

Segmentation and Fractional Coverage Estimation of Soil, Illuminated Vegetation, and Shaded Vegetation in Corn Canopy Images Using CCSNet and UAV Remote Sensing

 ,
,  ,
,  ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
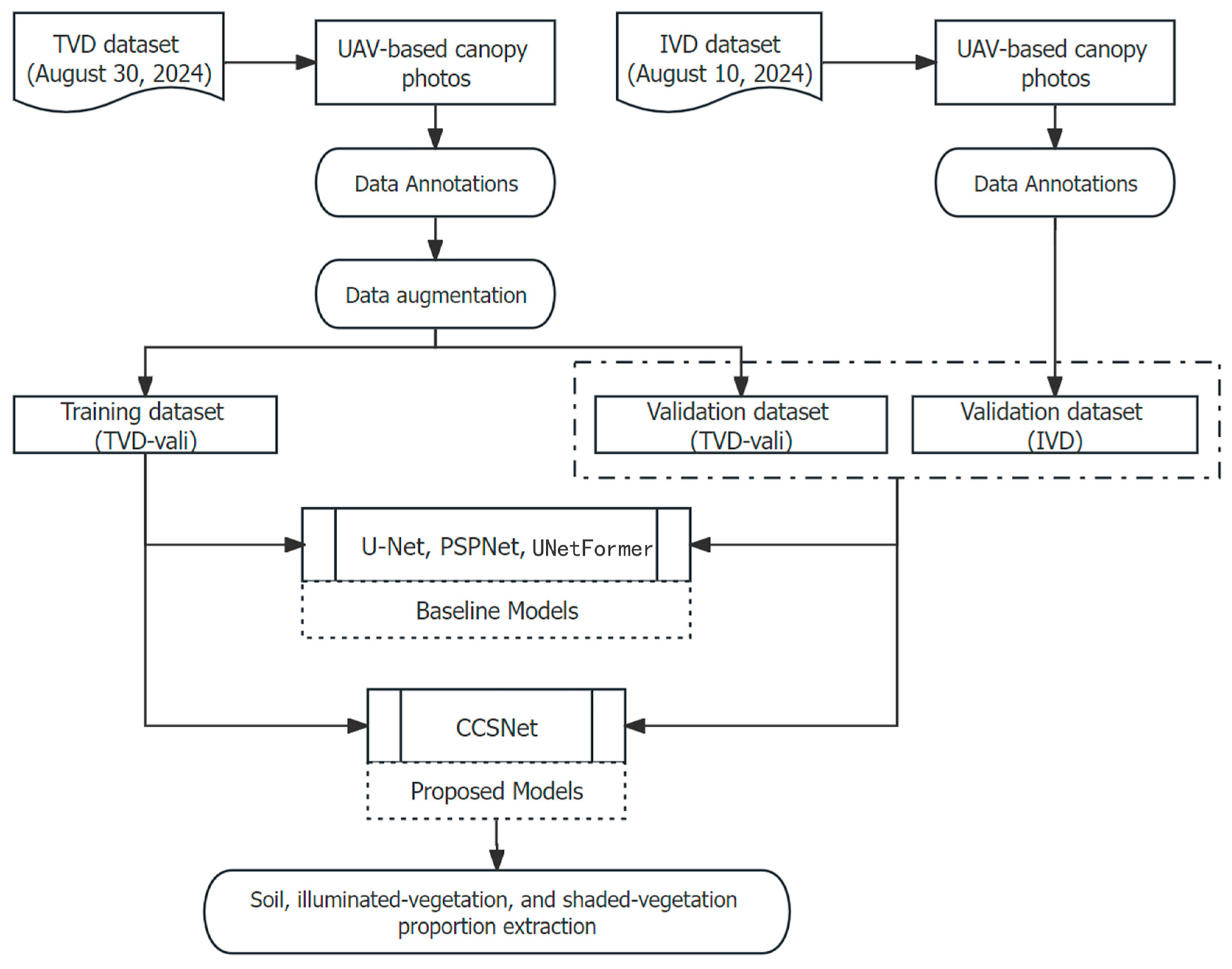
2.1. Study Area and Experimental Design
2.2. Data Annotation and Augmentation
2.3. Methodology Framework
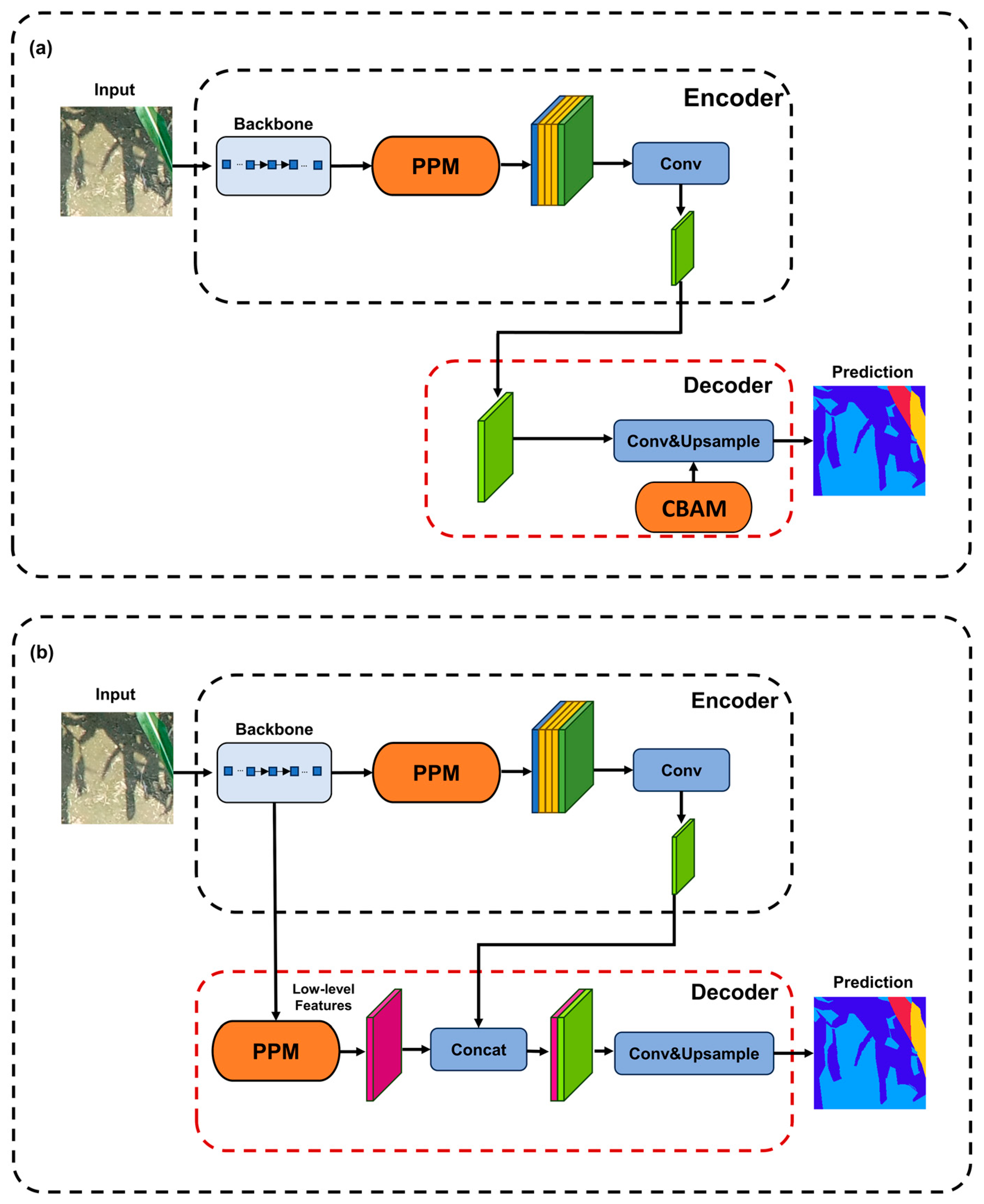
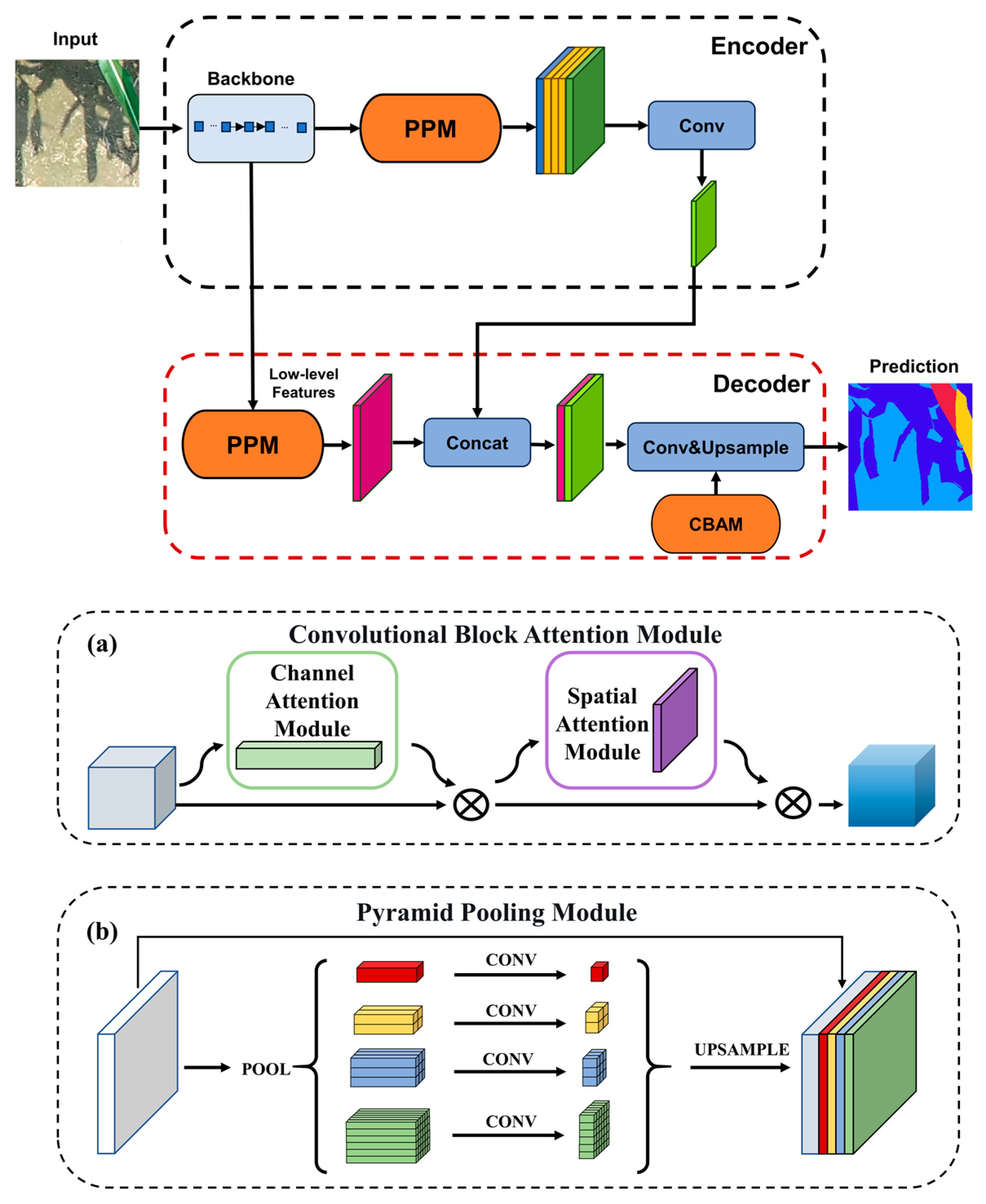
2.4. Proposed CCSNet Segmentation Model
2.5. Benchmark Models: U-Net, PSPNet, and UNetFormer
2.6. Model Parameter Settings and Accuracy Evaluation
3. Results
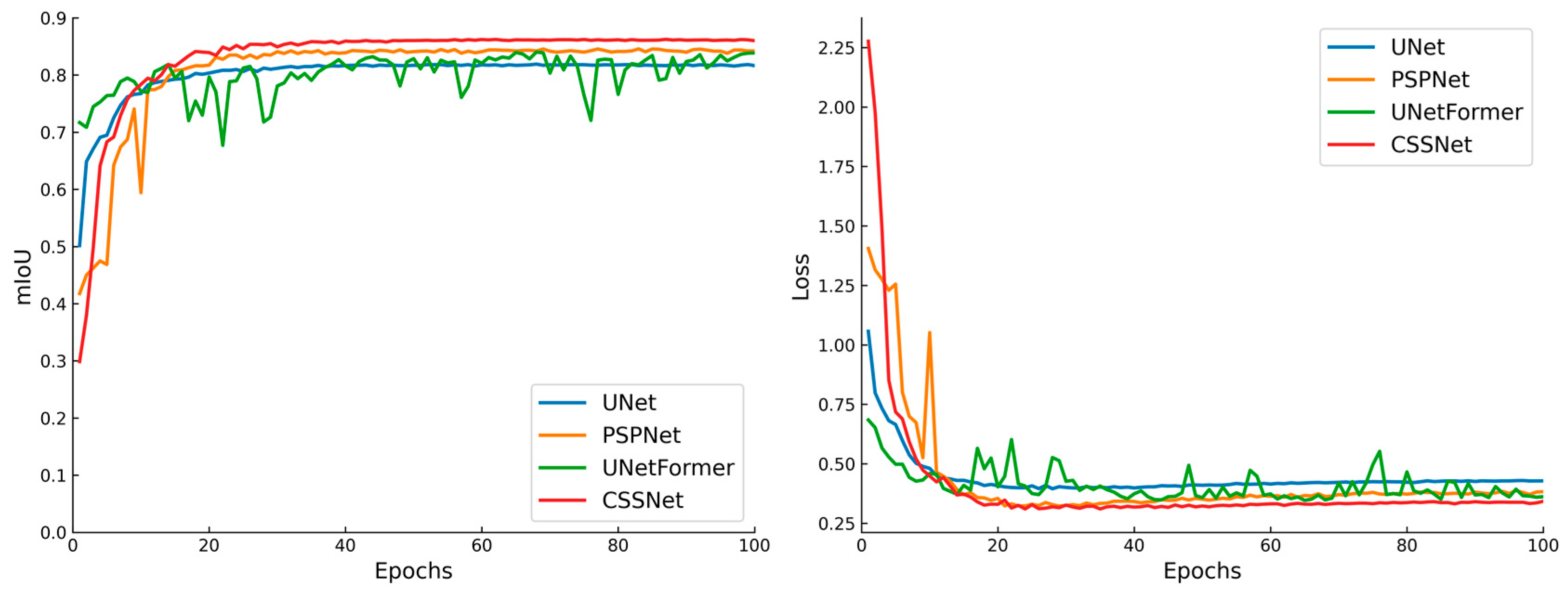
3.1. Model Training and Testing
3.2. Ablation Experiments of CCSNet Based on the TVD-Vali and IVD
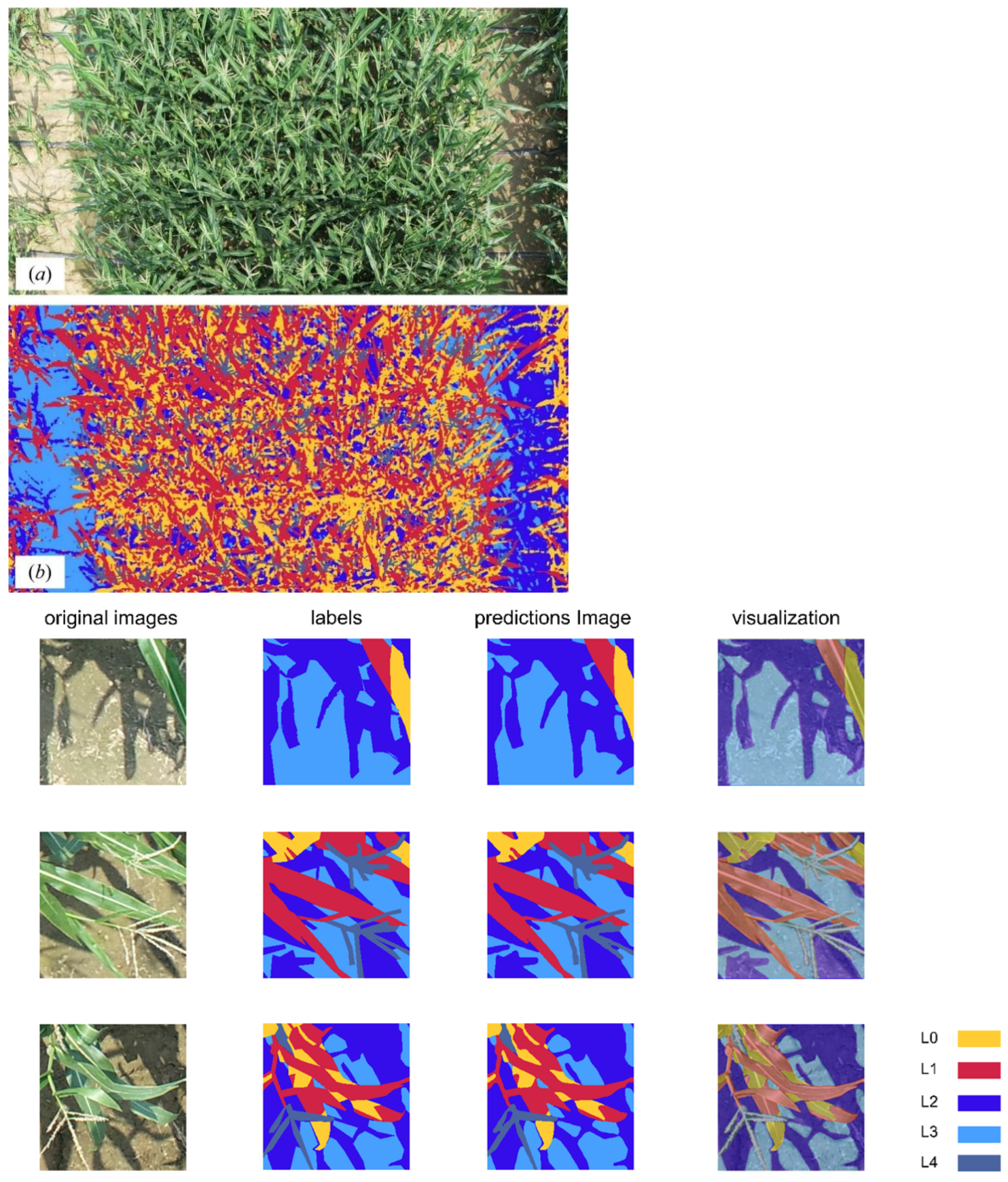
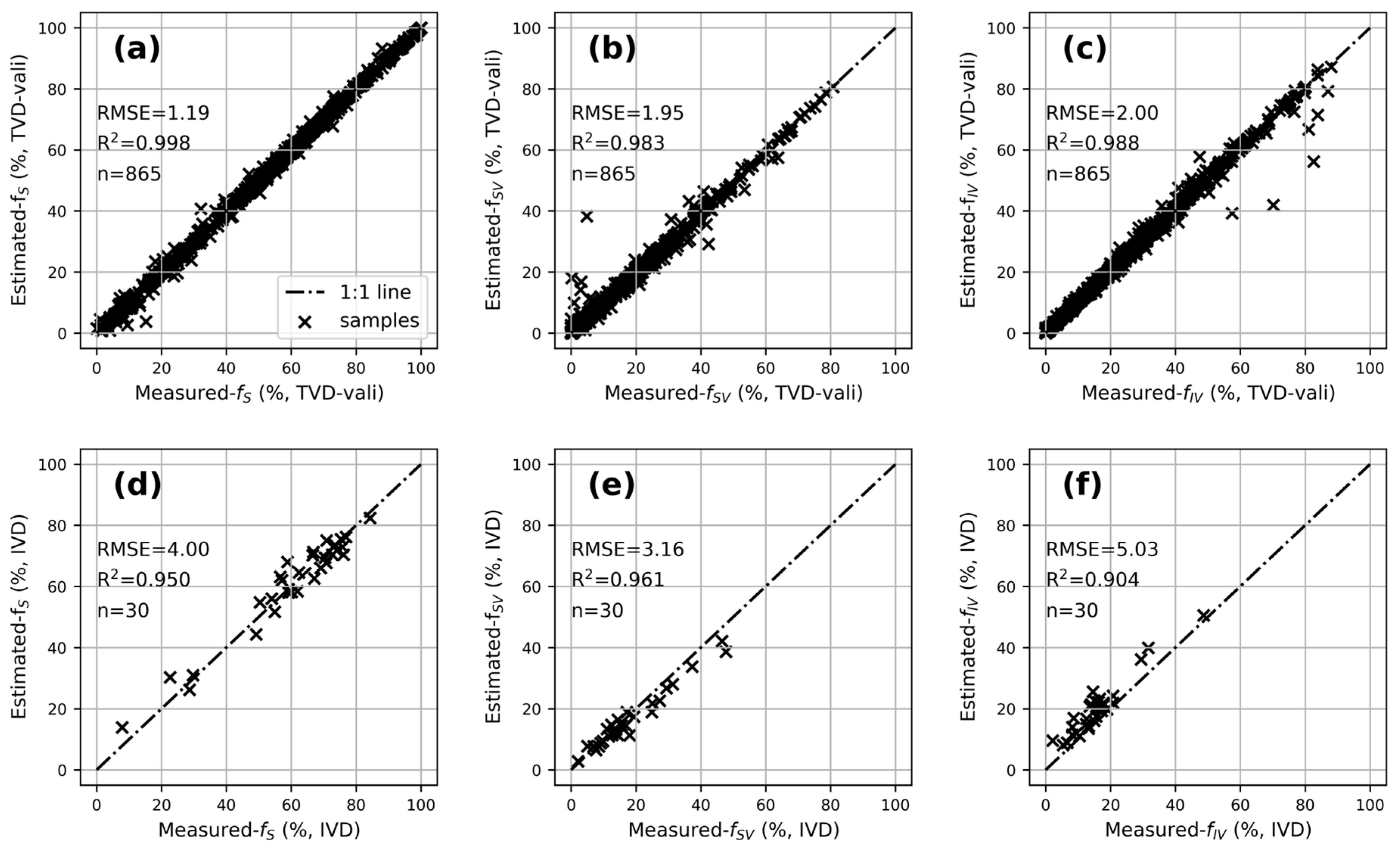
3.3. Segmentation Results and Fractional Coverage Estimation Accuracy Based on CCSNet
4. Discussion
4.1. Advantages of Deep Learning Models in Segmenting and Fractional Coverage Extraction
4.2. Disadvantages of the Proposed Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Foley, D.J.; Thenkabail, P.S.; Aneece, I.P.; Teluguntla, P.G.; Oliphant, A.J. A Meta-Analysis of Global Crop Water Productivity of Three Leading World Crops (Wheat, Corn, and Rice) in the Irrigated Areas over Three Decades. Int. J. Digit. Earth 2020, 13, 939–975. [Google Scholar] [CrossRef]
- Poole, N.; Donovan, J.; Erenstein, O. Viewpoint: Agri-Nutrition Research: Revisiting the Contribution of Maize and Wheat to Human Nutrition and Health. Food Policy 2021, 100, 101976. [Google Scholar] [CrossRef]
- Haque, M.A.; Marwaha, S.; Deb, C.K.; Nigam, S.; Arora, A.; Hooda, K.S.; Soujanya, P.L.; Aggarwal, S.K.; Lall, B.; Kumar, M.; et al. Deep Learning-Based Approach for Identification of Diseases of Maize Crop. Sci. Rep. 2022, 12, 6334. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Li, M.; Liu, J.; Deng, S.; Zhang, Y.; Xia, Y.; Liu, B.; Xu, M. Multi-Omics Analysis Reveals the Pivotal Role of Phytohormone Homeostasis in Regulating Maize Grain Water Content. Crop J. 2024, 12, 1081–1092. [Google Scholar] [CrossRef]
