Risk Factors for Distortion Product Otoacoustic Emissions in Young Adults

Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Procedures
2.3. Measures
2.4. Statistical Analyses
Variable Definitions
3. Results
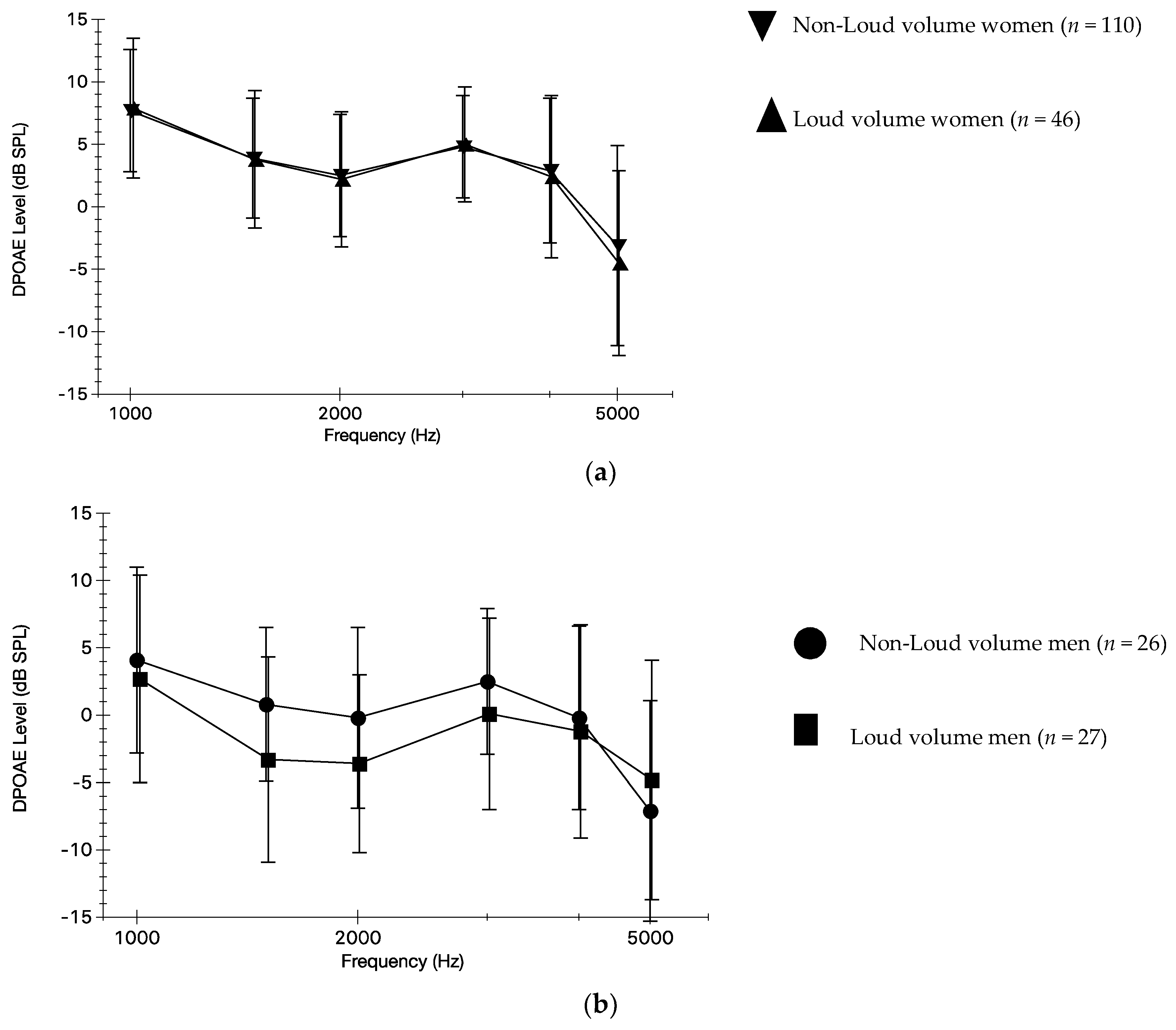
