Periocular Recognition in the Wild: Implementation of RGB-OCLBCP Dual-Stream CNN



Abstract
:Featured Application
Abstract
1. Introduction
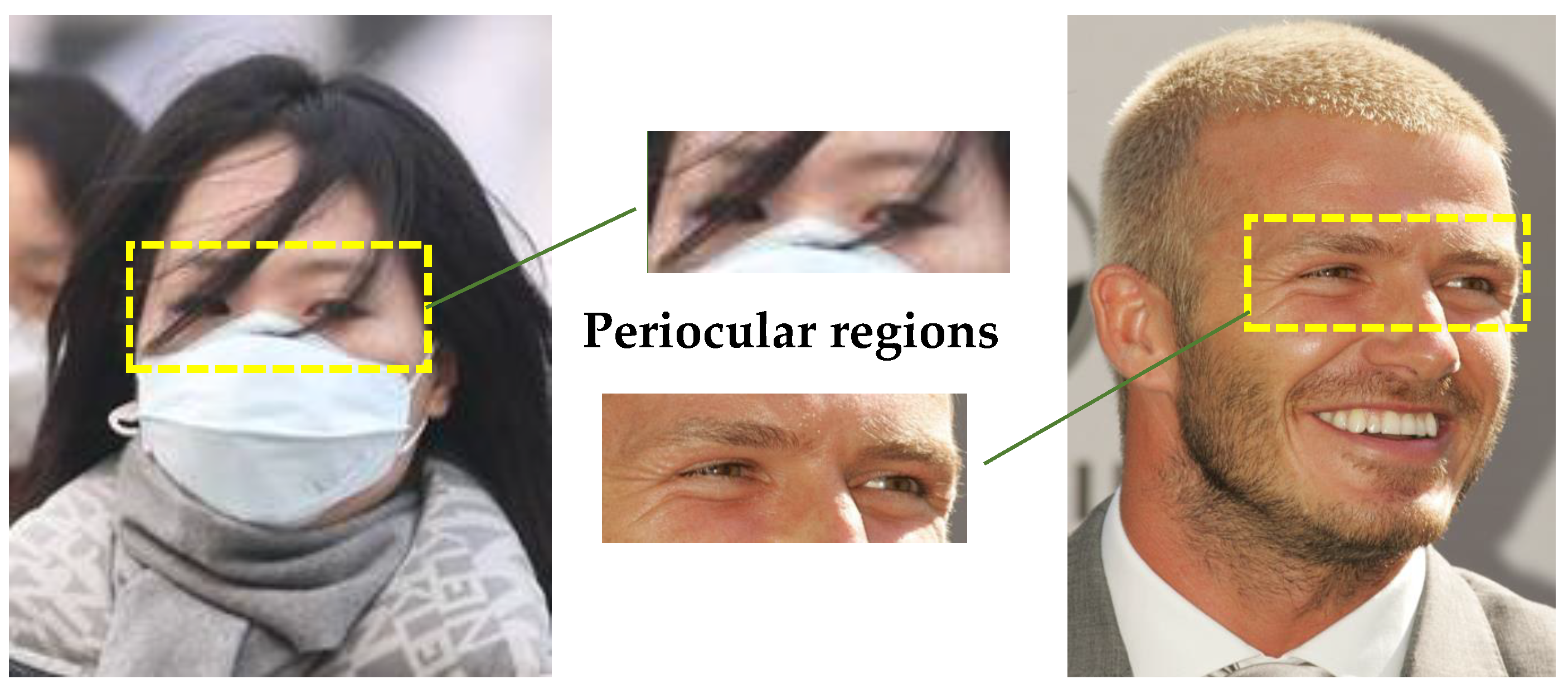
1.1. Related Works
1.2. Motivation and Contributions
- To study complementarity between CNN and input features, we investigate and analyse the combination of RGB image and a novel texture descriptor, namely OCLBCP for periocular recognition in the wild.
- Two distinct late-fusion layers are introduced in the proposed CNN. The role of the late-fusion layers is to aggregate the RGB image and OCLBCP descriptor. Hence, the proposed two-stream CNN is beneficial from these new features of the late-fusion layers to deliver better accuracy performance.
- A new periocular in the wild database, namely Ethnic-ocular, is created and shared in [33]. The images were collected across highly uncontrolled subject–camera distances, appearances, resolutions, locations, levels of illumination, and so on. The database includes training and testing schemes for performance analysis and evaluation.
