1. Introduction
Computer performance depends on how well the hardware components work together and interact as a whole system. Continuously updating one part of the computer while preserving obsolete components will not lead to a significant increase in computer performance, if at all. Hereinafter, we survey some of the most important hardware components of a computing system regarding its efficiency and computing power. The description of these parts does not mean complete definition and serves only to give new users some idea of what the diver characteristics of computer performance mean. The central processing unit (CPU), the RAM, the bus, and the storage are the most important components in determining performance inside a computer. The degree of compliance of the system with its purpose is called the efficiency (quality) of the system. For complex systems like computing systems, efficiency cannot be determined by one quantity, and therefore, it is represented by a set of quantities called system characteristics. The set of characteristics is formed in such a way that, on aggregate, they give the most complete picture of the effectiveness of the system [
1]. The main characteristic of a computing system is performance. The tasks of evaluating the effectiveness of the organization of computing systems are defined as mathematical objects, called system parameters. As parameters, values are used that determine the number and speed of devices, memory capacity, workload, etc., in fact, all objects that characterize the primary aspects of the organization of the system and significantly affect the characteristics.
Performance is a characteristic of the computing power of a system that determines the amount of computing work performed by the system per unit of time. Currently, there is no generally accepted method for assessing the performance of a computing system, which is primarily due to the lack of units for measuring the amount of computational work. Therefore, to evaluate the performance, a wide range of values are used—performance indicators—that both individually and in aggregate do not fully meet the needs of the theory and practice of designing and operating a computing system [
1].
Nominal performance characterizes only the potential capabilities of devices that cannot be fully utilized. This is hampered by the influence of the structure of communications between devices on their performance, which is manifested in a change in the speed of operation of some devices when others work. Therefore, due to the fact that the processor and I/O channels are connected to common RAM, an increase in I/O speed leads to an increase in processor performance; the total performance of I/O devices connected to the multiplex channel is limited by the channel bandwidth, the actual performance of the drives connected to the block-multiplex channel is less than their total nominal speed, etc. [
2,
3]. To evaluate the influence of the first group of factors—the system structure on the performance of devices—a special characteristic is used: complex performance. Complex performance is estimated by the set of speeds of the devices provided by their joint work. There are a lot of ways to assess integrated performance. One approach to its assessment is as follows. In some way, a typical mixture of input operations, access to external memory, processing and output of data is determined, based on which, a synthetic artificial program is created that generates a process with a given mixture of operations. By running a synthetic program and measuring its runtime, the integrated system performance is estimated [
4].
The influence between the systems is manifested, for example, in the following. The organization of system input and output is associated with the use of a processor and external storage devices for intermediate storage of input and output datasets. As a result, part of the processor time, I/O channels, and external storage devices are spent on I/O service. The same situation arises when organizing a virtual memory system, time-sharing mode and providing other auxiliary functions. For computing systems that are in operation or are being developed for a specific application, the class of tasks is fully defined, at least statistically. That is, the workload of the computing system is determined. In this case, performance is evaluated on the workload and is called system performance [
5]. It is mainly the number and speed of devices, the capacity of RAM and external memory (with an increase in performance if these factors increase), as well as the structure of the system and the bandwidth of connections between the elements of the system that have the most significant effect on performance. The performance of a computing system is manifested, on the one hand, in the speed of processing tasks, and on the other, in the degree of use of system resources. The more resources are loaded, the higher the system performance, and underloading of resources indicates the presence of reserves to improve performance. Therefore, when analyzing system performance, not only are performance indicators evaluated, but also indicators characterizing the use of resources.
1.1. Motivation
There are three main objectives to evaluate computer states: computer selection, computer designing, and configuration enhancement [
6]. In all these fields, the goal is to optimize the response of the actual or projected system to the actual or predicted workload. Assessment of the state of computers is attempting to define how well a particular system corresponds or can satisfy certain processing requirements for data or planned resources. There are several available assessment methods, the bulk of which are appropriate to some of the objectives, for instance, synthetic programs and benchmarks are considered the best evaluation methods. However, these evaluation techniques are not based on an analysis of real data taken from the existing real systems. All fuzzy based CPU utilization predictive models are based on tendency and previous workload states [
7] or consider historical data of CPU (cores, response time), memory (reading, writing, swapping time, queue), bus (I/O throughput, latency), etc., that are too long. Moreover, each object has a variety of pointers (time, workload, frequency, and percent) that complicates the evaluation task. However, all of the above methods are complicated despite a good result. Many of them require data that are difficult to obtain for each user and require special programming skills, such as machine learning algorithms, reference datasets for evaluating performance and in-depth knowledge of computer architecture. Moreover, the results of evaluating the performance or resource utilization presented by the approaches discussed above are not fully understandable to the user. Based on the explanations above, it is necessary to simplify and convert all data types to unequal metrics, i.e., linguistic variables using fuzzy set theory. This paper aims to build an evaluation model for any type of computer systems from personal computers to large mainframes and supercomputers that can be used by non-professional users who have no analytical knowledge about hardware components. The proposed model should evaluate the state of the computer system, CPU utilization, determine the incompatibility and bottleneck of hardware components and predict the CPU utilization in given condition cases.
1.2. Related Work
The related work in this field has been done by different simulations, environment and performance tools. In various studies, analysts have considered the following factors while evaluating the computer performance: waiting time, load balancing, number of requests, the throughput and rate of transactions. These computer performance factors were evaluated by many approaches. We classified them as fuzzy set theory based and machine learning (prediction) based approaches.
1.2.1. Fuzzy Set Theory Based Approaches
Butt et al. [
8] have developed a fuzzy decision-making system to improve the CPU scheduling algorithm in a multitasking operating system. They used a new formula to calculate the recent CPU utilization by each process. In addition, the algorithm maintains time intervals and recalculates the dynamic priority of the processes upon the arrival of the high-priority process and after the allotted time of the process. They have developed the simulator so that it takes the packet time, the finished value and the arrival time of each finished process as input. Then, the simulator calculates the recent CPU utilization of each process using the formula. A FIS generates a fuzzy dynamic priority (dpi) for each process. In accordance with the dpi of each process in descending order, the process at the head of the queue is selected to run on the processor. The proposed performance evaluation method by Jung et al. [
9] measures the online computer systems using the modeling occurrences of failed computer hardware units based on fuzzy set theory. In this method, it is mandatory to use subjective possibilities and probabilities when there is not enough information about some parameters of a model. Information can be obtained subjectively from experts or very little data. They present the fuzzification model and performance evaluation of online computing systems with failure based on fuzzy set theory [
9]. Suzer et al. [
10] proposed and developed a fuzzy controller for utilization management. Their developed fuzzy controller can easily adapt its control actions, i.e., rules that consider the real-time system behavior. This means the controller could manage the system workload.
