to reduce the model size, achieving lightweight design while enhancing the model’s feature extraction capability. The improved part is MobileNetV2* in Figure 3.
- Replace the original convolutional modules in the neck section with improved convolutional modules to further reduce the model size while enhancing its feature extraction capabilities. The improved part is c3k2-Pconv* in Figure 3.
- Design a fused attention mechanism, CBAM-ECA, to achieve dual attention mechanisms, where CBAM captures spatial grayscale interference and ECA enhances feature extraction capabilities. The improved part is the CBAM-ECA* in Figure 3.
2.2.2. Position Loss Function
2.2.3. MobileNetV2
2.2.4. Convolution Optimization Section
2.2.5. Design of the CBAM-ECA Attention Mechanism
3. Result
3.1. Evaluation Indicators
3.2. Experimental Results
3.2.1. Experimental Environment Configuration
3.2.2. Comparison of Model Improvement Result
- Experimental results of loss function improvement.
- 2.
- Experimental Results of Replacing the Main Network with MobileNetV2.
- 3.
- Improved experimental results for partial convolution.
- 4.
- Results of comparative experiments with the addition of attention mechanisms.
3.3. Comparative Tests
3.4. Ablation Experiment
3.5. Results of Instance Verification
3.6. Data Visualization Heat Map Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, D.; Liu, H.; Sun, H.J. Forest flame detection with feature constraints and spatial domain frequency domain interaction. J. Saf. Environ. 2025, 1–10. [Google Scholar] [CrossRef]
- Gong, W.; Xiao, D.; He, B. Fire Target Detection Algorithm Based on Improved YOLOv7. J. Combust. Sci. Technol. 2024, 30, 394–402. [Google Scholar]
- Wang, Z.; Zhang, J. Research on improved YOLOv8 lightweight fire detection algorithm based on. Comput. Technol. Dev. 2024, 34, 61–68. [Google Scholar] [CrossRef]
- Deng, L.; Zhou, J.; Liu, Q. Flame and smoke detection algorithm based on improved YOLOv8. J. Tsinghua Univ. Nat. Sci. Ed. 2025, 65, 681–689. [Google Scholar] [CrossRef]
- Guo, J.; Liu, L.; He, J. Fire Detection Algorithm for UAV Aerial Photography Based on Improved YOLOv8. J. For. Eng. 2025, 10, 111–122. [Google Scholar] [CrossRef]
- Chen, K.; Tian, X.; Guan, Y. Smoke and fire detection algorithm for chemical plants based on improved YOLOv8. Control. Eng. 2025, 1–9. [Google Scholar] [CrossRef]
- Yun, B.; Xu, X.; Zeng, J.; Lin, Z.; He, J.; Dai, Q. An Improved Unmanned Aerial Vehicle Forest Fire Detection Model Based on YOLOv8. Fire 2025, 8, 138. [Google Scholar] [CrossRef]
- Li, Y.; Song, X.; Lin, F.; Fang, X. Enhanced flame detection in virtual tunnels using DEV-YOLOv8 and digital twin systems. Simul. Model. Pract. Theory 2025, 143, 103143. [Google Scholar] [CrossRef]
- Li, D.; Yang, T.; Zhou, J.; Wu, S.-q.; Liu, Q.-y. YOLOv8-EMSC: A lightweight fire recognition algorithm for large spaces. J. Saf. Sci. Resil. 2024, 5, 422–431. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, J.; Xu, Y.; Xie, L. Mcan-YOLO: An Improved Forest Fire and Smoke Detection Model Based on YOLOv7. Forests 2024, 15, 1781. [Google Scholar] [CrossRef]
