An Algorithm for Scene Text Detection Using Multibox and Semantic Segmentation




Abstract
1. Introduction
2. Related Work
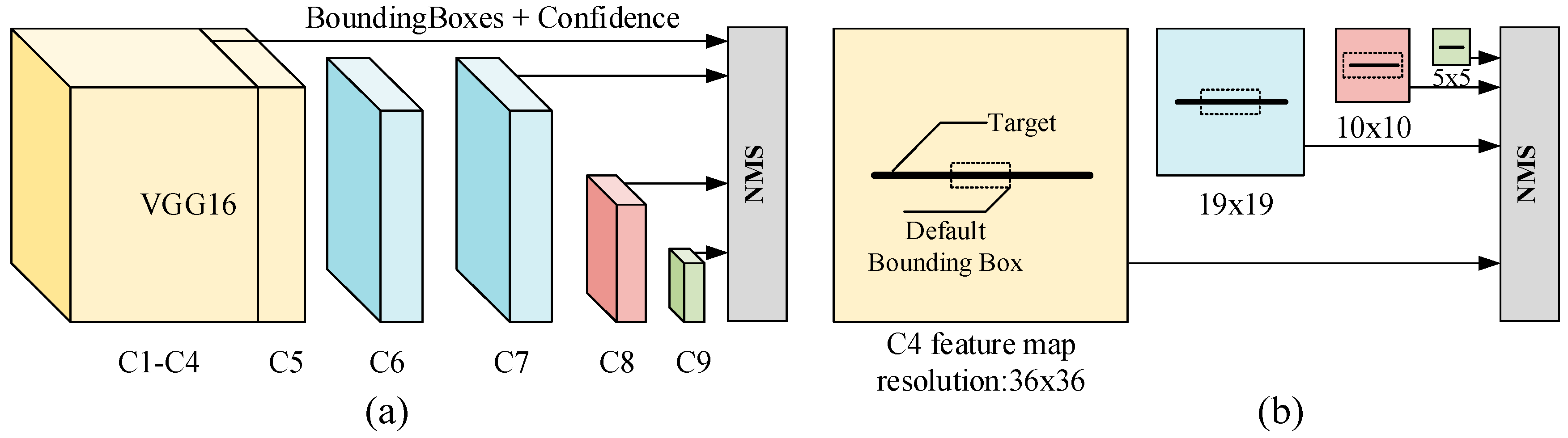
2.1. Multibox Text Detector
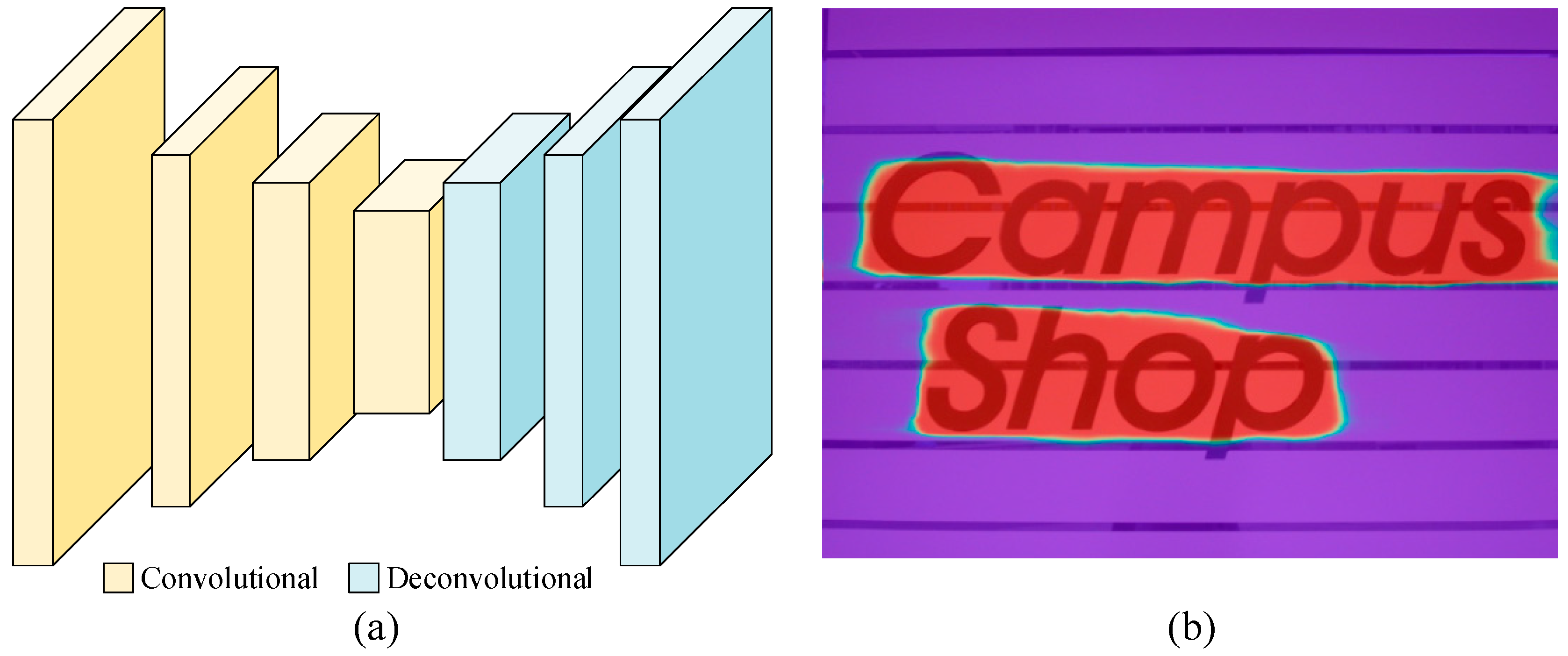
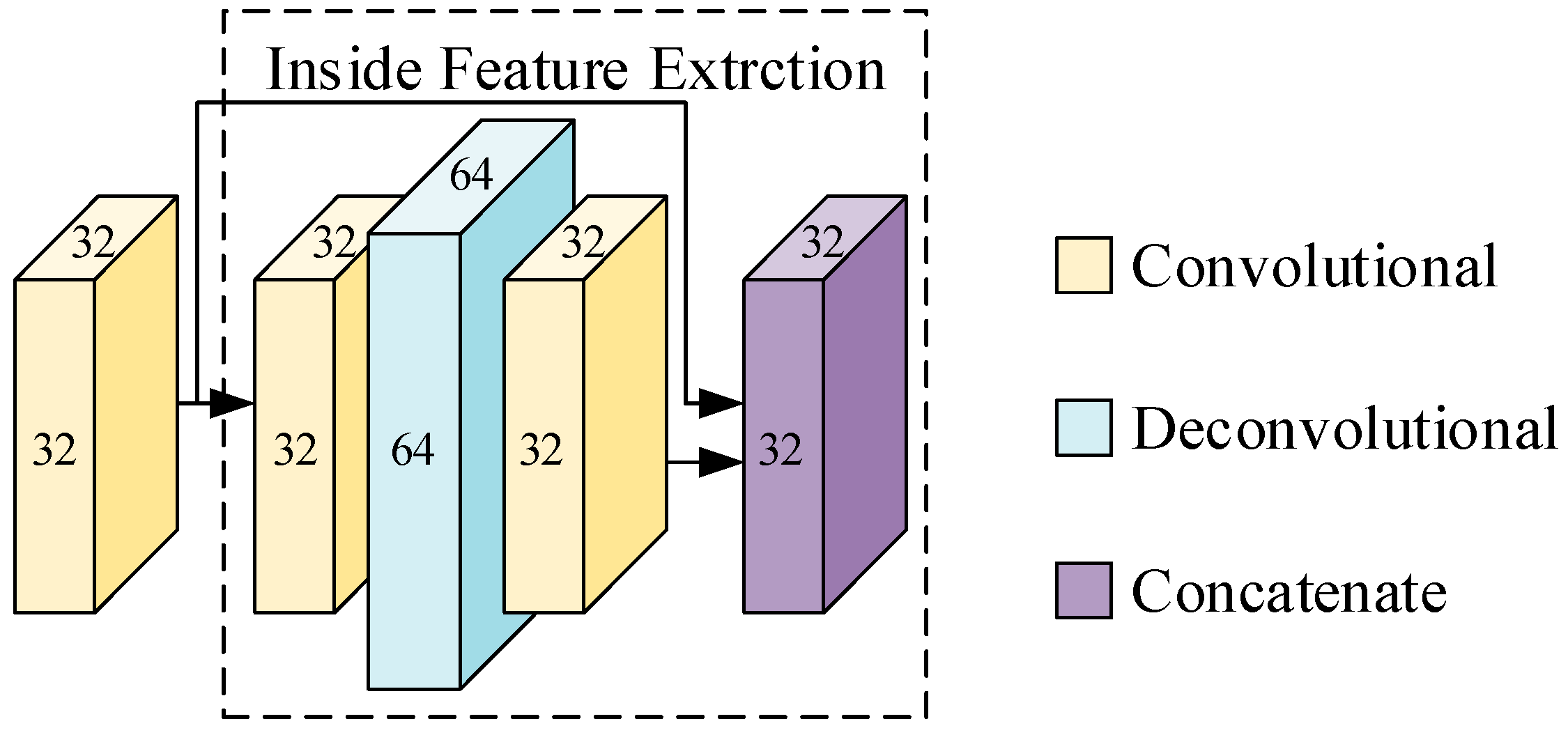
2.2. Semantic Segmentation
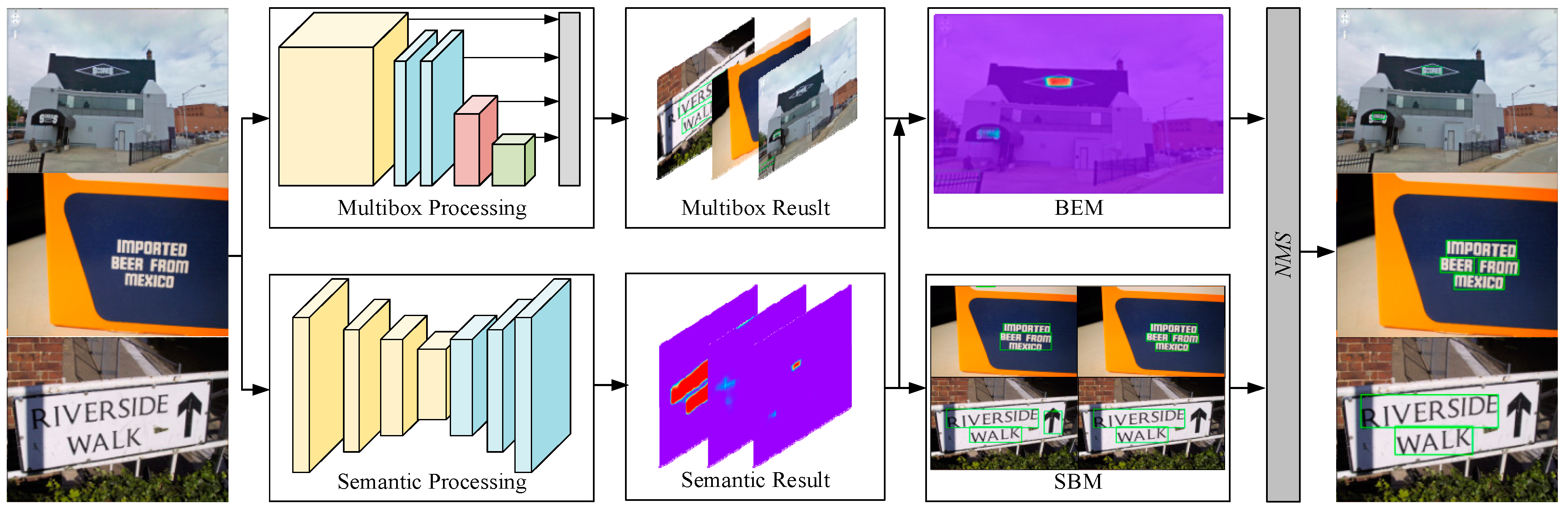
3. Proposed Algorithm
3.1. Overall Framework
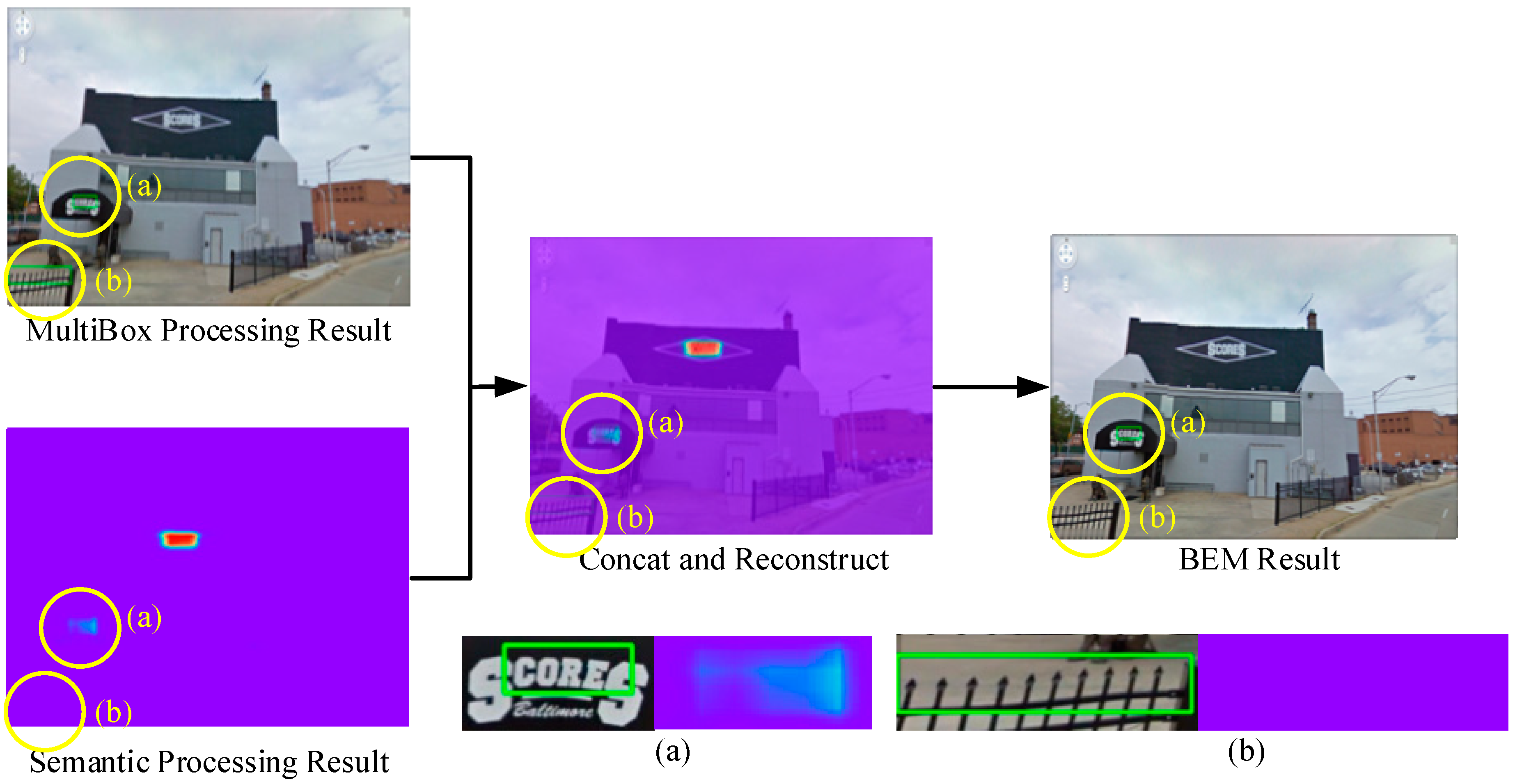
3.2. Bounding Box Enhancement Module
| Algorithm 1. Bounding box enhancement module (BEM) | |
| Step 1. | Acquire a multibox result: Reci = ((x1, y1), (x2, y2))i. i refers to the i-th result. (x1, y1) is the coordinates of the upper left corner of the text bounding box. (x2, y2) is the coordinates of the right bottom corner of the text bounding box. |
| Step 2. | Get the rectangular area AreaRec of Reci in the semantic segmentation result. |
| Step 3. | Calculate the regional median probability: |
| Step 4. | Compare to the threshold T: If : Delete the Reci in the multibox results. Else: continue. |
| Step 5. | Repeat steps 1--4 until all multibox results have been calculated. |
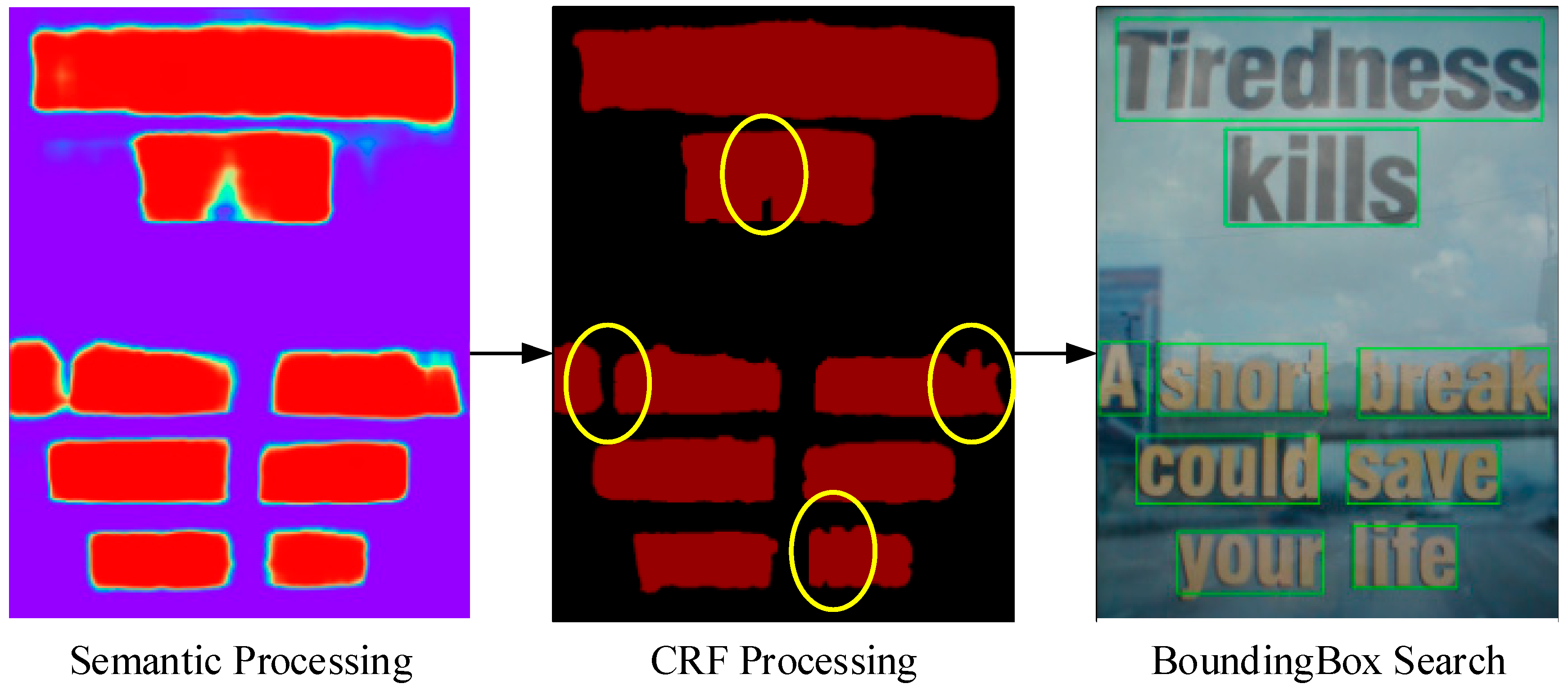
3.3. Semantic Bounding Box Module
4. Experimental Results
4.1. Datasets
4.2. Exploration Study
