
Bringing Semantics to the Vineyard: An Approach on Deep Learning-Based Vine Trunk Detection

 , ,
, ,  , ,
, ,  ,
,  and
and 
Abstract
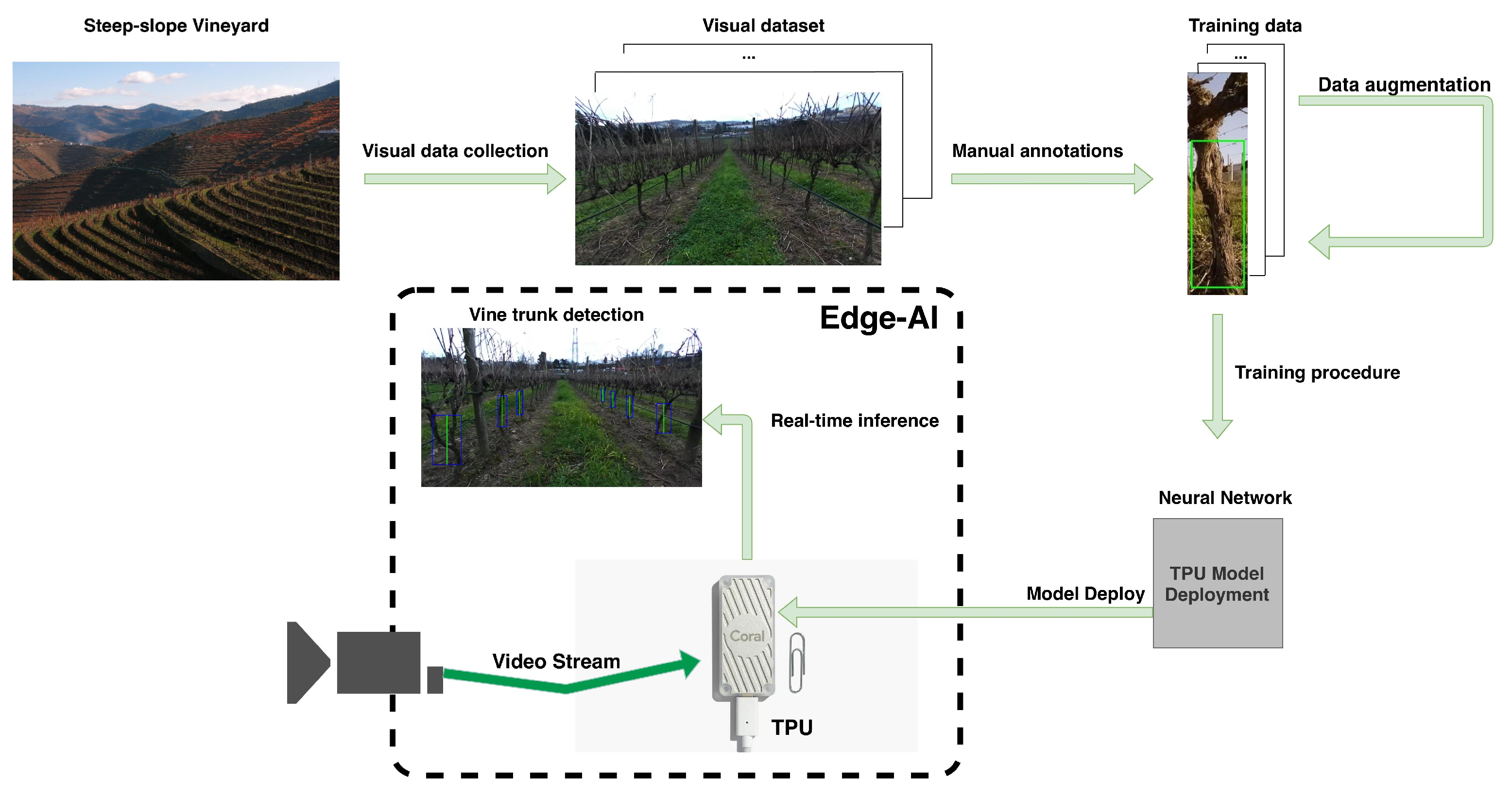
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Approach | Performance |
|---|---|---|
| Badeka et al. [21] | Deep Learning-based vine trunk detection. Uses Faster R-CNN and two YOLO versions. | Average Precision of 73.2% and execution time of 29.6 ms. |
| Lamprecht et al. [24] | Detection based on Airbone Laser Scanning. Uses a Crown Base Height estimation and 3D clustering to isolate laser points on tree trunks. | Detection rate of 75% and overall accuracy of 84%. |
| Shalal et al. [25] | Orchard tree detection using a camera and a laser sensor. Based on image segmentation and data fusion techniques. | Average rate of detection confidence of 82.2%. |
| Xue et al. [26] | Uses a camera and a laser sensor to detect and measure the trunk width. Algorithm based on data fusion and decision with Dempster-Shafer theory. | Trunk width measurement with error rates from 6% to 16.7%. |
| Juman et al. [27] | Ground removal by colour space combination and segmentation and trunk detection using the Viola-Jones detector. | Detection rate of 97.8%. |
| Bargoti et al. [28] | Implements a Hough transformation to extract trunk candidates, and uses pixelwise classification to update their likelihood of being a tree trunk. | 87–96% accuracy during the preharvest season, and 99% accuracy during the flowering season. |
| Colmenero-Martinez et al. [29] | Uses an infrared sensor to detect tree trunks. | Detection rate of 91%. |
| Reference | Application | Performance |
|---|---|---|
| Dias et al. [30] | Detect apple flowers. | AP of 97.20% and F1 score of 92.10%. |
| Zheng et al. [31] | Detect and classify crop species. | AP of 92.79%. |
| Koirala et al. [32] | Detect mango fruit. | AP of 98.60% and F1 score of 96.70%. |
| Tian et al. [33] | Detect apples in orchards. | F1 score of 81.70%. |
