Deep Learning for Facial Recognition on Single Sample per Person Scenarios with Varied Capturing Conditions

 ,
,
Abstract
1. Introduction
2. Methods
2.1. Face Detection and Alignment
2.2. Feature Extraction
2.3. Matching
3. Evaluation
3.1. Databases
- gb2sTablet: A set of 250 frames coming from the gb2sTablet_Face_Dataset which is part of the proprietary gb2sTablet_Database. It contains images from 60 people captured in an indoor environment using artificial lighting and simple but uncontrolled backgrounds. Images were recorded in a frontal position but without restrictions about the distance to the camera, appearance or accessories. The size of the images is 320 × 240 px.
- gb2s_Selfies: A proprietary database oriented to emulate real daily-life scenarios. Accordingly, this dataset shows different illumination conditions and backgrounds, possible presence and absence of glasses, hear variations, or expressions. Twenty-six individuals participated in the database creation and 10 images per person were recorded in 10 different sessions, one image per day. Each person captured images of his/her face using the frontal camera of his/her own mobile phone the more frontal as possible (Selfie position).
- gb2s_IDCards: A private database oriented to evaluate security applications which require from an official document to verify the identity of the users. In this case, the same 26 individuals participated in the database creation and 10 images per person were recorded in 10 different sessions, one image per day. Each person captured images of his/her ID card using the back camera of his/her own mobile phone.
3.2. Evaluation Protocol
- Dataset Organisation. First, each evaluation dataset was divided into validation and test subsets, which contain 70% and 30% of the samples respectively. Next, validation subset is in turn separated into enrolment and access samples (also 70% and 30%, respectively), to generate the biometric profile of the users and to simulate accesses into the system. This way, methods were validated and the acceptance threshold was adjusted. Then, new accesses into the already configured system were made using the test samples, allowing for the calculation of more realistic performance rates.
- Computation of Scores. A list of genuine and zero-effort impostor scores was generated at this stage. To this end, the biometric template of each user was created using only one enrolment sample, and access samples were divided into genuine and impostor, corresponding to authentic and forger users, respectively. Then, genuine scores were computed by comparing the access samples against the reference template of the same user, and impostor scores were obtained by comparing each access sample against the biometric templates of the other users. The same process was repeated for each enrolment sample.
- Metrics calculation. Finally, certain metrics about the performance of the system were obtained from genuine and impostor scores. Concretely, validation results are offered in terms of Equal Error Rate (EER) and test results wer measured in terms of False Match Rate (FMR) and False Non-Match Rate (FNMR).The threshold associated to the EER computed in the validation stage was used in the test stage.
