Review of Artificial Intelligence Adversarial Attack and Defense Technologies


Abstract
1. Introduction
2. Adversarial Samples and Adversarial Attack Strategies
2.1. Adversarial Example (AE)
2.1.1. Causes of Adversarial Examples
2.1.2. Characteristics of Adversarial Examples
- Transferability. When constructing adversarial samples for an attack against one target model , it is unnecessary to obtain the architecture or parameters of model if the adversary has knowledge of , as long as model is trained to perform the task that model performs as well.
- Advsarial instability. After physical transformation, such as translation and rotation, it is easy to lose its own adversarial for adversarial samples. In this case, adversarial samples will be correctly classified by target models.
- Regularization effect. Adversarial training [15] is a regularization method that can reveal the defects of models and improve the robustness of samples. Compared to other regularization methods, the cost of constructing adversarial samples is expensive.
2.2. Adversarial Capabilities and Goals
2.2.1. Adversarial Capabilities
Training Stage Capabilities
- Data Injection. The adversary does not have any access to the training data and learning algorithms but has the ability to add new data to the training dataset. The adversary can corrupt the target model by inserting adversarial samples into the training dataset.
- Data Modification. The adversary does not have access to the learning algorithms but has access to full training data. The adversary can poison the training data by modifying the data before it is used for training the target model.
- Logic Corruption. The adversary has access to meddle with the learning algorithms of the target model.
Testing Stage Capabilities
- Non-Adaptive Black-Box Attack. The adversaries can only access to the training data distribution of target model f. Therefore, adversaries choose a training procedure for model , and train a local model on samples from the data distribution to approximate the target model. Then, adversaries generate adversarial samples by using white-box attack strategies on model and apply these samples to model f to lead misclassification.
- Adaptive Black-Box Attack. The adversaries cannot access to any information about the target model but can access the model f as an oracle. In this case, adversaries query the target model to obtain output label y by inputting data X, and then adversaries choose a training procedure and a model to train a local model on tuples obtained from querying the target model. Finally, adversaries apply adversarial samples generated by the white-box attack on local model to the target model.
- Strict Black-Box Attack. The adversaries cannot access to the data distribution but can collect input–output pairs from the target model. It differs from the adaptive black-box attack in that it cannot change the inputs to observe the changes in outputs.
2.2.2. Adversarial Goals
- Confidence Reduction. The adversaries attempt to reduce the confidence of prediction for the target model, e.g., the adversarial samples of a “stop” sign is predicted with lower confidence.
- Misclassification. The adversaries attempt to change the output classification of input to any class different from the original class, e.g., an adversarial sample of a “stop” sign is predicted to be any class different from the “stop” sign.
- Targeted Misclassification. The adversaries attempt to change the output classification of the input to a special target class, e.g., any adversarial samples inputted into a classifier is predicted to be a “go” sign.
- Source/Target Misclassification. The adversaries attempt to change the output classification of a special input to a special target class, e.g., a “stop” sign is predicted to be a “go” sign.
3. Adversarial Attacks
3.1. Training Stage Adversarial Attacks
- Modify Training Dataset. Barreno et al. [7] firstly proposed the term poisoning attacks, a common adversarial attack method. They changed the original distribution of training data by modifying or deleting training data or injecting adversarial samples, in order to make the learning algorithm logically changed. Kearns et al. [60] showed that, when the model’s prediction error is smaller than , the probability b of maximum tolerance to modify the training dataset should satisfy:
- Label Manipulation. If an adversary only has the capabilities to modify the training labels with some or all knowledge of the target model, he needs to find the most vulnerable labels. Perturbing labels randomly, one of the most basic methods to modify labels, refers to select a label from the random distribution as the label of training data. Biggio et al. [8] showed that randomly flipping 40% of training labels is enough to reduce the performance of classifiers using SVMs.
- Input Feature Manipulation. In this case, the adversaries are powerful enough to manipulate labels as well as the input features of training points analyzed by the learning algorithm. This scenario also assumes that the adversaries have knowledge of the learning algorithm. Biggio et al. [11] and Mei et al. [13] showed the adversaries injected malicious data generated carefully to change the distribution of training dataset. Therefore, the decision boundary of the trained model changes accordingly, which reduces the accuracy of the model in the test stage, even, leads the model to output the specified misclassification labels. Kloft et al. [9] showed that inserting malicious points into a training dataset can gradually change the decision boundary of an anomaly detection classifier. Similar works have been done in articles [10,12].
3.2. Testing Stage Adversarial Attacks
3.2.1. White-Box Attacks
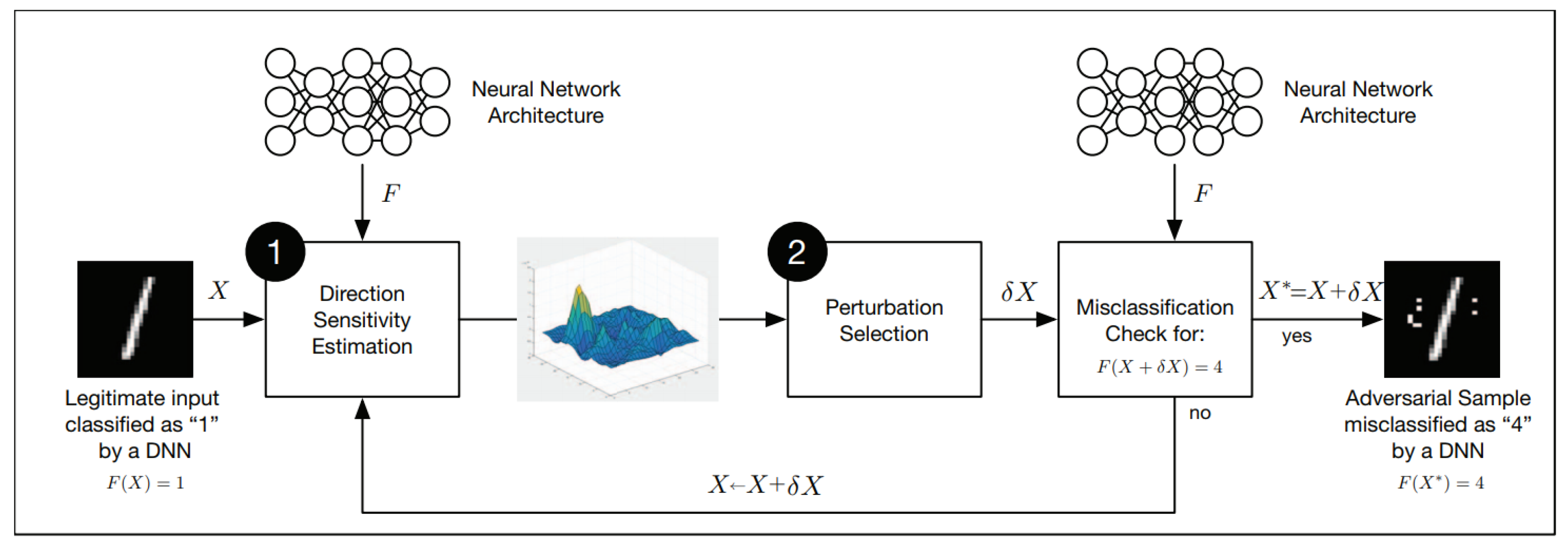
- Direction Sensitivity Estimation. The adversary evaluates the sensitivity of the change to each input feature by identifying directions in the data manifold around sample X in which the model f is most sensitive and likely to result in a class change.
- Perturbation Selection. The adversary then exploits the knowledge of sensitive information to select a perturbation in order to obtain an adversarial perturbation which is most efficient.
