Cover the Violence: A Novel Deep-Learning-Based Approach Towards Violence-Detection in Movies




Abstract
:1. Introduction
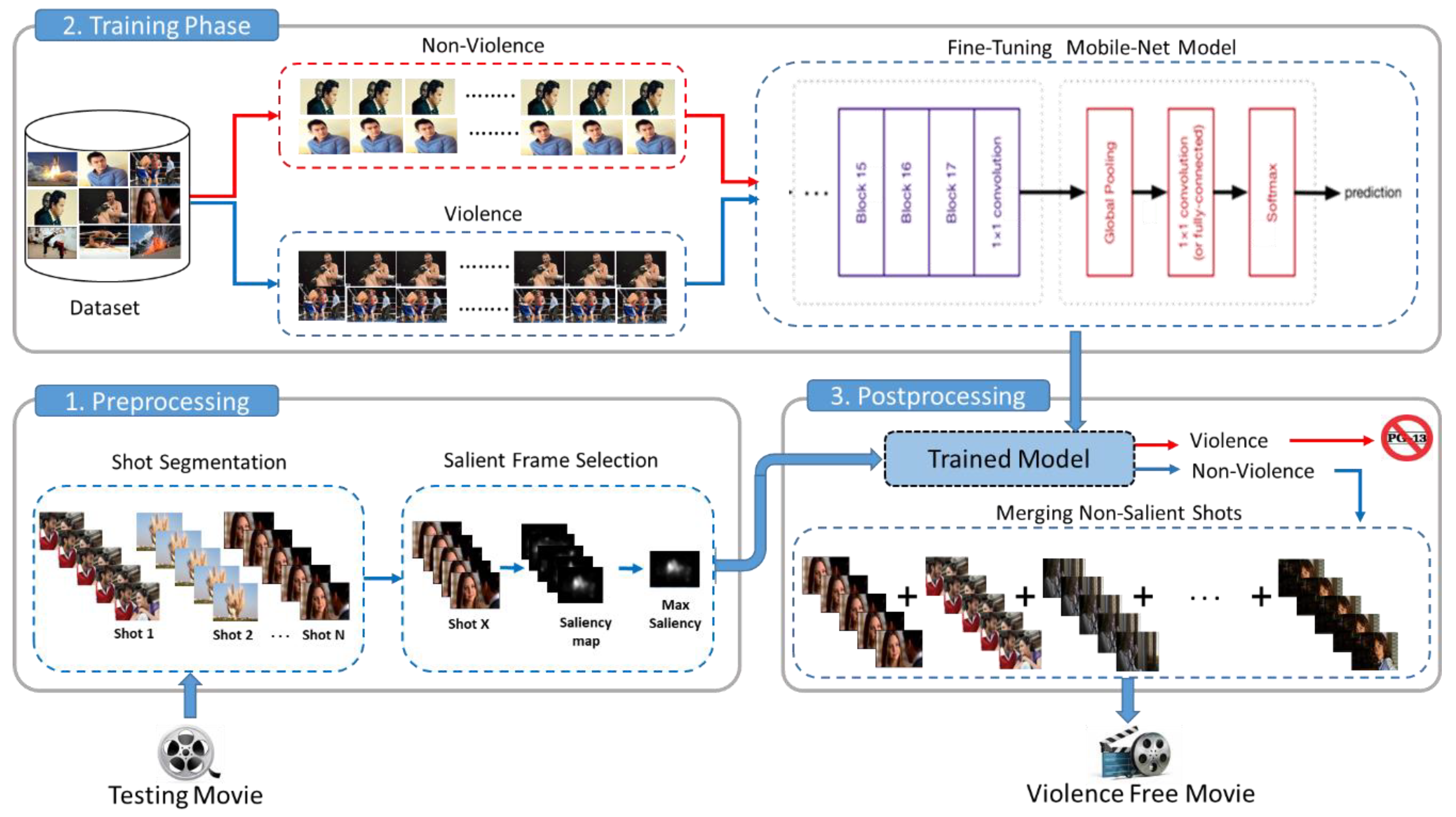
- With the rise of technology and the increase in smart devices, children have access to different entertainment resources that include movies and video games. Some movies have violent scenes or actions that are inappropriate for children or some sensitive people, which results in the need for automatic techniques to cover up the violent scenes. To prevent individuals from watching violent scenes, we presented a novel framework that incorporates shot segmentation, salient frame extraction, and an efficient CNN architecture to automatically detect violent scenes and cover them in movies.
- The structure of movie data is very complex, and it comprises of different scenes, each having shots. Prior to violence-detection, we take the advantage of some preprocessing mechanisms based on hand-engineered features that are easy to compute and help to structure the movie data before passing it into the next step. Our key contribution is the segmentation of a movie into various shots that have proper structure and provide assistance to the subsequent salient-frame extraction strategy.
