Reinforcement Learning-Based Anti-Jamming in Networked UAV Radar Systems


Abstract
:1. Introduction
- 1.
- Intelligent UAVs may be energy-limited. The energy modules on most UAVs may pose a major constraint on their motion ability. Meanwhile, when the UAV carries a radar payload to perform detection tasks, its motion and adaptation of the radar parameters may introduce considerable energy consumption. Therefore, a UAV may need to strike a beneficial trade-off between the motion energy and energy consumed by the radar.
- 2.
- The antenna performance of smart UAVs may be limited. Due to the limited volume and load capacity of the UAV, the number of array elements may be limited, resulting in poor spatial resolution. However, the beam width adopted by radar in certain tasks may demand high spatial resolutions, e.g., when measuring angle by beam scanning method. Therefore, the networked UAV radar system should exploit the distributed UAV cooperation to overcome the antenna constraint of a single UAV.
- 3.
- The topology of the networked UAV radar system may be complex. In order to comprehensively analyse the received information, the target data need to be transmitted to a data fusion center. Therefore, secondary forwarding devices such as relays may be applied during long-range communications. The networked UAV radar system should control complexity of information transmission process, and control the risks of information interception and jamming.
- 1.
- A radar countermeasure system based on intelligent networked UAV swarms is established. Compared with the existing radar countermeasure models, our model introduces joint programming of UAV-borne radar to make full use of various degrees of freedom, where the policies can be generated from three dimensions of antenna, frequency and position.
- 2.
- Two UAV radar networking modes are proposed and implemented. The simulation results show that the proposed algorithm can realize the effective programming of radar system parameters in both modes.
- 3.
- This paper introduces a novel reward design by the information representation method to quantify the information received by the networked UAV radar systems.
2. Related Works
3. System Model
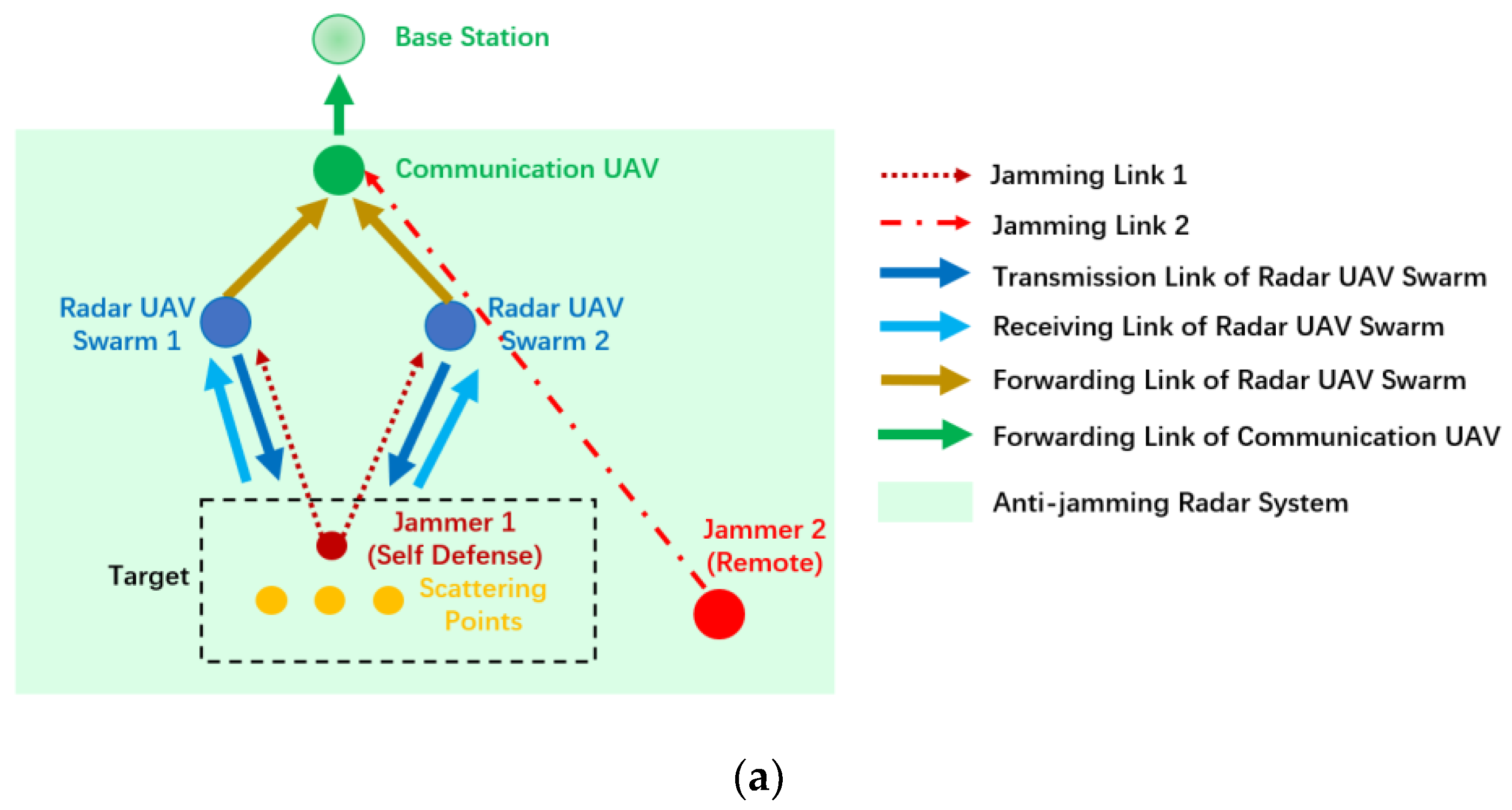
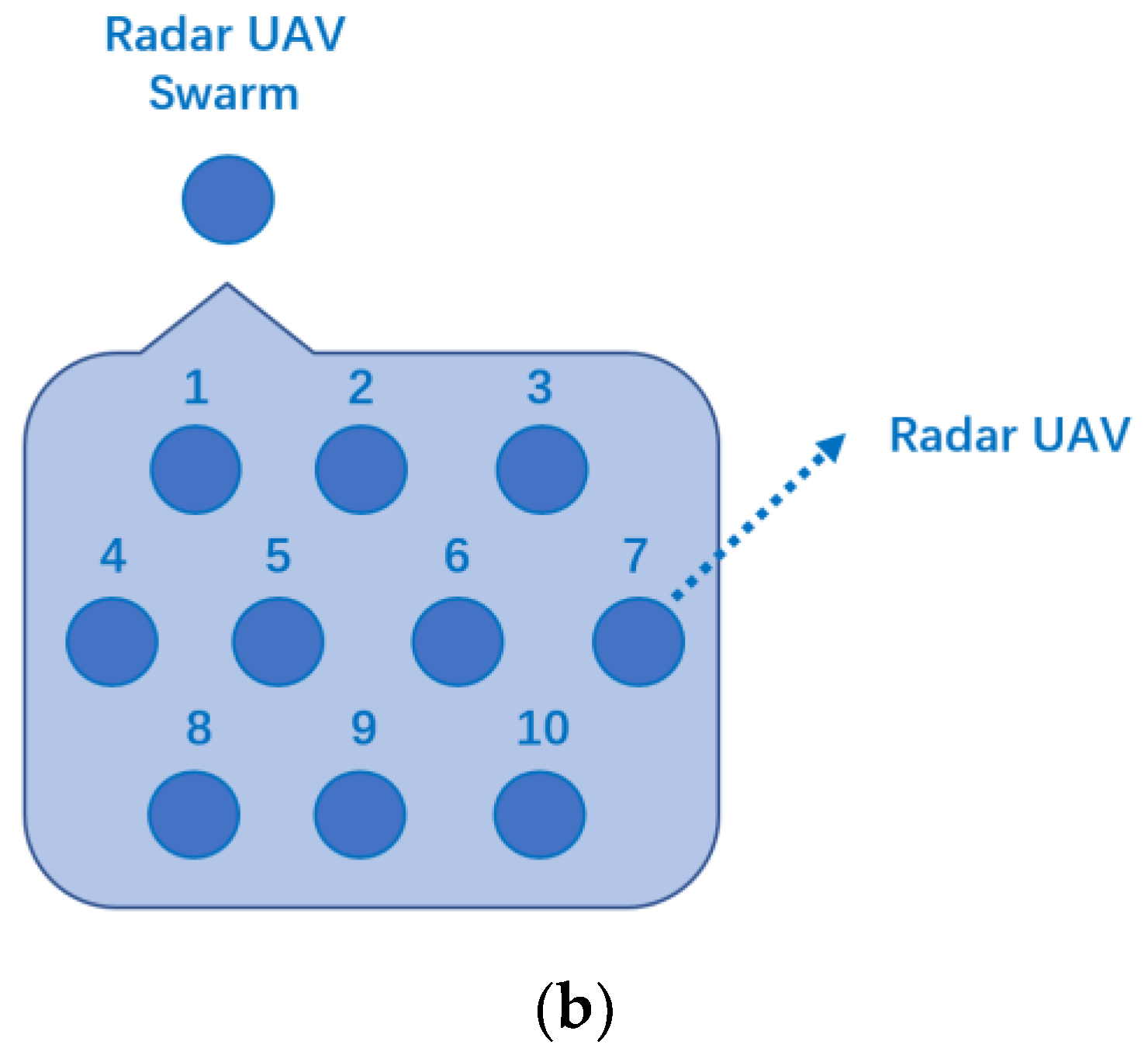
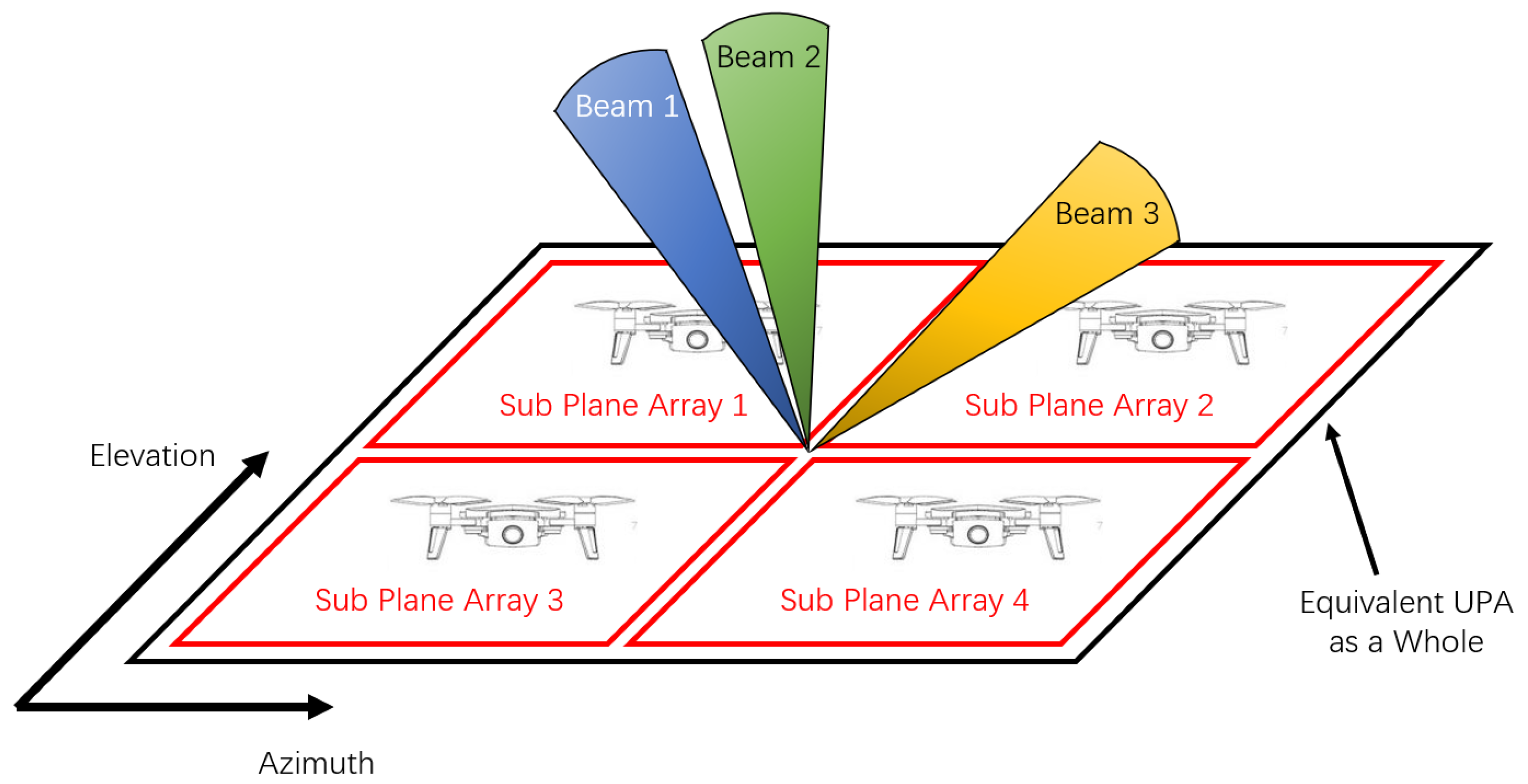
3.1. Modeling of Radar Unmanned Aerial Vehicle (UAV) Swarm Networking
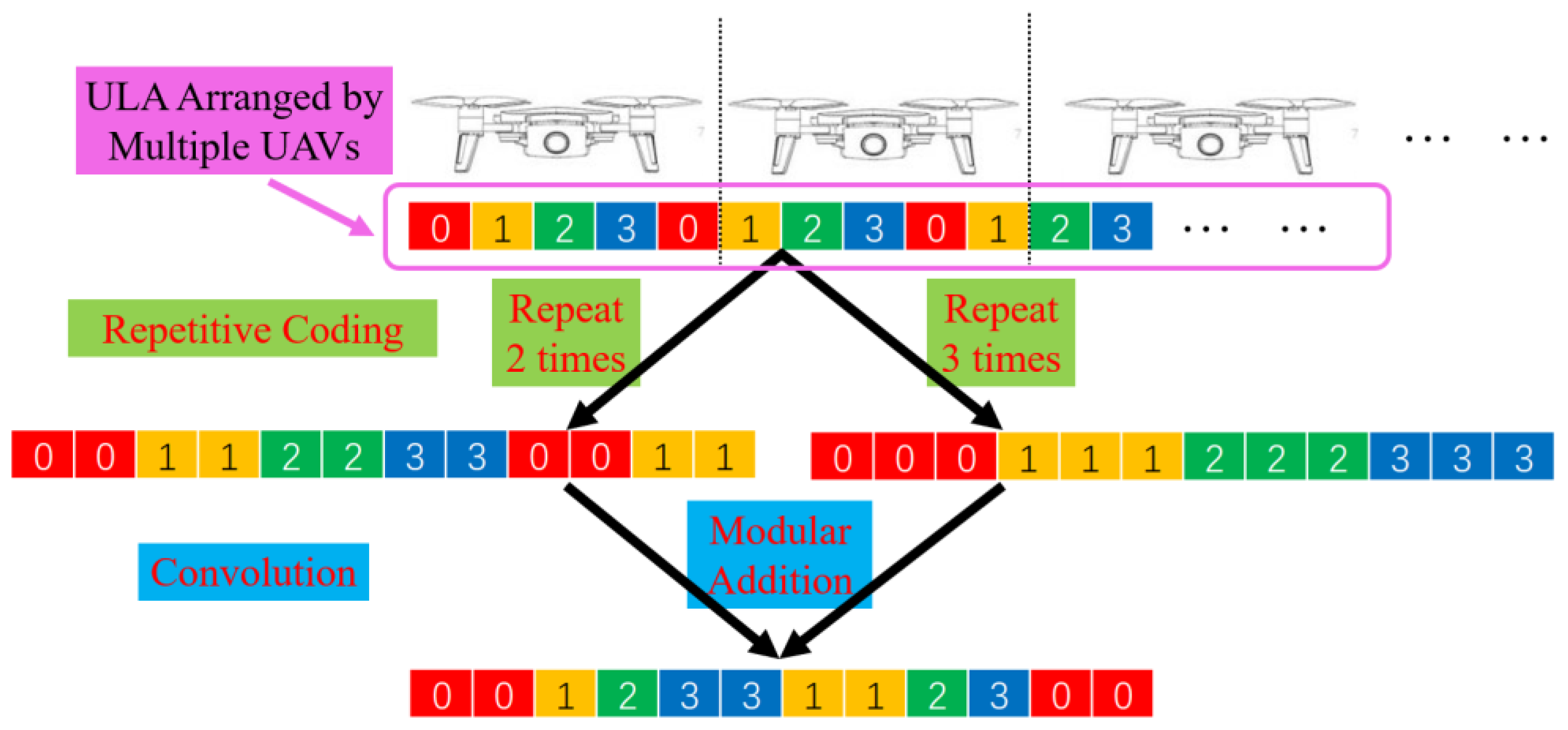
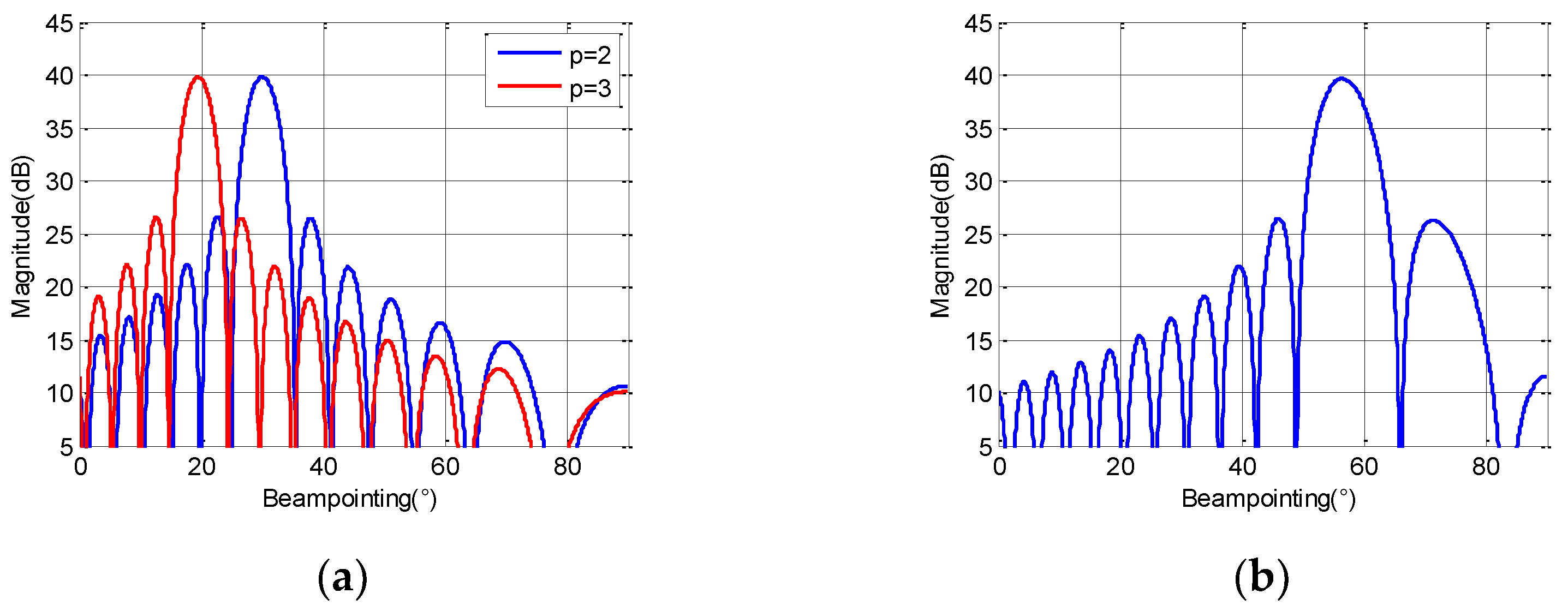
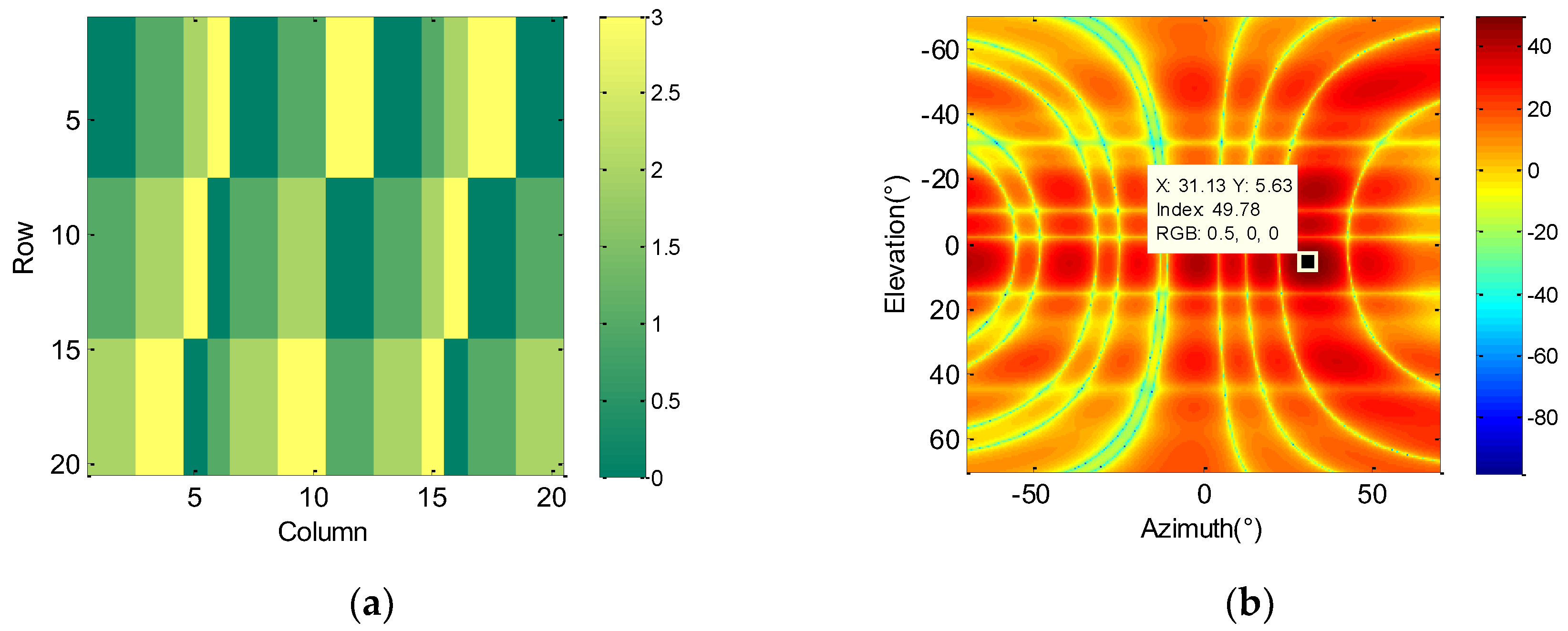
3.2. Beam Synthesis Method under Low-Bit Phase Array
4. Algorithm Design
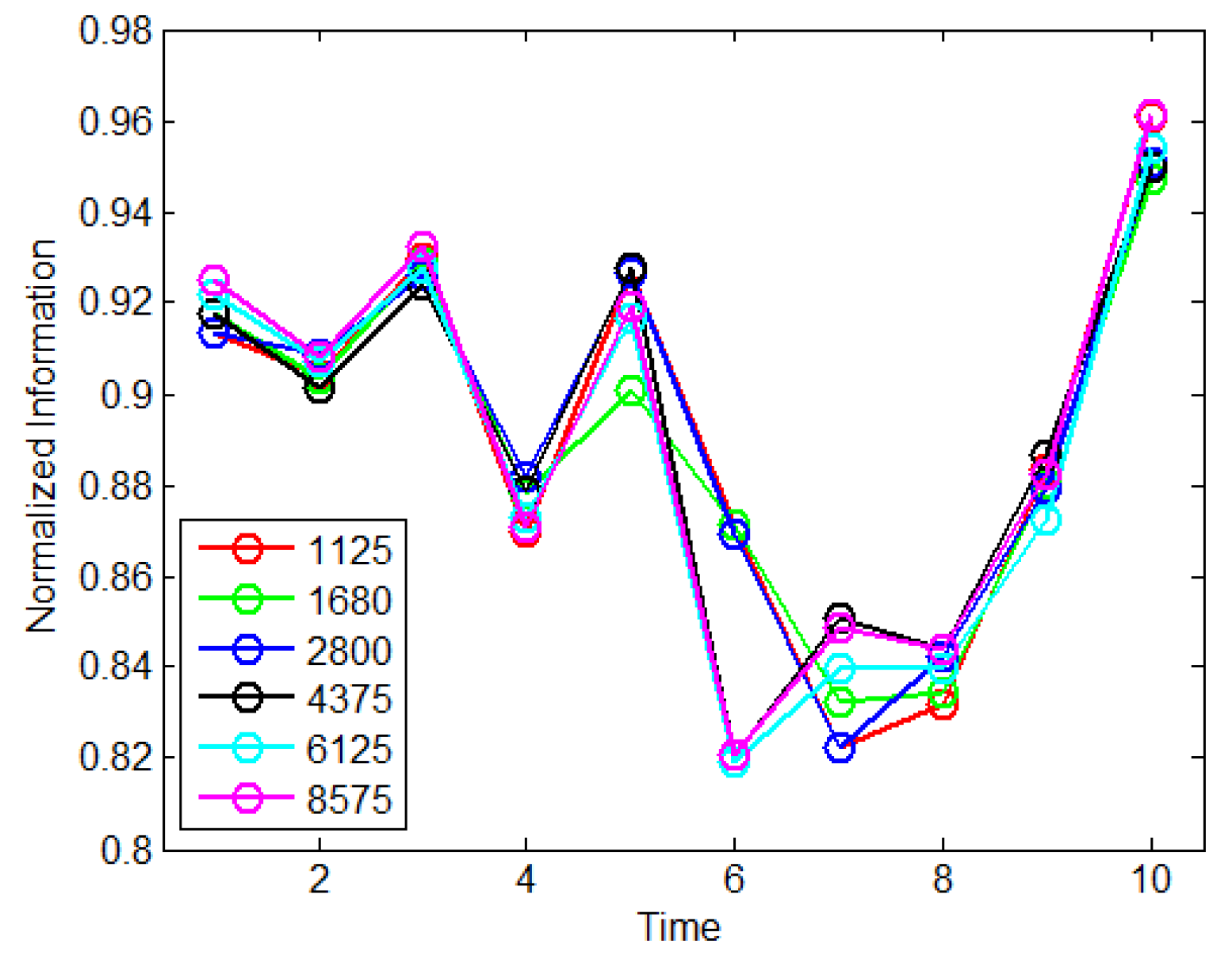
4.1. Information Representation Reward Design
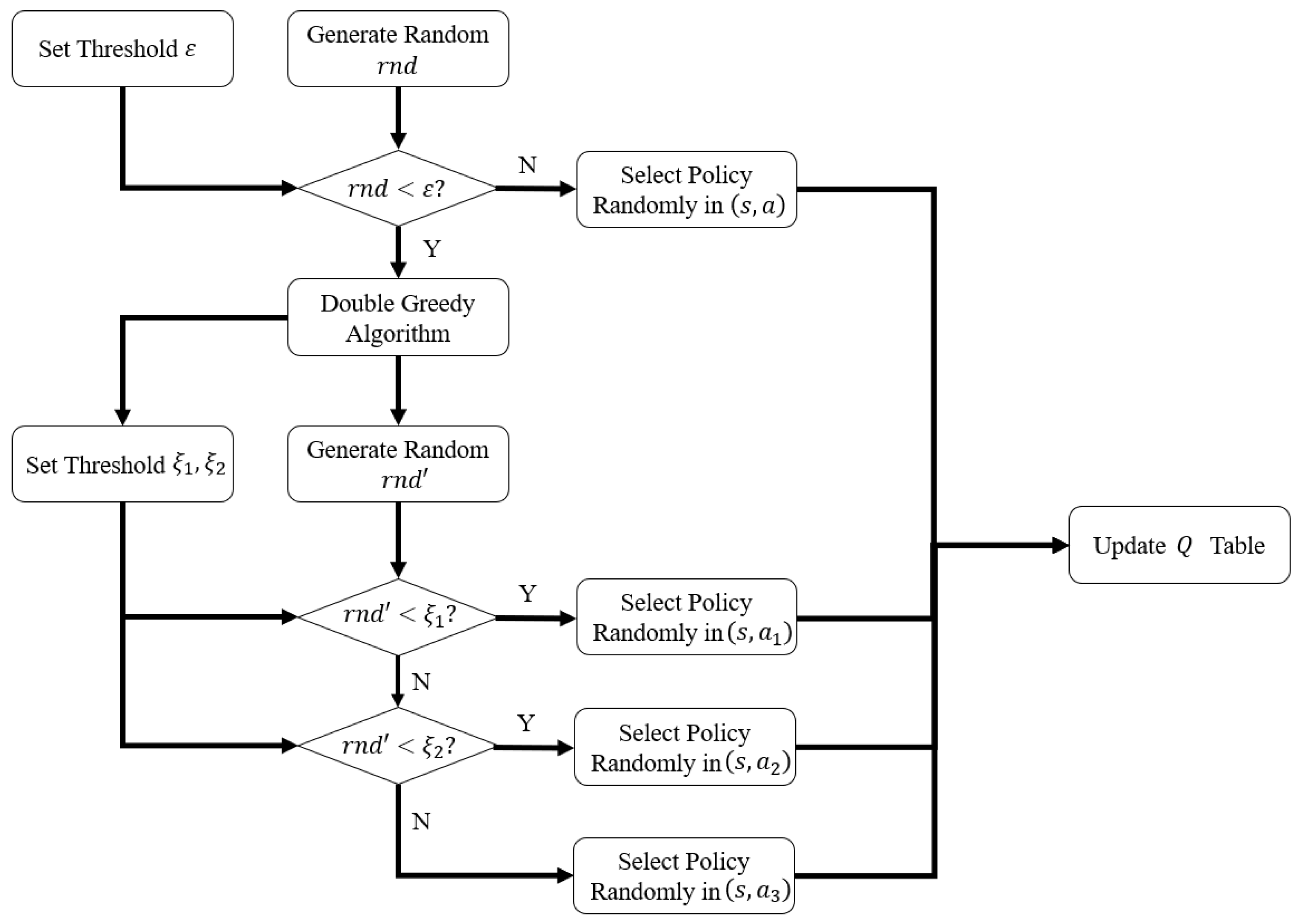
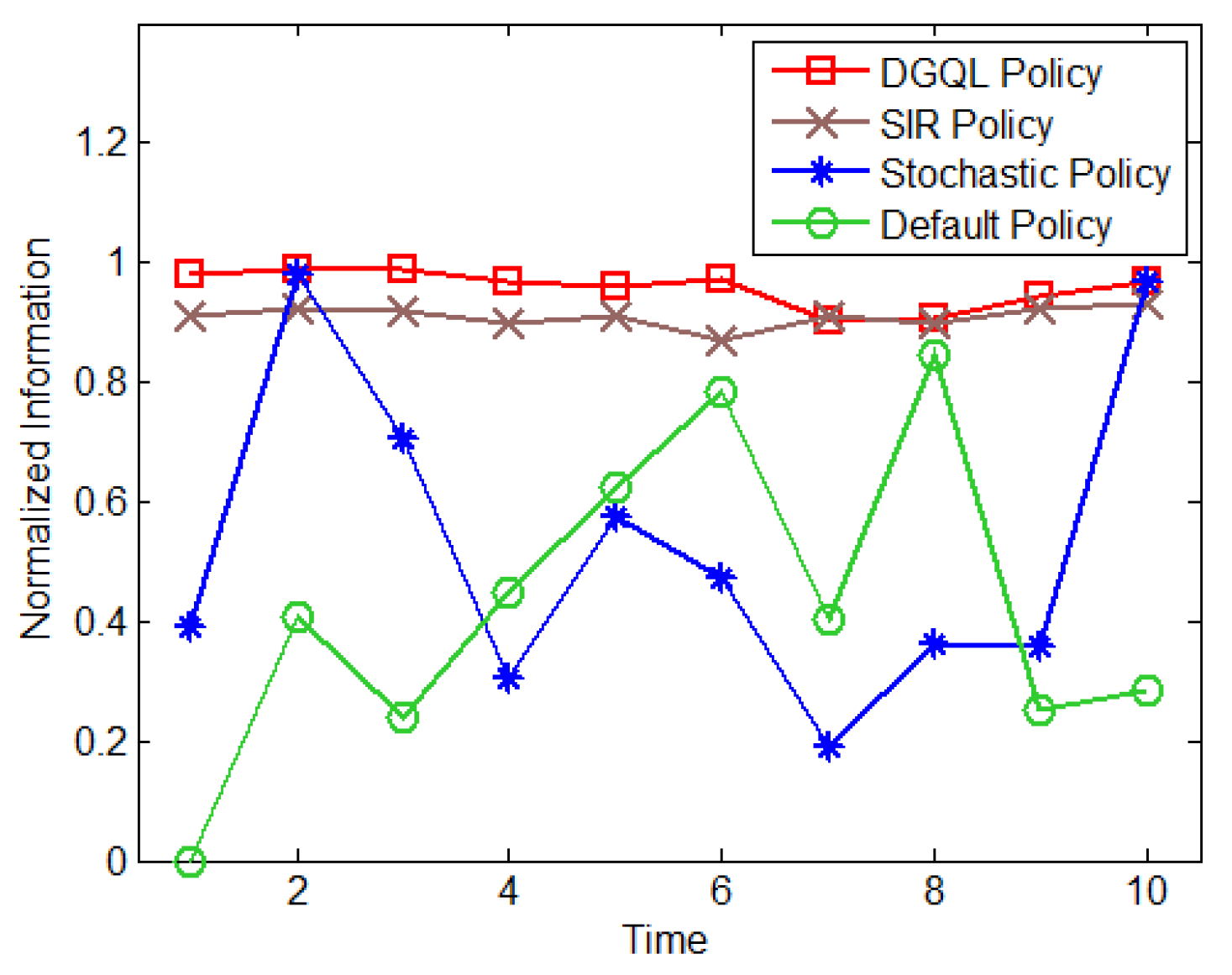
4.2. DGQL (Double-Greedy Reinforcement Learning) Algorithm Based on Information Representation
| Algorithm 1. Double-Greedy Reinforcement Learning Algorithm |