- Shao, D.; Liu, Y.; Liu, G.; Wang, N.; Chen, P.; Yu, J.; Liang, G. YOLOv7scb: A Small-Target Object Detection Method for Fire Smoke Inspection. Fire 2025, 8, 62. [Google Scholar] [CrossRef]
- Alkhammash, E.H. Multi-Classification Using YOLOv11 and Hybrid YOLO11n-MobileNet Models: A Fire Classes Case Study. Fire 2025, 8, 17. [Google Scholar] [CrossRef]
- Huo, Y.; Zhang, Y.; Xu, J.; Dai, X.; Shen, L.; Liu, C.; Fang, X. A Small-Sample Target Detection Method for Transmission Line Hill Fires Based on Meta-Learning YOLOv11. Energies 2025, 18, 1511. [Google Scholar] [CrossRef]
- Han, T.; Yu, S.; Ma, L.; Huang, Y.; Hou, S.; Pang, J. Research on the Detection Model of Foreign Objects and Defects in Photovoltaic Panels Based on Improved YOLOv11n. Comput. Eng. Appl. 2025, 61, 123–134. [Google Scholar] [CrossRef]
- Liu, H.; Huang, Z.; Qiu, B.; Wang, K. Major defect detection method for transmission lines based on improved YOLOv11n. High Volt. Technol. 2025, 1–12. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, H.; Chen, F. Solar cell microdefect detection method based on improved YOLO11. Laser Optoelectron. Prog. 2025, 1–16. Available online: http://kns.cnki.net/kcms/detail/31.1690.tn.20250409.1031.074.html (accessed on 12 April 2025).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Invertedresiduals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Yue, Y.; Zhang, W. Detection and Counting Model of Soybean at the Flowering and Podding Stage in the Field Based on Improved YOLOv5. Agriculture 2025, 15, 528. [Google Scholar] [CrossRef]
- Ye, P.; Zhang, H.; Zhou, X. CNN-CBAM-LSTM: Enhancing Stock Return Prediction Through Long and Short Information Mining in Stock Prediction. Mathematics 2024, 12, 3738. [Google Scholar] [CrossRef]
- Bui, T.D.; Do Le, T.M. Ghost-Attention-YOLOv8: Enhancing Rice Leaf Disease Detection with Lightweight Feature Extraction and Advanced Attention Mechanisms. AgriEngineering 2025, 7, 93. [Google Scholar] [CrossRef]
- Tong, X.; Liang, Z.; Liu, F. Succulent Plant Image Classification Based on Lightweight GoogLeNet with CBAM Attention Mechanism. Appl. Sci. 2025, 15, 3730. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, Y. GCS-YOLO: A Lightweight Detection Algorithm for Grape Leaf Diseases Based on Improved YOLOv8. Appl. Sci. 2025, 15, 3910. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, D.; He, Y.; Zhao, J.; Duan, X.; Zhang, T. Improved YOLO11 Algorithm for Insulator Defect Detection in Power Distribution Lines. Electronics 2025, 14, 1201. [Google Scholar] [CrossRef]
- Chen, K.; Diao, Y.; Wang, Y.; Zhang, X.; Zhou, Y.; Gu, M.; Zhang, B.; Hu, B.; Li, M.; Li, W.; et al. MCT-CNN-LSTM: A Driver Behavior Wireless Perception Method Based on an Improved Multi-Scale Domain-Adversarial Neural Network. Sensors 2025, 25, 2268. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Teng, G. Identification Method of Mature Wheat Varieties Based on Improved DenseNet Model. Agriculture 2025, 15, 736. [Google Scholar] [CrossRef]
