Woc-Bots: An Agent-Based Approach to Decision-Making



Abstract
:1. Introduction
2. Methods & Design
2.1. Datasets & Libraries
- The Movie Database (TMDb) (https://www.kaggle.com/tmdb/tmdb-movie-metadata/)
- MovieLens (ML) https://www.kaggle.com/grouplens/movielens-20m-dataset/) [13]
- Movies were matched between the two datasets based on ID, using “movieId” and “tmdbId” values provided in the ML dataset.
- The ML dataset used a 0–5 rating system while the TMDb dataset used a 0–10 rating system, the ML ratings were multiplied by 2.
- Only overlapping genres from each dataset were considered; e.g., if, for Toy Story, the ML dataset lists it as “action, animation, family” and the TMDb dataset lists Toy Story as “family, adventure, animation”, the movie was considered to fall into only the “animation” and “family” genres.
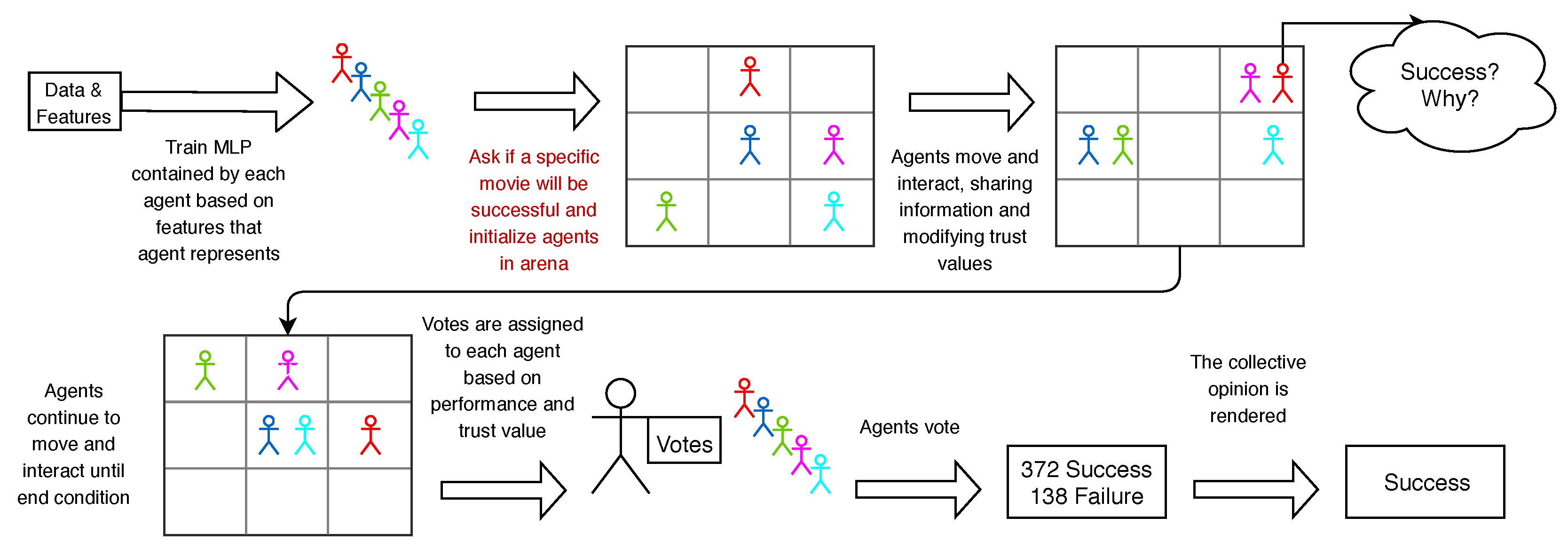
2.2. Agent Design
- Classifier: MLP classifier with a single hidden layer
- Classifier configuration: shape, depth, activation and optimization algorithms
- Initialization algorithm: How the agents are initialized within the interaction space
- Movement algorithm: How the agents move within the interaction space
- Interaction algorithm: How (if) an agent interacts with other agents
- Scoring algorithm: How an agent reaches the conclusion it does; a combination of the internal classifier and information learned while interacting with other agents
2.2.1. Classifier
2.2.2. Agent Initialization & Movement
2.2.3. Interaction & Scoring
2.3. Opinion Aggregation
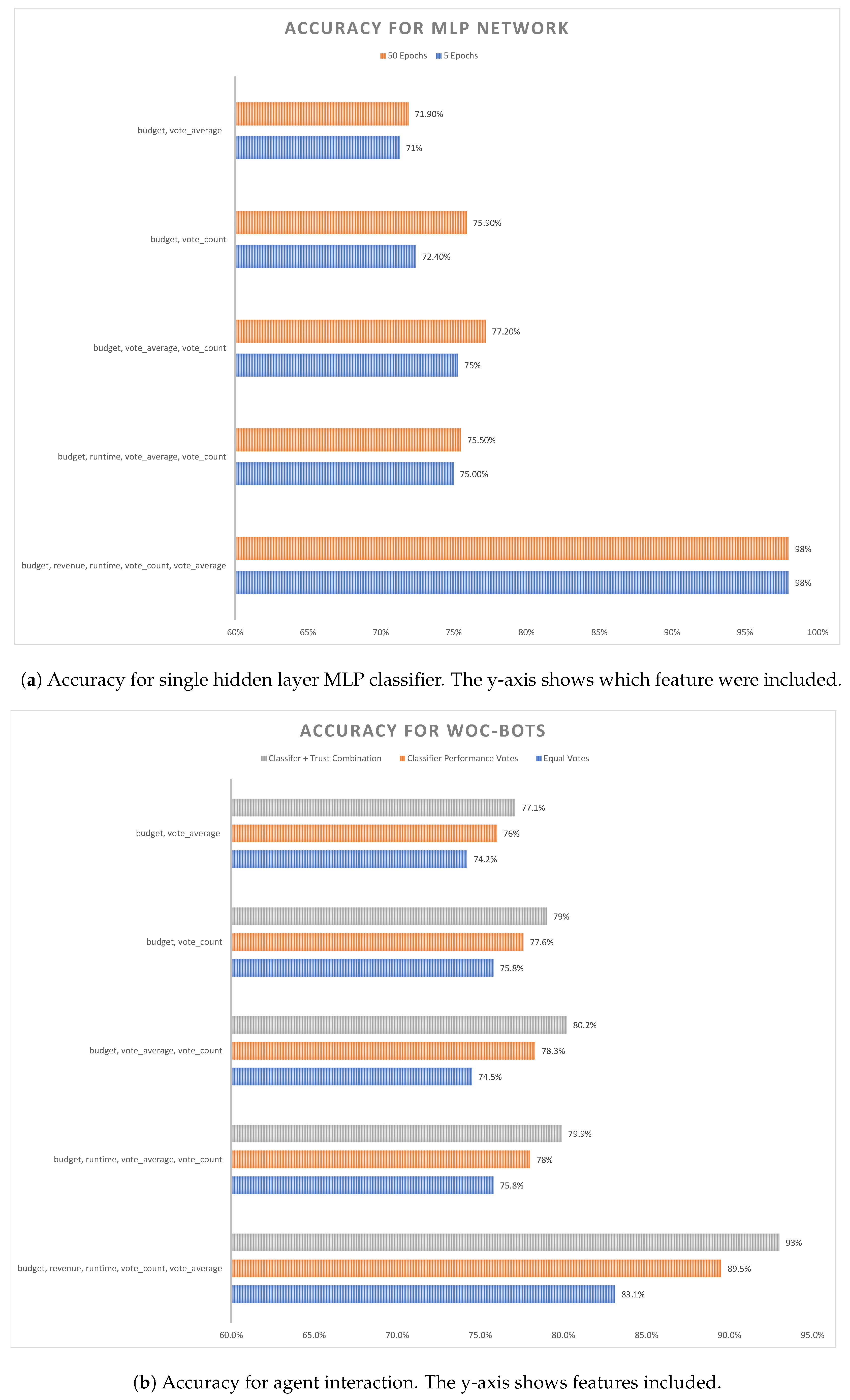
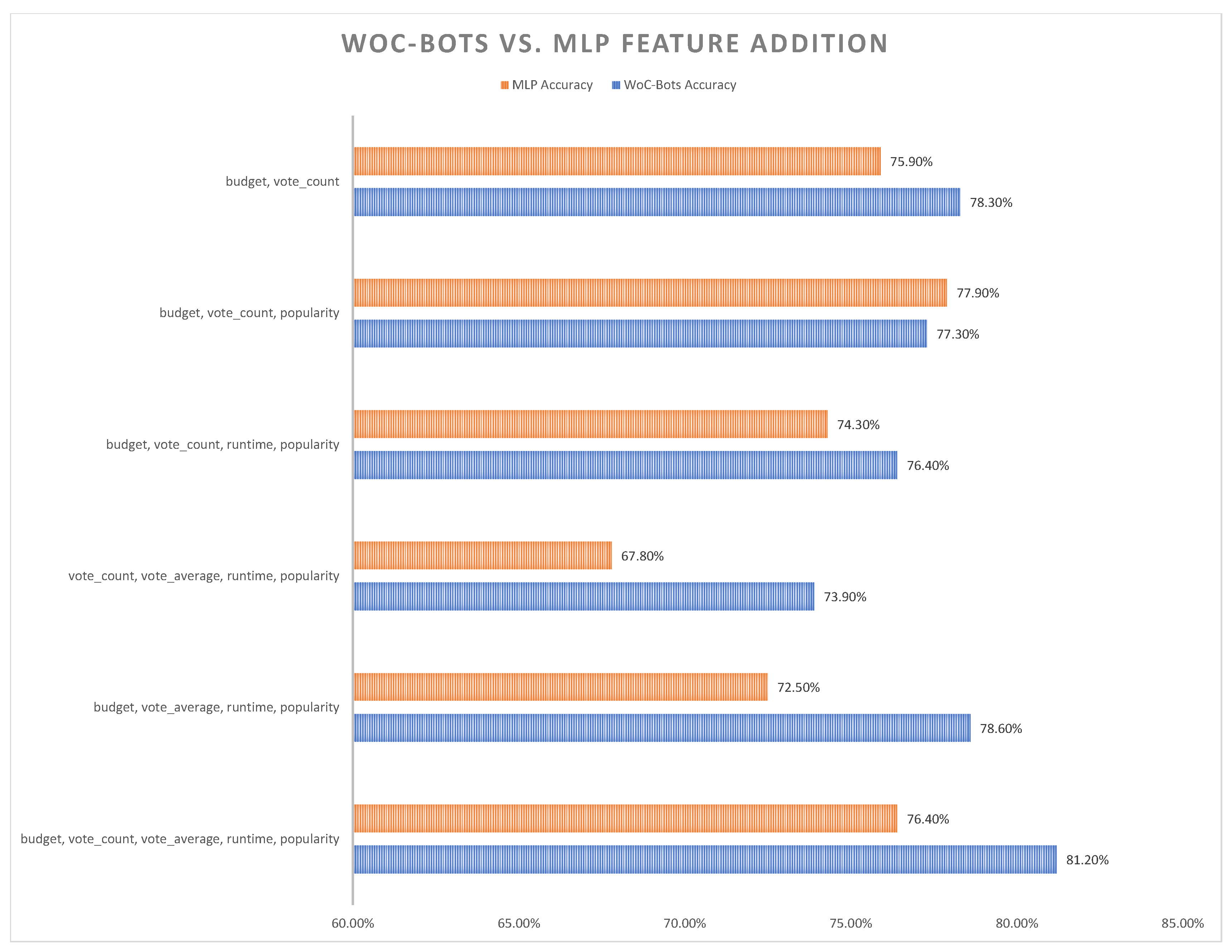
