
MAMNet: Lightweight Multi-Attention Collaborative Network for Fine-Grained Cropland Extraction from Gaofen-2 Remote Sensing Imagery



Abstract
:1. Introduction
2. Description of the Study Area and Data Sources
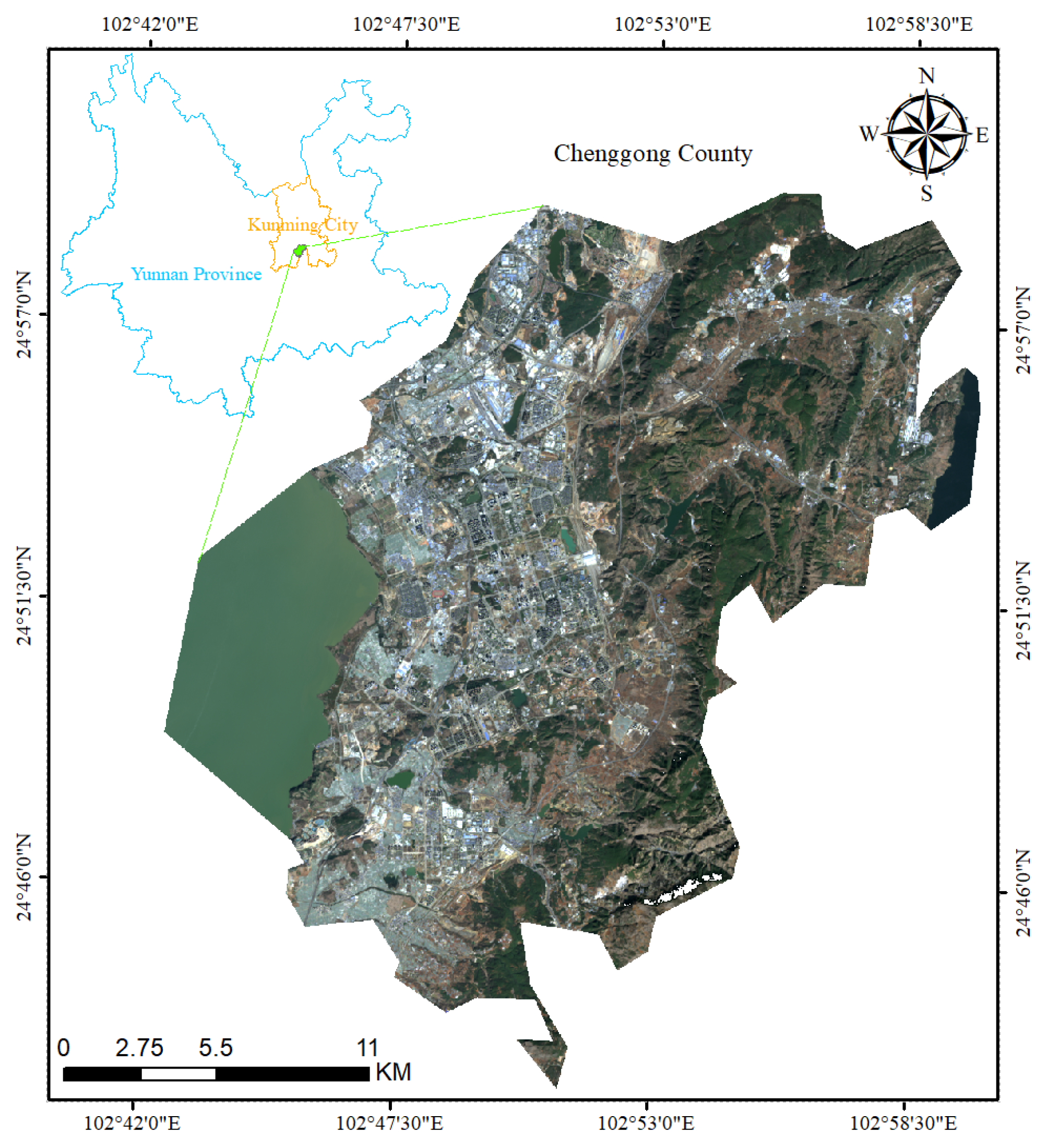
2.1. Description of the Study Area
2.2. Test Data
3. Research Methodology
3.1. MAMNet Network Architecture
3.2. Attention Mechanism Module
3.2.1. Detail Improvement Module

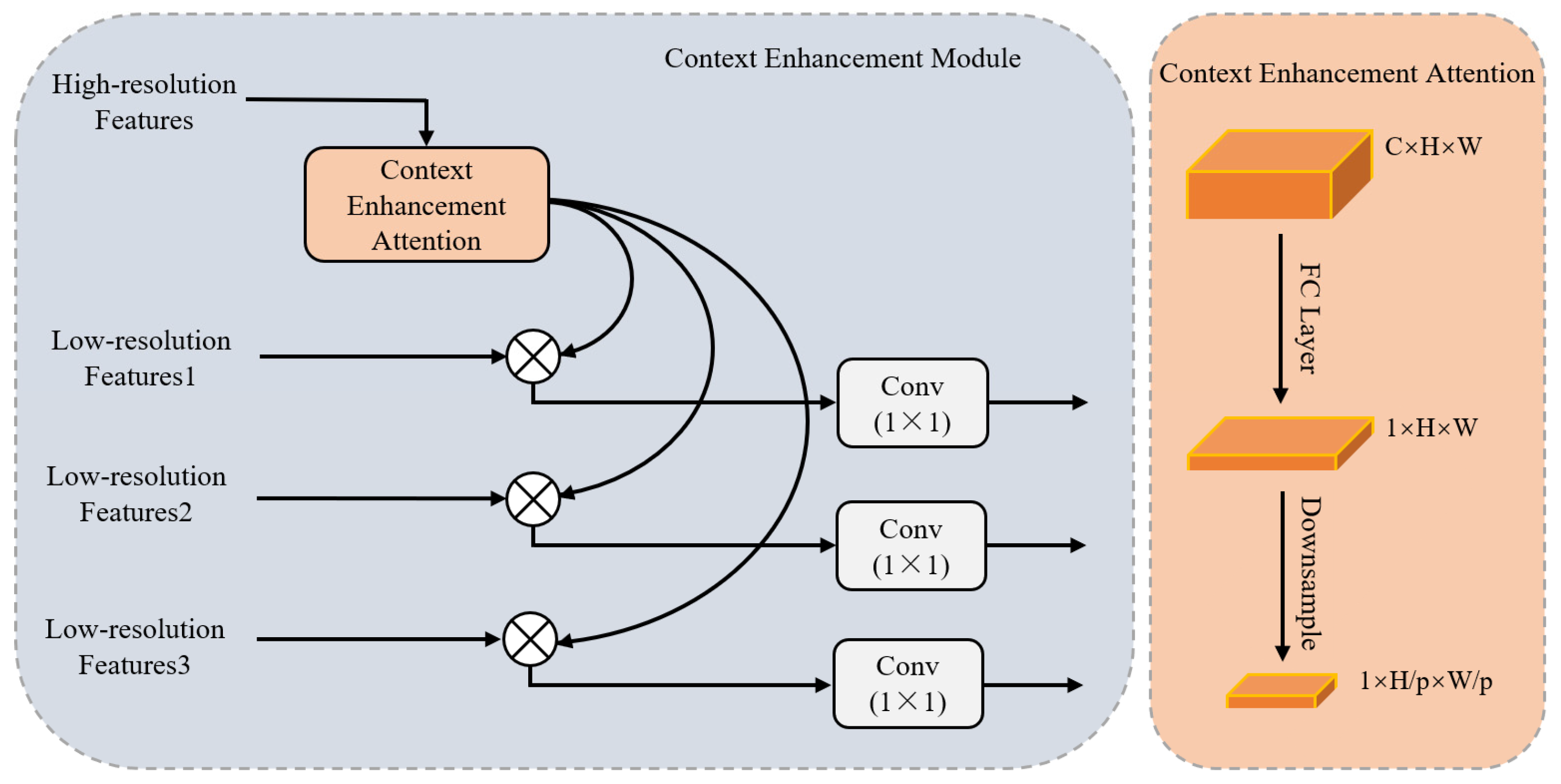
3.2.2. Contextual Information Enhancement Module
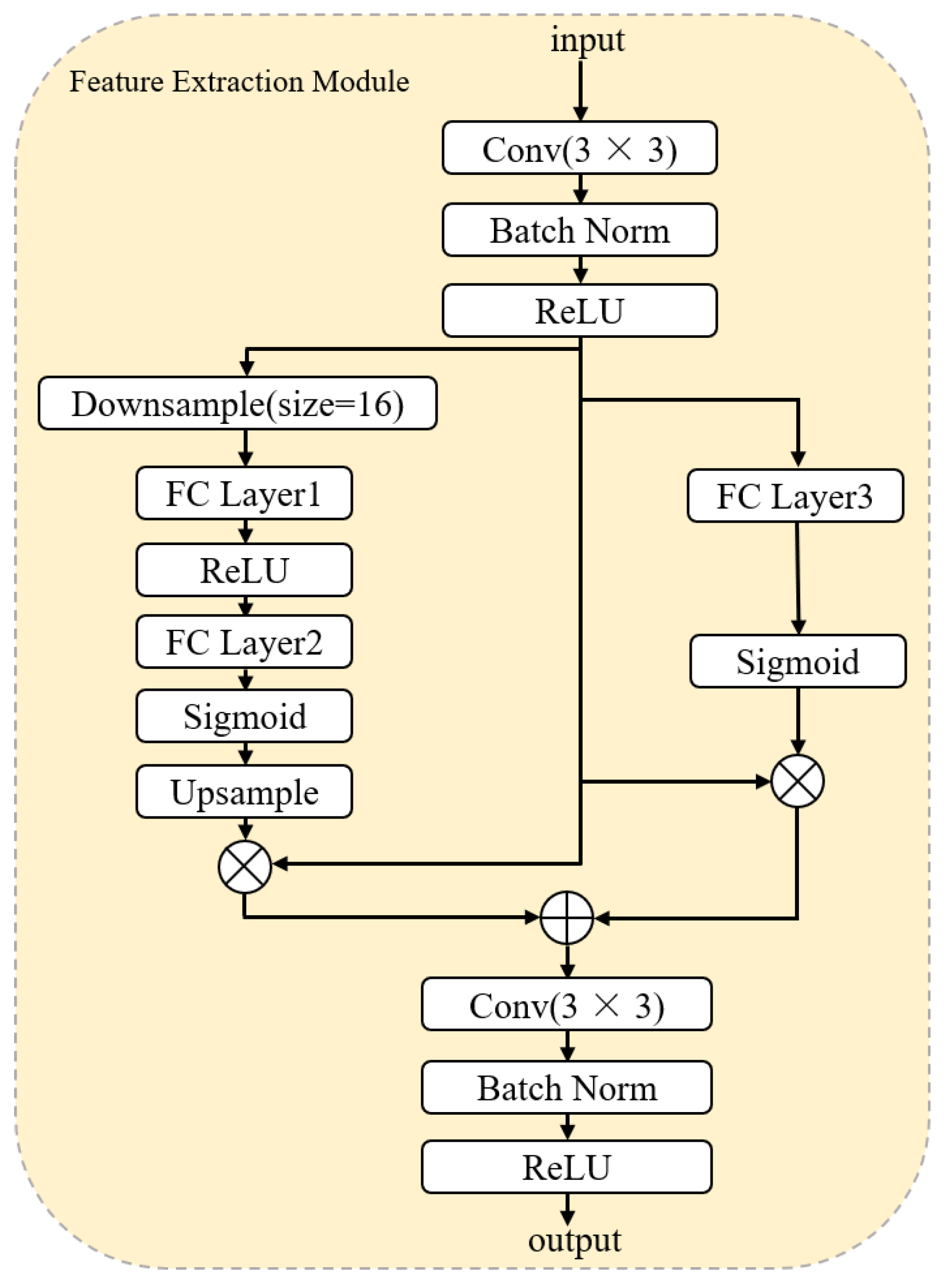
3.2.3. Feature Extraction Module
3.2.4. Feature Reconstruction Head
3.3. Loss Function
3.4. Test Environment and Parameter Setting
3.5. Evaluation Indicators
4. Result
4.1. Test Results and Analysis
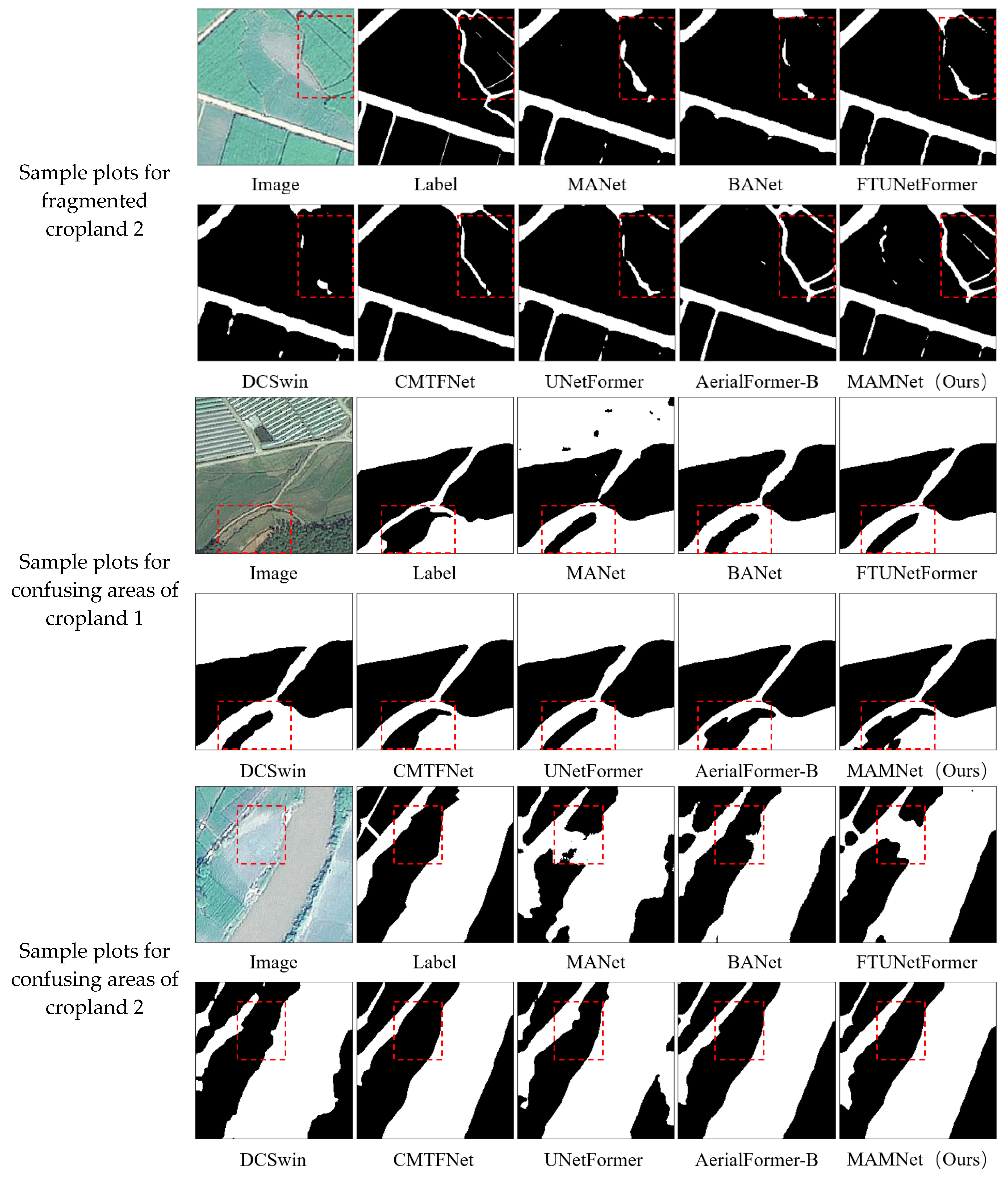
4.1.1. Comparative Test Results and Analysis
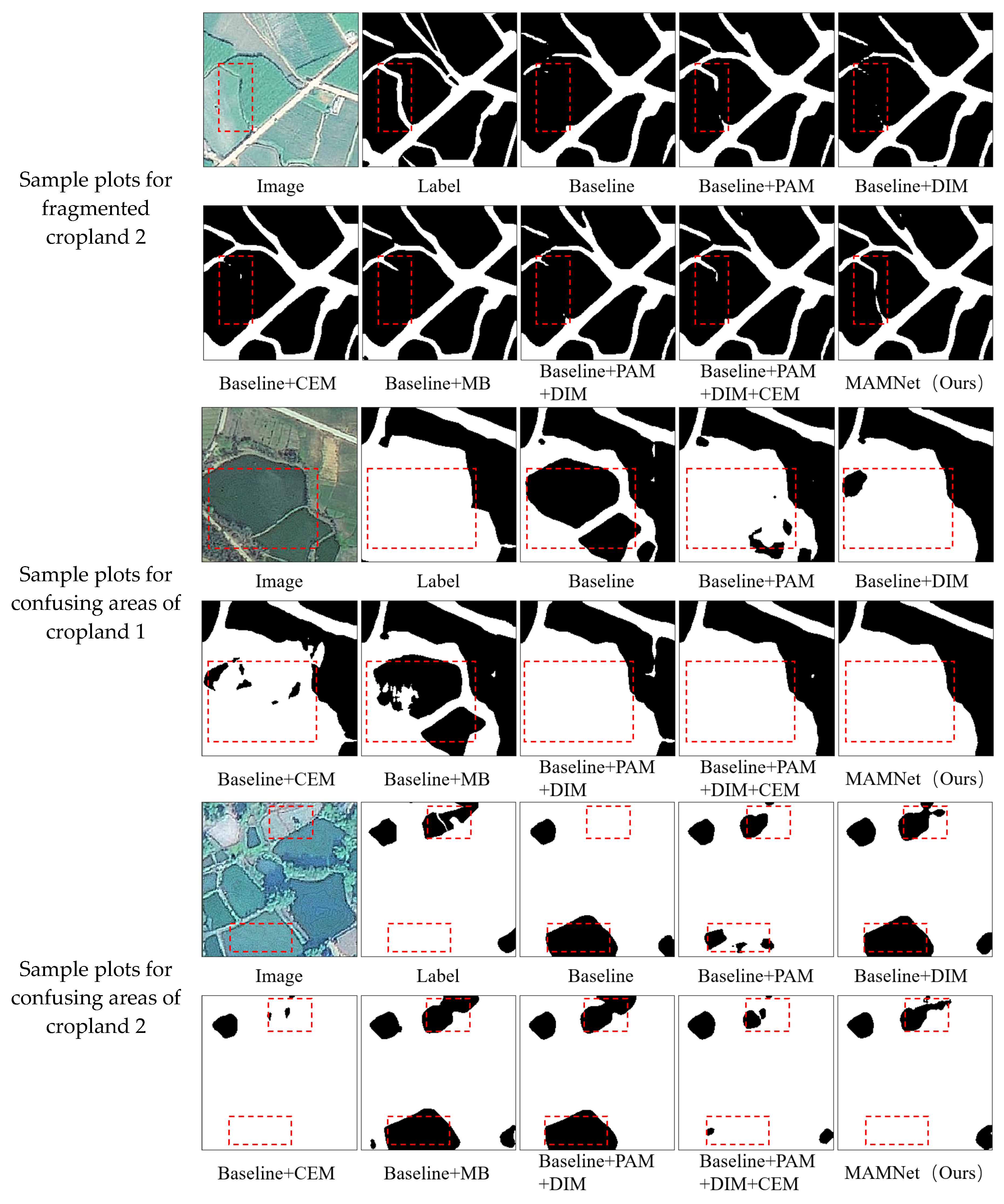
4.1.2. Ablation Test Results and Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Xie, D.; Xu, H.; Xiong, X.; Liu, M.; Hu, H.; Xiong, M.; Liu, L. Cropland Extraction in Southern China from Very High-Resolution Images Based on Deep Learning. Remote Sens. 2023, 15, 2231. [Google Scholar] [CrossRef]
