
The Rapid Detection of Foreign Fibers in Seed Cotton Based on Hyperspectral Band Selection and a Lightweight Neural Network



Abstract
1. Introduction
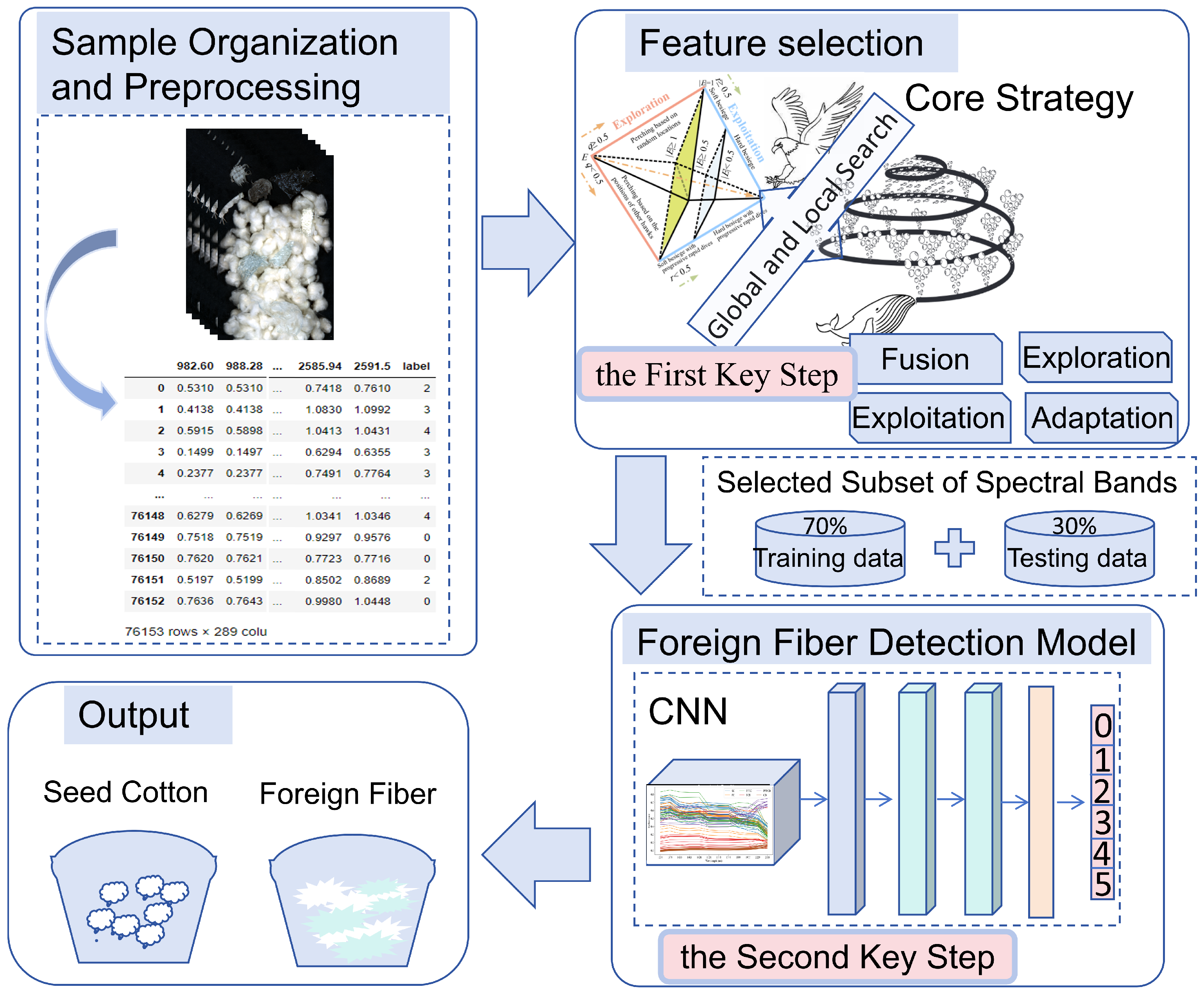
2. Materials and Methods
2.1. Cotton Sample Acquisition
2.2. Sample Preprocessing
2.3. Primary Theories
2.3.1. Hyperspectral Data Analysis Methods
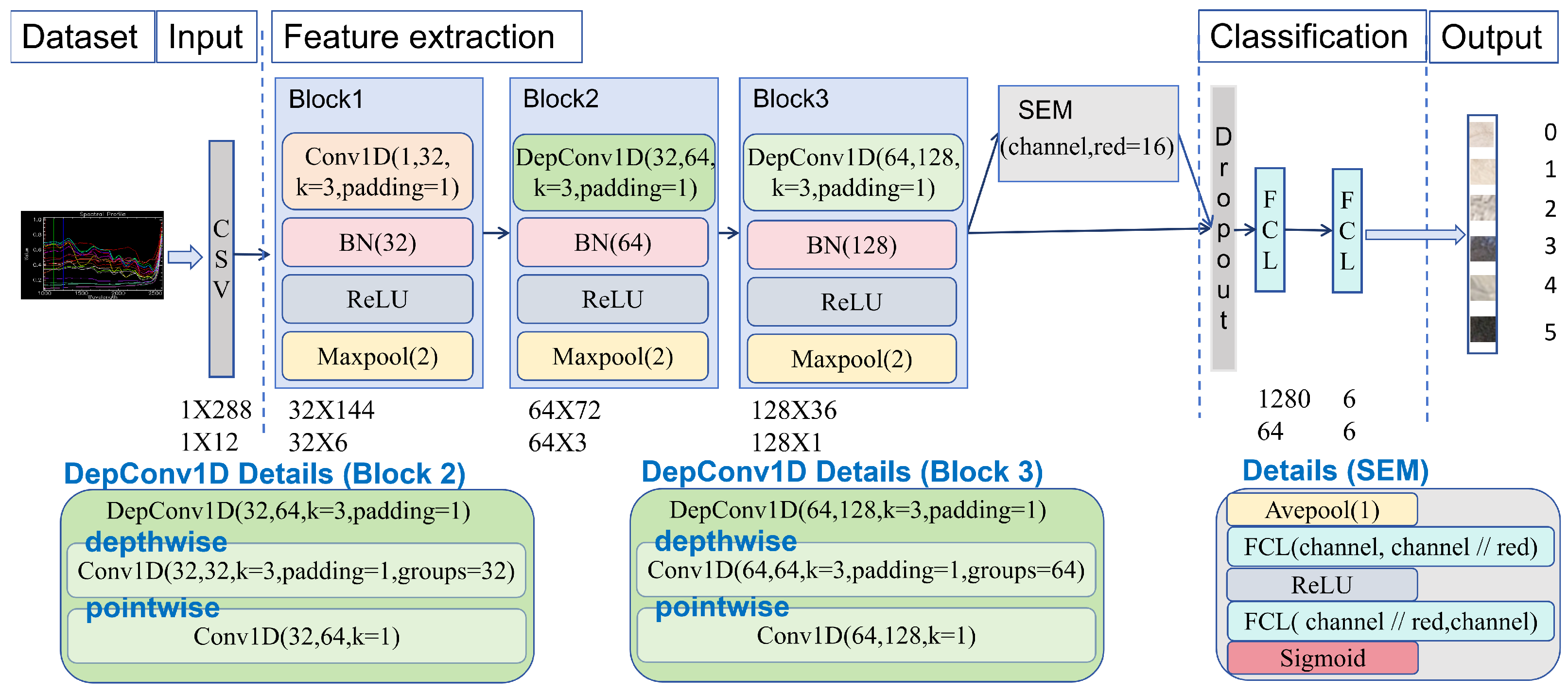
2.3.2. The Classification Model
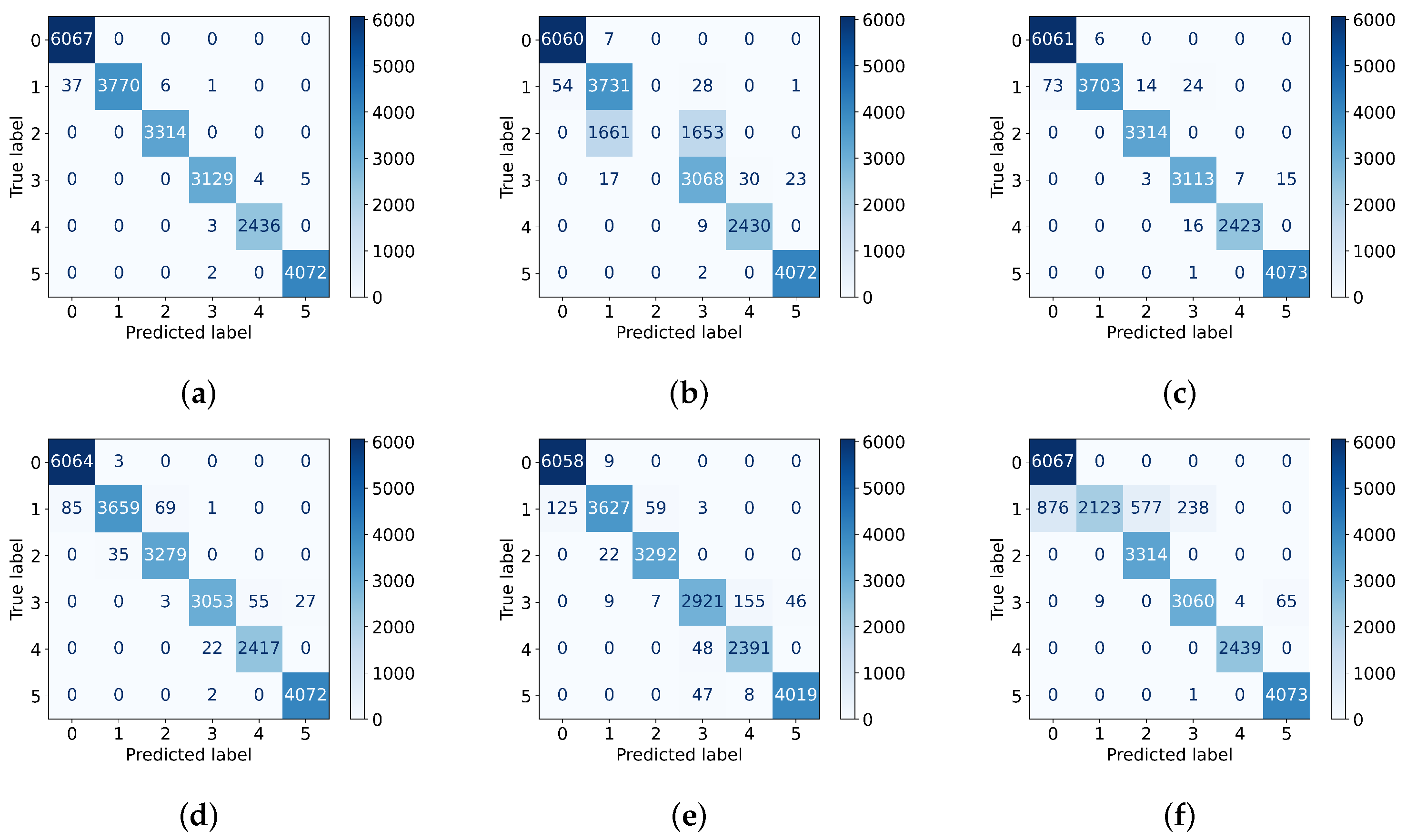
3. Results and Discussion
3.1. Feature Selection
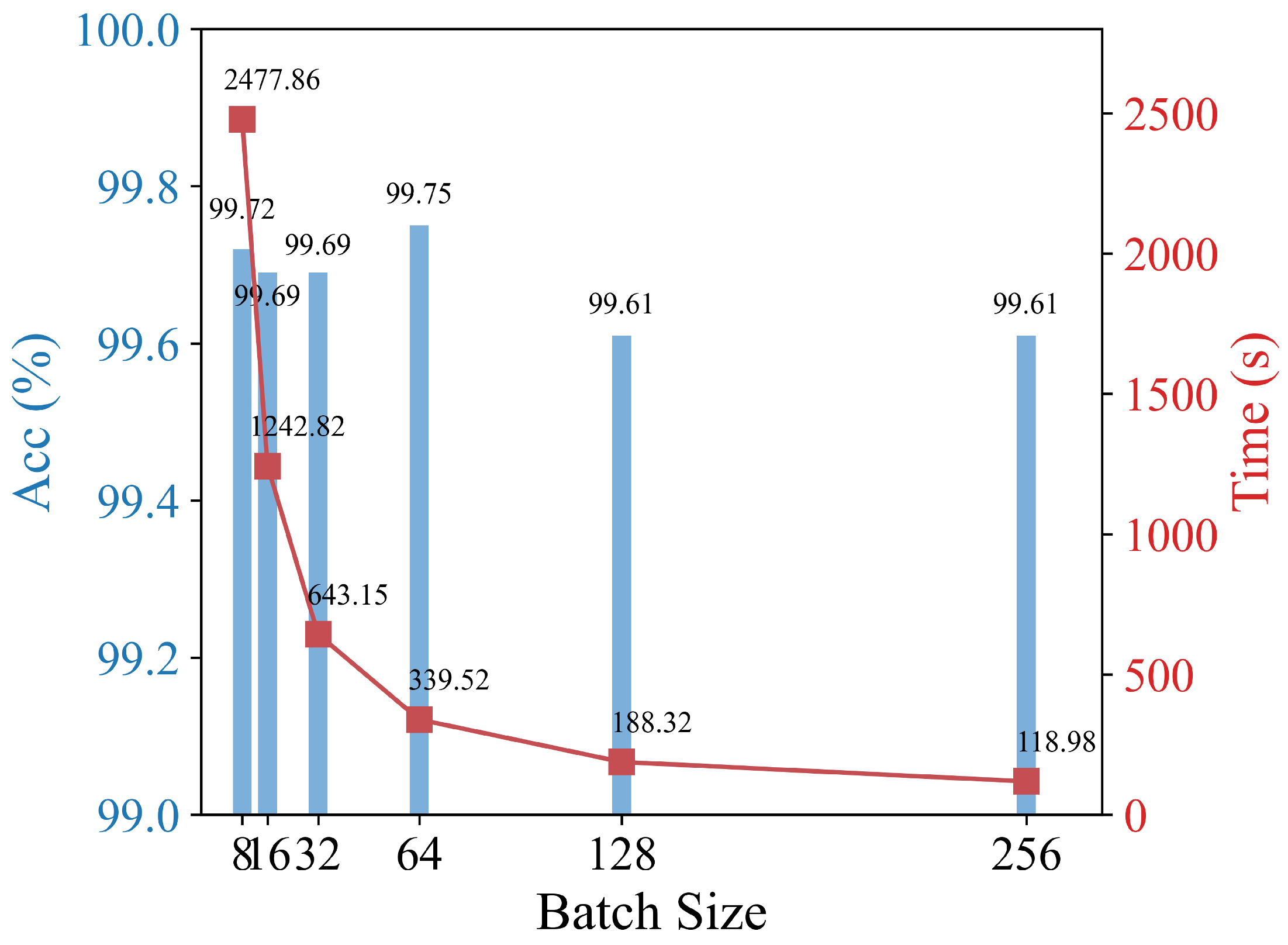
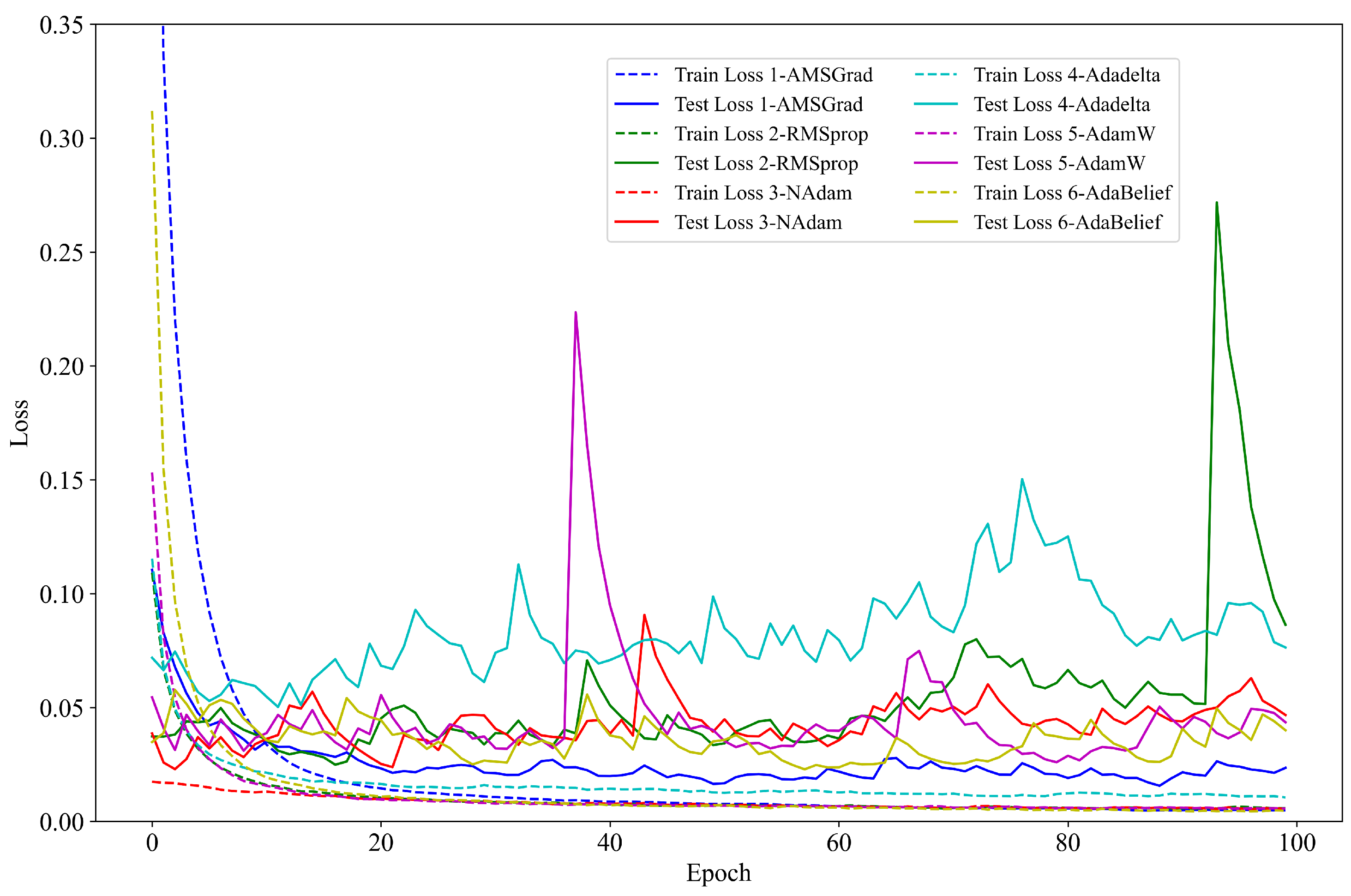
3.2. Model Optimization and Performance Analysis
3.3. A Comparison of the Proposed Model with Other Algorithms
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 1DCNN | One-Dimensional CNN |
| AA | Mean Accuracy |
| Acc | Overall Accuracy |
| ACO | Ant Colony Optimization |
| ANN | Artificial Neural Network |
| AUC | Area Under the ROC Curve |
| CB | Conveyor Belt |
| CNN | Convolutional Neural Network |
| ELM | Extreme Learning Machine |
| EWMA | Exponentially Weighted Moving Average |
| FA | Firefly Algorithm |
| FC | Film on Cotton |
| FCB | Film on the Conveyor Belt |
| FCLs | Fully Connected Layers |
| GA | Genetic Algorithm |
| HHO | Harris Hawks Optimization |
| HSI | Hyperspectral Imaging |