A self-adaptive algorithm for predicting the cloud resources using a fuzzy neural network has been proposed by Chen et al. [
11]. They used the combined algorithms of Fuzzy C-means and the subtractive fuzzy clustering algorithm to optimize the characteristics of convergence and learning speed. Their fuzzy neural network learning algorithm is optimized using a self-adjusting learning rate and impulse weight, which improves reliability and performance in real time. Beghdad et al. [
7] proposed an approach aiming to develop a model one step before CPU utilization prediction based on the clusterized selection of instances in the past steps. Proposed adaptive network-based fuzzy inference (ANFIS) predicts using the Naive Bayesian Network controller. They used the C-means clustering method, which estimates the next step direction in the time series. The second proposed approach by Beghdad et al. [
12] shows the future of CPU usage prediction based on a mixture of ANFIS models to compute short-term accuracy and mid-term reliable prediction. Sh. Javad [
13] presented an attempt to apply neuro-fuzzy in the development and realization of a rule-based planning algorithm to eliminate the disadvantage of known planning algorithms. The decision maker on the basis of fuzzy data was asked to calculate the new priority of all CPU processes in accordance with the priority of the process and the time of its execution.
1.2.2. Machine Leaning Based Approaches
Mason et al. [
14] proposed an evolutionary neural network to predict host CPU utilization using several different recurrent neural networks. The authors used a dataset that used PlanetLab files and three optimization algorithms to optimize weights for RNN, namely: optimization of a particle swarm (PSO), differential evolution (DE) and evolutionary adaptation strategy of the covariance matrix (CMA-ES). Duggan et al. [