- Feeding raw data to a CNN model without any prerequisite filtration mechanism results in wasting resources. Hence, we used a salient-keyframes extraction mechanism to select the salient frames and advance them to the trained CNN model for the final classification of a scene as violent or non-violent. This helped to reduce the time and complexity of our system and ensures efficient detection of violence.
2. Methodology
2.1. Preprocessing
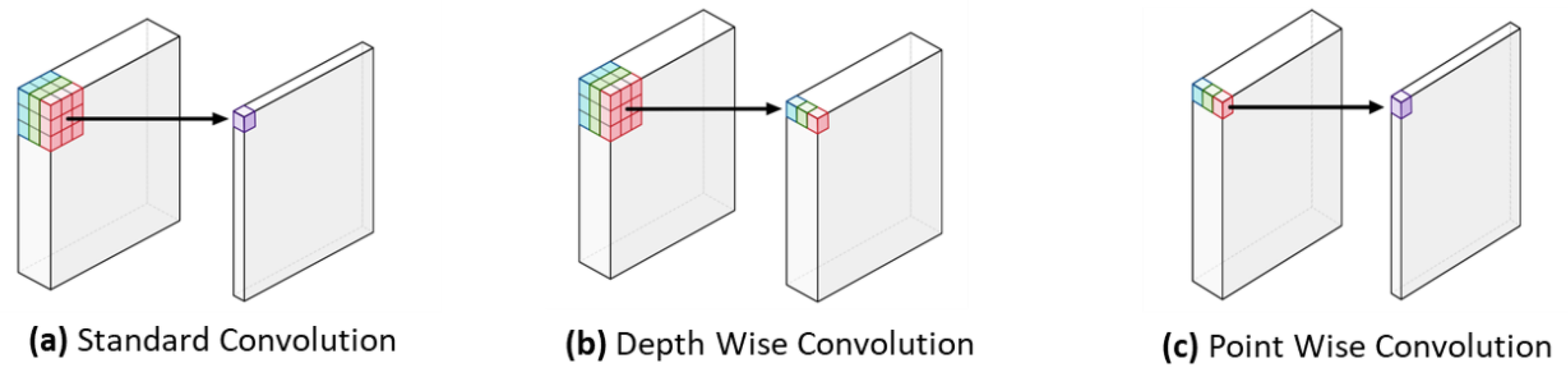
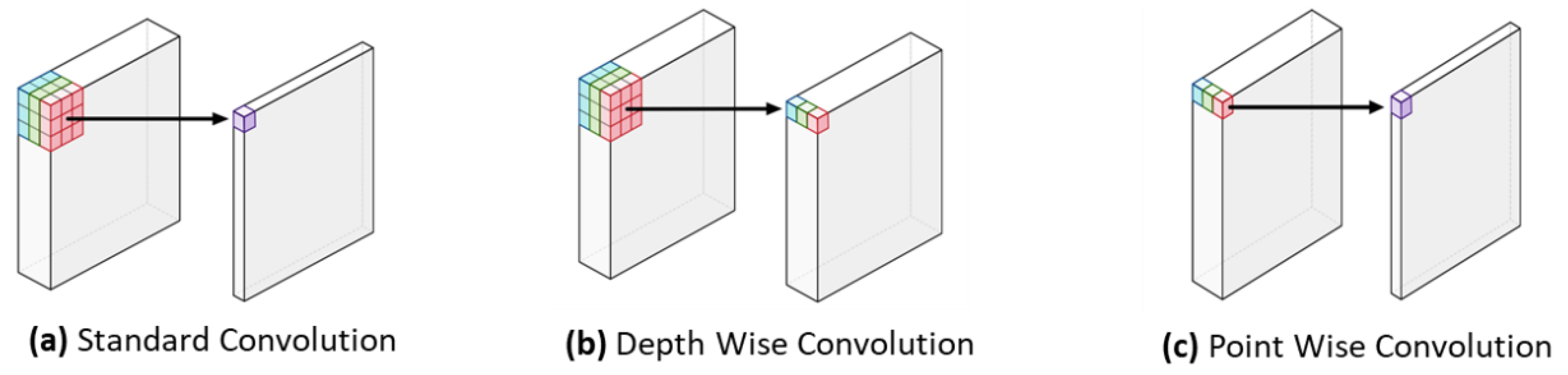
2.2. Fine-Tuning MobileNet Model
2.3. Postprocessing
3. Experimental Results
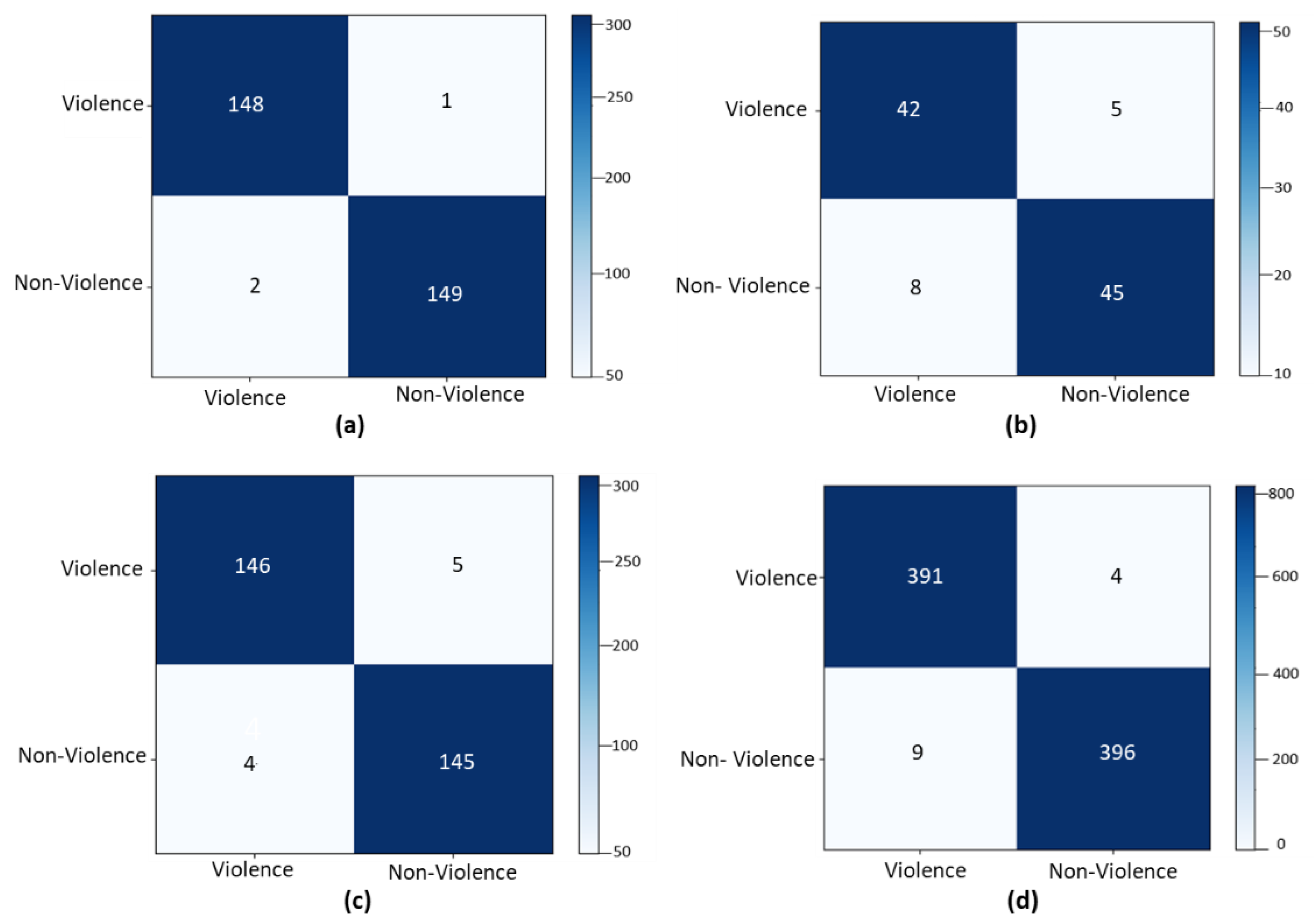
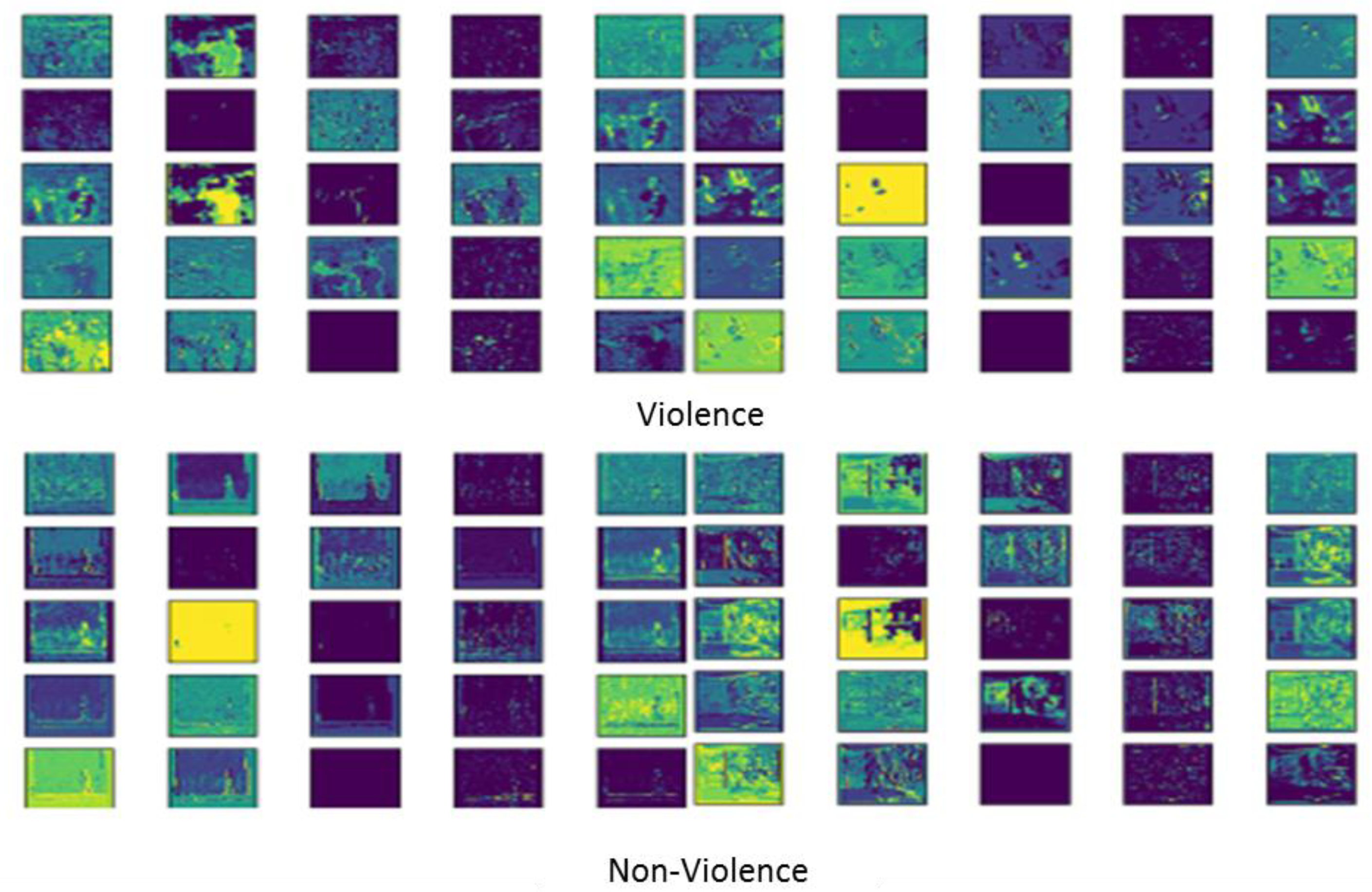
3.1. Datasets
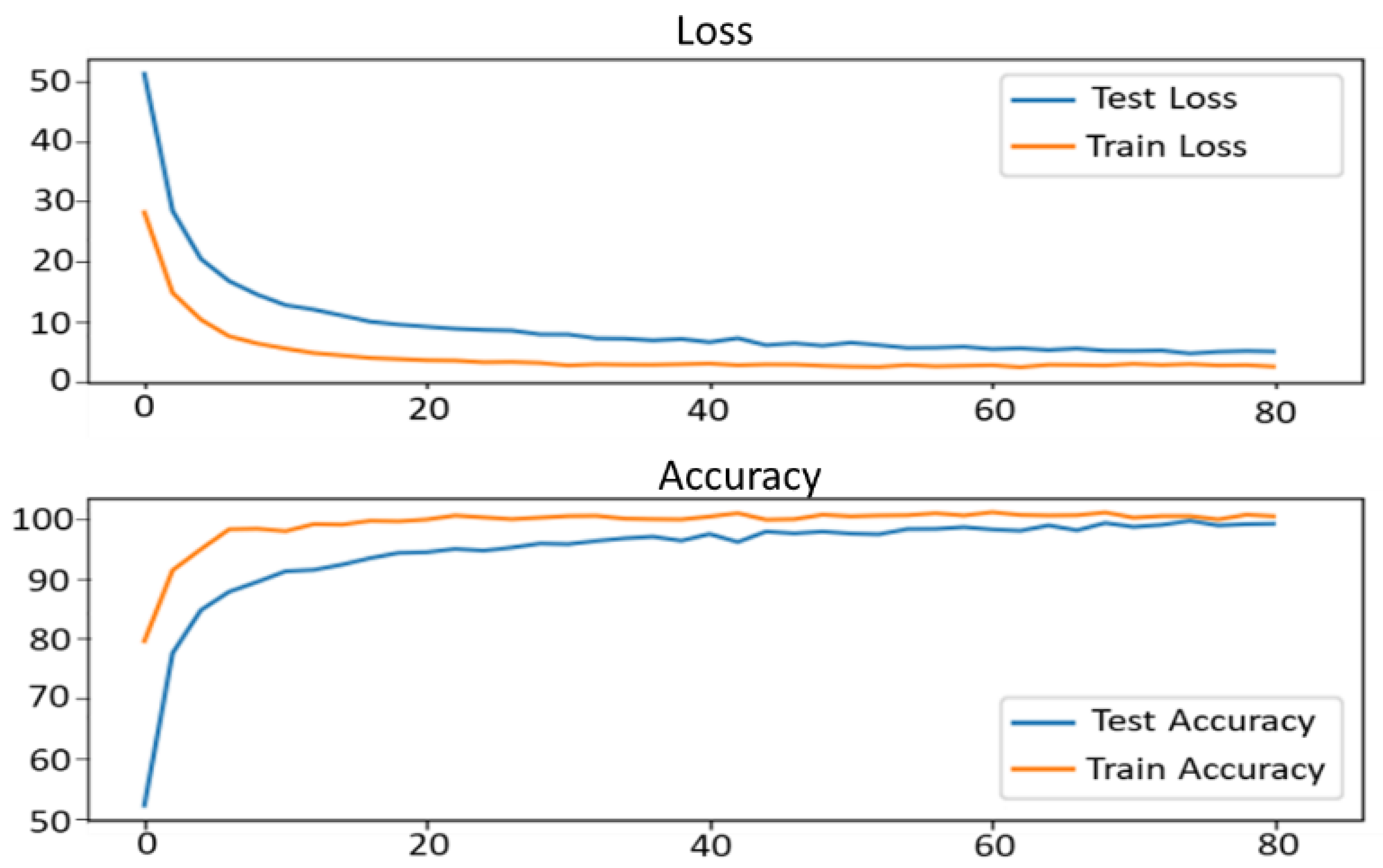
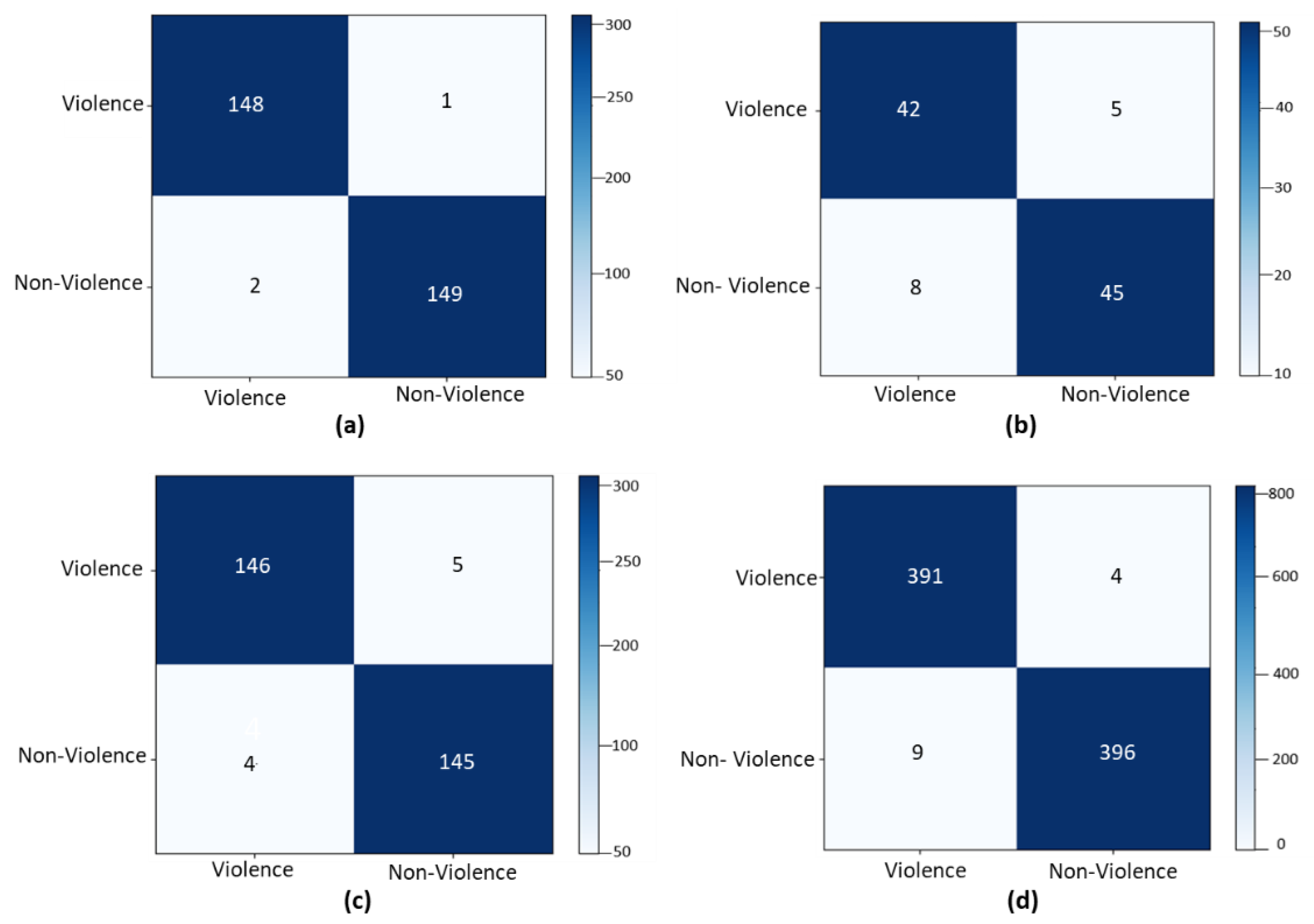
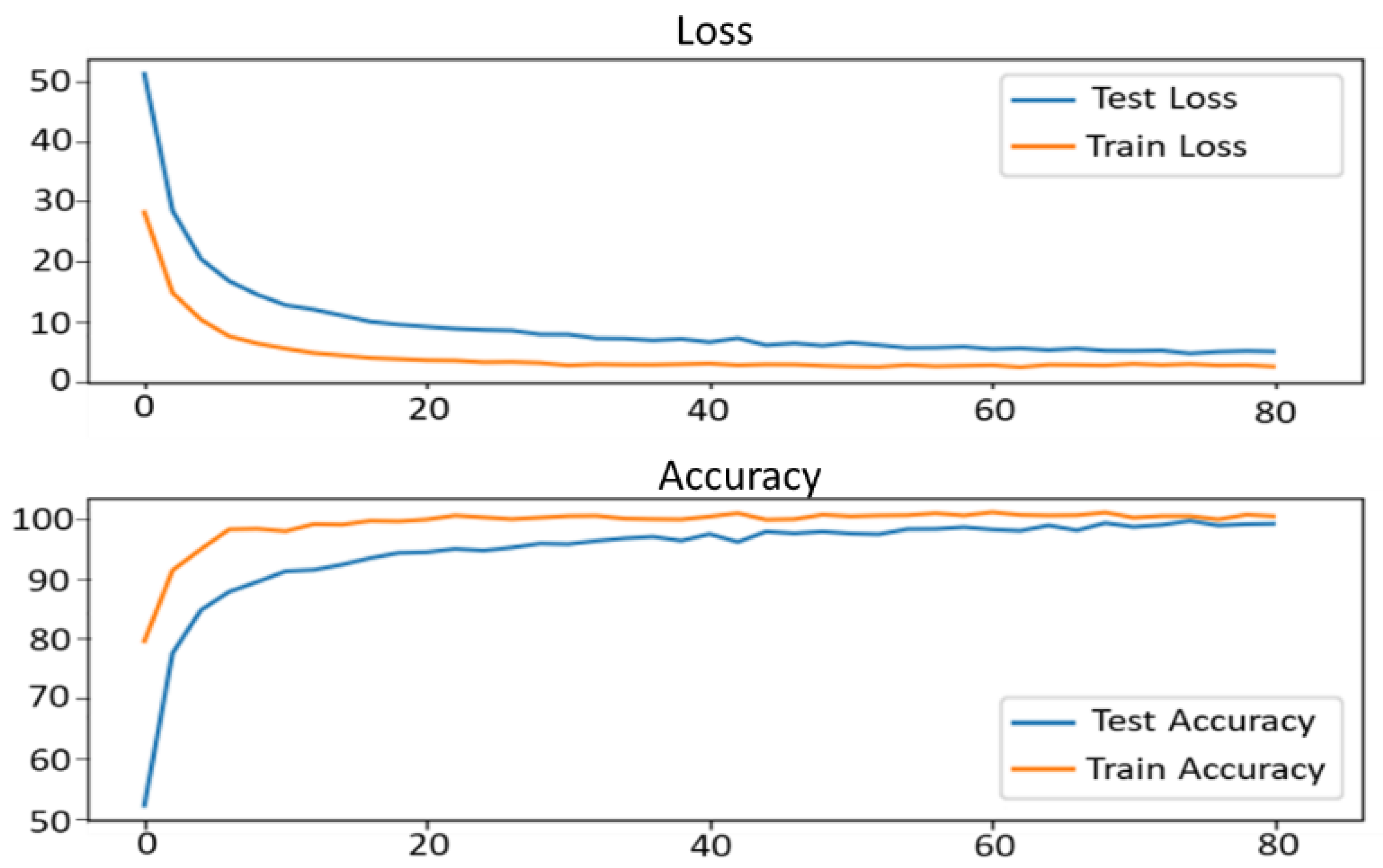
3.2. Comparative Analysis
4. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Elliott, C.; Dastidar, S.G. The Indian Film Industry in a Changing International Market. J. Cult. Econ. 2019, in press. [Google Scholar]
- Romer, D.; Jamieson, P.E.; Jamieson, K.H.; Lull, R.; Adebimpe, A. Parental desensitization to gun violence in PG-13 movies. Pediatrics 2018, 141, e20173491. [Google Scholar] [CrossRef]
- Ferguson, C.J.; Markey, P. PG-13 rated movie violence and societal violence: Is there a link? Psychiatr. Q. 2019, 90, 395–403. [Google Scholar] [CrossRef]