- Dechant, B.; Ryu, Y.; Badgley, G.; Zeng, Y.; Berry, J.A.; Zhang, Y.; Goulas, Y.; Li, Z.; Zhang, Q.; Kang, M.; et al. Canopy Structure Explains the Relationship between Photosynthesis and Sun-Induced Chlorophyll Fluorescence in Crops. Remote Sens. Environ. 2020, 241, 111733. [Google Scholar] [CrossRef]
- Tucker, S.L.; Dohleman, F.G.; Grapov, D.; Flagel, L.; Yang, S.; Wegener, K.M.; Kosola, K.; Swarup, S.; Rapp, R.A.; Bedair, M.; et al. Evaluating Maize Phenotypic Variance, Heritability, and Yield Relationships at Multiple Biological Scales across Agronomically Relevant Environments. Plant Cell Environ. 2020, 43, 880–902. [Google Scholar] [CrossRef]
- Marais-Sicre, C.; Queguiner, S.; Bustillo, V.; Lesage, L.; Barcet, H.; Pelle, N.; Breil, N.; Coudert, B. Sun/Shade Separation in Optical and Thermal UAV Images for Assessing the Impact of Agricultural Practices. Remote Sens. 2024, 16, 1436. [Google Scholar] [CrossRef]
- Castro-Valdecantos, P.; Apolo-Apolo, O.E.; Pérez-Ruiz, M.; Egea, G. Leaf Area Index Estimations by Deep Learning Models Using RGB Images and Data Fusion in Maize. Precis. Agric. 2022, 23, 1949–1966. [Google Scholar] [CrossRef]
- Danilevicz, M.F.; Bayer, P.E.; Boussaid, F.; Bennamoun, M.; Edwards, D. Maize Yield Prediction at an Early Developmental Stage Using Multispectral Images and Genotype Data for Preliminary Hybrid Selection. Remote Sens. 2021, 13, 3976. [Google Scholar] [CrossRef]
- Herrmann, I.; Bdolach, E.; Montekyo, Y.; Rachmilevitch, S.; Townsend, P.A.; Karnieli, A. Assessment of Maize Yield and Phenology by Drone-Mounted Superspectral Camera. Precis. Agric. 2020, 21, 51–76. [Google Scholar] [CrossRef]
- He, H.; Hu, Q.; Li, R.; Pan, X.; Huang, B.; He, Q. Regional Gap in Maize Production, Climate and Resource Utilization in China. Field Crops Res. 2020, 254, 107830. [Google Scholar] [CrossRef]
