Pursuer’s Control Strategy for Orbital Pursuit-Evasion-Defense Game with Continuous Low Thrust Propulsion


Abstract
1. Introduction
2. Mathematical Model of Orbital Pursuit-Evasion-Defense Game
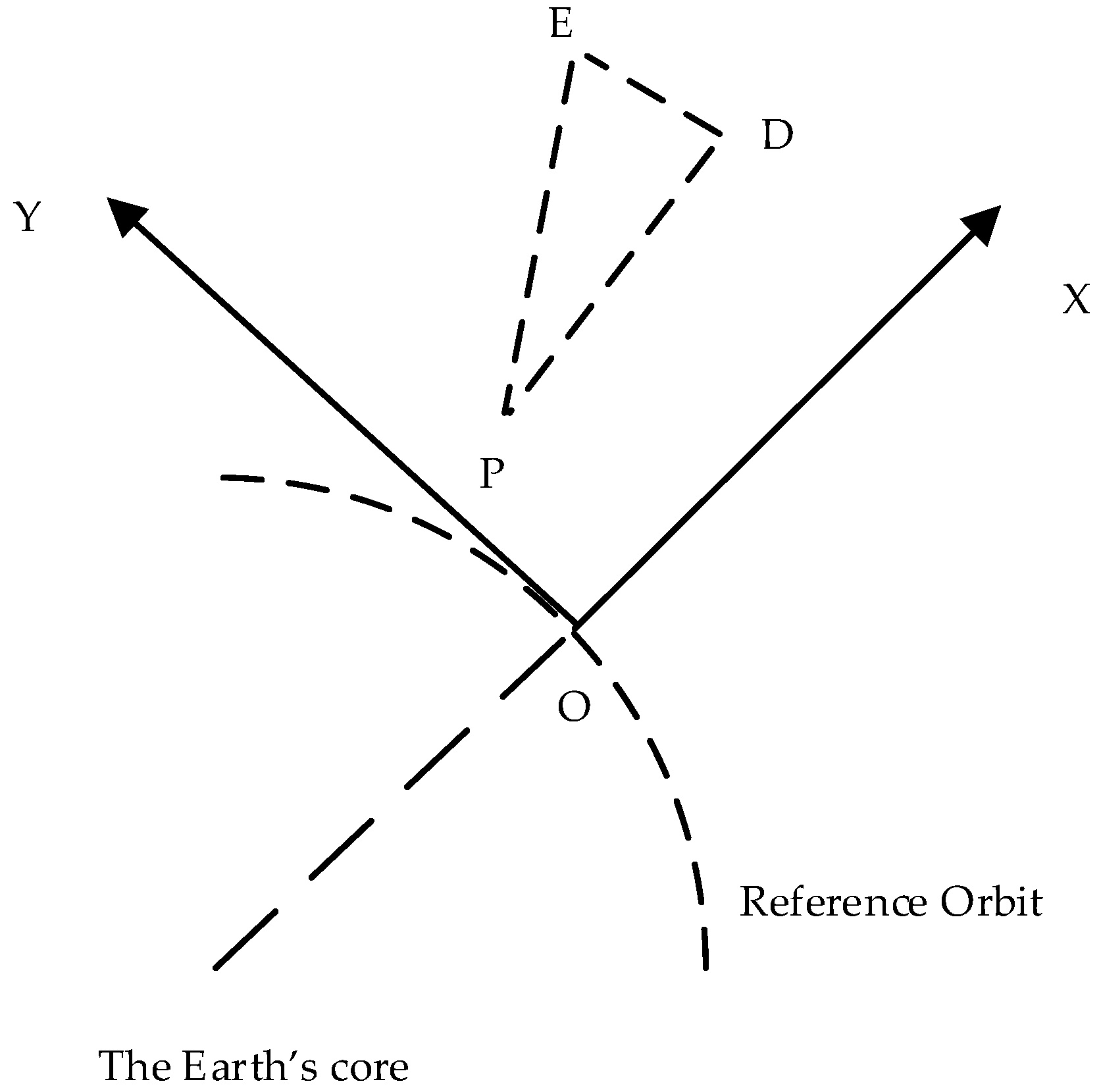
2.1. Relative Orbital Dynamics
2.2. Dimension-Reduction
2.3. Design of Objective Function Based on Fuzzy Comprehensive Evaluation
3. Solution Method for Orbital Pursuit-Evasion-Defense Game
3.1. Necessary Conditions for Optimal Strategies
3.2. Hybrid Numerical Method
3.2.1. Multi-Objective Genetic Algorithm
3.2.2. Multiple Shooting Method
- Step 1.