- Li, S.; Li, X. Global understanding of farmland abandonment: A review and prospects. J. Geogr. Sci. 2017, 27, 1123–1150. [Google Scholar] [CrossRef]
- Persello, C.; Tolpekin, V.A.; Bergado, J.R.; de By, R.A. Delineation of agricultural fields in smallholder farms from satellite images using fully convolutional networks and combinatorial grouping. Remote Sens. Environ. 2019, 231, 111253. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, S.; Lizaga, I.; Zhang, Y.; Ge, X.; Zhang, Z.; Zhang, W.; Huang, Q.; Hu, Z. UAS-based remote sensing for agricultural Monitoring: Current status and perspectives. Comput. Electron. Agric. 2024, 227, 109501. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, X.; Wang, L.; Jin, Z. A lightweight convolution neural network based on joint features for Remote Sensing scene image classification. Int. J. Remote Sens. 2023, 44, 6615–6641. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.B.T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Qi, W.; Wei, M.; Yang, W.; Xu, C.; Ma, C. Automatic Mapping of Landslides by the ResU-Net. Remote Sens. 2020, 12, 2487. [Google Scholar] [CrossRef]
- Liu, G.; Bai, L.; Zhao, M.; Zang, H.; Zheng, G. Segmentation of wheat farmland with improved U-Net on drone images. J. Appl. Remote Sens. 2022, 16, 034511. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xu, H.; Song, J.; Zhu, Y. Evaluation and Comparison of Semantic Segmentation Networks for Rice Identification Based on Sentinel-2 Imagery. Remote Sens. 2023, 15, 1499. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Guo, H.; Wei, Y. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Zhong, B.; Wei, T.; Luo, X.; Du, B.; Hu, L.; Ao, K.; Yang, A.; Wu, J. Multi-Swin Mask Transformer for Instance Segmentation of Agricultural Field Extraction. Remote Sens. 2023, 15, 549. [Google Scholar] [CrossRef]
- Xie, W.; Zhao, M.; Liu, Y.; Yang, D.; Huang, K.; Fan, C.; Wang, Z. Recent advances in Transformer technology for agriculture: A comprehensive survey. Eng. Appl. Artif. Intell. 2024, 138, 109412. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, T.; Huang, Y.; Shi, F. An Edge-Aware Multitask Network Based on CNN and Transformer Backbone for Farmland Instance Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 13765–13779. [Google Scholar] [CrossRef]
