
A Machine Learning Model to Predict Postoperative Speech Recognition Outcomes in Cochlear Implant Recipients: Development, Validation, and Comparison with Expert Clinical Judgment


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design and Data Source
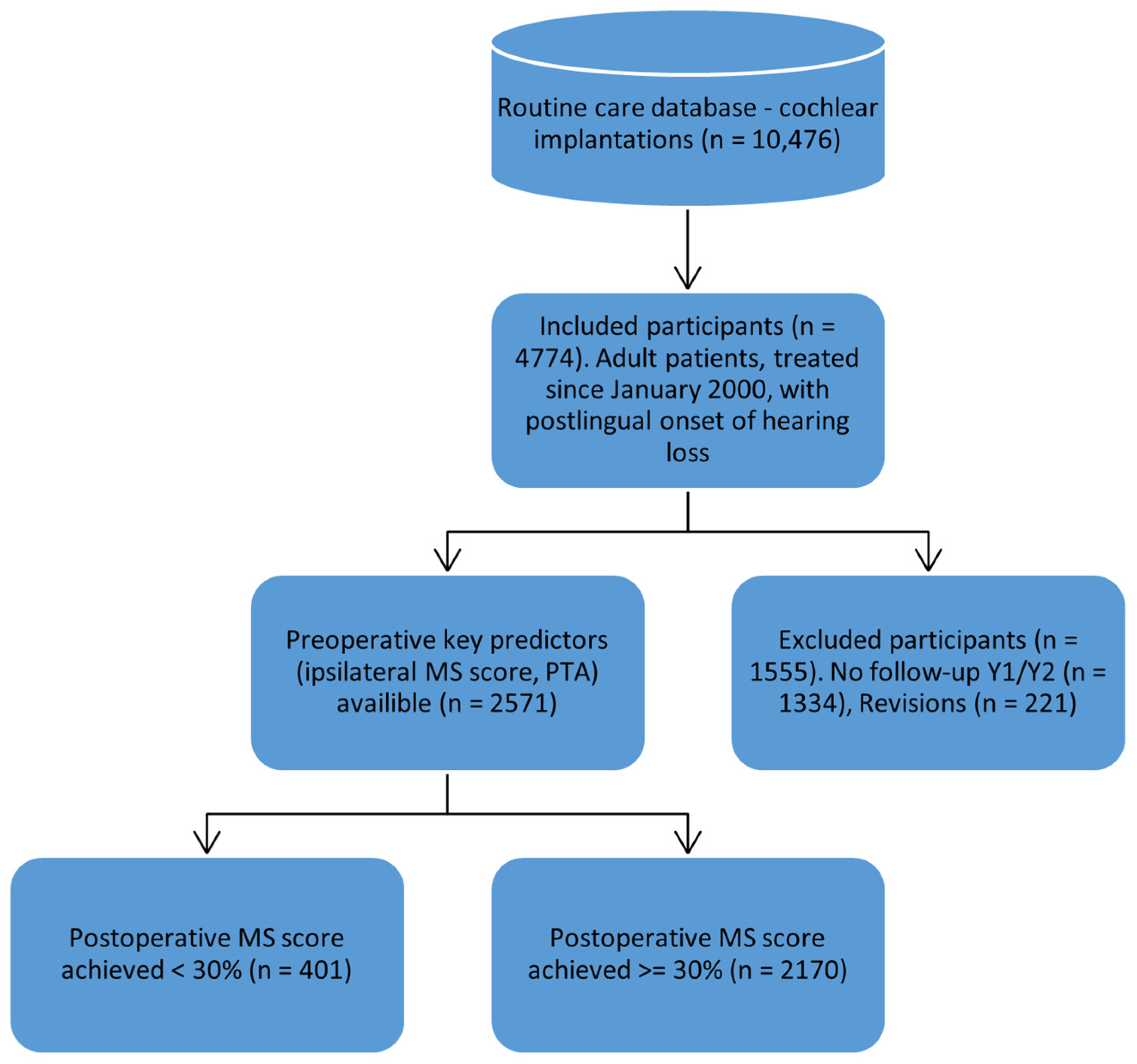
2.2. Participants
- Were 18 years of age or older at the time of surgery;
- Had postlingual onset of hearing loss;
- Underwent their first cochlear implantation (i.e., no revision surgeries).