| Bargoti and Underwood [34] | Detect fruit in orchards. | F1 score of 90.40% for apples, 90.80% for mangoes and 77.50% for almonds. |
| Sa et al. [35] | Detect sweet pepper and rock melon | F1 score of 83.80%. |
| Kirk et al. [36] | Detect ripe soft fruits. | F1 score of 74.40%. |
| Li et al. [37] | Detect and count oil palm trees from high-resolution remote sensing images. | Maximum overall detection accuracy of 99% and counting error less than 4% for each considered region. |
| Ding and Taylor [38] | Detect pest. | AP of 93.10%. |
| Zhong et al. [39] | Detect flying insects. | Counting accuracy of 93.71%. |
| Steen et al. [40] | Detect an obstacle. | Precision of 99.9% and recall of 36.7% in row crops, and precision of 90.8% and a recall of 28.1% in mowing grass. |
- A novel DL-oriented dataset for vine trunk detection called VineSet, publicly available (http://vcriis01.inesctec.pt/datasets/DataSet/VineSet.zip) and recognized by the ROS Agriculture community (http://wiki.ros.org/agriculture) as “A Large Vine Trunk Image Collection and Annotation using the Pascal VOC format”.
- A way of extending the dataset size using data augmentation techniques.
- The train, benchmark, and characterization of state-of-the-art Single Shot Multibox Detector (SSD) [45] models for vine trunk detection using the VineSet.
- Real-time deployment of the models using a Tensor Processing Unit (TPU).
- An automatic annotation tool for datasets of trunks in agricultural contexts.
2. Background
2.1. Single Shot Multibox
- Convolutional feature layers that decrease progressively in size, detecting objects at multiple scales.
- Convolutional filters that are represented on the top of Figure 2 produce a fixed number of detection predictions.
- A set of bounding boxes associated with each feature map cell.
2.2. MobileNets
2.3. Inception
3. Materials and Methods
3.1. Data Acquisition
3.2. Data Annotation
3.3. Data Augmentation
3.4. Training Procedure
- the full quantization of models to 8-bit precision; and,
- compilation of the model to the TPU context.
