FDCNet: Frontend-Backend Fusion Dilated Network Through Channel-Attention Mechanism


Abstract
:1. Introduction
- We fuse the feature maps of the frontend and the backend. It has only a single column with convolutional kernels of one size, subtracting additional branches and multi-columns and reducing parameters. The convolutional layers of different levels contain not only different semantic information but also different scale feature information. Their fusion can deal with the large scale variation due to the perspective effect and the background interference, and share more features. It also requires fewer parameters and computation.
- We introduce the channel-attention block motived by Reference [10]. Avoiding the crude concatenate, the channel-attention block could take the weights of channels into consideration and ensure consummate fusion by enhancing the various scale features. On the other hand, it can conduct feature recalibration to capture spatial correlations and selectively emphasize informative features, so as to make the density map present a smooth transition between nearest pixels and improve the representation of our network.
- We utilize the dilated layer as the dilated block to the tail end of the network, which has less parameters but expands the receptive field. Furthermore, it contains more detailed global and spatial information to generate a high-quality density map.
- We subjoin SSIM to the loss function, which measures the local pattern consistency of the estimated density map and ground truth. So the final loss function has better representation of the difference between the estimation and the ground truth. Owing to it the accuracy can be greatly improved.
2. Related Work
2.1. Detection-Based Methods
2.2. Regression-Based Methods
2.3. CNN-Based Methods
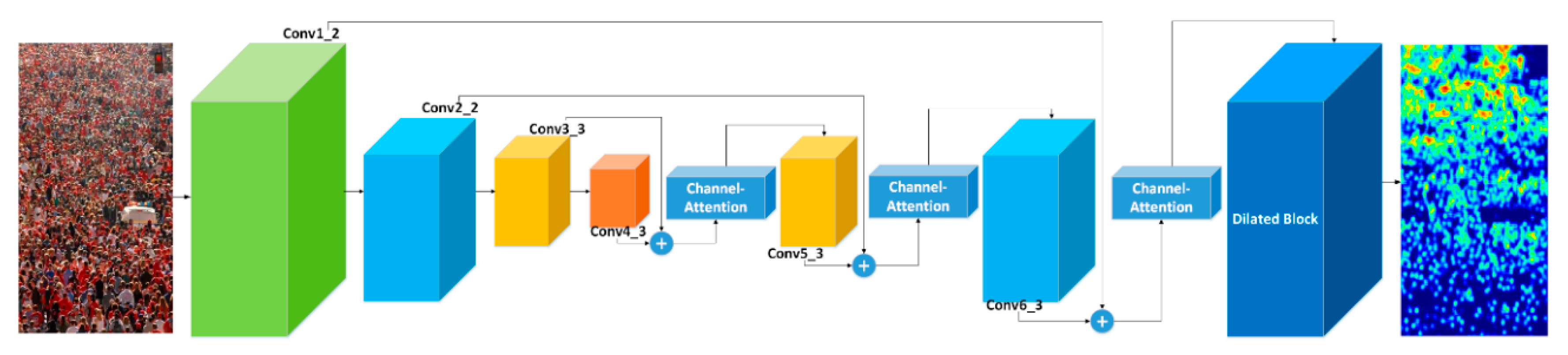
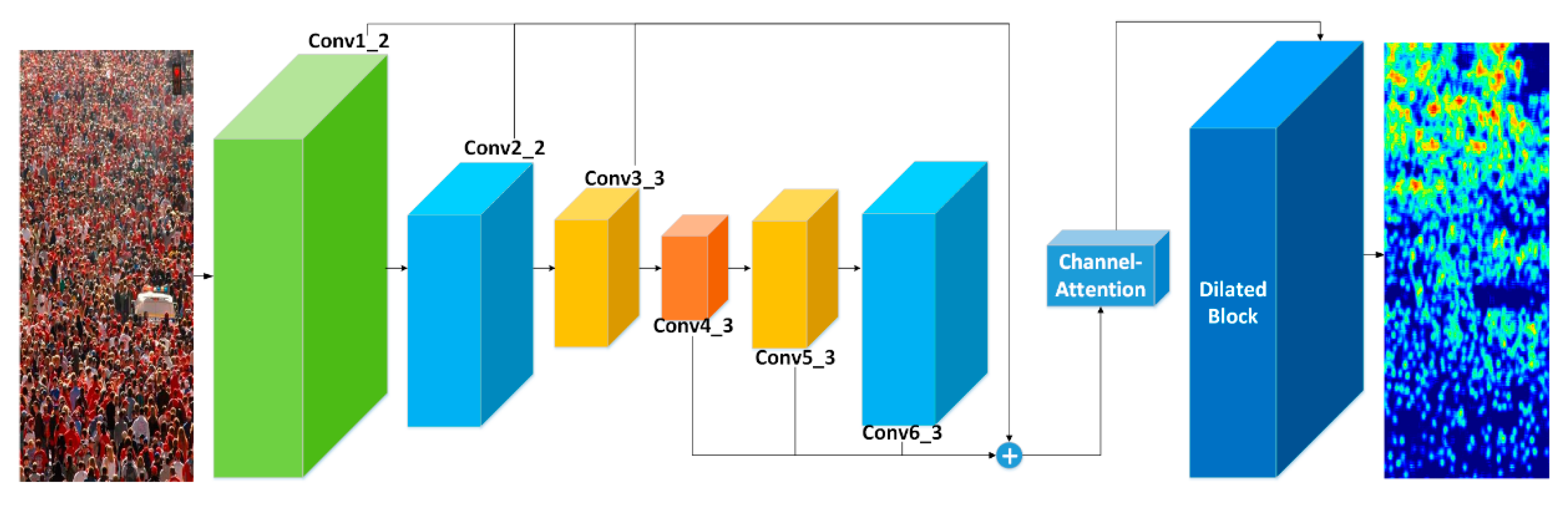
3. Our Proposed Method—FDCNet
3.1. The Frontend-Backend Fusion
3.2. The Channel-Attention Block