Direction Sensitivity Estimation
- L-BFGS. Szegedy et al. [6] firstly introduced the term adversarial sample and formalized the minimization problem, as shown in Formula (3) to search for an adversarial sample. Since this problem is complex, they turned to solve a simplified problem, that is, to find the minimum loss function additions, so that the neural network could make a false classification, which transformed the problem into a convex optimization process. Although this method has good performance, it is expensive to calculate the adversarial samples.
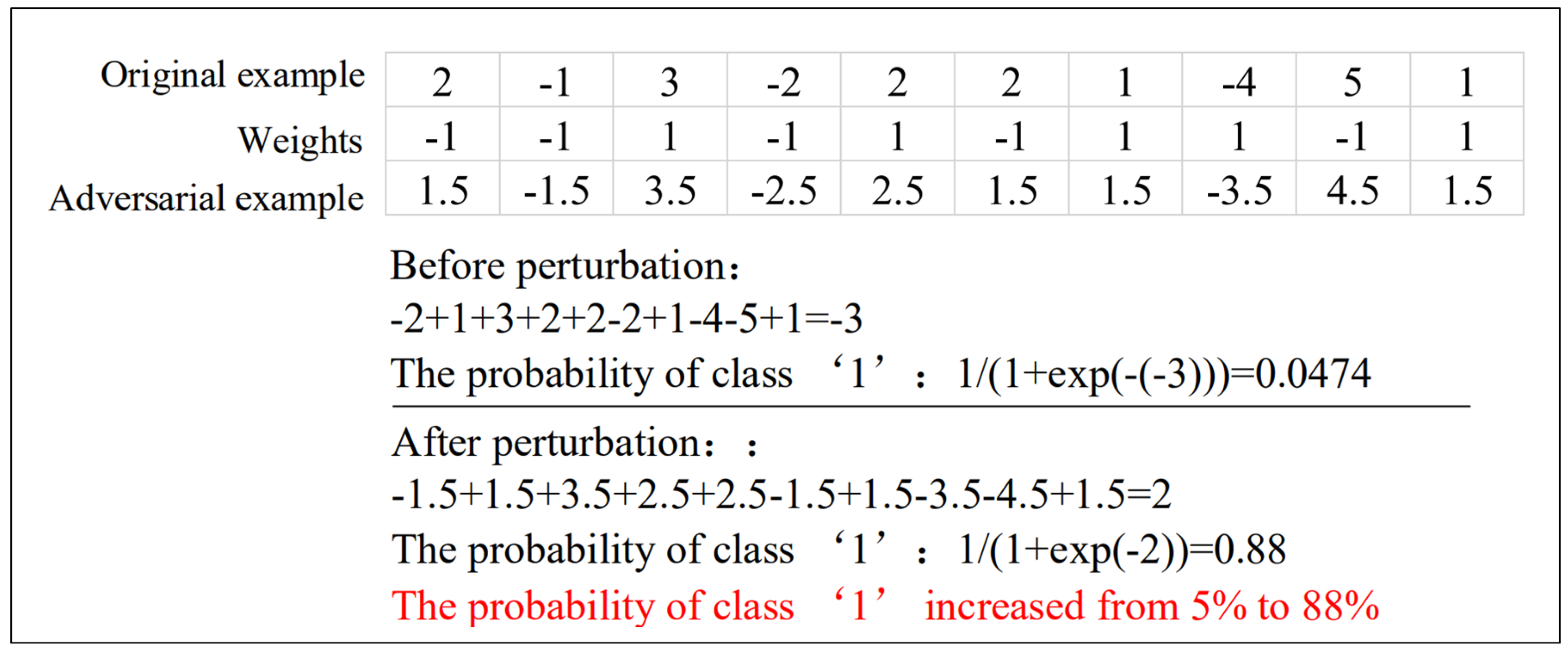
- Fast Gradient Sign Method (FGSM). Goodfellow et al. [15] proposed a Fast Gradient Sign method, which calculates the gradient of the cost function relative to the neural network input. Adversarial samples are produced by the following formula:Here, J is the cost function of model f, indicates the gradient of the model with respect to a normal sample X with correct label , denotes the hyper-parameter which controls the amplitude of the disturbance. Although this is an approximate solution based on linear hypothesis, it also enables the target model to achieve 89.4% misclassification on the MNIST dataset.
- One-Step Target Class Method [16]. This method, a variant of FGSM, maximizes the probability of some specific target class , which is unlikely to be a true class for a given sample. For a model with cross-entropy loss, the adversarial samples could be made following Formula (5) in the one-step target class method:
- Basic Iterative Method (BIM) [16]. This is a straightforward extension of FGSM to apply FGSM multiple times with small step size:Here, the denotes step length, and is the element-wise clipping of X. This method generally does not rely on the approximation of the model and produces additional harmful adversarial samples when this algorithm runs for more iterations. The articles [26,61] have conducted research on this basis and produced good results.
- Iterative Least-Likely Class Method (ILCM) [16]. By using the class with the smallest recognition probability (target class) to replace the class variable in the disturbance, and get adversarial examples which are misclassified in more than 99% of the cases:
- Jacobian Based Saliency Map (JSMA). Papernot et al. [17] proposed a method to find the sensitivity direction by using the Jacobian matrix of the model. This method directly provides the gradient of the output component relative to each input component, and the obtained knowledge is used in the complex saliency map method to produce the adversarial samples. This method limits the norm of the perturbations, which means only a few pixels of the image need to be modified. This method is especially useful for source/target misclassification attacks.
- One Pixel Attack. Su et al. [18] proposed an extreme attack method, which can be achieved by changing an only one-pixel value in the image. They used the differential evolution algorithm to iteratively modify each pixel to generate a sub-image and compared it with the parent image to retain the sub-image with the best attack effect according to the selection criteria to realize the adversarial attacks.
- DeepFool. Moosavi-dezfooli et al. [19] proposed to compute a minimal norm adversarial perturbation for a given image in an iterative manner, in order to find the decision boundary closest to the normal sample X and find the minimal adversarial samples across the boundary. They solved the problem of choosing the parameter under FGSM [15] and carried out the attack against the general nonlinear decision functions by using multiple linear approximations. They demonstrated that the perturbations they generate are smaller than FGSM and have a similar deception rate.
- HOUDINI. Cisse et al. [20] proposed a method called HOUDINI, which deceives gradient-based machine learning algorithms. It realized the adversarial attack by generating adversarial sample specific to the task loss function, i.e., using the gradient information of the differentiable loss function of the network to generate disturbance. They demonstrated that HOUDINI can be used to deceive not only an image classification network but also a speech recognition network.
Perturbation Selection
- Perturb all the input dimensions. Goodfellow et al. [15] proposed a method to interfere with each input dimension, but the amount of interference to calculate the gradient sign direction by the FGSM method is small. This method effectively reduces the Euclidean distance between the original samples and the corresponding adversarial samples.
- Perturb the selected input dimension. Papernot et al. [17] chose a more complex process involving the saliency map and only selected a limited number of input dimensions to perturb. This method effectively reduces the amount of perturbation with the input features when generating adversarial samples.
