Clinical and Surgical Applications of Large Language Models: A Systematic Review

 ,
,  , ,
, ,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Search Strategy
2.2. Data Sources and Databases Searched
2.3. Study Eligibility and Selection Process
2.4. Data Collection and Synthesis
3. Results
Characteristics of Included Studies
4. Discussion
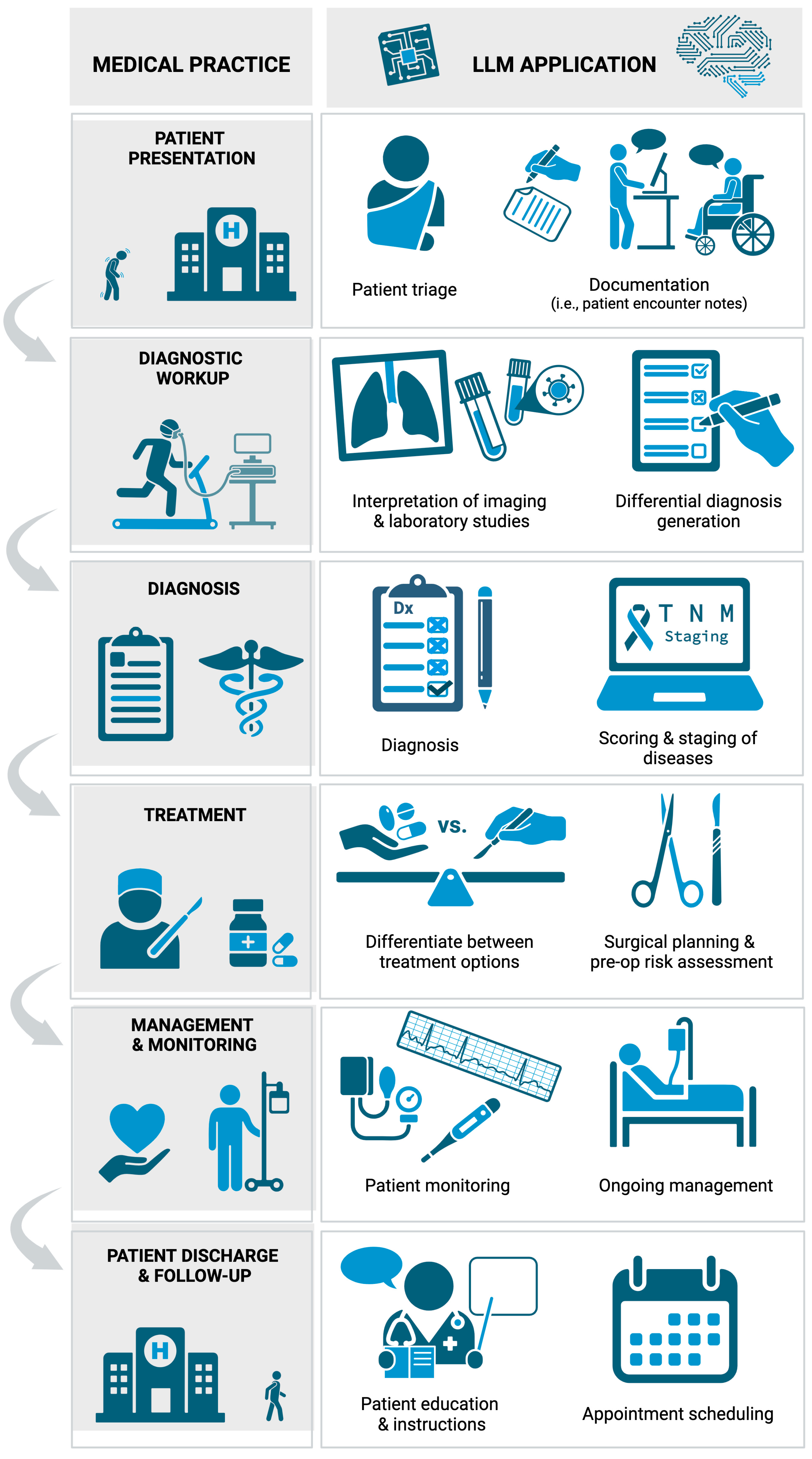
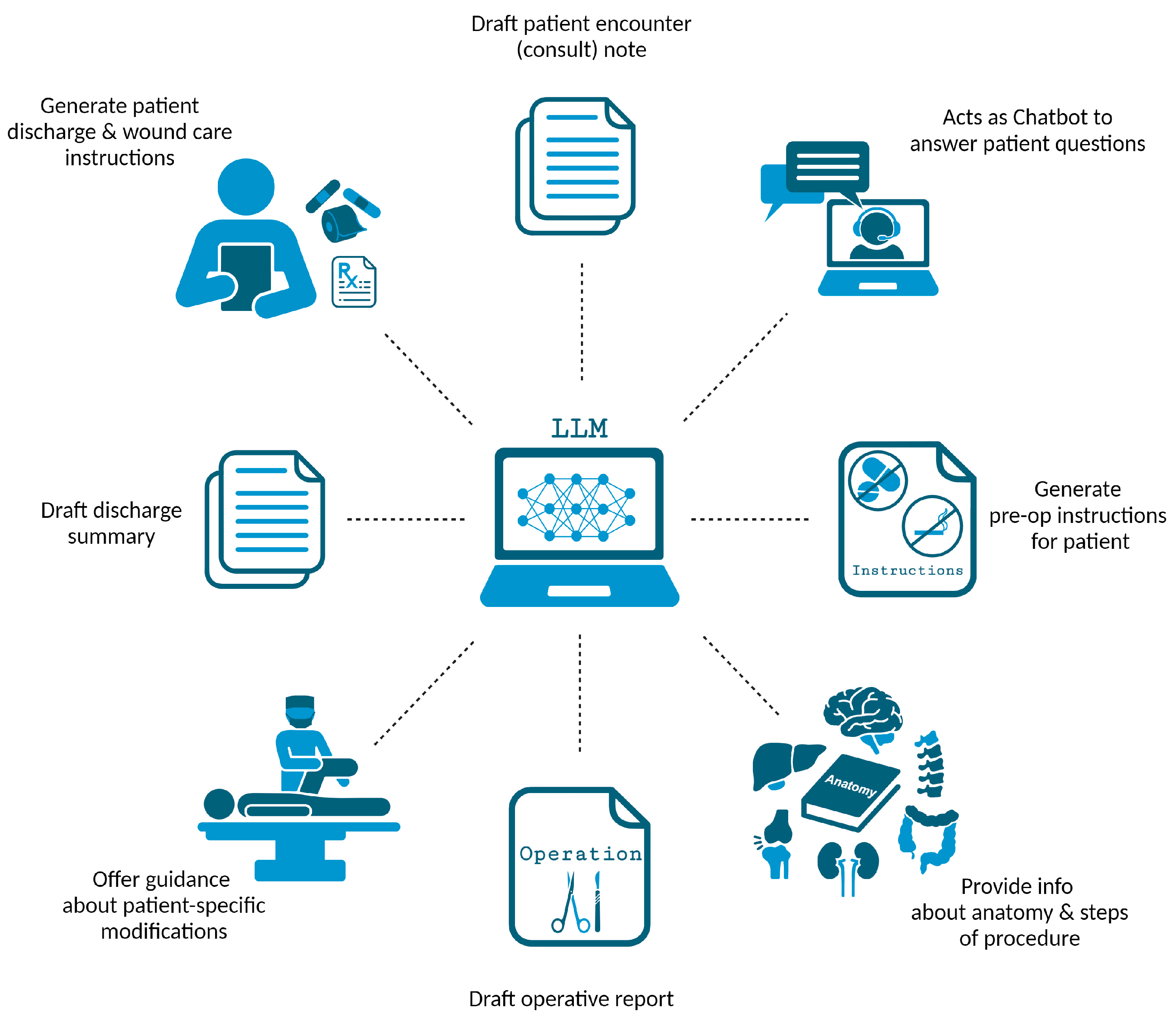
4.1. Applications of LLMs in Clinical Settings
4.2. Applications of LLMs in Surgical Settings
4.3. Additional LLM Applications in Recent Research
4.4. Non-Clinical Applications of LLMs in Healthcare
4.5. Limitations of LLMs in Healthcare
4.6. Limitations of This Systematic Review
4.7. Future Directions and Recommendations
- Enhancing Accuracy and Reducing Biases. Future research must prioritize the enhancement of LLM accuracy, particularly in clinical diagnosis and management recommendations. Efforts should be directed towards minimizing the occurrence of artificial “hallucinations” and ensuring that the information provided is current, accurate, and evidence-based. Additionally, addressing biases in training datasets is crucial to prevent the perpetuation of discriminatory practices and to ensure equitable healthcare outcomes. This involves diversifying data sources, implementing debiasing methods, and continuously monitoring for bias.
- Expanding Clinical and Surgical Applications. There is a need for further exploration into the potential applications of LLMs within more specialized medical fields and complex clinical scenarios. Future studies should investigate the integration of LLMs in managing rare diseases and complex cases, as well as providing support in high-stakes surgical planning and decision-making. Research should also explore the feasibility and impact of LLMs in supporting emergency care settings, where rapid and accurate decision-making is critical.
