A Novel Searching Method Using Reinforcement Learning Scheme for Multi-UAVs in Unknown Environments


Abstract
:1. Introduction
2. Materials and Methods
2.1. Environmental Model
2.2. Effect of Collision Avoidance on Search Map
2.3. Unmanned Aerial Vehicle Model
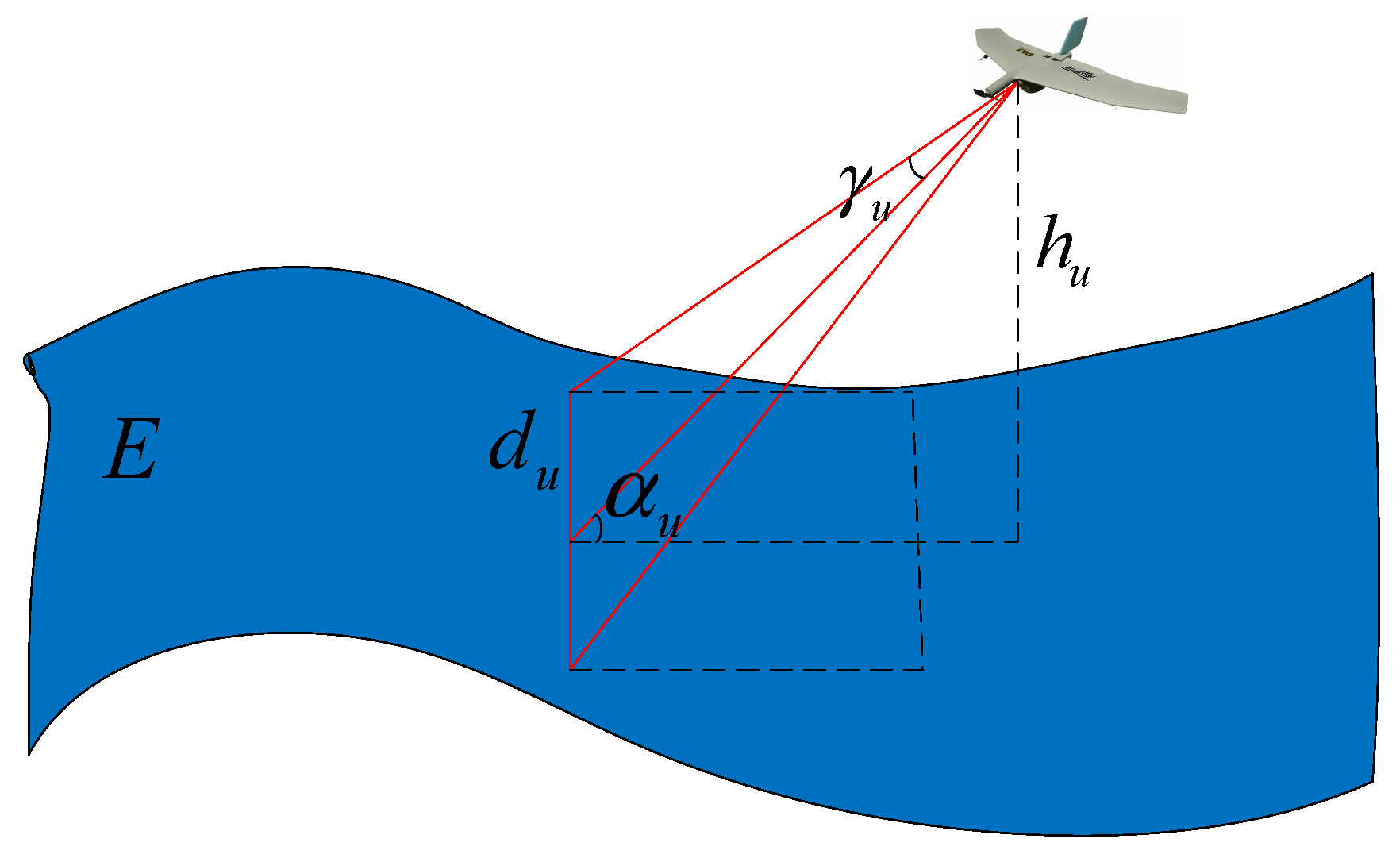
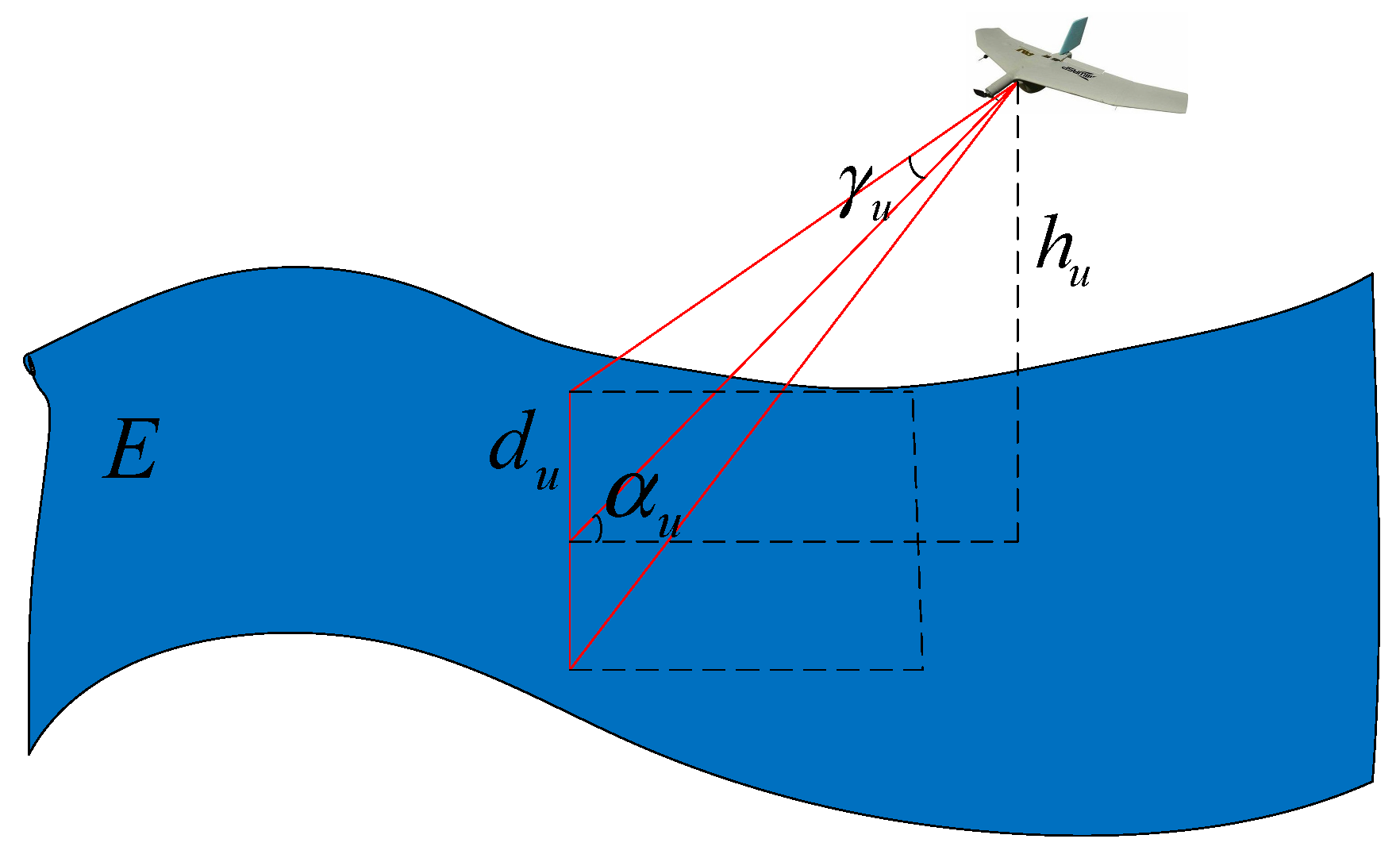
2.4. Sensor Model
2.5. Multi-Objective Function Establishment
3. Design of Cooperative Search Strategy
3.1. Establishment of Q-Value Table
3.2. Q-Value Update Process
3.3. Design of Reword and Punishment Function
| Algorithm 1 Q-Learning of cooperative search |
| Input: |
| Initialize unknown search areas: E |
| Initialize the Q-table that represents the state-decision model and corresponding parameters . |
| Initialize the state of multiple UAVs . |
| Start: |
| For episode = 1 to do |
| Initialize the state of multiple UAVs, Get the initial state . |
| For k = 1 to T do |
| A decision is randomly selected with |