3.2.2. Black-Box Attacks
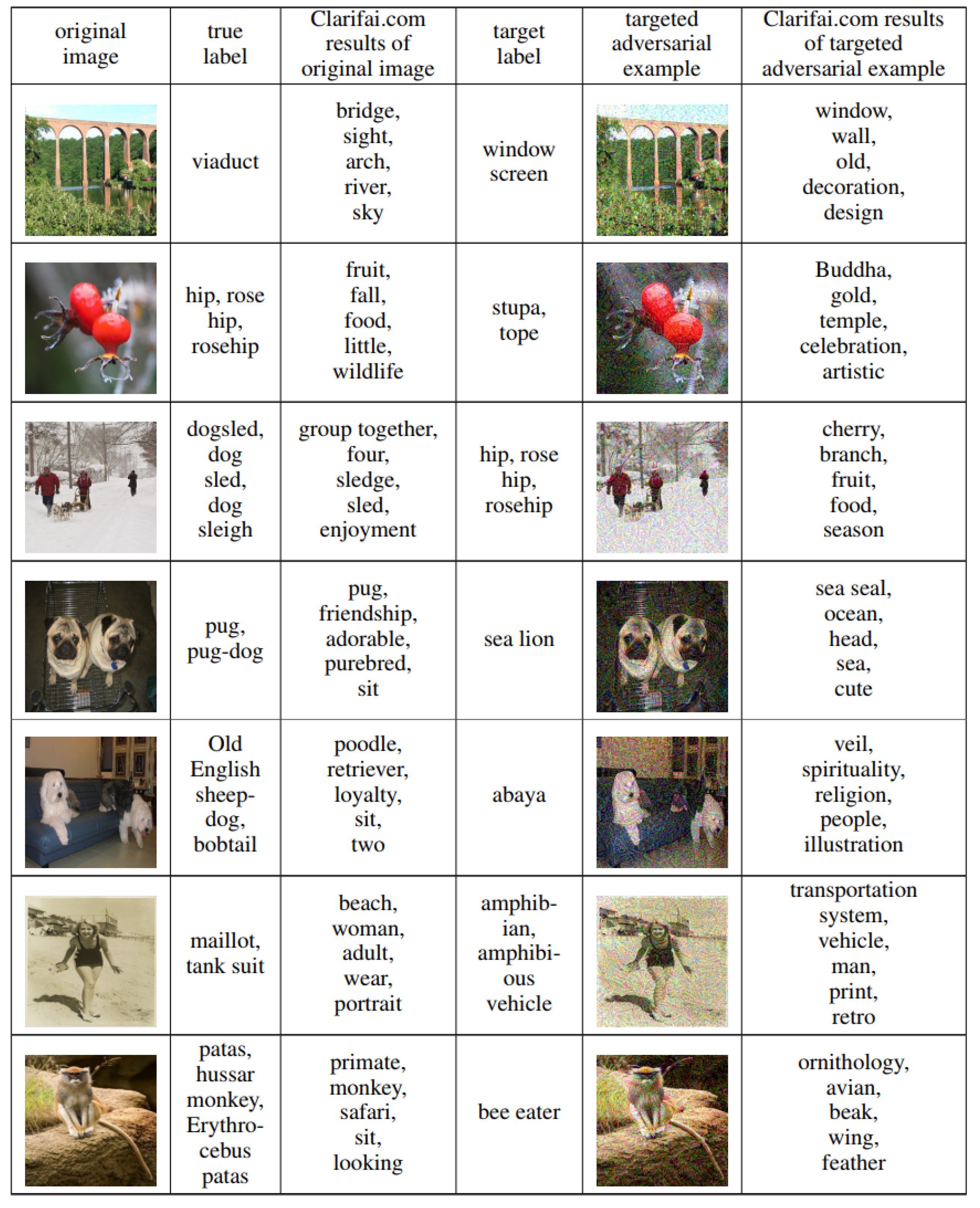
- Utilizing Transferability. Papernot et al. [21] used cross-model transferability of adversarial samples to carry out black-box attack, which used synthetic input generated by the adversary to train a local substitute model and used this substitute model to make adversarial samples, which could be misclassified by the original target model. The articles [14,62] demonstrated that adversarial attacks can lead the misclassification reach 84.24% on MetaMind, an online DNN training model, and then the author used this method on the Amazon cloud service which achieves logical regression, and the misclassification can reach 96%. The greedy heuristic followed by the adversaries is to prioritize the samples when querying oracle labels to obtain a substitute DNN model that approximates decision boundaries of the target model.
- Model Inversion. Fredrikson et al. [22] tried to eliminate the limitations of their previous work [63] and proved that, for a black-box model, adversaries also can predict the genetic markers of patients. These model inversion attacks use machine learning (ML) APIs to infer sensitive features that are used as decision tree models for lifestyle surveys and as input to recover images from API access to facial recognition services. The attack successfully tested facial recognition using multiple neural network models, including softmax regression, multilayer perceptron (MLP), and stacked denoising autoencoder network (DAE). When accessing to the model and the name, the adversaries can recover the face images. The reconstruction results of these three algorithms are shown in Figure 5. Because of the richness of the deep learning model structure, the model inversion attacks can only recover a small number of prototype samples that are similar to the actual data of the defined classes.
- Model Extraction. Tramèr et al. [23] proposed a simple attack method, a strict black-box attack, to extract the target model for popular models, such as logistic regression, neural network, and decision tree. Adversaries can build a local model which has a similar function with the target model. The author demonstrated the model extraction attack against online ML service providers such as BigML and Amazon Machine Learning. The ML APIs provided by the ML-as-Service providers return exact confidence values and class labels. Since the adversaries do not have any information about the model or the distribution of training data, he can attempt to solve mathematically for unknown parameters or features given the confidence value and equations by querying random d-dimensional inputs for unknown parameters.