2.3. Outcome and Predictions
2.3.1. Outcome Measure
2.3.2. Predictor Variables
- Age at implantation (years)
- Duration of deafness (years) on the ipsilateral side
- Best preoperative MS score (%) on ipsilateral and contralateral sides
- ⚬
- Taken at the most favorable loudness level within up to one year prior to surgery
- Preoperative pure tone average (PTA, dB) on ipsilateral and contralateral sides
- ⚬
- Averaged across four frequencies: 500, 1000, 2000, and 4000 Hz
- Onset of hearing loss, categorized as “progredient”, “acute”, or “since childhood”, encoded as a one-hot variable
- Time since first implantation (years)
- ⚬
- Applicable only to patients who had a contralateral implant before their first implantation; otherwise, set to zero
2.4. Data Processing and Handling of Missing Data
2.5. Data Analysis and Machine Learning Methods
- Acute onset (1/0)
- Progredient onset (1/0)
- Onset since childhood (1/0)
- Random Test Split (10%): A simple random sample comprising 10% of the overall dataset, set aside before model training.
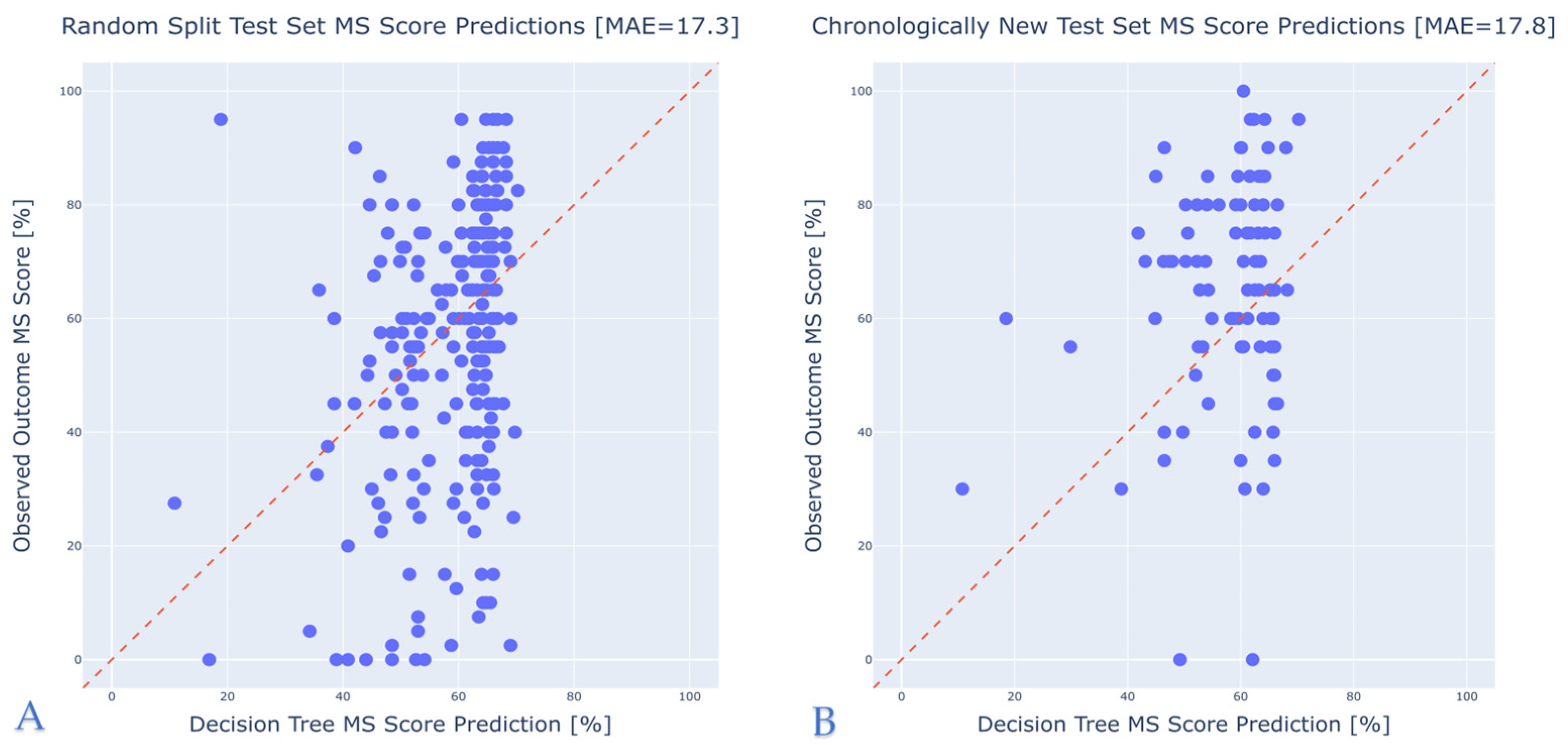
- Chronologically New Data: To approximate real-life usage where future patients may differ from those on whom the model was trained, we created a “future” dataset containing cases from 2020 onward, ensuring these were not included in the training set. This dataset was to evaluate if the model, trained on older data, would still be able to predict performance of more recently implanted patients.