| as probability. After the decision is executed, the multiple UAVs reach a new round of state , and the return is calculated according to the reward and punishment function: |
| . |
| Update the status of the multiple UAVs , and replace with the update formula of the Q-value. |
| . |
| Update the Q-value. |
| End for |
| End for |
| Output: Q-table |
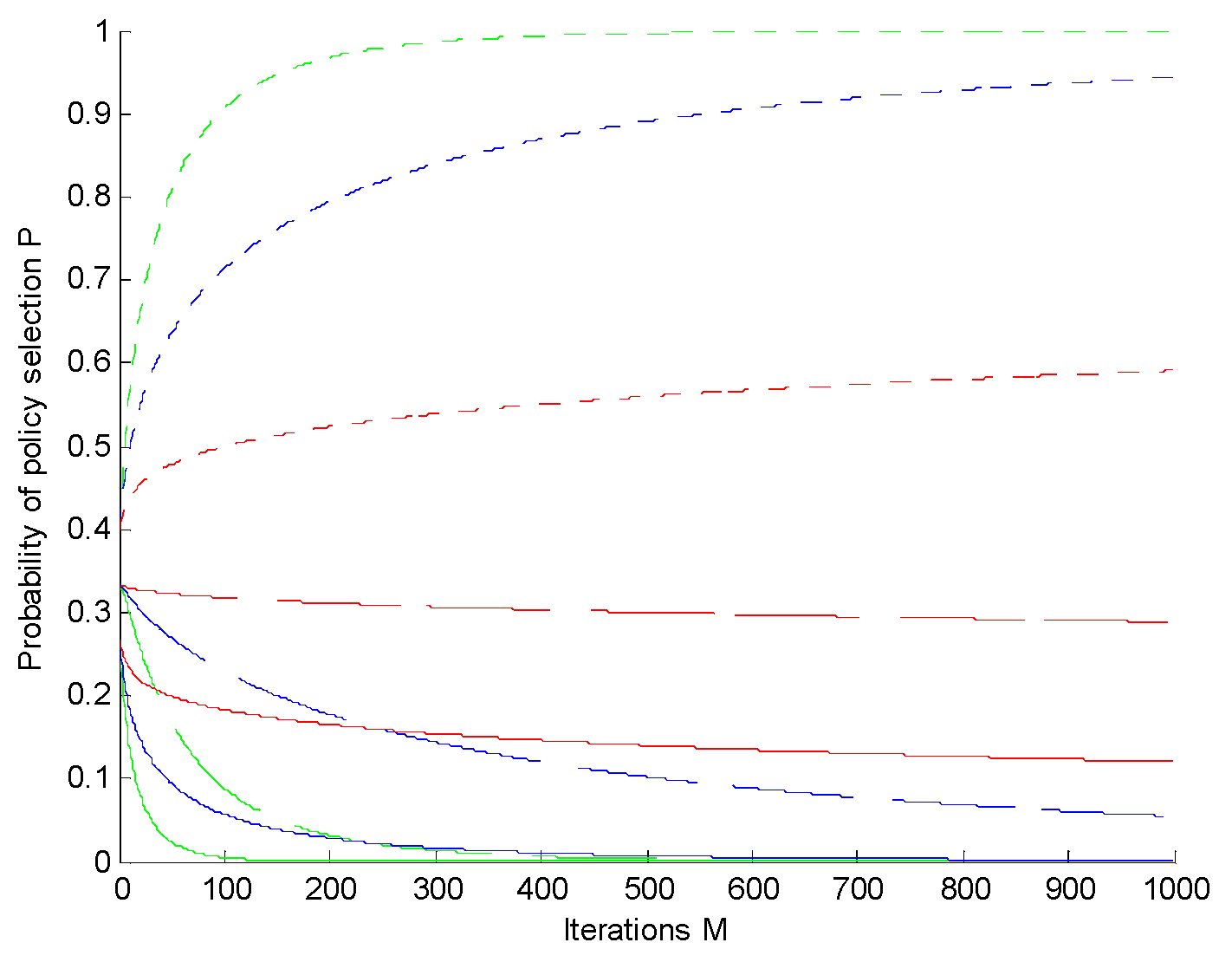
4. Simulation Results
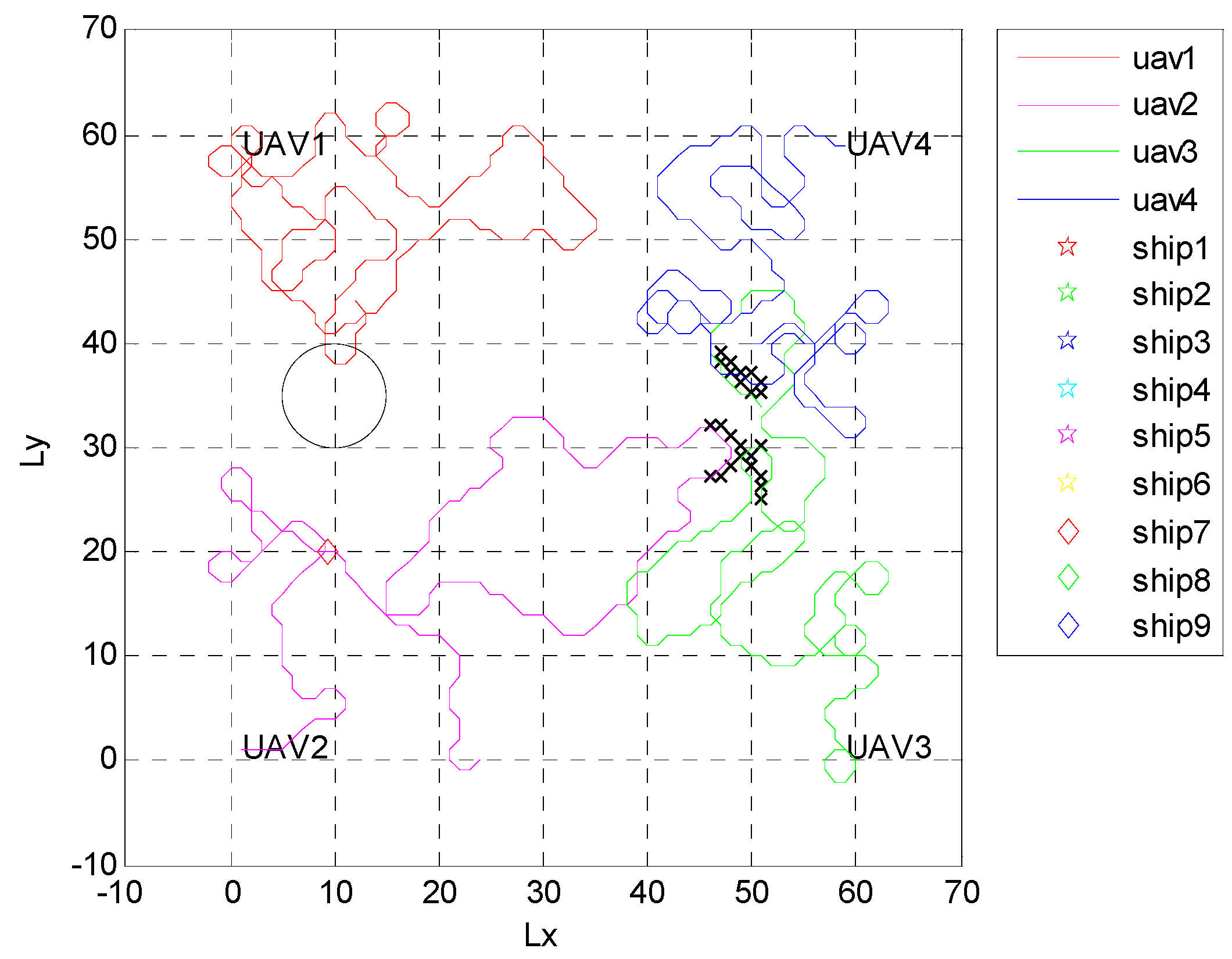
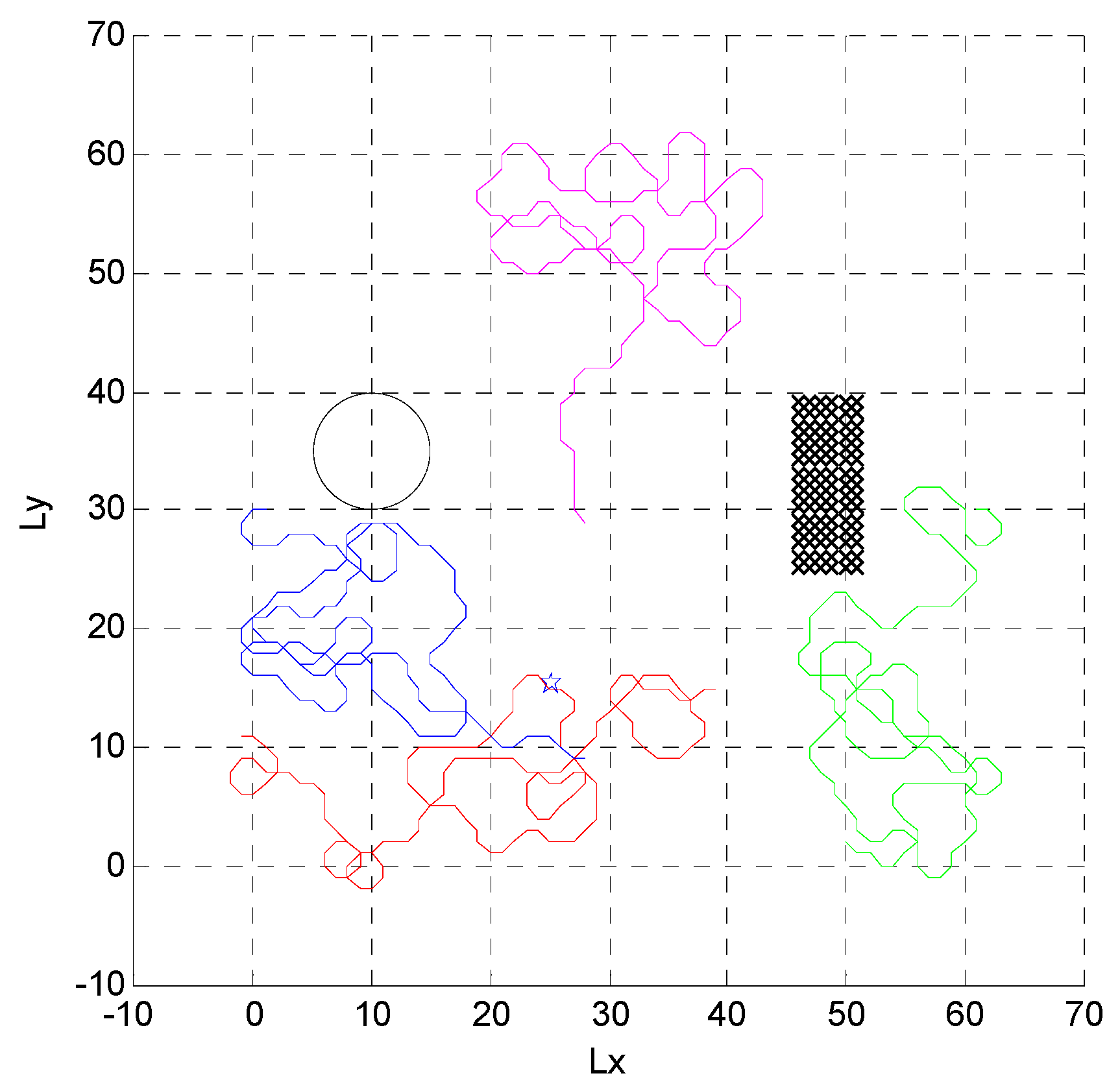
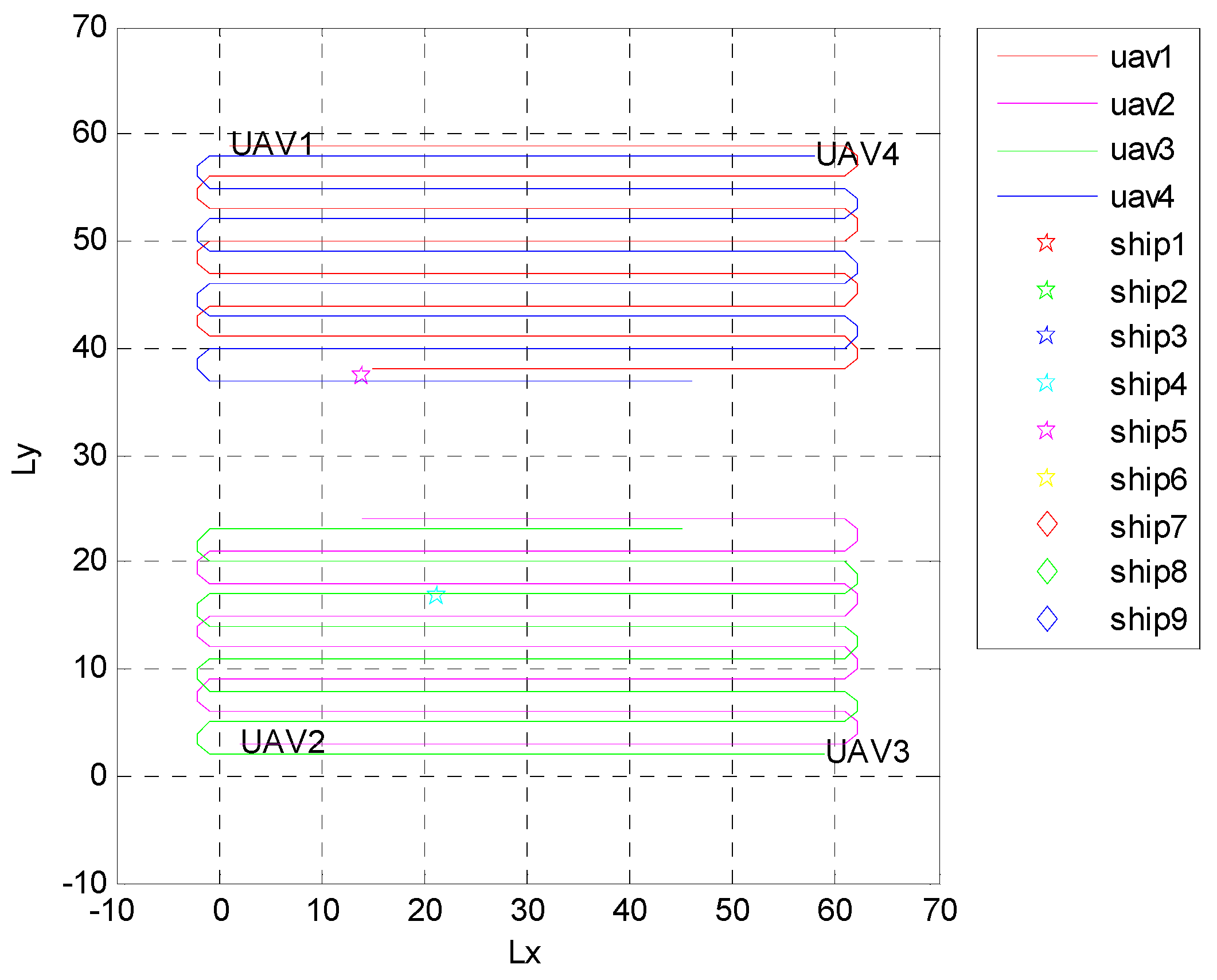
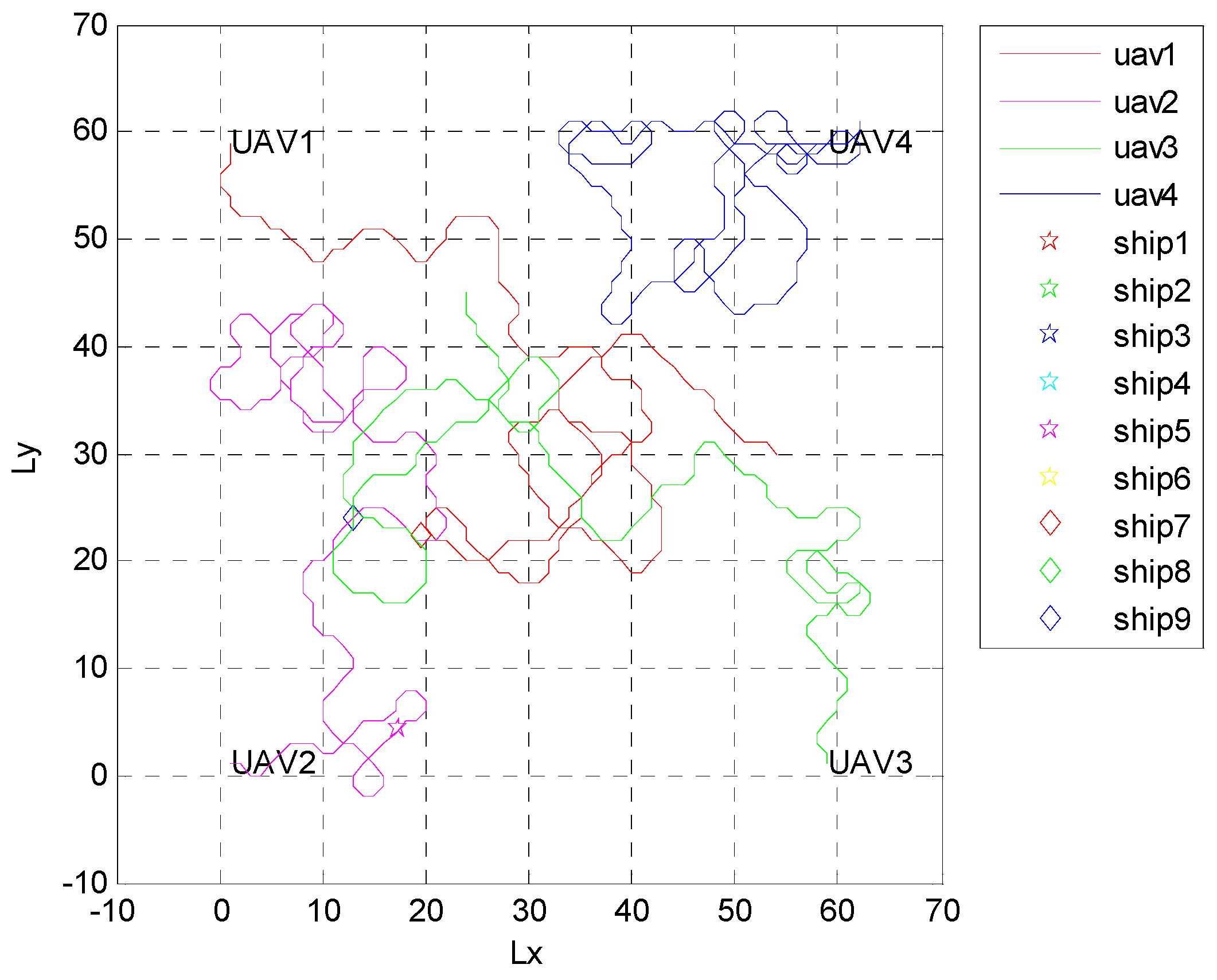
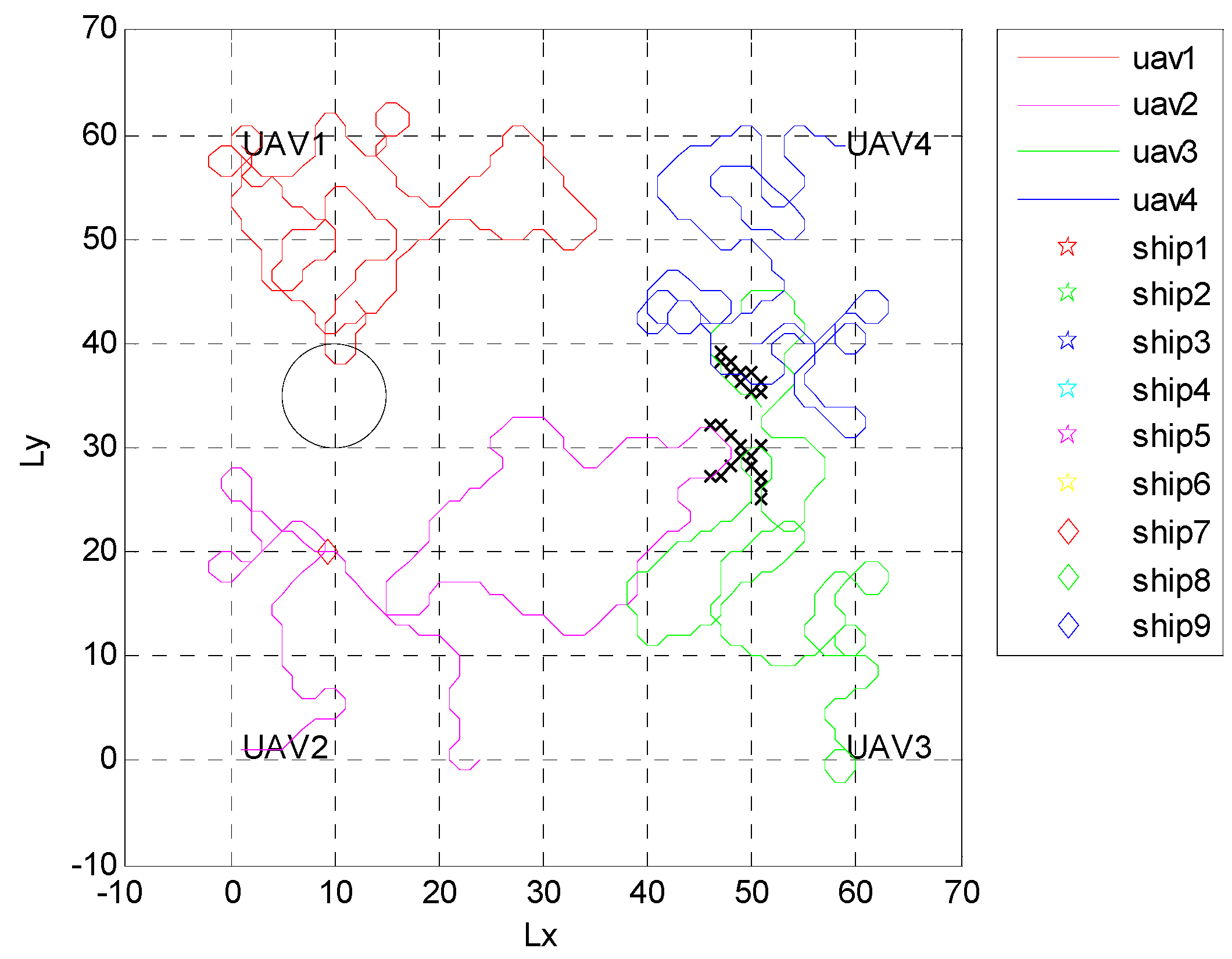
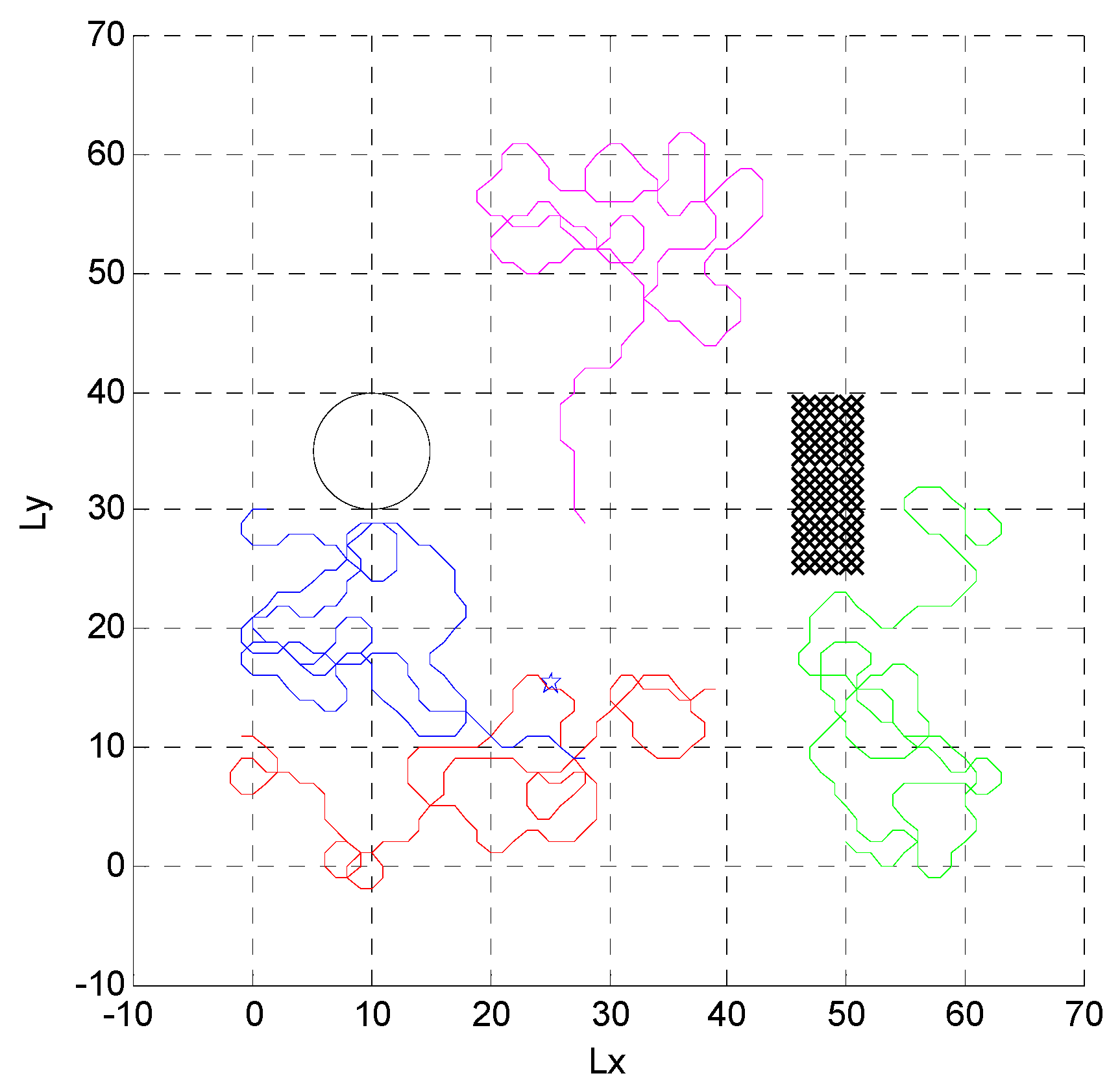
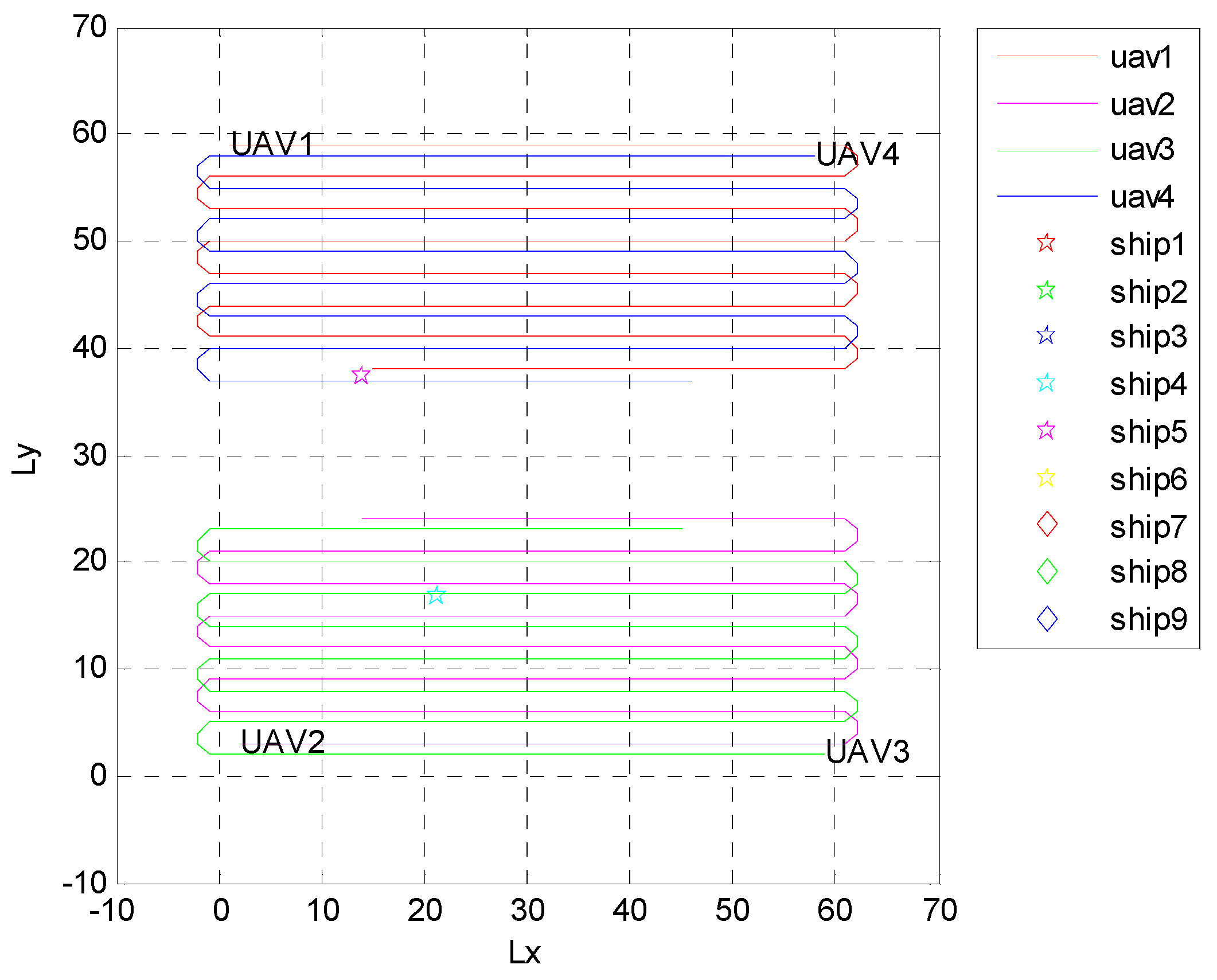
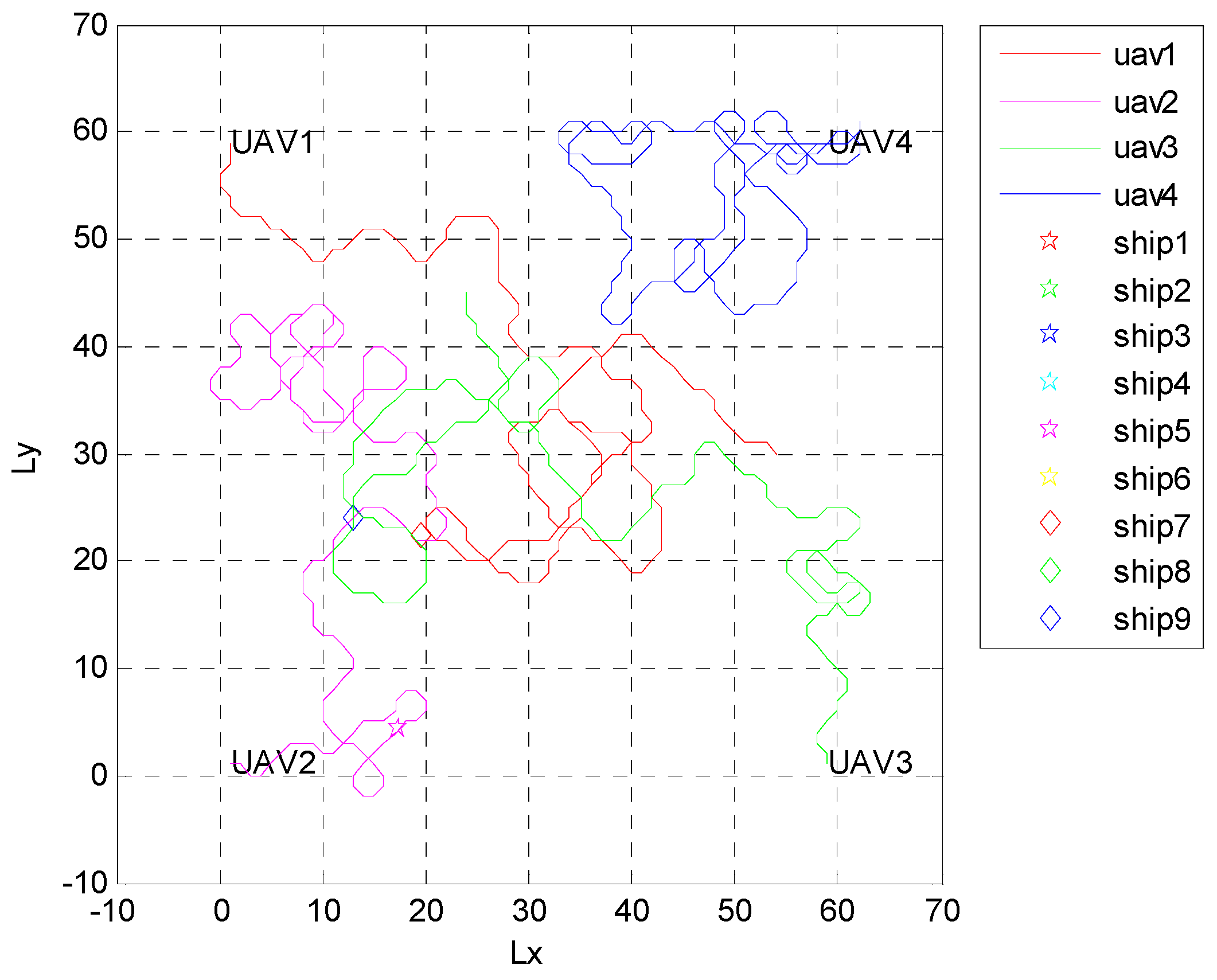
4.1. Independent Random Distribution of Targets
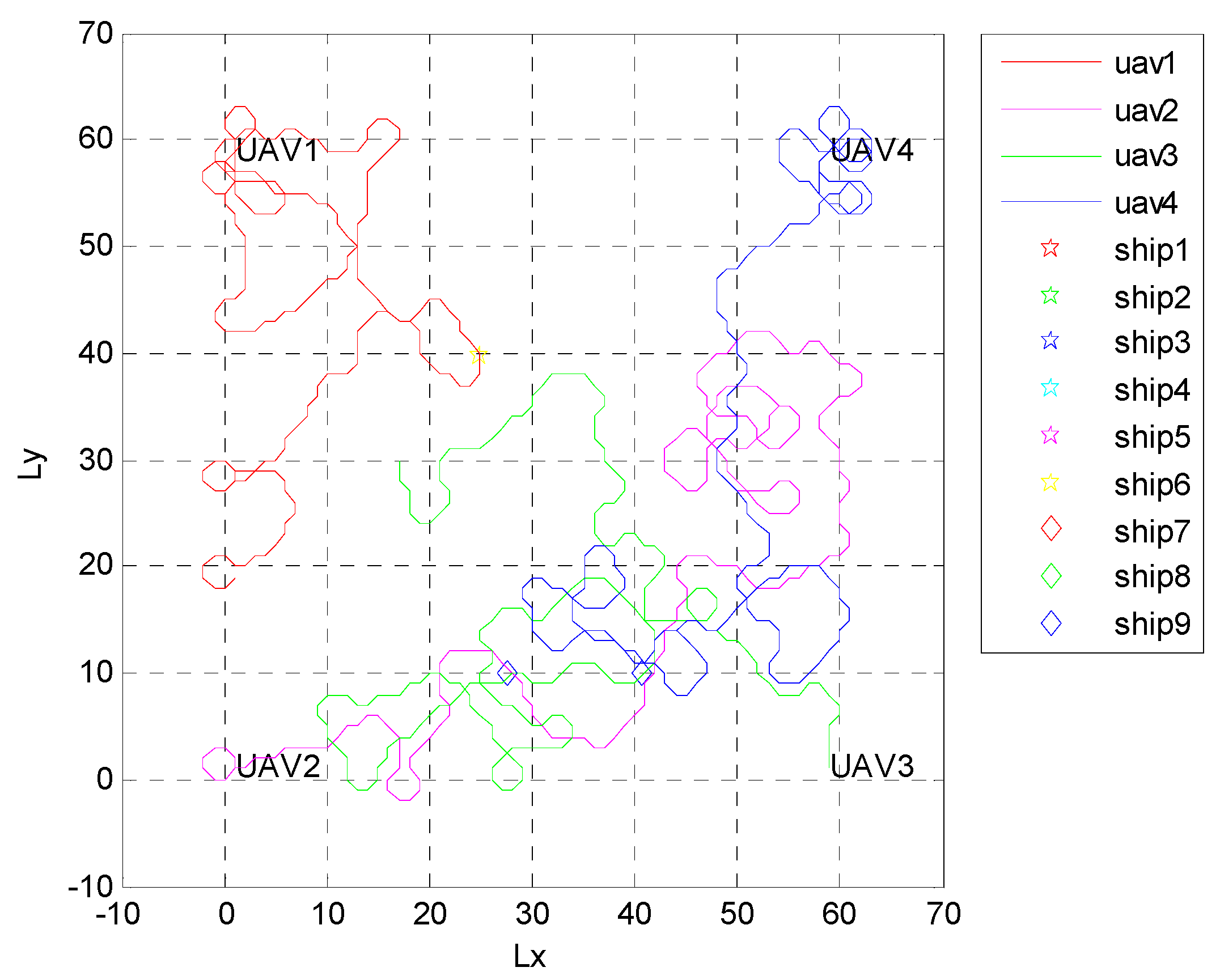
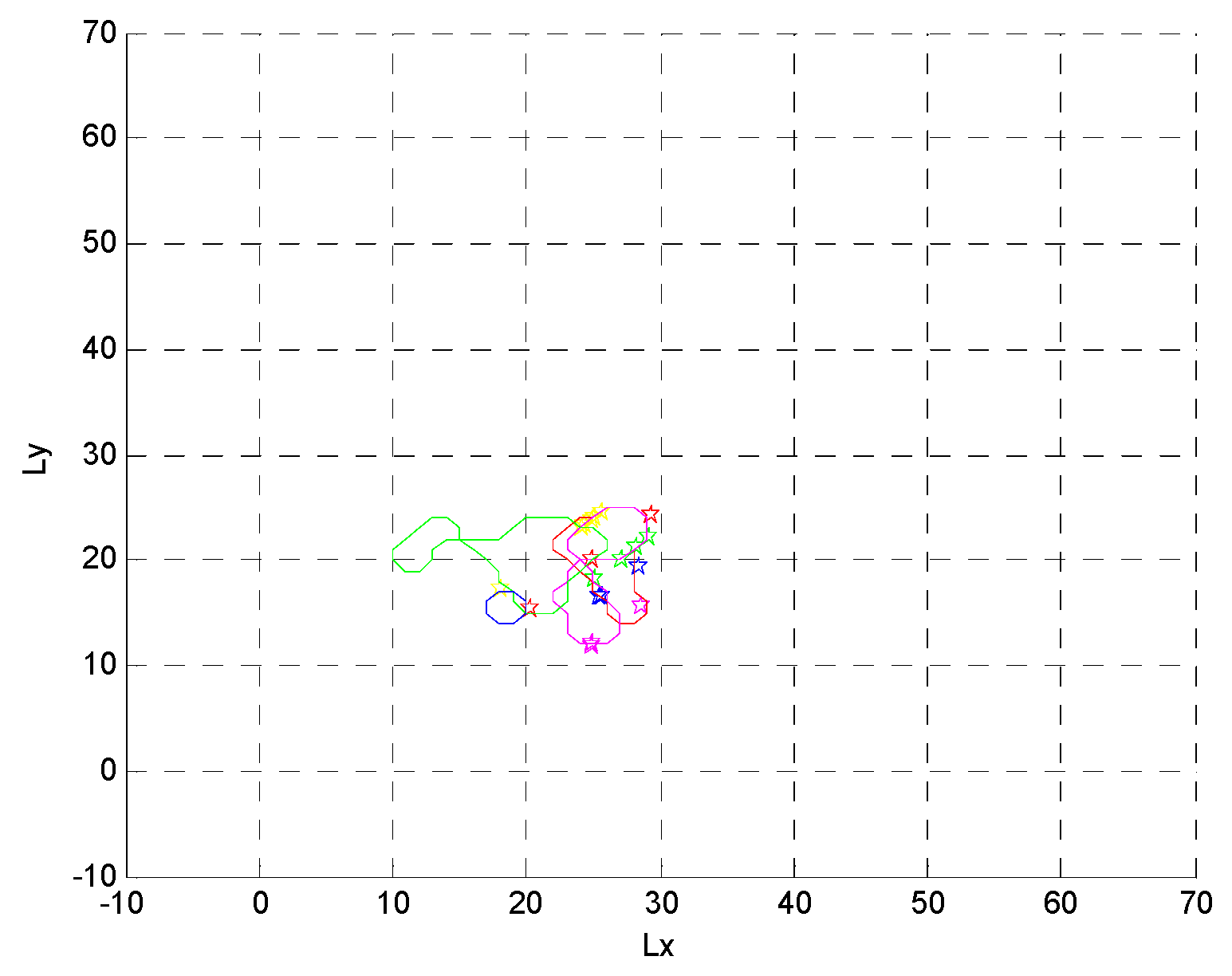
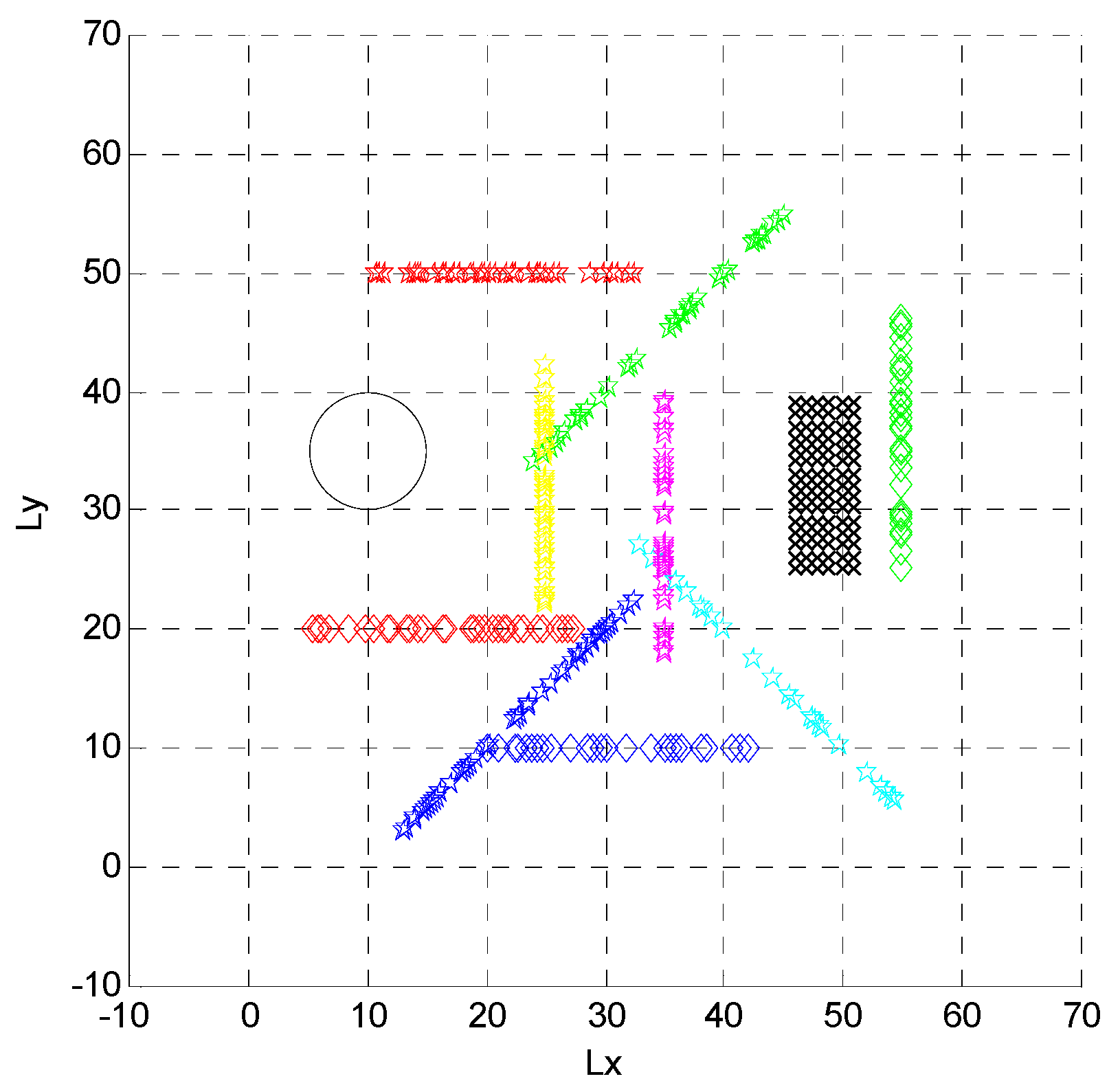
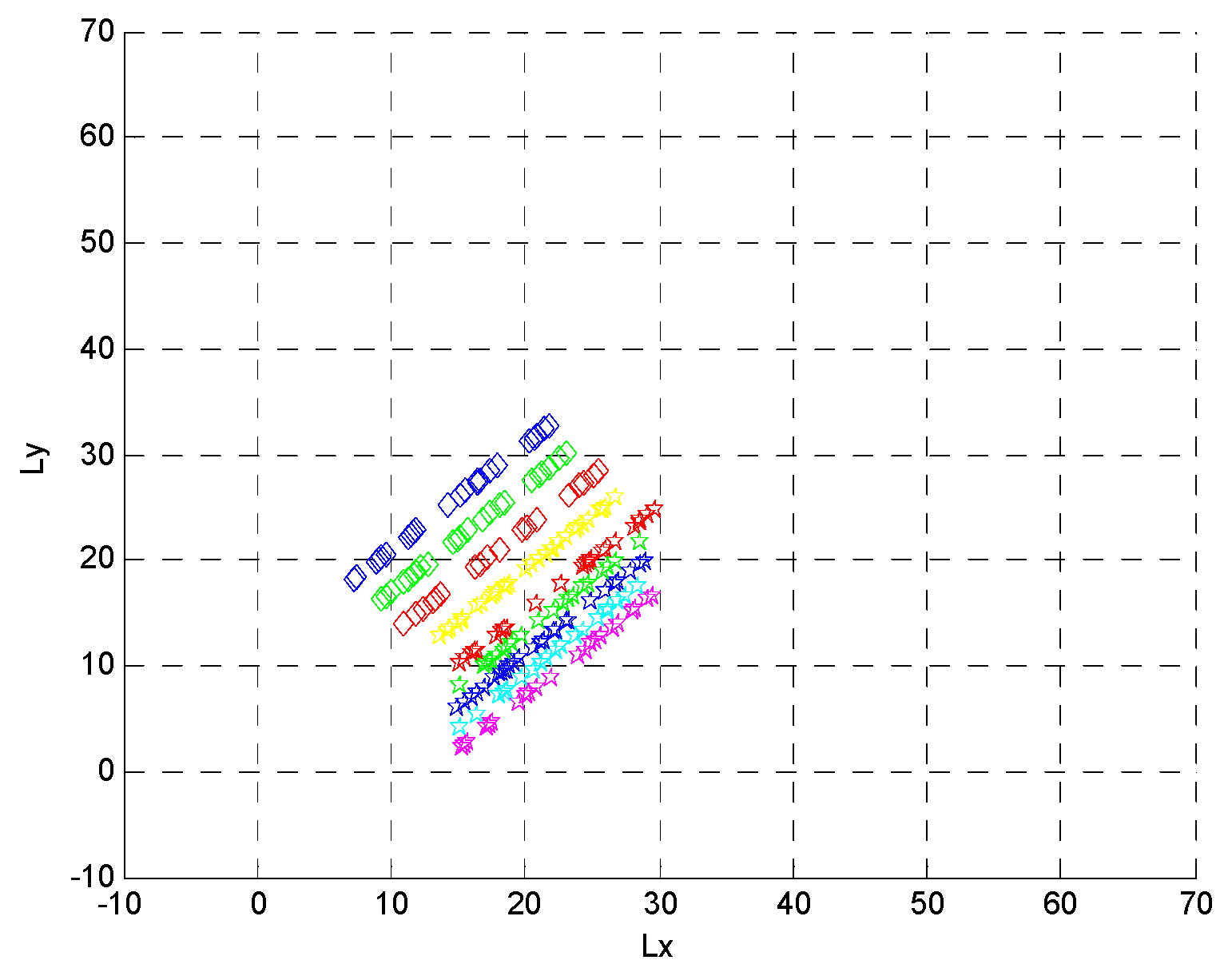