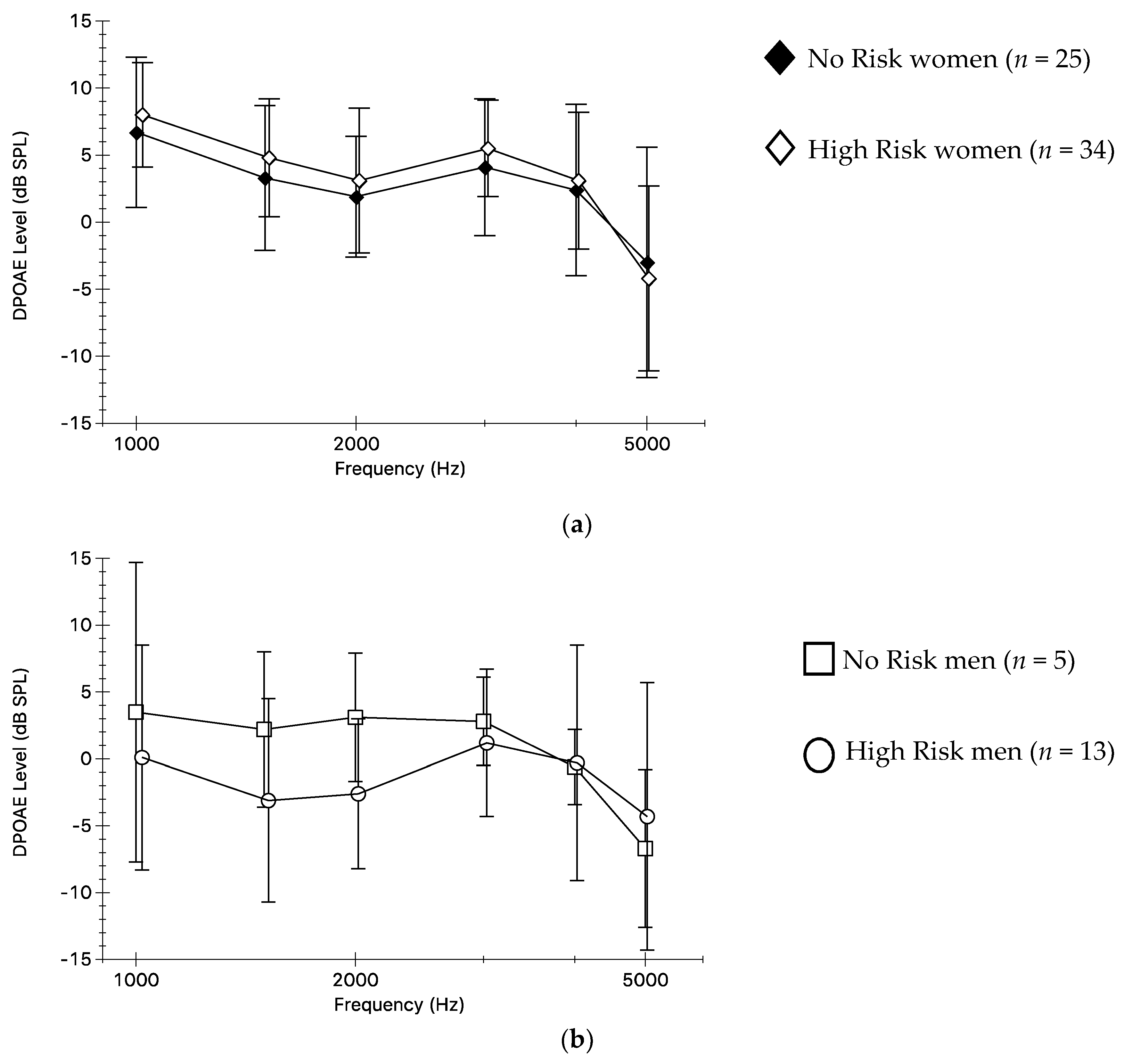
3.1. Self-Reported Volume Use and DPOAEs
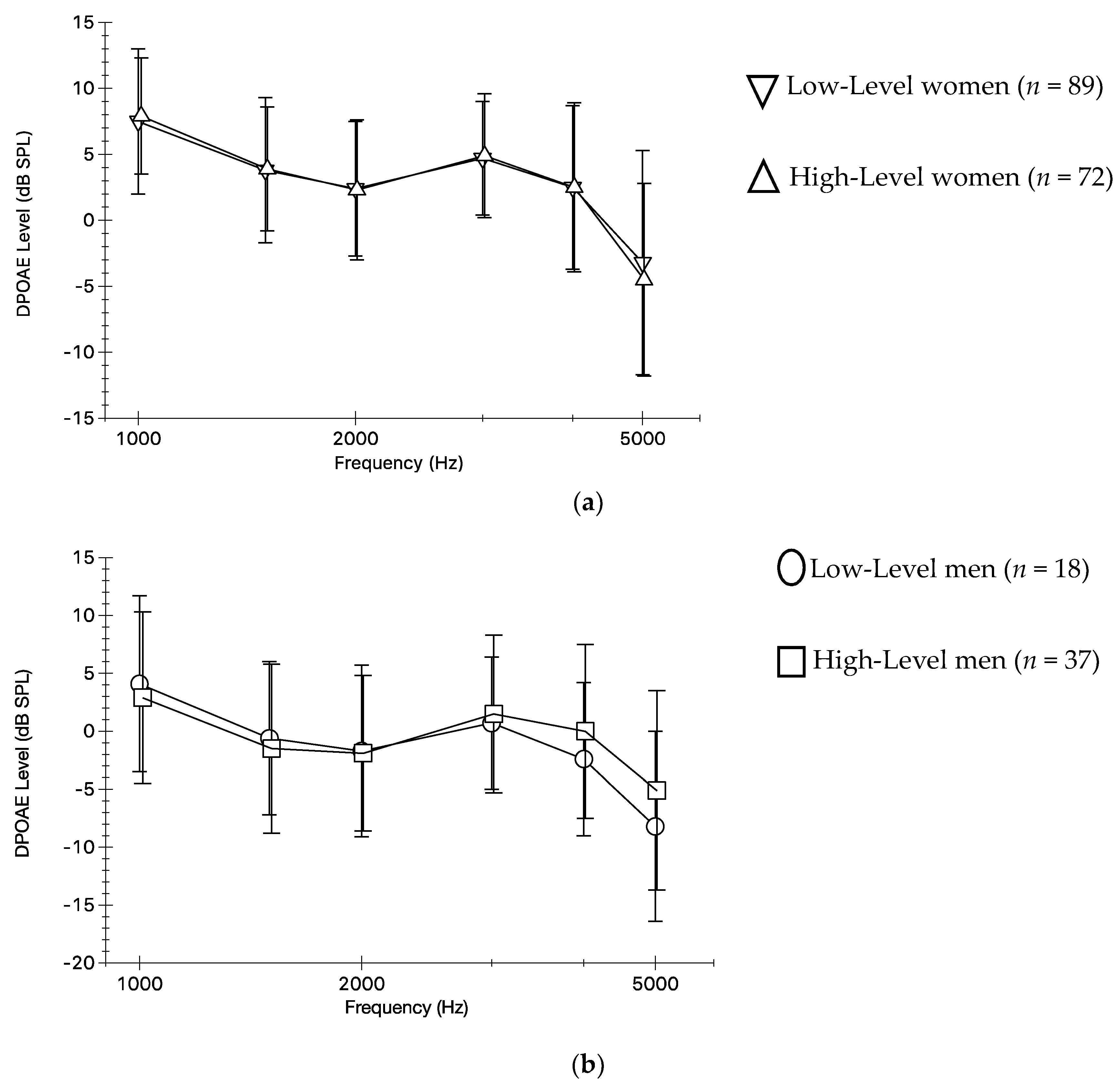
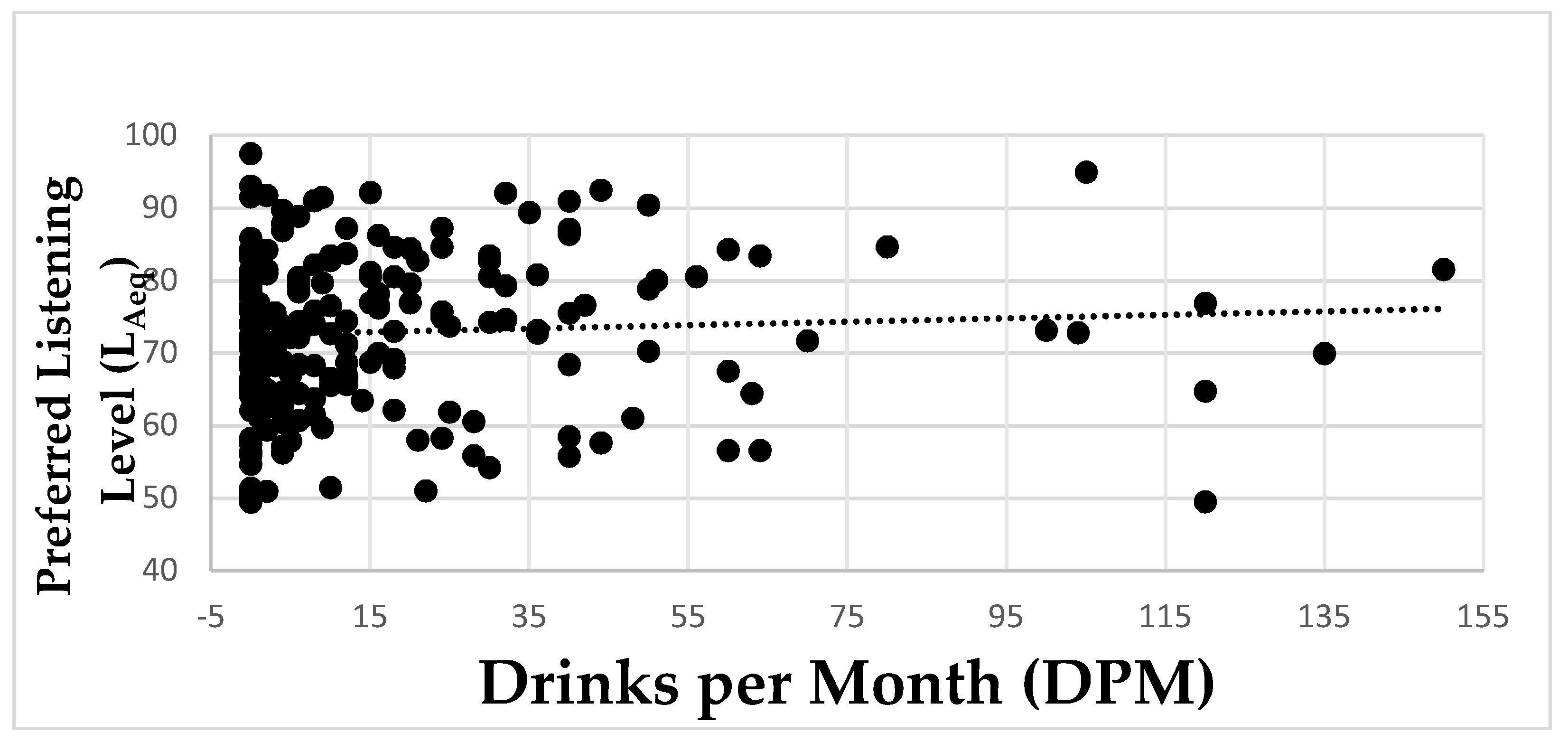
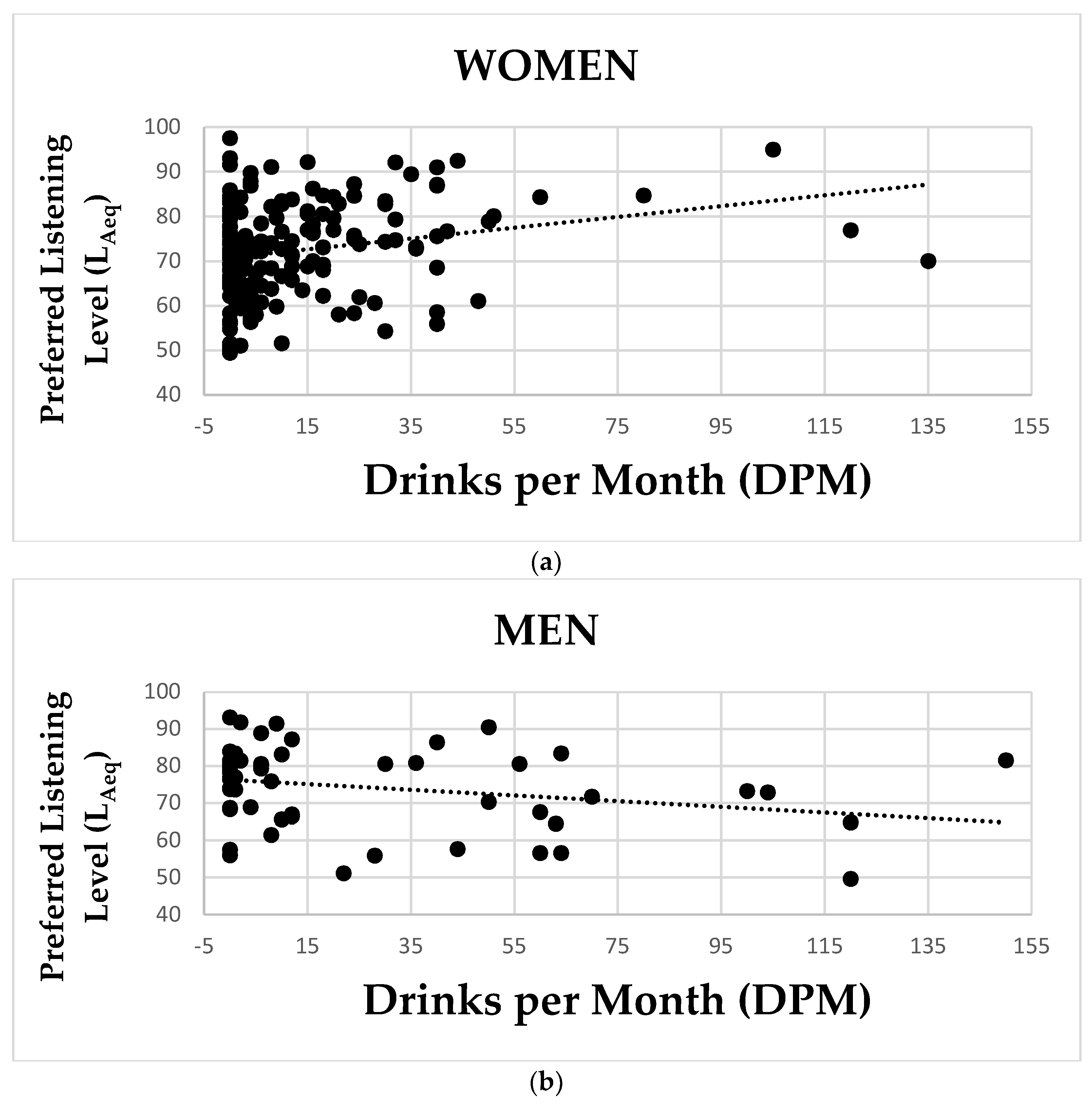
3.2. Preferred Listening Level and DPOAEs
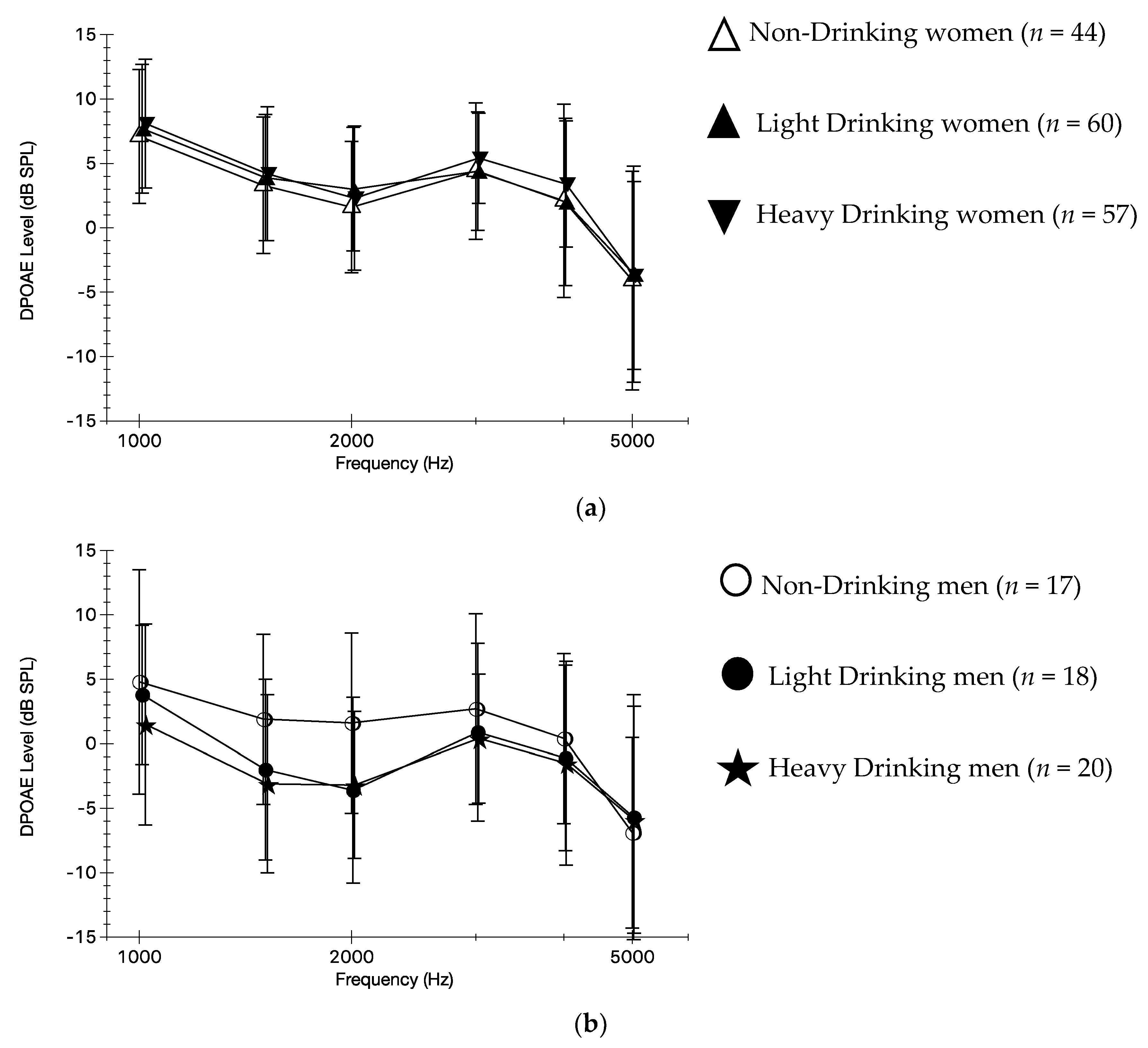
3.3. Self-Reported Alcohol Use and DPOAEs
3.4. Multiple Risk Factors and DPOAEs
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Torre, P., III. Young adults’ use and output level settings of personal music systems. Ear Hear. 2008, 29, 791–799. [Google Scholar] [CrossRef] [PubMed]
- Danhauer, J.L.; Johnson, C.E.; Byrd, A.; DeGood, L.; Meuel, C.; Pecile, A.; Koch, L.L. Survey of college students on iPod use and hearing health. J. Am. Acad. Audiol. 2009, 20, 5–27. [Google Scholar] [CrossRef] [PubMed]
- Zogby, J. Survey of Hispanic adults, adults in general, hispanic teens, and teens in general about the use of personal electronic devices with head phones. Am. Speech Lang. Hear. Assoc 2006. Available online: https://www.asha.org/uploadedFiles/HeadphoneSurveyDomestic.pdf (accessed on 16 April 2019).