4. Adversarial Attack Applications
4.1. Computer Vision
4.1.1. Image Classification
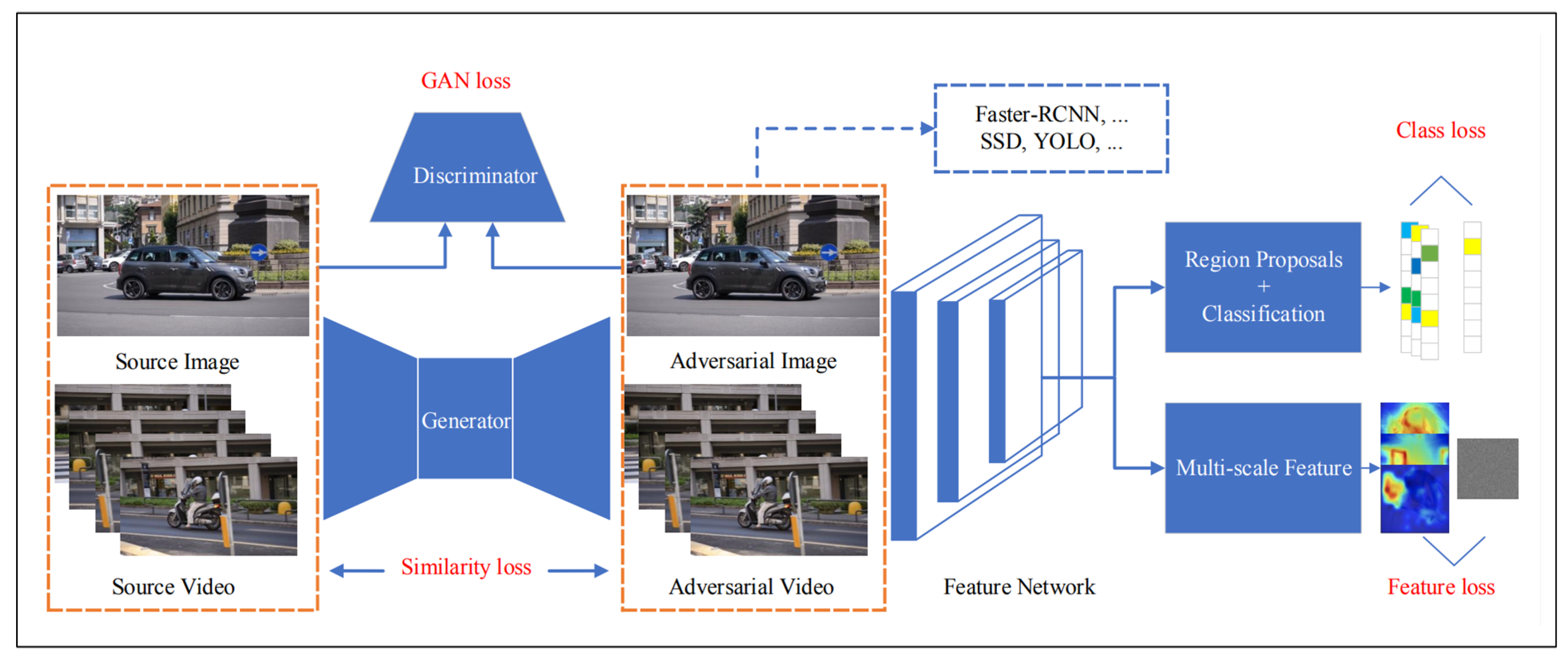
4.1.2. Semantic Image Segmentation and Object Detection
4.2. Natural Language Processing
4.2.1. Text Classification
4.2.2. Machine Translation
4.3. Cyberspace Security
4.3.1. Cloud Service
4.3.2. Malware Detection
4.3.3. Intrusion Detection
4.4. Attack in Physical World
4.4.1. Spoofing Camera
4.4.2. Road Sign Recognition
4.4.3. Machine Vision
4.4.4. Face Recognition
5. Defense Strategy
5.1. Modifying Data
5.1.1. Adversarial Training
5.1.2. Gradient Hiding
5.1.3. Blocking the Transferability
5.1.4. Data Compression
5.1.5. Data Randomization
5.2. Modifying Model
5.2.1. Regularization
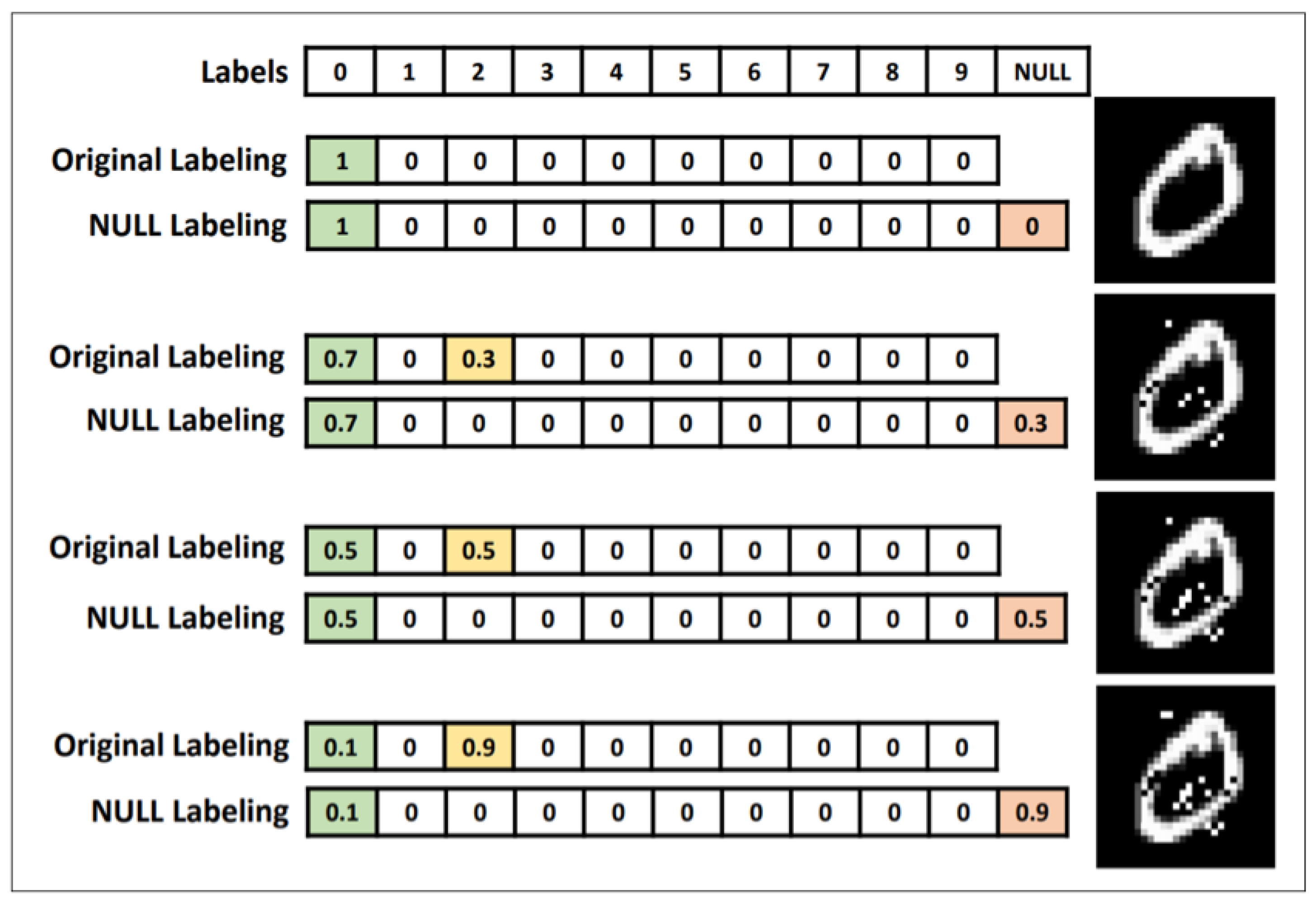
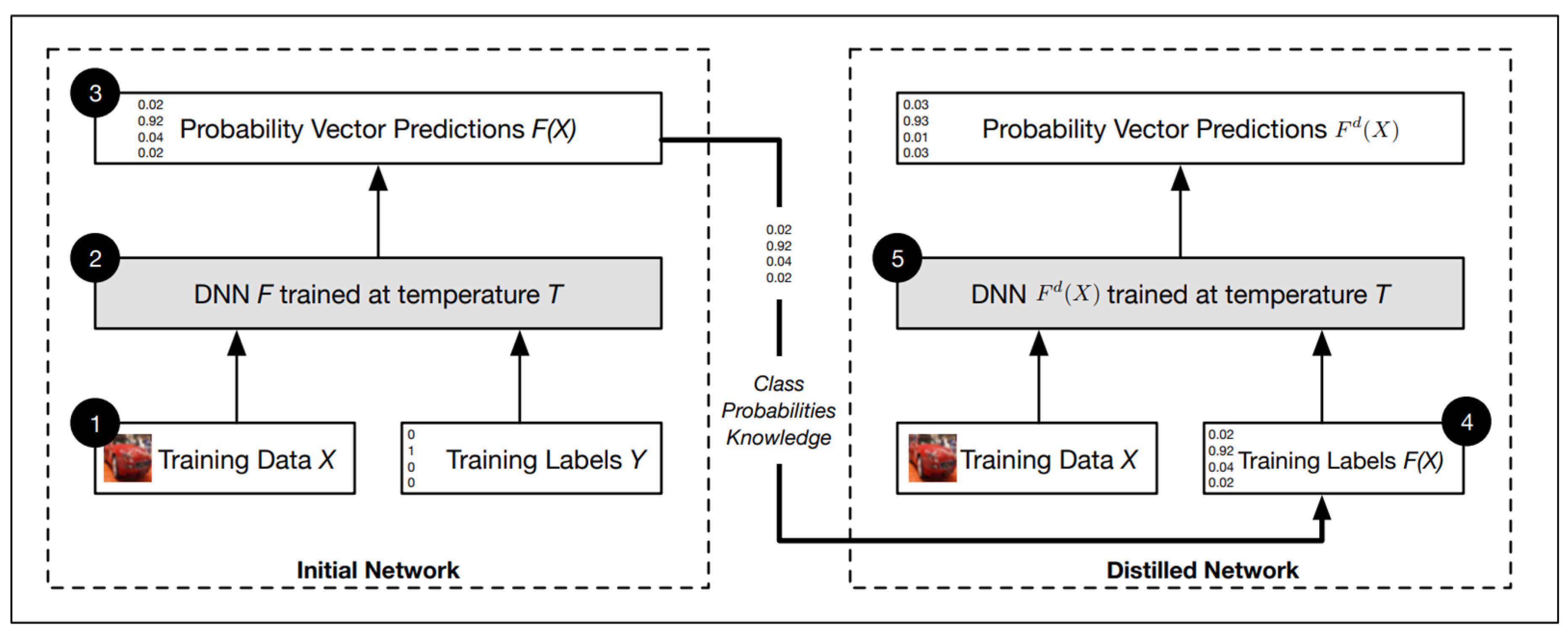
5.2.2. Defensive Distillation
5.2.3. Feature Squeezing
5.2.4. Deep Contractive Network (DCN)
5.2.5. Mask Defense
5.2.6. Parseval Networks
5.3. Using Auxiliary Tool
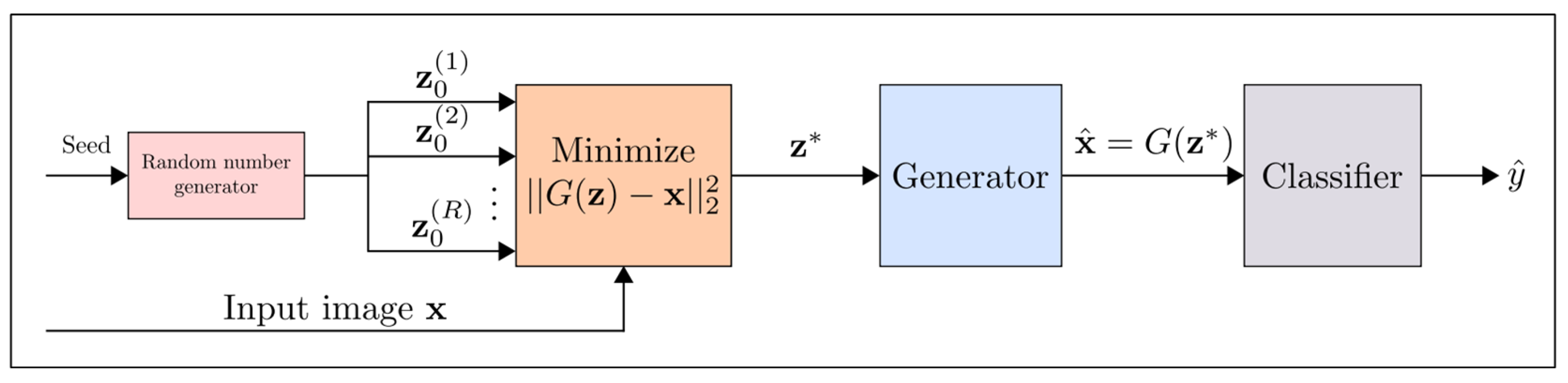
5.3.1. Defense-GAN
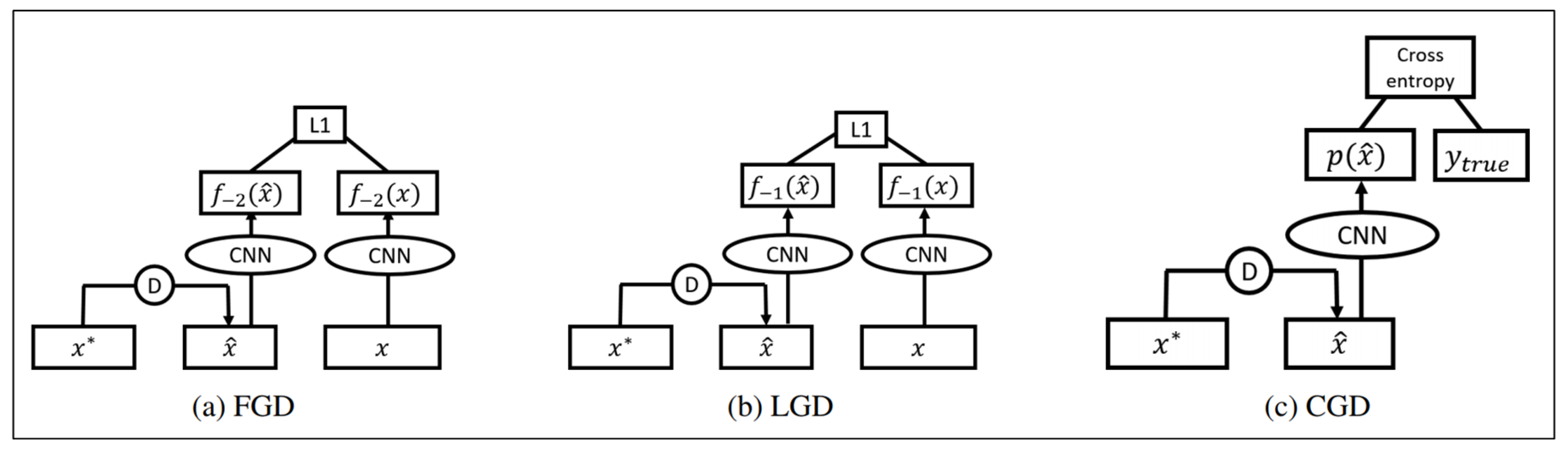
5.3.2. MagNet
5.3.3. High-Level Representation Guided Denoiser (HGD)
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ma, J.; Sheridan, R.P.; Liaw, A.; Dahl, G.E.; Svetnik, V. Deep neural nets as a method for quantitative structure–activity relationships. J. Chem. Inf. Model. 2015, 55, 263–274. [Google Scholar] [CrossRef] [PubMed]
- Helmstaedter, M.; Briggman, K.L.; Turaga, S.C.; Jain, V.; Seung, H.S.; Denk, W. Connectomic reconstruction of the inner plexiform layer in the mouse retina. Nature 2013, 500, 168. [Google Scholar] [CrossRef] [PubMed]
- Ciodaro, T.; Deva, D.; De Seixas, J.; Damazio, D. Online particle detection with neural networks based on topological calorimetry information. J. Phys. Conf. Ser. IOP Publ. 2012, 368, 012030. [Google Scholar] [CrossRef]
- Adam-Bourdarios, C.; Cowan, G.; Germain, C.; Guyon, I.; Kégl, B.; Rousseau, D. The Higgs boson machine learning challenge. In Proceedings of the NIPS 2014 Workshop on High-Energy Physics and Machine Learning, Montreal, QC, Canada, 8–13 December 2014; pp. 19–55. [Google Scholar]
- Xiong, H.Y.; Alipanahi, B.; Lee, L.J.; Bretschneider, H.; Merico, D.; Yuen, R.K.; Hua, Y.; Gueroussov, S.; Najafabadi, H.S.; Hughes, T.R.; et al. The human splicing code reveals new insights into the genetic determinants of disease. Science 2015, 347, 1254806. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv, 2013; arXiv:1312.6199. [Google Scholar]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006; pp. 16–25. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Support vector machines under adversarial label noise. In Proceedings of the Asian Conference on Machine Learning, Taoyuan, Taiwan, 13–15 November 2011; pp. 97–112. [Google Scholar]
- Kloft, M.; Laskov, P. Online anomaly detection under adversarial impact. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 405–412. [Google Scholar]
- Kloft, M.; Laskov, P. Security analysis of online centroid anomaly detection. J. Mach. Learn. Res. 2012, 13, 3681–3724. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. arXiv, 2012; arXiv:1206.6389. [Google Scholar]
- Biggio, B.; Didaci, L.; Fumera, G.; Roli, F. Poisoning attacks to compromise face templates. In Proceedings of the 2013 International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–7. [Google Scholar]