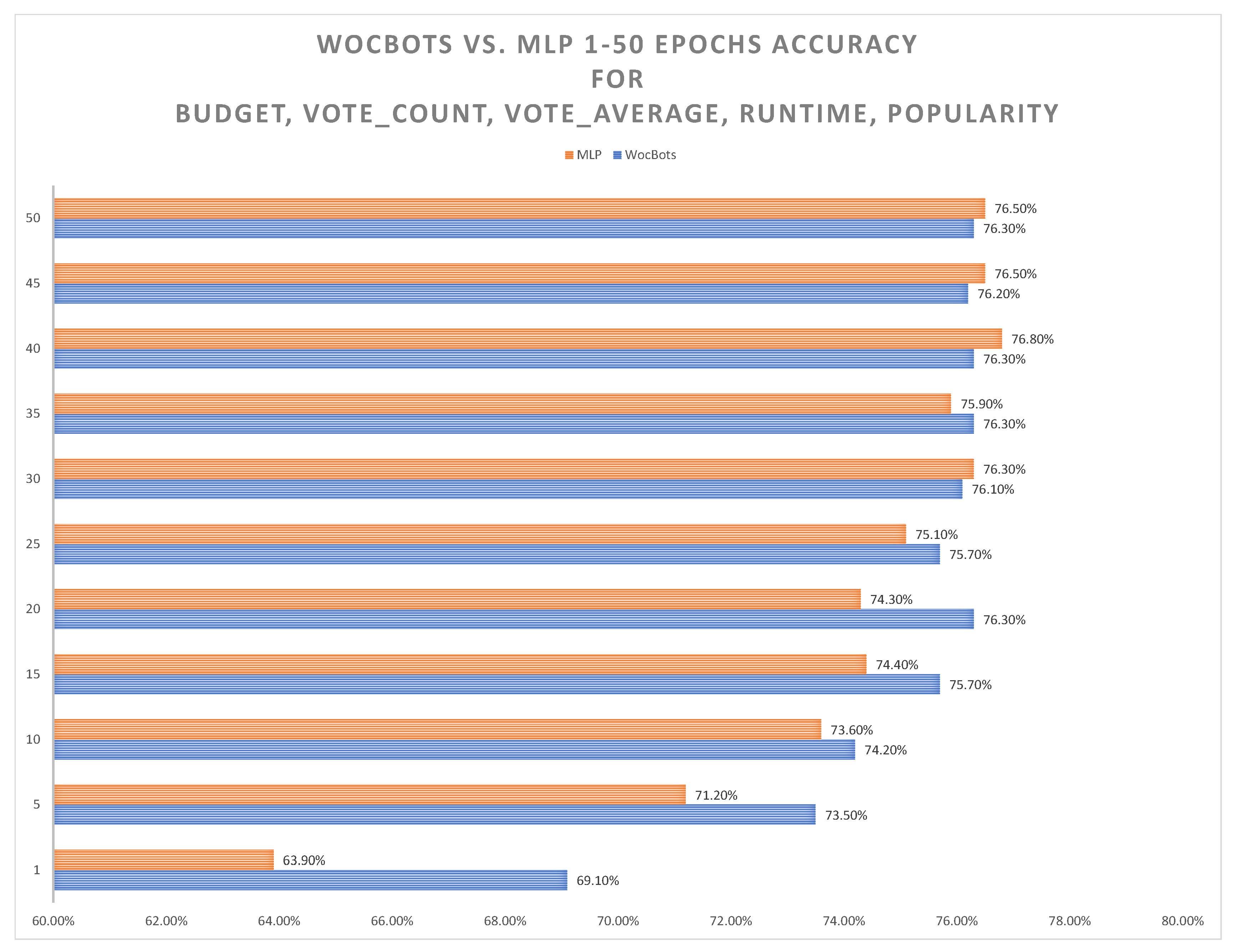
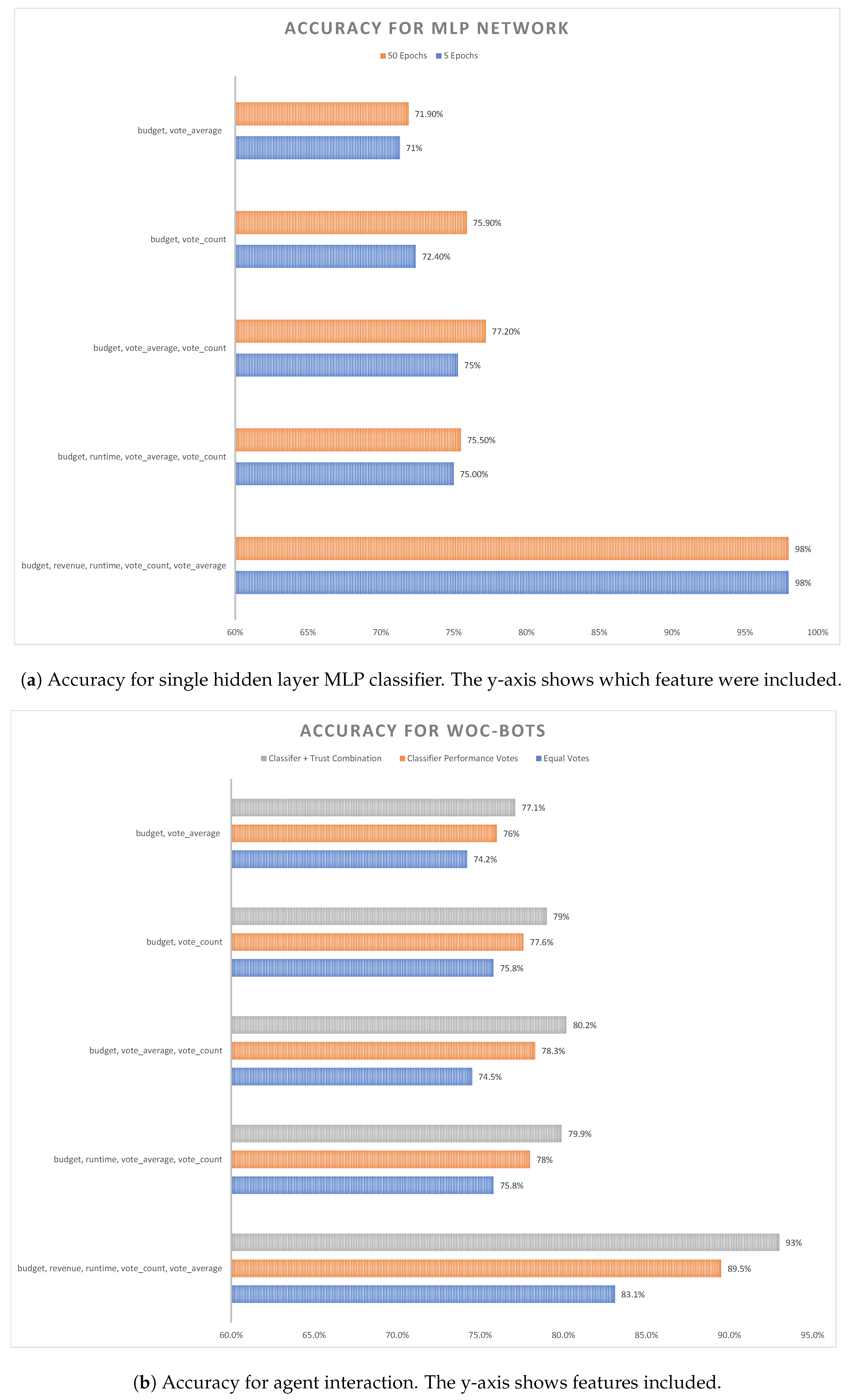
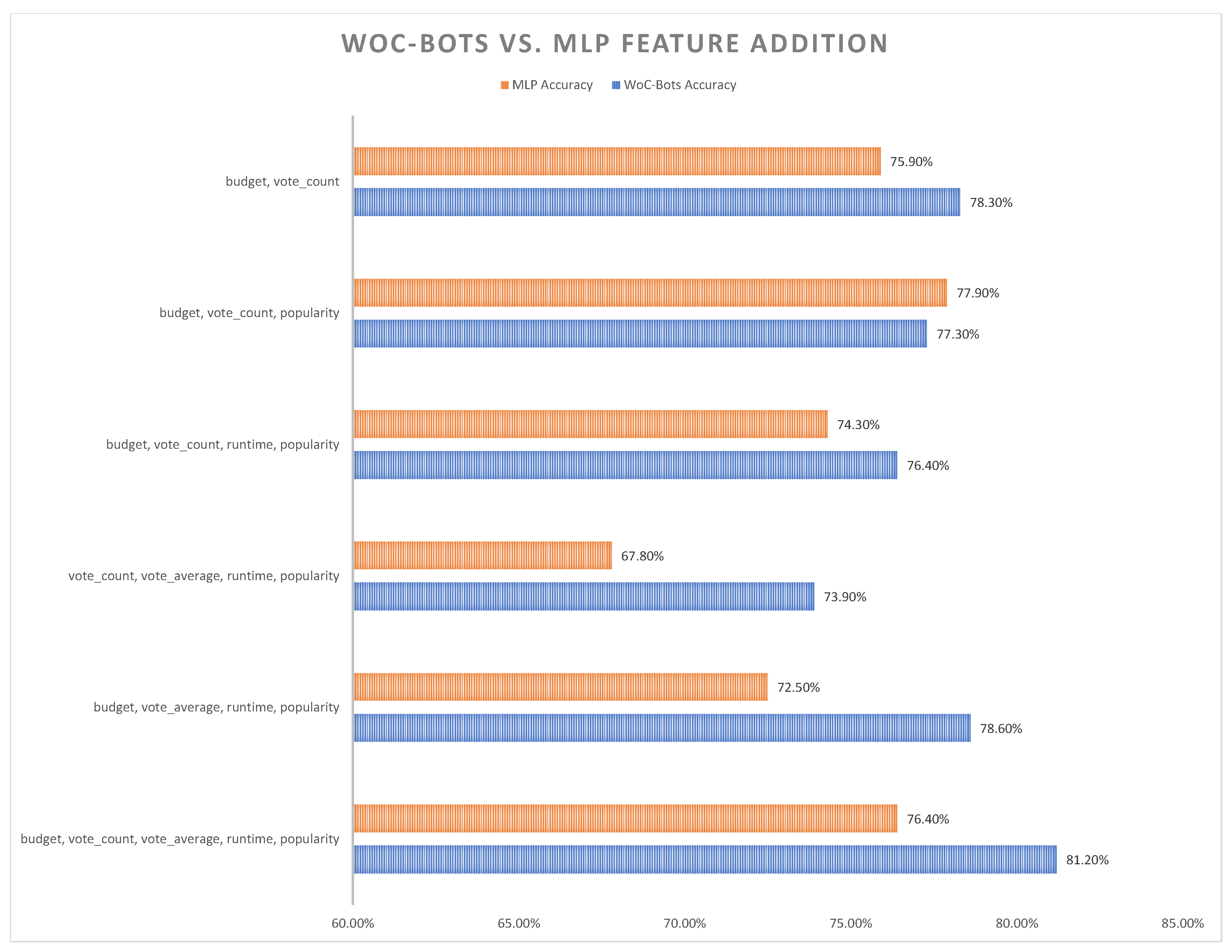
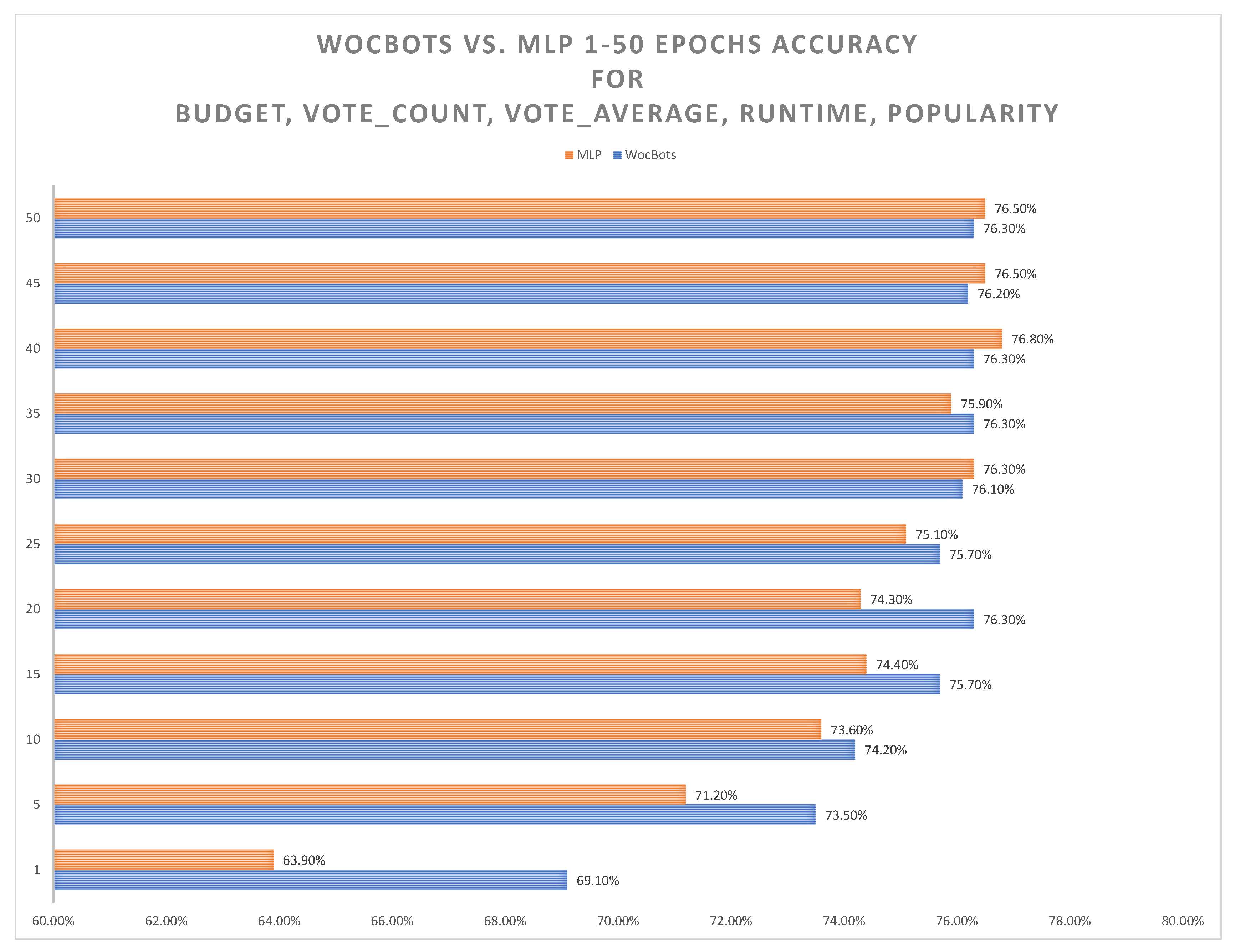
3. Results
4. Discussion
5. Conclusions & Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| WoC | Wisdom of the Crowd |
| MLP | Multi-layer Perceptron |
| ANN | Artificial Neural Network |
| PM | Prediction Market |
| TMDb | The Movie Database |
| API | Application Programming Interface |
| ML | MovieLens |
| DL4J | Deeplearning4j |
| JVM | Java Virtual Machine |
| UWM | Unweighted Mean Model |
References
- Olivas, E.S. Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2009. [Google Scholar]
- Yoon, J.; Yang, E.; Lee, J.; Hwang, S.J. Lifelong learning with dynamically expandable networks. arXiv 2017, arXiv:1708.01547. [Google Scholar]