| Initialize table set for in radar policies and jamming policies do Generate , via network topology if mode 1 then else if mode 2 then end if end for Set arbitrarily for each episode do Initialize for each step of episode do Generate random number and if < then Extract action subset from Generate random number if then Choose from using policy derived from else if then Choose from using policy derived from else: Choose from using policy derived from end if else Choose randomly from end if Take action , observe , until is terminal end for end for |
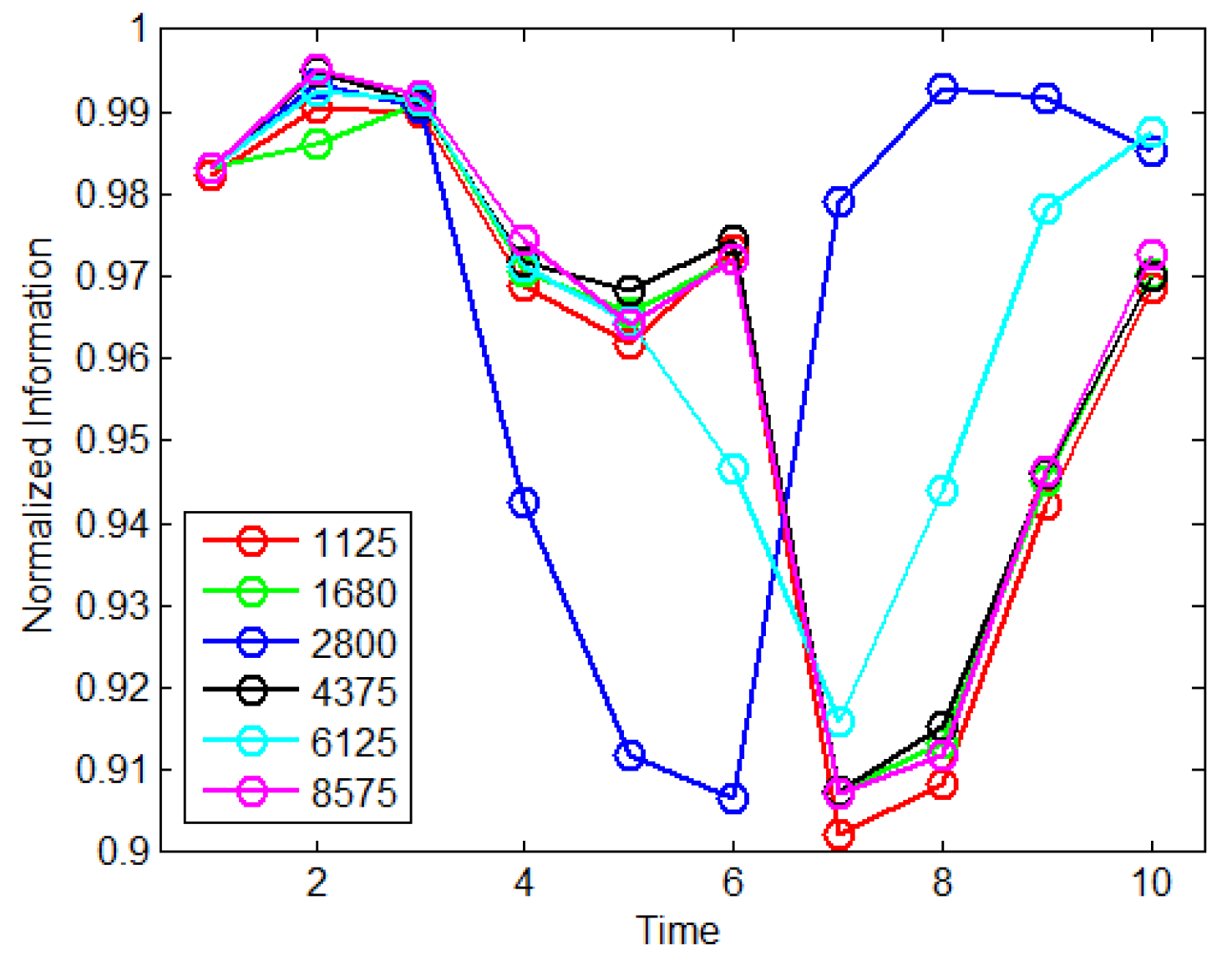
5. Simulation Results
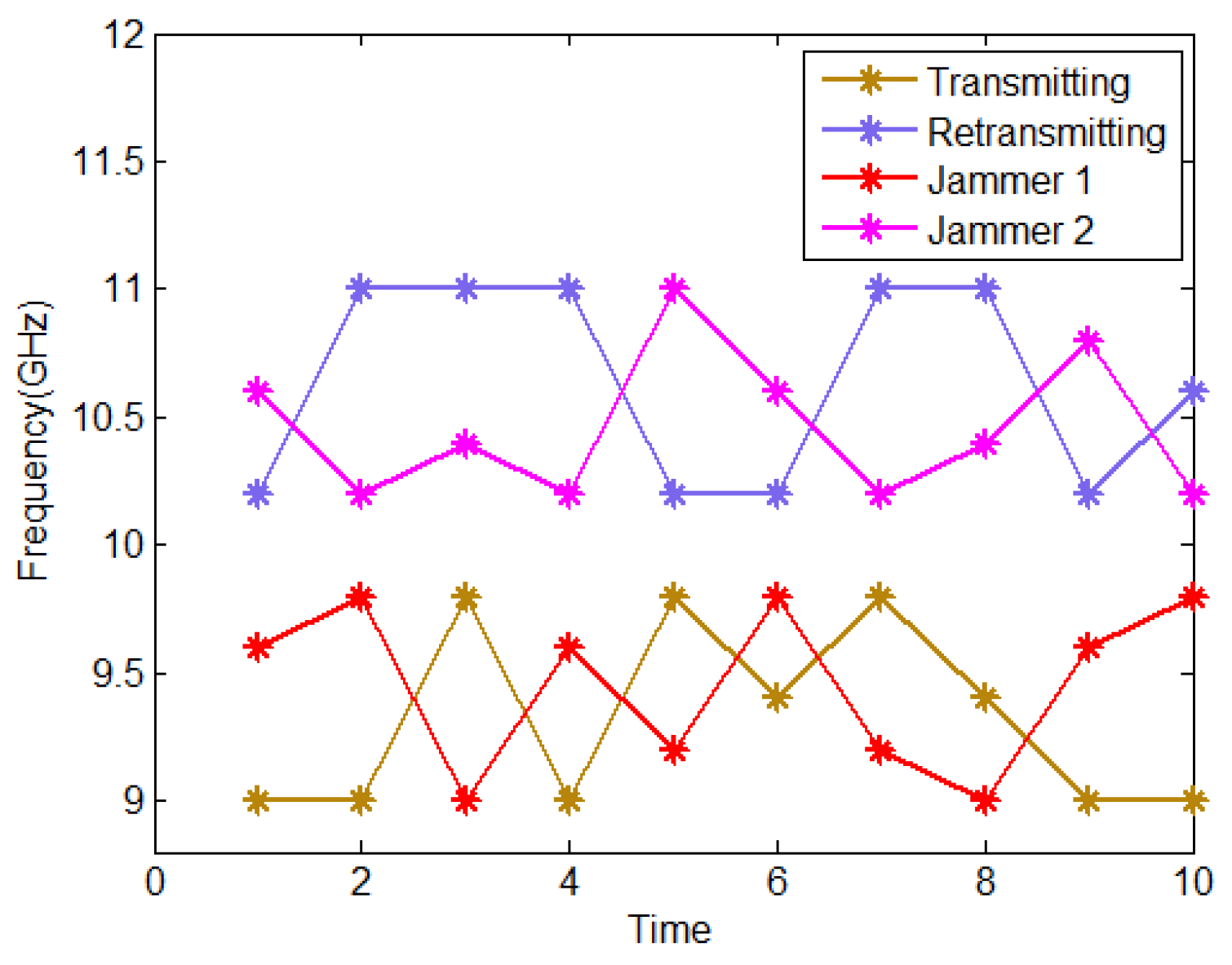
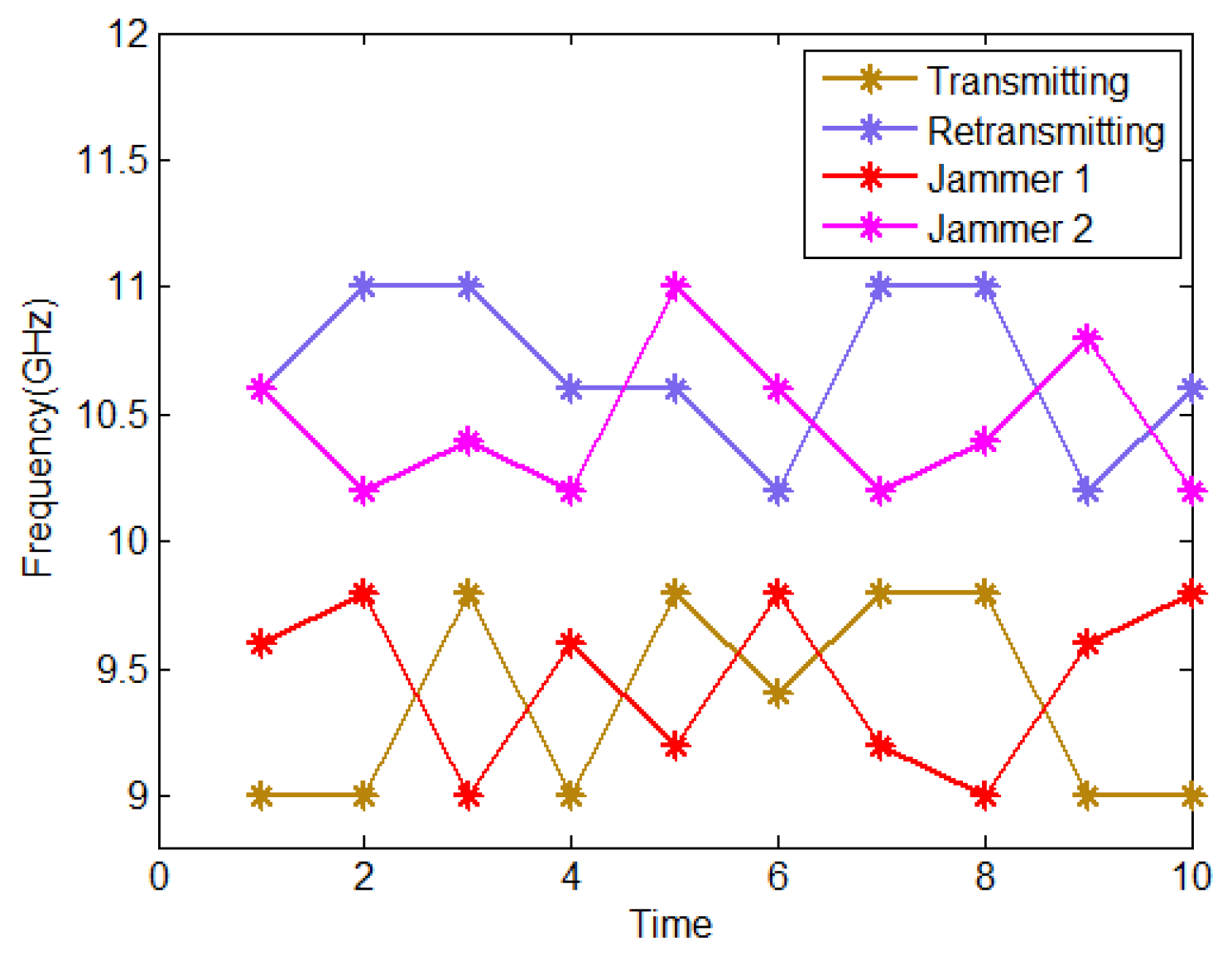
5.1. Map Gridding
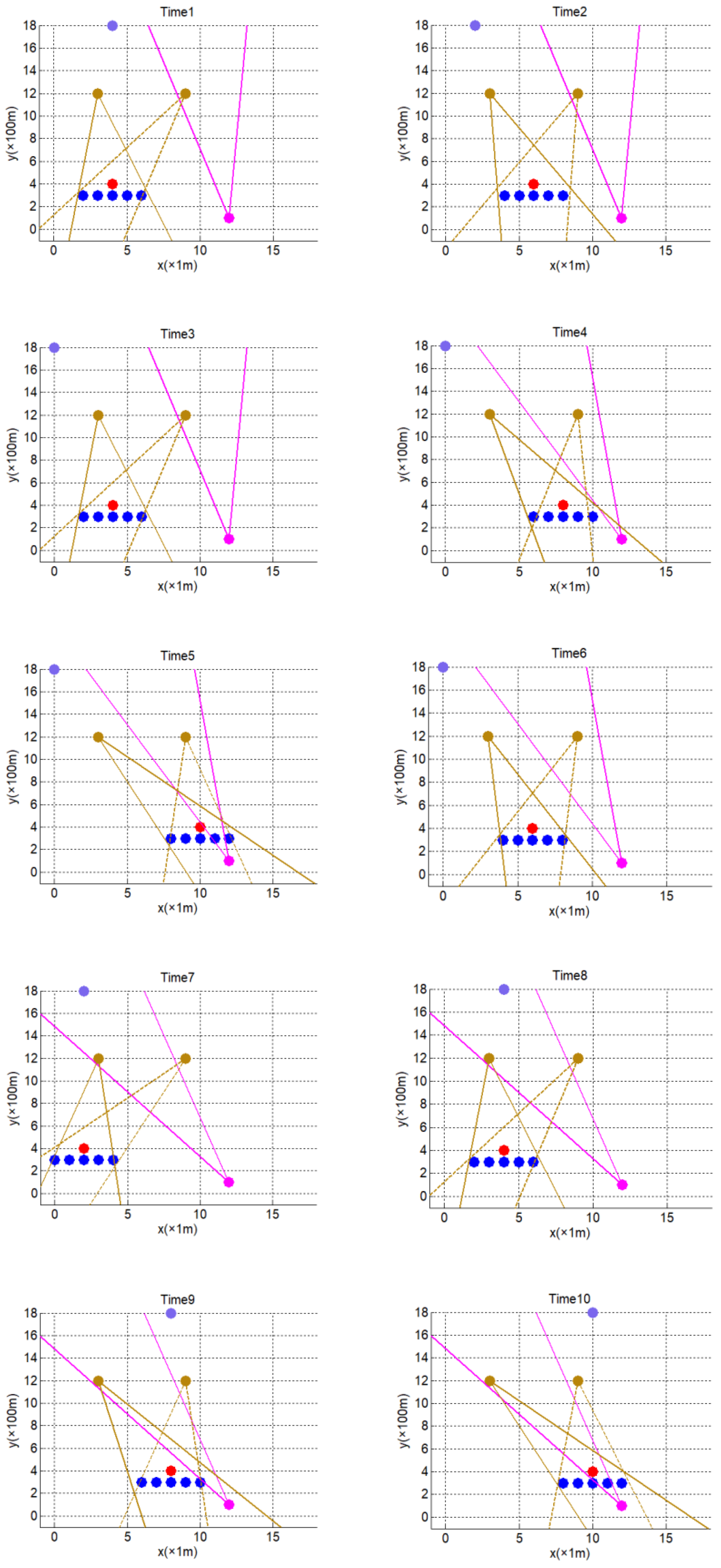
5.2. Collaborative Target Ranging
5.3. Collaborative Scattering Point Localization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Xing, Q.; Zhu, W.-G.; Jia, X. Intelligent countermeasure design of radar working-modes unknown. In Proceedings of the IEEE International Conference on Signal Processing, Louisville, KY, USA, 6–8 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Zhang, J. Study on wideband sparse spectrum waveform for anti-interception and anti-jamming countermeasure. In Proceedings of the CIE International Conference on Radar, Seattle, WA, USA, 8–12 May 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Song, X.; Willett, P.; Zhou, S.; Luh, P.B. The MIMO radar and jammer games. IEEE Trans. Signal Process. 2011, 60, 687–699. [Google Scholar] [CrossRef]