- Mei, S.; Zhu, X. Using Machine Teaching to Identify Optimal Training-Set Attacks on Machine Learners. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2871–2877. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv, 2014; arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv, 2016; arXiv:1611.01236. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Su, J.; Vargas, D.V.; Kouichi, S. One pixel attack for fooling deep neural networks. arXiv, 2017; arXiv:1710.08864. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Cisse, M.; Adi, Y.; Neverova, N.; Keshet, J. Houdini: Fooling deep structured prediction models. arXiv, 2017; arXiv:1707.05373. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, UAE, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing Machine Learning Models via Prediction APIs. In Proceedings of the USENIX Security Symposium, Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Hu, X.; Li, J.; Zhu, J. Boosting adversarial attacks with momentum. arXiv, 2017; arXiv:1710.06081. [Google Scholar]
- Xiao, C.; Deng, R.; Li, B.; Yu, F.; Liu, M.; Song, D. Characterizing adversarial examples based on spatial consistency information for semantic segmentation. arXiv, 2018; arXiv:1810.05162. [Google Scholar]
- Wei, X.; Liang, S.; Cao, X.; Zhu, J. Transferable Adversarial Attacks for Image and Video Object Detection. arXiv, 2018; arXiv:1811.12641. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and natural noise both break neural machine translation. arXiv, 2017; arXiv:1711.02173. [Google Scholar]
- Liang, B.; Li, H.; Su, M.; Bian, P.; Li, X.; Shi, W. Deep text classification can be fooled. arXiv, 2017; arXiv:1704.08006. [Google Scholar]
- Katz, G.; Barrett, C.; Dill, D.L.; Julian, K.; Kochenderfer, M.J. Towards proving the adversarial robustness of deep neural networks. arXiv, 2017; arXiv:1709.02802. [Google Scholar] [CrossRef]
- Krotov, D.; Hopfield, J.J. Dense associative memory is robust to adversarial inputs. arXiv, 2017; arXiv:1701.00939. [Google Scholar] [CrossRef] [PubMed]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial perturbations against deep neural networks for malware classification. arXiv, 2016; arXiv:1606.04435. [Google Scholar]
- Huang, C.H.; Lee, T.H.; Chang, L.H.; Lin, J.R.; Horng, G. Adversarial Attacks on SDN-Based Deep Learning IDS System. In International Conference on Mobile and Wireless Technology; Springer: Hong Kong, China, 2018; pp. 181–191. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning visual classification. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Piscataway, NJ, USA, 2018; pp. 1625–1634. [Google Scholar]
- Melis, M.; Demontis, A.; Biggio, B.; Brown, G.; Fumera, G.; Roli, F. Is deep learning safe for robot vision? adversarial examples against the icub humanoid. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 751–759. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Zhou, Z.; Tang, D.; Wang, X.; Han, W.; Liu, X.; Zhang, K. Invisible Mask: Practical Attacks on Face Recognition with Infrared. arXiv, 2018; arXiv:1803.04683. [Google Scholar]
- Yann, L.; Corinna, C.; Christopher, J. MNIST. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 6 May 2017).
- Huang, R.; Xu, B.; Schuurmans, D.; Szepesvári, C. Learning with a strong adversary. arXiv, 2015; arXiv:1511.03034. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv, 2017; arXiv:1705.07204. [Google Scholar]
- Hosseini, H.; Chen, Y.; Kannan, S.; Zhang, B.; Poovendran, R. Blocking transferability of adversarial examples in black-box learning systems. arXiv, 2017; arXiv:1703.04318. [Google Scholar]
- Dziugaite, G.K.; Ghahramani, Z.; Roy, D.M. A study of the effect of jpg compression on adversarial images. arXiv, 2016; arXiv:1608.00853. [Google Scholar]
- Das, N.; Shanbhogue, M.; Chen, S.T.; Hohman, F.; Chen, L.; Kounavis, M.E.; Chau, D.H. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression. arXiv, 2017; arXiv:1705.02900. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial examples for semantic segmentation and object detection. arXiv, 2017; arXiv:1703.08603. [Google Scholar]