- Erenstein, O.; Jaleta, M.; Sonder, K.; Mottaleb, K.; Prasanna, B.M. Global Maize Production, Consumption and Trade: Trends and R&D Implications. Food Secur. 2022, 14, 1295–1319. [Google Scholar] [CrossRef]
- Song, Y.; Ma, P.; Gao, J.; Dong, C.; Wang, Z.; Luan, Y.; Chen, J.; Sun, D.; Jing, P.; Zhang, X.; et al. Natural Variation in Maize Gene ZmSBR1 Confers Seedling Resistance to Fusarium Verticillioides. Crop J. 2024, 12, 836–844. [Google Scholar] [CrossRef]
- Yu, F.; Bai, J.; Fang, J.; Guo, S.; Zhu, S.; Xu, T. Integration of a Parameter Combination Discriminator Improves the Accuracy of Chlorophyll Inversion from Spectral Imaging of Rice. Agric. Commun. 2024, 2, 100055. [Google Scholar] [CrossRef]
- Rasti, S.; Bleakley, C.J.; Holden, N.M.; Whetton, R.; Langton, D.; O’Hare, G. A Survey of High Resolution Image Processing Techniques for Cereal Crop Growth Monitoring. Inf. Process. Agric. 2022, 9, 300–315. [Google Scholar] [CrossRef]
- Yu, H.; Liu, J.; Chen, C.; Heidari, A.A.; Zhang, Q.; Chen, H.; Mafarja, M.; Turabieh, H. Corn Leaf Diseases Diagnosis Based on K-Means Clustering and Deep Learning. IEEE Access 2021, 9, 143824–143835. [Google Scholar] [CrossRef]
- Jin, S.; Su, Y.; Gao, S.; Wu, F.; Hu, T.; Liu, J.; Li, W.; Wang, D.; Chen, S.; Jiang, Y.; et al. Deep Learning: Individual Maize Segmentation from Terrestrial Lidar Data Using Faster R-CNN and Regional Growth Algorithms. Front. Plant Sci. 2018, 9, 866. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Shi, Y.; Gao, S.; Jiang, F.; Veeranampalayam-Sivakumar, A.-N.; Thompson, L.; Luck, J.; Liu, C. Improved Crop Row Detection with Deep Neural Network for Early-Season Maize Stand Count in UAV Imagery. Comput. Electron. Agric. 2020, 178, 105766. [Google Scholar] [CrossRef]
- Liu, H.; Sun, H.; Li, M.; Iida, M. Application of Color Featuring and Deep Learning in Maize Plant Detection. Remote Sens. 2020, 12, 2229. [Google Scholar] [CrossRef]