- Parkes, D.C.; Seuken, S. Prediction Markets. In Introduction to Economics and Computation: A Design Approach; Cambridge University Press: Cambridge, UK, 2016; Chapter 18. [Google Scholar]
- Yi, S.K.; Steyvers, M.; Lee, M.D.; Dry, M.J. The wisdom of the crowd in combinatorial problems. Cogn. Sci. 2012, 36, 452–470. [Google Scholar] [CrossRef] [PubMed]
- Othman, A. Zero-intelligence agents in prediction markets. In Proceedings of the 7th International Joint Conference on Autonomous Agents and Multiagent Systems, Honolulu, HI, USA, 14–18 May 2007; Volume 2, pp. 879–886. [Google Scholar]
- Chen, Y.; Reeves, D.M.; Pennock, D.M.; Hanson, R.D.; Fortnow, L.; Gonen, R. Bluffing and strategic reticence in prediction markets. In Proceedings of the International Workshop on Web and Internet Economics, San Diego, CA, USA, 12–14 December 2007; pp. 70–81. [Google Scholar]
- Dimitrov, S.; Sami, R. Non-myopic strategies in prediction markets. In Proceedings of the 9th ACM Conference on Electronic Commerce, Chicago, IL, USA, 8–12 June 2008; pp. 200–209. [Google Scholar]
- Othman, A.; Sandholm, T. When do markets with simple agents fail? In Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems, Toronto, ON, Canada, 9–14 May 2010; Volume 1, pp. 865–872. [Google Scholar]
- Ertekin, Ş.; Rudin, C.; Hirsh, H. Approximating the crowd. Data Min. Knowl. Discov. 2014, 28, 1189–1221. [Google Scholar] [CrossRef]
- Page, S.E. The Difference: How the Power of Diversity Creates Better Groups, Firms, Schools, and Societies-New Edition; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Helsinger, A.; Thome, M.; Wright, T. Cougaar: A scalable, distributed multi-agent architecture. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, The Hague, The Netherlands, 10–13 October 2004; Volume 2, pp. 1910–1917. [Google Scholar]
- De Vany, A. Hollywood Economics: How Extreme Uncertainty Shapes the Film Industry; Routledge: Abingdon, UK, 2003. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. ACM Trans. Interact. Intell. Syst. 2016, 5, 19. [Google Scholar] [CrossRef]
- Team, D. Deeplearning4j: Open-source distributed deep learning for the JVM. Apache Softw. Found. Licens. 2018, 2. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Garnett, P.; Bissell, J. Modelling Social Networks Reveals How Information Spreads. 2013. Available online: http://theconversation.com/modelling-social-networks-reveals-how-information-spreads-18776 (accessed on 10 June 2019).
- Du, Q.; Hong, H.; Wang, G.A.; Wang, P.; Fan, W. CrowdIQ: A New Opinion Aggregation Model. In Proceedings of the 50th Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 4–7 January 2017. [Google Scholar]
- Hastie, R.; Kameda, T. The robust beauty of majority rules in group decisions. Psychol. Rev. 2005, 112, 494. [Google Scholar] [CrossRef] [PubMed]
- Valentini, G.; Hamann, H.; Dorigo, M. Self-organized collective decision making: The weighted voter model. In Proceedings of the International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014; pp. 45–52. [Google Scholar]
- Awasthi, D. Exploratory Analysis of Movies on TMDB. Available online: https://rstudio-pubs-static.s3.amazonaws.com/369891_b123051c3cb64da5a6d22a8d0b6e0d84.html (accessed on 19 October 2019).