| HWOO | Harris Hawks and Whale Optimisation Operator |
| KNN | K-Nearest Neighbors |
| LDA | Linear Discriminant Analysis |
| MNF | Minimum Noise Fraction |
| NIR | Near-Infrared |
| PLS | Partial Least Squares |
| PPFC | Polypropylene Fibers on Cotton |
| PPFCB | Polypropylene Fibers on the Conveyor Belt |
| PSO | Particle Swarm Optimization |
| ROI | Region of Interest |
| SC | Seed Cotton |
| SEM SE | Module |
| SVM | Support Vector Machine |
| Total mult-adds | The Total Number of Multiply-Adds |
| WOA | Whale Optimization Algorithm |
References
- Liang, R.; Zhang, L.; Jia, R.; Meng, H.; Kan, Z.; Zhang, B.; Li, Y. Study on friction characteristics between cotton stalk-residual film-external contact materials. Ind. Crop. Prod. 2024, 209, 118022. [Google Scholar] [CrossRef]
- Dong, C.; Du, Y.; Ren, W.; Zhao, C. Research progress in optical imaging technology for detecting foreign fibers in cotton. J. Text. Res. 2020, 41, 183–189. [Google Scholar] [CrossRef]
- Li, D.; Yang, W.; Wang, S. Classification of foreign fibers in cotton lint using machine vision and multi-class support vector machine. Comput. Electron. Agric. 2010, 74, 274–279. [Google Scholar] [CrossRef]