- Sabri, N.; Shafekah Kassim, N.; Ibrahim, S.; Roslan, R.; Mangshor, N.N.A.; Ibrahim, Z. Nutrient Deficiency Detection in Maize (Zea mays L.) Leaves Using Image Processing. IAES Int. J. Artif. Intell. IJ-AI 2020, 9, 304. [Google Scholar] [CrossRef]
- Ao, Z.; Wu, F.; Hu, S.; Sun, Y.; Su, Y.; Guo, Q.; Xin, Q. Automatic Segmentation of Stem and Leaf Components and Individual Maize Plants in Field Terrestrial LiDAR Data Using Convolutional Neural Networks. Crop J. 2022, 10, 1239–1250. [Google Scholar] [CrossRef]
- Zhou, J.; Wu, Y.; Chen, J.; Cui, M.; Gao, Y.; Meng, K.; Wu, M.; Guo, X.; Wen, W. Maize Stem Contour Extraction and Diameter Measurement Based on Adaptive Threshold Segmentation in Field Conditions. Agriculture 2023, 13, 678. [Google Scholar] [CrossRef]
- Xu, X.; Xu, S.; Jin, L.; Song, E. Characteristic Analysis of Otsu Threshold and Its Applications. Pattern Recognit. Lett. 2011, 32, 956–961. [Google Scholar] [CrossRef]
- Miao, Y.; Li, S.; Wang, L.; Li, H.; Qiu, R.; Zhang, M. A Single Plant Segmentation Method of Maize Point Cloud Based on Euclidean Clustering and K-Means Clustering. Comput. Electron. Agric. 2023, 210, 107951. [Google Scholar] [CrossRef]
- Mouret, F.; Albughdadi, M.; Duthoit, S.; Kouamé, D.; Rieu, G.; Tourneret, J.-Y. Reconstruction of Sentinel-2 Derived Time Series Using Robust Gaussian Mixture Models—Application to the Detection of Anomalous Crop Development. Comput. Electron. Agric. 2022, 198, 106983. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Gao, G.; Zhang, S.; Shen, J.; Hu, K.; Tian, J.; Yao, Y.; Tian, Q.; Fu, Y.; Feng, H.; Liu, Y.; et al. Segmentation and Proportion Extraction of Crop, Crop Residues, and Soil Using Digital Images and Deep Learning. Agriculture 2024, 14, 2240. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef]