3.5. Assisted Labelling Tool
4. Results
4.1. Methodology
4.2. Object Detection Metrics
- True Positive (TP): IoU , i.e., a correct detection.
- False Positive (FP): IoU , i.e., an incorrect detection.
- False Negative (FN): a ground truth is not detected.
4.3. Detectors Performance
4.4. Impact of the Dataset Size on the Detection Performance
4.5. Comparison of Transfer Learning against Training from Scratch
4.6. Assisted Labelling Procedure
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Andresen, T.; de Aguiar, F.B.; Curado, M.J. The Alto Douro Wine Region greenway. Landsc. Urban Plan. 2004, 68, 289–303. [Google Scholar] [CrossRef]
- Dos Santos, F.N.; Sobreira, H.; Campos, D.; Morais, R.; Moreira, A.P.; Contente, O. Towards a reliable robot for steep slope vineyards monitoring. J. Intell. Robot. Syst. 2016, 83, 429–444. [Google Scholar] [CrossRef]
- Roldán, J.J.; del Cerro, J.; Garzón-Ramos, D.; Garcia-Aunon, P.; Garzón, M.; de León, J.; Barrientos, A. Robots in Agriculture: State of Art and Practical Experiences. In Service Robots; InTech: London, UK, 2018. [Google Scholar] [CrossRef]
- Duckett, T.; Pearson, S.; Blackmore, S.; Grieve, B.; Chen, W.H.; Cielniak, G.; Cleaversmith, J.; Dai, J.; Davis, S.; Fox, C.; et al. Agricultural Robotics: The Future of Robotic Agriculture. arXiv 2018, arXiv:cs.RO/1806.06762. [Google Scholar]
- Dos Santos, F.N.; Sobreira, H.M.P.; Campos, D.F.B.; Morais, R.; Moreira, A.P.G.M.; Contente, O.M.S. Towards a Reliable Monitoring Robot for Mountain Vineyards. In Proceedings of the 2015 IEEE International Conference on Autonomous Robot Systems and Competitions, Vila Real, Portugal, 8–10 April 2015; pp. 37–43. [Google Scholar] [CrossRef]
- Cheein, F.A.; Steiner, G.; Paina, G.P.; Carelli, R. Optimized EIF-SLAM algorithm for precision agriculture mapping based on stems detection. Comput. Electron. Agric. 2011, 78, 195–207. [Google Scholar] [CrossRef]
- Aguiar, A.; Santos, F.; Santos, L.; Sousa, A. Monocular Visual Odometry Using Fisheye Lens Cameras. In Progress in Artificial Intelligence; Moura Oliveira, P., Novais, P., Reis, L.P., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 319–330. [Google Scholar]
- Aguiar, A.S.; dos Santos, F.N.; Cunha, J.B.; Sobreira, H.; Sousa, A.J. Localization and Mapping for Robots in Agriculture and Forestry: A Survey. Robotics 2020, 9, 97. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl. Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Shao, L.; Zhu, F.; Li, X. Transfer Learning for Visual Categorization: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1019–1034. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer Learning. In Handbook of Research on Machine Learning Applications; IGI Global: Hershey, PA, USA, 2009. [Google Scholar] [CrossRef]
- Santos, L.; Santos, F.N.; Oliveira, P.M.; Shinde, P. Deep Learning Applications in Agriculture: A Short Review. In Robot 2019: Fourth Iberian Robotics Conference; Silva, M.F., Luís Lima, J., Reis, L.P., Sanfeliu, A., Tardioli, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 139–151. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Badeka, E.; Kalampokas, T.; Vrochidou, E.; Tziridis, K.; Papakostas, G.; Pachidis, T.; Kaburlasos, V. Real-time vineyard trunk detection for a grapes harvesting robot via deep learning. In Proceedings of the Thirteenth International Conference on Machine Vision, Rome, Italy, 2–6 November 2020; Osten, W., Nikolaev, D.P., Zhou, J., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2021; Volume 11605, pp. 394–400. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:cs.CV/1506.01497. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lamprecht, S.; Stoffels, J.; Dotzler, S.; Haß, E.; Udelhoven, T. aTrunk—An ALS-Based Trunk Detection Algorithm. Remote Sens. 2015, 7, 9975–9997. [Google Scholar] [CrossRef]