15] used a machine learning based approach for forecasting CPU utilization. They utilized a recurrent neural network trained using the algorithm known as backpropagation over time to predict host CPU utilization in the Google Cluster trace dataset. Kumar et al. [
16] developed a novel model for forecasting the workload of cloud data centers using LSTM networks. They tested the model using three benchmark datasets of HTTP traces of the NASA server, Saskatchewan server, and Calgary server. The proposed model achieved significant results. Their proposed model can perform a 60-min prediction of the workload of big datacenters.
Two methods for predicting the resource consumption were presented by Tan et al. [
17]. The first method predicts the resource usage for a specific node and uses both CPU and memory usage for its performance predictions. The second method focuses on a large number of nodes and the workload running on them, which is likely caused by a smaller number of jobs. Tan et al. [
17] proposed an approach based on PCA to predict processor and memory utilization in the commercial data center.
Datrois et al. [
18] proposed a method that uses machine learning algorithms that predict the 24-h availability of resources at the host level. Their predicting method is based on the employment of quantile regression to ensure an elastic composition between the potential amount of resources to reclaim and to define unused resources. Hardware components like the central processor, memory, storage, and network metrics have been predicted to ensure exhaustive availability is guaranteed. Sekma et al. [
19] have developed basic guidelines for developing an appropriate system for predicting the availability of CPUs for such computing infrastructures. They proposed a process for constructing a predictor that automatically checks the assumptions of vector autoregressive models in a time series. The authors performed three different past analyses, that is, the last hours, the same hours of the previous days, and the same weekly hours of the previous weeks. The suggested prediction model uses a multi-state prediction method to select a corresponding predictor.
2. Proposed Method
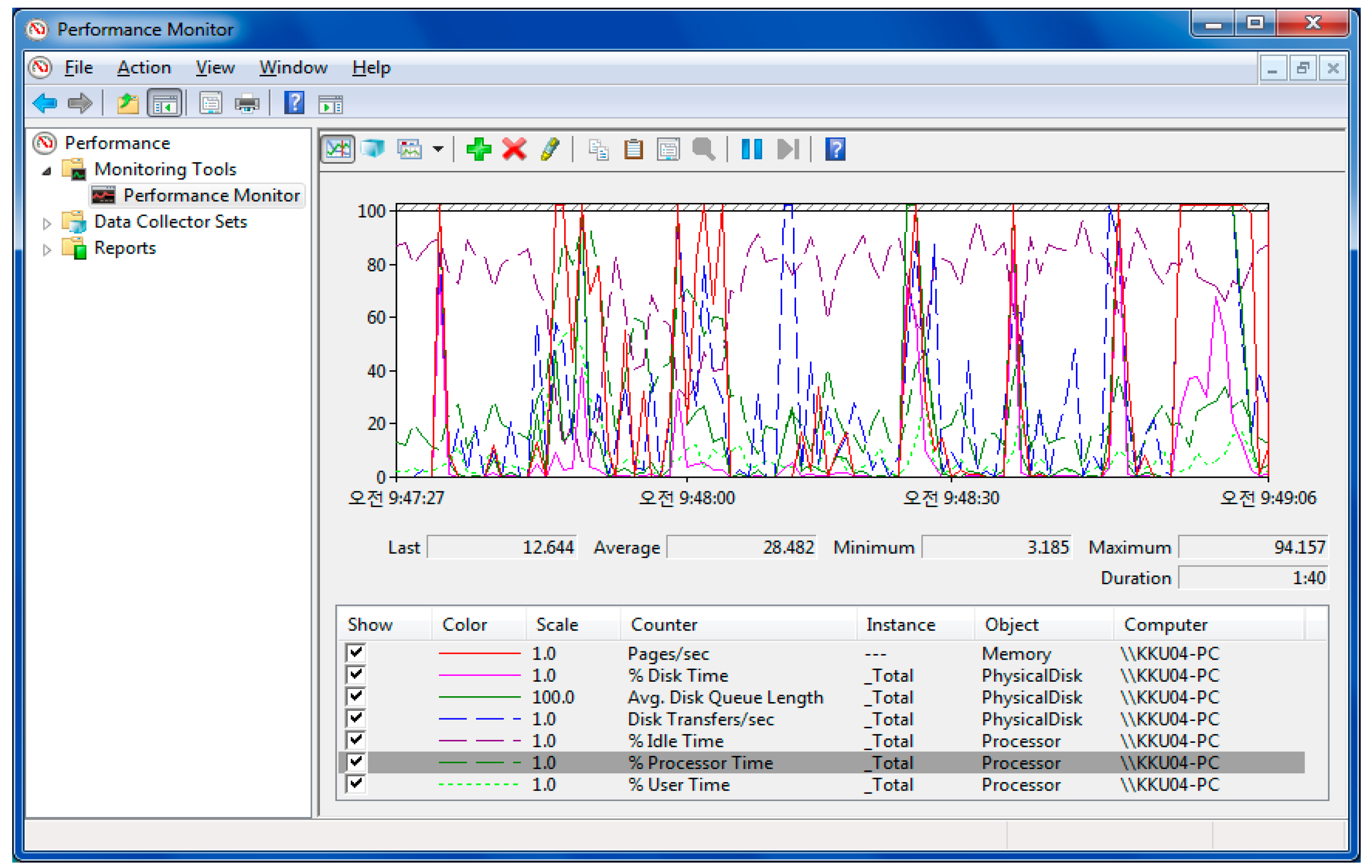
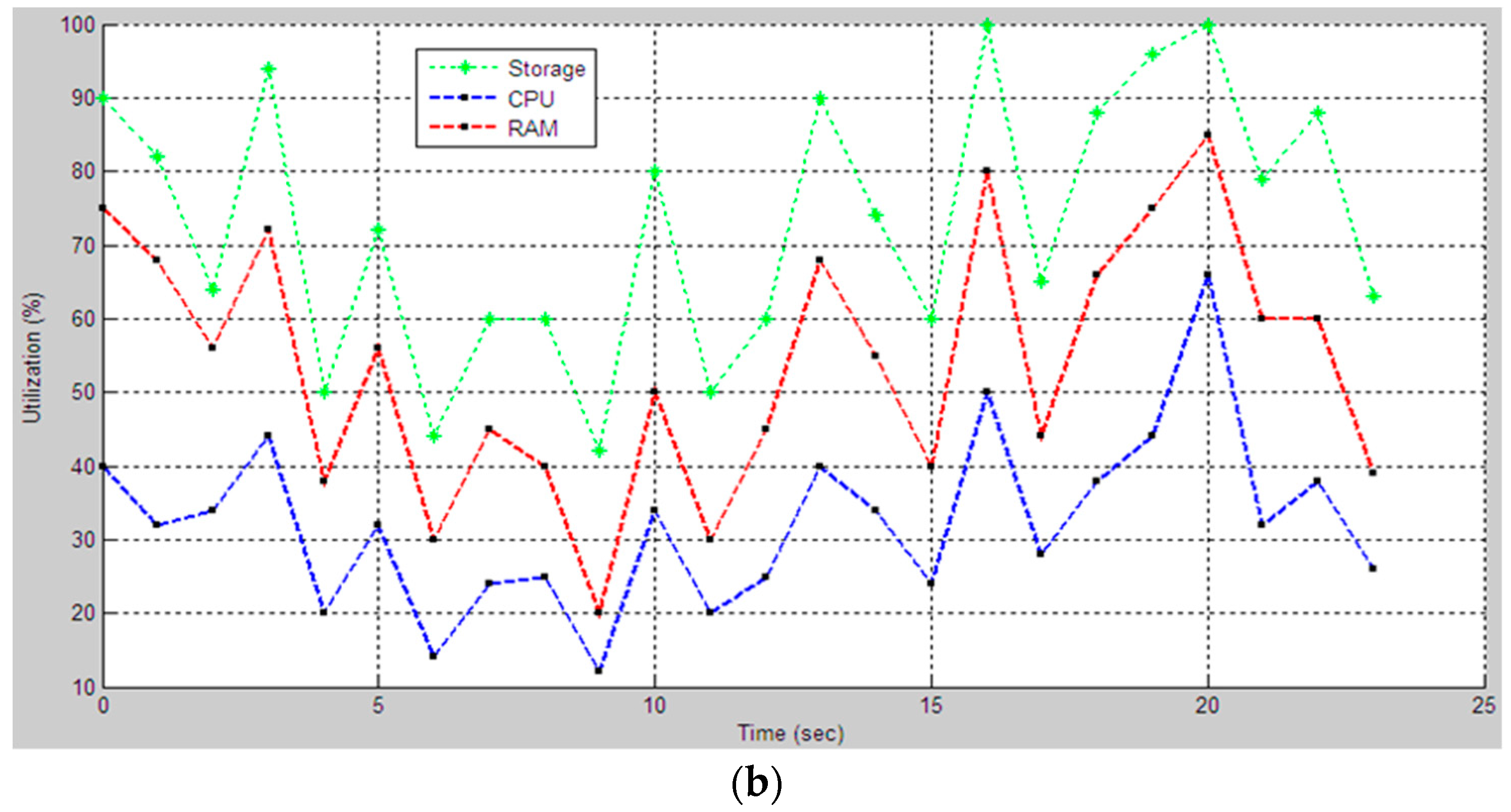
This paper aims to apply fuzzy logic theory to evaluate the CPU utilization by including the impact of RAM and storage utilizations to the CPU performance, while simultaneously running multiple applications processing. We used the system monitor (perfmon.exe) of the operating system to collect the performance data of hardware components, which are the processor time, swapping(pages), and disk time characteristics, accordingly CPU, RAM, and storage utilization information. During the monitoring, we built a dataset of RAM, storage and CPU utilizations from the test-bed computer. The view of the dataset is shown in
Table 1.
A fuzzy expert system that uses human knowledge and their experience in this field to create linguistic descriptors for variables and to create fuzzy sets that allow the behavior of the studied phenomena to be controlled, or even as a tool for decision making [
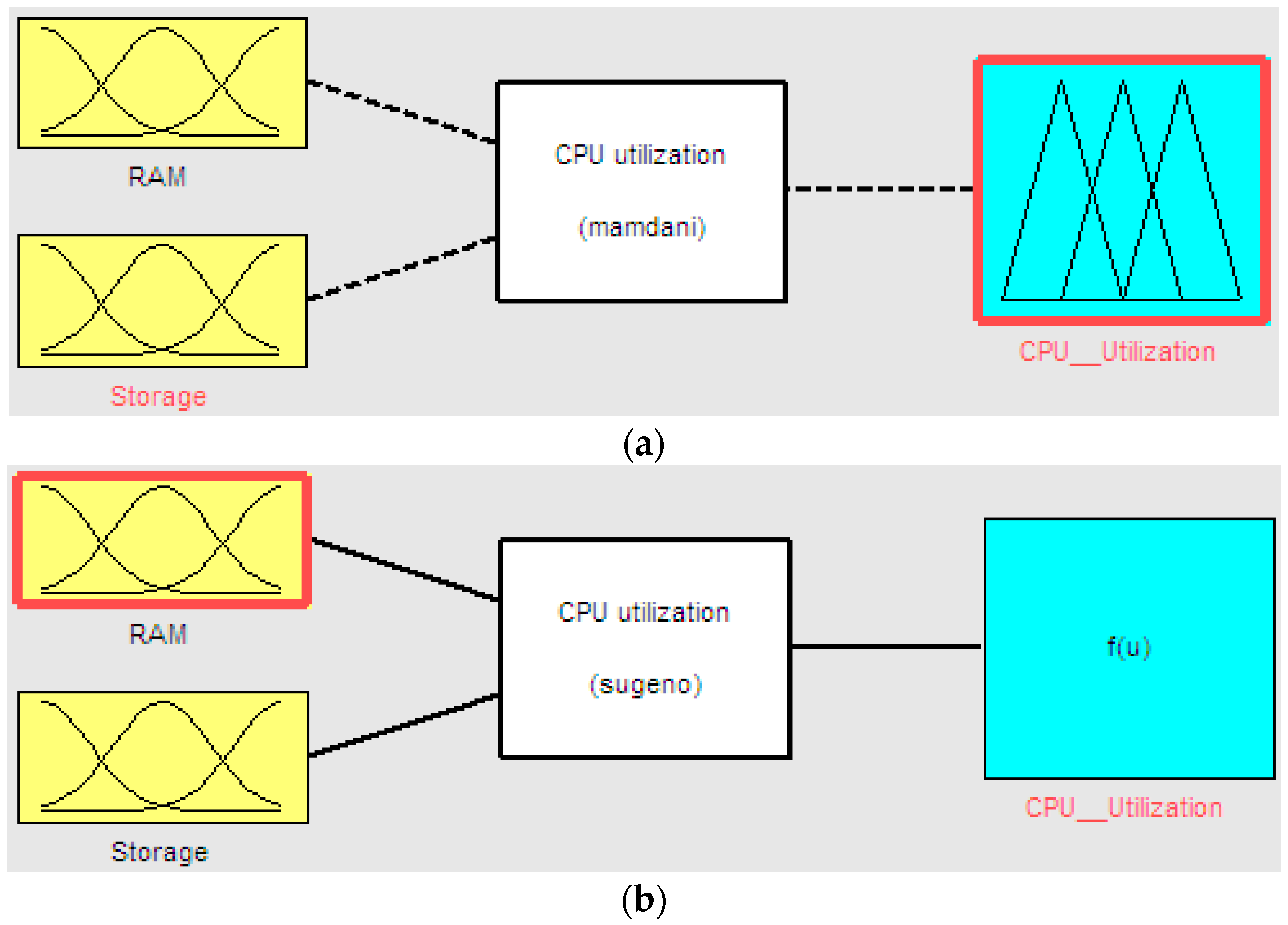
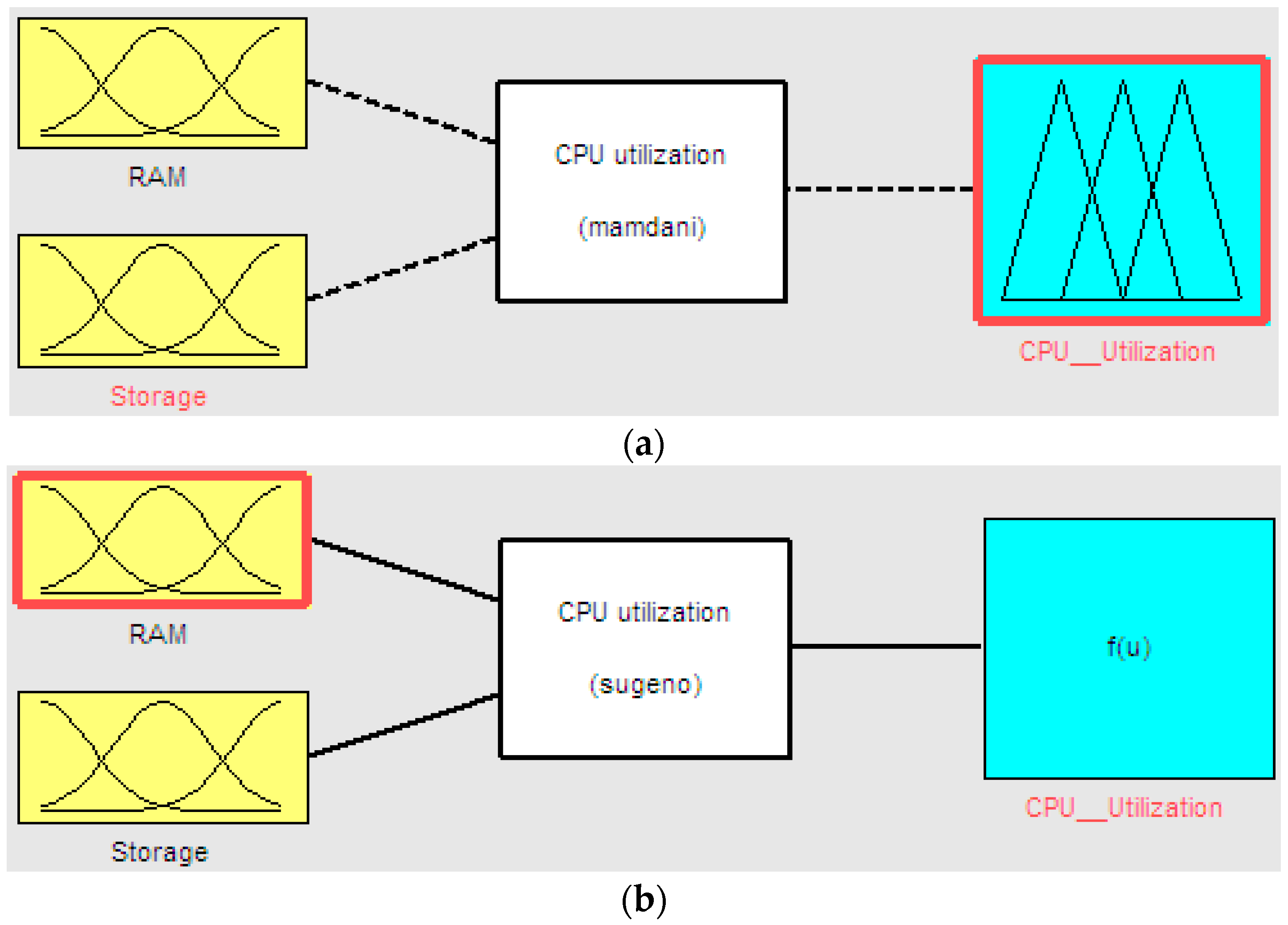
20]. In this work, we developed two types of FIS model (Sugeno and Mamdani) to evaluate the CPU utilization status by considering the influence of memory and storage utilization on CPU utilization. The difference between the FIS models are knowledge base and output, i.e., the Sugeno FIS uses a database and outputs quantity value of CPU utilization and the Mamdani FIS uses a rule base and performs linguistic value on the utilization state of CPU, like low, normal or high.