- Integrating LLMs with Healthcare Systems. Future steps should include the development of interoperable systems that seamlessly integrate LLMs with existing electronic health records. Additionally, future steps should focus on developing secure, HIPAA-compliant, and user-friendly interfaces.
- Addressing Ethical Concerns. Efforts to resolve ethical concerns related to patient confidentiality, informed consent, and the potential for misinformation are necessary. These ethical concerns should be considered when guiding LLM development and deployment.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| CINAHL | Cumulative Index to Nursing and Allied Health Literature |
| EMBASE | Excerpta Medica Database |
| GCS | Glasgow Coma Scale |
| GPT | generative pre-trained transformer |
| HIPAA | Health Insurance Portability and Accountability Act |
| LLM | large language model |
| LSS | lumbar spinal stenosis |
| MS AUC | Mohs surgery appropriate use criteria |
| NASS | North American Spine Society |
| NLP | natural language processing |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| USMLE | United States Medical Licensing Examination |
References
- Hamet, P.; Tremblay, J. Artificial intelligence in medicine. Metabolism 2017, 69, S36–S40. [Google Scholar] [CrossRef] [PubMed]
- Manning, C. Artificial Intelligence Definitions. Stanford University Human-Centered Artificial Intelligence. Available online: https://hai.stanford.edu/sites/default/files/2020-09/AI-Definitions-HAI.pdf (accessed on 18 October 2023).