3.3. The Dilated Block
3.4. The Loss Function
3.4.1. The Euclidean Loss Function
3.4.2. The SSIM-Based Loss Function
3.4.3. The Fusion Loss Function
4. Experiments
4.1. Training Details and Data Augmentation
4.2. Ground Truth Generation
4.3. Evaluation Metric
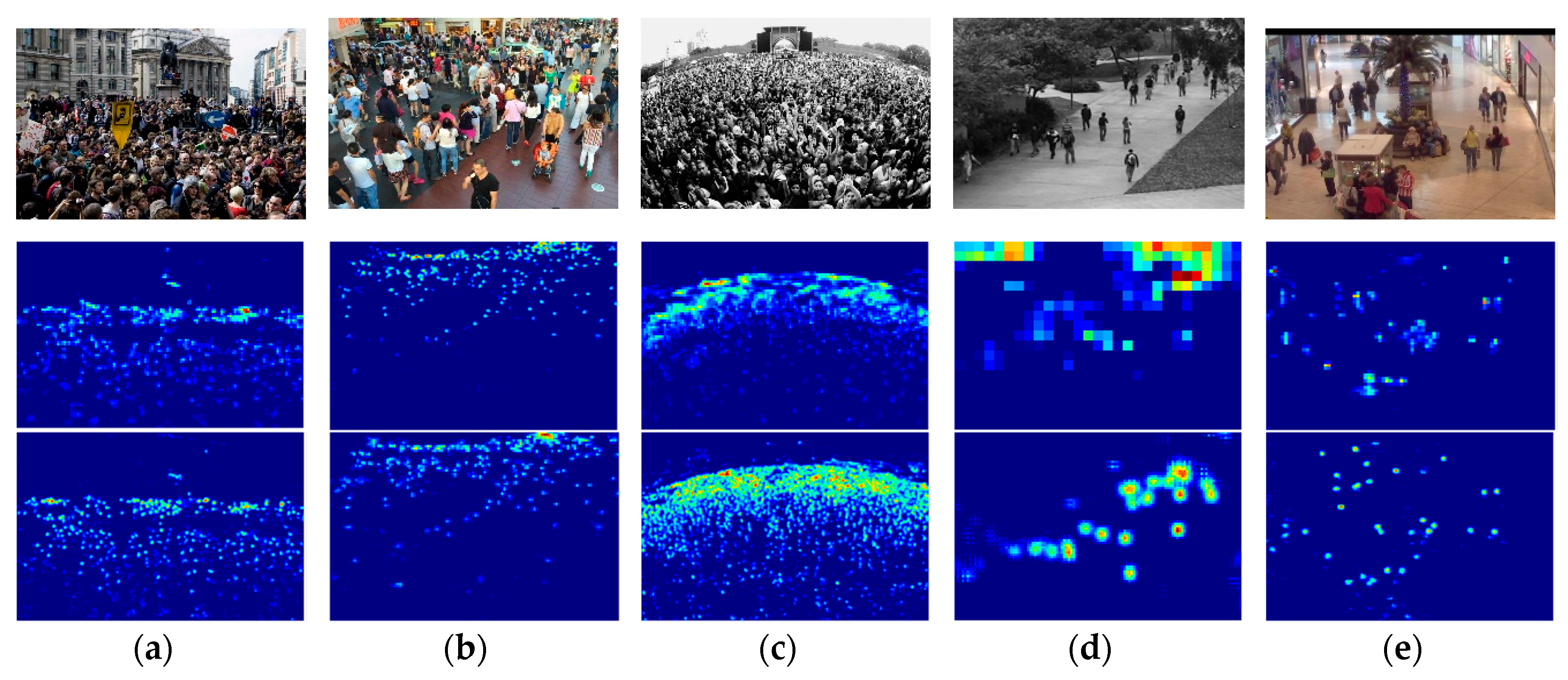
4.4. Performance on Common Datasets
4.4.1. The ShanghaiTech Dataset
4.4.2. The UCF_CC_50 Dataset
4.4.3. The UCSD Dataset
4.4.4. The Mall Dataset
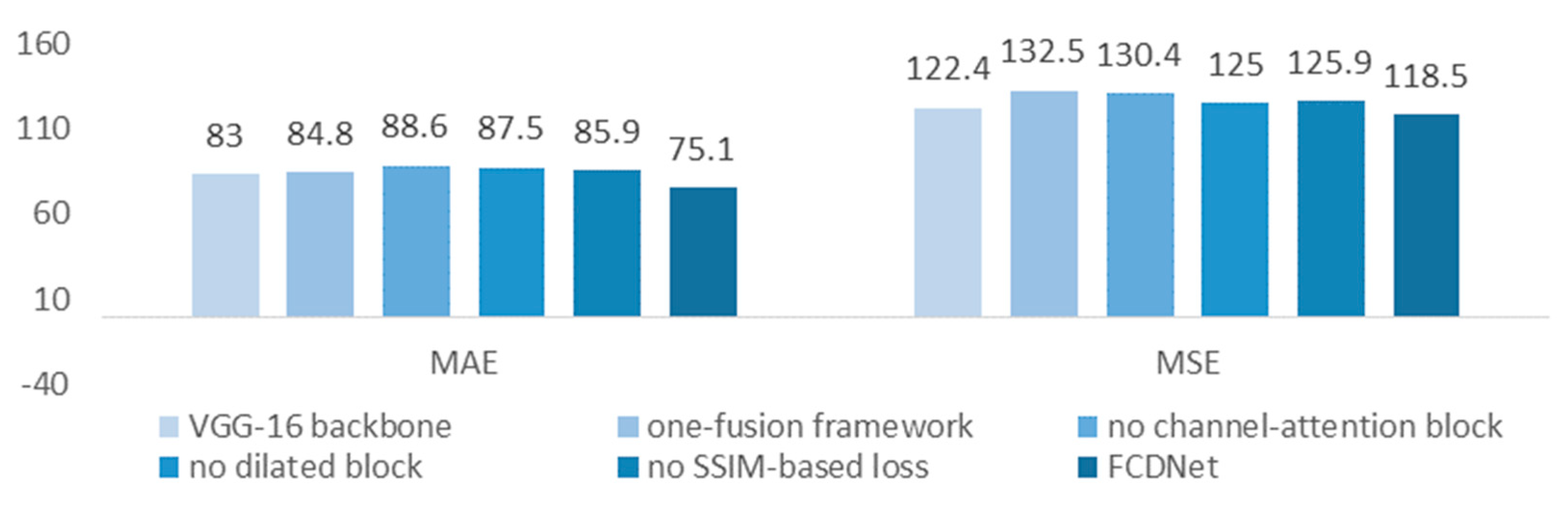
4.4.5. Ablation Study
- VGG-16 framework
- One-fusion framework
- The channel-attention block
- The dilated block
- The loss function
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Idrees, H.; Soomro, K.; Shah, M. Detecting humans in dense crowds using locally-consistent scale prior and global occlusion reasoning. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1986–1998. [Google Scholar] [CrossRef] [PubMed]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 2547–2554. [Google Scholar]
- Yang, J.; Zhou, Y.; Kung, S.Y. Multi-scale generative adversarial networks for crowd counting. In Proceedings of the IEEE International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 1051–4651. [Google Scholar]
- Olmschenk, G.; Tang, H.; Zhu, Z. Crowd counting with minimal data using generative adversarial networks for multiple target regression. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, CA, USA, 12–15 March 2018. [Google Scholar]
- Liu, L.; Wang, H.; Li, G.; Ouyang, W.; Lin, L. Counting using Deep Recurrent Spatial-Aware Network. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating high-quality crowd density maps using contextual pyramid cnns. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1879–1888. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale aggregation network for accurate and efficient crowd counting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 6. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multitask learning of high-level prior and density estimation for crowd counting. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100. [Google Scholar]