The architecture of the proposed fuzzy inference system is shown in
Figure 1. The model contains fuzzification, knowledge base, inference engine, and defuzzification modules. The algorithm of the fuzzy inference system is described in Algorithm 1.
| Algorithm 1. Algorithm of Fuzzy inference system |
Definition of linguistic variables Construction membership functions Construction knowledge base (rule base and database) Fuzzification crisp input values Training and evaluation knowledge base Combining the results of each rule Defuzzification non-fuzzy output values
|
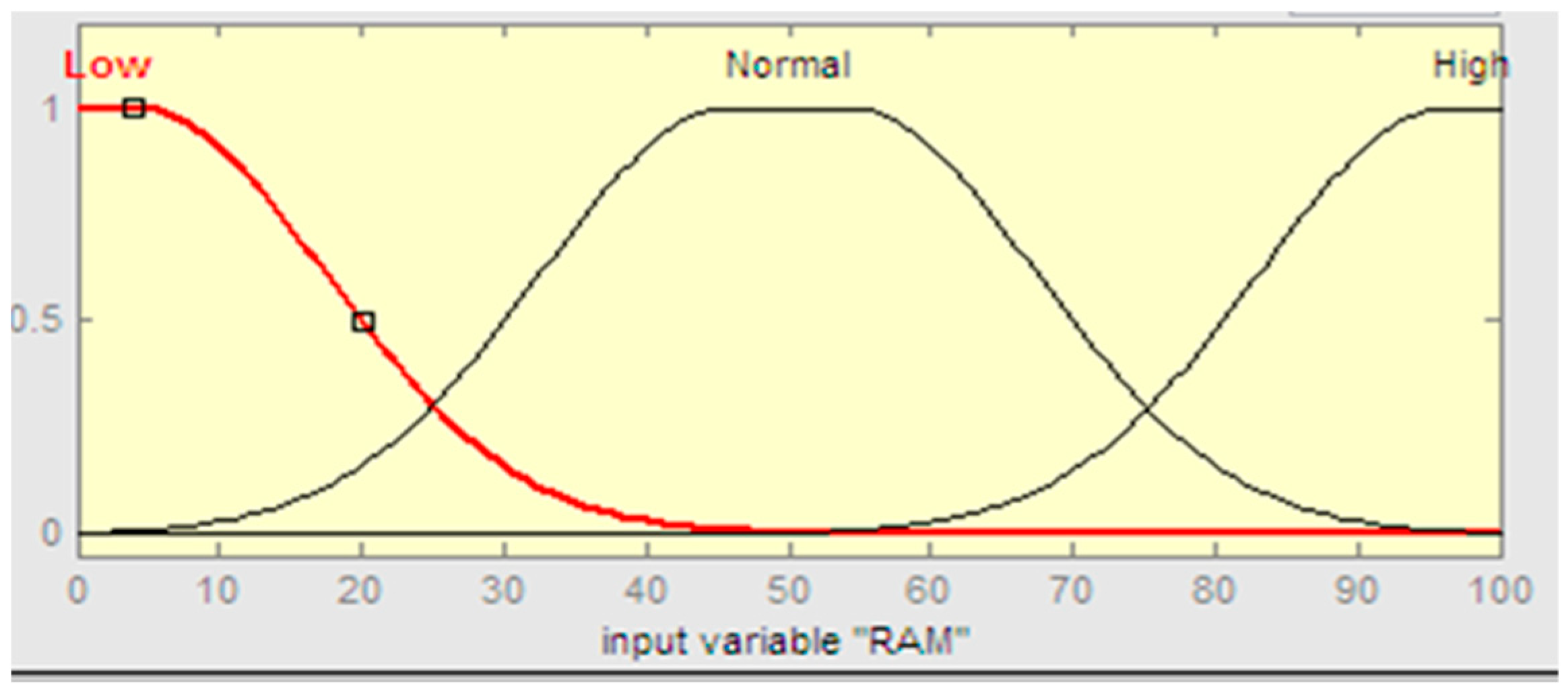
The fuzzification process is the first step in the fuzzy inference system. The crisp input values of RAM and storage are converted to fuzzy inputs by a fuzzification module, which assigns the degree of membership to fuzzy sets defined for variables. We used the Gaussian membership function for the fuzzy set as shown in
Figure 2 and Equation (1).
Equation (1) shows that c represents the center and
determines the width of the membership function. In
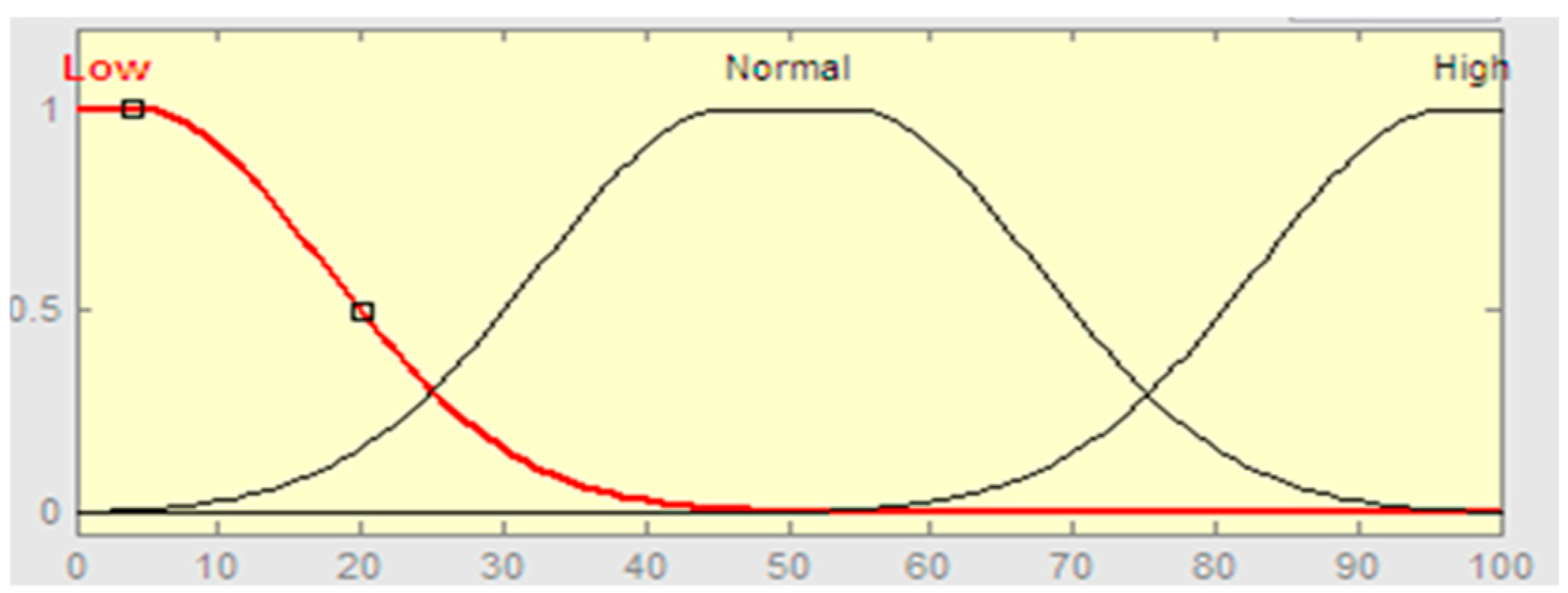
Figure 2, the described membership function with the “normal” linguistic term defined by the function of Gaussian (x; 50, 25). This means that the center of membership function 50, where the function reaches the maximum value 1. Equation (1) uses all input and output variables to make membership functions.
