A Comparative Analysis of Machine Learning and Pedotransfer Functions Under Varying Data Availability in Two Greek Regions

 ,
, 
 and
and
Abstract
1. Introduction
2. Materials and Methods
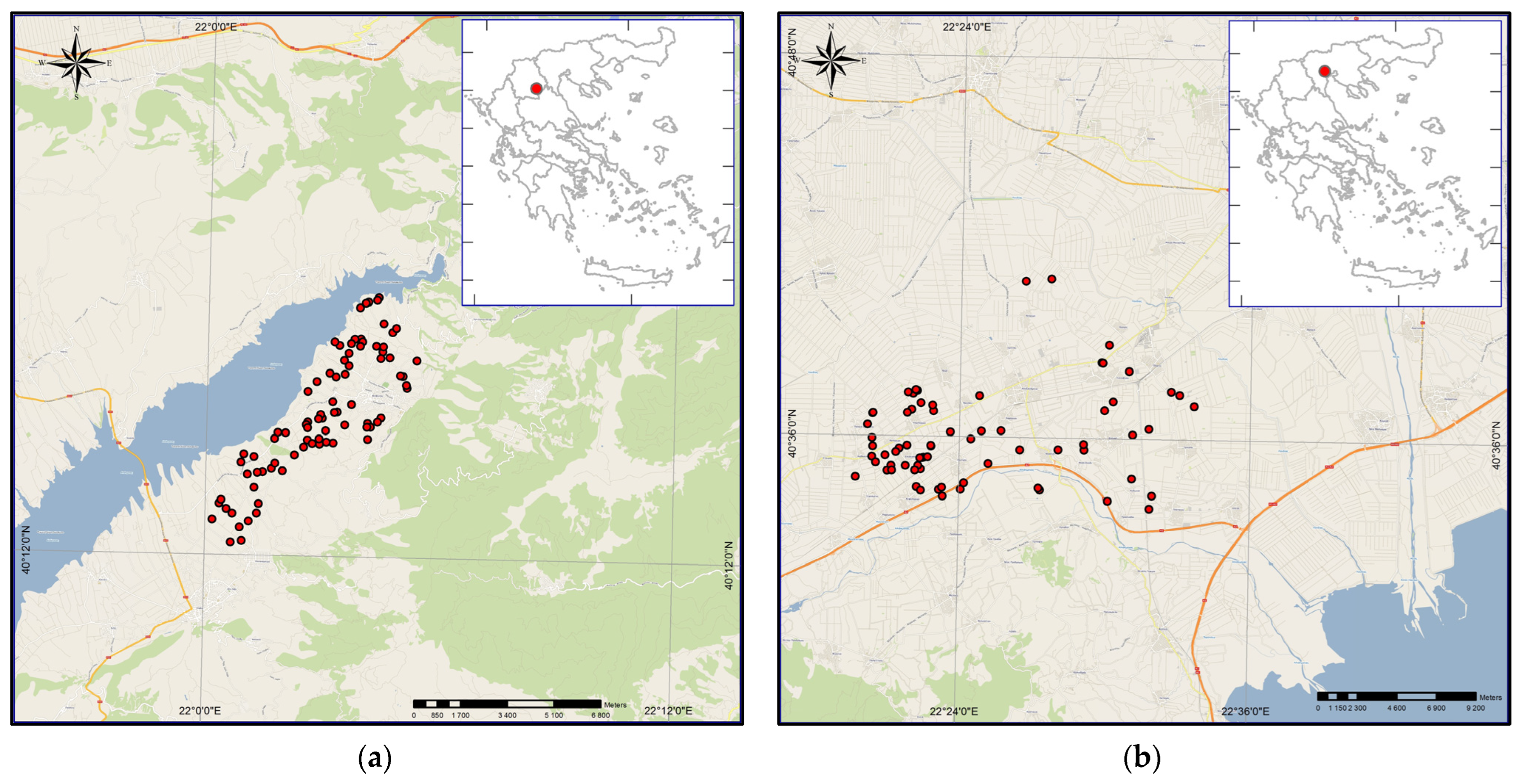
2.1. Study Area
2.2. Soil Sampling and Soil Data Covariates
2.3. ML Methods and Pedotransfer Functions
2.4. Error Assessment Indices
2.5. Software
3. Results
3.1. Descriptive Statistics
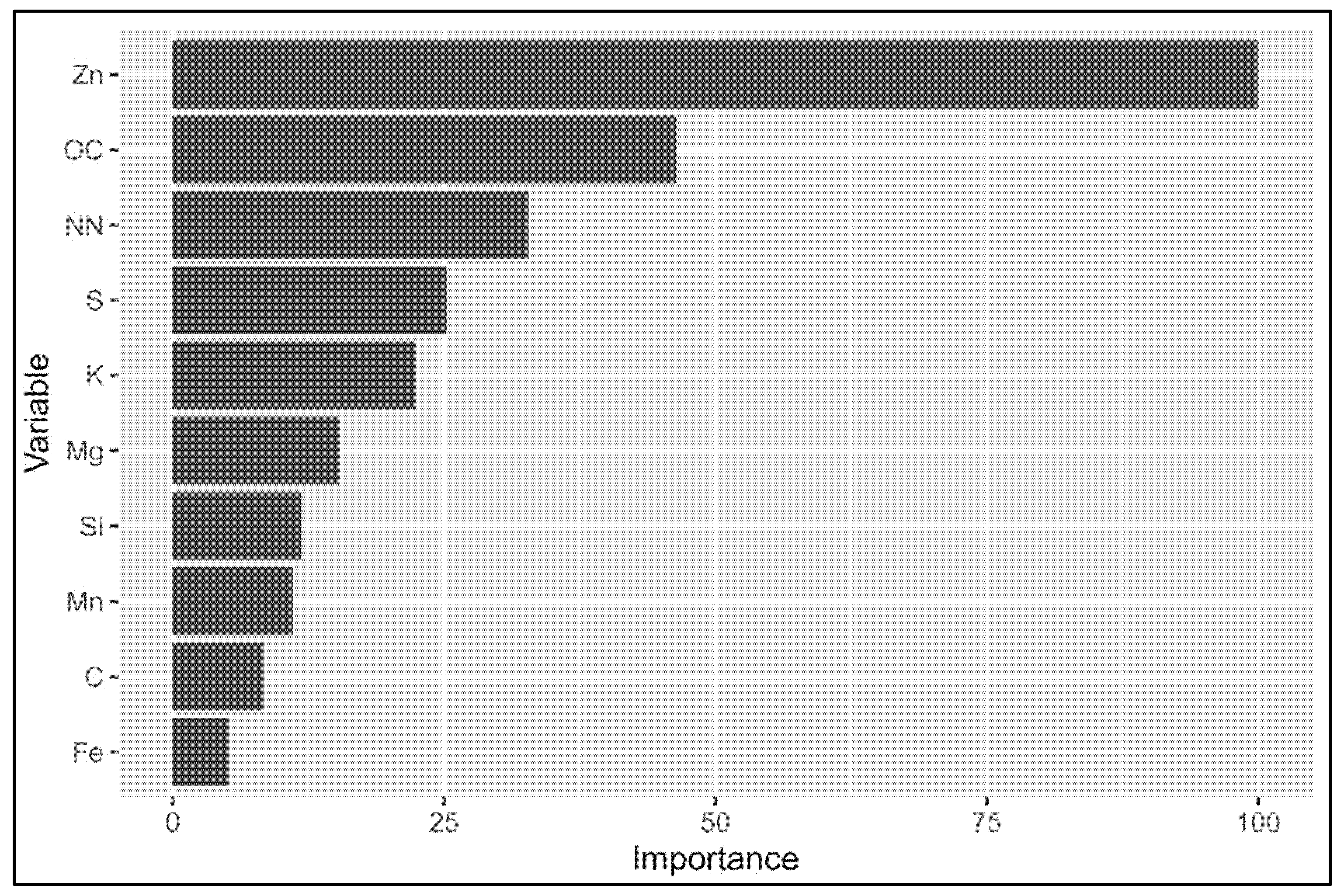
3.2. Prediction Results
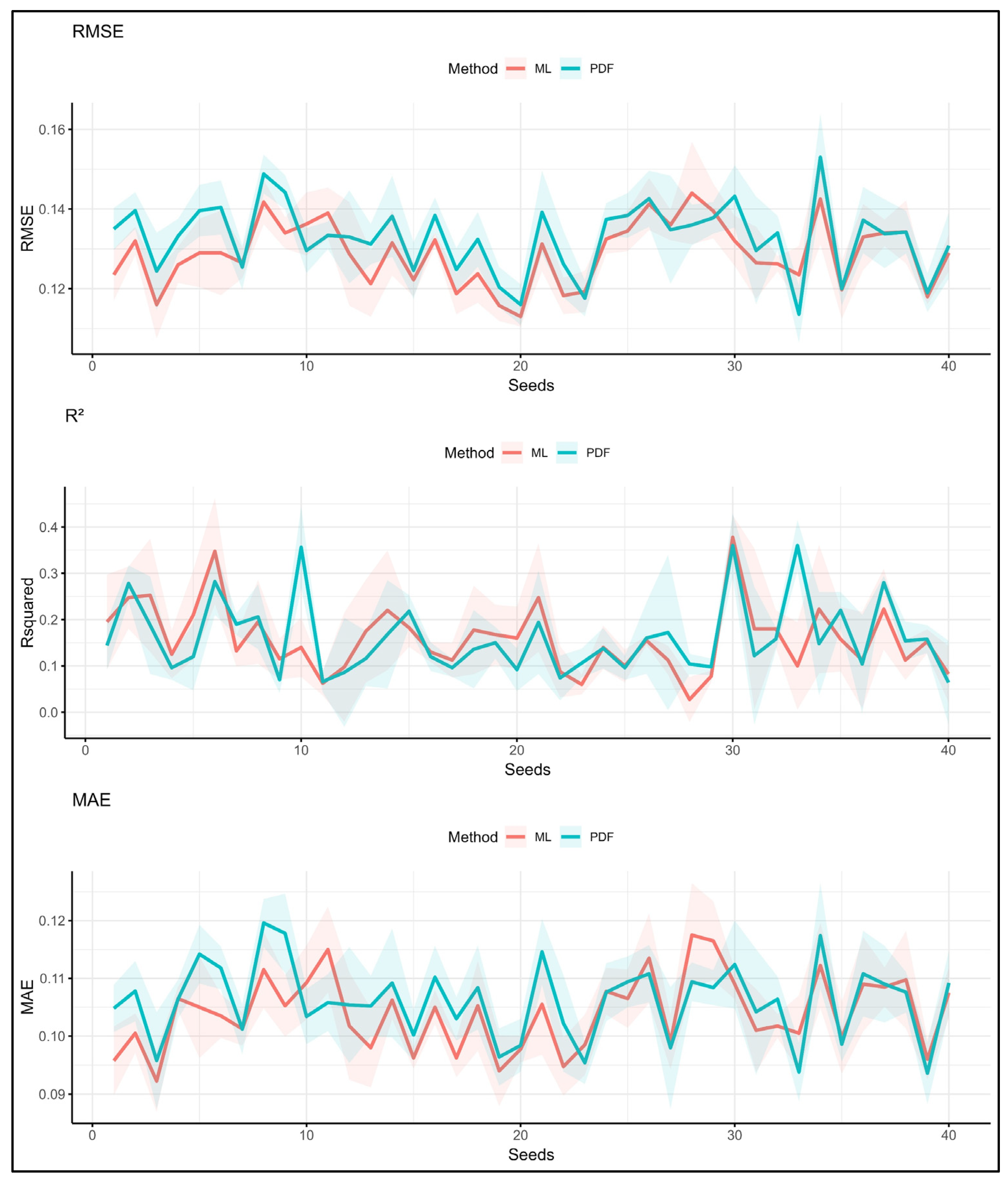
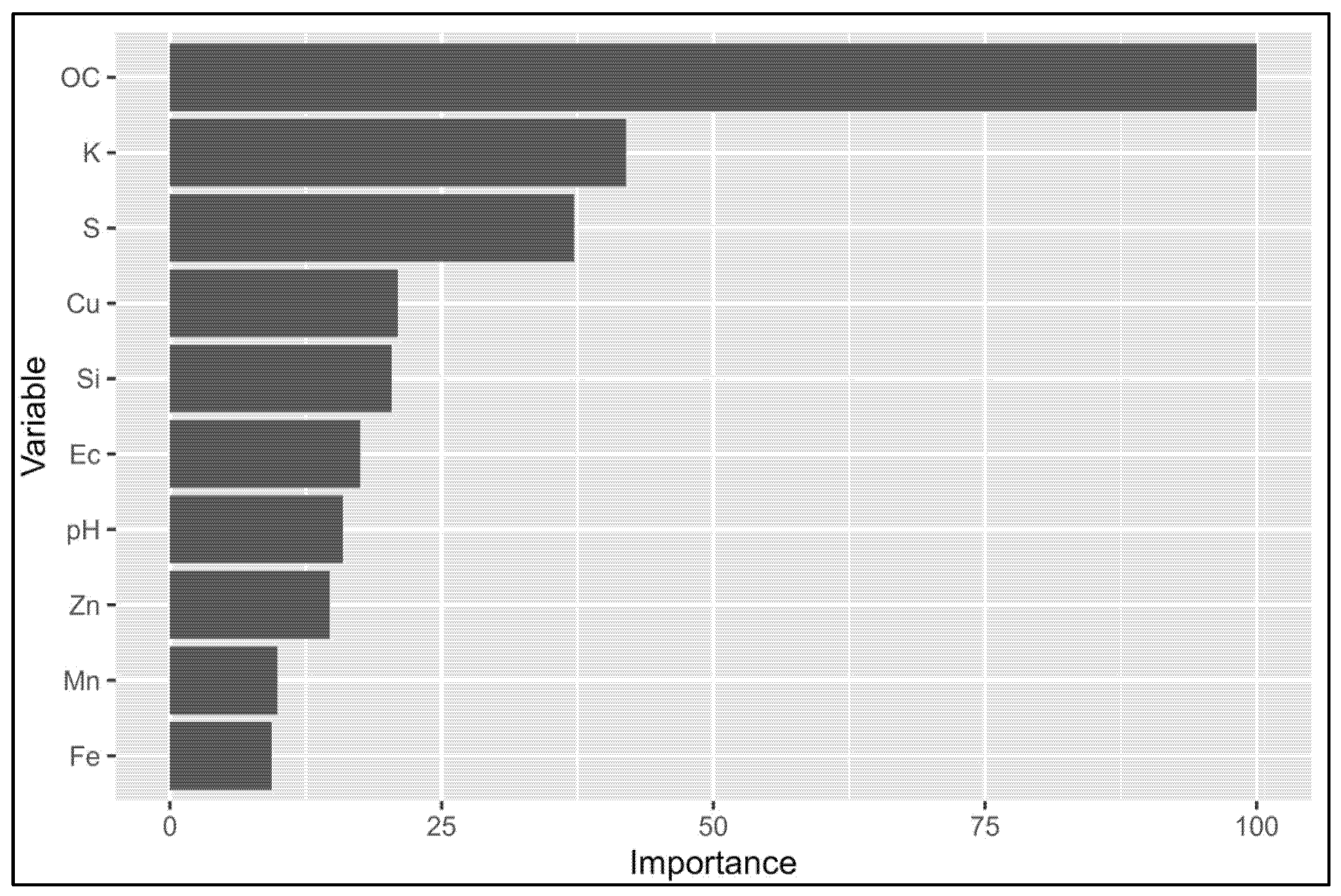
3.2.1. Kozani Dataset—PTFs vs. ML_min (C, Si, S, OC)
3.2.2. Kozani Dataset—PTFs vs. ML
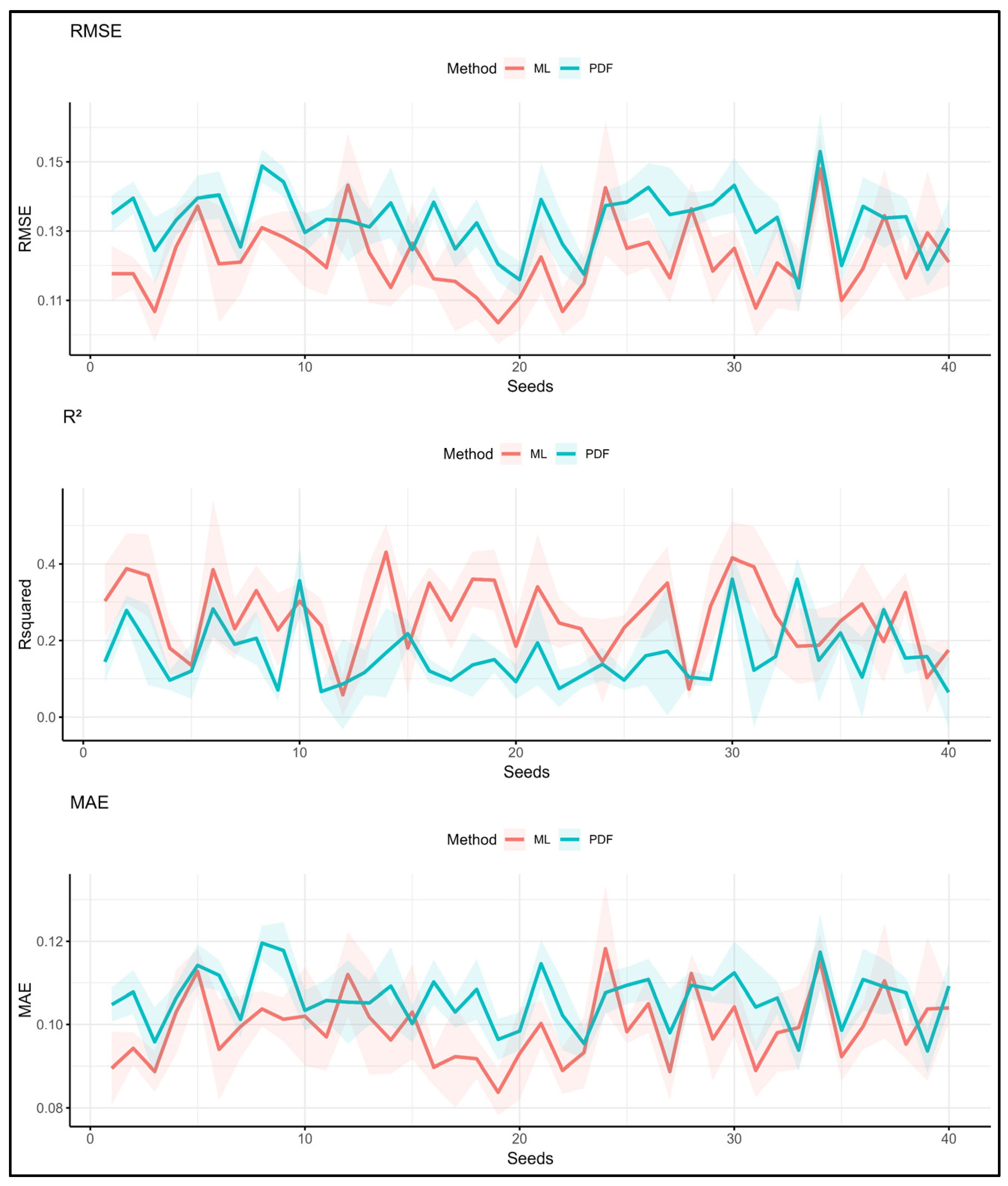
3.2.3. Veroia Dataset—PTFs vs. ML_min (C, Si, S, OC)
3.2.4. Veroia Dataset—PTFs vs. ML
4. Discussion
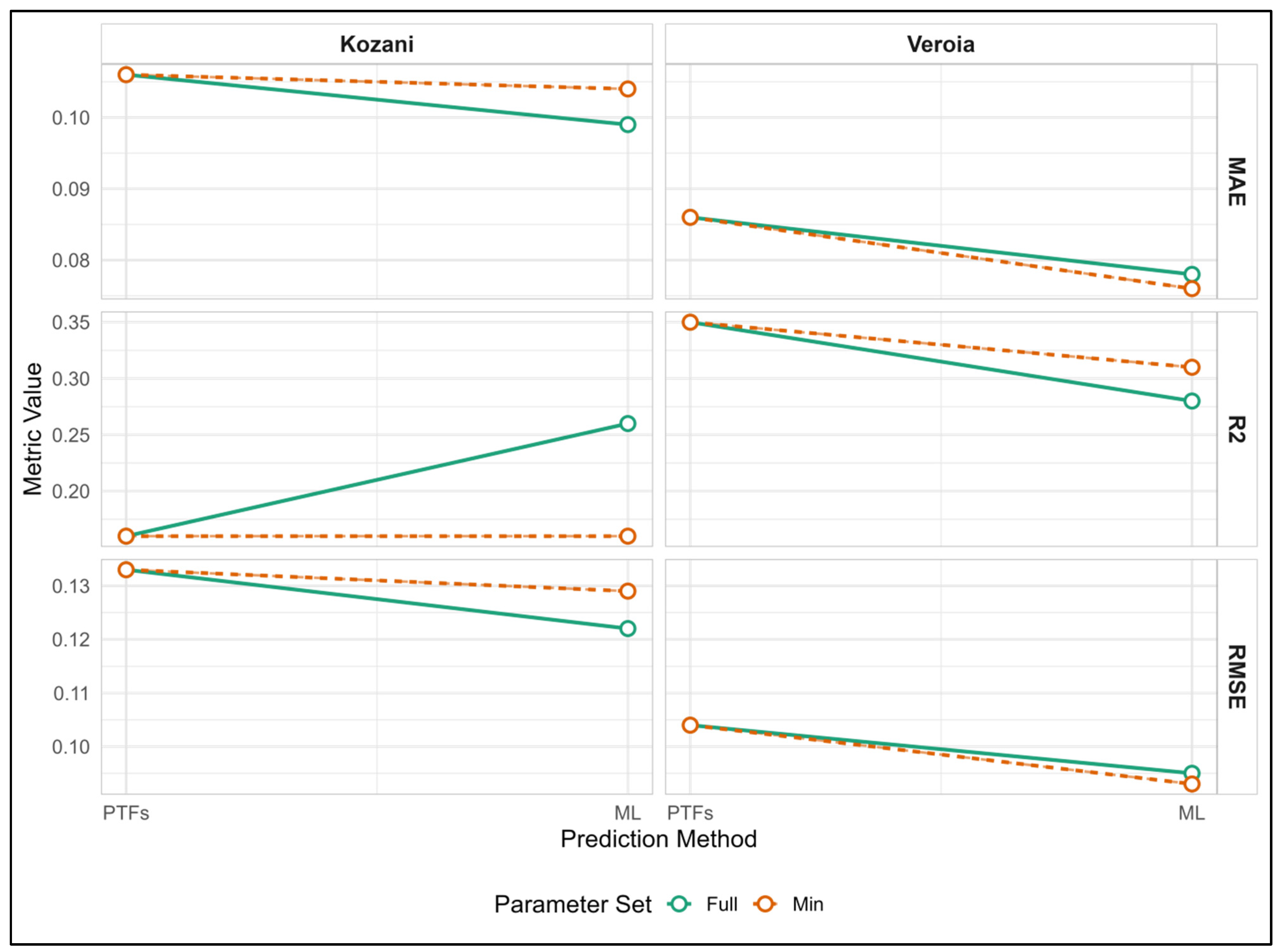
4.1. Regional Differences (Veroia vs. Kozani)
4.2. ML vs. PTF Performance
4.3. Impact of Dataset Size (“Full” vs. “Min”)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ramcharan, A.; Hengl, T.; Beaudette, D.; Wills, S. A Soil Bulk Density Pedotransfer Function Based on Machine Learning: A Case Study with the NCSS Soil Characterization Database. Soil Sci. Soc. Am. J. 2017, 81, 1279–1287. [Google Scholar] [CrossRef]
- Lai, R.; Kimble, J. Importance of soil bulk density and methods of its importance. In Assessment Methods for Soil Carbon; CRC Press: Boca Raton, FL, USA, 2000; Volume 31. [Google Scholar]
- Hillel, D. Introduction to Environmental Soil Physics; Elsevier: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Schaetzl, R.; Anderson, S. Soils: Genesis and Geomorphology; Cambridge University Press: New York, NY, USA, 2015. [Google Scholar]
- Reichert, J.M.; Suzuki, L.E.A.S.; Reinert, D.J.; Horn, R.; Håkansson, I. Reference bulk density and critical degree-of-compactness for no-till crop production in subtropical highly weathered soils. Soil Tillage Res. 2009, 102, 242–254. [Google Scholar] [CrossRef]