- Mavridou, E.; Vrochidou, E.; Papakostas, G.A.; Pachidis, T.; Kaburlasos, V.G. Machine Vision Systems in Precision Agriculture for Crop Farming. J. Imaging 2019, 5, 89. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.-Y.; Kong, J.-L.; Jin, X.-B.; Wang, X.-Y.; Su, T.-L.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Qian, X.; Zhang, C.; Chen, L.; Li, K. Deep Learning-Based Identification of Maize Leaf Diseases Is Improved by an Attention Mechanism: Self-Attention. Front. Plant Sci. 2022, 13, 864486. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Jogin, M.; Mohana; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature Extraction Using Convolution Neural Networks (CNN) and Deep Learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar]
- Yue, J.; Yang, H.; Feng, H.; Han, S.; Zhou, C.; Fu, Y.; Guo, W.; Ma, X.; Qiao, H.; Yang, G. Hyperspectral-to-Image Transform and CNN Transfer Learning Enhancing Soybean LCC Estimation. Comput. Electron. Agric. 2023, 211, 108011. [Google Scholar] [CrossRef]
- Wei, J.; Wang, Q.; Li, Z.; Wang, S.; Zhou, S.K.; Cui, S. Shallow Feature Matters for Weakly Supervised Object Localization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5989–5997. [Google Scholar]
- Hu, J.; Feng, H.; Wang, Q.; Shen, J.; Wang, J.; Liu, Y.; Feng, H.; Yang, H.; Guo, W.; Qiao, H.; et al. Pretrained Deep Learning Networks and Multispectral Imagery Enhance Maize LCC, FVC, and Maturity Estimation. Remote Sens. 2024, 16, 784. [Google Scholar] [CrossRef]
- Shen, J.; Wang, Q.; Zhao, M.; Hu, J.; Wang, J.; Shu, M.; Liu, Y.; Guo, W.; Qiao, H.; Niu, Q.; et al. Mapping Maize Planting Densities Using Unmanned Aerial Vehicles, Multispectral Remote Sensing, and Deep Learning Technology. Drones 2024, 8, 140. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Cloud/Shadow Detection Based on Spectral Indices for Multi/Hyperspectral Optical Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 235–253. [Google Scholar] [CrossRef]
- You, D.; Wang, S.; Wang, F.; Zhou, Y.; Wang, Z.; Wang, J.; Xiong, Y. EfficientUNet+: A Building Extraction Method for Emergency Shelters Based on Deep Learning. Remote Sens. 2022, 14, 2207. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Khan, F.A.; Asif, M. Comparison of Deep-Learning-Based Segmentation Models: Using Top View Person Images. IEEE Access 2020, 8, 136361–136373. [Google Scholar] [CrossRef]