- Muftić, F.; Kadunić, M.; Mušinbegović, A.; Abd Almisreb, A. Exploring Medical Breakthroughs: A Systematic Review of ChatGPT Applications in Healthcare. Southeast Eur. J. Soft Comput. 2023, 12, 13–41. [Google Scholar] [CrossRef]
- Jin, Z. Analysis of the Technical Principles of ChatGPT and Prospects for Pre-trained Large Models. In Proceedings of the 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 26–28 May 2023; pp. 1755–1758. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. Interspeech 2010, 2, 1045–1048. [Google Scholar]
- Abi-Rafeh, J.; Xu, H.H.; Kazan, R.; Tevlin, R.; Furnas, H. Large Language Models and Artificial Intelligence: A Primer for Plastic Surgeons on the Demonstrated & Potential Applications, Promises, and Limitations of ChatGPT. Aesthet. Surg. J. 2023, 44, 329–343. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M. ChatGPT utility in healthcare education, research, and practice: Systematic review on the promising perspectives and valid concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Tustumi, F.; Andreollo, N.A.; de Aguilar-Nascimento, J.E. Future of the Language Models in Healthcare: The Role of ChatGPT. Review. ABCD-Arq. Bras. Cir. Dig.-Braz. Arch. Dig. Surg. 2023, 36, e1727. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT. Available online: https://chat.openai.com/chat (accessed on 21 September 2023).
- Deng, J.; Lin, Y. The Benefits and Challenges of ChatGPT: An Overview. Front. Comput. Intell. Syst. 2023, 2, 81–83. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Zhang, Y.; Pei, H.; Zhen, S.; Li, Q.; Liang, F. Chat Generative Pre-Trained Transformer (ChatGPT) usage in healthcare. Gastroenterol. Endosc. 2023, 1, 139–143. [Google Scholar] [CrossRef]
- Bohr, A.; Memarzadeh, K. The rise of artificial intelligence in healthcare applications. In Artificial Intelligence in Healthcare; Elsevier: Amsterdam, The Netherlands, 2020; pp. 25–60. [Google Scholar]
- Jiang, F.; Jiang, Y.; Zhi, H.; Dong, Y.; Li, H.; Ma, S.; Wang, Y.; Dong, Q.; Shen, H.; Wang, Y. Artificial intelligence in healthcare: Past, present and future. Stroke Vasc. Neurol. 2017, 2, 230–243. [Google Scholar] [CrossRef]
- Yin, J.; Ngiam, K.Y.; Teo, H.H. Role of Artificial Intelligence Applications in Real-Life Clinical Practice: Systematic Review. J. Med. Internet Res. 2021, 23, e25759. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.-H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef] [PubMed]
- Argentiero, A.; Muscogiuri, G.; Rabbat, M.G.; Martini, C.; Soldato, N.; Basile, P.; Baggiano, A.; Mushtaq, S.; Fusini, L.; Mancini, M.E. The Applications of Artificial Intelligence in Cardiovascular Magnetic Resonance-A Comprehensive Review. J. Clin. Med. 2022, 11, 2866. [Google Scholar] [CrossRef] [PubMed]
- Tran, B.X.; Latkin, C.A.; Vu, G.T.; Nguyen, H.L.T.; Nghiem, S.; Tan, M.-X.; Lim, Z.-K.; Ho, C.S.; Ho, R.C. The Current Research Landscape of the Application of Artificial Intelligence in Managing Cerebrovascular and Heart Diseases: A Bibliometric and Content Analysis. Int. J. Environ. Res. Public Health 2019, 16, 2699. [Google Scholar] [CrossRef] [PubMed]
- Uzun Ozsahin, D.; Ikechukwu Emegano, D.; Uzun, B.; Ozsahin, I. The systematic review of artificial intelligence applications in breast cancer diagnosis. Diagnostics 2022, 13, 45. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Weng, Y.; Lund, J. Applications of explainable artificial intelligence in diagnosis and surgery. Diagnostics 2022, 12, 237. [Google Scholar] [CrossRef] [PubMed]
- Page, M.J.; Moher, D.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. PRISMA 2020 explanation and elaboration: Updated guidance and exemplars for reporting systematic reviews. BMJ 2021, 372, n160. [Google Scholar] [CrossRef] [PubMed]
- Asch, D.A. An interview with ChatGPT about health care. NEJM Cat. 2023, 4, 1–8. [Google Scholar]
- Bugaj, M.; Kliestik, T.; Lăzăroiu, G. Generative Artificial Intelligence-based Diagnostic Algorithms in Disease Risk Detection, in Personalized and Targeted Healthcare Procedures, and in Patient Care Safety and Quality. Contemp. Read. Law Soc. Justice 2023, 15, 9–26. [Google Scholar] [CrossRef]
- Cadamuro, J.; Cabitza, F.; Debeljak, Z.; De Bruyne, S.; Frans, G.; Perez, S.M.; Ozdemir, H.; Tolios, A.; Carobene, A.; Padoan, A. Potentials and pitfalls of ChatGPT and natural-language artificial intelligence models for the understanding of laboratory medicine test results. An assessment by the European Federation of Clinical Chemistry and Laboratory Medicine (EFLM) Working Group on Artificial Intelligence (WG-AI). Clin. Chem. Lab. Med. 2023, 61, 1158–1166. [Google Scholar] [CrossRef]
- Chen, T.C.; Kaminski, E.; Koduri, L.; Singer, A.; Singer, J.; Couldwell, M.; Delashaw, J.; Dumont, A.; Wang, A. Chat GPT as a Neuro-score Calculator: Analysis of a large language model’s performance on various neurological exam grading scales. World Neurosurg. 2023, 179, e342–e347. [Google Scholar] [CrossRef] [PubMed]
- Cheng, K.; Li, Z.; He, Y.; Guo, Q.; Lu, Y.; Gu, S.; Wu, H. Potential Use of Artificial Intelligence in Infectious Disease: Take ChatGPT as an Example. Ann. Biomed. Eng. 2023, 51, 1130–1135. [Google Scholar] [CrossRef] [PubMed]
- Chiesa-Estomba, C.M.; Lechien, J.R.; Vaira, L.A.; Brunet, A.; Cammaroto, G.; Mayo-Yanez, M.; Sanchez-Barrueco, A.; Saga-Gutierrez, C. Exploring the potential of Chat-GPT as a supportive tool for sialendoscopy clinical decision making and patient information support. Eur. Arch. Otorhinolaryngol. 2023, 281, 2081–2086. [Google Scholar] [CrossRef] [PubMed]