- Deligiannis, A.; Lambotharan, S. A Bayesian game theoretic framework for resource allocation in multistatic radar networks. In Proceedings of the 2017 IEEE Radar Conference (RadarConf), Seattle, WA, USA, 8–12 May 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Lan, X.; Li, W.; Wang, X.; Yan, J.; Jiang, M. MIMO radar and target Stackelberg game in the presence of clutter. IEEE Sens. J. 2015, 15, 6912–6920. [Google Scholar] [CrossRef]
- Jameel, F.; Wyne, S.; Kaddoum, G.; Duong, T.Q. A comprehensive survey on cooperative relaying and jamming strategies for physical layer security. IEEE Commun. Surv. Tutor. 2018, 21, 2734–2771. [Google Scholar] [CrossRef]
- Xiong, J.; Cheng, L.; Ma, D.; Wei, J. Destination-Aided Cooperative Jamming for Dual-Hop Amplify-and-Forward MIMO Untrusted Relay Systems. IEEE Trans. Veh. Technol. 2016, 65, 7274–7284. [Google Scholar] [CrossRef]
- Kang, L.; Bo, J.; Hongwei, L.; Siyuan, L. Reinforcement Learning based Anti-jamming Frequency Hopping Strategies Design for Cognitive Radar. In Proceedings of the 2018 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Qingdao, China, 14–16 September 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Wang, Y.; Zhang, T.; Xu, L.; Tian, T.; Kong, L.; Yang, X. Model-free Reinforcement Learning based Multi-stage Smart Noise Jamming. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Li, H.; Ye, W. A Study on the Influence of Bit Error Ratio against Jamming Signal Ratio under Different Channel Jamming. In Proceedings of the International Symposium on Computational Intelligence & Design, Hangzhou, China, 9–10 December 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Baker, C.J. Intelligence and radar systems. In Proceedings of the Radar Conference 2010, Arlington, VA, USA, 10–14 May 2010. [Google Scholar]