- Lam, V.; Phan, S.; Le, D.-D.; Duong, D.A.; Satoh, S.I. Evaluation of multiple features for violent scenes detection. Multimed. Tools Appl. 2017, 76, 7041–7065. [Google Scholar] [CrossRef]
- Hauptmann, A.; Yan, R.; Lin, W.-H.; Christel, M.; Wactlar, H. Can high-level concepts fill the semantic gap in video retrieval? A case study with broadcast news. IEEE Trans. Multimed. 2007, 9, 958–966. [Google Scholar] [CrossRef]
- Shafaei, M.; Samghabadi, N.S.; Kar, S.; Solorio, T. Rating for Parents: Predicting Children Suitability Rating for Movies Based on Language of the Movies. arXiv 2019, arXiv:1908.07819. [Google Scholar]
- Nayak, L. Audio-Visual Content-Based Violent Scene Characterisation. Ph.D. Thesis, National Institute of Technology, Rourkela Odisha, India, 2015. [Google Scholar]
- Chen, L.-H.; Hsu, H.-W.; Wang, L.-Y.; Su, C.-W. Violence detection in movies. In Proceedings of the 2011 Eighth International Conference Computer Graphics, Imaging and Visualization, Singapore, 17–19 August 2011; pp. 119–124. [Google Scholar]
- Clarin, C.; Dionisio, J.; Echavez, M.; Naval, P. DOVE: Detection of movie violence using motion intensity analysis on skin and blood. PCSC 2005, 6, 150–156. [Google Scholar]
- Zhang, B.; Yi, Y.; Wang, H.; Yu, J. MIC-TJU at MediaEval Violent Scenes Detection (VSD) 2014. In Proceedings of the MediaEval 2014 Workshop, Barcelona, Spain, 16–17 October 2014. [Google Scholar]