- Dheeraj, A.; Chand, S. Deep learning based weed classification in corn using improved attention mechanism empowered by Explainable AI techniques. Crop Prot. 2025, 190, 107058. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Con-ference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Miao, L.; Li, X.; Zhou, X.; Yao, L.; Deng, Y.; Hang, T.; Zhou, Y.; Yang, H. SNUNet3+: A Full-Scale Connected Siamese Network and a Dataset for Cultivated Land Change Detection in High-Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4400818. [Google Scholar] [CrossRef]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel squeeze & excitation in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]
- Li, H.; Lin, H.; Luo, J.; Wang, T.; Chen, H.; Xu, Q.; Zhang, X. Fine-Grained Abandoned Cropland Mapping in Southern China Using Pixel Attention Contrastive Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2283–2295. [Google Scholar] [CrossRef]
- Xiao, J.; Zhang, D.; Li, J.; Liu, J. A study on the classification of complexly shaped cultivated land considering multi-scale features and edge priors. Environ. Monit. Assess. 2024, 196, 816. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607713. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Hanyu, T.; Yamazaki, K.; Tran, M.; McCann, R.A.; Liao, H.; Rainwater, C.; Adkins, M.; Cothren, J.; Le, N. AerialFormer: Multi-Resolution Transformer for Aerial Image Segmentation. Remote Sens. 2024, 16, 2930. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and Multiscale Transformer Fusion Network for Remote-Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Płotka, S.; Chrabaszcz, M.; Biecek, P. Swin SMT: Global Sequential Modeling for Enhancing 3D Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI, Marrakesh, Morocco, 6–10 October 2024; pp. 689–698. [Google Scholar]
- Li, Z.; Shen, H.; Weng, Q.; Zhang, Y.; Dou, P.; Zhang, L. Cloud and cloud shadow detection for optical satellite imagery: Features, algorithms, validation, and prospects. ISPRS J. Photogramm. Remote Sens. 2022, 188, 89–108. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU (%) | mIoU (%) | F1 (%) | OA (%) |
|---|---|---|---|---|
| MANet | 81.15 | 83.65 | 91.07 | 90.40 |
| BANet | 80.72 | 82.08 | 90.16 | 89.76 |
| DCSwin | 80.29 | 81.89 | 90.04 | 89.58 |
| UNetFormer | 81.50 | 83.78 | 91.17 | 90.54 |
| FTUNetFormer | 81.21 | 83.27 | 90.87 | 90.29 |
| AerialFormer-B | 84.41 | 86.20 | 92.58 | 92.65 |
| CMTFNet | 82.87 | 84.49 | 91.59 | 91.14 |
| MAMNet | 84.17 | 86.68 | 92.86 | 92.20 |