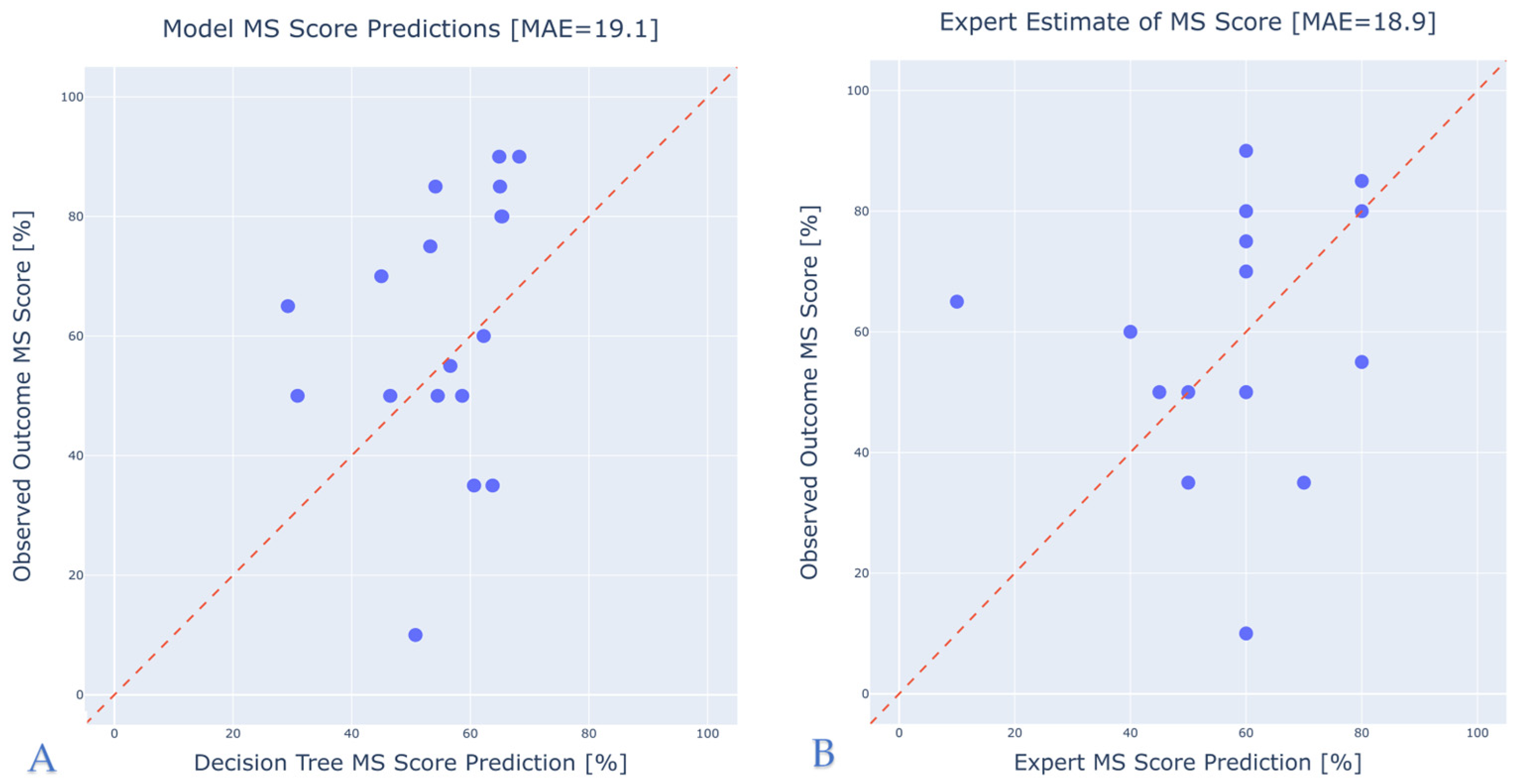
- Expert Comparison Dataset: We prospectively collected 19 cases for which experienced audiologists at our center provided predicted MS scores. This enabled a direct comparison of model-based predictions against human expert estimations on the same individuals. The dataset includes all relevant predictors, the actual postoperative MS score (ground truth), and the audiologist’s predicted MS score.