- Bilinski, P.; Bremond, F. Human violence recognition and detection in surveillance videos. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 30–36. [Google Scholar]
- Fu, E.Y.; Leong, H.V.; Ngai, G.; Chan, S.C. Automatic fight detection in surveillance videos. Int. J. Pervasive Comput. Commun. 2017, 13, 130–156. [Google Scholar] [CrossRef]
- Lin, J.; Wang, W. Weakly-supervised violence detection in movies with audio and video based co-training. In Pacific-Rim Conference on Multimedia; Springer: Berlin/Heidelberg, Germany, 2009; pp. 930–935. [Google Scholar]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6. [Google Scholar]
- Mabrouk, A.B.; Zagrouba, E. Spatio-temporal feature using optical flow based distribution for violence detection. Pattern Recognit. Lett. 2017, 92, 62–67. [Google Scholar] [CrossRef]
- Khan, M.; Tahir, M.A.; Ahmed, Z. Detection of violent content in cartoon videos using multimedia content detection techniques. In Proceedings of the 2018 IEEE 21st International Multi-Topic Conference (INMIC), Karachi, Pakistan, 1–2 November 2018; pp. 1–5. [Google Scholar]
- Nguyen, N.T.; Phung, D.Q.; Venkatesh, S.; Bui, H. Learning and detecting activities from movement trajectories using the hierarchical hidden Markov model. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 955–960. [Google Scholar]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar]