- Zhang, C.; Li, L.; Dong, Q.; Ge, R. Recognition for machine picking seed cotton impurities based on ga-svm model. Trans. Chin. Soc. Agric. Eng. 2016, 32, 189–196. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, M.; Wen, Z.; Zhao, Z.; Zhang, R. Residual mulching film detection in seed cotton using line laser imaging. Agronomy 2024, 14, 1481. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Z.-F.; Yang, B.; Xi, H.-Q.; Zhai, Y.-S.; Zhang, R.-L.; Geng, L.-J.; Chen, Z.-Y.; Yan, K.G. Detection and classification of cotton foreign fibers based on polarization imaging and improved yolov5. Sensors 2023, 23, 4415. [Google Scholar] [CrossRef]
- Wei, X.; Wu, S.; Xu, L.; Shen, B.; Li, M. Identification of foreign fibers of seed cotton using hyper-spectral images based on minimum noise fraction. Trans. Chin. Soc. Agric. Eng. 2014, 30, 243–248. [Google Scholar] [CrossRef]
- Chang, J.; Zhang, R.; Pang, Y.; Zhang, M.; Zha, Y. Classification of impurities in machine-harvested seed cotton using hyperspectral imaging. Spectrosc. Spectr. Anal. 2021, 41, 3552–3558. [Google Scholar] [CrossRef]
- Ni, C.; Li, Z.; Zhang, X.; Sun, X.; Huang, Y.; Zhao, L.; Zhu, T.; Wang, D. Online sorting of the film on cotton based on deep learning and hyperspectral imaging. IEEE Access 2020, 8, 93028–93038. [Google Scholar] [CrossRef]
- Pal, M.; Foody, G.M. Feature selection for classification of hyperspectral data by svm. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2297–2307. [Google Scholar] [CrossRef]