- Walter, K.; Don, A.; Tiemeyer, B.; Freibauer, A. Determining Soil Bulk Density for Carbon Stock Calculations: A Systematic Method Comparison. Soil Sci. Soc. Am. J. 2016, 80, 579–591. [Google Scholar] [CrossRef]
- Xu, L.; He, N.P.; Yu, G.R.; Wen, D.; Gao, Y.; He, H.L. Differences in pedotransfer functions of bulk density lead to high uncertainty in soil organic carbon estimation at regional scales: Evidence from Chinese terrestrial ecosystems. J. Geophys. Res. Biogeosci. 2015, 120, 1567–1575. [Google Scholar] [CrossRef]
- Blanco, H.; Lal, R. Principles of Soil Conservation and Management; Springer: New York, NY, USA, 2008; Volume 167169. [Google Scholar]
- Panagos, P.; De Rosa, D.; Liakos, L.; Labouyrie, M.; Borrelli, P.; Ballabio, C. Soil bulk density assessment in Europe. Agric. Ecosyst. Environ. 2024, 364, 108907. [Google Scholar] [CrossRef]
- Benites, V.M.; Machado, P.L.O.A.; Fidalgo, E.C.C.; Coelho, M.R.; Madari, B.E. Pedotransfer functions for estimating soil bulk density from existing soil survey reports in Brazil. Geoderma 2007, 139, 90–97. [Google Scholar] [CrossRef]
- Saxton, K.E.; Rawls, W.J. Soil Water Characteristic Estimates by Texture and Organic Matter for Hydrologic Solutions. Soil Sci. Soc. Am. J. 2006, 70, 1569–1578. [Google Scholar] [CrossRef]
- Abdelbaki, A.M. Evaluation of pedotransfer functions for predicting soil bulk density for US soils. Ain Shams Eng. J. 2018, 9, 1611–1619. [Google Scholar] [CrossRef]
- Holmes, K.W.; Wherrett, A.; Keating, A.; Murphy, D.V. Meeting bulk density sampling requirements efficiently to estimate soil carbon stocks. Soil Res. 2012, 49, 680–695. [Google Scholar] [CrossRef]