- Divide the time interval into m subintervals, and represents the boundary points of subintervals, which satisfy .
- Step 2.
- For each subinterval , consider the initial value problem: , , where is the initial value of the problem.
- Step 3.
- Calculate the initial guess by the multi-objective genetic algorithm.
- Step 4.
- Solve the initial value problem on each subinterval to obtain the solution .
- Step 5.
- Determine whether the condition and boundary conditions (29) and (30) are satisfied. If not, use the Newton method to modify the initial value and return to step 4. If the conditions are satisfied, the solution of the TPBVP is obtained successfully.
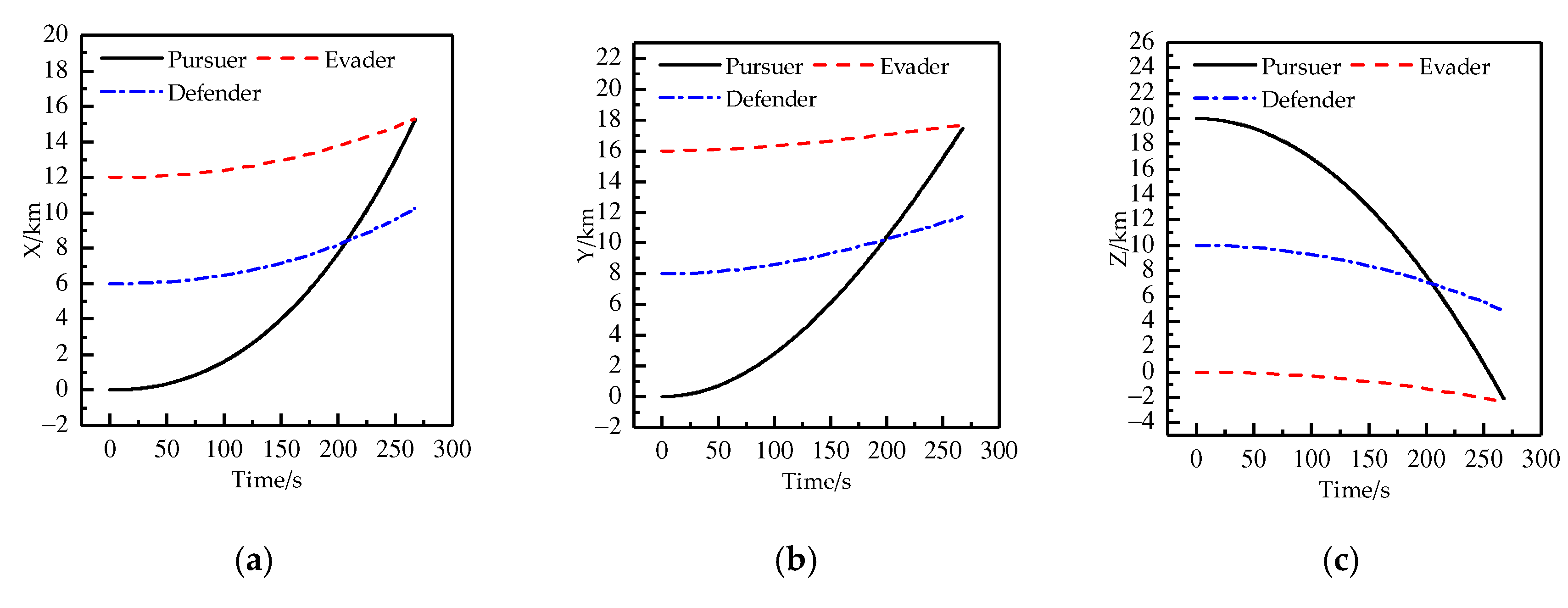
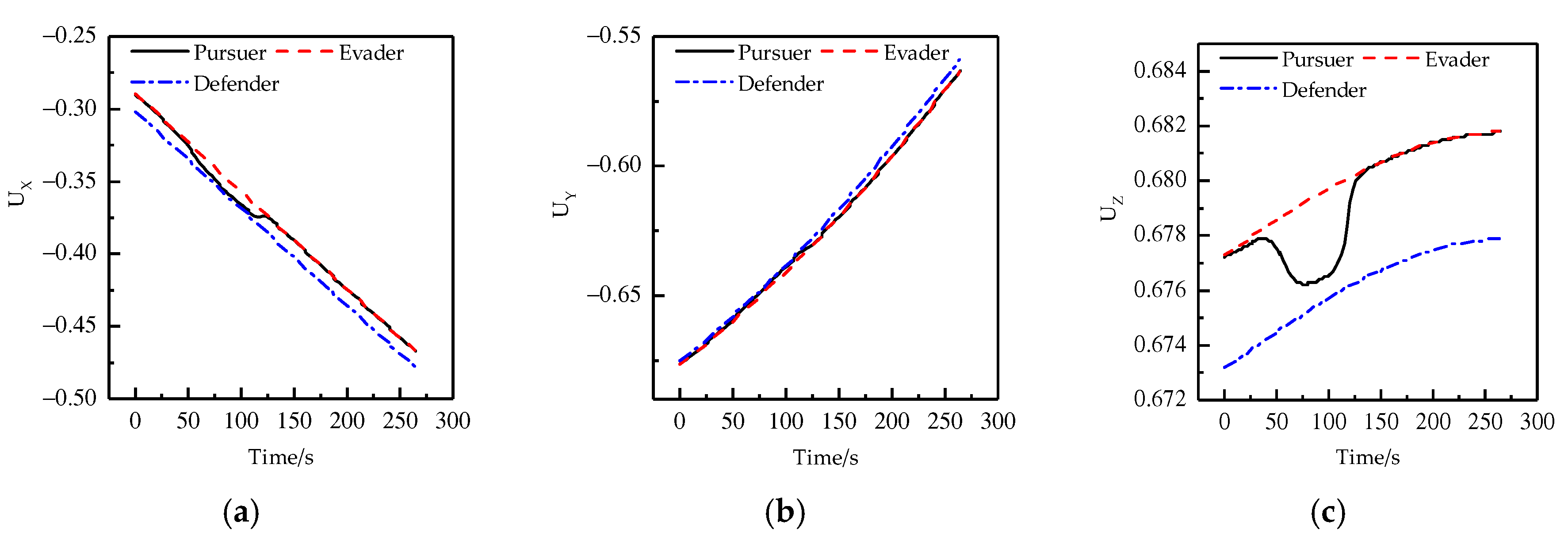
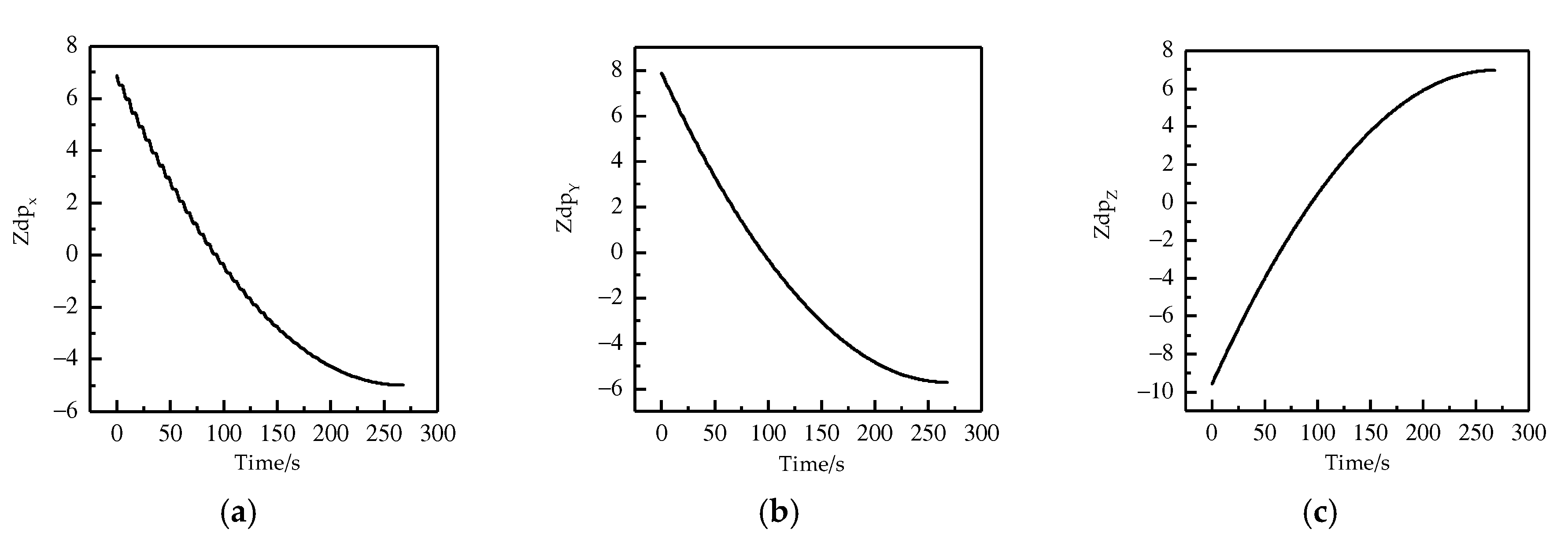
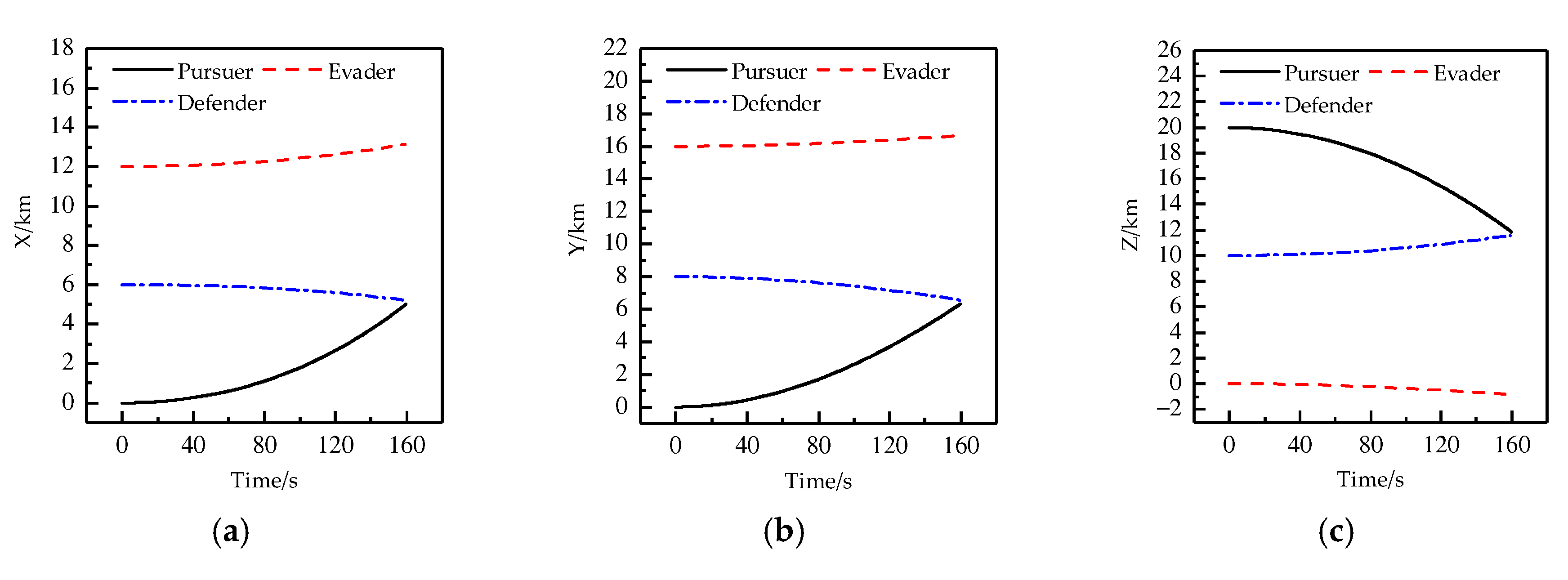
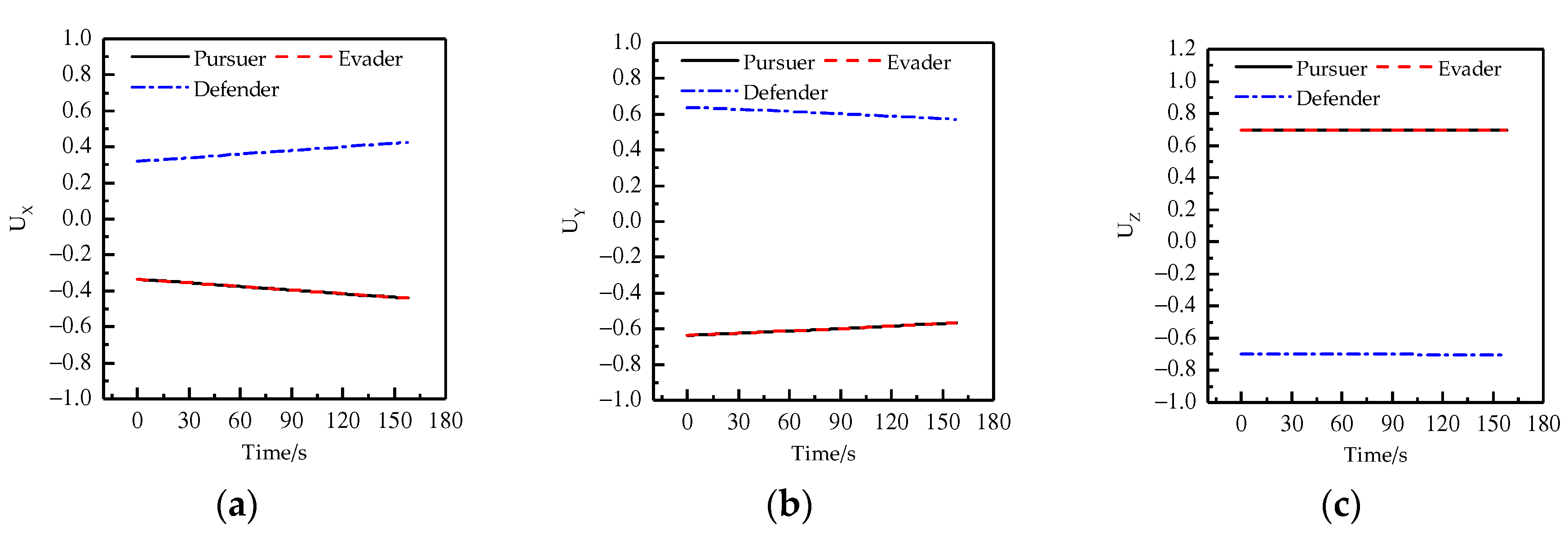
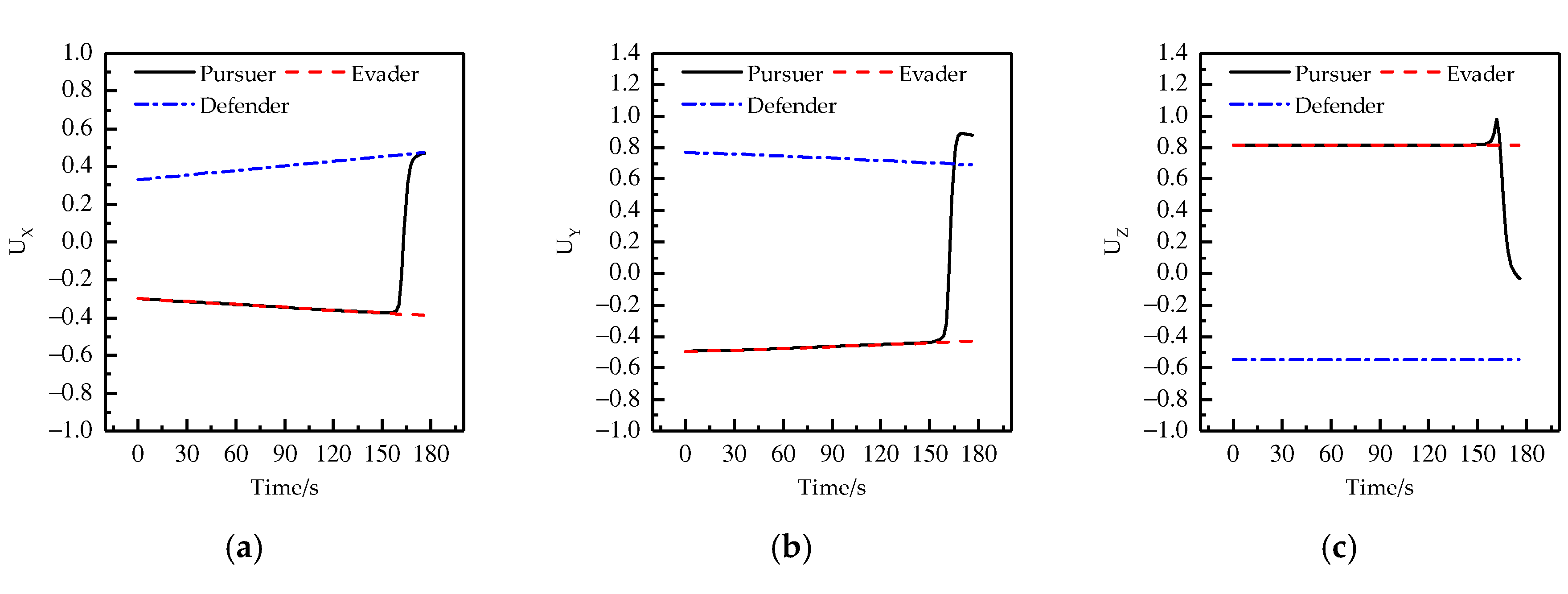
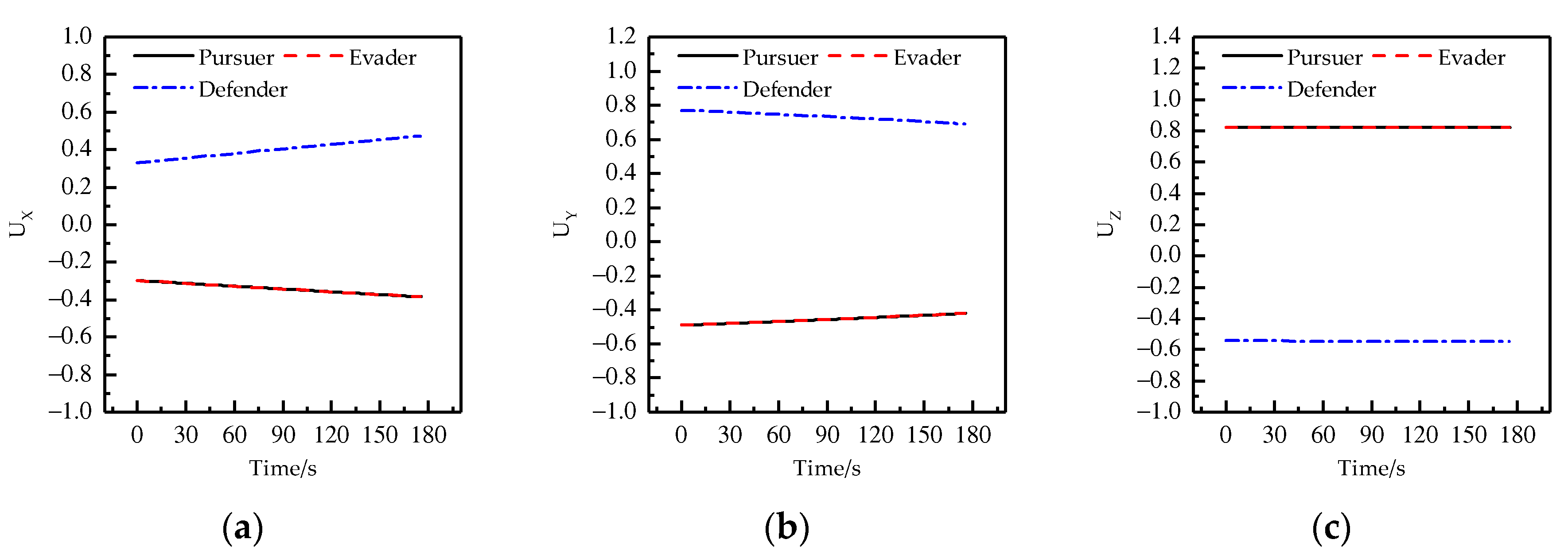
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Widhalm, J.W.; Heise, S.A. Optimal in-plane orbital evasive maneuvers using continuous thrust propulsion. J. Guid. Control Dyn. 1991, 14, 1323–1326. [Google Scholar] [CrossRef]
