Get Your Guidance Going: Investigating the Activation of Spatial Priors for Efficient Search in Virtual Reality


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Availability and Preregistration
2.2. Participants
2.3. Apparatus
2.4. Stimuli
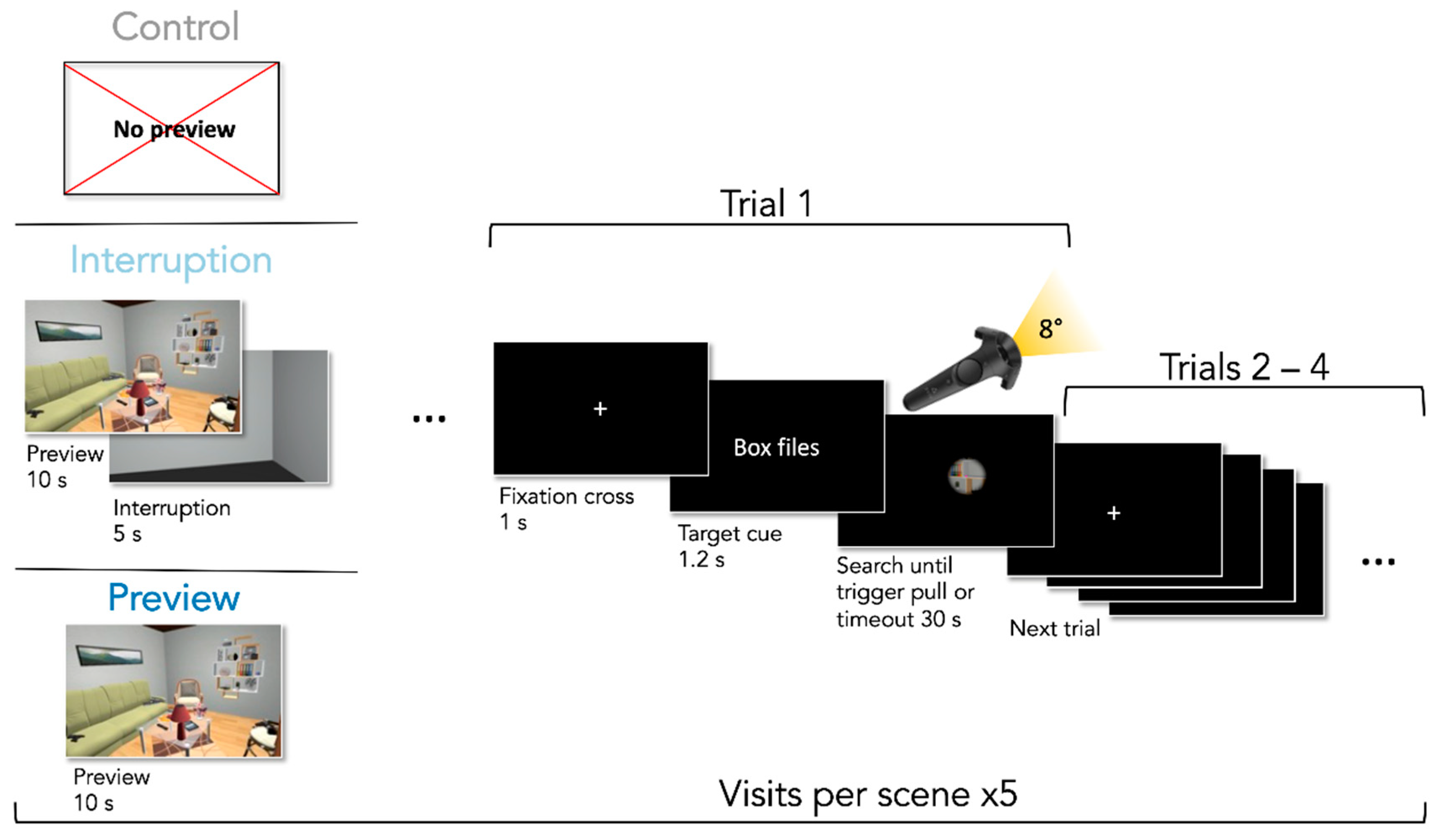
2.5. Experimental Design
2.6. Procedure
2.7. Data Analysis
3. Results
3.1. Preregistered Analyses
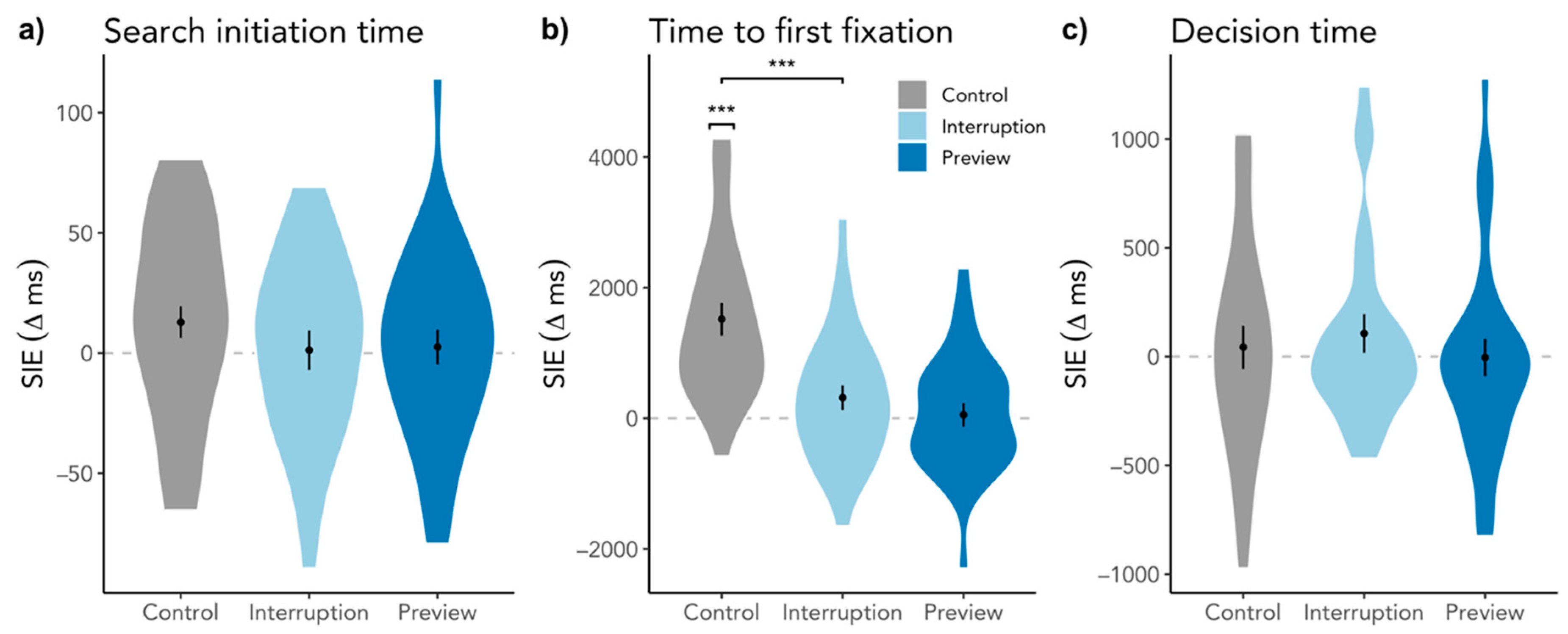
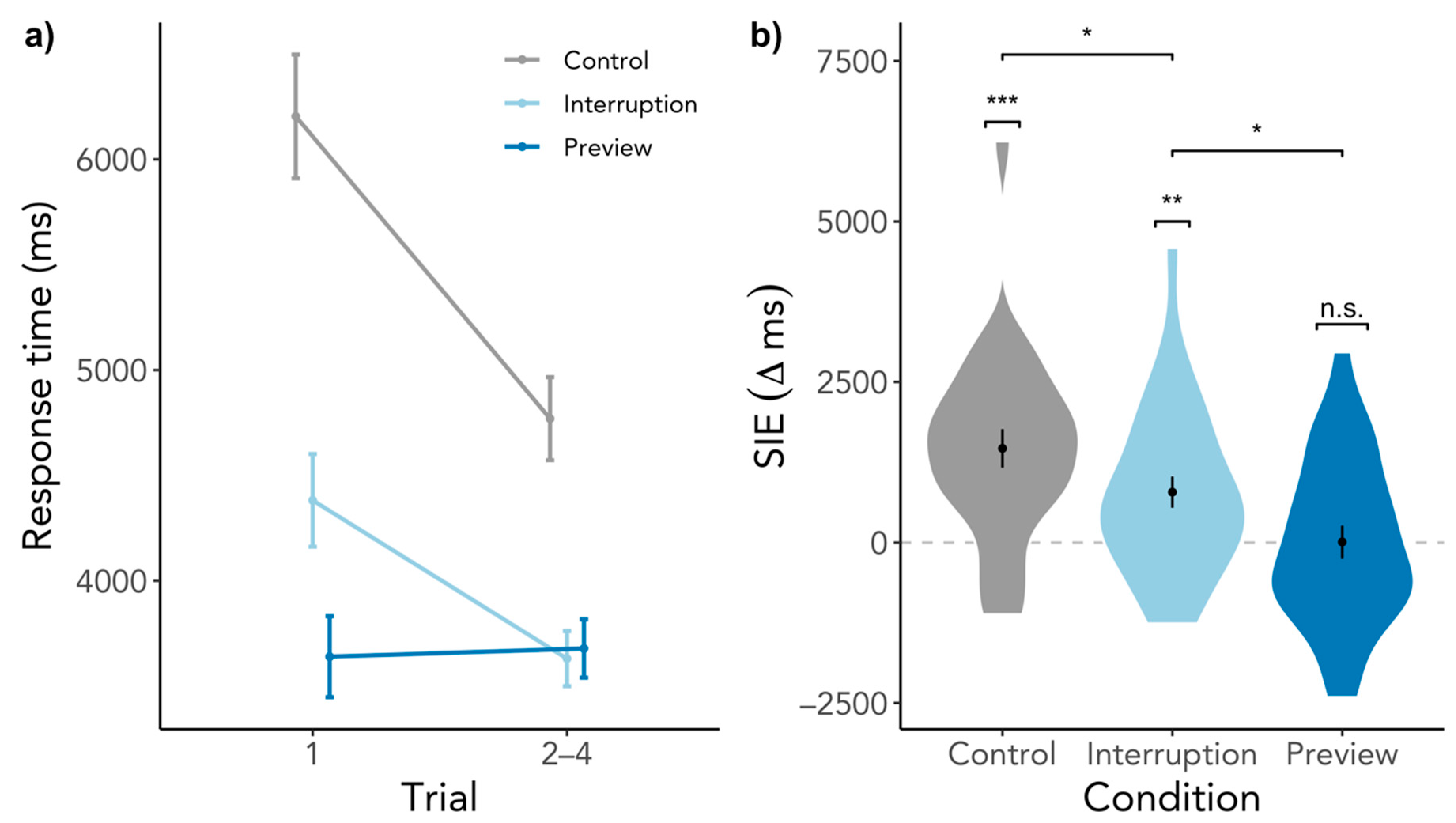
3.1.1. Search Initiation Effect in Response Time
3.1.2. Search Initiation Effect in Search Initiation Time and Time to First Target Fixation
3.2. Exploratory Analyses
3.2.1. Search Initiation Effect in Decision Time
3.2.2. Incidental Memory
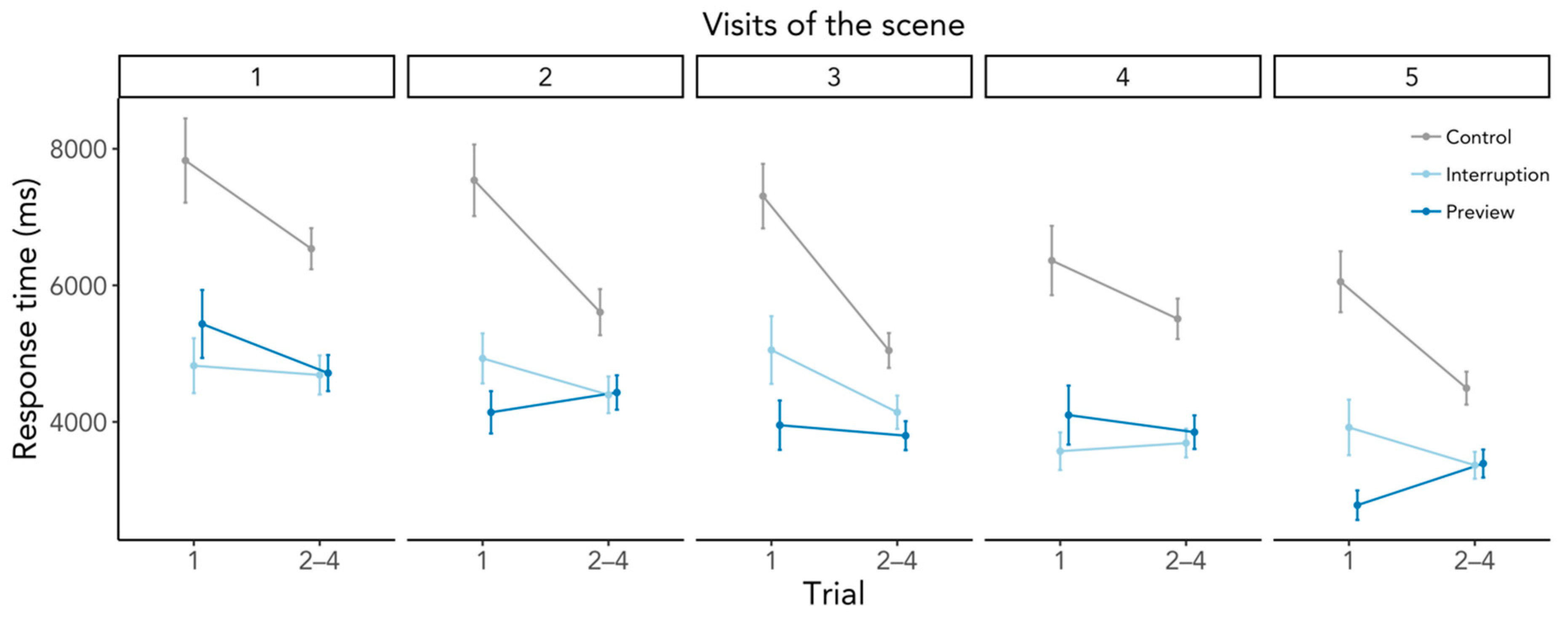
3.2.3. Preview Effects beyond the First Search
4. Discussion
5. Conclusion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Preregistered Analyses

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fixed Effects | β | SE | df | t | p |
|---|---|---|---|---|---|
| Interruption–Control | −1177.23 | 311.90 | 1770.61 | −3.77 | <0.001 |
| Preview–Interruption | −361.93 | 314.59 | 1774.10 | −1.15 | 0.250 |
| Scene revisit | −84.85 | 90.98 | 1772.03 | −0.93 | 0.351 |
| Fixed Effects | β | SE | df | t | p |
|---|---|---|---|---|---|
| Interruption–Control | −11.25 | 10.93 | 1630.40 | −1.03 | 0.303 |
| Preview–Interruption | 2.13 | 11.00 | 1755.21 | 0.19 | 0.846 |
| Scene revisit | 13.451 | 4.48 | 1761.26 | 3.00 | 0.003 |
| Fixed Effects | β | SE | df | t | p |
|---|---|---|---|---|---|
| Interruption–Control | 74.34 | 128.44 | 1654.55 | 0.58 | 0.563 |
| Preview–Interruption | −112.58 | 129.02 | 1742.88 | −0.87 | 0.383 |
| Scene revisit | 3.13 | 52.50 | 1743.09 | 0.06 | 0.952 |
Appendix B. Response Time as a Function of Scene Revisits

References