- Zhou, W.; Guan, K.; Peng, B.; Margenot, A.; Lee, D.; Tang, J.; Jin, Z.; Grant, R.; DeLucia, E.; Qin, Z.; et al. How does uncertainty of soil organic carbon stock affect the calculation of carbon budgets and soil carbon credits for croplands in the U.S. Midwest? Geoderma 2023, 429, 116254. [Google Scholar] [CrossRef]
- Grossman, R.; Reinsch, T. 2.1 Bulk density and linear extensibility. In Methods of Soil Analysis: Part 4 Physical Methods; John Wiley & Sons: New York, NY, USA, 2002; Volume 5, pp. 201–228. [Google Scholar]
- Bouma, J. Using soil survey data for quantitative land evaluation. In Advances in Soil Science; Springer: New York, NY, USA, 1989; Volume 9, pp. 177–213. [Google Scholar]
- De Vos, B.; Van Meirvenne, M.; Quataert, P.; Deckers, J.; Muys, B. Predictive Quality of Pedotransfer Functions for Estimating Bulk Density of Forest Soils. Soil Sci. Soc. Am. J. 2005, 69, 500–510. [Google Scholar] [CrossRef]
- de Castro Moreira da Silva, L.; Amorim, R.S.S.; Fernandes Filho, E.I.; Bocuti, E.D.; da Silva, D.D. Pedotransfer functions and machine learning: Advancements and challenges in tropical soils. Geoderma Reg. 2023, 35, e00720. [Google Scholar] [CrossRef]
- Chirico, G.B.; Medina, H.; Romano, N. Functional evaluation of PTF prediction uncertainty: An application at hillslope scale. Geoderma 2010, 155, 193–202. [Google Scholar] [CrossRef]
- Goidts, E.; Van Wesemael, B.; Crucifix, M. Magnitude and sources of uncertainties in soil organic carbon (SOC) stock assessments at various scales. Eur. J. Soil Sci. 2009, 60, 723–739. [Google Scholar] [CrossRef]
- Alaboz, P.; Demir, S.; Dengiz, O. Assessment of Various Pedotransfer Functions for the Prediction of the Dry Bulk Density of Cultivated Soils in a Semiarid Environment. Commun. Soil Sci. Plant Anal. 2021, 52, 724–742. [Google Scholar] [CrossRef]