- Huang, J.-F.; Chen, S.-L. Detection of violent crowd behavior based on statistical characteristics of the optical flow. In Proceedings of the 2014 11th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Xiamen, China, 19–21 August 2014; pp. 565–569. [Google Scholar]
- Zhang, T.; Yang, Z.; Jia, W.; Yang, B.; Yang, J.; He, X. A new method for violence detection in surveillance scenes. Multimed. Tools Appl. 2016, 75, 7327–7349. [Google Scholar] [CrossRef]
- Nievas, E.B.; Suarez, O.D.; García, G.B.; Sukthankar, R. Violence detection in video using computer vision techniques. In International conference on Computer Analysis of Images and Patterns; Springer: Berlin/Heidelberg, Germany, 2011; pp. 332–339. [Google Scholar]
- Gracia, I.S.; Suarez, O.D.; Garcia, G.B.; Kim, T.-K. Fast fight detection. PLoS ONE 2015, 10, e0120448. [Google Scholar]
- Song, W.; Zhang, D.; Zhao, X.; Yu, J.; Zheng, R.; Wang, A. A Novel Violent Video Detection Scheme Based on Modified 3D Convolutional Neural Networks. IEEE Access 2019, 7, 39172–39179. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Violence detection using spatiotemporal features with 3D convolutional neural network. Sensors 2019, 19, 2472. [Google Scholar] [CrossRef] [PubMed]
- Mu, G.; Cao, H.; Jin, Q. Violent scene detection using convolutional neural networks and deep audio features. In Chinese Conference on Pattern Recognition; Springer: Singapore, 2016; pp. 451–463. [Google Scholar]