- Emam, Z.; Kondrich, A.; Harrison, S.; Lau, F.; Wang, Y.; Kim, A.; Branson, E. On The State of Data In Computer Vision: Human Annotations Remain Indispensable for Developing Deep Learning Models. arXiv 2021, arXiv:2108.00114. [Google Scholar]
- Yue, J.; Li, T.; Feng, H.; Fu, Y.; Liu, Y.; Tian, J.; Yang, H.; Yang, G. Enhancing Field Soil Moisture Content Monitoring Using Laboratory-Based Soil Spectral Measurements and Radiative Transfer Models. Agric. Commun. 2024, 2, 100060. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, P.; Zhang, H.; Dai, J.; Yi, Y.; Zhang, H.; Zhang, Y. Deep Learning on Computational-Resource-Limited Platforms: A Survey. Mob. Inf. Syst. 2020, 2020, 8454327:1–8454327:19. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 2019, 51, 93. [Google Scholar] [CrossRef]
- Yue, J.; Tian, J.; Xu, N.; Tian, Q. Vegetation-Shadow Indices Based on Differences in Effect of Atmospheric-Path Radiation between Optical Bands. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102579. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Predicting Targets | Description | |
|---|---|---|---|
| Segmentation and Importance | Fractional Coverage | ||
| L0 | Shaded vegetation (high) | Shaded vegetation Illuminated vegetation | Corn leaves not exposed to sunlight. |
| L1 | Illuminated vegetation (high) | Corn leaves exposed to sunlight. | |
| L2 | Shaded soil (low) | Soil | Soil not exposed to sunlight. |
| L3 | Illuminated soil (low) | Soil exposed to sunlight. | |
| L4 | Tassel (low) | - | Corn tassel. |
| Model | U-Net | PSPNet | UNetFormer | CCSNet | |||||
|---|---|---|---|---|---|---|---|---|---|
| Backbone | MobilieNetV2 | ResNet50 | MobilieNetV2 | ResNet50 | MobilieNetV2 | ResNet50 | MobileNetV2 | ResNet50 | |