- Xiao, Y.; Xue, J.; Zhang, X.; Wang, N.; Hong, Y.; Jiang, Y.; Zhou, Y.; Teng, H.; Hu, B.; Lugato, E.; et al. Improving pedotransfer functions for predicting soil mineral associated organic carbon by ensemble machine learning. Geoderma 2022, 428, 116208. [Google Scholar] [CrossRef]
- Nelson, D.W.; Sommers, L.E. Total carbon, organic carbon, and organic matter. Methods Soil Anal. Part 3 Chem. Methods 1996, 5, 961–1010. [Google Scholar]
- Gunarathna, M.H.J.P.; Sakai, K.; Nakandakari, T.; Momii, K.; Kumari, M.K.N. Machine Learning Approaches to Develop Pedotransfer Functions for Tropical Sri Lankan Soils. Water 2019, 11, 1940. [Google Scholar] [CrossRef]
- Nikou, M.; Tziachris, P. Prediction and Uncertainty Capabilities of Quantile Regression Forests in Estimating Spatial Distribution of Soil Organic Matter. ISPRS Int. J. Geo-Inf. 2022, 11, 130. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wang, Y.; Witten, I.H. Inducing model trees for continuous classes. In Proceedings of the Ninth European Conference on Machine Learning, Prague, Czech Republic, 23–25 April 1997; pp. 128–137. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Post, W.M.; Kwon, K.C. Soil carbon sequestration and land-use change: Processes and potential. Glob. Change Biol. 2000, 6, 317–327. [Google Scholar] [CrossRef]
- Rawls, W.J.; Nemes, A.; Pachepsky, Y. Effect of soil organic carbon on soil hydraulic properties. Dev. Soil Sci. 2004, 30, 95–114. [Google Scholar]
- Ruehlmann, J.; Körschens, M. Calculating the effect of soil organic matter concentration on soil bulk density. Soil Sci. Soc. Am. J. 2009, 73, 876–885. [Google Scholar] [CrossRef]
- Sevastas, S.; Gasparatos, D.; Botsis, D.; Siarkos, I.; Diamantaras, K.I.; Bilas, G. Predicting bulk density using pedotransfer functions for soils in the Upper Anthemountas basin, Greece. Geoderma Reg. 2018, 14, e00169. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Category | Unit | Method of Analysis | |
