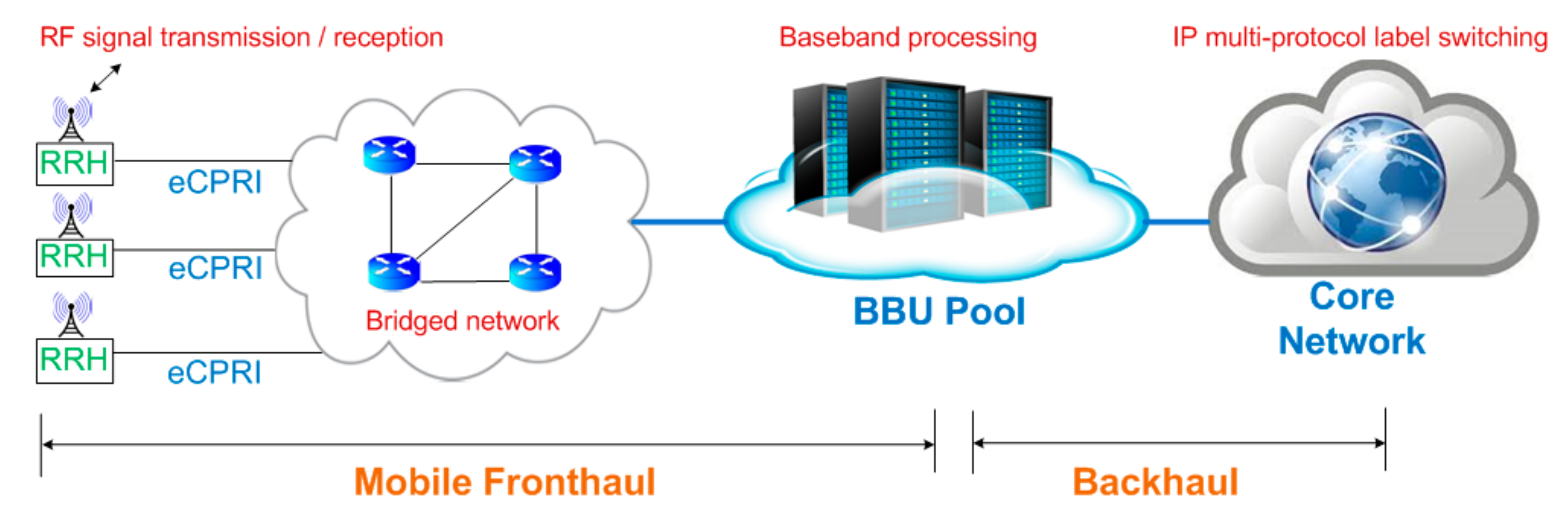
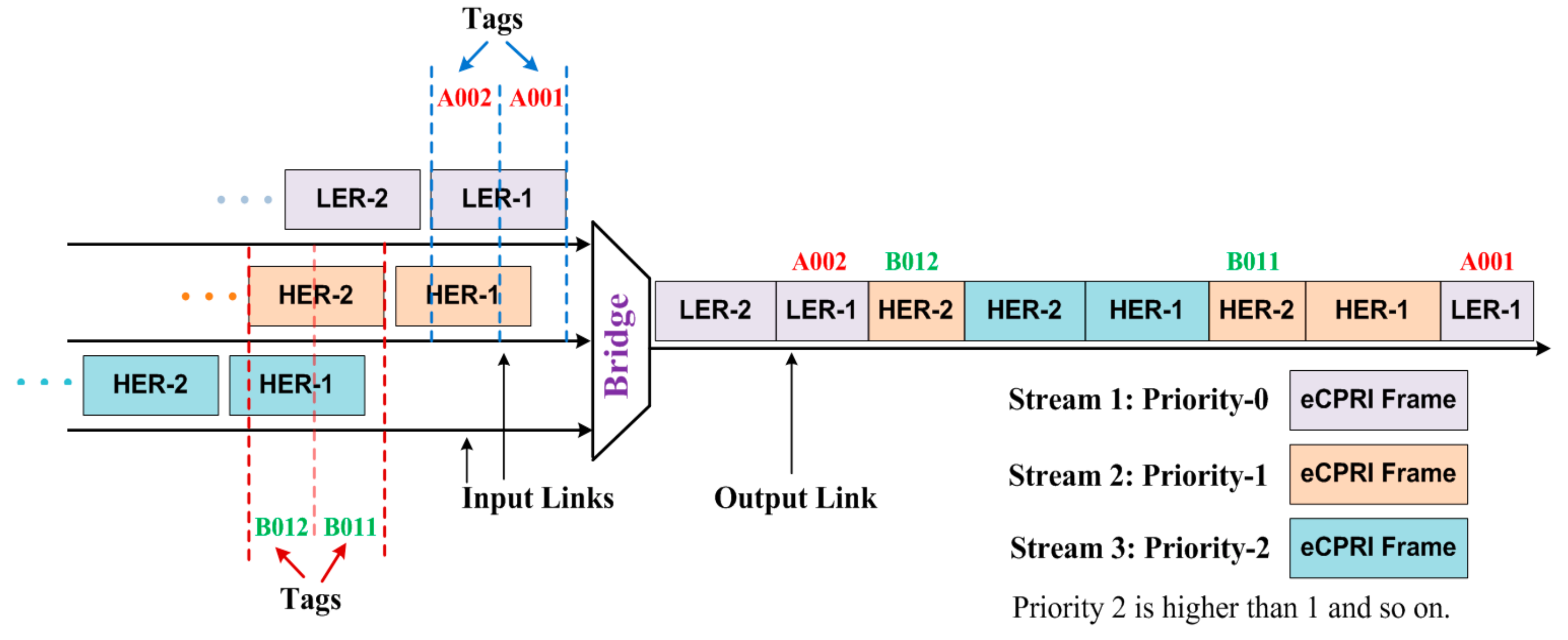
1. Introduction
According to a recent prediction [
1], the mobile data traffic will increase 10 times from 2017 to 2022, and more than 50 billion devices will be connected to the existing infrastructure by 2020. A transition from the static radio access networks (RANs) to flexible and reconfigurable networks through the virtualizations and cloudification was highly desirable to anticipate the traffic demands of future 5G cellular networks. Recently, cloud radio access networks (C-RANs) have been proposed, which are enhancements of classical RAN architectures through the cloudification and virtualizations techniques to comply with the requirements of envisioned 5G mobile networks. In C-RANs, the base station functionalities are split into distributed units known as the remote radio heads (RRHs) and central units known as the baseband units (BBUs), which are virtualized and pool at a central cloud [
2]. The C-RANs approach brings several advantages for the network operators, including a reduction in the operational, management, and energy costs, as well as effective implementations of the coordinated multipoint (CoMP) transmission and reception schemes for the inter-cell interference mitigations [
3]. With the virtualization of base station functionalities, the scalability of RAN architectures has been improved, and the spectral efficiency of the operator’s network can be increased. Furthermore, a number of RRHs can be installed at the cell sites by simply connecting with the BBU pool, which reduces the cost of deploying expensive baseband processing units nearer to the RRHs at the cell sites [
4].
The 3rd generation partnership project (3GPP) [
5] defined the eight functional splits for the C-RANs in order to connect the RRHs and the BBU pool. A chosen functional split uniquely defines the properties of the system design such as the complexity, costs, latency, data rates, throughputs, and achievable statistical multiplexing gains. In a low-level functional split, which has the maximum benefits of performance and cost efficiency, all the higher layer functions are moved into the BBU pool, and only the radio frequency (RF) functions are employed in the RRHs at a cell site [
6]. This requires a high-speed communication link between the RRHs and the BBU pool, which is referred to as the mobile fronthaul (MFH). The fronthaul segment is connected to the core network through the backhaul links [
7].
