Preserved Contextual Cueing in Realistic Scenes in Patients with Age-Related Macular Degeneration

 ,
, 
Abstract

1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Stimuli
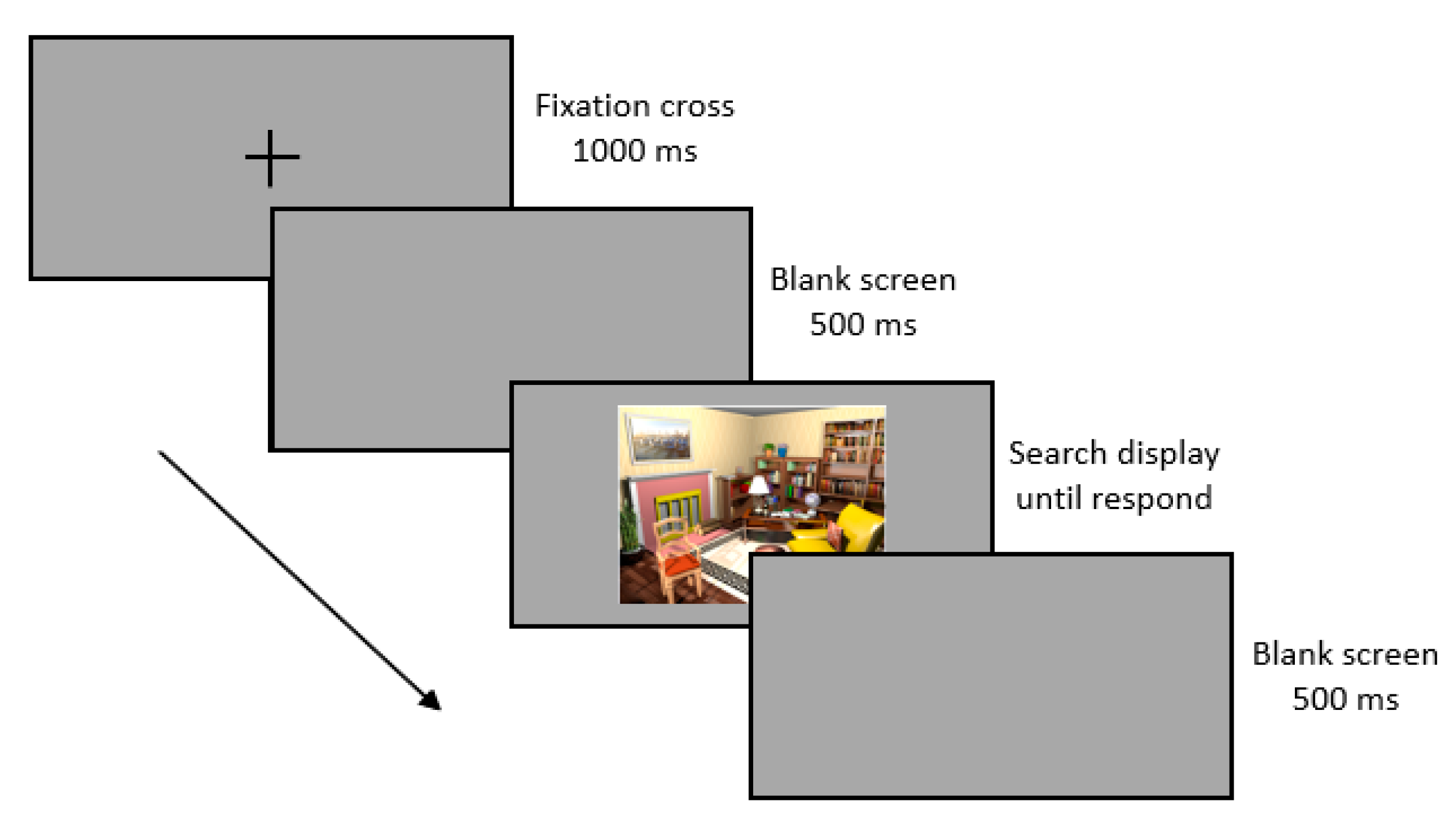
2.3. Procedures
2.4. Recognition Test
2.5. Data Analysis
3. Results
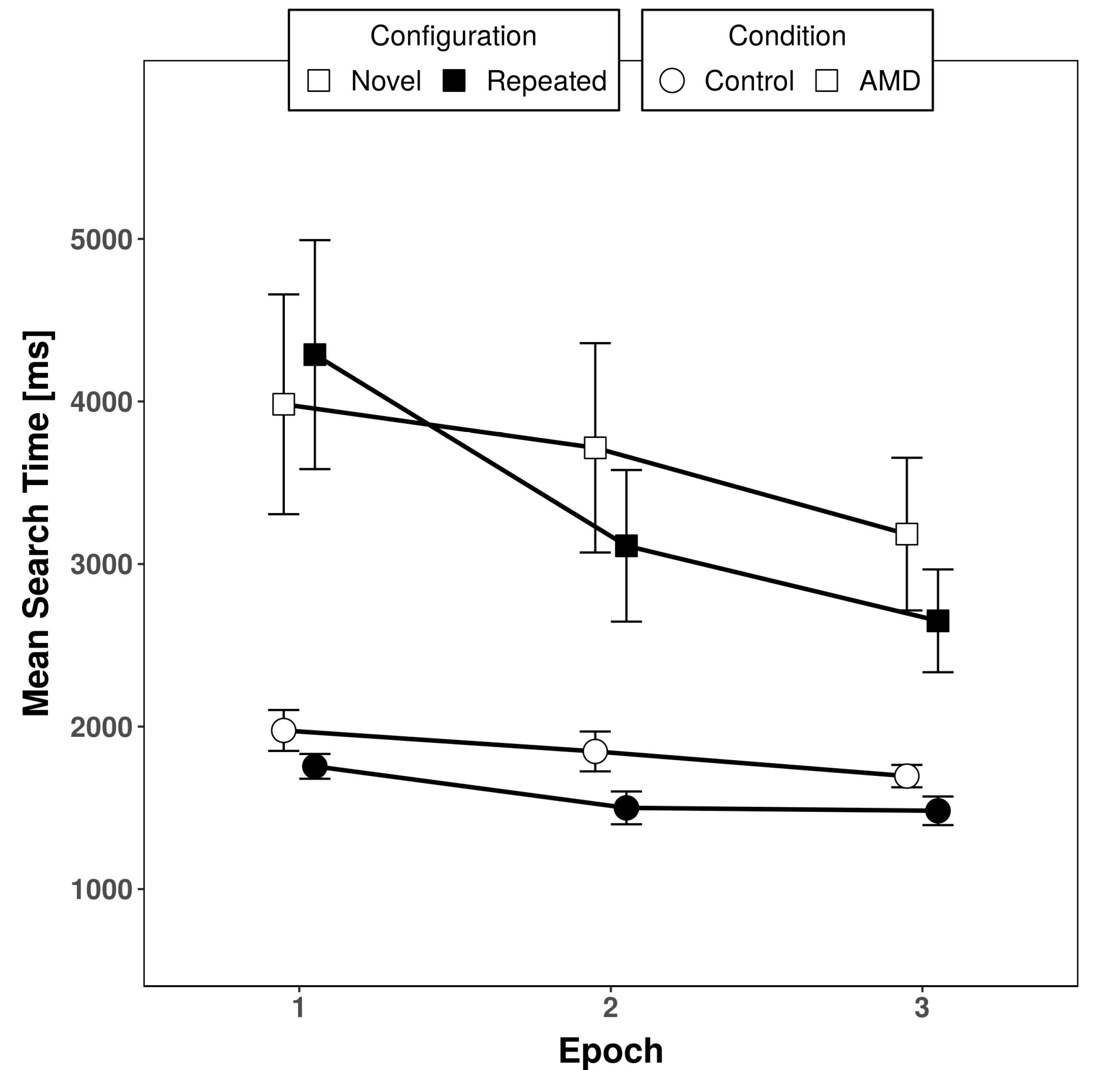
3.1. Response Times
3.2. Accuracy
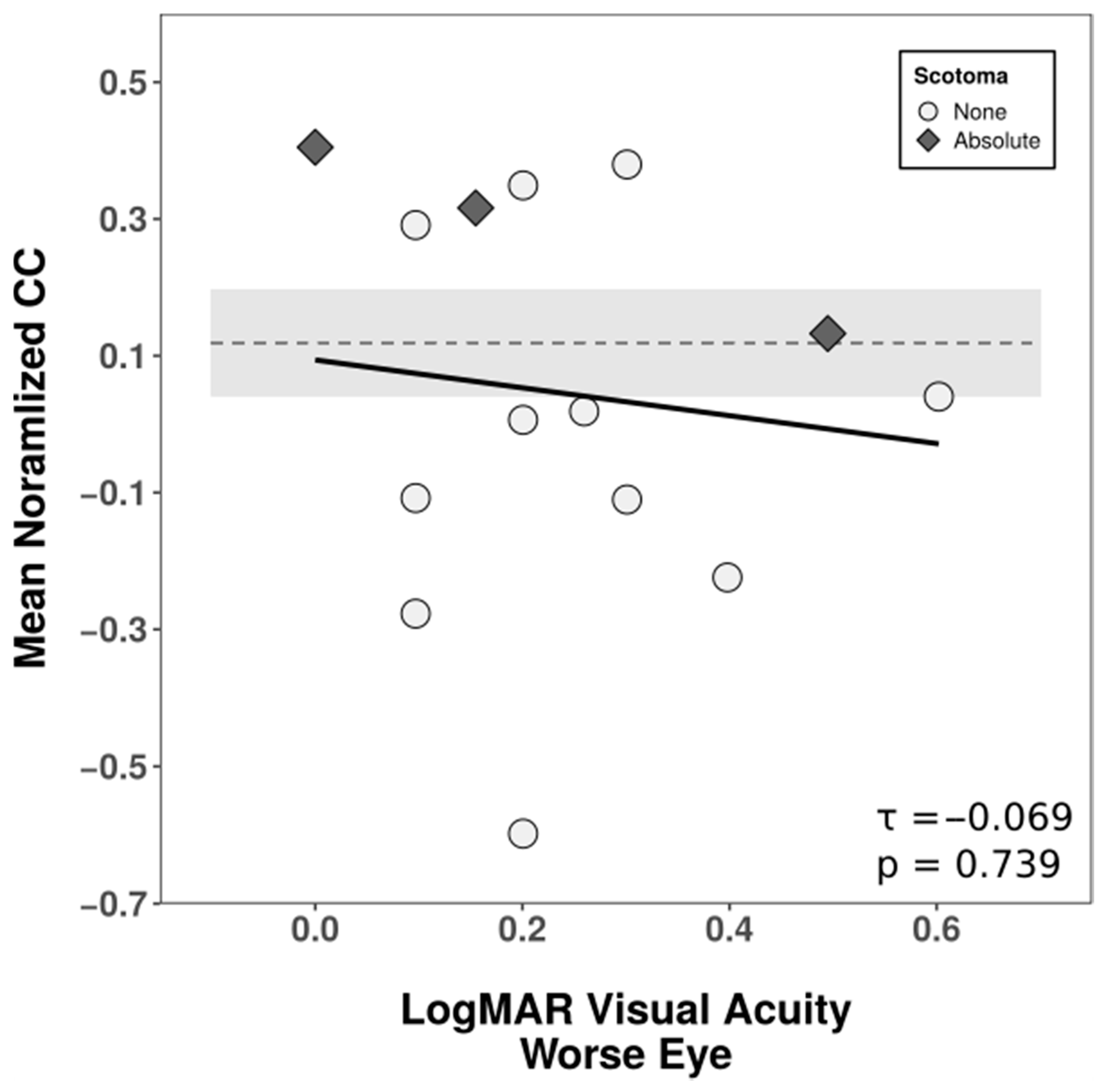
3.3. Recognition Test
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Brockmole, J.R.; Henderson, J.M. Using real-world scenes as contextual cues for search. Vis. Cognit. 2006, 13, 99–108. [Google Scholar] [CrossRef]
- Chun, M.M.; Jiang, Y. Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognit. Psychol. 1998, 36, 28–71. [Google Scholar] [CrossRef] [PubMed]
- Vadillo, M.A.; Konstantinidis, E.; Shanks, D.R. Underpowered samples, false negatives, and unconscious learning. Psychonom. Bull. Rev. 2016, 23, 87–102. [Google Scholar] [CrossRef] [PubMed]
- Geyer, T.; Shi, Z.; Müller, H.J. Contextual cueing in multiconjunction visual search is dependent on color- and configuration-based intertrial contingencies. J. Exp. Psychol. Hum. Percept. Perform. 2010, 36, 515–532. [Google Scholar] [CrossRef] [PubMed]
- Geyer, T.; Baumgartner, F.; Müller, H.J.; Pollmann, S. Medial temporal lobe-dependent repetition suppression and enhancement due to implicit vs. explicit processing of individual repeated search displays. Front. Hum. Neurosci. 2012, 6, 272. [Google Scholar] [CrossRef] [PubMed]
- Colagiuri, B.; Livesey, E.J. Contextual cuing as a form of nonconscious learning: Theoretical and empirical analysis in large and very large samples. Psychon. Bull. Rev. 2016, 23, 1996–2009. [Google Scholar] [CrossRef] [PubMed]