2.6. Implementation
3. Results
3.1. Participant Flow and Dataset Preparation
- A random split test set comprising the remaining 10% of the data.
- A chronologically new test set containing patients treated after 2020.
- An expert estimation test set, created to compare model predictions with those of experienced healthcare professionals, i.e., audiologists.
3.2. Model Performance
3.3. Comparison with Expert Predictions
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Olusanya, B.O.; Neumann, K.J.; Saunders, J.E. The Global Burden of Disabling Hearing Impairment: A Call to Action. Bull. World Health Organ. 2014, 92, 367–373. [Google Scholar] [CrossRef] [PubMed]
- World Report on Hearing. Available online: https://www.who.int/publications/i/item/9789240020481 (accessed on 4 February 2025).
- Lin, F.R.; Yaffe, K.; Xia, J.; Xue, Q.-L.; Harris, T.B.; Purchase-Helzner, E.; Satterfield, S.; Ayonayon, H.N.; Ferrucci, L.; Simonsick, E.M.; et al. Hearing Loss and Cognitive Decline in Older Adults. JAMA Intern. Med. 2013, 173, 293–299. [Google Scholar] [CrossRef]
- Gifford, R.H.; Shallop, J.K.; Peterson, A.M. Speech Recognition Materials and Ceiling Effects: Considerations for Cochlear Implant Programs. Audiol. Neurootol. 2008, 13, 193–205. [Google Scholar] [CrossRef]
- Boisvert, I.; Reis, M.; Au, A.; Cowan, R.; Dowell, R.C. Cochlear Implantation Outcomes in Adults: A Scoping Review. PLoS ONE 2020, 15, e0232421. [Google Scholar] [CrossRef]
- Pisoni, D.B.; Kronenberger, W.G.; Harris, M.S.; Moberly, A.C. Three Challenges for Future Research on Cochlear Implants. World J. Otorhinolaryngol.—Head Neck Surg. 2017, 03, 240–254. [Google Scholar] [CrossRef]
- Lazard, D.S.; Giraud, A.L.; Truy, E.; Lee, H.J. Evolution of Non-Speech Sound Memory in Postlingual Deafness: Implications for Cochlear Implant Rehabilitation. Neuropsychologia 2011, 49, 2475–2482. [Google Scholar] [CrossRef] [PubMed]
- Velde, H.; Rademaker, M.; Damen, J.; Smit, A.; Stegeman, I. Prediction Models for Clinical Outcome after Cochlear Implantation: A Systematic Review. J. Clin. Epidemiol. 2021, 137, 182–194. [Google Scholar] [CrossRef] [PubMed]
- Holden, L.K.; Finley, C.C.; Firszt, J.B.; Holden, T.A.; Brenner, C.; Potts, L.G.; Gotter, B.D.; Vanderhoof, S.S.; Mispagel, K.; Heydebrand, G.; et al. Factors Affecting Open-Set Word Recognition in Adults With Cochlear Implants. Ear Hear. 2013, 34, 342. [Google Scholar] [CrossRef]
- Hoppe, U.; Hast, A.; Hornung, J.; Hocke, T. Evolving a Model for Cochlear Implant Outcome. J. Clin. Med. 2023, 12, 6215. [Google Scholar] [CrossRef]
- Crowson, M.G.; Dixon, P.; Mahmood, R.; Lee, J.W.; Shipp, D.; Le, T.; Lin, V.; Chen, J.; Chan, T.C.Y. Predicting Postoperative Cochlear Implant Performance Using Supervised Machine Learning. Otol. Neurotol. 2020, 41, e1013. [Google Scholar] [CrossRef]