- He, X.; Liu, L.; Liu, C.; Li, W.; Sun, J.; Li, H.; He, Y.; Yang, L.; Zhang, D.; Cui, T.; et al. Discriminant analysis of maize haploid seeds using near-infrared hyperspectral imaging integrated with multivariate methods. Biosyst. Eng. 2022, 222, 142–155. [Google Scholar] [CrossRef]
- Hongjun, S. Dimensionality reduction for hyperspectral remote sensing: Advances, challenges, and prospects. Natl. Remote Sens. Bull. 2022, 26, 1504–1529. [Google Scholar] [CrossRef]
- Ma, J.-P.; Zheng, Z.-B.; Tong, Q.-X.; Zheng, L.-F. An application of genetic algorithms on band selection for hyperspectral image classification. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 03EX693), Xi’an, China, 2–5 November 2023; IEEE: New York, NY, USA, 2003; Volume 5, pp. 2810–2813. [Google Scholar] [CrossRef]
- Li, S.; Wu, H.; Wan, D.; Zhu, J. An effective feature selection method for hyperspectral image classification based on genetic algorithm and support vector machine. Knowl.-Based Syst. 2011, 24, 40–48. [Google Scholar] [CrossRef]
- Su, H.; Du, Q.; Chen, G.; Du, P. Optimized hyperspectral band selection using particle swarm optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2014, 7, 2659–2670. [Google Scholar] [CrossRef]