Figure 1 depicts the considered MFH networks of the C-RANs architecture.
A MFH carries the digitized in-phase and quadrature (IQ) samples of baseband signals through the common public radio interface (CPRI) [
8]. The CPRI is a non-packetized protocol that was specifically designed for the fronthaul networks by the leading telecom vendors, and cannot be integrated with other packetized transmissions unless a circuit (e.g., a wavelength) is reserved for it [
9]. In this work, we consider a recent evolution of CPRI that is eCPRI (enhanced-CPRI) [
10], which can packetize the IQ samples within Ethernet frames and is fully compatible with Ethernet systems. The eCPRI-based MFH networks are expected to deliver the throughputs of 10 Gbps, packet delay variations (PDVs) within 100 ns, and end-to-end (E2E) latency of less than 250 μs for all the RRHs streams [
11,
12]. The aforementioned requirements can only be fulfilled with the expensive and extremely high-capacity optical links. However, the cost of deploying such optical fronthaul bridged networks significantly increased the capital expenditure (CAPEX) and operational expenses (OPEX) for the network operators. As a result, the cost benefits of the C-RANs architecture could not be realized [
13]. Thus, the implementation of low-cost MFH becomes a challenging issue in the C-RANs [
14].
The 10 gigabit Ethernet systems can be more economical and remunerative solutions as compared to the optical networks to carry the eCPRI traffic in the MFH. Moreover, Ethernet supports the virtualization techniques and OAM (operations, administration, and management) functionalities, which make them more suitable to connect the RRHs with the BBU pool through the fronthaul bridged networks. However, the Ethernet networks that use the legacy quality of service (QoS)-aware routing [
15] and packet forwarding schemes [
16] yield the per-hop latency of about one millisecond and PDVs of up to hundreds of microseconds, which are much higher than the eCPRI traffic requirements [
10,
17]. A major cause in Ethernet systems for not complying with the eCPRI requirements is the non-consideration of frame-level queuing delays at the bridging nodes, which are caused by the globally synchronized eCPRI bursts flowing to and from the RRHs at different line rates. Despite the utilization of the QoS-aware forwarding schemes in the optical fronthaul bridged networks, the queuing delays among the burst of eCPRI streams are high, which increases the E2E latencies to an unacceptable level [
18]. The queuing delays and E2E latencies become more critical in capacity-constraint Ethernet-based fronthaul bridged networks (EFBNs) [
13]. For enhancing the capability of economically affordable and ubiquitously deployed Ethernet networks to transport the eCPRI streams at tolerable latencies, a novel packet forwarding mechanism that would efficiently utilize the limited Ethernet bandwidths and yield the low queuing delays at intermediate bridges is vital. Therefore, this paper proposes the E2E latency-aware path selection and packet transmission schemes that guarantee the low queuing delays in the EFBNs and retain the E2E latencies of maximum eCPRI streams closer to the threshold by taking advantage of the virtualization and OAM capabilities of the Ethernet systems. The proposed latency-aware path selection scheme assures the lowest E2E latencies in the fronthaul bridged networks by considering the frame-level queuing delays of eCPRI bursts. The proposed packet forwarding scheme mitigates the delays of eCPRI streams that experience high latency by slightly increasing the queuing delays of traffic streams that experience low latency. As a result, for all traffic streams, tolerable E2E latencies can be realized in the EFBNs. The computer simulations are undertaken on varied and realistic scenarios. The simulation results confirmed that the proposed schemes maximize the simultaneous transmissions of eCPRI streams of up to 100 Gbps without violating the QoS requirements as well as improve the link distances, whereas such performance is not guaranteed with the existing schemes. Moreover, the transmissions of time-sensitive eCPRI streams at tolerable latencies with the proposed schemes through the leveraging Ethernet links significantly reduced the CAPEX and OPEX of deploying extortionate optical links in fronthaul bridged networks. Hence, without hardware upgradations, the performance of low-cost Ethernet networks can be improved with the proposed schemes, which can be programmed at the intermediate nodes of the EFBNs using the OpenFlow protocols and software-defined networking (SDN) techniques [
19].