- Hayhoe, M.; Ballard, D. Modeling Task Control of Eye Movements. Curr. Biol. 2014, 24, R622–R628. [Google Scholar] [CrossRef] [PubMed]
- DiCarlo, J.J.; Zoccolan, D.; Rust, N.C. How Does the Brain Solve Visual Object Recognition? Neuron 2012, 73, 415–434. [Google Scholar] [CrossRef] [PubMed]
- Võ, M.L.-H.; Boettcher, S.E.; Draschkow, D. Reading Scenes: How Scene Grammar Guides Attention and Aids Perception in Real-World Environments. Curr. Opin. Psychol. 2019, 29, 205–210. [Google Scholar] [CrossRef] [PubMed]
- Nobre, A.C.; Stokes, M.G. Premembering Experience: A Hierarchy of Time-Scales for Proactive Attention. Neuron 2019, 104, 132–146. [Google Scholar] [CrossRef] [PubMed]
- Võ, M.L.-H.; Wolfe, J.M. The Role of Memory for Visual Search in Scenes. Ann. N. Y. Acad. Sci. 2015, 1339, 72–81. [Google Scholar] [CrossRef]
- Bar, M. Visual Objects in Context. Nat. Rev. Neurosci. 2004, 5, 617–629. [Google Scholar] [CrossRef] [PubMed]
- Hutchinson, J.B.; Turk-Browne, N.B. Memory-Guided Attention: Control from Multiple Memory Systems. Trends Cogn. Sci. 2012, 16, 576–579. [Google Scholar] [CrossRef] [PubMed]
- Võ, M.L.-H.; Wolfe, J.M. When Does Repeated Search in Scenes Involve Memory? Looking at versus Looking for Objects in Scenes. J. Exp. Psychol. Hum. Percept. Perform. 2012, 38, 23–41. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Võ, M.L.-H.; Evans, K.K.; Greene, M.R. Visual Search in Scenes Involves Selective and Nonselective Pathways. Trends Cogn. Sci. 2011, 15, 77–84. [Google Scholar] [CrossRef]
- Draschkow, D.; Wolfe, J.M.; Võ, M.L.-H. Seek and You Shall Remember: Scene Semantics Interact with Visual Search to Build Better Memories. J. Vis. 2014, 14, 10. [Google Scholar] [CrossRef] [PubMed]
- Draschkow, D.; Võ, M.L.-H. Of “What” and “Where” in a Natural Search Task: Active Object Handling Supports Object Location Memory beyond the Object’s Identity. Atten. Percept. Psychophys. 2016, 78, 1574–1584. [Google Scholar] [CrossRef] [PubMed]