3.3. Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation from Predicting 10,000 Classes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 1891–1898. [Google Scholar]
- Wang, M.; Deng, W. Deep Face Recognition: A Survey. arXiv 2018, arXiv:1804.06655. [Google Scholar]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Christmas, W.; Li, S.Z.; Hospedales, T. When Face Recognition Meets with Deep Learning: An Evaluation of Convolutional Neural Networks for Face Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Tampa, FL, USA, 5–8 December 2015; pp. 384–392. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Amos, B.; Bartosz, L.; Satyanarayanan, M. OpenFace: A General-Purpose Face Recognition Library with Mobile Applications; Technical Report, CMU-CS-16-118; CMU School of Computer Science: Pittsburgh, PA, USA, 2016. [Google Scholar]
- Zhu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Identity-Preserving Face Space. In Proceedings of the 2013 IEEE International Conference on Computer Vision and Pattern Recognition, Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 113–120. [Google Scholar]
- Zhu, Z.; Luo, P.; Wang, X.; Tang, X. Recover Canonical-View Faces in the Wild with Deep Neural Networks. arXiv 2014, arXiv:1404.3543. [Google Scholar]
- Gao, S.; Zhang, Y.; Jia, K.; Lu, J.; Zhang, Y. Single Sample Face Recognition via Learning Deep Supervised Autoencoders. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2108–2118. [Google Scholar] [CrossRef]
- Hong, S.; Im, W.; Ryu, J.; Yang, H.S. SSPP-DAN: Deep domain adaptation network for face recognition with single sample per person. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 825–829. [Google Scholar]
- Yang, M.; Wang, X.; Zeng, G.; Shen, L. Joint and collaborative representation with local adaptive convolution feature for face recognition with single sample per person. Pattern Recognit. 2017, 66, 117–128. [Google Scholar] [CrossRef]
- Guo, Y.; Jiao, L.; Wang, S.; Wang, S.; Liu, F. Fuzzy Sparse Autoencoder Framework for Single Image per Person Face Recognition. IEEE Trans. Cybern. 2018, 48, 2402–2415. [Google Scholar] [CrossRef] [PubMed]
- Xihua, L. Improving Precision and Recall of Face Recognition in Sipp with Combination of Modified Mean Search and Lsh. Ph.D. Thesis, Beihang University, Beijing, China, 2018. [Google Scholar]
- Zeng, J.; Zhao, X.; Gan, J.; Mai, C.; Zhai, Y.; Wang, F. Deep Convolutional Neural Network Used in Single Sample per Person Face Recognition. Comput. Intell. Neurosci. 2018, 2018, 3803627. [Google Scholar] [CrossRef] [PubMed]
- Ouanan, H.; Ouanan, M.; Aksasse, B. Non-linear dictionary representation of deep features for face recognition from a single sample per person. Procedia Comput. Sci. 2018, 127, 114–122. [Google Scholar] [CrossRef]