- Wang, Q.; Guo, W.; Zhang, K.; Ororbia, I.; Alexander, G.; Xing, X.; Liu, X.; Giles, C.L. Learning adversary-resistant deep neural networks. arXiv, 2016; arXiv:1612.01401. [Google Scholar]
- Lyu, C.; Huang, K.; Liang, H.N. A unified gradient regularization family for adversarial examples. In Proceedings of the 2015 IEEE International Conference on Data Mining (ICDM), Atlantic City, NJ, USA, 14–17 November 2015; pp. 301–309. [Google Scholar]
- Zhao, Q.; Griffin, L.D. Suppressing the unusual: Towards robust cnns using symmetric activation functions. arXiv, 2016; arXiv:1603.05145. [Google Scholar]
- Rozsa, A.; Gunther, M.; Boult, T.E. Towards robust deep neural networks with BANG. arXiv, 2016; arXiv:1612.00138. [Google Scholar]
- Papernot, N.; McDaniel, P. Extending defensive distillation. arXiv, 2017; arXiv:1705.05264. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv, 2017; arXiv:1704.0115. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv, 2014; arXiv:1412.5068. [Google Scholar]
- Gao, J.; Wang, B.; Lin, Z.; Xu, W.; Qi, Y. Deepcloak: Masking deep neural network models for robustness against adversarial samples. arXiv, 2017; arXiv:1702.06763. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-GAN: Protecting classifiers against adversarial attacks using generative models. arXiv, 2018; arXiv:1805.06605. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems, Proceedings of the Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 135–147. [Google Scholar]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Zhu, J.; Hu, X. Defense against adversarial attacks using high-level representation guided denoiser. arXiv, 2017; arXiv:1712.02976. [Google Scholar]
- Taga, K.; Kameyama, K.; Toraichi, K. Regularization of hidden layer unit response for neural networks. In Proceedings of the 2003 IEEE Pacific Rim Conference on Communications, Computers and signal Processing, Victoria, BC, Canada, 28–30 August 2003; Volume 1, pp. 348–351. [Google Scholar]
- Zhang, J.; Jiang, X. Adversarial Examples: Opportunities and Challenges. arXiv, 2018; arXiv:1809.04790. [Google Scholar]
- Kearns, M.; Li, M. Learning in the presence of malicious errors. SIAM J. Comput. 1993, 22, 807–837. [Google Scholar] [CrossRef]
- Miyato, T.; Maeda, S.i.; Ishii, S.; Koyama, M. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv, 2016; arXiv:1605.07277. [Google Scholar]
- Fredrikson, M.; Lantz, E.; Jha, S.; Lin, S.; Page, D.; Ristenpart, T. Privacy in Pharmacogenetics: An End-to-End Case Study of Personalized Warfarin Dosing. In Proceedings of the USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 17–32. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. arXiv, 2017; arXiv:1610.08401v3. [Google Scholar]
- Sarkar, S.; Bansal, A.; Mahbub, U.; Chellappa, R. UPSET and ANGRI: Breaking High Performance Image Classifiers. arXiv, 2017; arXiv:1707.01159. [Google Scholar]
- Baluja, S.; Fischer, I. Adversarial transformation networks: Learning to generate adversarial examples. arXiv, 2017; arXiv:1703.09387. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-box Adversarial Attacks with Limited Queries and Information. arXiv, 2018; arXiv:1804.08598. [Google Scholar]
- Li, P.; Yi, J.; Zhang, L. Query-Efficient Black-Box Attack by Active Learning. arXiv, 2018; arXiv:1809.04913. [Google Scholar]
- Adate, A.; Saxena, R. Understanding How Adversarial Noise Affects Single Image Classification. In Proceedings of the International Conference on Intelligent Information Technologies, Chennai, India, 20–22 December 2017; pp. 287–295. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Advances in Neural Information Processing Systems; Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 649–657. [Google Scholar]
- Kulynych, B. TextFool. Available online: https://github.com/bogdan-kulynych/textfool (accessed on 6 May 2017).