- Helbing, J.; Draschkow, D.; Võ, M.L.-H. Search Superiority: Goal-Directed Attentional Allocation Creates More Reliable Incidental Identity and Location Memory than Explicit Encoding in Naturalistic Virtual Environments. Cognition 2020, 196, 104147. [Google Scholar] [CrossRef] [PubMed]
- Hollingworth, A. Task Specificity and the Influence of Memory on Visual Search: Commentary on Võ and Wolfe (2012). J. Exp. Psychol. Hum. Percept. Perform. 2012, 38, 1596–1603. [Google Scholar] [CrossRef] [PubMed]
- Hout, M.C.; Goldinger, S.D. Learning in Repeated Visual Search. Atten. Percept. Psychophys. 2010, 72, 1267–1282. [Google Scholar] [CrossRef] [PubMed]
- Wolfe, J.M.; Klempen, N.; Dahlen, K. Postattentive Vision. J. Exp. Psychol. Hum. Percept. Perform. 2000, 26, 693–716. [Google Scholar] [CrossRef] [PubMed]
- Chun, M.M.; Jiang, Y. Contextual Cueing: Implicit Learning and Memory of Visual Context Guides Spatial Attention. Cogn. Psychol. 1998, 36, 28–71. [Google Scholar] [CrossRef] [PubMed]
- Körner, C.; Gilchrist, I.D. Finding a New Target in an Old Display: Evidence for a Memory Recency Effect in Visual Search. Psychon. Bull. Rev. 2007, 14, 846–851. [Google Scholar] [CrossRef][Green Version]
- Kunar, M.A.; Flusberg, S.; Wolfe, J.M. The Role of Memory and Restricted Context in Repeated Visual Search. Percept. Psychophys. 2008, 70, 314–328. [Google Scholar] [CrossRef]
- Höfler, M.; Gilchrist, I.D.; Körner, C. Guidance toward and Away from Distractors in Repeated Visual Search. J. Vis. 2015, 15, 12. [Google Scholar] [CrossRef]
- Körner, C.; Gilchrist, I.D. Memory Processes in Multiple-Target Visual Search. Psychol. Res. 2008, 72, 99–105. [Google Scholar] [CrossRef]
- Hollingworth, A. Two Forms of Scene Memory Guide Visual Search: Memory for Scene Context and Memory for the Binding of Target Object to Scene Location. Vis. Cogn. 2009, 17, 273–291. [Google Scholar] [CrossRef]