| Method | Backbone | Parameters (M) | Complexity (G) | Memory (MB) | Speed (Number of Samples/Second) | mIoU (%) |
|---|---|---|---|---|---|---|
| MANet | ResNet50 | 35.9 | 14.88 | 572.25 | 27.44 | 83.65 |
| BANet | Rest-Lite | 12.7 | 2.49 | 212.25 | 39.67 | 82.08 |
| DCSwin | Swin-small | 66.9 | 8.61 | 1058.25 | 21.37 | 81.89 |
| UNetFormer | ResNet18 | 11.7 | 2.25 | 197.92 | 46.59 | 83.78 |
| FTUNetFormer | Swin-base | 96.0 | 23.10 | 1503.68 | 12.71 | 83.27 |
| AerialFormer-B | Swin-base | 114.0 | 33.04 | 1587.43 | 10.54 | 86.20 |
| CMTFNet | ResNet50 | 30.1 | 6.66 | 486.66 | 29.02 | 84.49 |
| MAMNet | ResNet18 | 12.0 | 3.64 | 202.54 | 41.52 | 86.68 |
| Mould | Module | mIoU (%) | F1 (%) | OA (%) | Parameter (M) | Memory (MB) | |||
|---|---|---|---|---|---|---|---|---|---|
| PAM | DIM | CEM | MB | ||||||
| Baseline | 83.78 | 91.17 | 90.54 | 11.7 | 197.92 | ||||
| Baseline + PAM | √ | 85.40 | 92.13 | 91.55 | 11.8 | 199.21 | |||
| Baseline + DIM | √ | 84.62 | 91.67 | 91.12 | 11.8 | 198.39 | |||
| Baseline + CEM | √ | 84.90 | 91.84 | 91.01 | 11.7 | 196.69 | |||
| Backline + MB | √ | 85.37 | 92.11 | 91.64 | 11.9 | 201.94 | |||
| Baseline + PAM + DIM | √ | √ | 85.50 | 92.18 | 91.60 | 11.8 | 199.09 | ||