- Geringswald, F.; Herbik, A.; Hoffmann, M.B.; Pollmann, S. Contextual cueing impairment in patients with age-related macular degeneration. J. Vis. 2013, 13, 28. [Google Scholar] [CrossRef]
- Geringswald, F.; Baumgartner, F.; Pollmann, S. Simulated loss of foveal vision eliminates visual search advantage in repeated displays. Front. Hum. Neurosci. 2012, 6, 134. [Google Scholar] [CrossRef]
- Geringswald, F.; Pollmann, S. Central and peripheral vision loss differentially affects contextual cueing in visual search. J. Exp. Psychol. Learn. Mem. Cognit. 2015, 41, 1485–1496. [Google Scholar] [CrossRef]
- Annac, E.; Manginelli, A.A.; Pollmann, S.; Shi, Z.; Müller, H.J.; Geyer, T. Memory under pressure: Secondary-task effects on contextual cueing of visual search. J. Vis. 2013, 13, 1–15. [Google Scholar] [CrossRef]
- Manginelli, A.A.; Geringswald, F.; Pollmann, S. Visual search facilitation in repeated displays depends on visuospatial working memory. Exp. Psychol. 2012, 59, 47–54. [Google Scholar] [CrossRef] [PubMed]
- Manginelli, A.A.; Langer, N.; Klose, D.; Pollmann, S. Contextual cueing under working memory load: Selective interference of visuospatial load with expression of learning. Attent. Percept. Psychophys. 2013, 75, 1103–1117. [Google Scholar] [CrossRef] [PubMed]
- Pollmann, S. Working memory dependence of spatial contextual cueing for visual search. Brit. J. Psychol. 2019, 110, 372–380. [Google Scholar] [CrossRef] [PubMed]
- Biederman, I. Perceiving real-world scenes. Science 1972, 177, 77–80. [Google Scholar] [CrossRef]
- Vo, M.L.H.; Wolfe, J.M. The interplay of episodic and semantic memory in guiding repeated search in scenes. Cognition 2013, 126, 198–212. [Google Scholar] [CrossRef]