The rest of the manuscript has the following organization.
Section 2 introduces the state-of-the-art work on the CPRI and Ethernet-based fronthaul networks.
Section 3 formulates the measurement procedures for the end-to-end latencies and distances in the EFBNs.
Section 4 introduces the proposed transport schemes for the EFBNs.
Section 5 presents the simulation setup for evaluating the proposed schemes. The results of the proposed schemes and comparison with the existing techniques are presented in
Section 6. Finally, conclusions are provided in
Section 7.
2. State of the Art—Ethernet Based Fronthaul Networks
Due to prior investments and backward compatibility issues, the existing standard bodies are focusing on the Ethernet-based fronthaul implementations. Currently, the IEEE 1914.3 [
20] working group is investigating the techniques to encapsulate the CPRI samples within the Ethernet frames. This standard is also working on defining the techniques to improve the statistical multiplexing gains in the CPRI over Ethernet networks. The IEEE 802.1CM [
21] is striving to standardize the Ethernet-based fronthaul systems for transporting the eCPRI streams in bridged networks. This standard is in the process of defining the default configurations, procedures, and profiles to carry the time-sensitive eCPRI streams in the MFH at low latencies. However, no mechanism has been defined explicitly in the standards to compensate the constraints of queuing delays at bridges and simultaneously transport the multiple eCPRI streams in Ethernet-based fronthaul bridged networks by satisfying the latency requirements.
Recently, due to the cost–benefits of Ethernet networks over the eCPRI-based optical switching networks, several academicals research proposals have been submitted to carry the time-sensitive fronthaul traffic in Ethernet networks. Most of the initial studies addressed the delay, jitter, and throughput challenges of the fronthaul networks by implementing the priority schemes [
22] and packets scheduling [
23] protocols, which were initially proposed for time-sensitive networking (TSN). The study [
24] implemented the frames priority mechanism and traffic scheduling algorithm for the Ethernet-based MFH networks. This study shows that traffic priority can be effective in minimizing the delays in the Ethernet networks, but cannot fulfill the CPRI demands. The author claims that the queuing delays could be mitigated at switches with the traffic scheduling algorithm for a few CPRI streams. However, the parameters and configurations under which the results were obtained were not detailed in the paper. A performance analysis of passive optical networks (PON)-based fronthaul systems for long-range transmissions has been reported in [
25]. This study shows that PON systems could not fully satisfy the eCPRI requirements without several hardware upgrades. This study also proposed to employ an expensive erbium-doped fiber amplifier (EDFA) at selected locations of the networks for achieving the QoS parameters within the eCPRI requirements. It is suggested to use an EDFA before the BBU pool for the considered fronthaul scenario to comply with the eCPRI demands. The studies [
26] and [
27] discussed the traffic scheduling and buffering techniques for Ethernet switching systems to improve the multiplexing gains in the fronthaul networks while retaining the delays and jitter within the CPRI limits. These studies showed that the CPRI traffic flows can be transported through at maximum one or two Ethernet switching nodes without violating the CPRI requirements. However, these schemes become ineffective for retaining the E2E latencies within the limits in more realistic fronthaul bridged networks, which comprises several intermediate bridging nodes between the RRHs and the BBU pool.