- Chen, X.; Wang, S.; Dinavahi, V.; Yang, L.; Wu, D.; Shen, M. Landslide Recognition Based on DeepLabv3+ Framework Fusing ResNet101 and ECA Attention Mechanism. Appl. Sci. 2025, 15, 2613. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Li, Z.; Li, M.; Wu, H.; Jia, Y.; Yang, J.; Bi, S. An Efficient Method for Counting Large-Scale Plantings of Transplanted Crops in UAV Remote Sensing Images. Agriculture 2025, 15, 511. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, C. DAHD-YOLO: A New High Robustness and Real-Time Method for Smoking Detection. Sensors 2025, 25, 1433. [Google Scholar] [CrossRef]
- Gao, X.; Du, J.; Liu, X.; Jia, D.; Wang, J. Object Detection Based on Improved YOLOv10 for Electrical Equipment Image Classification. Processes 2025, 13, 529. [Google Scholar] [CrossRef]
- Sultan, T.; Chowdhury, M.S.; Safran, M.; Mridha, M.F.; Dey, N. Deep Learning-Based Multistage Fire Detection System and Emerging Direction. Fire 2024, 7, 451. [Google Scholar] [CrossRef]
- Gupta, S.; Dubey, A.K.; Singh, R.; Kalra, M.K.; Abraham, A.; Kumari, V.; Laird, J.R.; Al-Maini, M.; Gupta, N.; Singh, I.; et al. Four Transformer-Based Deep Learning Classifiers Embedded with an Attention U-Net-Based Lung Segmenter and Layer-Wise Relevance Propagation-Based Heatmaps for COVID-19 X-ray Scans. Diagnostics 2024, 14, 1534. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Total | Flame | Smoldering |
|---|---|---|---|
| Training set | 3280 | 1980 | 1300 |
| Test set | 410 | 280 | 130 |
| Validation set | 410 | 200 | 210 |
| Number of Layers | Operation | Convolution Kernel | Number of Repetitions | Stride |
|---|---|---|---|---|
| 1 | Conv | 3 × 3 | 1 | 2 |
| 2 | Bottleneck | 3 × 3, 1 × 1 | 1 | 1 |
| 3~4 | Bottleneck | 3 × 3, 1 × 1 | 2 | 2 |
| 5~7 | Bottleneck | 3 × 3, 1 × 1 | 3 | 2 |
| 8~11 | Bottleneck | 3 × 3, 1 × 1 | 4 | 1 |
| 12~14 | Bottleneck | 3 × 3, 1 × 1 | 3 | 2 |
| 15~17 | Bottleneck | 3 × 3, 1 × 1 | 3 | 2 |
| 18 | Bottleneck | 3 × 3, 1 × 1 | 1 | 1 |
| 19 | Conv | 1 × 1 | 1 | 1 |
| 20 | Avgpool | 7 × 7 | 1 | - |
| 21 | Conv | 1 × 1 × k | 1 | - |
| Parameters | Value |
|---|---|
| Lr | 0.01 |
| Epoch | 1000 |
| Iou | 0.7 |
| Momentum | 0.937 |
| Optimizer | SGD |
| Model | Pr | All Pr /% | Recall /% | MAP /% | |
|---|---|---|---|---|---|
| Smoldering/% | Flame/% | ||||
| YOLOv11 | 90.9 | 91.7 | 90.8 | 93.5 | 95.1 |
| +DIoU | 90.9 | 92.6 | 91.3 | 92.2 | 95.2 |
| Model | Pr | All Pr /% | Recall /% | mAP /% | |
|---|---|---|---|---|---|
| Smoldering/% | Flame/% | ||||
| YOLOv11 | 90.9 | 91.7 | 90.8 | 93.5 | 95.1 |
| +MobileNetV2 | 90.6 | 90.0 | 90.4 | 94.3 | 95.0 |
| Model | Pr | All Pr /% | Recall /% | mAP /% | |
|---|---|---|---|---|---|
| Smoldering/% | Flame/% | ||||