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fletcher, L.A.; Kasturi, R. A robust algorithm for text string separation from mixed text/graphics images. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 910–918. [Google Scholar] [CrossRef]
- Ye, Q.; Doermann, D. Text detection and recognition in imagery: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1480–1500. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Zhao, L.; Li, X.; Wang, X.; Tao, D. Geometry-aware scene text detection with instance transformation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Chen, H.; Tsai, S.S.; Schroth, G.; Chen, D.M.; Grzeszczuk, R.; Girod, B. Robust text detection in natural images with edge-enhanced maximally stable extremal regions. In Proceedings of the 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Neumann, L.; Matas, J. Real-time scene text localization and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar]
- Shi, C.; Wang, C.; Xiao, B.; Zhang, Y.; Gao, S. Scene text detection using graph model built upon maximally stable extremal regions. Pattern Recognit. Lett. 2013, 34, 107–116. [Google Scholar] [CrossRef]
- Epshtein, B.; Ofek, E.; Wexler, Y. Detecting text in natural scenes with stroke width transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Mosleh, A.; Bouguila, N.; Hamza, A.B. Image text detection using a bandlet-based edge detector and stroke width transform. In BMVC; BMVC: Newcastle, UK, 2012. [Google Scholar]
- He, W.; Zhang, X.Y.; Yin, F.; Liu, C.L. Deep direct regression for multi-oriented scene text detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Liu, Y.; Jin, L. Deep matching prior network: Toward tighter multi-oriented text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimedia 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Xiang, D.; Guo, Q.; Xia, Y. Robust text detection with vertically-regressed proposal network. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016. [Google Scholar]
- Shi, B.; Bai, X.; Belongie, S. Detecting oriented text in natural images by linking segments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Tian, Z.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting text in natural image with connectionist text proposal network. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016. [Google Scholar]
- Tian, S.; Pan, Y.; Huang, C.; Lu, S.; Yu, K.; Lim Tan, C. Text flow: A unified text detection system in natural scene images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Cho, H.; Sung, M.; Jun, B. Canny text detector: Fast and robust scene text localization algorithm. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Zhang, Z.; Zhang, C.; Shen, W.; Yao, C.; Liu, W.; Bai, X. Multi-oriented text detection with fully convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. TextBoxes: A Fast Text Detector with a Single Deep Neural Network; AAAI: Menlo Park, CA, USA, 2017. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An efficient and accurate scene text detector. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- He, P.; Huang, W.; He, T.; Zhu, Q.; Qiao, Y.; Li, X. Single shot text detector with regional attention. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Rother, C.; Kolmogorov, V.; Blake, A. Grabcut: Interactive foreground extraction using iterated graph cuts. In ACM Transactions on Graphics (TOG); ACM: New York, NY, USA, 2004. [Google Scholar]
- Kohli, P.; Torr, P.H. Robust higher order potentials for enforcing label consistency. Int. J. Comput.Vis. 2009, 82, 302–324. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Bigorda, L.G.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.A.; de Las Heras, L.P. ICDAR 2013 robust reading competition. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Wang, K.; Belongie, S. Word spotting in the wild. In European Conference on Computer Vision; Springer: Berlin, Germany, 2010. [Google Scholar]
- Lucas, S.M.; Panaretos, A.; Sosa, L.; Tang, A.; Wong, S.; Young, R.; Ashida, K.; Nagai, H.; Okamoto, M.; Yamamoto, H. ICDAR 2003 robust reading competitions: entries, results, and future directions. Int. J. Doc. Anal Recognit. 2005, 7, 105–122. [Google Scholar] [CrossRef]
- Yin, X.-C.; Yin, X.; Huang, K.; Hao, H.W. Robust text detection in natural scene images. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 970–983. [Google Scholar] [PubMed]
- Neumann, L.; Matas, J. Efficient scene text localization and recognition with local character refinement. In Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Zhang, Z.; Shen, W.; Yao, C.; Bai, X. Symmetry-based text line detection in natural scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | IC13 Standard | DetEval Standard | ||||
|---|---|---|---|---|---|---|
| R 1 | P 2 | F 3 | R | P | F | |
| SSD | 52.20% | 87.76% | 65.18% | 53.06% | 87.24% | 65.98% |
| SSD-IFE | 49.17% | 82.79% | 61.69% | 49.88% | 83.29% | 62.39% |
| SSD-OMC | 69.30% | 81.21% | 74.78% | 70.15% | 85.10% | 76.91% |
| SSTD-IFE | 74.54% | 83.65% | 78.83% | 75.39% | 84.07% | 79.50% |
| SSTD-OMC | 80.51% | 82.27% | 81.38% | 80.43% | 87.60% | 83.86% |
| Network | IC13 Standard | DetEval Standard | ||||