- Hollingworth, A.; Henderson, J.M. Accurate Visual Memory for Previously Attended Objects in Natural Scenes. J. Exp. Psychol. Hum. Percept. Perform. 2002, 28, 113–136. [Google Scholar] [CrossRef]
- Boettcher, S.E.P.; Draschkow, D.; Dienhart, E.; Võ, M.L.-H. Anchoring Visual Search in Scenes: Assessing the Role of Anchor Objects on Eye Movements during Visual Search. J. Vis. 2018, 18, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Cornelissen, T.H.W.; Võ, M.L.-H. Stuck on Semantics: Processing of Irrelevant Object-Scene Inconsistencies Modulates Ongoing Gaze Behavior. Atten. Percept. Psychophys. 2017, 79, 154–168. [Google Scholar] [CrossRef] [PubMed]
- Draschkow, D.; Võ, M.L.-H. Scene Grammar Shapes the Way We Interact with Objects, Strengthens Memories, and Speeds Search. Sci. Rep. 2017, 7, 16471. [Google Scholar] [CrossRef]
- Draschkow, D.; Stänicke, D.; Võ, M.L.-H. All Beginnings Are Difficult: Repeated Search through Repeated Studies. In Proceedings of the Visual Search and Selective Attention (VSSA IV) Symposium, Munich, Germany, 13–16 June 2018. [Google Scholar]
- Wolfe, J.M.; Alvarez, G.A.; Rosenholtz, R.; Kuzmova, Y.I.; Sherman, A.M. Visual Search for Arbitrary Objects in Real Scenes. Atten. Percept. Psychophys. 2011, 73, 1650–1671. [Google Scholar] [CrossRef]
- Castelhano, M.S.; Henderson, J.M. Initial Scene Representations Facilitate Eye Movement Guidance in Visual Search. J. Exp. Psychol. Hum. Percept. Perform. 2007, 33, 753–763. [Google Scholar] [CrossRef]
- Võ, M.L.-H.; Henderson, J.M. The Time Course of Initial Scene Processing for Eye Movement Guidance in Natural Scene Search. J. Vis. 2010, 10, 1–13. [Google Scholar] [CrossRef]
- Võ, M.L.-H.; Schneider, W.X. A Glimpse Is Not a Glimpse: Differential Processing of Flashed Scene Previews Leads to Differential Target Search Benefits. Vis. Cogn. 2010, 18, 171–200. [Google Scholar] [CrossRef]