A fuzzy inference engine can draw conclusions or predict the results of a system using a knowledge base. In the proposed FIS, the inference engine is based on a set of IF-THEN rules. As aforementioned, we developed two types of FIS. These are the Mamdani FIS and the Sugeno FIS. Our proposed Mamdani-type FIS is implemented by the following steps:
Fuzzification input crisp values
Built fuzzy rules
Finding outcomes of the rules by combining the rule strength and output
Get output distribution by combining the outcomes
Defuzzification of the output
The inference engine steps of the Sugeno model are almost the same as these steps, but the Sugeno FIS generates rules by a training process. Training occurs using the database, which is illustrated in
Table 1. After training, the model builds optimal weights for prediction CPU utilization.
The detailed process of the Mamdani and Sugeno inference engine is illustrated in
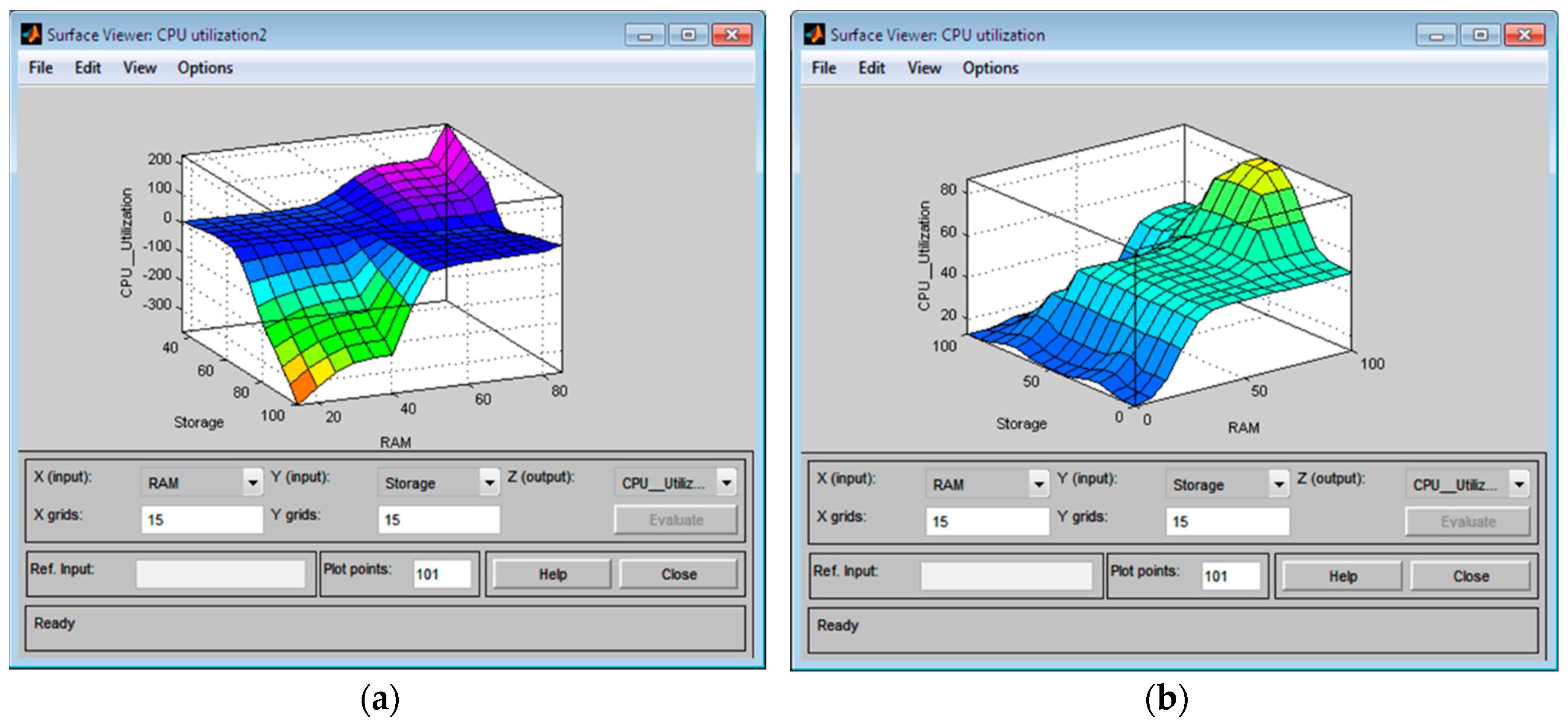
Figure 3. In Equations (2) and (3) we define two rules using two inputs (the full rule base is described in Figure 8). In these equations, RAM and storage are fuzzy values. Two inputs are fuzzified by applying an intersection on the crisp input values using a membership function. We used the “and” operator for combining two fuzzified inputs to obtain the rule strength. The Mamdani and Sugeno inference engine uses a membership function for each rule and then, according to the condition of the rule, reaches a conclusion.
In the last step, the defuzzification module converts the resulting fuzzy output, that is, the Sugeno FIS outputs crisp value and Mamdani FIS outputs linguistic value on CPU utilization. Here the scalar value of the fuzzy system is fuzzified, the rules are applied, the training model is built, and each rule generates fuzzy outputs and converts them to a scalar quantity. We used the centroid defuzzification method for the Mamdani FIS and the weighted average defuzzification method for the Sugeno FIS as shown in
Figure 3.