- Shalal, N.; Low, T.; McCarthy, C.; Hancock, N. A preliminary evaluation of vision and laser sensing for tree trunk detection and orchard mapping. In Proceedings of the Australasian Conference on Robotics and Automation (ACRA 2013), Sydney, Australia, 2–4 December 2013; pp. 1–10. [Google Scholar]
- Xue, J.; Fan, B.; Yan, J.; Dong, S.; Ding, Q. Trunk detection based on laser radar and vision data fusion. Int. J. Agric. Biol. Eng. 2018, 11, 20–26. [Google Scholar] [CrossRef]
- Juman, M.A.; Wong, Y.W.; Rajkumar, R.K.; Goh, L.J. A novel tree trunk detection method for oil-palm plantation navigation. Comput. Electron. Agric. 2016, 128, 172–180. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J.P.; Nieto, J.I.; Sukkarieh, S. A Pipeline for Trunk Detection in Trellis Structured Apple Orchards. J. Field Robot. 2015, 32, 1075–1094. [Google Scholar] [CrossRef]
- Colmenero-Martinez, J.T.; Blanco-Roldán, G.L.; Bayano-Tejero, S.; Castillo-Ruiz, F.J.; Sola-Guirado, R.R.; Gil-Ribes, J.A. An automatic trunk-detection system for intensive olive harvesting with trunk shaker. Biosyst. Eng. 2018, 172, 92–101. [Google Scholar] [CrossRef]
- Dias, P.A.; Tabb, A.; Medeiros, H. Apple flower detection using deep convolutional networks. Comput. Ind. 2018, 99, 17–28. [Google Scholar] [CrossRef]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Su, T.L.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.X.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef]
- Kirk, R.; Cielniak, G.; Mangan, M. L*a*b*Fruits: A Rapid and Robust Outdoor Fruit Detection System Combining Bio-Inspired Features with One-Stage Deep Learning Networks. Sensors 2020, 20, 275. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef]
- Ding, W.; Taylor, G.W. Automatic moth detection from trap images for pest management. Comput. Electron. Agric. 2016, 123, 17–28. [Google Scholar] [CrossRef]
- Zhong, Y.; Gao, J.; Lei, Q.; Zhou, Y. A Vision-Based Counting and Recognition System for Flying Insects in Intelligent Agriculture. Sensors 2018, 18, 1489. [Google Scholar] [CrossRef]
- Steen, K.A.; Christiansen, P.; Karstoft, H.; Jørgensen, R.N. Using Deep Learning to Challenge Safety Standard for Highly Autonomous Machines in Agriculture. J. Imaging 2016, 2, 6. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:cs.CV/1804.02767. [Google Scholar]
- Pinto de Aguiar, A.S.; Neves dos Santos, F.B.; Feliz dos Santos, L.C.; de Jesus Filipe, V.M.; Miranda de Sousa, A.J. Vineyard trunk detection using deep learning—An experimental device benchmark. Comput. Electron. Agric. 2020, 175, 105535. [Google Scholar] [CrossRef]
- Aguiar, A.S.; Santos, F.N.D.; De Sousa, A.J.M.; Oliveira, P.M.; Santos, L.C. Visual Trunk Detection Using Transfer Learning and a Deep Learning-Based Coprocessor. IEEE Access 2020, 8, 77308–77320. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2015. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:cs.CV/1704.04861. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:cs.CV/1512.00567. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Santos, L.; Santos, F.; Mendes, J.; Costa, P.; Lima, J.; Reis, R.; Shinde, P. Path Planning Aware of Robot’s Center of Mass for Steep Slope Vineyards. Robotica 2020, 38, 684–698. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. arXiv 2016, arXiv:1605.08695. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]