- Daher, M.; Koa, J.; Boufadel, P.; Singh, J.; Fares, M.Y.; Abboud, J. Breaking Barriers: Can ChatGPT Compete with a Shoulder and Elbow Specialist in Diagnosis and Management? JSES Int. 2023, 7, 2534–2541. [Google Scholar] [CrossRef] [PubMed]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef] [PubMed]
- Duey, A.H.; Nietsch, K.S.; Zaidat, B.; Ren, R.; Ndjonko, L.C.M.; Shrestha, N.; Rajjoub, R.; Ahmed, W.; Hoang, T.; Saturno, M.P.; et al. Thromboembolic prophylaxis in spine surgery: An analysis of ChatGPT recommendations. Spine J. 2023, 23, 1684–1691. [Google Scholar] [CrossRef] [PubMed]
- Gala, D.; Makaryus, A.N. The Utility of Language Models in Cardiology: A Narrative Review of the Benefits and Concerns of ChatGPT-4. Int. J. Environ. Res. Public Health 2023, 20, 6438. [Google Scholar] [CrossRef]
- Gebrael, G.; Sahu, K.K.; Chigarira, B.; Tripathi, N.; Mathew Thomas, V.; Sayegh, N.; Maughan, B.L.; Agarwal, N.; Swami, U.; Li, H. Enhancing Triage Efficiency and Accuracy in Emergency Rooms for Patients with Metastatic Prostate Cancer: A Retrospective Analysis of Artificial Intelligence-Assisted Triage Using ChatGPT 4.0. Cancers 2023, 15, 3717. [Google Scholar] [CrossRef] [PubMed]
- Grupac, M.; Zauskova, A.; Nica, E. Generative Artificial Intelligence-based Treatment Planning in Clinical Decision-Making, in Precision Medicine, and in Personalized Healthcare. Contemp. Read. Law Soc. Justice 2023, 15, 46–62. [Google Scholar] [CrossRef]
- Haemmerli, J.; Sveikata, L.; Nouri, A.; May, A.; Egervari, K.; Freyschlag, C.; Lobrinus, J.A.; Migliorini, D.; Momjian, S.; Sanda, N.; et al. ChatGPT in glioma adjuvant therapy decision making: Ready to assume the role of a doctor in the tumour board? BMJ Health Care Inform. 2023, 30, e100775. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Singh, R.P. ChatGPT for healthcare services: An emerging stage for an innovative perspective. BenchCouncil Trans. Benchmarks Stand. Eval. 2023, 3, 100105. [Google Scholar] [CrossRef]
- Kottlors, J.; Bratke, G.; Rauen, P.; Kabbasch, C.; Persigehl, T.; Schlamann, M.; Lennartz, S. Feasibility of differential diagnosis based on imaging patterns using a large language model. Radiology 2023, 308, e231167. [Google Scholar] [CrossRef]
- O’Hern, K.; Yang, E.; Vidal, N.Y. ChatGPT underperforms in triaging appropriate use of Mohs surgery for cutaneous neoplasms. JAAD Int. 2023, 12, 168–170. [Google Scholar] [CrossRef] [PubMed]
- Qu, R.W.; Qureshi, U.; Petersen, G.; Lee, S.C. Diagnostic and Management Applications of ChatGPT in Structured Otolaryngology Clinical Scenarios. OTO Open 2023, 7, e67. [Google Scholar] [CrossRef] [PubMed]
- Rajjoub, R.; Arroyave, J.S.; Zaidat, B.; Ahmed, W.; Mejia, M.R.; Tang, J.; Kim, J.S.; Cho, S.K. ChatGPT and its Role in the Decision-Making for the Diagnosis and Treatment of Lumbar Spinal Stenosis: A Comparative Analysis and Narrative Review. Glob. Spine J. 2023, 14, 998–1017. [Google Scholar] [CrossRef]
- Ravipati, A.; Pradeep, T.; Elman, S.A. The role of artificial intelligence in dermatology: The promising but limited accuracy of ChatGPT in diagnosing clinical scenarios. Int. J. Dermatol. 2023, 62, e547–e548. [Google Scholar] [CrossRef]
- Rizwan, A.; Sadiq, T. The Use of AI in Diagnosing Diseases and Providing Management Plans: A Consultation on Cardiovascular Disorders With ChatGPT. Cureus 2023, 15, e43106. [Google Scholar] [CrossRef]
- Schukow, C.; Smith, S.C.; Landgrebe, E.; Parasuraman, S.; Folaranmi, O.O.; Paner, G.P.; Amin, M.B. Application of ChatGPT in Routine Diagnostic Pathology: Promises, Pitfalls, and Potential Future Directions. Adv. Anat. Pathol. 2023, 31, 15–21. [Google Scholar] [CrossRef]
- Sharma, S.C.; Ramchandani, J.P.; Thakker, A.; Lahiri, A. ChatGPT in Plastic and Reconstructive Surgery. Indian. J. Plast. Surg. 2023, 56, 320–325. [Google Scholar] [CrossRef]
- Sorin, V.; Klang, E.; Sklair-Levy, M.; Cohen, I.; Zippel, D.B.; Balint Lahat, N.; Konen, E.; Barash, Y. Large language model (ChatGPT) as a support tool for breast tumor board. NPJ Breast Cancer 2023, 9, 44. [Google Scholar] [CrossRef]
- Srivastav, S.; Chandrakar, R.; Gupta, S.; Babhulkar, V.; Agrawal, S.; Jaiswal, A.; Prasad, R.; Wanjari, M.B. ChatGPT in Radiology: The Advantages and Limitations of Artificial Intelligence for Medical Imaging Diagnosis. Cureus 2023, 15, e41435. [Google Scholar] [CrossRef]
- Vaira, L.A.; Lechien, J.R.; Abbate, V.; Allevi, F.; Audino, G.; Beltramini, G.A.; Bergonzani, M.; Bolzoni, A.; Committeri, U.; Crimi, S.; et al. Accuracy of ChatGPT-Generated Information on Head and Neck and Oromaxillofacial Surgery: A Multicenter Collaborative Analysis. Otolaryngol. Head Neck Surg. 2023, 170, 1492–1503. [Google Scholar] [CrossRef] [PubMed]
- Xiao, D.; Meyers, P.; Upperman, J.S.; Robinson, J.R. Revolutionizing Healthcare with ChatGPT: An Early Exploration of an AI Language Model’s Impact on Medicine at Large and its Role in Pediatric Surgery. J. Pediatr. Surg. 2023, 58, 2410–2415. [Google Scholar] [CrossRef] [PubMed]
- Xv, Y.; Peng, C.; Wei, Z.; Liao, F.; Xiao, M. Can Chat-GPT a substitute for urological resident physician in diagnosing diseases?: A preliminary conclusion from an exploratory investigation. World J. Urol. 2023, 41, 2569–2571. [Google Scholar] [CrossRef] [PubMed]