- Lowe, M.X.; Rajsic, J.; Ferber, S.; Walther, D.B. Discriminating Scene Categories from Brain Activity within 100 Milliseconds. Cortex 2018, 106, 275–287. [Google Scholar] [CrossRef]
- Greene, M.R.; Oliva, A. The Briefest of Glances: The Time Course of Natural Scene Understanding. Psychol. Sci. 2009, 20, 464–472. [Google Scholar] [CrossRef] [PubMed]
- Greene, M.R.; Oliva, A. Recognition of Natural Scenes from Global Properties: Seeing the Forest without Representing the Trees | Elsevier Enhanced Reader. Cognit. Psychol. 2009, 58, 137–176. [Google Scholar] [CrossRef] [PubMed]
- Peyrin, C.; Michel, C.M.; Schwartz, S.; Thut, G.; Seghier, M.; Landis, T.; Marendaz, C.; Vuilleumier, P. The Neural Substrates and Timing of Top–Down Processes during Coarse-to-Fine Categorization of Visual Scenes: A Combined FMRI and ERP Study. J. Cogn. Neurosci. 2010, 22, 2768–2780. [Google Scholar] [CrossRef] [PubMed]
- Võ, M.L.-H.; Henderson, J.M. Object–Scene Inconsistencies Do Not Capture Gaze: Evidence from the Flash-Preview Moving-Window Paradigm. Atten. Percept. Psychophys. 2011, 73, 1742–1753. [Google Scholar] [CrossRef] [PubMed]
- Hillstrom, A.P.; Scholey, H.; Liversedge, S.P.; Benson, V. The Effect of the First Glimpse at a Scene on Eye Movements during Search. Psychon. Bull. Rev. 2012, 19, 204–210. [Google Scholar] [CrossRef]
- Li, C.-L.; Aivar, M.P.; Kit, D.M.; Tong, M.H.; Hayhoe, M.M. Memory and Visual Search in Naturalistic 2D and 3D Environments. J. Vis. 2016, 16, 9. [Google Scholar] [CrossRef]
- Henderson, J.M.; Hollingworth, A. Eye movements, visual memory, and scene representation. In Perception of Faces, Objects, and Scenes: Analytic and Holistic Processes; Peterson, M.A., Rhodes, G., Eds.; Oxford University Press: Oxford, UK, 2003; pp. 356–383. ISBN 9780195313659. [Google Scholar]