- Min, R.; Xu, S.; Cui, Z. Single-Sample Face Recognition Based on Feature Expansion. IEEE Access 2019, 7, 45219–45229. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Weinberger, K.Q.; Blitzer, J.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. In Advances in Neural Information Processing Systems 18; Weiss, Y., Schölkopf, B., Platt, J.C., Eds.; MIT Press: Cambridge, MA, USA, 2006; pp. 1473–1480. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database forStudying Face Recognition in Unconstrained Environments. In Proceedings of the Workshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17 October 2008. [Google Scholar]
- Sandberg, D. Face Recognition Using Tensorflow. 2017. Available online: https://github.com/davidsandberg/facenet (accessed on 8 March 2019).
- Yi, D.; Lei, Z.; Liao, S.; Li, S. Learning Face Representation from Scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Ng, H.W.; Winkler, S. A data-driven approach to cleaning large face datasets. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE Xplore Digital Library: Piscataway, NJ, USA, 2014; pp. 343–347. [Google Scholar]
- BioID. BioID Face Database. Available online: https://www.bioid.com/facedb/ (accessed on 8 March 2019).
- EUCFI. The Essex University Collection of Face Images. Available online: https://cswww.essex.ac.uk/mv/allfaces/index.html (accessed on 8 March 2019).
- ORL. The Database of Faces. Available online: http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html (accessed on 8 March 2019).
- YaleB. The Extended Yale Face Database B. Available online: http://vision.ucsd.edu/~iskwak/ExtYaleDatabase/ExtYaleB.html (accessed on 8 March 2019).
- Anjos, A.; Marcel, S. Counter-Measures to Photo Attacks in Face Recognition: A public database and a baseline. In Proceedings of the International Joint Conference on Biometrics 2011, Washington, DC, USA, 11–13 October 2011. [Google Scholar]
- Ríos-Sánchez, B.; Arriaga-Gómez, M.; Guerra-Casanova, J.; de Santos-Sierra, D.; de Mendizábal-Vázquez, I.; Bailador, G.; Sánchez-Ávila, C. gb2sμMOD: A MUltiMODal biometric video database using visible and IR light. Inf. Fusion 2016, 32, 64–79. [Google Scholar] [CrossRef]
- ISO. ISO/IEC 19795-1:2007: Information Technology—Biometric Performance Testing and Reporting—Part 1: Principles and Framework; International Organization for Standardization (ISO): Geneva, Switzerland, 2007. [Google Scholar]
- ISO. ISO/IEC 19795-2:2007: Information Technology—Biometric Performance Testing and Reporting—Part 2: Testing Methodologies for Technology and Scenario Evaluation; International Organization for Standardization (ISO): Geneva, Switzerland, 2007. [Google Scholar]



{kind=link}
{kind=link}
| Method | Database | Main Variations | # People | # Images | ATD | Match Rate (%) |
|---|---|---|---|---|---|---|
| Face Identity Preserving Features + DNN ([7]) | Multi-PIE | P, I, E, T | 337 | 128,940 | No | 90.46 |
| Face Recovery + FCDN ([8]) | LFW | P, I, S, A, E, T | 5749 | 13,233 | CelebFaces | 97.27 |
| Deep Supervised | Ext. Yale B | I | 38 | 2432 | No | 82.22 |
| Autoencoders ([9]) | AR | I, A | 100 | 2600 | No | 85.21 |
| PIE | I, P, E | 68 | 5508 | No | 72.36 | |
| Multi-PIE | LT, I, V | 337 | 20,209 | No | 76.12 | |
| Virtual image synthesis + DDAN ([10] | EK-LFH | I, B, P, V, S | 30 | 15,930 | No | 72.08 |