2. Colour-Based Orthogonal Combination—Local Binary Coded Pattern
| Algorithm 1 Creating colour-based texture description OCLBCP. |
| Input: Output: OCLBCP |
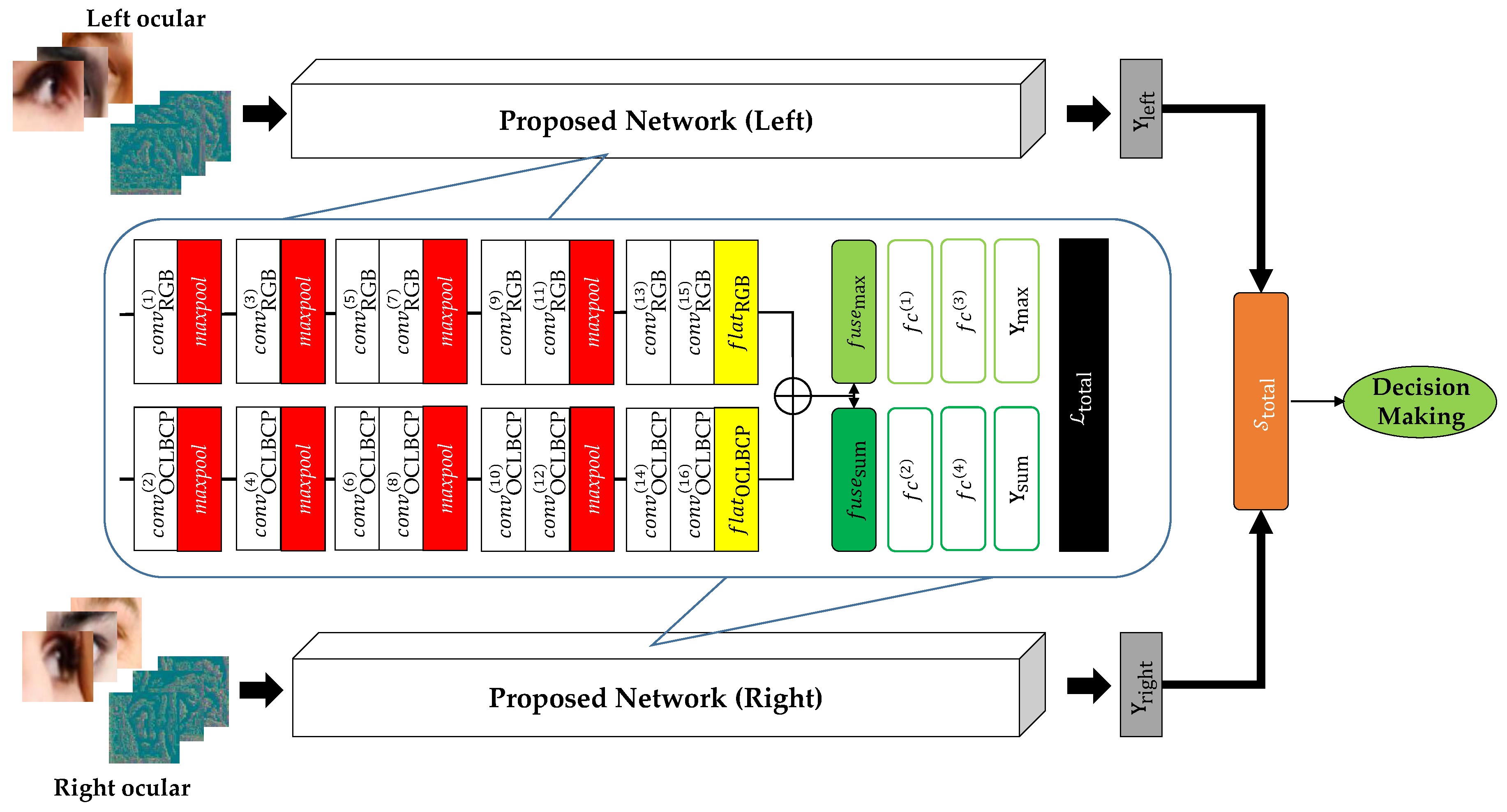
3. RGB-OCLBCP of Dual-Stream CNN
3.1. Fusion Layers
3.2. Total Loss for Training
3.3. Score Fusion Layer for Recognition
4. Database
4.1. Collection Setup
4.2. Training Protocol
4.3. Benchmark Protocol
5. Experiments
5.1. Experimental Setup
5.1.1. Configuration of Proposed Network
5.1.2. Configuration of Benchmark Networks
5.2. Experimental Results
5.2.1. Performance Analysis on Proposed Network
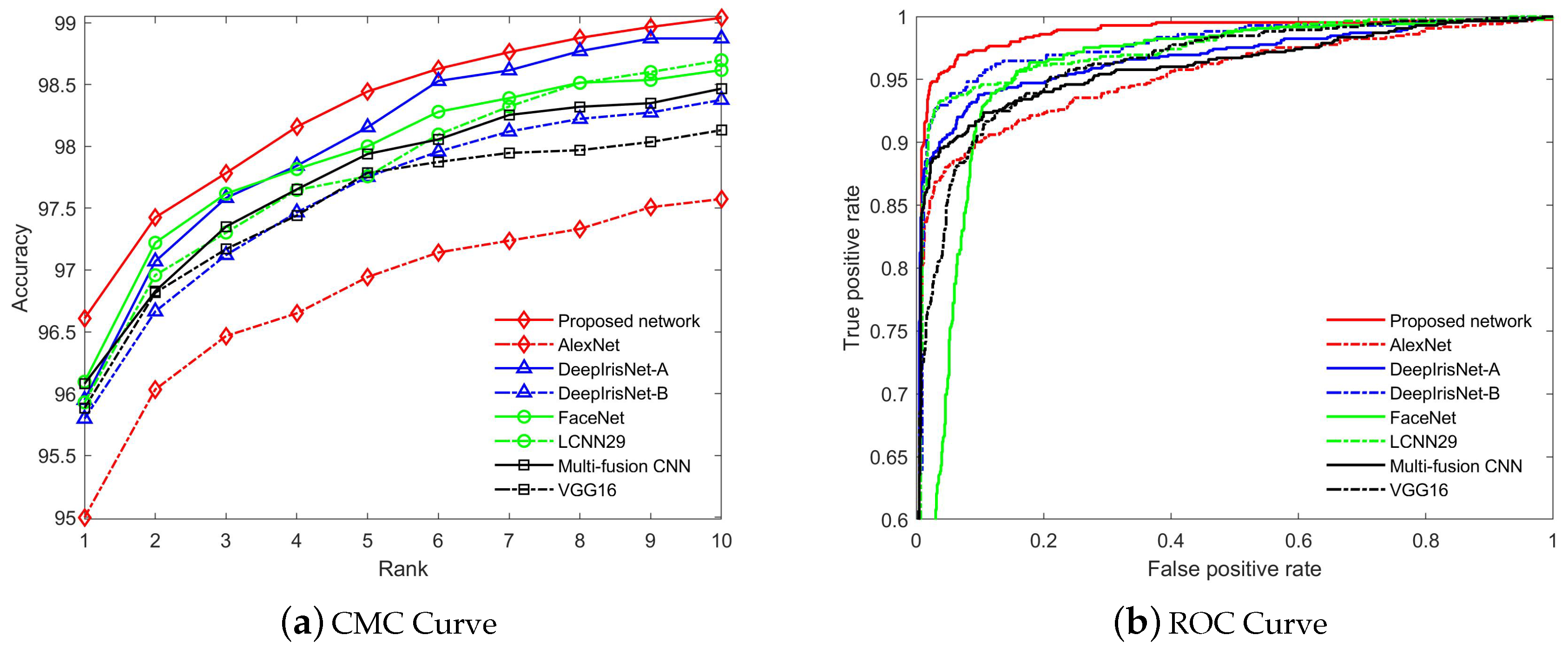
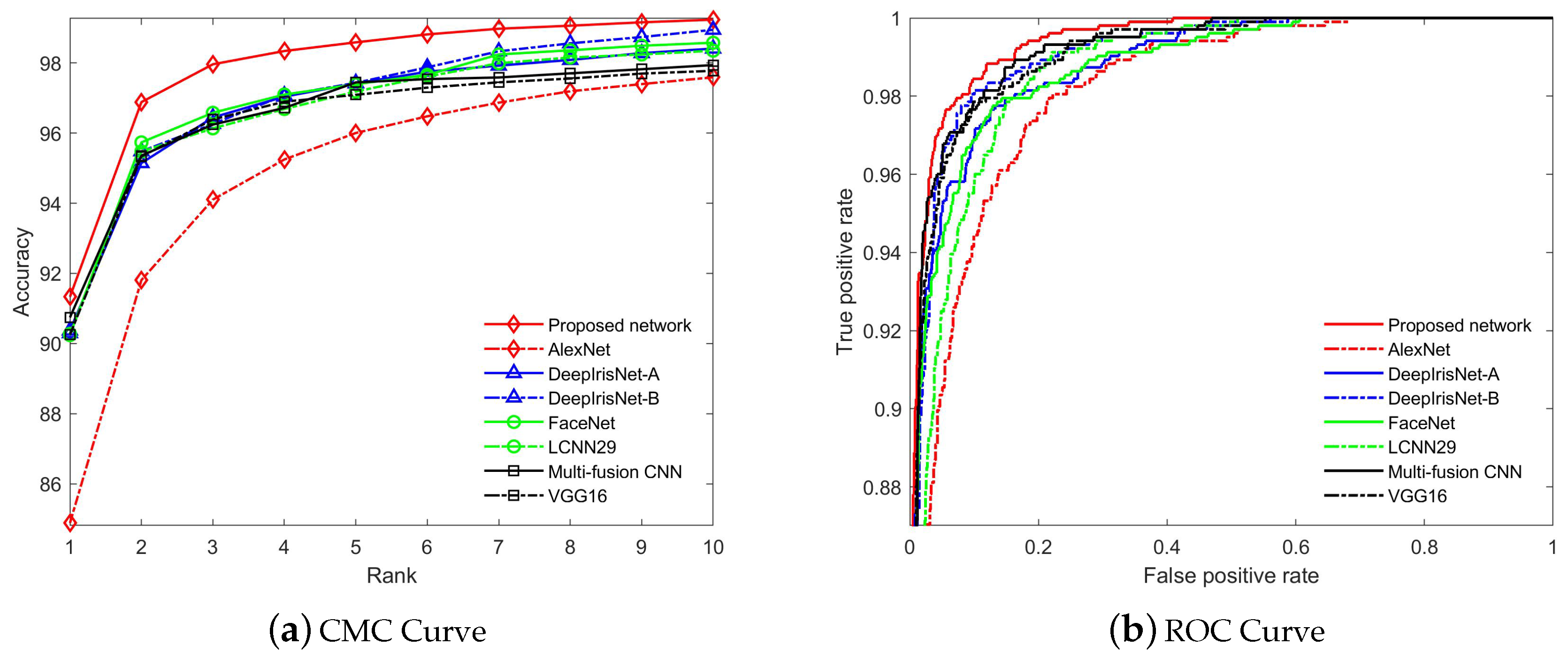