- Shafieibavani, E.; Goudey, B.; Kiral, I.; Zhong, P.; Jimeno-Yepes, A.; Swan, A.; Gambhir, M.; Buechner, A.; Kludt, E.; Eikelboom, R.H.; et al. Predictive Models for Cochlear Implant Outcomes: Performance, Generalizability, and the Impact of Cohort Size. Trends Hear. 2021, 25, 23312165211066174. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Kang, W.S.; Park, H.J.; Lee, J.Y.; Park, J.W.; Kim, Y.; Seo, J.W.; Kwak, M.Y.; Kang, B.C.; Yang, C.J.; et al. Cochlear Implantation in Postlingually Deaf Adults Is Time-Sensitive Towards Positive Outcome: Prediction Using Advanced Machine Learning Techniques. Sci. Rep. 2018, 8, 18004. [Google Scholar] [CrossRef] [PubMed]
- Roditi, R.E.; Poissant, S.F.; Bero, E.M.; Lee, D.J. A Predictive Model of Cochlear Implant Performance in Postlingually Deafened Adults. Otol. Neurotol. 2009, 30, 449. [Google Scholar] [CrossRef] [PubMed]
- Plant, K.; McDermott, H.; van Hoesel, R.; Dawson, P.; Cowan, R. Factors Predicting Postoperative Unilateral and Bilateral Speech Recognition in Adult Cochlear Implant Recipients with Acoustic Hearing. Ear Hear. 2016, 37, 153. [Google Scholar] [CrossRef] [PubMed]
- Favaretto, N.; Marioni, G.; Brotto, D.; Sorrentino, F.; Gheller, F.; Castiglione, A.; Montino, S.; Giacomelli, L.; Trevisi, P.; Martini, A.; et al. Cochlear Implant Outcomes in the Elderly: A Uni- and Multivariate Analyses of Prognostic Factors. Eur. Arch. Otorhinolaryngol. 2019, 276, 3089–3094. [Google Scholar] [CrossRef]
- James, C.J.; Karoui, C.; Laborde, M.-L.; Lepage, B.; Molinier, C.-É.; Tartayre, M.; Escudé, B.; Deguine, O.; Marx, M.; Fraysse, B. Early Sentence Recognition in Adult Cochlear Implant Users. Ear Hear. 2019, 40, 905. [Google Scholar] [CrossRef]
- Collins, G.S.; Moons, K.G.M.; Dhiman, P.; Riley, R.D.; Beam, A.L.; Van Calster, B.; Ghassemi, M.; Liu, X.; Reitsma, J.B.; Van Smeden, M.; et al. TRIPOD+AI Statement: Updated Guidance for Reporting Clinical Prediction Models That Use Regression or Machine Learning Methods. BMJ 2024, 385, e078378. [Google Scholar] [CrossRef]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing Value Estimation Methods for DNA Microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman and Hall/CRC: New York, NY, USA, 2017; ISBN 978-1-315-13947-0. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. Additive Models, Trees, and Related Methods. In The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Hastie, T., Tibshirani, R., Friedman, J., Eds.; Springer: New York, NY, USA, 2009; pp. 295–336. ISBN 978-0-387-84858-7. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. IJCAL 2001, 14, 1137–1143. [Google Scholar]
- Mckinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Buhl, M.; Kludt, E.; Schell-Majoor, L.; Avan, P.; Campi, M. Discrimination Loss vs. SRT: A Model-Based Approach towards Harmonizing Speech Test Interpretations. arXiv 2025, arXiv:2501.08921. [Google Scholar]
- Saak, S.; Huelsmeier, D.; Kollmeier, B.; Buhl, M. A Flexible Data-Driven Audiological Patient Stratification Method for Deriving Auditory Profiles. Front. Neurol. 2022, 13, 959582. [Google Scholar] [CrossRef] [PubMed]
- Systems, S.G. Ocean Health Clinical Knowledge Manager. Available online: https://ckm.highmed.org/ckm/projects/1246.152.56 (accessed on 22 April 2025).