- Xu, M.; Shi, J.; Chen, W.; Shen, J.; Gao, H.; Zhao, J. A band selection method for hyperspectral image based on particle swarm optimization algorithm with dynamic sub-swarms. J. Signal Process. Syst. 2018, 90, 1269–1279. [Google Scholar] [CrossRef]
- Allegrini, F.; Olivieri, A.C. A new and efficient variable selection algorithm based on ant colony optimization. applications to near infrared spectroscopy/partial least-squares analysis. Anal. Chim. Acta 2011, 699, 18–25. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, M.; Zheng, L.; Qin, Q.; Lee, W.S. Spectral features extraction for estimation of soil total nitrogen content based on modified ant colony optimization algorithm. Geoderma 2019, 333, 23–34. [Google Scholar] [CrossRef]
- Goodarzi, M.; Coelho, L.d.S. Firefly as a novel swarm intelligence variable selection method in spectroscopy. Anal. Chim. Acta 2014, 852, 20–27. [Google Scholar] [CrossRef]
- Su, H.; Yong, B.; Du, Q. Hyperspectral band selection using improved firefly algorithm. IEEE Geosci. Remote Sens. Lett. 2015, 13, 68–72. [Google Scholar] [CrossRef]
- Wang, D.; Vinson, R.; Holmes, M.; Seibel, G.; Bechar, A.; Nof, S.; Tao, Y. Early detection of tomato spotted wilt virus by hyperspectral imaging and outlier removal auxiliary classifier generative adversarial nets (or-ac-gan). Sci. Rep. 2019, 9, 4377. [Google Scholar] [CrossRef]