- Henderson, J.M.; Anes, M.D. Roles of Object-File Review and Type Priming in Visual Identification within and across Eye Fixations. J. Exp. Psychol. Hum. Percept. Perform. 1994, 20, 826–839. [Google Scholar] [CrossRef]
- Henderson, J.M. Two Representational Systems in Dynamic Visual Identification. J. Exp. Psychol. Gen. 1994, 123, 410–426. [Google Scholar] [CrossRef]
- Hollingworth, A. Memory for Object Position in Natural Scenes. Vis. Cogn. 2005, 12, 1003–1016. [Google Scholar] [CrossRef]
- Hollingworth, A. Visual Memory for Natural Scenes: Evidence from Change Detection and Visual Search. Vis. Cogn. 2006, 14, 781–807. [Google Scholar] [CrossRef]
- Figueroa, J.C.M.; Arellano, R.A.B.; Calinisan, J.M.E. A Comparative Study of Virtual Reality and 2D Display Methods in Visual Search in Real Scenes. In Advances in Human Factors in Simulation and Modeling; Cassenti Proceedings of the AHFE 2017 International Conference on Human Factors in Simulation and Modeling, Los Angeles, CA, USA, 17–21 July 2017; Springer International Publishing: Cham, Switzerland, 2018; pp. 366–377. [Google Scholar]
- David, E.; Lebranchu, P.; Da Silva, M.P.; Le Callet, P. A New Toolbox to Process Gaze and Head Motion in Virtual Reality. 2020. In Preparation. [Google Scholar]
- Gutiérrez, J.; David, E.J.; Coutrot, A.; Da Silva, M.P.; Callet, P.L. Introducing UN Salient360! Benchmark: A Platform for Evaluating Visual Attention Models for 360° Contents. In Proceedings of the 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX), Cagliari, Italy, 29 May–1 June 2018; pp. 1–3. [Google Scholar]
- Nyström, M.; Holmqvist, K. An Adaptive Algorithm for Fixation, Saccade, and Glissade Detection in Eyetracking Data. Behav. Res. Methods 2010, 42, 188–204. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- RStudio Team. RStudio: Integrated Development Environment for R.; RStudio, Inc.: Boston, MA, USA, 2018. [Google Scholar]