- Philpott, N.; Philips, B.; Donders, R.; Mylanus, E.; Huinck, W. Variability in Clinicians’ Prediction Accuracy for Outcomes of Adult Cochlear Implant Users. Int. J. Audiol. 2024, 63, 613–621. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
| Characteristic | Train/Test Set (n = 2479) | “Recent” Test Set (n = 92) | Expert Estimation (n = 18) |
|---|---|---|---|
| Cochlear Implantation Period | 2000–2019 | 2020–2022 | 2022–2023 |
| Study Design | Retrospective Longitudinal Cohort | Retrospective Longitudinal Cohort | Retrospective Longitudinal Cohort with Prospectively Collected Expert Estimates |
| Setting | Tertiary Care Center in Large University Hospital (Hannover, Germany) | ||
| Inclusion Criteria | Adult patients with severe hearing loss/deafness treated with cochlear implantation | Same + postoperative monosyllabic score being estimated by expert | |
| Outcome | Monosyllabic score on implanted side in 1 year after surgery | ||
| Average Postoperative MS score (std), % | 55 (25) | 65 (20) | 60 (20) |
| Average Age at Implantation (range), y | 59 (18–94) | 61 (23–93) | 63 (18–86) |
| Average Preoperative MS score, ipsilateral (std), % | 16 (23) | 18 (22) | 23 (24) |
| Average Preoperative PTA, ipsilateral, (std), dB | 102 (20) | 97 (19) | 95 (23) |
| Characteristic | All Patients (n = 2479) | MS < 30% (n = 399) | MS ≥ 30% (n = 2080) |
|---|---|---|---|
| Median Age (IQR), y | 60 (49–72) | 63 (50–74) | 60 (49–71) |
| Median MS Score Ipsilateral (IQR), % | 0 (0–30) | 0 (0–15) | 5 (0–30) |
| Median MS Score Contralateral (IQR), % | 45 (0–85) | 40 (0–85) | 45 (0–80) |
| Median PTA Ipsilateral (IQR), dB | 102 (85–120) | 110 (90–130) | 101 (85–118) |
| Median PTA Contralateral (IQR), dB | 82 (61–110) | 81 (56–107) | 83 (62–111) |
| Median Duration of Deafness (IQR), y | 1.7 (0–8.2) | 4.4 (0.7–19.5) | 1.5 (0–6.8) |
| Progredient Onset (% of cases), n cases | 2006 (80) | 296 (74) | 1710 (82) |
| Acute Onset (% of cases), n cases | 408 (16) | 92 (23) | 315 (15) |
| Onset Since Childhood (% of cases), n cases | 83 (4) | 15 (3) | 68 (3) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Demyanchuk, A.; Kludt, E.; Lenarz, T.; Büchner, A. A Machine Learning Model to Predict Postoperative Speech Recognition Outcomes in Cochlear Implant Recipients: Development, Validation, and Comparison with Expert Clinical Judgment. J. Clin. Med. 2025, 14, 3625. https://doi.org/10.3390/jcm14113625
Demyanchuk A, Kludt E, Lenarz T, Büchner A. A Machine Learning Model to Predict Postoperative Speech Recognition Outcomes in Cochlear Implant Recipients: Development, Validation, and Comparison with Expert Clinical Judgment. Journal of Clinical Medicine. 2025; 14(11):3625. https://doi.org/10.3390/jcm14113625
Chicago/Turabian StyleDemyanchuk, Alexey, Eugen Kludt, Thomas Lenarz, and Andreas Büchner. 2025. "A Machine Learning Model to Predict Postoperative Speech Recognition Outcomes in Cochlear Implant Recipients: Development, Validation, and Comparison with Expert Clinical Judgment" Journal of Clinical Medicine 14, no. 11: 3625. https://doi.org/10.3390/jcm14113625
APA StyleDemyanchuk, A., Kludt, E., Lenarz, T., & Büchner, A. (2025). A Machine Learning Model to Predict Postoperative Speech Recognition Outcomes in Cochlear Implant Recipients: Development, Validation, and Comparison with Expert Clinical Judgment. Journal of Clinical Medicine, 14(11), 3625. https://doi.org/10.3390/jcm14113625