- Wang, Z.; Fan, S.; An, T.; Zhang, C.; Chen, L.; Huang, W. Detection of insect-damaged maize seed using hyperspectral imaging and hybrid 1d-cnn-bilstm model. Infrared Phys. Technol. 2024, 137, 105208. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, Y.; Rong, Y.; Xiong, S.; Lu, X. Matnet: A combining multi-attention and transformer network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Chen, T.; Wang, M.; Jiang, Y.; Yao, J.; Li, M. A lightweight diagnosis method for gear fault based on multi-path convolutional neural networks with attention mechanism. Appl. Intell. 2025, 55, 114. [Google Scholar] [CrossRef]
- Zhao, Y.; Dong, J.; Li, X.; Chen, H.; Li, S. A binary dandelion algorithm using seeding and chaos population strategies for feature selection. Appl. Soft Comput. 2022, 125, 109166. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; no. 53; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 Novembe–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Chi, J.; Bu, X.; Zhang, X.; Wang, L.; Zhang, N. Insights into cottonseed cultivar identification using raman spectroscopy and explainable machine learning. Agriculture 2023, 13, 768. [Google Scholar] [CrossRef]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural Networks for Machine Learning, Coursera, Video Lectures; University of Toronto: Toronto, ON, Canada, 2012; Volume 264, pp. 2146–2153. Available online: https://www.cs.toronto.edu/~hinton/coursera_lectures.html (accessed on 4 May 2025).
- Dozat, T. Incorporating nesterov momentum into adam. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016; Available online: https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ (accessed on 4 May 2025).
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.C.; Dvornek, N.; Papademetris, X.; Duncan, J. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Adv. Neural Inf. Process. Syst. 2020, 33, 18795–18806. [Google Scholar]
- Li, X.; Jiang, H.; Jiang, X.; Shi, M. Identification of geographical origin of chinese chestnuts using hyperspectral imaging with 1d-cnn algorithm. Agriculture 2021, 11, 1274. [Google Scholar] [CrossRef]
- Huang, J.; He, H.; Lv, R.; Zhang, G.; Zhou, Z.; Wang, X. Non-destructive detection and classification of textile fibres based on hyperspectral imaging and 1d-cnn. Anal. Chim. Acta 2022, 1224, 340238. [Google Scholar] [CrossRef]
- Devassy, B.M.; George, S. Contactless classification of strawberry using hyperspectral imaging. In Proceedings of the CEUR Workshop Proceedings, Luxembourg, 3–4 December 2020; Volume 2688, p. 9. Available online: https://ceur-ws.org/Vol-2688/paper9.pdf (accessed on 4 May 2025).