- Atkinson, D. Generative Artificial Intelligence-based Treatment Planning in Patient Consultation and Support, in Digital Health Interventions, and in Medical Practice and Education. Contemp. Read. Law Soc. Justice 2023, 15, 134–151. [Google Scholar] [CrossRef]
- Cresswell, A.; Hart, M.; Suchanek, O.; Young, T.; Leaver, L.; Hibbs, S. Mind the gap: Improving discharge communication between secondary and primary care. BMJ Qual. Improv. Rep. 2015, 4, u207936.w3197. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.J. ChatGPT and Lacrimal Drainage Disorders: Performance and Scope of Improvement. Ophthalmic Plast. Reconstr. Surg. 2023, 39, 221–225. [Google Scholar] [CrossRef] [PubMed]
- Mert, S.; Stoerzer, P.; Brauer, J.; Fuchs, B.; Haas-Lützenberger, E.M.; Demmer, W.; Giunta, R.E.; Nuernberger, T. Diagnostic power of ChatGPT 4 in distal radius fracture detection through wrist radiographs. Arch. Orthop. Trauma. Surg. 2024, 144, 2461–2467. [Google Scholar] [CrossRef] [PubMed]
- Pressman, S.M.; Borna, S.; Gomez-Cabello, C.A.; Haider, S.A.; Forte, A.J. AI in Hand Surgery: Assessing Large Language Models in the Classification and Management of Hand Injuries. J. Clin. Med. 2024, 13, 2832. [Google Scholar] [CrossRef]
- Gengatharan, D.; Saggi, S.S.; Bin Abd Razak, H.R. Pre-operative Planning of High Tibial Osteotomy With ChatGPT: Are We There Yet? Cureus 2024, 16, e54858. [Google Scholar] [CrossRef]
- Ćirković, A.; Katz, T. Exploring the Potential of ChatGPT-4 in Predicting Refractive Surgery Categorizations: Comparative Study. JMIR Form. Res. 2023, 7, e51798. [Google Scholar] [CrossRef] [PubMed]
- Najafali, D.; Galbraith, L.G.; Camacho, J.M.; Arnold, S.H.; Alperovich, M.; King, T.W.; Cohen, M.S.; Morrison, S.D.; Dorafshar, A.H. Addressing the Rhino in the Room: ChatGPT Creates "Novel" Patent Ideas for Rhinoplasty. Eplasty 2024, 24, e13. [Google Scholar] [PubMed]
- Milne-Ives, M.; de Cock, C.; Lim, E.; Shehadeh, M.H.; de Pennington, N.; Mole, G.; Normando, E.; Meinert, E. The Effectiveness of Artificial Intelligence Conversational Agents in Health Care: Systematic Review. J. Med. Internet Res. 2020, 22, e20346. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, S.; Harvey, H.; Melvin, T.; Vollebregt, E.; Wicks, P. Large language model AI chatbots require approval as medical devices. Nat. Med. 2023, 29, 2396–2398. [Google Scholar] [CrossRef] [PubMed]
- Caruccio, L.; Cirillo, S.; Polese, G.; Solimando, G.; Sundaramurthy, S.; Tortora, G. Can ChatGPT provide intelligent diagnoses? A comparative study between predictive models and ChatGPT to define a new medical diagnostic bot. Expert. Syst. Appl. 2024, 235, 121186. [Google Scholar] [CrossRef]
- Pressman, S.M.; Borna, S.; Gomez-Cabello, C.A.; Haider, S.A.; Haider, C.; Forte, A.J. AI and Ethics: A Systematic Review of the Ethical Considerations of Large Language Model Use in Surgery Research. Healthcare 2024, 12, 825. [Google Scholar] [CrossRef]
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, D.J.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 2023, 183, 589–596. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First Author | Specialty | Study Design | Objective/Purpose | Main Clinical Application(s) of LLMs | Main Limitation(s) of LLMs | Conclusions |
|---|---|---|---|---|---|---|
| Abi-Rafeh et al. [6] | Plastic surgery | Systematic review of 175 articles | To demonstrate the current and potential clinical uses of ChatGPT in plastic surgery. | Augment clinician knowledge by providing evidence-based recommendations. Assist in clinical note writing, patient triage, interpreting imaging and lab findings, informed consent, and preoperative risk assessment. | Accuracy, reliability, and completeness of provided information. Lack of transparency. Difficulty with interpersonal communication. | Thorough research of proposed applications and limitations of ChatGPT is needed before widespread use in plastic surgery. |
| Ali [6] | Ophthalmic plastic surgery | Evaluative study | To assess ChatGPT performance regarding lacrimal drainage disorders. | Provide evidence-based information regarding lacrimal drainage disorders. | Content quality relies on training data, impacting accuracy and reliability. Responses may be outdated, verbose, and generic, with potential for discriminatory content. Absence of accountability. | ChatGPT shows average performance in addressing lacrimal drainage disorders yet holds significant potential, necessitating additional development. |
| Asch [22] | Nonspecific | Interview | To explore ChatGPT’s applications, limitations, and potential impact in healthcare. | Operate as virtual assistants that can answer patient questions, schedule appointments, and provide remote consultations. Expedite the diagnostic process and personalize healthcare. Automate clinical documentation such as medical charts and progress notes. | Data privacy, security, and lack of regulation. Biased responses due to biased data. Interpretability and lack of transparency. Lack of human interaction. | ChatGPT has the potential to improve healthcare delivery, but careful consideration of its challenges and concerns is required before its implementation. |