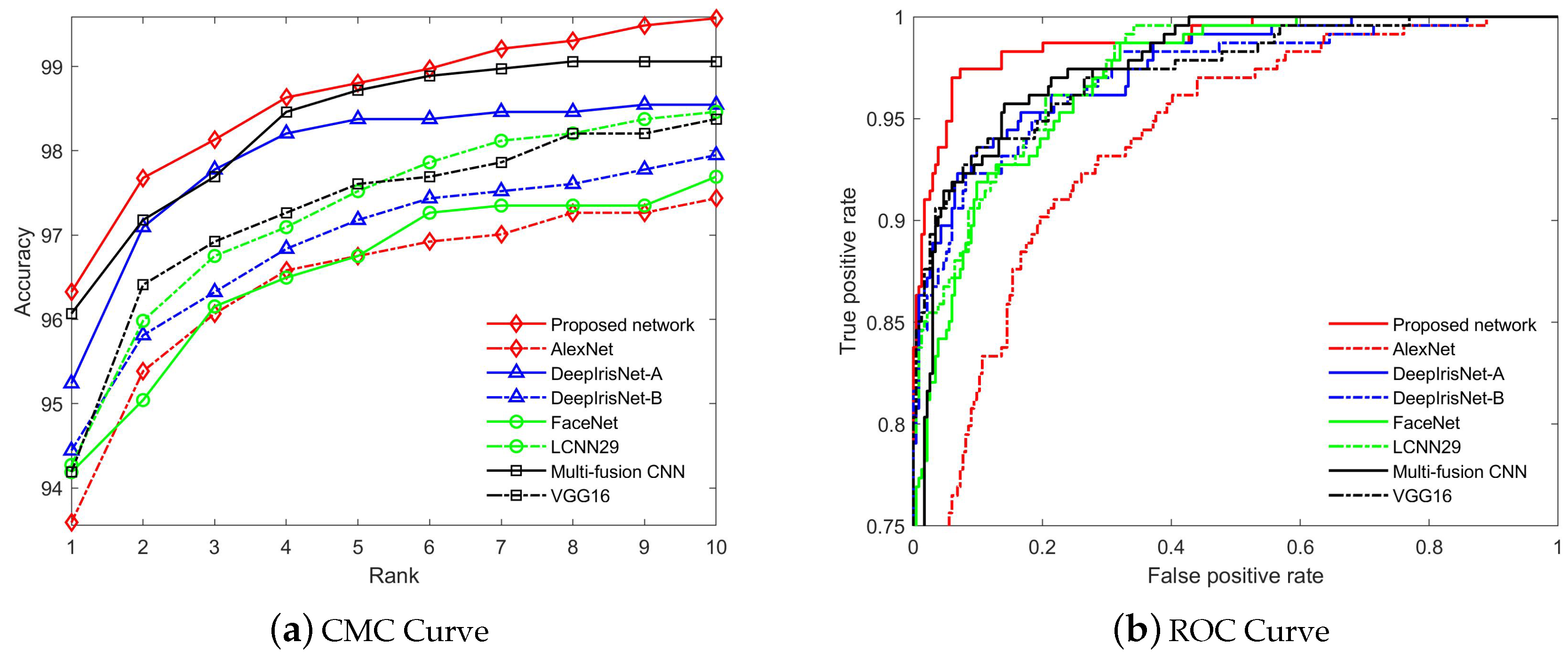
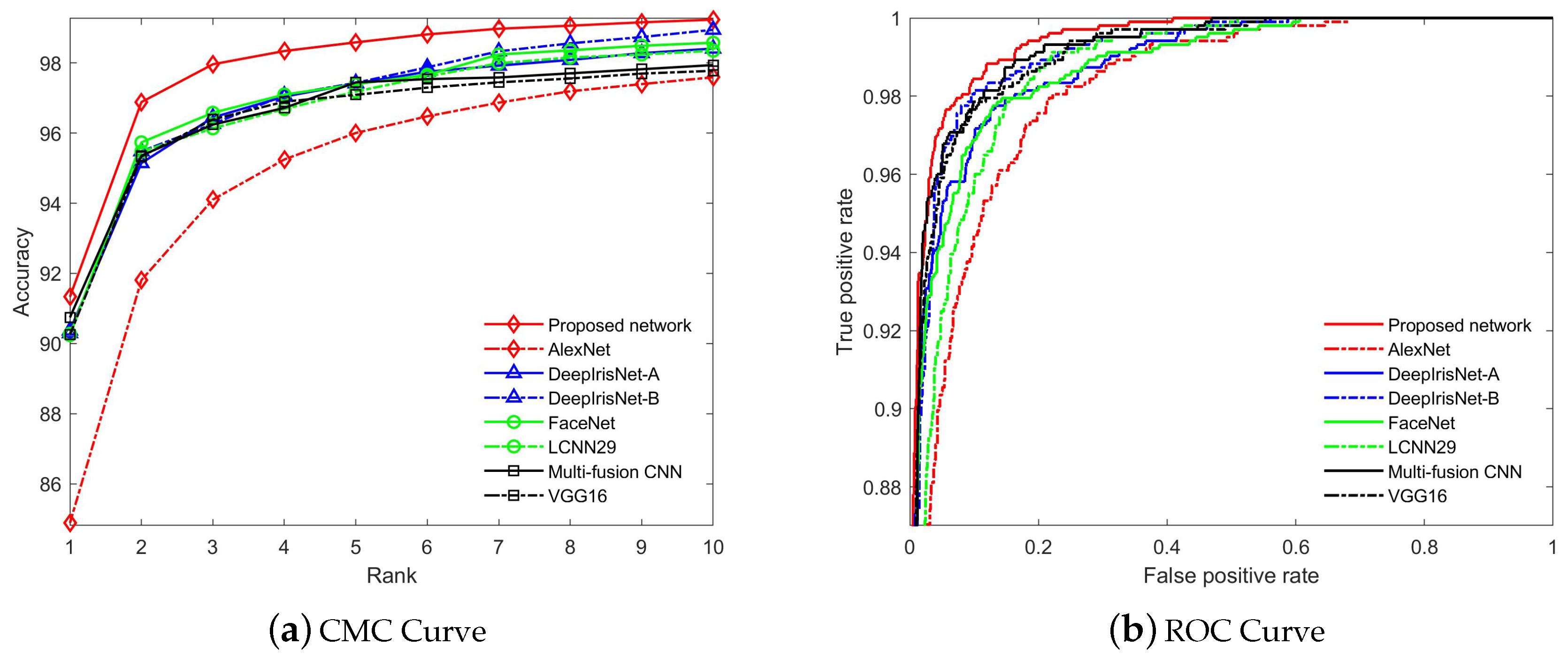
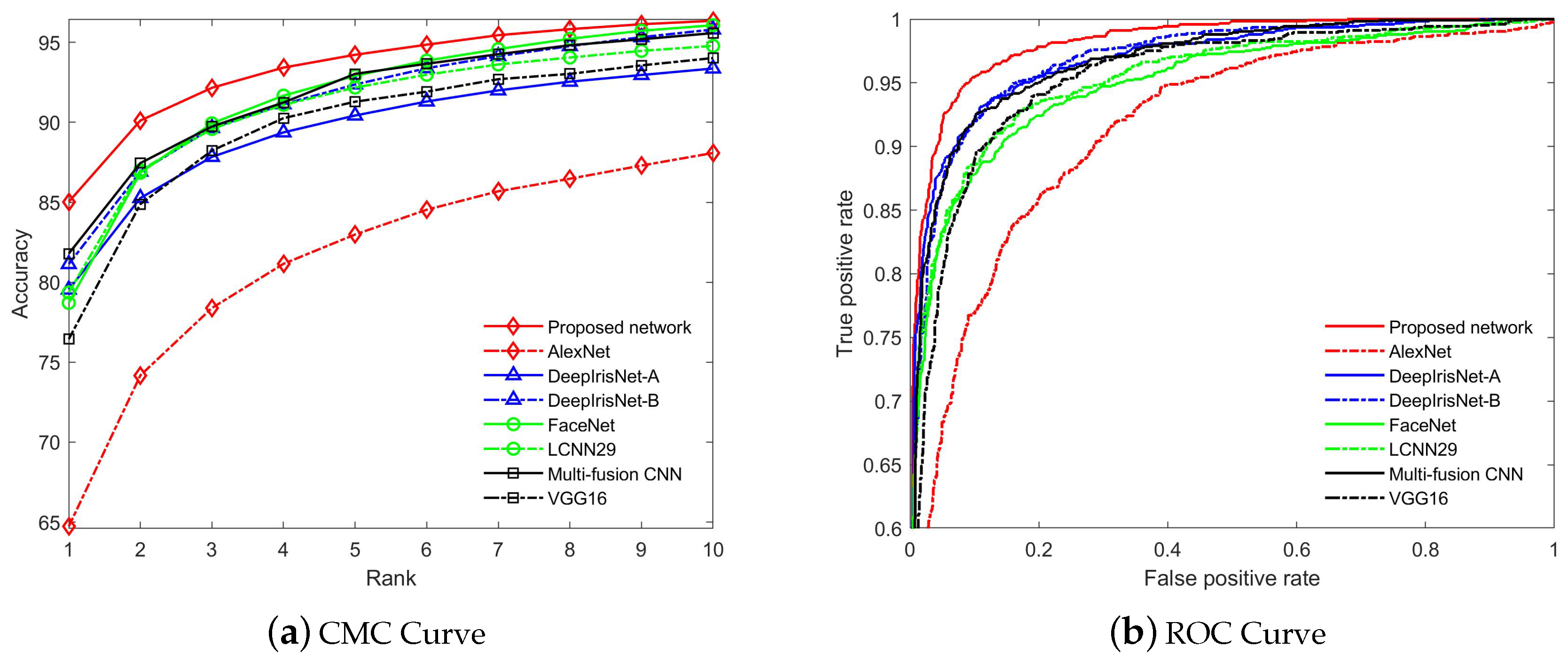
5.2.2. Performance Evaluation on Recognition and Verification Tasks
Evaluation on AR Database
Evaluation on CASIA-Iris Distance Database
Evaluation on UBIPr Database
Evaluation on Ethnic-Ocular Database
5.2.3. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jain, A.K.; Nandakumar, K.; Ross, A. 50 years of biometric research: Accomplishments, challenges, and opportunities. Pattern Recog. Lett. 2016, 79, 80–105. [Google Scholar] [CrossRef]