|---|---|---|---|---|
| 1 | * Clay (C) | Soil | % | Particle size analysis with hydrometer |
| 2 | * Silt (Si) | Soil | % | Particle size analysis with hydrometer |
| 3 | * Sand (S) | Soil | % | Particle size analysis with hydrometer |
| 4 | * Organic Carbon (OC) | Soil | % | Walkley–Black method |
| 5 | * Bulk Density (BD) | Soil | g/cm3 | Intact soil samples using a core cylinder |
| 6 | Electric Conductivity (EC) | Soil | mS/cm | In soil saturation extracts measured with conductometer |
| 7 | Acidity (pH) | Soil | --- | In soil saturated paste measured with pH meter |
| 8 | Nitrate Nitrogen (NN) | Soil | ppm | With 2M KCl colorimetric with photometer |
| 9 | Phosphorus (P) | Soil | ppm | With 0.5 M NaHCO3 pH 8.5 colorimetric with photometer |
| 10 | Potassium (K) | Soil | ppm | With ammonium acetate at pH = 7.0 measured by ICP-OES |
| 11 | Magnesium (Mg) | Soil | ppm | With ammonium acetate at pH = 7.0 measured by ICP-OES |
| 12 | Iron (Fe) | Soil | ppm | DTPA ** measured by ICP-OES |
| 13 | Zinc (Zn) | Soil | ppm | DTPA ** measured by ICP-OES |
| 14 | Manganese (Mn) | Soil | ppm | DTPA ** measured by ICP-OES |
| 15 | Copper (Cu) | Soil | ppm | DTPA ** measured by ICP-OES |
| 16 | Boron (B) | Soil | ppm | Azomethine-H, colorimetric with photometer |
| Authors | Abbrev. | Function | |
|---|---|---|---|
| 1 | Abdelbaki [12] | AB | BD = 1.449e − 0.03OC |
| 2 | Post and Kwon [30] | PK | BD = 100/[(OM/0.244) + ((100 − OM)/MBD)] |
| 3 | Rawls, Nemes, and Pachepsky [31] | R | BD = 1.36411 + 0.185628 × (0.0845397 + 0.701658w − 0.614038w2 − 1.18871w3 + 0.0991862y − 0.301816wy − 0.153337w2y − 0.0722421y2 + 0.392736wy2 + 0.0886315y3 − 0.601301z + 0.651673wz − 1.37484w2z + 0.298823yz − 0.192686wyz + 0.0815752y2z − 0.0450214z2 − 0.179529wz2 − 0.0797412yz2 + 0.00942183z3) x = −1.2141 + 4.23123 × (Sand/100) y = −1.70126 + 7.55319 × (Clay/100) z = −1.55601 + 0.507094 × OM w = −0.0771892 + 0.256629x + 0.256704x2 − 0.140911x3 − 0.0237361y − 0.098737x2y − 0.140381y2 + 0.0140902xy2 + 0.0287001y3 |