- Xingyu, X.; Daoliang, H.; Li, Y.; Xiaoyang, W. Optimal Waveform Design for Smart Jamming Focused on CA-CFAR. In Proceedings of the 2017 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 23–25 September 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Łabowski, M.; Kaniewski, P. A method of swath calculation for side-looking airborne radar. In Proceedings of the 2018 14th International Conference on Advanced Trends in Radioelecrtronics, Telecommunications and Computer Engineering (TCSET), Lviv, Ukraine, 20–24 February 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Bhattacharya, S.; Başar, T. Game-theoretic analysis of an aerial jamming attack on a UAV communication network. American Control Conference (ACC), Baltimore, MD, USA, 30 June–2 July 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Xiao, L.; Lu, X.; Xu, D.; Tang, Y.; Wang, L.; Zhuang, W. UAV Relay in VANETs Against Smart Jamming with Reinforcement Learning. IEEE Trans. Veh. Technol. 2018, 67, 4087–4097. [Google Scholar] [CrossRef]
- Li, H.; Luo, J.; Liu, C. Selfish Bandit based Cognitive Anti-jamming Policy for Aeronautic Swarm network in Presence of Multiple Jammert. IEEE Access 2019, 7, 30234–30243. [Google Scholar] [CrossRef]
- Li, Z.; Lu, Y.; Shi, Y.; Wang, Z.; Qiao, W.; Liu, Y. A Dyna-Q-Based Solution for UAV Networks Against Smart Jamming Attacks. Symmetry 2019, 11, 617. [Google Scholar] [CrossRef]