- Jagat, A.; Sinclair, A.J. Optimization of spacecraft pursuit-evasion game trajectories in the euler-hill reference frame. In Proceedings of the AIAA/AAS Astrodynamics Specialist Conference, San Diego, CA, USA, 4–7 August 2014. [Google Scholar]
- Stupik, J. Optimal Pursuit/Evasion Spacecraft Trajectories in the Hill Reference Frame. Master’s Thsies, University of Illinois at Urbana-Champaign, Champaign, IL, USA, 2013. [Google Scholar]
- Ye, D.; Shi, M.M.; Sun, Z.W. Satellite proximate interception vector guidance based on differential games. Chin. J. Aeronaut. 2018, 31, 1352–1361. [Google Scholar] [CrossRef]
- Isaacs, R. Differential Games: A Mathematical Theory with Applications to Warfare and Pursuit, Control and Optimization; Courier Corporation: New York, NY, USA, 1999. [Google Scholar]
- Wong, R.E. Some aerospace differential games. J. Spacecr. Rocket. 1967, 4, 1460–1465. [Google Scholar] [CrossRef]
- Anderson, G.M.; Bohn, G.D. A near-optimal control law for pursuit-evasion problems between two spacecraft. AIAA J. 1977, 15, 1203–1205. [Google Scholar] [CrossRef]
- Anderson, G.M. Feedback control for a pursuing spacecraft using differential dynamic programming. AIAA J. 1977, 15, 1084–1088. [Google Scholar] [CrossRef]