- Zhang, L.; Shi, M.; Chen, Q. Crowd counting via scale-adaptive convolutional neural network. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, CA, USA, 12–15 March 2018; pp. 1113–1121. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 544–559. [Google Scholar]
- Liu, X.; van de Weijer, J.; Bagdanov, A.D. Leveraging unlabeled data for crowd counting by learning to rank. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Shi, M.; Yang, Z.; Xu, C.; Chen, Q. Perspective-Aware CNN for Crowd Counting. In Proceedings of the 21st IEEE International Conference on Electronics, Bucharest, Romania, 29–31 October 2018. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Chan, A.B.; Vasconcelos, N. Bayesian poisson regression for crowd counting. In Proceedings of the IEEE 12th International Conference, Kyoto, Japan, 27 September–4 October 2009; pp. 545–551. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2010; pp. 1324–1332. [Google Scholar]
- Pham, V.Q.; Kozakaya, T.; Yamaguchi, O.; Okada, R. Count forest: Co-voting uncertain number of targets using random forest for crowd density estimation. In Proceedings of the Computer Vision IEEE International Conference, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 3253–3261. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the ACM on Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-aware crowd counting. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Liu, C.; Weng, X.; Mu, Y. Recurrent attentive zooming for joint crowd counting and precise localization. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Chaudhari, S.; Polatkan, G.; Ramanath, R.; Mithal, V. An Attentive Survey of Attention Models. Available online: https://arxiv.org/abs/1904.02874 (accessed on 5 April 2019).