| Baseline + PAM + DIM + CEM | √ | √ | √ | 85.84 | 92.38 | 91.83 | 11.8 | 200.39 | |
| MAMNet | √ | √ | √ | √ | 86.68 | 92.86 | 92.20 | 12.0 | 202.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Ding, X.; Wang, J.; Pan, J. MAMNet: Lightweight Multi-Attention Collaborative Network for Fine-Grained Cropland Extraction from Gaofen-2 Remote Sensing Imagery. Agriculture 2025, 15, 1152. https://doi.org/10.3390/agriculture15111152
Wu J, Ding X, Wang J, Pan J. MAMNet: Lightweight Multi-Attention Collaborative Network for Fine-Grained Cropland Extraction from Gaofen-2 Remote Sensing Imagery. Agriculture. 2025; 15(11):1152. https://doi.org/10.3390/agriculture15111152
Chicago/Turabian StyleWu, Jiayong, Xue Ding, Jinliang Wang, and Jiya Pan. 2025. "MAMNet: Lightweight Multi-Attention Collaborative Network for Fine-Grained Cropland Extraction from Gaofen-2 Remote Sensing Imagery" Agriculture 15, no. 11: 1152. https://doi.org/10.3390/agriculture15111152
APA StyleWu, J., Ding, X., Wang, J., & Pan, J. (2025). MAMNet: Lightweight Multi-Attention Collaborative Network for Fine-Grained Cropland Extraction from Gaofen-2 Remote Sensing Imagery. Agriculture, 15(11), 1152. https://doi.org/10.3390/agriculture15111152