- Klare, B.F.; Klein, B.; Taborsky, E.; Blanton, A.; Cheney, J.; Allen, K.; Grother, P.; Mah, A.; Jain, A.K. Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus benchmark A. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1931–1939. [Google Scholar]
- Klontz, J.C.; Jain, A.K. A case study of automated face recognition: The Boston Marathon bombings suspects. Computer 2013, 46, 91–94. [Google Scholar] [CrossRef]
- Barroso, E.; Santos, G.; Cardoso, L.; Padole, C.; Proença, H. Periocular recognition: How much facial expressions affect performance? Pattern Anal. Appl. 2016, 19, 517–530. [Google Scholar] [CrossRef]
- Park, U.; Jillela, R.R.; Ross, A.; Jain, A.K. Periocular biometrics in the visible spectrum: A feasibility study. In Proceedings of the International Conferences on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 28–30 September 2009; pp. 1–6. [Google Scholar]
- Bharadwaj, S.; Bhatt, H.S.; Vatsa, M.; Singh, R. Periocular biometrics: When iris recognition fails. In Proceedings of the International Conferences on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010; pp. 1–6. [Google Scholar]
- Park, U.; Jillela, R.R.; Ross, A.; Jain, A.K. Periocular biometrics in the visible spectrum. IEEE Trans. Inf. Forensics Secur. 2011, 6, 96–106. [Google Scholar] [CrossRef]
- Raja, K.B.; Raghavendra, R.; Stokkenes, M.; Busch, C. Smartphone authentication system using periocular biometrics. In Proceedings of the International Conferences on Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 10–12 September 2014; pp. 1–8. [Google Scholar]
- Mokhayeri, F.; Granger, E.; Bilodeau, G. Synthetic face generation under various operational conditions in video surveillance. In Proceedings of the International Conferences on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4052–4056. [Google Scholar]
- The Korea Times. Available online: https://www.koreatimes.co.kr/www/nation/2019/01/371_262460.html (accessed on 12 February 2019).
- Kitchen Decor. Available online: https://kitchendecor.club/files/now-beckham-hairstyle-david.html (accessed on 12 February 2019).