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localized crowd counting. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Wang, Y.; Zou, Y. Fast visual object counting via example-based density estimation. In Proceedings of the 2016 IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Average Resolution | Total Images | Min Number | Max Number | Avg Number | Total Number |
|---|---|---|---|---|---|---|
| ShanghaiTech Part A | 589 × 868 | 482 | 33 | 3139 | 501 | 241,677 |
| ShanghaiTech Part B | 768 × 1024 | 716 | 9 | 578 | 124 | 88,488 |
| UCF_CC_50 | 2101 × 2888 | 50 | 94 | 4543 | 1280 | 63,974 |
| UCSD | 238 × 158 | 2000 | 11 | 46 | 25 | 49,885 |
| Mall | 640 × 480 | 2000 | 13 | 53 | 31 | 62,325 |
| Method | Part A | Part B | ||
|---|---|---|---|---|
| MAE | MSE | MAE | MSE | |
| MCNN [16] | 110.2 | 173.2 | 26.4 | 41.3 |
| SwitchCNN [8] | 90.4 | 135.0 | 21.6 | 33.4 |
| SaCNN [12] | 86.8 | 139.2 | 16.2 | 25.8 |
| CSRNet [11] | 68.2 | 115.0 | 10.6 | 16.0 |
| FDCNet | 75.1 | 118.5 | 10.3 | 15.8 |
| Method | MAE | MSE |
|---|---|---|
| MCNN [16] | 377.6 | 509.1 |
| SwitchCNN [8] | 318.1 | 439.2 |
| SaCNN [12] | 314.9 | 424.8 |
| CSRNet [11] | 266.1 | 397.5 |
| FDCNet | 246.8 | 322.2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Li, G.; Lei, J.; He, J. FDCNet: Frontend-Backend Fusion Dilated Network Through Channel-Attention Mechanism. Appl. Sci. 2019, 9, 3466. https://doi.org/10.3390/app9173466
Zhang Y, Li G, Lei J, He J. FDCNet: Frontend-Backend Fusion Dilated Network Through Channel-Attention Mechanism. Applied Sciences. 2019; 9(17):3466. https://doi.org/10.3390/app9173466
Chicago/Turabian StyleZhang, Yuqian, Guohui Li, Jun Lei, and Jiayu He. 2019. "FDCNet: Frontend-Backend Fusion Dilated Network Through Channel-Attention Mechanism" Applied Sciences 9, no. 17: 3466. https://doi.org/10.3390/app9173466
APA StyleZhang, Y., Li, G., Lei, J., & He, J. (2019). FDCNet: Frontend-Backend Fusion Dilated Network Through Channel-Attention Mechanism. Applied Sciences, 9(17), 3466. https://doi.org/10.3390/app9173466