|---|---|---|---|---|---|---|
| R | P | F | R | P | F | |
| SSD | 48.61% | 73.24% | 58.43% | 48.17% | 75.12% | 58.70% |
| SSD-IFE | 50.34% | 79.91% | 61.77% | 50.34% | 79.91% | 61.77% |
| SSD-OMC | 69.91% | 73.57% | 71.69% | 66.01% | 77.97% | 71.48% |
| SSTD-IFE | 78.60% | 73.35% | 75.89% | 78.60% | 73.35% | 75.89% |
| SSTD-OMC | 85.13% | 71.68% | 77.83% | 81.65% | 79.78% | 80.71% |
| Network | IC13 Standard | DetEval Standard | ||||
|---|---|---|---|---|---|---|
| R 1 | P 2 | F 3 | R | P | F | |
| FCN | 62.54% | 60.80% | 61.66% | 66.97 | 62.05% | 64.42% |
| SSD | 52.20% | 87.76% | 65.18% | 53.06% | 87.24% | 65.98% |
| SSD-OMC | 69.30% | 81.21% | 74.78% | 70.15% | 85.10% | 76.91% |
| SSTD | 74.54% | 83.65% | 78.83% | 75.39% | 84.07% | 79.50% |
| SSTD-OMC | 80.51% | 82.27% | 81.38% | 80.43% | 87.60% | 83.86% |
| Network | IC13 Standard | DetEval Standard | ||||
|---|---|---|---|---|---|---|
| R | P | F | R | P | F | |
| Yin [34] | 0.66 | 0.88 | 0.76 | 0.69 | 0.89 | 0.78 |
| Neumann [35] | 0.72 | 0.82 | 0.77 | - | - | - |
| Zhang [36] | 0.74 | 0.88 | 0.80 | 0.76 | 0.88 | 0.82 |
| Textboxes [22] | 0.74 | 0.86 | 0.80 | 0.74 | 0.88 | 0.81 |
| SSTD-OMC | 0.80 | 0.82 | 0.81 | 0.80 | 0.80 | 0.83 |
| Network | IC13 Standard | DetEval Standard | ||||