- Malkoc, I. The Movies Dataset. Available online: http://ibomalkoc.com/movies-dataset/ (accessed on 23 August 2019).
- Surowiecki, J. The Wisdom of the Crowds; Anchor Books, a Division of Random House: New York, NY, USA, 2005. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Zhu, Y.F.; Tang, X.M. Overview of swarm intelligence. In Proceedings of the IEEE International Conference on Computer Application and System Modeling, Taiyuan, China, 22–24 October 2010; Volume 9, pp. 9–400. [Google Scholar]
- Rosenberg, L. Artificial Swarm Intelligence, a Human-in-the-loop approach to AI. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Rosenberg, L.; Pescetelli, N.; Willcox, G. Artificial Swarm Intelligence amplifies accuracy when predicting financial markets. In Proceedings of the IEEE 8th Annual Conference on Ubiquitous Computing, Electronics and Mobile Communication, New York, NY, USA, 19–21 October 2017; pp. 58–62. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Description |
|---|---|
| budget | given to all agents, reported budget for movie |
| tmdb_popularity | dynamic variable from TMDb API attempting to represent interest in movie |
| revenue | used for sanity checks, reported revenue |
| runtime | unreliable metric for success without including genre information |
| tmdb_vote_average | average score from TMDb, can be combined with ML average |
| tmdb_vote_count | total votes for a movie from TMDb, can be combined with ML count |
| ml_vote_average | average score from ML, can be combined with TMDb average |
| ml_vote_count | total votes for a movie from ML, can be combined with TMDb count |
| ml_tmdb_genres | combined genre information from TMDb & ML; first 2 listed genres used |
| vote_average | combined tmdb_vote_average and ml_vote_average |
| vote_count | combined tmdb_vote_count and ml_vote_count |
| Variable | Description |
|---|---|
| current_prediction | true if prediction for movie is success |
| trust_score | initialized to classifier precision, updated by other agents |
| features | a list of features used by the agent’s classifier |
| prior_performance | long-term history of agent performance, varied between 0.7 and 1.3 where 1.0 is average performance |
| certainty | an average of classifier accuracy and precision, multiplied by prior_performance, bounded by 0.5 and 1.5 |
| eval_accuracy | initial classification accuracy |
| eval_precision | initial classification precision |
| eval_recall | initial classification recall |
| confidence | biased value based on an average of accuracy, precision, and recall favoring whichever is deemed most important |
| Features | 5 Epochs | 50 Epochs |
|---|---|---|
| budget, revenue | 98% | 100% |
| budget, vote_average, vote_count | 77.2% | 77.6% |
| budget, tmdb_popularity, vote_average, vote_count | 75.4% | 75.7% |
| budget, vote_count | 75.7% | 75.5% |
| budget, tmdb_popularity, tmdb_vote_average, tmdb_vote_count | 72.8% | 74.9% |
| budget, tmdb_vote_count, ml_vote_count | 73% | 73.4% |
| budget, ml_vote_average, ml_vote_count | 62.2% | 64.1% |
| budget, ml_vote_count | 60.3% | 61.9% |
| budget, tmdb_vote_average | 60.9% | 61.4% |
| budget, runtime | 53.9% | 56.4% |
| Average (budget, revenue agent removed) | 67.93% | 68.99% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grimes, S.; Breen, D.E. Woc-Bots: An Agent-Based Approach to Decision-Making. Appl. Sci. 2019, 9, 4653. https://doi.org/10.3390/app9214653
Grimes S, Breen DE. Woc-Bots: An Agent-Based Approach to Decision-Making. Applied Sciences. 2019; 9(21):4653. https://doi.org/10.3390/app9214653
Chicago/Turabian StyleGrimes, Sean, and David E. Breen. 2019. "Woc-Bots: An Agent-Based Approach to Decision-Making" Applied Sciences 9, no. 21: 4653. https://doi.org/10.3390/app9214653
APA StyleGrimes, S., & Breen, D. E. (2019). Woc-Bots: An Agent-Based Approach to Decision-Making. Applied Sciences, 9(21), 4653. https://doi.org/10.3390/app9214653