- Pollmann, S.; Geringswald, F.; Wei, P.; Porracin, E. Intact contextual cueing for search in realistic scenes with simulated central or peripheral vision loss. Trans. Vis. Sci. Technol. 2020, 9, 15. [Google Scholar] [CrossRef]
- Freiburg Vision Test (‘FrACT’). Available online: www.michaelbach.de/fract/index.html (accessed on 6 December 2020).
- Pierce, J. Generating stimuli for neuroscience using PsychoPy. Front. Neuroinform. 2009, 2, 10. [Google Scholar] [CrossRef]
- Sweet Home 3D. Available online: http://www.sweethome3d.com (accessed on 6 December 2020).
- Dienes, Z. Using Bayes to get the most out of non-significant results. Front. Psychol. 2014, 5, 781. [Google Scholar] [CrossRef]
- JASP Team. JASP (Version 0.14) [Computer Software]. 2020. Available online: https://jasp-stats.org/ (accessed on 6 December 2020).
- Wagenmakers, E.; Love, J.; Marsmann, M.; Jamil, T.; Ly, A.; Verhagen, J.; Selker, R.; Gronau, Q.F.; Dropmann, D.; Boutin, B.; et al. Bayesian inference for psychology. Part II: Example applications with JASP. Psychonom. Bull. Rev. 2018, 25, 58–76. [Google Scholar] [CrossRef]
- Jiang, Y.V.; Sisk, C.A. Contextual Cueing. In Spatial Learning and Attention Guidance, 1st ed.; Pollmann, S., Ed.; Neuromethods, Humana: New York, NY, USA, 2019; Volume 151. [Google Scholar] [CrossRef]
- Boucart, M.; Moroni, C.; Thibaut, M.; Szaffarczyk, S.; Greene, M. Scene categorization at large visual eccentricities. Vis. Res. 2013, 86, 35–42. [Google Scholar] [CrossRef]
- Boucart, M.; Moroni, C.; Szaffarczyk, S.; Tran, T.H.C. Implicit processing of scene context in macular degeneration. Investig. Ophthalm. Vis. Sci. 2013, 54, 1950–1957. [Google Scholar] [CrossRef] [PubMed]