- Benini, S.; Savardi, M.; Bálint, K.; Kovács, A.B.; Signoroni, A. On the influence of shot scale on film mood and narrative engagement in film viewers. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Yu, J.; Song, W.; Zhou, G.; Hou, J.-J. Violent scene detection algorithm based on kernel extreme learning machine and three-dimensional histograms of gradient orientation. Multimed. Tools Appl. 2019, 78, 8497–8512. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Zhang, S. Shot boundary detection based on multilevel difference of colour histograms. In Proceedings of the 2016 First International Conference on Multimedia and Image Processing (ICMIP), Bandar Seri Begawan, Brunei, 1–3 June 2016; pp. 15–22. [Google Scholar]
- Tavakoli, H.R.; Rahtu, E.; Heikkilä, J. Fast and efficient saliency detection using sparse sampling and kernel density estimation. In Scandinavian Conference on Image Analysis; Springer: Berlin/Heidelberg, Germany, 2011; pp. 666–675. [Google Scholar]
- Zhang, X.; Yao, L.; Wang, X.; Monaghan, J.; Mcalpine, D. A Survey on Deep Learning based Brain Computer Interface: Recent Advances and New Frontiers. arXiv 2019, arXiv:1905.04149. [Google Scholar]
- Liu, N.; Wan, L.; Zhang, Y.; Zhou, T.; Huo, H.; Fang, T. Exploiting convolutional neural networks with deeply local description for remote sensing image classification. IEEE Access 2018, 6, 11215–11228. [Google Scholar] [CrossRef]
- Haq, I.U.; Ullah, A.; Muhammad, K.; Lee, M.Y.; Baik, S.W. Personalized Movie Summarization Using Deep CNN-Assisted Facial Expression Recognition. Complexity 2019, 2019, 10. [Google Scholar]
- Demarty, C.-H.; Penet, C.; Soleymani, M.; Gravier, G. VSD, a public dataset for the detection of violent scenes in movies: Design, annotation, analysis and evaluation. Multimed. Tools Appl. 2015, 74, 7379–7404. [Google Scholar] [CrossRef]
- Hussain, T.; Muhammad, K.; Ullah, A.; Cao, Z.; Baik, S.W.; de Albuquerque, V.H.C. Cloud-assisted multi-view video summarization using CNN and bi-directional LSTM. IEEE Trans. Ind. Inform. 2019, in press. [Google Scholar] [CrossRef]
- Muhammad, K.; Hussain, T.; Baik, S.W. Efficient CNN based summarization of surveillance videos for resource-constrained devices. Pattern Recognit. Lett. 2018, in press. [Google Scholar] [CrossRef]
- Hussain, T.; Muhammad, K.; Khan, S.; Ullah, A.; Lee, M.Y.; Baik, S.W. Intelligent Baby Behavior Monitoring using Embedded Vision in IoT for Smart Healthcare Centers. Journal of Artificial Intelligence and Systems. J. Artif. Intell. Syst. 2019, 1, 15. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Datasets Accuracies (%) | Domain Adoptability | |||
|---|---|---|---|---|---|