| Augmentation Operation | Description |
|---|---|
| Rotation | Rotates the image by 15, −15 and 45 degrees. |
| Translation | Translates the image by −30% to +30% on x- and y-axis. |
| Scale | Scales the image to a value of 50 to 150% of their original size. |
| Flipping | Mirrors the image horizontally. |
| Multiply | Multiplies all pixels in an image with a random value sampled once per image, which can be used to make images lighter or darker. |
| Hue and saturation | Increases or decreases hue and saturation by random values. This operation first transforms images to HSV colourspace, then adds random values to the H and S channels, and afterwards converts back to RGB. |
| Gaussian noise | Adds noise sampled from Gaussian distributions element-wise to images. |
| Random combination | Applies a random combination of three of the previous operations. |
| M del | Train Dataset | Fine-Tuning | From Scratch | From Scratch | |||
|---|---|---|---|---|---|---|---|
| 50 k | 50 k | 100 k | |||||
| AP (%) | F1 | AP (%) | F1 | AP (%) | F1 | ||
| SSD MobileNet-V1 | Small subset | 49.74 | 0.610 | - | - | - | - |
| SSD MobileNet-V2 | 52.98 | 0.590 | - | - | - | - | |
| SSD Inception-V2 | 46.10 | 0.610 | - | - | - | - | |
| SSD MobileNet-V1 | VineSet | 84.16 | 0.841 | 68.44 | 0.685 | 85.93 | 0.834 |
| SSD MobileNet-V2 | 83.01 | 0.808 | 60.44 | 0.639 | 83.70 | 0.812 | |
| SSD Inception-V2 | 75.78 | 0.848 | 58.05 | 0.658 | 76.77 | 0.849 | |
| Model | Inference Time per Image (ms) |
|---|---|
| SSD MobileNet-V1 | 21.18 |
| SSD MobileNet-V2 | 23.14 |
| SSD Inception-V2 | 359.64 |
| Dataset | Number of Images | Number of Trunks | Automatic Annotations (%) | Average Time with Assisted Labelling (min) | Average Time without Assisted Labelling (min) |
|---|---|---|---|---|---|
| Other vineyards | 11 | 75 | 72.32 | 1.74 | 6.35 |
| Hazelnut orchard | 20 | 139 | 48.34 | 5.99 | 11.58 |
| Forest | 264 | 1647 | 28.05 | 101.97 | 137.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguiar, A.S.; Monteiro, N.N.; Santos, F.N.d.; Solteiro Pires, E.J.; Silva, D.; Sousa, A.J.; Boaventura-Cunha, J. Bringing Semantics to the Vineyard: An Approach on Deep Learning-Based Vine Trunk Detection. Agriculture 2021, 11, 131. https://doi.org/10.3390/agriculture11020131
Aguiar AS, Monteiro NN, Santos FNd, Solteiro Pires EJ, Silva D, Sousa AJ, Boaventura-Cunha J. Bringing Semantics to the Vineyard: An Approach on Deep Learning-Based Vine Trunk Detection. Agriculture. 2021; 11(2):131. https://doi.org/10.3390/agriculture11020131
Chicago/Turabian StyleAguiar, André Silva, Nuno Namora Monteiro, Filipe Neves dos Santos, Eduardo J. Solteiro Pires, Daniel Silva, Armando Jorge Sousa, and José Boaventura-Cunha. 2021. "Bringing Semantics to the Vineyard: An Approach on Deep Learning-Based Vine Trunk Detection" Agriculture 11, no. 2: 131. https://doi.org/10.3390/agriculture11020131
APA StyleAguiar, A. S., Monteiro, N. N., Santos, F. N. d., Solteiro Pires, E. J., Silva, D., Sousa, A. J., & Boaventura-Cunha, J. (2021). Bringing Semantics to the Vineyard: An Approach on Deep Learning-Based Vine Trunk Detection. Agriculture, 11(2), 131. https://doi.org/10.3390/agriculture11020131