| 4 | Saxton and Rawls [11] | SR | SWC-HPC Model |
| 5 | Ruehlmann and Korschens [32] | RK | BD = (2.684 − 140.943 × 0.008) × EXP(−0.008 × OC × 10) |
| Metric | Equation | |
|---|---|---|
| Mean absolute error (MAE) | (1) | |
| Root mean square error (RMSE) | (2) | |
| Coefficient of determination (R2) | (3) | |
| where | ||
| and |
| S | C | Si | pH | Ec | NN | P | K | Mg | Fe | Zn | Mn | Cu | B | OC | BD | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | 56.76 | 14.72 | 28.51 | 6.85 | 0.49 | 11.31 | 20.72 | 171.90 | 257.17 | 33.45 | 2.39 | 11.15 | 5.26 | 0.59 | 0.84 | 1.44 |
| sd | 13.15 | 9.17 | 6.45 | 0.73 | 0.17 | 6.77 | 13.37 | 102.10 | 158.89 | 32.16 | 1.33 | 6.94 | 3.48 | 0.25 | 0.29 | 0.14 |
| median | 60.00 | 12.00 | 28.00 | 6.95 | 0.45 | 10.32 | 18.98 | 149.00 | 198.00 | 22.35 | 2.25 | 9.23 | 4.56 | 0.56 | 0.82 | 1.45 |
| min | 12.00 | 2.00 | 16.00 | 4.87 | 0.25 | 2.69 | 3.15 | 50.00 | 60.00 | 4.13 | 0.37 | 2.19 | 0.85 | 0.21 | 0.36 | 1.05 |
| max | 80.00 | 54.00 | 58.00 | 8.08 | 1.27 | 45.18 | 69.47 | 553.00 | 753.00 | 189.80 | 5.80 | 35.62 | 20.47 | 1.71 | 1.64 | 1.78 |
| skew | −1.18 | 1.79 | 1.14 | −0.59 | 1.47 | 2.08 | 1.04 | 1.50 | 1.17 | 2.16 | 0.63 | 1.36 | 1.54 | 1.60 | 0.43 | −0.29 |
| kurtosis | 1.44 | 3.78 | 2.87 | 0.00 | 3.06 | 6.27 | 0.92 | 2.27 | 0.61 | 5.47 | −0.21 | 1.89 | 3.33 | 4.07 | −0.44 | −0.10 |
| S | C | Si | pH | Ec | NN | P | K | Mg | Fe | Zn | Mn | Cu | B | OC | BD | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | 19.78 | 31.46 | 48.75 | 7.73 | 1.06 | 21.89 | 14.12 | 466.00 | 525.18 | 20.76 | 1.95 | 26.76 | 6.81 | 0.74 | 1.32 | 1.35 |