4.2. Formation Targets
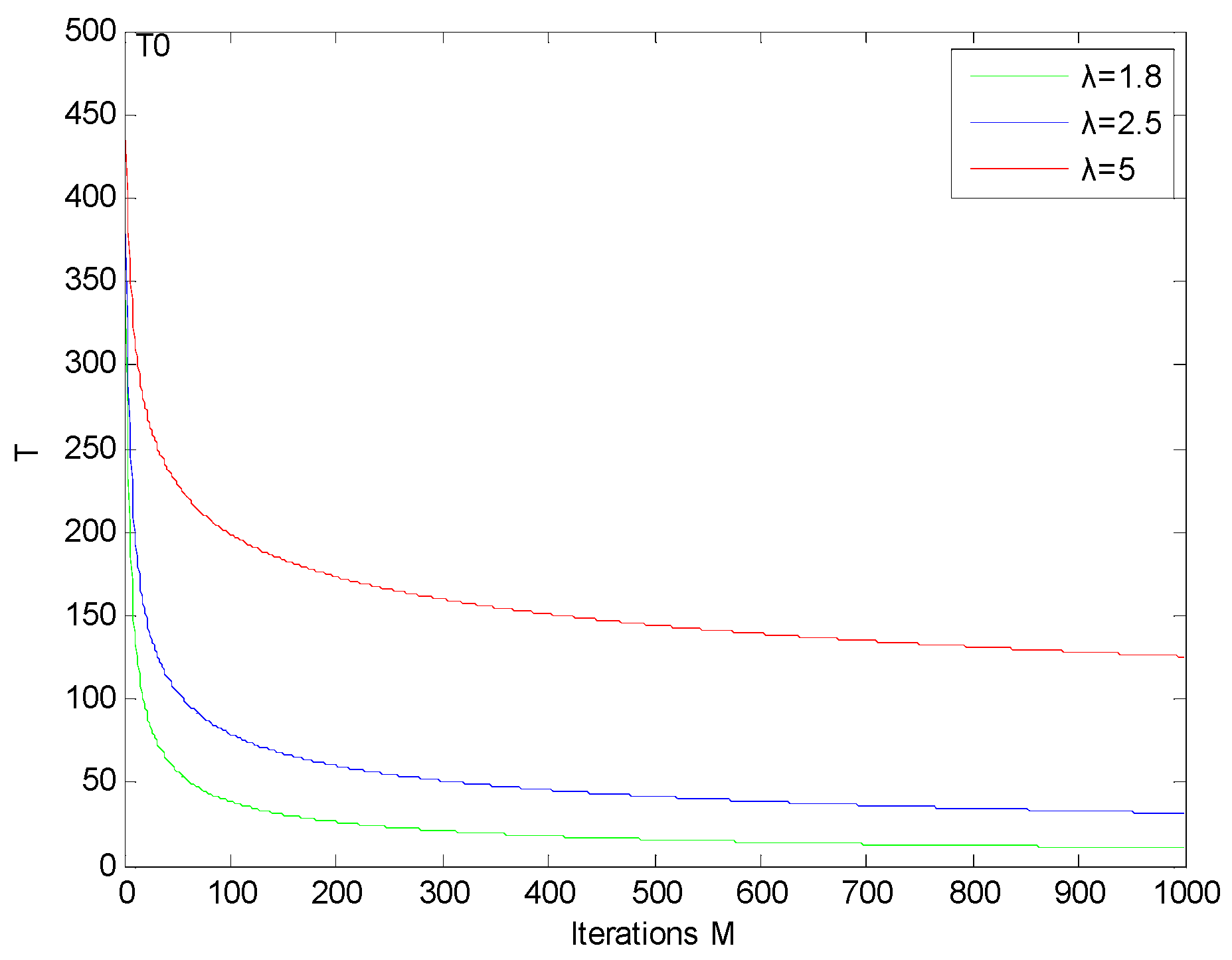
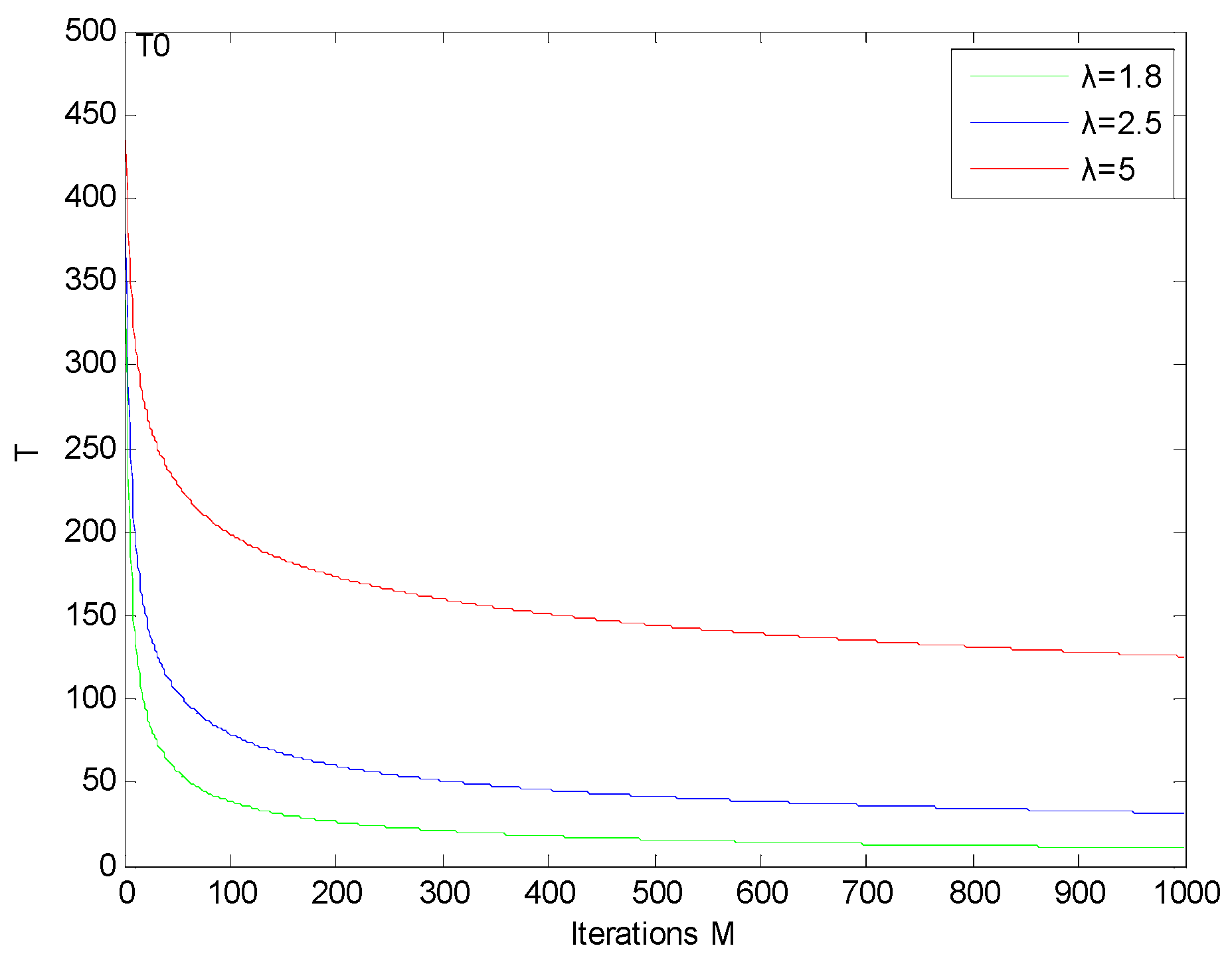
4.3. Algorithm Parameter Analysis
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chung, T.H.; Hollinger, G.A.; Isler, V. Search and pursuit-evasion in mobile robotics. Auton. Robot. 2011, 31, 299–316. [Google Scholar] [CrossRef]
- Cui, X.T.; Yang, R.J.; He, Y. Modeling and simulation of multi-ship coordinated spiral call-searching. Ship Sci. Technol. 2010, 32, 95–98. [Google Scholar]
- Yu, Y.D.; Zhang, D. Modeling and Simulation of Alpine Leaf search and potential search with Magnetometer. Ship Electron. Eng. 2017, 37, 88–92. [Google Scholar]
- Peng, H.; Shen, L.C.; Huo, X.H. A Study of Multi-UAVs Cooperative Area Coverage Search. J. Syst. Simul. 2007, 19, 2472–2476. [Google Scholar]
- Yao, P.; Xie, Z.; Ren, P. Optimal UAV Route Planning for Coverage Search of Stationary Target in River. IEEE Trans. Control Syst. Technol. 2017, 27, 822–829. [Google Scholar] [CrossRef]