- Smith, N.D.; Crabb, D.P.; Garway-Heath, D.F. An exploratory study of visual search performance in glaucoma. Ophthalm. Physiol. Opt. 2011, 31, 225–232. [Google Scholar] [CrossRef] [PubMed]
- Geringswald, F.; Porracin, E.; Pollmann, S. Impairment of visual memory for objects in natural scenes by simulated central scotomata. J. Vis. 2016, 16, 6. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diagnoses | Acuity | Scotoma | ||||||
|---|---|---|---|---|---|---|---|---|
| Subject | Sex | Age (years) | RE | LE | RE | LE | RE | LE |
| S01 | F | 61 | AMD(wet) | AMD (dry) | 0.6 | 1.0 | r | r |
| S02 | F | 80 | AMD(wet) | / | 0.1 | 0.8 | r | r |
| S03 | F | 78 | AMD(wet) | AMD (wet) | 0.7 | 1.0 | r | r |
| S04 | F | 79 | AMD(wet) | AMD (wet) | 0.3 | 0.05 | r | r |
| S05 | F | 76 | AMD(wet) | AMD (wet) | 0.7 | 0.7 | r | r |
| S06 | F | 55 | AMD(wet) | AMD (wet) | 0.8 | 0.8 | r | r |
| S07 | M | 81 | AMD (dry) | AMD (dry) | 0.8 | 0.5/0.6 | r | r* |
| S08 | M | 74 | AMD (dry) | AMD (dry) | 0.04 | 0.5 | a | r* |
| S09 | F | 80 | AMD (dry) | AMD (dry) | 0.5 | 0.32 | –ag | –ag* |
| S10 | F | 84 | AMD (dry) | AMD (dry) | 1.0 | 0.8 | –ag | –ag* |
| S11 | M | 71 | AMD (dry) | AMD (dry) | 0.63 | 0.63 | –ag | –ag* |
| S12 | F | 78 | AMD (dry) | AMD (wet) | 0.8 | 0.4 | –ag* | –ag |
| S13 | M | 80 | AMD (dry) | AMD (dry) | 0.63 | 0.63 | –ag* | –ag |
| S14 | F | 75 | AMD (dry) | AMD (dry) | 0.03 | 0.8 | aag | –ag* |
| S15 | M | 79 | AMD (dry) | AMD (dry) | 0.63 | 0.63 | –ag | –ag* |
| S16 | F | 79 | AMD (dry) | AMD (dry) | 0.8 | 0.8 | –ag* | –ag |
| S17 | M | 80 | AMD (dry) | AMD (wet) | 0.32 | 0.08 | a* | a |
| S18 | M | 76 | AMD (dry) | AMD (dry) | 1.0 | 0.25 | –* | r |
| S19 | F | 72 | AMD (dry) | AMD (dry) | 0.7 | 1.0 | a* | r |