The constraint-based and QoS aware routing schemes would be alternative solutions to manage the latencies in multi-hop Ethernet networks. Since then, these routing schemes have been well studied in the past few years to tackle the network constraints such as the cost, capacity, throughputs, and delays. Dijkstra’s shortest path algorithm that allocates the weights to different links, based on the available bandwidths and distances, has been studied in [
28] for TSN networks, which could be an efficient solution for the delay constraint routing problems. Mutual constraint-based routing procedures have been discussed in [
29] to fairly utilize the limited resources in the Ethernet bridged networks. In a study [
30], multipath routing schemes were expedited for performing the dynamical load balancing and improving the congestions in TSNs by monitoring and maintaining the various performance indicating parameters. However, the existing QoS-aware routing schemes focus on searching the feasible routes subject to single or multiple QoS constraints, and select the best routes with no consideration of the frame level queuing delays, which is the case in the fronthaul bridged networks due to the simultaneous transmissions of the globally synchronized eCPRI bursts. Moreover, a high control messages overhead with the legacy routing schemes [
31] due to the dynamic selection of the paths and continuous monitoring of the networking parameters further increases the delays, which makes them unsuitable for the E2E latency constraints of the EFBNs.
The study [
18] proposes a queuing model to improve the delays in optical fronthaul bridged networks. In this study, Nakayama et al. proposed a low latency routing (LLR) mechanism based on the Markov chain Monte Carlo (MCMC) method, which searches the paths for individual streams by considering the traffic load on the different links. This study showed that the legacy QoS-aware routing schemes such as the constraint-based shortest path bridging (SPB) [
32] become inefficient to satisfy the latency requirements in the MFH bridged networks, and schemes such as the LLR are required to satisfy the MFH requirements. However, the LLR scheme also yields intolerable E2E latencies, and becomes ineffective at complying with the eCPRI requirements once the traffic load increases to a certain level. This is because the LLR scheme uses a single path for transporting the time-sensitive flows, which are usually the shortest neighboring paths. Under the high load conditions, these alternative paths also get congested and cause intolerable E2E latencies for the eCPRI flows. Moreover, the LLR scheme lacks the mechanism to minimize the queuing delays of eCPRI streams of equal priority at the bridging nodes, which is highly desirable for alleviating the E2E latencies and successfully deploying the leveraging Ethernet-based fronthaul bridged networks in 5G cloud-RANs.
3. E2E Latency and Distance Formulation
The MFH networks require high multiplexing gains to efficiently implement the coordinated multiple point schemes in the C-RANs, which can be improved by increasing the aggregation of RRHs streams over the fronthaul links. However, the simultaneous transmissions of multiple eCPRI streams from the RRHs increased the E2E latencies to an unacceptable level, especially in the Ethernet networks [
24,
25,
26]. Currently, the eCPRI-based Ethernet networks are gaining the attention of network operators and telecom vendors due to their low-cost and reconfigurability features, but achieving the required E2E latency is still a challenging issue [
27] that requires further exploration. The E2E latency in such networks is the result of indeterministic and deterministic delays. The indeterministic delays such as the encapsulation delay
DelEncp, the queuing delay
DelQue, and the processing delay
DelProc vary non-predictably in the EFBNs, while the deterministic delays such as the propagation delay
DelProp and the transmission delay
DelTran are pre-determined.
The indeterministic delays such as the
DelEncp correspond to the mapping delay of the eCPRI IQ samples within the Ethernet payload at the bridging nodes before transmitting them over the outgoing links. In this study, the
DelEncp for 10-gigabit Ethernet networks is estimated between the 19 μs to 2 μs for mapping the eCPRI flows from line rate option 1 to 7 [
10], respectively within the Ethernet payload size of 1500 bytes [
26]. However, the
DelEncp only increases when the traffic flows first enter the Ethernet networks. Therefore, the
DelEncp values are only considered at the first level of the bridging nodes within which the RRHs are physically connected.
The
DelQue is the length of time for which the packets of different streams wait in the buffers of the bridges before transmissions. When the
f-th flow competes the
g-th flow for simultaneous transmission over the
n-th link, these flows are referred to as competitive flows [
18]. Hence, the worst-case
DelQue experienced by the
f-th flow over the
n-th link is calculated from Equation (1):
where
m is the maximum burst size of a flow, and
C is the link capacity, while
λ is the number of competitive flows [
18].