|---|---|---|---|---|---|---|
| R | P | F | R | P | F | |
| FCN | 50.78% | 54.94% | 52.78% | 55.13% | 54.94% | 55.03% |
| SSD | 48.61% | 73.24% | 58.43% | 48.17% | 75.12% | 58.70% |
| SSD-OMC | 69.91% | 73.57% | 71.69% | 66.01% | 77.97% | 71.48% |
| SSTD | 78.60% | 73.35% | 75.89% | 78.60% | 73.35% | 75.89% |
| SSTD-OMC | 85.13% | 71.68% | 77.83% | 81.65% | 79.78% | 80.71% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, H.; Zhang, H.; Wang, H.; Yan, Y.; Zhang, M.; Zhao, W. An Algorithm for Scene Text Detection Using Multibox and Semantic Segmentation. Appl. Sci. 2019, 9, 1054. https://doi.org/10.3390/app9061054
Qin H, Zhang H, Wang H, Yan Y, Zhang M, Zhao W. An Algorithm for Scene Text Detection Using Multibox and Semantic Segmentation. Applied Sciences. 2019; 9(6):1054. https://doi.org/10.3390/app9061054
Chicago/Turabian StyleQin, Hongbo, Haodi Zhang, Hai Wang, Yujin Yan, Min Zhang, and Wei Zhao. 2019. "An Algorithm for Scene Text Detection Using Multibox and Semantic Segmentation" Applied Sciences 9, no. 6: 1054. https://doi.org/10.3390/app9061054
APA StyleQin, H., Zhang, H., Wang, H., Yan, Y., Zhang, M., & Zhao, W. (2019). An Algorithm for Scene Text Detection Using Multibox and Semantic Segmentation. Applied Sciences, 9(6), 1054. https://doi.org/10.3390/app9061054