- Pontani, M.; Conway, B.A. Numerical solution of the three-dimensional orbital pursuit-evasion game. J. Guid. Control Dyn. 2009, 32, 474–487. [Google Scholar] [CrossRef]
- Sun, S.T.; Zhang, Q.H.; Chen, Y. Numerical solution for a class of pursuit-evasion problem in low earth orbit. In Proceedings of the 9th Asian Control Conference (ASCC), Istanbul, Turkey, 23–26 June 2013. [Google Scholar]
- Sun, S.T.; Zhang, Q.H.; Loxton, R.; Li, B. Numerical solution of a pursuit-evasion differential game involving two spacecraft in low earth orbit. J. Ind. Manag. Optim. 2015, 11, 1127–1147. [Google Scholar] [CrossRef]
- Hafer, W.T.; Reed, H.L.; Turner, J.D.; Pham, K. Sensitivity methods applied to orbital pursuit evasion. J. Guid. Control Dyn. 2015, 38, 1118–1126. [Google Scholar] [CrossRef]
- Burk, R.C.; Widhalm, J.W. Minimum impulse orbital evasive maneuvers. J. Guid. Control Dyn. 1989, 12, 121–123. [Google Scholar] [CrossRef]
- Prussing, J.E.; Clifton, R.S. Optimal multiple-impulse satellite evasive maneuvers. J. Guid. Control Dyn. 1994, 17, 599–606. [Google Scholar] [CrossRef]
- Merz, A.W. Noisy satellite pursuit-evasion guidance. J. Guid. Control Dyn. 1989, 12, 901–905. [Google Scholar] [CrossRef]