- Rahmes, M.; Chester, D.; Clouse, R.; Hunt, J.; Ottoson, T. Cooperative cognitive electronic warfare UAV game modeling for frequency hopping radar. In Unmanned Systems Technology XX; International Society for Optics and Photonics: Orlando, FL, USA, 2018; Volume 10640. [Google Scholar]
- Cevik, P.; Kocaman, I.; Akgul, A.S.; Akca, B. The Small and Silent Force Multiplier: A Swarm UAV—Electronic Attack. J. Intell. Robot. Syst. 2013, 70, 595–608. [Google Scholar] [CrossRef]
- Xing, Q.; Zhu, W.-G.; Jia, X. Intelligent radar countermeasure based on Q-learning. Syst. Eng. Electron. 2018, 40, 1031–1035. [Google Scholar]
- Liu, P.; Liu, Y.; Huang, T.; Lu, Y.; Wang, X. Cognitive Radar Using Reinforcement Learning in Automotive Applications. arXiv 2019, arXiv:1904.10739. [Google Scholar]
- You, S.; Diao, M.; Gao, L. Deep reinforcement learning for target searching in cognitive electronic warfare. IEEE Access 2019, 7, 37432–37447. [Google Scholar] [CrossRef]
- Wang, L.; Fortunati, S.; Greco, M.S.; Gini, F. Reinforcement learning-based waveform optimization for MIMO multi-target detection. In Proceedings of the 2018 52nd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Alberge, F. Deep Learning Constellation Design for the AWGN Channel with Additive Radar Interference. IEEE Trans. Commun. 2018, 67, 1413–1423. [Google Scholar] [CrossRef]
- Huo, Y.; Tian, Y.; Ma, L.; Cheng, X.; Jing, T. Jamming strategies for physical layer security. IEEE Wirel. Commun. 2017, 25, 148–153. [Google Scholar] [CrossRef]
- Cui, T.J. Microwave metamaterials–From passive to digital and programmable controls of electromagnetic waves. J. Opt. 2017, 19, 084004. [Google Scholar] [CrossRef]