| Atkinson [22] | Nonspecific | Systematic review of 34 articles | To explore how Generative AI like ChatGPT can improve medical practice and education. | Improve patient consultations and provide personalized patient care. Streamline physician workflow. Assist in decision-making relating to diagnosis and treatment. | Not adequately discussed. | ChatGPT has potential in healthcare by assisting in diagnosis and management. |
| Bugaj et al. [23] | Nonspecific | Systematic review of 32 articles | To offer insights into the effect of generative AI-based diagnostic algorithms on patient care based on recent literature. | Assist in clinical decision-making to improve patient care. | Not adequately discussed. | Generative AI, such as ChatGPT, can assess patients and contribute to medical decision-making, resulting in enhanced patient care. |
| Cadamuro et al. [24] | Laboratory medicine | Evaluative study | To assess ChatGPT’s ability to interpret laboratory results. | Interpret laboratory test results and offer insights regarding deviations. Determine the need for further examination and physician consultation. | Misleading, superficial, and indefinite interpretations. Reluctance to make follow-up recommendations. | ChatGPT can analyze laboratory reports test by test but currently falls short in contextual diagnostic interpretation. |
| Chen et al. [25] | Neurosurgery | Evaluative study | To evaluate ChatGPT’s ability to assess stroke patients using neurologic scoring systems. | Use established neurologic assessment scales to perform neurologic evaluations. | Accuracy and “hallucinations”. Struggles with complex scenarios. | ChatGPT has potential to assist neurologic evaluations by using established assessment scales. However, occasional inaccurate or “hallucinated” responses currently render it inappropriate for clinical use. |
| Cheng et al. [26] | Infectious disease | Letter to the Editor | To assess the application of ChatGPT in clinical practice and research within the context of infectious disease. | Disseminate up-to-date information and assist in diagnosis, treatment, and risk assessment. Support telemedicine. Aid in infectious disease surveillance. | Inaccurate or vague answers without references. Regulations. | While ChatGPT holds promise as a tool for clinicians in infectious disease, further development is essential for effective use. |
| Chiesa-Estomba et al. [27] | Otolaryngology | Prospective cross-sectional study | To evaluate ChatGPT’s capacity to improve management of salivary gland disorders and patient education. | Clinical decision support regarding treatment. | Can produce inaccurate or biased responses. Lack of direct healthcare professional interaction. | ChatGPT shows promise in aiding clinical decision-making and patient information in the salivary gland clinic but needs further development for reliability. |
| Daher et al. [28] | Orthopedic surgery | Evaluative study | To explore ChatGPT’s potential to diagnose and manage shoulder and elbow complaints. | Diagnosis and management of patients with shoulder and elbow complaints. First consultation resource for primary physicians. | Inaccurate responses. Dependence on imaging results. Lack of up-to-date information. | With its limitations, ChatGPT currently cannot replace a shoulder and elbow specialist in diagnosing and treating patients. |
| Dave et al. [29] | Nonspecific | Mini review | To explore the practical applications, limitations, and ethical implications of ChatGPT use in healthcare. | Augment a healthcare professional’s knowledge. Assist in generating notes to streamline medical recordkeeping. Assist in diagnosis and clinical decision support. | Can produce inaccurate or biased responses. Potential copyright infringement and other medico-legal issues. | ChatGPT has valuable healthcare applications, but addressing limitations and ethical concerns is essential for effective implementation. |
| Duey et al. [30] | Orthopedic surgery | Comparative study | To evaluate ChatGPT’s recommendations compared to NASS clinical guidelines regarding thromboembolic prophylaxis for spine surgery. | Perioperative management, specifically thromboembolic prophylaxis recommendations for spine surgery. | Provide recommendations that are incomplete or overly definitive. | ChatGPT shows reasonable alignment with NASS guidelines but requires further refinement for clinical reliability. |
| Gala and Makaryus [31] | Cardiology | Review | To explore potential applications of LLMs like ChatGPT-4 in cardiology. | Assist in diagnosis and medical decision-making. Facilitate administrative tasks such as documentation. | Provide outdated responses. Lack of contextual understanding. Potential to increase healthcare costs. Lack of accessibility. Lack of human touch and empathy. | ChatGPT has the potential to improve patient outcomes in cardiology. However, limitations and ethical concerns must be addressed for safe use. |
| Gebrael et al. [32] | Emergency medicine | Retrospective analysis | To evaluate ChatGPT-4’s ability to triage patients with metastatic prostate cancer in the ER. | Analyze patient information to assist in decision-making. | Can produce biased or “hallucinated” responses. Poor disease severity predicting ability. Regulations like HIPAA. | ChatGPT holds promise in enhancing decision-making, such as ER triage, and improving patient care efficiency, but needs refinement for reliable clinical use. |