- Woodbury, T.D.; Hurtado, J.E. Adaptive play via estimation in uncertain nonzero-sum orbital pursuit evasion games. In Proceedings of the AIAA SPACE and Astronautics Forum and Exposition, Orlando, FL, USA, 12–14 September 2017. [Google Scholar]
- Ghosh, P.; Conway, B.A. Near-optimal feedback strategies synthesized using a spatial statistical approach. J. Guid. Control Dyn. 2013, 36, 905–919. [Google Scholar] [CrossRef]
- Liu, Y.F.; Li, R.F.; Hu, L.; Cai, Z.Q. Optimal solution to orbital three-player defense problems using impulsive transfer. Soft Comput. 2018, 22, 2921–2934. [Google Scholar] [CrossRef]
- Liu, Y.; Ye, D.; Hao, Y. Distributed online mission planning for multi-player space pursuit and evasion. Chin. J. Aeronaut. 2016, 29, 1709–1720. [Google Scholar] [CrossRef]
- Markopoulos, N. Analytically exact non-Keplerian motion for orbital transfers. In Proceedings of the Astrodynamics Conference, Scottsdale, AZ, USA, 1–3 August 1994. [Google Scholar]
- Bellman, R. Dynamic Programming; Princeton University: Princeton, NJ, USA, 1957. [Google Scholar]
- Rubinsky, S.; Gutman, S. Three-player pursuit and evasion conflict. J. Guid. Control Dyn. 2014, 37, 98–110. [Google Scholar] [CrossRef]