- Liu, S.; Cui, T.J.; Zhang, L.; Xu, Q.; Wang, Q.; Wan, X.; Gu, J.Q.; Tang, W.X.; Qing, Q.M.; Han, J.G.; et al. Convolution operations on coding metasurface to reach flexible and continuous controls of terahertz beams. Adv. Sci. 2016, 3, 1600156. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Cheng, Y.; Li, X.; Wang, H. Beam Synthesis with Low-Bit Reflective Coding Metamaterial Antenna: Theoretical and Experimental Results. Int. J. Antennas Propag. 2018, 2018, 1–9. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, X.; Caelli, T.; Li, X.; Moran, B. On information resolution of radar systems. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 3084–3102. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, X.; Morelande, M.; Moran, B. Information geometry of target tracking sensor networks. Inf. Fusion 2013, 14, 311–326. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Variables |
|---|---|
| Transmitting Power of Radar Unmanned Aerial Vehicle (UAV) Swarm 1 | |
| Target Scattering Coefficient | |
| Antenna Gain of Radar UAV Swarm 1 for Each Scattering Point | |
| Transmission Link Path Loss of Radar UAV Swarm 1 | |
| Forwarding Gain of Radar UAV Swarm 1 | |
| Forwarding Link Path Loss of Radar UAV Swarm 1 | |
| Transmitting Power of Radar UAV Swarm 2 | |
| Antenna Gain of Radar UAV Swarm 2 for Each Target Scattering Point | |
| Transmission Link Path Loss of Radar UAV Swarm 2 | |
| Forwarding Gain of Radar UAV Swarm 2 | |
| Forwarding Link Path Loss of Radar UAV Swarm 2 | |
| Transmitting Power of Jammer 1 | |
| Antenna Gain of Jammer 1 | |