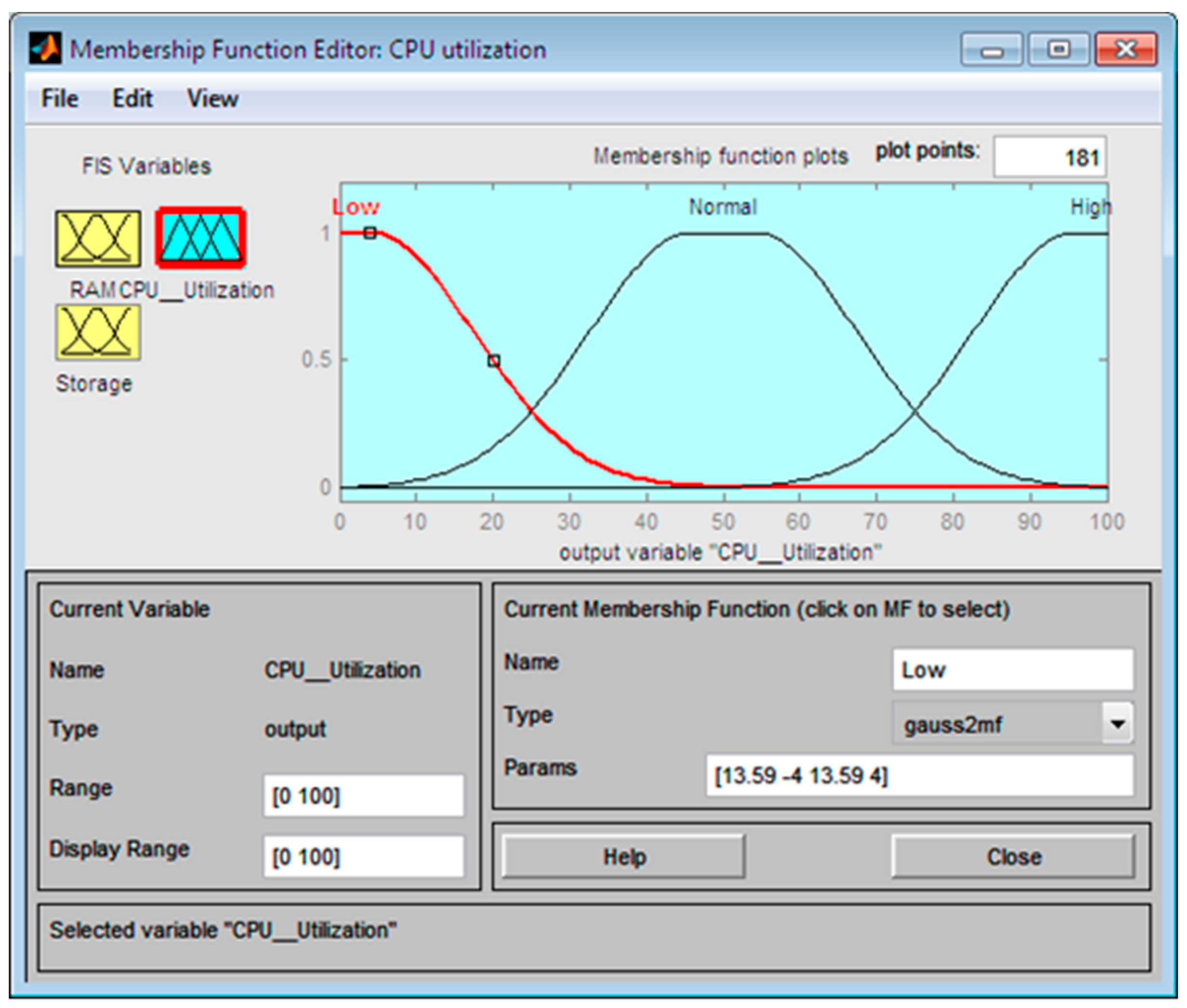
The linguistic variables like low, normal and high are the criteria for evaluating the CPU, RAM, and the storage represented in the linguistic descriptors as the value ranges. For example, the variable CPU has a range of values from 0 to 40, which is considered “Low”, from 20 to 80 is considered “Normal”, and from 60 to 100 is considered “High”. “Low”, “Normal”, and “High” are linguistic descriptors for the value sets for all variables of CPU, RAM, and storage.
As in principles of the fuzzy theory, sets of values overlap, and thus a value may partially belong to the set and have a membership degree of 0 ≤ µ ≤ 1, which can be any point between zero and one, where µ represents the degree of membership [
21]. Consequently, the value belongs to several sets, and the total membership is added to one. The linguistic descriptors “Low” and “Normal” are two fuzzy sets of CPU variables that can overlap, so a CPU of 20 can be mostly “Low” with μ = 0.7 and somewhat “Normal” with μ = 0.3.
Thus, the fuzzy system converts the crisp input values into fuzzy inputs through a fuzzification block, which sets the degree of belonging to fuzzy sets for previously defined variables. The fuzzy system then uses a rule base developed by a human expert to predict a fuzzy inference of the phenomenon under investigation, as a result of which the fuzzy system has a defuzzification block that converts the fuzzy output to a crisp value. In this work, we built a fuzzy inference system with two crisp input variables and one output as shown in Figure 6.
4. Discussion and Conclusions
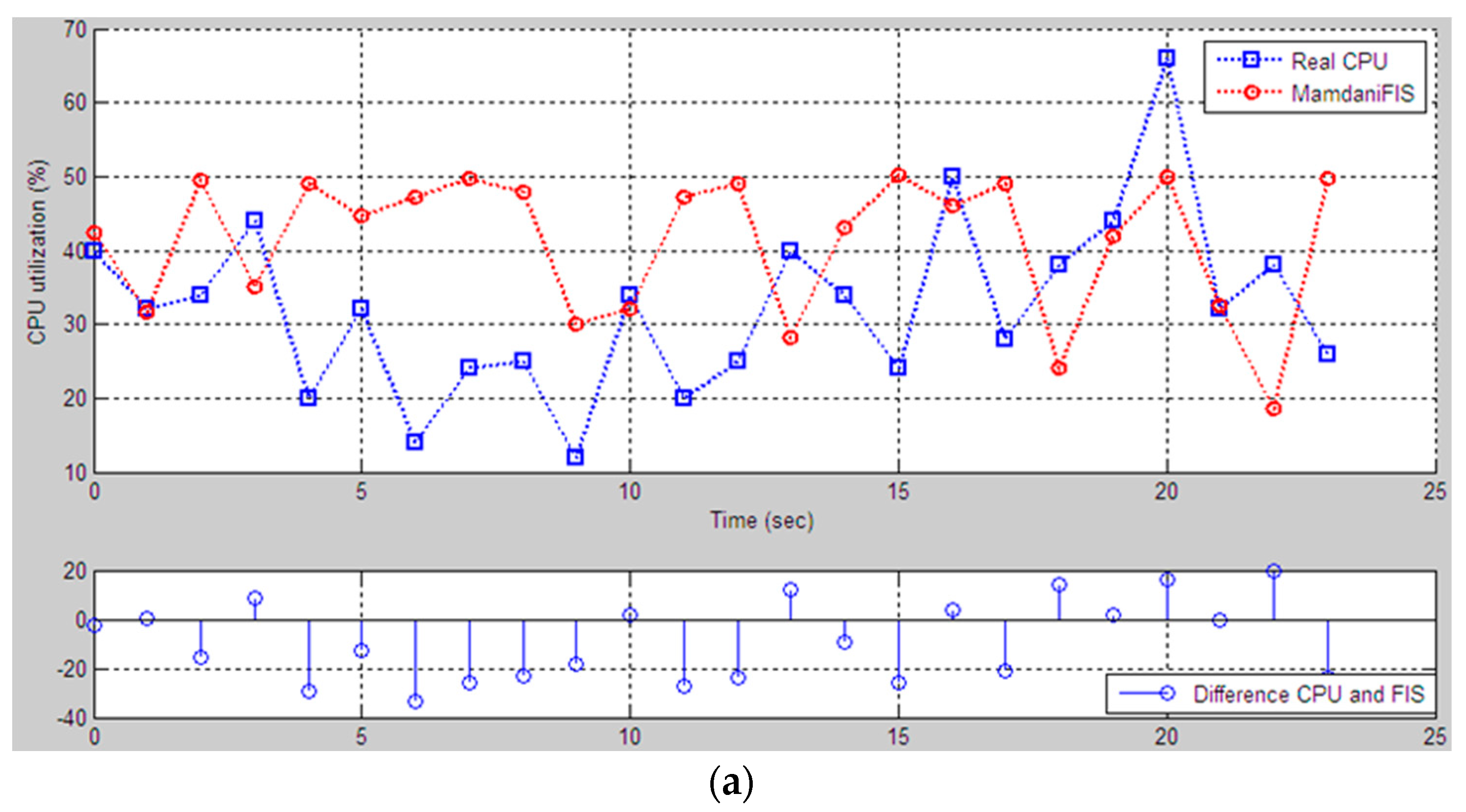
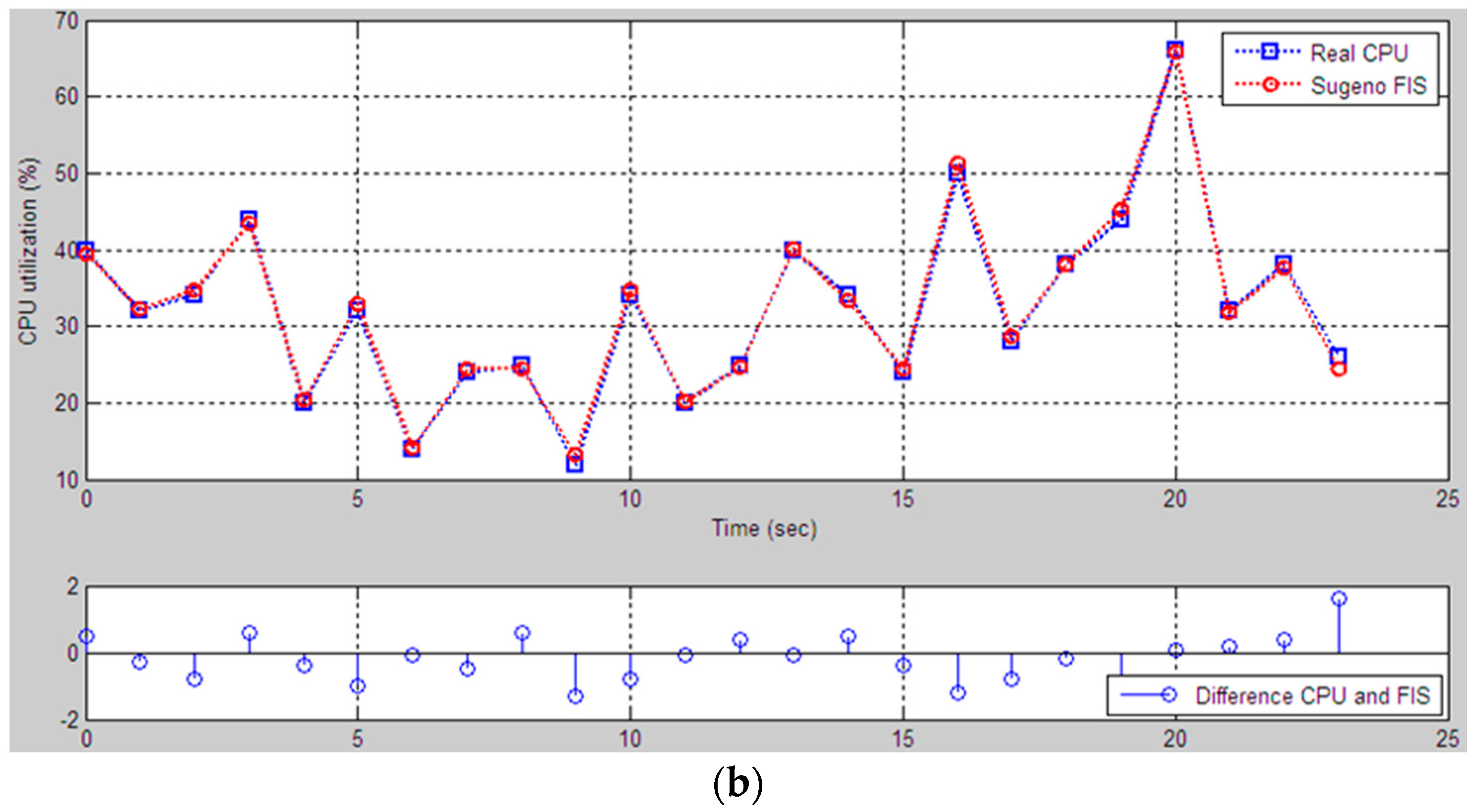
The proposed fuzzy logic model for CPU performance evaluation is based on certain parameters that broadly represent the usual parameters like average workload percentage related to memory and storage. We have made the assumptions that the RAM and storage incorporate all the basic factors involved in computing system infrastructure, i.e., CPU load. The fuzzy logic system was used to define the rules for evaluation. An artificial neural