- Hoover, A.; Krishnamurti, S. Survey of college students’ MP3 listening: Habits, safety issues, attitudes, and education. Am. J. Audiol. 2010, 19, 73–83. [Google Scholar] [CrossRef]
- Portnuff, C.D.F.; Fligor, B.J.; Arehart, K.H. Self-report and long-term field measures of MP3 player use: How accurate is self-report? Int. J. Audiol. 2013, 52, S33–S40. [Google Scholar] [CrossRef]
- Hodgetts, W.E.; Rieger, J.M.; Szarko, R.A. The effects of listening environment and earphone style on preferred listening levels of normal hearing adults using an MP3 player. Ear Hear. 2007, 28, 290–297. [Google Scholar] [CrossRef]
- Worthington, D.A.; Siegel, J.H.; Wilber, L.A.; Faber, B.M.; Dunckley, K.T.; Garstecki, D.C.; Dhar, S. Comparing two methods to measure preferred listening levels of personal listening devices. J. Acoust. Soc. Am. 2009, 125, 3733–3741. [Google Scholar] [CrossRef]
- Torre, P., III; Grace, J. Changes in distortion product otoacoustic emission components after music exposure. J. Am. Acad. Audiol. 2014, 25, 805–813. [Google Scholar] [CrossRef]
- Park, Y.; Guercio, D.; Ledon, V.; Le Prell, C.G. Variation in music player listening level as function of campus location. J. Am. Acad. Audiol. 2017, 28, 295–313. [Google Scholar] [CrossRef]
- Torre, P., III; Reed, M.B. Can self-reported personal audio system volume predict actual listening levels in young adults? J. Am. Acad. Audiol. 2019, 30, 153–161. [Google Scholar] [CrossRef]
- National Institute for Occupational Safety and Health. Criteria for a Recommended Standard: Occupational Noise Exposure (Revised Criteria 1998); No. 98-126; US Department of Health and Human Services (NIOSH): Cincinnati, OH, USA, 1998.
- Occupational Safety & Health Administration. Occupational Noise Exposure Standard (29 CFR 191.25). Code of Federal Regulations; US Department of Labor: Washington DC, USA, 2007.
- Montoya, F.S.; Ibargüen, A.M.; Vences, A.R.; Sanchez del Rey, A.; Fernandez, J.M.S. Evaluation of cochlear function in normal-hearing young adults exposed to MP3 player noise by analyzing transient evoked otoacoustic emissions and distortion products. J. Oto-Head Neck Surg. 2008, 37, 718–724. [Google Scholar]
- Torre, P., III; Grace, J.; Hansen, C.; Millman, P.; Martin, H. Gender, music, and distortion product otoacoustic emission components. Ear Hear. 2013, 34, e74–e81. [Google Scholar] [CrossRef]
- Le Prell, C.G.; Siburt, H.W.; Lobarinas, E.; Griffiths, S.K.; Spankovich, C. No reliable association between recreational noise exposure and threshold sensitivity, distortion product otoacoustic emission amplitude, or word-in-noise performance in a college student population. Ear Hear. 2018, 39, 1057–1074. [Google Scholar] [CrossRef]
- Clapp, J.D.; Reed, M.B.; Holmes, M.R.; Lange, J.E.; Voas, R.B. Drunk in public, drunk in private: The relationship between college students’ drinking environments and alcohol consumption. Am. J. Drug Alcohol Abus. 2006, 32, 275–285. [Google Scholar] [CrossRef] [PubMed]
- Harford, T.C.; Wechsler, H.; Seibring, M. Attendance and alcohol use at parties and bars in college: A national survey of current drinkers. J. Stud. Alcohol Drugs 2002, 63, 726–733. [Google Scholar] [CrossRef]
- Schulenberg, J.E.; Johnston, L.D.; O’Malley, P.M.; Bachman, J.G.; Miech, R.A.; Patrick, M.E. Monitoring the Future National Survey Results on Drug Use, 1975–2016: Volume II, College Students and Adults Ages 19–55. Ann Arbor: Institute for Social Research, The University of Michigan, 2017. Available online: http://monitoringthefuture.org/pubs.html#monographs (accessed on 4 January 2019).
- Bray, A.; Szymański, M.; Mills, R. Noise induced hearing loss in dance music disc jockeys and an examination of sound levels in nightclubs. J. Laryngol. Otol. 2004, 118, 123–128. [Google Scholar] [CrossRef] [PubMed]
- Hughes, K.; Quigg, Z.; Eckley, L.; Bellis, M.; Jones, L.; Calafat, A.; Kosir, M.; Van Hasselt, N. Environmental factors in drinking venues and alcohol-related harm: The evidence base for European intervention. Addiction 2011, 106, 37–46. [Google Scholar] [CrossRef] [PubMed]
- Stafford, L.D.; Dodd, H. Music increases alcohol consumption rate in young females. Exp. Clin. Psychopharmacol. 2013, 21, 408–415. [Google Scholar] [CrossRef]
- Gueguen, N.; Jacob, C.; Le Guellec, H.; Morineau, T.; Lourel, M. Sound level of experimental music and drinking behavior: A field experiment with beer drinkers. Alcohol Clin. Exp. Res. 2008, 32, 1795–1798. [Google Scholar] [CrossRef]
- Clapp, J.D.; Min, J.W.; Shillington, A.M.; Reed, M.B.; Ketchie, C.J. Person and environment predictors of blood alcohol concentrations: A multi-level study of college parties. Alcohol Clin. Exp. Res. 2008, 22, 100–107. [Google Scholar] [CrossRef]
- Recommended Alcohol Questions. Available online: https://www.niaaa.nih.gov/research/guidelines-and-resources/recommended-alcohol-questions (accessed on 1 April 2019).