- Stupik, J.; Pontani, M.; Conway, B. Optimal pursuit/evasion spacecraft trajectories in the hill reference frame. In Proceedings of the AIAA/AAS Astrodynamics Specialist Conference, Minneapolis, MN, USA, 13–16 August 2012. [Google Scholar]
- Lawden, D.F. Optimal Trajectories for Space Navigation; Butterworths: London, UK, 1963. [Google Scholar]
- Clohessy, W.H.; Wiltshire, R.S. Terminal guidance system for satellite rendezvous. J. Aerosp. Sci. 1960, 27, 653–658. [Google Scholar] [CrossRef]
- Tartaglia, V.; Innocenti, M. Game theoretic strategies for spacecraft rendezvous and motion synchronization. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, San Diego, CA, USA, 4–8 January 2016. [Google Scholar]
- Li, Z.Y.; Zhu, H.; Yang, Z.; Luo, Y.Z. A dimension-reduction solution of free-time differential games for spacecraft pursuit-evasion. Acta Astronaut. 2019. [Google Scholar] [CrossRef]
- Sarma, I.; Ragade, R.; Prasad, U. Necessary conditions for optimal strategies in a class of noncooperative N-person differential games. SIAM J. Control 1969, 7, 637–644. [Google Scholar] [CrossRef]