| Path Loss of Jamming Link 1 | |
| Transmitting Power of Jammer 2 | |
| Antenna Gain of Jammer 2 | |
| Path Loss of Jamming Link 2 |
| Parameters | Range | Unit |
|---|---|---|
| Transmitting Frequency of Radar UAV Swarm | 9–9.8 | GHz |
| Forwarding Frequency of Radar UAV Swarm | 10.2–11 | GHz |
| Mainlobe Width of Radar UAV Swarm | 5–70 | degree |
| Position of Communication UAV | [0, 18], [2, 18], [4, 18], [6, 18], [8, 18], [10, 18], [12, 18] | [x (1 m),y (100 m)] |
| Transmitting Frequency of Jammer 1 | 9–9.8 | GHz |
| Position of Jammer 1 | [2, 4], [4, 4], [6, 4], [8, 4], [10, 4] | [x (1 m),y (100 m)] |
| Transmitting Frequency of Jammer 2 | 10.2–11 | GHz |
| Beampointing of Jammer 2 | 60–83 | degree |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Q.; Wang, H.; Li, X.; Zhang, B.; Peng, J. Reinforcement Learning-Based Anti-Jamming in Networked UAV Radar Systems. Appl. Sci. 2019, 9, 5173. https://doi.org/10.3390/app9235173
Wu Q, Wang H, Li X, Zhang B, Peng J. Reinforcement Learning-Based Anti-Jamming in Networked UAV Radar Systems. Applied Sciences. 2019; 9(23):5173. https://doi.org/10.3390/app9235173
Chicago/Turabian StyleWu, Qinhao, Hongqiang Wang, Xiang Li, Bo Zhang, and Jinlin Peng. 2019. "Reinforcement Learning-Based Anti-Jamming in Networked UAV Radar Systems" Applied Sciences 9, no. 23: 5173. https://doi.org/10.3390/app9235173
APA StyleWu, Q., Wang, H., Li, X., Zhang, B., & Peng, J. (2019). Reinforcement Learning-Based Anti-Jamming in Networked UAV Radar Systems. Applied Sciences, 9(23), 5173. https://doi.org/10.3390/app9235173