- Marshall, L.; Lapsley Miller, J.A.; Heller, L.M. Distortion-product otoacoustic emissions as a screening tool for noise-induced hearing loss. Noise Health 2001, 3, 43–60. [Google Scholar] [PubMed]
- Marshall, L.; Lapsley Miller, J.A.; Heller, L.M.; Wolgemuth, K.S.; Hughes, L.M.; Smith, S.D.; Kopke, R.D. Detecting incipient inner-ear damage from impulse noise with otoacoustic emissions. J. Acoust. Soc. Am. 2009, 125, 995–1013. [Google Scholar] [CrossRef] [PubMed]
- Lee, G.J.C.; Lim, M.Y.; Kuan, A.Y.W.; Teo, J.H.W.; Tan, H.G.; Low, W.K. Relationship between leisure noise exposure and otoacoustic emissions in a young Asian population. Int. J. Audiol. 2014, 53, 462–468. [Google Scholar] [CrossRef]
- Sulaiman, A.H.; Husain, R.; Seluakumaran, K. Evaluation of early hearing damage in personal listening device users using extended high-frequency audiometry and otoacoustic emissions. Eur. Arch. Otorhinolaryngol. 2014, 271, 1463–1470. [Google Scholar] [CrossRef]
- Hwang, J.H.; Tan, C.T.; Chiang, C.W.; Liu, T.C. Acute effects of alcohol on auditory thresholds and distortion product otoacoustic emissions in humans. Acta Otolaryngol. 2003, 123, 936–940. [Google Scholar] [CrossRef]
- Rosenhall, U.; Sixt, E.; Sundh, V.; Svanborg, A. Correlations between presbyacusis and extrinsic noxious factors. Int. J. Audiol. 1993, 32, 234–243. [Google Scholar] [CrossRef]
- Popelka, M.M.; Cruickshanks, K.J.; Wiley, T.L.; Tweed, T.S.; Klein, B.E.K.; Klein, R.; Nondahl, D. Moderate alcohol consumption and hearing loss: A protective effect. J. Am. Geriatr. Soc. 2000, 48, 1273–1278. [Google Scholar] [CrossRef]
- Gopinath, B.; Flood, V.M.; McMahon, C.M.; Burlutsky, G.; Smith, W.; Mitchell, P. The effects of smoking and alcohol consumption on age-related hearing loss: The blue mountains hearing study. Ear Hear. 2010, 31, 277–282. [Google Scholar] [CrossRef] [PubMed]
- Curhan, S.G.; Eavey, R.; Shargorodsky, J.; Curhan, G.C. Prospective study of alcohol use and hearing loss in men. Ear Hear. 2011, 32, 46–52. [Google Scholar] [CrossRef] [PubMed]
- Dawes, P.; Cruickshanks, K.J.; Moore, D.R.; Edmondson-Jones, M.; McCormack, A.; Fortnum, H.; Munro, K.J. Cigarette smoking, passive smoking, alcohol consumption, and hearing loss. J. Assoc. Res. Otolaryngol. 2014, 15, 663–674. [Google Scholar] [CrossRef] [PubMed]
- Curhan, S.G.; Eavey, R.; Wang, M.; Stampfer, M.J.; Curhan, G.C. Prospective study of alcohol consumption and self-reported hearing loss in women. Alcohol 2015, 49, 71–77. [Google Scholar] [CrossRef]
- Cruickshanks, K.J.; Wiley, T.L.; Tweed, T.S.; Klein, B.E.K.; Klein, R.; Mares-Perlman, J.A.; Nondahl, D.M. Prevalence of hearing loss in older adults in Beaver Dam, Wisconsin: The epidemiology of hearing loss study. Am. J. Epidemiol. 1998, 148, 879–886. [Google Scholar] [CrossRef]
- Cruickshanks, K.J.; Nondahl, D.M.; Tweed, T.S.; Wiley, T.L.; Klein, B.E.K.; Klein, R.; Chappell, R.; Dalton, D.S.; Nash, S.D. Education, occupation, noise exposure history and the 10-yr cumulative incidence of hearing impairment in older adults. Hear Res. 2010, 264, 3–9. [Google Scholar] [CrossRef]
- Nash, S.D.; Cruickshanks, K.J.; Klein, R.; Klein, B.E.K.; Nieto, F.J.; Huang, G.H.; Pankow, J.S.; Tweed, T.S. The prevalence of hearing impairment and associated risk factors. The beaver dam offspring study. Arch. Otolaryngol. Head Neck Surg. 2011, 137, 432–439. [Google Scholar] [CrossRef]