- Padole, C.N.; Proença, H. Periocular recognition: Analysis of performance degradation factors. In Proceedings of the International Conferences on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 439–445. [Google Scholar]
- Raja, K.B.; Raghavendra, R.; Stokkenes, M.; Busch, C. Collaborative representation of deep sparse filtered features for robust verification of smartphone periocular images. In Proceedings of the International Conferences on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 330–334. [Google Scholar]
- Alonso-Fernandez, F.; Bigun, J. Periocular recognition using retinotopic sampling and Gabor decomposition. In Proceedings of the European International Conferences on Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 309–318. [Google Scholar]
- Cao, Z.; Schmid, N.A. Fusion of operators for heterogeneous periocular recognition at varying ranges. Pattern Recognit. Lett. 2016, 82, 170–180. [Google Scholar] [CrossRef]
- Mahalingam, G.; Ricanek, K. LBP-based periocular recognition on challenging face datasets. EURASIP J. Image Video Process. 2013, 36, 1–13. [Google Scholar] [CrossRef]
- Tan, C.-W.; Kumar, A. Towards online iris and periocular recognition under relaxed imaging constraints. IEEE Trans. Image Process. 2013, 22, 3751–3765. [Google Scholar]
- Nigam, I.; Vatsa, M.; Singh, R. Ocular biometrics: A survey of modalities and fusion approaches. Inf. Fusion 2015, 26, 1–35. [Google Scholar] [CrossRef]
- Raghavendra, R.; Busch, C. Learning deeply coupled autoencoders for smartphone based robust periocular verification. In Proceedings of the International Conferences on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 325–329. [Google Scholar]
- Cho, S.R.; Nam, G.P.; Shin, K.Y.; Nguyen, D.T.; Pham, T.D.; Lee, E.C.; Park, K.R. Periocular-based biometrics robust to eye rotation based on polar coordinates. Multimed. Tools Appl. 2017, 76, 11177–11197. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Geoffrey, H. Imagenet classification with deep convolutional neural networks. In Proceedings of the International Conferences on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Anwer, R.M.; Khan, F.S.; van de Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 138, 74–85. [Google Scholar] [CrossRef] [Green Version]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the International Conferences on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2301–2305. [Google Scholar]
- Proença, H.; Neves, J.C. Deep-PRWIS: Periocular recognition without the iris and sclera using deep learning frameworks. IEEE Trans. Inf. Forensics Secur. 2018, 13, 888–896. [Google Scholar] [CrossRef]
- Zhao, Z.; Kumar, A. Improving periocular recognition by explicit attention to critical regions in deep neural network. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2937–2952. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H.; Sun, Z.; Tan, T. Deep feature fusion for iris and periocular biometrics on mobile devices. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2897–2912. [Google Scholar] [CrossRef]
- Soleymani, S.; Dabouei, A.; Kazemi, H.; Dawson, J.; Nasrabadi, N.M. Multi-level feature abstraction from convolutional neural networks for multimodal biometric identification. In Proceedings of the International Conferences on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3469–3476. [Google Scholar]
- Levi, G.; Hassner, T. Emotion recognition in the wild via convolutional neural networks and mapped binary patterns. In Proceedings of the International Conferences on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 503–510. [Google Scholar]
- CASIA-Iris Distance Database. Available online: http://www.cbsr.ia.ac.cn/china/Iris%20Databases%20CH.asp (accessed on 12 December 2018).
- Marsico, M.D.; Nappi, M.; Riccio, D.; Wechsler, H. Mobile iris challenge evaluation (MICHE)-I, biometric iris dataset and protocols. Pattern Recognit. Lett. 2015, 57, 17–23. [Google Scholar] [CrossRef]
- Alonso-Fernandez, F.; Raja, K.B.; Raghavendra, R.; Busch, C.; Bigun, J.; Vera-Rodriguez, R.; Fierrez, J. Cross-sensor periocular biometrics: A comparative benchmark including smartphone authentication. arXiv 2019, arXiv:1902.08123. [Google Scholar]
- Rhee, S.C.; Woo, K.S.; Kwon, B. Biometric study of eyelid shape and dimensions of different races with references to beauty. Aesthetic Plast. Surg. 2012, 36, 1236–1245. [Google Scholar] [CrossRef] [PubMed]
- Ethnic-Ocular Database. Available online: https://www.dropbox.com/sh/vgg709to25o01or/AAB4-20q0nXYmgDPTYdBejg0a?dl=0 (accessed on 29 January 2019).
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar]
- Tiong, L.C.O. Multimodal Biometrics Recognition Using Multi-Layer Fusion Convolutional Neural Network with RGB and Texture Descriptor. Ph.D. Thesis, KAIST, Daejeon, Korea, 15 February 2019. [Google Scholar]
- Delac, K.; Grgic, M.; Kos, T. Sub-image homomorphic filtering technique for improving facial identification under difficult illumination conditions. In Proceedings of the International Conferences on Systems, Signals and Image Processing, Budapest, Hungary, 21–23 September 2006; pp. 95–98. [Google Scholar]
- Martinez, W.L.; Martinez, A.R.; Solka, J. Chapter 3 Dimensionality reduction—Nonlinear methods. In Exploratory Data Analysis with MATLAB; Martinez, W.L., Martinez, A.R., Solka, J., Eds.; CRC Press LLC: Boca Raton, FL, USA, 2005; pp. 61–68. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1933–1941. [Google Scholar]
- BBC News. Available online: http://www.bbc.com/news (accessed on 10 October 2018).
- CNN News. Available online: https://edition.cnn.com/ (accessed on 11 October 2018).
- Naver News. Available online: http://news.naver.com/ (accessed on 11 October 2018).
- Ng, H.W.; Winkler, S. A data-driven approach to cleaning large face datasets. In Proceedings of the International Conferences on Image Processing (ICIP), CNIT La Défense, Paris, France, 27–30 October 2014; pp. 343–347. [Google Scholar]
- Matlab Object Detector. Available online: https://uk.mathworks.com/help/vision/ref/vision.cascadeobjectdetector-system-object.html (accessed on 10 October 2018).
- Štruc, V.; Pavešić, N. The complete Gabor-fisher classifier for robust face recognition. EURASIP J. Adv. Signal Process. 2010, 1–26. [Google Scholar]
- TensorFlow. Available online: https://tensorflow.org (accessed on 21 November 2018).