The
DelProc is the time that the switches take to decode the header of a packet to output them on the egress ports. The
DelProc value, including the OpenFlow-based forwarding table lookup delays per bridging node experienced by the eCPRI streams, is estimated as 1.5 μs for the considered networks [
27]. Thus, the indeterministic delays
Delindet in the EFBNs along a route can be calculated from Equation (2), and the deterministic delays
Deldet can be calculated from Equation (3). Here, the deterministic delays such as
DelProp are a measure of the time required for a frame to propagate from one node to the other. The
DelProp is equal to
d/
s, where
d is the link distance in km, and
s is the signal propagation speed in copper (i.e., 2 × 10
8 ms
-1). The
DelTran is the time taken by the physical layer at the source to transmit the packets over the link. In this study, the
DelTran is estimated as 1.2 μs based on
L/C, where
L is the data packet length (i.e., 1500 bytes), and
C is the channel data rate (i.e., 10 Gbps). Finally, the E2E latency of the
n-th eCPRI traffic stream that is carried by a fronthaul link between the RRH and the BBU pool is formulated using Equation (4):
Along with the latency, the distance of the fronthaul links between the RRHs and the BBU pool is another important performance indicating parameter for the EFBNs [
24,
25,
26]. The E2E latency limits the maximum distances in the EFBNs. For commercially deploying the cloud-RANs, improvement in the link distances between the RRHs and the BBU pool is essential. The distance (km) of a fronthaul link in the considered scenario is calculated using Equation (5):
where
Maxthreshold is the maximum allowed E2E latency (i.e., 250 μs) for the fronthaul link,
WE2Elatency is the worst-case E2E latency experienced by a stream over the fronthaul link that can be computed from the Equation (4), and
d/s is the propagation delay.
5. Simulation Setup
The proposed schemes are evaluated with MATLAB programs. To verify the generality of the schemes, we employed the network topologies COST239 and ARPA2 [
37], which are widely used topologies in evaluations of carrier networks [
36].
IEEE 1914.3 [
20] defines the two encapsulation techniques (namely structure-agnostic and structure-aware) to carry the CPRI/eCPRI streams by mapping in the Ethernet frames. In this work, we employed the structure-agnostic mapping scheme to encapsulate the eCPRI packets in the standard Ethernet frames. In this scheme, eCPRI packets are mapped in the Ethernet frames without the knowledge of framing protocols, while in structure-aware encapsulation, eCPRI packets are broken into antenna-carrier and control-data components to transport through the Ethernet switching nodes.
The RRHs connected to the bridging nodes are configured to support the different eCPRI line rates. The RRHs periodically transmit the eCPRI-based bursty traffic toward the BBU pool, which is independent of the end user’s data rate and reserves the MFH bandwidth, even when no user is connected with the RRHs. Each RRH is configured to support a single eCPRI line rate randomly from the eCPRI line rate options 1 to 7 such as 0.61 Gbps, 1.22 Gbps, 2.45 Gbps, 3.07 Gbps, 4.91 Gbps, 6.14 Gbps, and 9.83 Gbps, respectively [
10]. In contrast, an eCPRI line rate represents the number of IQ samples that an MFH link can transport between the RRH and the BBU pool [
11]. Based on the configured line rates, the RRHs could transmit 50 to 100 Gbps of cumulative eCPRI traffic toward the BBU pool. However, for generality, loads are randomly connected to the bridging nodes. This is because the distribution of RRHs is determined by the demand distribution in reality [
10,
18]. In the considered EFBNs, each RRH sends a burst of 9000 bytes after every 2 ms toward the BBU pool based on [
38] for the backward compatibility with the long term evolution-advanced (LTE-A) standards. The maximum size of the Ethernet payload is considered to be 1500 bytes.