| Grupac et al. [33] | Nonspecific | Systematic review of 40 articles | To explore applications of generative AI-based diagnostic algorithms in disease risk detection, personalized healthcare, and patient care. | Augment a clinician’s knowledge by summarizing the literature and clinical guidelines to offer evidence-based recommendations. Assist in clinical decision support regarding diagnosis and treatment. Aid in patient monitoring. | Not adequately discussed. | ChatGPT has potential to provide accurate medical information, supporting clinical decisions, but further exploration is required to assess its limitations and enhance its reliability. |
| Haemmerli et al. [34] | Neuro-oncology | Evaluative study | To evaluate ChatGPT’s decision-making performance regarding adjuvant therapy for brain glioma. | Provide recommendations for treatment options. | Provide inaccurate, hallucinated, or outdated responses. Can make ineffective or harmful recommendations. Can struggle to accurately identify glioma subtype and consider functional status. | ChatGPT has potential as a supplemental tool by providing valuable adjuvant treatment recommendations, but has limitations. |
| Javaid et al. [35] | Nonspecific | Literature review | To explore applications of ChatGPT within healthcare. | Can access patient information to provide medical suggestions and counseling. Develop patient-specific treatment programs. Offer medication reminders and assist in remote patient monitoring. Schedule appointments. | Can produce inaccurate or biased responses, thereby spreading misinformation. Ethical and privacy concerns. Can struggle with complex or abstract scenarios. | ChatGPT shows promise in various healthcare applications. However, addressing limitations is crucial for maximizing its potential. |
| Kottlors et al. [36] | Radiology | Evaluative study | To evaluate GPT-4’s ability to generate differential diagnoses based on imaging patterns. | Generate differential diagnoses based on medical imaging. | Lack of transparency. Verification of references. | LLMs like ChatGPT-4 can provide differential diagnoses based on imaging patterns, ultimately showing promise in diagnostic decision-making. |
| Muftić et al. [3] | Nonspecific | Systematic review of 31 articles | To explore ChatGPT’s ability to streamline tasks, optimize clinical decision-making, and facilitate communication, ultimately improving patient care. | Facilitate inter-professional communication. Assist in clinical decision-making to improve patient care. | Can produce inaccurate or biased responses. Can struggle with prompts that are lengthy, image-based, in a different language, or contain medical terminology. Patient privacy. | ChatGPT holds promise in diverse medical applications, but addressing challenges and limitations is essential for safe implementation in healthcare. |
| O’Hern et al. [37] | Dermatology | Letter to the Editor | To assess ChatGPT’s ability to effectively triage surgical management for patients with cutaneous neoplasms. | Triage patients with cutaneous neoplasms and guide treatment. | ChatGPT was not designed for medical use. Limited congruency with established guidelines (e.g., MS AUC). | ChatGPT demonstrates limited proficiency in triaging surgical options for cutaneous neoplasms, highlighting the importance of cautious application in clinical decision-making. |
| Qu et al. [38] | Otolaryngology | Cross-sectional survey | To assess ChatGPT’s clinical applications and limitations within otolaryngology. | Support diagnosis and management in otolaryngology. | Responses may be inaccurate, “hallucinated”, biased, or outdated. | ChatGPT can provide differential diagnoses and treatment options in otolaryngology, however limitations must be addressed. |
| Rajjoub et al. [39] | Spine surgery | Comparative analysis and narrative review | To evaluate ChatGPT’s recommendations compared to NASS clinical guidelines regarding diagnosis and treatment of degenerative LSS. | Assist in decision-making relating to diagnosis and treatment. | Responses may be inaccurate, “hallucinated”, biased, or nonspecific. | ChatGPT shows potential in assisting clinical decision-making for LSS diagnosis and treatment, but requires further standardization and validation. |
| Ravipati et al. [40] | Dermatology | Letter to the Editor | To evaluate ChatGPT’s accuracy and reliability in diagnosing dermatologic conditions. | Assist in diagnostic support for dermatologic conditions, such as generating differential diagnoses. | Responses may be inaccurate. Can struggle with prompts that are image-based. | ChatGPT demonstrates potential as a differential diagnosis generator, but requires refinement before its application in dermatology. |
| Rizwan and Sadiq [41] | Cardiology | Evaluative study | To investigate ChatGPT’s potential to assist providers with diagnosis and treatment of cardiovascular disorders. | Assist in decision-making relating to diagnosis and treatment of cardiovascular disease. | Not personalized, as responses can be nonspecific and incomplete. | ChatGPT can provide comprehensive, understandable responses with academic and clinical benefits, yet its limitations require attention. |
| Sallam [7] | Nonspecific | Systematic review of 60 articles | To examine ChatGPT’s utility and limitations within healthcare, research, and medical education. | Assist in decision-making relating to diagnosis and treatment. | Ethical, copyright, and transparency issues. Risks of bias, plagiarism, and inaccurate content. | ChatGPT has potential to streamline healthcare, but its adoption requires caution due to limitations and ethical considerations. |