| YOLOv11 | 90.9 | 91.7 | 90.8 | 90.6 | 95.1 |
| +Pcov | 91.8 | 93.5 | 92.1 | 91.0 | 97.3 |
| Model | Pr | All Pr /% | Recall /% | mAP /% | |
|---|---|---|---|---|---|
| Smoldering/% | Fire/% | ||||
| Yolov11 | 90.9 | 91.7 | 90.8 | 93.5 | 95.1 |
| +CBAM | 91.4 | 92.7 | 91.6 | 90.5 | 96.6 |
| +ECA | 90.9 | 92.2 | 91.0 | 90.4 | 96.8 |
| +CBAM-ECA | 92.0 | 93.0 | 92.0 | 89.5 | 97.3 |
| Model | Number of Parameters /M | Pr | All Pr /% | Map /% | GFLOPs | Size /MB | FPS | |
|---|---|---|---|---|---|---|---|---|
| Smoldering/% | Flame/% | |||||||
| Yolov3-tiny | 9.5 | 87.2 | 86.3 | 86.8 | 92.2 | 14.3 | 19.2 | 71.4 |
| Yolov5s | 2.2 | 87.4 | 84.1 | 85.7 | 92.6 | 5.8 | 4.7 | 78.5 |
| Yolov8n | 2.7 | 89.8 | 84.6 | 86.8 | 92.8 | 6.9 | 5.7 | 81.3 |
| Reference 4 | 2.8 | 88.0 | 84.2 | 86.1 | 91.4 | 6.3 | 8.1 | 77.1 |
| Yolon10n | 2.7 | 87.6 | 84.3 | 87.4 | 91.3 | 8.2 | 5.9 | 79.3 |
| Yolov11 | 2.6 | 90.9 | 91.7 | 90.8 | 95.1 | 6.3 | 5.5 | 75.5 |
| Reference 11 | 3.9 | 88.5 | 84.5 | 86.6 | 92.3 | 8.5 | 8.3 | 71.4 |
| This algorithm | 1.6 | 92.3 | 94.7 | 92.7 | 97.6 | 3.8 | 3.5 | 85.5 |
| Model | Number of Parameters /M | Pr /% | Map /% | GFLOPs | Size /MB |
|---|---|---|---|---|---|
| Yolov11 | 2.6 | 90.1 | 95.3 | 6.3 | 5.5 |
| This algorithm | 1.6 | 92.3 | 96.3 | 3.8 | 3.5 |
| Number | +DIoU | +Pconv | +MN | +BE | Size/MB | Pr | All Pr | Recall | MAP /% | GFLOPs | Num of Para/M | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Smoldering/% | Fire/% | |||||||||||
| 1 | 5.5 | 90.9 | 91.7 | 90.8 | 93.5 | 95.1 | 6.3 | 2.58 | ||||
| 2 | √ | 5.5 | 90.9 | 92.6 | 91.3 | 92.2 | 95.2 | 6.3 | 2.58 | |||
| 3 | √ | 5.3 | 91.8 | 93.5 | 92.1 | 91.0 | 97.3 | 5.9 | 2.50 | |||
| 4 | √ | 3.6 | 90.6 | 90.0 | 90.8 | 94.3 | 95.0 | 3.9 | 1.62 | |||
| 5 | √ | 5.5 | 92.0 | 93.0 | 92.0 | 89.5 | 97.3 | 6.3 | 2.58 | |||
| 6 | √ | √ | √ | 3.5 | 91.4 | 92.8 | 91.6 | 91.7 | 96.5 | 3.7 | 1.58 | |
| 7 | √ | √ | √ | 4.4 | 92.6 | 95.2 | 93.1 | 90.3 | 97.7 | 5.2 | 2.08 | |
| 8 | √ | √ | √ | √ | 3.5 | 92.3 | 94.7 | 92.7 | 90.6 | 97.6 | 3.8 | 1.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Z.; Wu, F.; Han, C.; Song, D.; Wu, Y. Detection Model for Cotton Picker Fire Recognition Based on Lightweight Improved YOLOv11. Agriculture 2025, 15, 1608. https://doi.org/10.3390/agriculture15151608
Shi Z, Wu F, Han C, Song D, Wu Y. Detection Model for Cotton Picker Fire Recognition Based on Lightweight Improved YOLOv11. Agriculture. 2025; 15(15):1608. https://doi.org/10.3390/agriculture15151608
Chicago/Turabian StyleShi, Zhai, Fangwei Wu, Changjie Han, Dongdong Song, and Yi Wu. 2025. "Detection Model for Cotton Picker Fire Recognition Based on Lightweight Improved YOLOv11" Agriculture 15, no. 15: 1608. https://doi.org/10.3390/agriculture15151608
APA StyleShi, Z., Wu, F., Han, C., Song, D., & Wu, Y. (2025). Detection Model for Cotton Picker Fire Recognition Based on Lightweight Improved YOLOv11. Agriculture, 15(15), 1608. https://doi.org/10.3390/agriculture15151608