| S20 | M | 80 | AMD (dry) | AMD (wet) | 1.0 | 0.08 | r* | a |
| Epoch 1 | Epoch 2 | Epoch 3 | ||||
|---|---|---|---|---|---|---|
| Condition | Absolute Mean (SD) | Normalized Mean (SD) | Absolute Mean (SD) | Normalized Mean (SD) | Absolute Mean (SD) | Normalized Mean (SD) |
| Control | 221 (421) | 0.07 (0.18) | 347 (420) | 0.14 (0.17) | 213 (288) | 0.12 (0.17) |
| Patient | −306 (1281) | −0.17 (0.35) | 603 (1470) | 0.07 (0.25) | 534 (1227) | 0.08 (0.28) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pollmann, S.; Rosenblum, L.; Linnhoff, S.; Porracin, E.; Geringswald, F.; Herbik, A.; Renner, K.; Hoffmann, M.B. Preserved Contextual Cueing in Realistic Scenes in Patients with Age-Related Macular Degeneration. Brain Sci. 2020, 10, 941. https://doi.org/10.3390/brainsci10120941
Pollmann S, Rosenblum L, Linnhoff S, Porracin E, Geringswald F, Herbik A, Renner K, Hoffmann MB. Preserved Contextual Cueing in Realistic Scenes in Patients with Age-Related Macular Degeneration. Brain Sciences. 2020; 10(12):941. https://doi.org/10.3390/brainsci10120941
Chicago/Turabian StylePollmann, Stefan, Lisa Rosenblum, Stefanie Linnhoff, Eleonora Porracin, Franziska Geringswald, Anne Herbik, Katja Renner, and Michael B. Hoffmann. 2020. "Preserved Contextual Cueing in Realistic Scenes in Patients with Age-Related Macular Degeneration" Brain Sciences 10, no. 12: 941. https://doi.org/10.3390/brainsci10120941
APA StylePollmann, S., Rosenblum, L., Linnhoff, S., Porracin, E., Geringswald, F., Herbik, A., Renner, K., & Hoffmann, M. B. (2020). Preserved Contextual Cueing in Realistic Scenes in Patients with Age-Related Macular Degeneration. Brain Sciences, 10(12), 941. https://doi.org/10.3390/brainsci10120941