- Dickmanns, E.D.; Well, K.H. Approximate solution of optimal control problems using third order Hermite polynomial functions. In Proceedings of the Optimization Techniques IFIP Technical Conference, Novosibirsk, Russia, 1–7 July 1974; pp. 158–166. [Google Scholar]
- Stoer, J.; Bulirsch, R. Introduction to Numerical Analysis; Springer: New York, NY, USA, 1993. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- NSGA—II: A Multi-Objective Optimization Algorithm. Available online: https://www.mathworks.com/matlabcentral/fileexchange/10429-nsga-ii-a-multi-objective-optimization-algorithm (accessed on 19 July 2009).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 | |
| 1 | 0.9 | 0.8 | 0.7 | 0.6 | 0.5 | 0.4 | 0.3 | 0.2 | 0.1 | 0 |
| Parameter | Pursuer | Evader | Defender |
|---|---|---|---|
| 0 | 12 | 6 | |
| 0 | 16 | 8 | |
| 20 | 0 | 10 | |
| 0 | 0 | 0 | |
| 0 | 0 | 0 | |
| 0 | 0 | 0 |
| Parameter | Pursuer | Evader | Defender |
|---|---|---|---|
| 15.24 | 15.28 | 10.24 | |
| 17.44 | 17.68 | 11.72 | |
| −2.098 | −2.363 | 4.87 |
| Parameter | Pursuer | Evader | Defender |
|---|---|---|---|
| 0 | 8 | 18 | |
| 0 | 9 | 24 | |
| 30 | 12 | 0 | |
| 0 | 0 | 0 | |
| 0 | 0 | 0 | |
| 0 | 0 | 0 |
| Parameter | Pursuer | Evader | Defender |
|---|---|---|---|