| LFW | E, I, LT, O, V, A, P | 158 | >1580 | No | 97.91 | |
| JCR-ACF ([11]) | AR | I, E, A | 100 | 2600 | CASIA-WF | 96.10 |
| Multi-PIE | P, I, E | 249 | 14,940 | CASIA-WF | 70.40 | |
| LFW | E, I, LT, O, V, A, P | 158 | >1580 | CASIA-WF | 86.00 | |
| CASIA-WF | I, P, E, A | 9175 | 406,423 | No | 15.00 | |
| TLFL framework ([12]) | Ext. Yale B | E | 38 | 2404 | No | 34.86 |
| AR | E, I | 100 | 1400 | No | 55.50 | |
| PIE | P, I, E | 68 | 11,630 | No | 55.89 | |
| LFW | E, I, LT, O, V, A, P | 158 | >1422 | No | 15.21 | |
| CAS-PEAL | E | 284 | 1420 | No | 72.95 | |
| JAFFE | E | 10 | 213 | No | 89.47 | |
| Mean search + LSH + DNN ([13] | Msceleb | - | >10,000 | >100,000 | No | 95.00 |
| CASIA-WF | I, P, E, A | 10,408 | >492,744 | No | 52.43 | |
| DCNN ([14]) | AR | I, E, A, T | 100 | 2600 | CASIA-WF | 99.76 |
| Ext. Yale B | P, I | 38 | 2432 | CASIA-WF | 88.30 | |
| FERET | P, E, I | 200 | 1400 | CASIA-WF | 93.90 | |
| LFW | E, I, LT, O, V, A, P | 50 | >500 | CASIA-WF | 74.00 | |
| NDRDF ([15]) | AR | E, I, A, T | 116 | 3016 | No | 98.00 |
| Transfer Learning + KCFT ([16]) | ORL | E, I, A, T | 40 | 400 | CASIA-WF | 98.14 |
| FERET | P, E, I | 200 | 1400 | CASIA-WF | 93.04 | |
| LFW | E, I, LT, O, V, A, P | 50 | >500 | No | 97.49 |
| Type | Output Size | #1 × 1 | #3 × 3 Reduce | #3 × 3 | #5 × 5 Reduce | #5 × 5 | Pool Proj |
|---|---|---|---|---|---|---|---|
| conv1 (7 × 7 × 3,2) | 48 × 48 × 64 | ||||||
| max pool + norm | 24 × 24 × 64 | m 3 × 3,2 | |||||
| inception (2) | 24 × 24 × 192 | 64 | 192 | ||||
| norm + max pool | 12 × 12 × 192 | m3 × 3,2 | |||||
| inception (3a) | 12 × 12 × 256 | 64 | 96 | 128 | 16 | 32 | m, 32p |
| inception (3b) | 12 × 12 × 320 | 64 | 96 | 128 | 32 | 64 | , 64p |
| inception (3c) | 6 × 6 × 640 | 128 | 256,2 | 32 | 64,2 | m 3 × 3,2 | |
| inception (4a) | 6 × 6 × 640 | 256 | 96 | 192 | 32 | 64 | , 128p |
| inception (4e) | 3 × 3 × 1024 | 160 | 256,2 | 64 | 128,2 | m 3 × 3,2 | |
| inception (5a) | 3 × 3 × 384 | 128 | 64 | 192 | , 64p | ||
| inception (5b) | 3 × 3 × 384 | 128 | 64 | 192 | m, 64p | ||
| avg pool | 384 | ||||||
| linear | 128 | ||||||
| normalisation | 128 |
| Type | Output Size | #1 × 1 | #3 × 3 Reduce | #3 × 3 | #5 × 5 Reduce | #5 × 5 | Pool Proj |
|---|---|---|---|---|---|---|---|
| conv1 (7 × 7 × 3,2) | 48 × 48 × 64 | ||||||
| max pool + norm | 24 × 24 × 64 | m 3 × 3,2 | |||||
| inception (2) | 24 × 24 × 192 | 64 | 192 | ||||
| norm + max pool | 12 × 12 × 192 | m3 × 3,2 | |||||
| inception (3a) | 12 × 12 × 256 | 64 | 96 | 128 | 16 | 32 | m, 32p |
| inception (3b) | 12 × 12 × 320 | 64 | 96 | 128 | 32 | 64 | , 64p |
| inception (3c) | 6 × 6 × 640 | 128 | 256,2 | 32 | 64,2 | m 3 × 3,2 | |
| inception (4a) | 6 × 6 × 312 | 128 | 48 | 96 | 16 | 32 | , 56p |
| inception (4e) | 6 × 6 × 504 | 80 | 128,2 | 32 | 64,2 | m 3 × 3,2 | |
| inception (5a) | 3 × 3 × 256 | 96 | 32 | 128 | , 32p | ||
| inception (5b) | 3 × 3 × 256 | 96 | 32 | 128 | m, 32p | ||
| avg pool | 256 | ||||||
| linear | 128 | ||||||
| normalisation | 128 |
| Database | Access | #Users | #Images | Image Size | Color | Variations |
|---|---|---|---|---|---|---|