- Hosseini, H.; Kannan, S.; Zhang, B.; Poovendran, R. Deceiving Google’s Perspective API Built for Detecting Toxic Comments. arXiv, 2017; arXiv:1702.08138. [Google Scholar]
- Samanta, S.; Mehta, S. Generating Adversarial Text Samples. In Advances in Information Retrieval, Proceedings of the 40th European Conference on Information Retrieval Research, Grenoble, France, 26–29 March 2018; Springer International Publishing: Basel, Switzerland, 2018. [Google Scholar]
- Zhao, Z.; Dua, D.; Singh, S. Generating natural adversarial examples. arXiv, 2017; arXiv:1710.11342. [Google Scholar]
- Ebrahimi, J.; Lowd, D.; Dou, D. On Adversarial Examples for Character-Level Neural Machine Translation. arXiv, 2018; arXiv:1806.09030. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into transferable adversarial examples and black-box attacks. arXiv, 2016; arXiv:1611.02770. [Google Scholar]
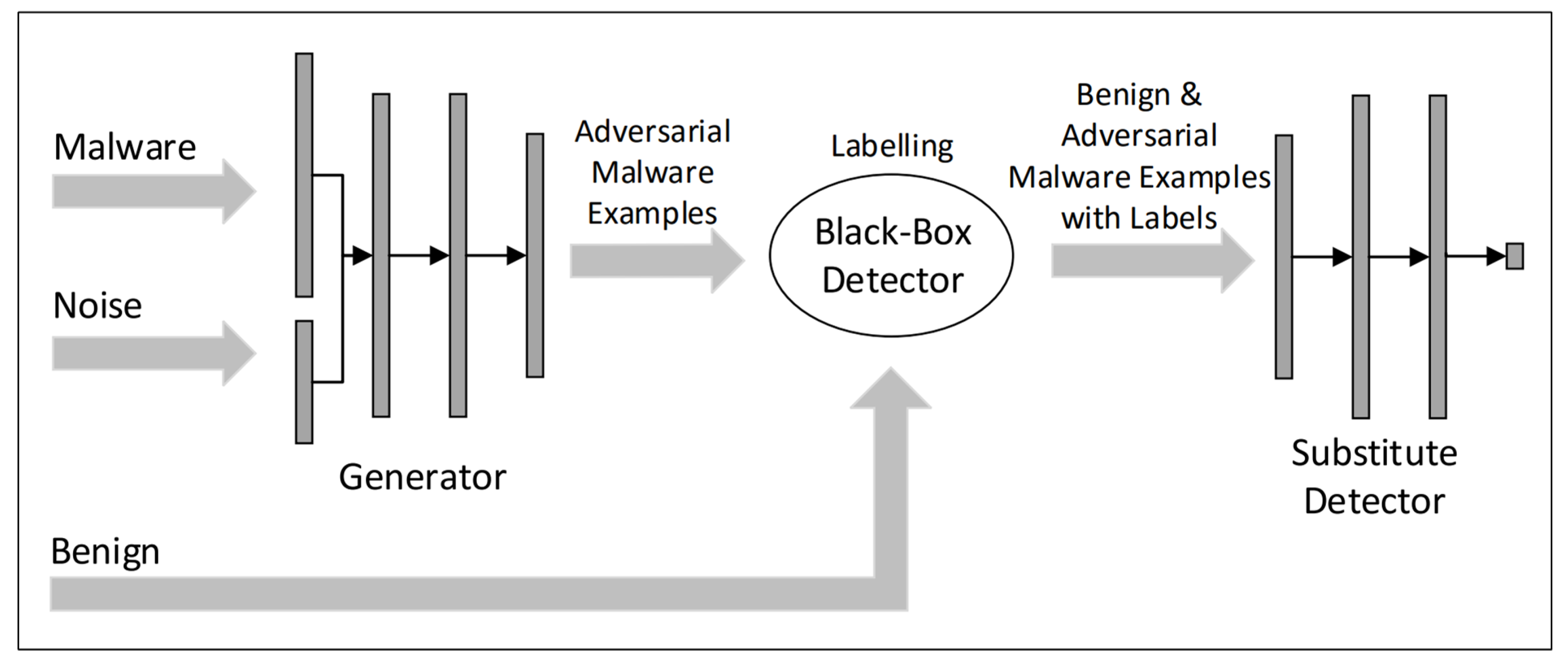
- Hu, W.; Tan, Y. Generating adversarial malware examples for black-box attacks based on GAN. arXiv, 2017; arXiv:1702.05983. [Google Scholar]
- Rosenberg, I.; Shabtai, A.; Rokach, L.; Elovici, Y. Generic Black-Box End-to-End Attack Against State of the Art API Call Based Malware Classifiers. In Proceedings of the International Symposium on Research in Attacks, Intrusions, and Defenses, Heraklion, Greece, 10–12 September 2018; pp. 490–510. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial examples for malware detection. In Proceedings of the European Symposium on Research in Computer Security, Oslo, Norway, 11–15 September 2017; pp. 62–79. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Mogelmose, A.; Trivedi, M.; Moeslund, T. Vision-based traffic sign detection and analysis for intelligent driver assistance systems: Perspectives and survey. Trans. Intell. Transport. Syst. 2012, 3, 1484–1497. [Google Scholar] [CrossRef]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef] [PubMed]
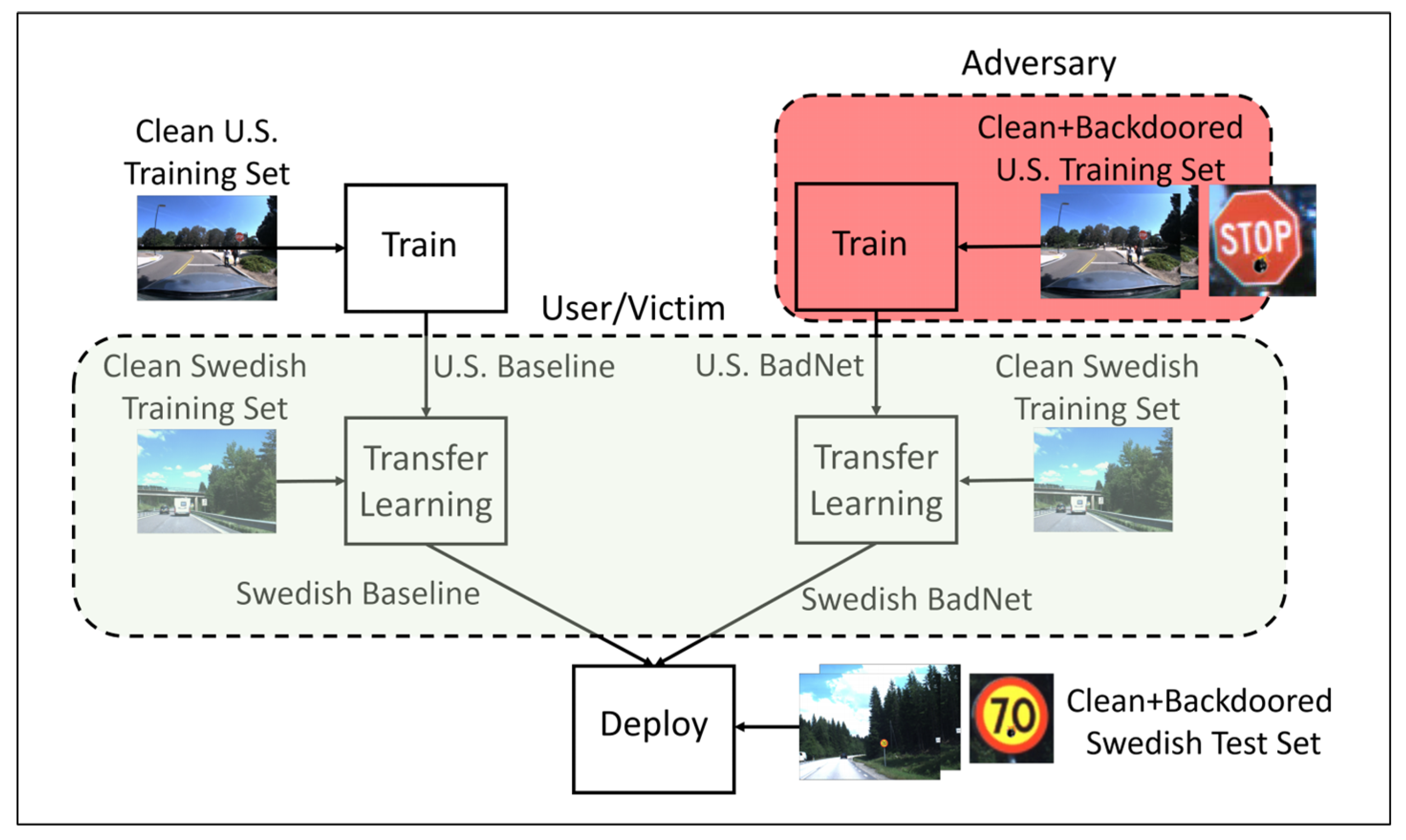
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv, 2017; arXiv:1708.06733. [Google Scholar]
- Xu, X.; Chen, X.; Liu, C.; Rohrbach, A.; Darell, T.; Song, D. Can you fool AI with adversarial examples on a visual Turing test? arXiv, 2017; arXiv:1709.08693. [Google Scholar]
- Rinaldi. Actress Reese Witherspoon. By Eva Rinaldi/CC BY-SA/cropped. Available online: https://goo.gl/a2sCdc (accessed on 6 May 2011).
- Rinaldi The Target. Eva Rinaldi/CC BY-SA/Cropped. Available online: https://goo.gl/AO7QYu (accessed on 21 December 2012).
- Akhtar, N.; Liu, J.; Mian, A. Defense against Universal Adversarial Perturbations. arXiv, 2017; arXiv:1711.05929. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv, 2015; arXiv:1503.02531. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 833–840. [Google Scholar]
- Kovačević, J.; Chebira, A. An introduction to frames. Found. Trends Signal Process. 2008, 2, 1–94. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Articles | Methods | Main Ideas |
|---|---|---|
| Szegedy et al. [6] | L-BFGS | using L-BFGS algorithm to optimize the objective equation . |
| Goodfellow et al. [15] | FGSM | FGSM is used to calculate the gradient of the cost function relative to the input of the neural network, calculate Formula (4) to get adversarial samples and lead the target model to achieve 89.4% misclassification on the MNIST dataset. |
| Kurakin et al. [16] | One-Step Target Class | Calculating the Formula (5) to get adversarial samples. |