- Rouder, J.N.; Speckman, P.L.; Sun, D.; Morey, R.D.; Iverson, G. Bayesian t Tests for Accepting and Rejecting the Null Hypothesis. Psychon. Bull. Rev. 2009, 16, 225–237. [Google Scholar] [CrossRef] [PubMed]
- Kass, R.E.; Raftery, A.E. Bayes Factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Morey, R.D.; Rouder, J.N.; Jamil, T.; Urbanek, S.; Forner, K.; Ly, A. Package “BayesFactor”. 2018. Available online: https://cran.r-project.org/web/packages/BayesFactor/index.html (accessed on 4 November 2020).
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using Lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Baayen, R.H.; Davidson, D.J.; Bates, D.M. Mixed-Effects Modeling with Crossed Random Effects for Subjects and Items. J. Mem. Lang. 2008, 59, 390–412. [Google Scholar] [CrossRef]
- Kliegl, R.; Wei, P.; Dambacher, M.; Yan, M.; Zhou, X. Experimental Effects and Individual Differences in Linear Mixed Models: Estimating the Relationship between Spatial, Object, and Attraction Effects in Visual Attention. Front. Psychol. 2011, 1, 238. [Google Scholar] [CrossRef]
- Schad, D.J.; Vasishth, S.; Hohenstein, S.; Kliegl, R. How to Capitalize on a Priori Contrasts in Linear (Mixed) Models: A Tutorial. J. Mem. Lang. 2020, 110, 104038. [Google Scholar] [CrossRef]
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random Effects Structure for Confirmatory Hypothesis Testing: Keep It Maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef]
- Bates, D.; Kliegl, R.; Vasishth, S.; Baayen, H. Parsimonious Mixed Models. arXiv 2015, arXiv:1506.04967. [Google Scholar]
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016; ISBN 9783319242774. [Google Scholar]
- Hope, R.M. Rmisc: Ryan Miscellaneous. 2013. Available online: https://cran.r-project.org/web/packages/Rmisc/index.html (accessed on 4 November 2020).