- Angley, D.; Ristic, B.; Moran, W.; Himed, B. Search for targets in a risky environment using multi-objective optimisation. IET Radar Sonar Navig. 2019, 13, 123–127. [Google Scholar] [CrossRef]
- Huang, L.; Qu, H.; Ji, P.; Liu, X.; Fan, Z. A novel coordinated path planning method using k-degree smoothing for multi-UAVs. Appl. Soft Comput. 2009, 48, 182–192. [Google Scholar] [CrossRef]
- Hu, J.; Xie, L.; Lum, K.Y.; Xu, J. Multiagent Information Fusion and Cooperative Control in Target Search. IEEE Trans. Control Syst. Technol. 2013, 21, 1223–1235. [Google Scholar] [CrossRef]
- Bourgault, F.; Ktogan, A.; Furukawa, T. Coordinated search for a lost target in a Bayesian world. Adv. Robot. 2004, 18, 979–1000. [Google Scholar] [CrossRef]
- Kassem, M.A.; El-Hadidy, M.A. Optimal multiplicative Bayesian search for a lost target. Appl. Math. Comput. 2014, 247, 795–802. [Google Scholar]
- Shem, A.G.; Mazzuchi, T.A.; Sarkani, S. Addressing Uncertainty in UAV Navigation Decision-Making. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 295–313. [Google Scholar] [CrossRef]
- Riehl, J.R.; Collins, G.E.; Hespanha, J.P. Cooperative Search by UAV Teams: A Model Predictive Approach using Dynamic Graphs. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 2637–2656. [Google Scholar] [CrossRef]
- Pablo, L.P. Minimum Time Search of Moving Targets in Uncertain Environments; Universidad Complutense de Madrid: Madrid, Spain, 2013. [Google Scholar]
- Du, Y.C.; Zhang, M.X.; Ling, H.F. Evolutionary Planning of Multi-UAV Search for Missing Tourists. IEEE Access 2019, 7, 480–492. [Google Scholar] [CrossRef]
- Pitre, R.R. An Information Value Approach to Route Planning for UAV Search and Track Missions. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 2551–2565. [Google Scholar] [CrossRef]