| Ext. Yale B | Public | 28 | 16,128 | 640 × 480 | gray | L, P |
| ORL | Public | 40 | 400 | 92 × 112 | gray | L, T, E, A |
| BioID | Public | 23 | 1521 | 384 × 286 | gray | B, L, S |
| EUCFI | Public | 395 | 7900 | 180 × 200 | color | B, S, E, A |
| PrintAttack | Public | 38 | 1400 | 320 × 240 | color | L |
| gb2sMOD | Public | 60 | 4220 | 640 × 480 | color | B, S, A |
| gb2sTablet | Private | 60 | 16,593 | 320 × 240 | color | B, S, A |
| gb2s_Selfies | Private | 26 | 262 | - | color | B, L, T, E, A |
| gb2s_IDCards | Private | 26 | 261 | - | gray | L, T |
| Feature Extraction | BioID | EUCFI | ORL | Ext. Yale B | Print Attack | gb2s Tablet | gb2s μMOD | gb2s Selfies | gb2s IDCards | Selfies-IDCards |
|---|---|---|---|---|---|---|---|---|---|---|
| Face Net | 1.47 | 1.16 | 0.25 | 3.60 | 0.05 | 0.05 | 4.28 | 1.91 | 0.55 | 4.66 |
| Open Face | 6.77 | 2.39 | 3.54 | 9.35 | 3.46 | 2.21 | 10.44 | 16.04 | 1.43 | 46.05 |
| gb2s_Model1 | 16.85 | 2.65 | 6.65 | 27.76 | 4.09 | 0.76 | 18.94 | 11.98 | 2.56 | 28.86 |
| gb2s_Model2 | 13.22 | 2.63 | 6.25 | 29.02 | 6.30 | 0.74 | 19.72 | 9.56 | 1.79 | 26.61 |
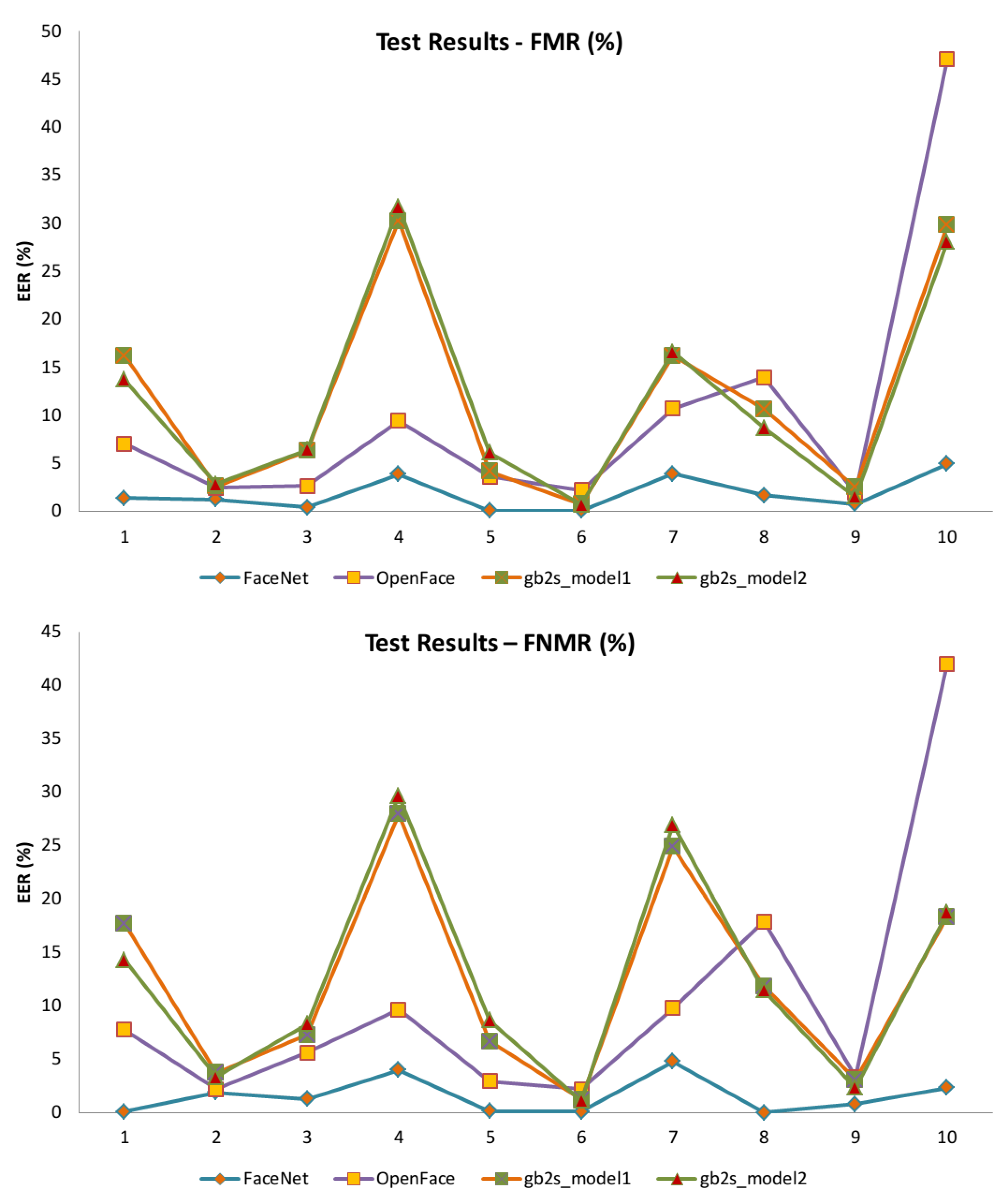
| Database | FaceNet | OpenFace | gb2s_Model1 | gb2s_Model2 | ||||
|---|---|---|---|---|---|---|---|---|
| FMR | FNMR | FMR | FNMR | FMR | FNMR | |||
| BioID | 1.34 | 0.07 | 6.99 | 7.73 | 16.17 | 17.72 | 13.70 | 14.30 |
| EUCFI | 1.21 | 1.85 | 2.44 | 2.16 | 2.55 | 3.71 | 2.79 | 3.30 |
| ORL | 0.35 | 1.25 | 2.62 | 5.60 | 3.29 | 7.25 | 6.35 | 8.25 |
| Ext. Yale B | 3.85 | 3.96 | 9.39 | 9.63 | 30.19 | 27.91 | 31.68 | 29.62 |
| Print Attack | 0.02 | 0.09 | 3.60 | 2.94 | 4.15 | 6.64 | 6.07 | 8.61 |
| gb2sTablet | 0.05 | 0.07 | 2.20 | 2.19 | 0.72 | 1.21 | 0.68 | 1.07 |
| gb2sMOD | 3.89 | 4.77 | 10.67 | 9.76 | 16.18 | 24.87 | 16.53 | 26.91 |
| gb2s_Selfies | 1.66 | 0.00 | 13.91 | 17.90 | 10.60 | 11.83 | 8.67 | 11.45 |
| gb2s_IDCards | 0.70 | 0.76 | 1.86 | 3.33 | 2.47 | 3.05 | 1.51 | 2.29 |
| Selfies-IDCards | 4.89 | 2.29 | 47.00 | 42.00 | 29.77 | 18.32 | 28.00 | 18.70 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ríos-Sánchez, B.; Costa-da-Silva, D.; Martín-Yuste, N.; Sánchez-Ávila, C. Deep Learning for Facial Recognition on Single Sample per Person Scenarios with Varied Capturing Conditions. Appl. Sci. 2019, 9, 5474. https://doi.org/10.3390/app9245474
Ríos-Sánchez B, Costa-da-Silva D, Martín-Yuste N, Sánchez-Ávila C. Deep Learning for Facial Recognition on Single Sample per Person Scenarios with Varied Capturing Conditions. Applied Sciences. 2019; 9(24):5474. https://doi.org/10.3390/app9245474
Chicago/Turabian StyleRíos-Sánchez, Belén, David Costa-da-Silva, Natalia Martín-Yuste, and Carmen Sánchez-Ávila. 2019. "Deep Learning for Facial Recognition on Single Sample per Person Scenarios with Varied Capturing Conditions" Applied Sciences 9, no. 24: 5474. https://doi.org/10.3390/app9245474
APA StyleRíos-Sánchez, B., Costa-da-Silva, D., Martín-Yuste, N., & Sánchez-Ávila, C. (2019). Deep Learning for Facial Recognition on Single Sample per Person Scenarios with Varied Capturing Conditions. Applied Sciences, 9(24), 5474. https://doi.org/10.3390/app9245474