The RRHs are connected to bridges through a link of 0.2 km length at the bandwidth of 10 Gbps. It is considered that all the bridges are located within an area of 20 km
2. The link distance between the consecutive bridges is randomly determined from 1 to 5 km similar to realistic networks [
18]. The link bandwidth between two bridges is considered to be 10 Gbps. In each topology, the BBU pool is connected to a node where a maximum number of links are connected. In the considered scenarios, the BBU pool is connected to the bridging node-3 and to the bridging node-7 in COST239 and ARPA2 topologies, respectively. The link bandwidth between the BBU-DN is assumed as 100 Gbps and the link length is assumed as 0.2 km.
Figure 4 shows the experimental setup to reflect the aforementioned configurations and parameters for simulating the fronthaul scenarios. As shown in
Figure 4a,b, the RRHs are configured to support the cumulative eCPRI traffic of approximately 50 Gbps and 60 Gbps for COST239 and ARPA2 topologies, respectively. Analogous to this, the cumulative eCPRI traffic loads of 70 to 100 Gbps are formulated during the simulations for both topologies by randomly connecting the RRHs with different nodes at different line rates. The link length between the RRH bridges and DN-BBU pool is considered as 0.2 km. The link lengths between bridges and bridges would be determined randomly from 1 to 5 km. The bandwidth of all the links is considered to be 10 Gbps except for the link between the DN and the BBU pool, which has 100 Gbps of bandwidth.
It is assumed that all the bridges of the fronthaul networks are capable of implementing the frame preemption principles and policies, as discussed in
Section 4.2. However, the frame preemption introduces a certain overhead for the preempted frames, which could impact the performance. Therefore, in order to realize the effect of preemption overhead in the EFBNs, the overhead per preemption is estimated as 124 ns, which is equivalent to the processing time of a 155-byte packet [
39]. In order to obtain the average of the results, we repeated the simulations 10 times for different topologies and traffic loads. Furthermore, the proposed work has been compared with the LLR scheme [
18]. This comparison is reasonable, because the LLR scheme is the most recent development on the given topic, and is considered to be one of the effective solutions to select the low-load paths in fronthaul bridged networks.
6. Results and Discussion
Figure 5a illustrates the average queuing delays experienced by the RRHs eCPRI streams for the COST239 topology while communicating with the BBU pool. The results showed that with the LLR scheme in the EFBNs, the average queuing delays increment as the incoming eCPRI data rates increase. This scheme resulted in the queuing delays up to 300 μs under the full load conditions, which are much higher than the required ranges of the fronthaul networks. The reason for the LLR scheme’s inefficiency is that this scheme managed the delays by selecting the neighboring paths of the shortest paths, and under the high-load conditions, congestions at the neighboring routes were also high, which resulted in high queuing delays and ultimately increased the latencies to an unacceptable level. Our proposed low-latency path computation scheme more efficiently minimized the queuing delays, even under the high traffic load conditions. As shown in
Figure 5a, the queuing delays with the LAPC scheme were reduced to 225 μs for 100 Gbps of eCPRI traffic. Further minimization of the queuing delays was realized by employing the proposed frame preemption concepts along with the low-latency path computation mechanism on the high-load paths. As shown in
Figure 5a, the frame preemption-based LLPF scheme, which was named the LLPF-FP, more adroitly alleviated the queuing delays and enabled transmissions of up to 100 Gbps of traffic while retaining delays of less than 200 μs. With analogy to COST239, similar trends for ARPA2 were shown by the proposed schemes, as depicted by
Figure 5b. The queuing delays for ARPA2 with the LAPC scheme were raised up to 265 μs for 100 Gbps of eCPRI traffic, while the LLR resulted beyond the 352 μs for the same load. This increment in delays is because of the increased in the propagation delays and the number of the bridges between the RRHs and the BBU in ARPA2 topology. However, the LLPF-FP scheme in ARPA2 topology retained the queuing delays for less than 248 μs, even when traffic load was high, which verifies the competency of the proposed mechanism to effectually minimize the queuing delays in time-sensitive EFBNs.