| Recall | L0 | 84.64 ± 0.96% | 86.74 ± 0.78% | 85.32 ± 0.69% | 90.27 ± 0.94% | 85.12 ± 0.95% | 89.56 ± 0.90% | 89.14 ± 0.86% | 89.46 ± 0.72% |
| L1 | 88.15 ± 0.67% | 91.25 ± 0.68% | 89.04 ± 1.02% | 93.75 ± 0.78% | 89.25 ± 0.76% | 92.67 ± 0.80% | 91.78 ± 0.65% | 94.49 ± 0.79% | |
| L2 | 90.41 ± 0.78% | 92.56 ± 0.83% | 91.67 ± 0.79% | 94.13 ± 0.83% | 90.36 ± 0.54% | 93.23 ± 0.54% | 91.46 ± 0.54% | 93.92 ± 0.54% | |
| L3 | 93.62 ± 0.56% | 93.94 ± 0.92% | 93.21 ± 0.84% | 95.12 ± 0.75% | 93.73 ± 0.81% | 94.56 ± 0.73% | 92.94 ± 0.74% | 94.84 ± 0.86% | |
| L4 | 78.43 ± 1.24% | 83.46 ± 0.75% | 78.70 ± 0.76% | 87.23 ± 0.68% | 72.62 ± 0.80% | 88.75 ± 0.65% | 84.75 ± 0.63% | 88.75 ± 0.65% | |
| PA | 89.32 ± 0.43% | 91.03 ± 0.67% | 88.32 ± 0.57% | 92.75 ± 0.97% | 89.31 ± 0.79% | 92.23 ± 0.82% | 91.34 ± 0.75% | 93.58 ± 0.76% * | |
| mIoU | 78.53 ± 0.43% | 81.42 ± 0.42% | 77.23 ± 0.83% | 84.27 ± 0.57% | 76.32 ± 0.75% | 84.32 ± 0.55% | 80.81 ± 0.89% | 86.42 ± 0.78% * | |
| Model | U-Net | PSPNet | UNetFormer | CCSNet | |||||
|---|---|---|---|---|---|---|---|---|---|
| Backbone | MobilieNetV2 | ResNet50 | MobilieNetV2 | ResNet50 | MobilieNetV2 | ResNet50 | MobileNetV2 | ResNet50 | |
| Recall | L0 | 75.43 ± 0.76% | 78.71 ± 0.45% | 71.26 ± 0.78% | 76.30 ± 0.76% | 73.48 ± 0.92% | 77.75 ± 0.86% | 75.21 ± 0.67% | 75.54 ± 0.67% |
| L1 | 82.53 ± 0.75% | 85.04 ± 0.97% | 82.73 ± 0.56% | 87.37 ± 0.57% | 86.46 ± 0.78% | 87.83 ± 0.79% | 86.70 ± 0.43% | 89.87 ± 0.82% | |
| L2 | 86.50 ± 0.84% | 86.78 ± 0.42% | 86.63 ± 0.73% | 88.84 ± 0.98% | 87.36 ± 0.49% | 88.98 ± 0.65% | 85.72 ± 0.92% | 88.43 ± 0.83% | |
| L3 | 69.13 ± 0.82% | 88.97 ± 0.65% | 85.84 ± 0.89% | 88.50 ± 0.75% | 56.79 ± 0.63% | 75.12 ± 0.89% | 87.66 ± 0.42% | 88.40 ± 0.56% | |
| L4 | 45.90 ± 1.50% | 62.34 ± 0.31% | 48.16 ± 0.90% | 59.52 ± 1.45% | 34.58 ± 0.86% | 69.12 ± 0.96% | 47.87 ± 0.92% | 68.26 ± 1.76% | |
| PA | 80.43 ± 0.97% | 85.12 ± 0.79% | 81.51 ± 0.76% | 85.87 ± 0.81% | 77.37 ± 0.65% | 82.57 ± 0.65% | 82.32 ± 0.74% | 85.97 ± 0.79% * | |