- Guo, C.; Liu, L.; Sun, H.; Wang, N.; Zhang, K.; Zhang, Y.; Zhu, J.; Li, A.; Bai, Z.; Liu, X.; et al. Predicting f v/f m and evaluating cotton drought tolerance using hyperspectral and 1d-cnn. Front. Plant Sci. 2022, 13, 1007150. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Class | Class Label | Training Set (Pixels) | Testing Set (Pixels) |
|---|---|---|---|
| SC | 0 | 14,157 | 6067 |
| FC | 1 | 8899 | 3814 |
| PPFC | 2 | 7732 | 3314 |
| FCB | 3 | 7323 | 3138 |
| PPFCB | 4 | 5691 | 2439 |
| CB | 5 | 9505 | 4074 |
| Algorithm | Bands | Acc (%) | AUC (%) | Time (s) | |||||
|---|---|---|---|---|---|---|---|---|---|
| Label0 1 | Label1 2 | Label2 3 | Label3 4 | Label4 5 | Label5 6 | ||||
| Original | 288 | 81.18 | 94.73 | 57.86 | 98.62 | 94.11 | 99.96 | 99.15 | 8.47 |
| GA | 107 | 86.43 | 97.54 | 71.73 | 97.73 | 99.00 | 99.97 | 99.94 | 4.39 |
| PSO | 108 | 86.46 | 97.23 | 73.57 | 98.00 | 98.88 | 99.93 | 99.88 | 4.39 |
| HHO | 16 | 92.45 | 98.56 | 84.04 | 99.06 | 98.89 | 99.96 | 99.84 | 2.82 |
| WOA | 17 | 91.87 | 97.90 | 83.40 | 99.44 | 98.83 | 99.97 | 99.56 | 2.86 |
| HWOO | 12 | 93.05 | 98.31 | 83.92 | 98.79 | 98.74 | 99.96 | 99.81 | 1.68 |
| Algorithm | Bands | Acc (%) | AA (%) | Kappa | Time (s) |
|---|---|---|---|---|---|
| HHO | 16 | 92.45 | 93.80 | 90.75 | 2.82 |
| 32 | 92.08 | 93.66 | 90.27 | 3.12 | |
| 29 | 92.45 | 93.42 | 90.75 | 3.32 | |
| 19 | 92.13 | 93.06 | 90.36 | 3.03 | |
| 22 | 92.52 | 93.64 | 90.82 | 3.00 | |
| WOA | 27 | 90.95 | 92.41 | 88.88 | 3.09 |
| 30 | 91.84 | 93.07 | 89.98 | 3.12 | |
| 23 | 92.84 | 93.95 | 91.23 | 3.03 | |
| 17 | 91.87 | 93.77 | 90.02 | 3.07 | |
| 19 | 93.04 | 94.51 | 91.46 | 2.80 | |
| HWOO | 12 | 92.64 | 93.58 | 90.98 | 1.85 |
| 13 | 91.54 | 93.71 | 89.59 | 1.87 | |
| 26 | 92.65 | 93.69 | 90.99 | 3.20 | |
| 19 | 92.77 | 93.83 | 91.13 | 2.99 | |
| 12 | 93.05 | 94.27 | 91.48 | 1.76 |
| Model | Acc (%) | Per-Pixel Test Time (µs) | Model Architecture Metrics | |
|---|---|---|---|---|
| Total Parameters | Total Mult-Adds (M) | |||
| DepSE-CNN-12 | 99.75 | 12.201 | 22,086 | 0.52 |
| [41] | 84.75 | 14.049 | 41,190 | 1.12 |
| [42] | 99.30 | 19.734 | 97,734 | 1.80 |
| [43] | 98.68 | 12.827 | 28,710 | 0.64 |
| [44] | 97.65 | 10.265 | 3217 | 0.38 |
| DepSE-CNN-288 | 92.25 | 23.581 | 5,920,646 | 68.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fei, Y.; Li, Z.; Wang, D.; Ni, C. The Rapid Detection of Foreign Fibers in Seed Cotton Based on Hyperspectral Band Selection and a Lightweight Neural Network. Agriculture 2025, 15, 1088. https://doi.org/10.3390/agriculture15101088
Fei Y, Li Z, Wang D, Ni C. The Rapid Detection of Foreign Fibers in Seed Cotton Based on Hyperspectral Band Selection and a Lightweight Neural Network. Agriculture. 2025; 15(10):1088. https://doi.org/10.3390/agriculture15101088
Chicago/Turabian StyleFei, Yeqi, Zhenye Li, Dongyi Wang, and Chao Ni. 2025. "The Rapid Detection of Foreign Fibers in Seed Cotton Based on Hyperspectral Band Selection and a Lightweight Neural Network" Agriculture 15, no. 10: 1088. https://doi.org/10.3390/agriculture15101088
APA StyleFei, Y., Li, Z., Wang, D., & Ni, C. (2025). The Rapid Detection of Foreign Fibers in Seed Cotton Based on Hyperspectral Band Selection and a Lightweight Neural Network. Agriculture, 15(10), 1088. https://doi.org/10.3390/agriculture15101088