Figure 6a depicts the worst-case E2E latencies experienced by the eCPRI streams with the LLR, LAPC, and LLPF-FP schemes. It can be observed that the LLR resulted in high E2E latencies for COST239, which exceeded beyond the 250 μs limits once the eCPRI traffic load increased to 60 Gbps. Whereas, for ARPA2 topology, as shown in
Figure 6b, the LLR scheme lacked the mechanism to transport even 50 Gbps of traffic, and resulted in intolerable E2E latencies. Our proposed LAPC algorithm improved the E2E latency performance in the considered EFBNs topologies as compared to existing schemes such as the LLR. The simulation result showed that the LAPC can transport up to 82 Gbps and 65 Gbps of traffic in COST239 and ARPA2 topologies, respectively, by fully satisfying the E2E latency constraints of the fronthaul systems. The LLPF-FP scheme further improved the performance of the EFBNs and enabled the successful transmission of eCPRI traffic up to 100 Gbps for COST239 while retaining the E2E latencies within the threshold. In ARPA2 topology—which has comparatively long routes and more numbers of intermediate bridges with respect to COST239—the proposed LLPF-FP scheme transmitted up to 85 Gbps of traffic without violating the threshold. This verifies the feasibility of our proposed scheme to transport the time-sensitive eCPRI streams in low-cost Ethernet fronthaul networks without deploying the expensive optical fronthaul networks. Under the considered scenario and based on the results for ARPA2 topology, with a successful transmission of 85% of fronthaul traffic through the low-cost Ethernet infrastructure, a significant amount of CAPEX and OPEX, which would be required to deploy the complete optical fronthaul networks, can be saved. Hence, in this case, only 15% of the traffic required transmission through high-capacity and expensive optical links. For networks such as COST239, almost all of the traffic can be transported through the Ethernet systems, which would be highly cost-effective.
The results in
Figure 7 show the distances that different schemes can support under different traffic load conditions based on the latency constraints. The distances are computed based on Equations (1)–(5). The proposed LAPC and LAPF-FP schemes outperform the LLR and considerably improve the distances supported by the fronthaul links. It can be observed that with the LAPF-FP scheme, the distances of the fronthaul segment can be increased up to 30 km for 50 Gbps of traffic, which reduced with the increase of traffic load, as shown in
Figure 7a. In ARPA2 topology, as the number of intermediate bridges and distances between the RRHs and BBU pool has been increased as compared to COST239. As a result, the processing, transmission, queuing, and encapsulations delays at each bridging node would also be increased, which resulted in high E2E latencies based on Equation (4), and low fronthaul distances based on Equation (5). As shown in
Figure 7b, the proposed LAPF-FP scheme can support fronthaul link distances from 3 km to 18 km for 50 Gbps to 100 Gbps of traffic, respectively. In contrast, the existing scheme can only support a maximum link distance of 4.5 km in Ethernet-based fronthaul bridged networks. The simulation results showed that in about 50% of cases, the proposed LAPF-FP scheme minimized the queuing delays and worst-case E2E latencies by more than 110 μs and 90 μs, respectively, compared to the LLR. In about 70% of cases, our scheme improved the link distances up to 35% compared to the LLR.
The results show that alone, delay-sensitive path computation schemes could not be enough to maximize the traffic transmissions in the EFBNs, and along with the path computation schemes, novel traffic forwarding concepts such as the one proposed in this study that enabled the frame preemption on high-load paths were required to fully exploit the advantages of leveraging Ethernet-based fronthaul networks. The simulation results showed a tradeoff between the maximum link distances and acceptable E2E latencies. By improving the E2E latencies in fronthaul networks, the length of Ethernet links can be increased. It can be concluded that with frame preemption in the proposed low-latency packet forwarding which is named the LAPF-FP scheme, the E2E latencies of maximum eCPRI streams can be retained closer to the threshold, and long-distance Ethernet links can be deployed between the RRHs and the BBU pool by fully satisfying the latency constraints of the fronthaul networks. However, this type of performance is not guaranteed with the existing schemes, which makes them less suitable to addressing the latency constraints of Ethernet-based fronthaul bridged networks.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}