| sd | 10.74 | 12.41 | 9.25 | 0.23 | 0.73 | 14.65 | 17.85 | 196.00 | 149.90 | 7.08 | 1.27 | 41.12 | 4.44 | 0.39 | 0.34 | 0.11 |
| median | 19.00 | 28.00 | 48.00 | 7.75 | 0.79 | 16.62 | 10.70 | 432.00 | 513.50 | 19.16 | 1.70 | 13.96 | 5.92 | 0.66 | 1.31 | 1.35 |
| min | 4.00 | 4.00 | 20.00 | 6.61 | 0.45 | 1.67 | 2.39 | 137.00 | 144.00 | 9.70 | 0.23 | 6.00 | 1.40 | 0.14 | 0.72 | 1.08 |
| max | 60.00 | 62.00 | 74.00 | 8.15 | 5.64 | 54.07 | 180.02 | 1357.00 | 988.00 | 52.29 | 7.54 | 247.80 | 31.28 | 2.56 | 2.79 | 1.63 |
| skew | 0.90 | 0.56 | −0.07 | −1.50 | 2.83 | 0.67 | 6.52 | 1.19 | 0.50 | 1.57 | 1.91 | 3.61 | 2.19 | 1.56 | 0.82 | 0.01 |
| kurtosis | 0.92 | −0.61 | −0.30 | 4.33 | 11.24 | −0.88 | 53.39 | 2.34 | 0.76 | 3.17 | 4.67 | 13.28 | 7.05 | 4.50 | 1.65 | −0.54 |
| PTFs | ML_min | ||||||
|---|---|---|---|---|---|---|---|
| Method | RMSE | MAE | R2 | Method | RMSE | MAE | R2 |
| AB | 0.137 | 0.110 | 0.14 | CB | 0.131 | 0.106 | 0.13 |
| PK | 0.138 | 0.110 | 0.14 | RF * | 0.125 | 0.101 | 0.19 |
| R | 0.131 | 0.104 | 0.15 | SVR | 0.130 | 0.104 | 0.13 |
| SR | 0.128 | 0.102 | 0.23 | GB | 0.129 | 0.105 | 0.19 |
| RK | 0.129 | 0.104 | 0.14 | ||||
| Average | 0.133 | 0.106 | 0.16 | Average | 0.129 | 0.104 | 0.16 |
| PTFs | ML | ||||||
|---|---|---|---|---|---|---|---|
| Method | RMSE | MAE | R2 | Method | RMSE | MAE | R2 |
| AB | 0.137 | 0.110 | 0.14 | CB | 0.124 | 0.102 | 0.25 |
| PK | 0.138 | 0.110 | 0.14 | RF * | 0.114 | 0.092 | 0.33 |
| R | 0.131 | 0.104 | 0.15 | SVR | 0.124 | 0.100 | 0.22 |
| SR | 0.128 | 0.102 | 0.23 | GB | 0.126 | 0.102 | 0.25 |
| RK | 0.129 | 0.104 | 0.14 | ||||
| Average | 0.133 | 0.106 | 0.16 | Average | 0.122 | 0.099 | 0.26 |
| PTFs | ML_min | ||||||
|---|---|---|---|---|---|---|---|
| Method | RMSE | MAE | R2 | Method | RMSE | MAE | R2 |
| AB | 0.110 | 0.091 | 0.36 | CB | 0.091 | 0.074 | 0.33 |
| PK | 0.118 | 0.098 | 0.36 | RF | 0.093 | 0.076 | 0.31 |