| Violence in Movies [21] | Hockey Fight [14] | Violent Scene Detection (VSD) [33] | Movies | Surveillance | |
| STIP, Bow and SVM [21] | 89.5 | - | - | ✔ | ✖ |
| Motion Blobs and Random Forest [22] | 96.9 | 82.4 | - | ✔ | ✖ |
| VIF [14] | - | 82.9 | - | ✖ | ✔ |
| Content based method [33] | - | 96.9 | ✔ | ✖ | |
| HOG3D+KELM [27] | 99.9 | 95.05 | - | ✔ | ✖ |
| Proposed Method | 99.5 | 87.0 | 97.0 | ✔ | ✔ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, S.U.; Haq, I.U.; Rho, S.; Baik, S.W.; Lee, M.Y. Cover the Violence: A Novel Deep-Learning-Based Approach Towards Violence-Detection in Movies. Appl. Sci. 2019, 9, 4963. https://doi.org/10.3390/app9224963
Khan SU, Haq IU, Rho S, Baik SW, Lee MY. Cover the Violence: A Novel Deep-Learning-Based Approach Towards Violence-Detection in Movies. Applied Sciences. 2019; 9(22):4963. https://doi.org/10.3390/app9224963
Chicago/Turabian StyleKhan, Samee Ullah, Ijaz Ul Haq, Seungmin Rho, Sung Wook Baik, and Mi Young Lee. 2019. "Cover the Violence: A Novel Deep-Learning-Based Approach Towards Violence-Detection in Movies" Applied Sciences 9, no. 22: 4963. https://doi.org/10.3390/app9224963
APA StyleKhan, S. U., Haq, I. U., Rho, S., Baik, S. W., & Lee, M. Y. (2019). Cover the Violence: A Novel Deep-Learning-Based Approach Towards Violence-Detection in Movies. Applied Sciences, 9(22), 4963. https://doi.org/10.3390/app9224963