network, some simulated environment or the real data values from the computing system were used to evaluate the performance. This fuzzy logic system is beneficial for those who are only learning about computer performance and how to evaluate hardware utilization. Computational experiments were conducted based on a neuro-fuzzy approach, to assess the impact of loading a physical disk and RAM on the processor state. The components of the input data are defined as term sets of the type low, middle, and high. The obtained results of computational experiments allow us to interpret the characteristics of computing systems in a linguistic form, i.e., in the natural language form, which is close to the judgment of specialists, which will significantly speed up the decision-making process. In this paper, the results are not compared with the result of benchmark experience data because the knowledge base was built in an individual testbed computer, i.e., the concept of our model requires an individual knowledge base. The generated rule base and data base cannot be used in the FIS model for evaluating the CPU utilization. We compared the results only with data that was received from the performance monitor. We did this comparison to show the reliability of the FIS models. Because the performance monitor shows only numerical data about hardware utilizations, the program does not analyze the influence between components. Our FIS models analyze the receiving performance data and then evaluate the CPU utilization. If data coming from the performance monitor and the FIS results are close to each other, then the model is reliable and we can use it to predict the CPU utilization and to define the compatibility of components. The approach can be applied to personal computers, large mainframes, and supercomputers, and centralized and distributed systems using the own knowledge base of all these systems. The security issues and privacy concerns are assumed to be in a separate dimension; just the performance-affecting factors are involved in the logical modeling.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}