| Schukow et al. [42] | Diagnostic pathology | Literature review | To explore ChatGPT’s potential advantages and disadvantages in diagnostic pathology. | Summarize diagnostic queries and enhance subspecialty inquiries. Assist in decision-making relating to diagnosis and treatment. | Responses may be incorrect and lack references. Patient privacy. | ChatGPT shows promise in diagnostic pathology, but its reliability and ethical use must be carefully considered. |
| Sharma et al. [43] | Plastic surgery | Literature review | To assess ChatGPT’s utility within plastic surgery. | Assist with clinical tasks and healthcare communication. | Responses may be incorrect or outdated, leading to misinformation. Plagiarism. Patient privacy. | ChatGPT can improve productivity in plastic surgery, but requires further development and cautious implementation. |
| Sorin et al. [44] | Oncology | Retrospective study | To assess ChatGPT’s role as a decision-making support tool for breast tumor boards. | Clinical decision support in breast tumor board meetings. Assist in summarizing patient cases and providing management recommendations. | Inconsistent recommendations. Biased responses due to biased data | ChatGPT has potential as a decision support tool, aligning with tumor board decisions, but further validation is required. |
| Srivastav et al. [45] | Radiology | Systematic review of 39 articles | To offer an overview of AI, particularly ChatGPT, in radiology and medical imaging diagnosis. | Enhance diagnostic accuracy and minimize errors to improve workflow efficiency. | Data quality and ethical concerns. | ChatGPT has potential to improve radiological diagnoses and patient care, but requires further research and development. |
| Tustumi et al. [8] | Gastrointestinal | Narrative review | To explore ChatGPT’s applications in disease diagnosis, treatment, prevention, and the development of clinical practice guidelines. | Can augment diagnostics and patient management. Can accelerate the creation of clinical practice guidelines. | Biased responses due to biased data. Need for human oversight. | While ChatGPT shows promise in healthcare, oversight and awareness of limitations is needed. Additionally, the model cannot replace healthcare professionals. |
| Vaira et al. [46] | Head and neck surgery | Observational and evaluative study | To evaluate ChatGPT’s accuracy in addressing head and neck surgery questions and clinical scenarios. | Assist in decision-making relating to diagnosis and treatment planning for head and neck surgery. Support patient counseling. | Inconsistent or incomplete recommendations. Lack of references. | ChatGPT shows promise in head and neck surgery but needs more development and validation to be a reliable decision aid. |
| Xiao et al. [47] | Pediatric surgery | Literature review | To explore ChatGPT’s potential in pediatric surgery research and practice. | Assist in decision-making relating to diagnosis and patient care. Facilitate administrative tasks such as documentation. | Responses may be inaccurate, unreliable, or outdated. Patient privacy. | ChatGPT offers potential in healthcare and pediatric surgery for efficiency and support, yet demands further development for effective integration. |
| Xv et al. [48] | Urology | Letter to the Editor | To evaluate ChatGPT’s ability to diagnose urinary diseases compared to urology residents. | Assist in the diagnosis of urinary system diseases. | Not adequately discussed. | ChatGPT can act as a supplementary tool for diagnosing common urinary diseases, supporting rather than substituting healthcare professionals. |
| Zhang et al. [12] | Gastrointestinal | Review | To explore ChatGPT’s applications and limitations in healthcare. | Enhance diagnostic accuracy and efficiency. Assist in treatment and patient care. Support public health initiatives. | Responses may be inaccurate or outdated, leading to misinformation. Patient privacy. | ChatGPT demonstrates potential in healthcare through professional support with reliable information, yet addressing its limitations is essential for widespread clinical use. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pressman, S.M.; Borna, S.; Gomez-Cabello, C.A.; Haider, S.A.; Haider, C.R.; Forte, A.J. Clinical and Surgical Applications of Large Language Models: A Systematic Review. J. Clin. Med. 2024, 13, 3041. https://doi.org/10.3390/jcm13113041
Pressman SM, Borna S, Gomez-Cabello CA, Haider SA, Haider CR, Forte AJ. Clinical and Surgical Applications of Large Language Models: A Systematic Review. Journal of Clinical Medicine. 2024; 13(11):3041. https://doi.org/10.3390/jcm13113041
Chicago/Turabian StylePressman, Sophia M., Sahar Borna, Cesar A. Gomez-Cabello, Syed Ali Haider, Clifton R. Haider, and Antonio Jorge Forte. 2024. "Clinical and Surgical Applications of Large Language Models: A Systematic Review" Journal of Clinical Medicine 13, no. 11: 3041. https://doi.org/10.3390/jcm13113041
APA StylePressman, S. M., Borna, S., Gomez-Cabello, C. A., Haider, S. A., Haider, C. R., & Forte, A. J. (2024). Clinical and Surgical Applications of Large Language Models: A Systematic Review. Journal of Clinical Medicine, 13(11), 3041. https://doi.org/10.3390/jcm13113041