| R | 0.091 | 0.076 | 0.35 | SVR * | 0.089 | 0.073 | 0.37 |
| SR | 0.096 | 0.077 | 0.34 | GB | 0.098 | 0.079 | 0.24 |
| RK | 0.105 | 0.088 | 0.36 | ||||
| Average | 0.104 | 0.086 | 0.35 | Average | 0.093 | 0.076 | 0.31 |
| PTFs | ML | ||||||
|---|---|---|---|---|---|---|---|
| Method | RMSE | MAE | R2 | Method | RMSE | MAE | R2 |
| AB | 0.110 | 0.091 | 0.36 | CB | 0.093 | 0.077 | 0.30 |
| PK | 0.118 | 0.098 | 0.36 | RF | 0.092 | 0.075 | 0.32 |
| R * | 0.091 | 0.076 | 0.35 | SVR | 0.096 | 0.078 | 0.27 |
| SR | 0.096 | 0.077 | 0.34 | GB | 0.099 | 0.081 | 0.24 |
| RK | 0.105 | 0.088 | 0.36 | ||||
| Average | 0.104 | 0.086 | 0.35 | Average | 0.095 | 0.078 | 0.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tziachris, P.; Louka, P.; Metaxa, E.; Iatrou, M.; Tsiouplakis, K. A Comparative Analysis of Machine Learning and Pedotransfer Functions Under Varying Data Availability in Two Greek Regions. Agriculture 2025, 15, 1134. https://doi.org/10.3390/agriculture15111134
Tziachris P, Louka P, Metaxa E, Iatrou M, Tsiouplakis K. A Comparative Analysis of Machine Learning and Pedotransfer Functions Under Varying Data Availability in Two Greek Regions. Agriculture. 2025; 15(11):1134. https://doi.org/10.3390/agriculture15111134
Chicago/Turabian StyleTziachris, Panagiotis, Panagiota Louka, Eirini Metaxa, Miltiadis Iatrou, and Konstantinos Tsiouplakis. 2025. "A Comparative Analysis of Machine Learning and Pedotransfer Functions Under Varying Data Availability in Two Greek Regions" Agriculture 15, no. 11: 1134. https://doi.org/10.3390/agriculture15111134
APA StyleTziachris, P., Louka, P., Metaxa, E., Iatrou, M., & Tsiouplakis, K. (2025). A Comparative Analysis of Machine Learning and Pedotransfer Functions Under Varying Data Availability in Two Greek Regions. Agriculture, 15(11), 1134. https://doi.org/10.3390/agriculture15111134