| 8.293 | 9.083 | 8.638 | |
| 8.804 | 9.609 | 9.026 | |
| 11.89 | 10.51 | 11.79 |
| Parameter | Pursuer | Evader | Defender |
|---|---|---|---|
| 8.384 | 9.069 | 8.714 | |
| 8.956 | 9.593 | 9.132 | |
| 11.81 | 10.51 | 11.68 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Zhao, L.; Cheng, J.; Wang, S.; Wang, Y. Pursuer’s Control Strategy for Orbital Pursuit-Evasion-Defense Game with Continuous Low Thrust Propulsion. Appl. Sci. 2019, 9, 3190. https://doi.org/10.3390/app9153190
Zhou J, Zhao L, Cheng J, Wang S, Wang Y. Pursuer’s Control Strategy for Orbital Pursuit-Evasion-Defense Game with Continuous Low Thrust Propulsion. Applied Sciences. 2019; 9(15):3190. https://doi.org/10.3390/app9153190
Chicago/Turabian StyleZhou, Junfeng, Lin Zhao, Jianhua Cheng, Shuo Wang, and Yipeng Wang. 2019. "Pursuer’s Control Strategy for Orbital Pursuit-Evasion-Defense Game with Continuous Low Thrust Propulsion" Applied Sciences 9, no. 15: 3190. https://doi.org/10.3390/app9153190
APA StyleZhou, J., Zhao, L., Cheng, J., Wang, S., & Wang, Y. (2019). Pursuer’s Control Strategy for Orbital Pursuit-Evasion-Defense Game with Continuous Low Thrust Propulsion. Applied Sciences, 9(15), 3190. https://doi.org/10.3390/app9153190