- Matsuda, A.; Misawa, H.; Horio, K. Decision making based on reinforcement learning and emotion learning for social behavior. In Proceedings of the IEEE International Conference on Fuzzy Systems, Taipei, Taiwan, 27–30 June 2011. [Google Scholar]
- Cai, Y.; Yang, S.X.; Xu, X. A combined hierarchical reinforcement learning based approach for multi-robot cooperative target searching in complex unknown environments. In Proceedings of the 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL), Singapore, 16–19 April 2013; pp. 52–59. [Google Scholar]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Van Nguyen, L. Reinforcement Learning for Autonomous UAV Navigation Using Function Approximation. In Proceedings of the IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018; pp. 1–6. [Google Scholar]
- Hung, S.M.; Givigi, S.N. A Q-Learning Approach to Flocking with UAVs in a Stochastic Environment. IEEE Trans. Cybern. 2016, 47, 186–197. [Google Scholar] [CrossRef] [PubMed]
- Poole, W.E. Field enclosure experiments on the technique of poisoning the rabbit, Oryctolagus cuniculus (L.). II. A study of territorial behaviour and the use of bait stations. Csiro Wildl. Res. 1963, 8, 28–35. [Google Scholar] [CrossRef]
- Jin, Y.; Liao, Y.; Minai, A.A.; Polycarpou, M.M. Balancing search and target response in cooperative unmanned aerial vehicle (UAV) teams. IEEE Trans. Cybern. 2006, 36, 571–587. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time (s) | 1000 | 2000 | 3000 | 4000 | 5000 | 6000 | 7000 | |
| Method | ||||||||
| Random Method | 0.396 | 0.794 | 1.210 | 1.702 | 2.262 | 2.652 | 3.050 | |
| Traversing Method | 0.336 | 0.638 | 0.894 | 1.262 | 1.626 | 2.196 | 2.532 | |
| Proposed Method | 1.188 | 1.734 | 2.154 | 2.672 | 3.068 | 3.660 | 4.166 | |
| Total Number | 5 | 9 | 14 | 20 | 25 | 30 | |
| Method | |||||||
| Random Method | 0.442 | 0.950 | 1.836 | 2.534 | 3.224 | 3.822 | |
| Traversing Method | 0.626 | 1.204 | 2.128 | 2.862 | 3.598 | 4.074 | |
| Proposed Method | 1.028 | 2.122 | 3.376 | 5.252 | 7.326 | 8.544 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, W.; Guan, X.; Wang, L. A Novel Searching Method Using Reinforcement Learning Scheme for Multi-UAVs in Unknown Environments. Appl. Sci. 2019, 9, 4964. https://doi.org/10.3390/app9224964
Yue W, Guan X, Wang L. A Novel Searching Method Using Reinforcement Learning Scheme for Multi-UAVs in Unknown Environments. Applied Sciences. 2019; 9(22):4964. https://doi.org/10.3390/app9224964
Chicago/Turabian StyleYue, Wei, Xianhe Guan, and Liyuan Wang. 2019. "A Novel Searching Method Using Reinforcement Learning Scheme for Multi-UAVs in Unknown Environments" Applied Sciences 9, no. 22: 4964. https://doi.org/10.3390/app9224964
APA StyleYue, W., Guan, X., & Wang, L. (2019). A Novel Searching Method Using Reinforcement Learning Scheme for Multi-UAVs in Unknown Environments. Applied Sciences, 9(22), 4964. https://doi.org/10.3390/app9224964