| mIoU | 59.43 ± 0.87% | 68.77 ± 0.52% | 61.73 ± 0.72% | 68.92 ± 0.99% | 54.43 ± 0.78% | 65.49 ± 0.73% | 63.56 ± 0.80% | 70.45 ± 0.54% * | |
| Type | Exp. 1 | Exp. 2 | Exp. 3 | ||||
|---|---|---|---|---|---|---|---|
| Label | TVD-vali | IVD | TVD-vali | IVD | TVD-vali | IVD | |
| Recall | L0 | 89.46% | 75.54% | 87.59% | 75.75% | 90.7% | 78.39% |
| L1 | 94.49% | 89.87% | 93.8% | 88.77% | 93.13% | 88.06% | |
| L2 | 93.92% | 88.40% | 92.54% | 85.53% | 93.98% | 87.86% | |
| L3 | 94.84% | 88.40% | 95.3% | 84.96% | 95.49% | 89.08% | |
| L4 | 88.75% | 68.26% | 83.64 | 50.23% | 88.03% | 49.95% | |
| PA | 93.58% * | 85.97% ** | 92.21% | 82.88% | 93.25% | 85.06% | |
| mIoU | 86.42% * | 70.45% ** | 83.83% | 64.6% | 84.51% | 67.51% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Yue, J.; Wang, X.; Feng, H.; Liu, Y.; Shu, M. Segmentation and Fractional Coverage Estimation of Soil, Illuminated Vegetation, and Shaded Vegetation in Corn Canopy Images Using CCSNet and UAV Remote Sensing. Agriculture 2025, 15, 1309. https://doi.org/10.3390/agriculture15121309
Zhang S, Yue J, Wang X, Feng H, Liu Y, Shu M. Segmentation and Fractional Coverage Estimation of Soil, Illuminated Vegetation, and Shaded Vegetation in Corn Canopy Images Using CCSNet and UAV Remote Sensing. Agriculture. 2025; 15(12):1309. https://doi.org/10.3390/agriculture15121309
Chicago/Turabian StyleZhang, Shanxin, Jibo Yue, Xiaoyan Wang, Haikuan Feng, Yang Liu, and Meiyan Shu. 2025. "Segmentation and Fractional Coverage Estimation of Soil, Illuminated Vegetation, and Shaded Vegetation in Corn Canopy Images Using CCSNet and UAV Remote Sensing" Agriculture 15, no. 12: 1309. https://doi.org/10.3390/agriculture15121309
APA StyleZhang, S., Yue, J., Wang, X., Feng, H., Liu, Y., & Shu, M. (2025). Segmentation and Fractional Coverage Estimation of Soil, Illuminated Vegetation, and Shaded Vegetation in Corn Canopy Images Using CCSNet and UAV Remote Sensing. Agriculture, 15(12), 1309. https://doi.org/10.3390/agriculture15121309