- Lilienthal, L.; Hale, S.; Myerson, J. The Effects of Environmental Support and Secondary Tasks on Visuospatial Working Memory. Mem. Cognit. 2014, 42, 1118–1129. [Google Scholar] [CrossRef] [PubMed]
- Lilienthal, L.; Hale, S.; Myerson, J. Effects of Age and Environmental Support for Rehearsal on Visuospatial Working Memory. Psychol. Aging 2016, 31, 249–254. [Google Scholar] [CrossRef] [PubMed]
- Souza, A.S.; Czoschke, S.; Lange, E.B. Gaze-Based and Attention-Based Rehearsal in Spatial Working Memory. J. Exp. Psychol. Learn. Mem. Cogn. 2020, 46, 980–1003. [Google Scholar] [CrossRef] [PubMed]
- Tatler, B.W.; Tatler, S.L. The Influence of Instructions on Object Memory in a Real-World Setting. J. Vis. 2013, 13, 5. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Hollingworth, A.; Williams, C.C.; Henderson, J.M. To See and Remember: Visually Specific Information Is Retained in Memory from Previously Attended Objects in Natural Scenes. Psychon. Bull. Rev. 2001, 8, 761–768. [Google Scholar] [CrossRef]
- Martarelli, C.S.; Mast, F.W. Eye Movements during Long-Term Pictorial Recall. Psychol. Res. 2013, 77, 303–309. [Google Scholar] [CrossRef]
- Oliva, A. Gist of the Scene. In Neurobiology of Attention; Itti, L., Rees, G., Tsotsos, J.K., Eds.; Academic Press: Burlington, MA, USA, 2005; ISBN 978-0-12-375731-9. [Google Scholar]
- Kristjánsson, Á. Simultaneous Priming along Multiple Feature Dimensions in a Visual Search Task. Vision Res. 2006, 46, 2554–2570. [Google Scholar] [CrossRef]
- Kristjánsson, Á.; Ásgeirsson, Á.G. Attentional Priming: Recent Insights and Current Controversies. Curr. Opin. Psychol. 2019, 29, 71–75. [Google Scholar] [CrossRef]
- Võ, M.L.-H.; Wolfe, J.M. Differential Electrophysiological Signatures of Semantic and Syntactic Scene Processing. Psychol. Sci. 2013, 24, 1816–1823. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Building the gist of a scene: The role of global image features in recognition. In Progress in Brain Research; Elsevier: Amsterdam, The Netherlands, 2006; Volume 155, pp. 23–36. ISBN 9780444519276. [Google Scholar]
- Graves, K.N.; Antony, J.W.; Turk-Browne, N.B. Finding the Pattern: On-Line Extraction of Spatial Structure During Virtual Navigation. Psychol. Sci. 2020, 31, 1183–1190. [Google Scholar] [CrossRef]
- Lauer, T.; Cornelissen, T.H.W.; Draschkow, D.; Willenbockel, V.; Võ, M.L.-H. The Role of Scene Summary Statistics in Object Recognition. Sci. Rep. 2018, 8, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Nuthmann, A. On the Visual Span during Object Search in Real-World Scenes. Vis. Cogn. 2013, 21, 803–837. [Google Scholar] [CrossRef]
- David, E.; Beitner, J.; Võ, M.L.-H. The Importance of Peripheral Vision When Searching 3D Real-World Scenes: A Gaze-Contingent Study in Virtual Reality. 2020. In Preparation. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beitner, J.; Helbing, J.; Draschkow, D.; Võ, M.L.-H. Get Your Guidance Going: Investigating the Activation of Spatial Priors for Efficient Search in Virtual Reality. Brain Sci. 2021, 11, 44. https://doi.org/10.3390/brainsci11010044
Beitner J, Helbing J, Draschkow D, Võ ML-H. Get Your Guidance Going: Investigating the Activation of Spatial Priors for Efficient Search in Virtual Reality. Brain Sciences. 2021; 11(1):44. https://doi.org/10.3390/brainsci11010044
Chicago/Turabian StyleBeitner, Julia, Jason Helbing, Dejan Draschkow, and Melissa L.-H. Võ. 2021. "Get Your Guidance Going: Investigating the Activation of Spatial Priors for Efficient Search in Virtual Reality" Brain Sciences 11, no. 1: 44. https://doi.org/10.3390/brainsci11010044
APA StyleBeitner, J., Helbing, J., Draschkow, D., & Võ, M. L.-H. (2021). Get Your Guidance Going: Investigating the Activation of Spatial Priors for Efficient Search in Virtual Reality. Brain Sciences, 11(1), 44. https://doi.org/10.3390/brainsci11010044