- Del Boca, F.K.; Darkes, J. The validity of self-reports of alcohol consumption: State of the science and challenges for research. Addiction 2003, 98 (Suppl. 2), 1–12. [Google Scholar] [CrossRef]
- Simmons, J.S.; Wills, T.A.; Emery, N.N.; Mark, R.M. Quantifying alcohol consumption: Self-report, transdermal assessment, and prediction of dependence symptoms. Addict. Behav. 2015, 50, 205–212. [Google Scholar] [CrossRef]
- Kraaijenga, V.J.C.; van Munster, J.J.C.M.; van Zanten, G.A. Association of behavior with noise-induced hearing loss among attendees of an outdoor music festival: A secondary analysis of a randomized clinical trial. JAMA Otolaryngol. Head Neck Surg. 2018, 144, 490–497. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Participants (n = 216) | ||
|---|---|---|
| n | Percent | |
| Women | 161 | 74.5 |
| Men | 55 | 25.5 |
| Ethnicity (n = 216) | ||
| Hispanic or Latino | 64 | 29.6 |
| Not Hispanic or Latino | 150 | 69.4 |
| Decline to state | 2 | 1.0 |
| Race (n = 216) | ||
| American Indian/Alaska Native | 3 | 1.4 |
| Asian | 24 | 11.1 |
| Native Hawaiian/Pacific Islander | 5 | 2.3 |
| Black/African American | 20 | 9.3 |
| White | 134 | 62.0 |
| Decline to state | 30 | 13.9 |
| ALL (n = 216) | WOMEN (n = 161) | MEN (n = 55) | |
|---|---|---|---|
| Self–reported PM system use 1 | |||
| Light (≤1 h/wk) | 30 (14.3%) | 24 (15.4%) | 6 (11.1%) |
| Moderate (1–7 h/wk) | 123 (58.6%) | 95 (60.9%) | 28 (51.9%) |
| Heavy (>7 h/wk) | 57 (27.1%) | 37 (23.7%) | 20 (37.0%) |
| Longest single use during a typical day 1 | |||
| <1 h | 93 (44.3%) | 73 (46.8%) | 20 (37.0%) |
| 1 h | 63 (30.0%) | 44 (28.2%) | 19 (35.2%) |
| 2 h | 38 (18.1%) | 29 (18.6%) | 9 (16.7%) |
| 3 h | 15 (7.1%) | 10 (6.4%) | 5 (9.3%) |
| 4 h | 1 (0.5%) | 0 (0.0%) | 1 (1.8%) |
| Volume use 1 | |||
| Low/medium volume | 136 (65.1%) | 110 (70.5%) | 26 (49.1%) |
| Loud/very loud volume | 73 (34.9%) | 46 (29.5%) | 27 (50.9%) |
| Hear people 2 | |||
| Easily hear/have a little trouble hearing people | 158 (75.2%) | 121 (77.6%) | 37 (68.5%) |
| Have a lot of trouble/cannot hear people | 52 (24.8%) | 35 (22.4%) | 17 (31.5%) |
| Report tinnitus after PM system use 1 | |||
| Yes | 27 (12.9%) | 23 (14.7%) | 4 (7.4%) |
| Preferred listening level LAeq (dB) | |||
| Mean (SD) | 73.0 (10.7) | 71.8 (10.7) | 76.5 (10.1) |
| Minimum, maximum | 49.4, 97.5 | 49.4, 97.5 | 49.6, 93.1 |
| Drinks per month (DPM) | |||
| Non–drinkers | 61 (28.2%) | 44 (27.3%) | 17 (30.9%) |
| Light drinkers (≤14 drinks) | 78 (36.1%) | 60 (37.3%) | 18 (32.7%) |
| Heavy drinkers (>14 drinks) | 77 (35.7%) | 57 (35.4%) | 20 (36.4%) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torre, P., III; Reed, M.B. Risk Factors for Distortion Product Otoacoustic Emissions in Young Adults. Appl. Sci. 2019, 9, 1608. https://doi.org/10.3390/app9081608
Torre P III, Reed MB. Risk Factors for Distortion Product Otoacoustic Emissions in Young Adults. Applied Sciences. 2019; 9(8):1608. https://doi.org/10.3390/app9081608
Chicago/Turabian StyleTorre, Peter, III, and Mark B. Reed. 2019. "Risk Factors for Distortion Product Otoacoustic Emissions in Young Adults" Applied Sciences 9, no. 8: 1608. https://doi.org/10.3390/app9081608
APA StyleTorre, P., III, & Reed, M. B. (2019). Risk Factors for Distortion Product Otoacoustic Emissions in Young Adults. Applied Sciences, 9(8), 1608. https://doi.org/10.3390/app9081608