| Kurakin et al. [16] | BIM | The adversarial samples generated by FGSM are used in each iteration to generate final adversarial samples by small step length iteration. |
| Kurakin et al. [16] | ILCM | Replacing the target label in the BIM method with the most unlikely labels predicted by the classifier. |
| Papernot et al. [17] | JSMA | Directly providing the gradient of the output component to each input component, and the resulted knowledge is used in complex saliency map methods to generate adversarial samples. |
| Su et al. [18] | One Pixel | Only modifying one pixel per image to generate adversarial samples. |
| Carlini et al. [24] | Carlini & Wagner | Limiting the norm, norm and norm of the perturbations. |
| Moosavi-Dezfooli et al. [19] | DeepFool | Calculating the minimum norm adversarial perturbation iterative method. |
| Moosavi-Dezfooli et al. [64] | Universal perturbation | Generating image independent general adversarial perturbation for many different models. |
| Sarkar et al. [65] | UPSET | Universal Perturbations for Steering to Exact Targets (UPSET) introduced residual generation network, whose input is target class t and output is image unknown disturbance . |
| Sarkar et al. [65] | ANGRI | Antagonistic Network for Generating Rogue Images (ANGRI) calculated image detail perturbation in a closely related way. |
| Cisse et al. [20] | HOUDINI | Deceiving the gradient-based learning machine by generating adversarial samples that can be customized for task loss. |
| Baluja et al. [66] | ANTs | The Adversarial Transformation Networks (ATNs) used a feed-forward neural network to generate adversarial samples. |
| Chen et al. [25] | ZOO | Using the zero-order (ZOO) random coordinate descent method combined with dimensionality reduction, hierarchical attack, and importance sampling technique to carry out black-box attacks effectively. |
| Ilyas et al. [67] | variant of NES | The variant of Natural Evolution Strategies (NES) Proposing the adversarial sample generation method under query limit setting, partial information setting and label only setting respectively. |
| Li et al. [68] | Active learning | Using the white-box attack method to generate samples for queries, and introducing an active learning strategy to significantly reduce the number of queries required. |
| Adate et al. [69] | GAN-based | Using GAN to generate adversarial noise and classify the individual image. |
| Dong et al. [26] | Momentum | Proposing an iterative algorithm based on momentum to enhance the success rate of adversarial attack. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, S.; Liu, Q.; Zhou, S.; Wu, C. Review of Artificial Intelligence Adversarial Attack and Defense Technologies. Appl. Sci. 2019, 9, 909. https://doi.org/10.3390/app9050909
Qiu S, Liu Q, Zhou S, Wu C. Review of Artificial Intelligence Adversarial Attack and Defense Technologies. Applied Sciences. 2019; 9(5):909. https://doi.org/10.3390/app9050909
Chicago/Turabian StyleQiu, Shilin, Qihe Liu, Shijie Zhou, and Chunjiang Wu. 2019. "Review of Artificial Intelligence Adversarial Attack and Defense Technologies" Applied Sciences 9, no. 5: 909. https://doi.org/10.3390/app9050909
APA StyleQiu, S., Liu, Q., Zhou, S., & Wu, C. (2019). Review of Artificial Intelligence Adversarial Attack and Defense Technologies. Applied Sciences, 9(5), 909. https://doi.org/10.3390/app9050909