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Wu, X.; He, R.; Sun, Z.; Tan, T. A light CNN for deep face representation with noisy labels. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2884–2896. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Hernandez-Diaz, K.; Alonso-Fernandez, F.; Bigun, J. Periocular recognition using CNN features off-the-shelf. arXiv 2018, arXiv:1809.06157. [Google Scholar]
- Martínez, A.; Benavente, R. The AR Face Database; CVC Technical Report #24; Robot Vision Lab; Purdue University: Barcelona, Spain, 1998. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Layers | Configurations |
|---|---|
| , | : 64@80 × 80; : 2 × 2; : 2 × 2 |
| , | f: 128@40 × 40; k: 2 × 2; : 2 × 2 |
| , | f: 256@20 × 20; k: 2 × 2 |
| , | f: 256@20 × 20; k: 2 × 2; : 2 × 2 |
| , | f: 512@10 × 10; k: 2 × 2 |
| , | f: 512@10 × 10; k: 2 × 2; : 2 × 2 |
| , | f: 512@10 × 10; k: 2 × 2 |
| , | f: 512@10 × 10; k: 2 × 2 |
| , | 1 × 1 × 12,800 |
| , | 1 × 1 × 4096 |
| , | 1 × 1 × 4096 |
| , | 1 × 1 × 4096 |
| , | 1 × 1 |
| Networks | Accuracy (%) | t.w. | flops | |
|---|---|---|---|---|
| Rank-1 | Rank-5 | |||
| CNN with RGB image | 80.79 ± 1.43 | 90.42 ± 1.29 | 131.1 M | 2.22 GFLOPS |
| CNN with OCLBCP | 66.65 ± 2.22 | 89.73 ± 1.91 | 131.1 M | 2.22 GFLOPS |
| Dual-stream CNN (using unshared weights) | 82.09 ± 1.59 | 92.11 ± 1.32 | 250.8 M | 1.90 GFLOPS |
| Proposed network | 85.03 ± 1.88 | 94.23 ± 1.26 | 126.1 M | 0.90 GFLOPS |
| Networks | AR | CASIA-iris | UBIPr | Ethnic-Ocular | ||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | |
| AlexNet | 93.59 | 96.75 | 95.00 ± 1.8 | 96.98 ± 2.5 | 84.88 ± 2.5 | 96.01 ± 1.8 | 64.72 ± 3.3 | 82.98 ± 2.5 |
| DeepIristNet-A | 95.24 | 98.38 | 95.95 ± 2.1 | 98.15 ± 0.6 | 90.30 ± 1.2 | 97.41 ± 1.1 | 79.54 ± 3.1 | 90.43 ± 2.4 |
| DeepIristNet-B | 94.44 | 97.18 | 95.79 ± 2.6 | 97.75 ± 0.6 | 90.20 ± 1.7 | 97.43 ± 0.5 | 81.13 ± 3.1 | 92.37 ± 1.2 |
| FaceNet | 94.19 | 97.75 | 96.09 ± 2.1 | 98.10 ± 0.4 | 90.24 ± 1.4 | 97.36 ± 0.4 | 78.71 ± 3.7 | 92.19 ± 1.6 |
| LCNN29 | 94.27 | 97.52 | 96.01 ± 2.0 | 97.85 ± 0.9 | 90.28 ± 1.7 | 97.18 ± 0.7 | 79.35 ± 2.6 | 92.17 ± 1.8 |
| Multi-fusion CNN | 96.07 | 98.71 | 95.81 ± 1.9 | 97.67 ± 1.0 | 90.75 ± 1.0 | 97.44 ± 0.3 | 81.79 ± 3.5 | 93.03 ± 1.3 |
| VGG16 | 94.20 | 97.61 | 95.88 ± 0.1 | 97.99 ± 0.5 | 90.24 ± 1.4 | 97.09 ± 1.1 | 76.43 ± 2.2 | 91.29 ± 1.5 |
| Proposed Network | 96.32 | 98.80 | 96.62 ± 1.3 | 98.45 ± 0.4 | 91.28 ± 1.2 | 98.59 ± 0.4 | 85.03 ± 1.9 | 94.23 ± 1.3 |
| Networks | AR | CASIA-Iris | UBIPr | Ethnic-Ocular | ||||
|---|---|---|---|---|---|---|---|---|
| EER (%) | AUC | EER (%) | AUC | EER (%) | AUC | EER (%) | AUC | |
| AlexNet | 14.53 | 0.9363 | 8.06 ± 5.3 | 0.9533 | 7.11 ± 2.9 | 0.9805 | 16.47 ± 1.6 | 0.9139 |
| DeepIristNet-A | 7.69 | 0.9751 | 7.51 ± 1.1 | 0.9674 | 5.07 ± 2.2 | 0.9877 | 8.79 ± 1.7 | 0.9689 |
| DeepIristNet-B | 8.12 | 0.9741 | 5.87 ± 1.5 | 0.9756 | 4.29 ± 0.9 | 0.9890 | 8.77 ± 1.1 | 0.9693 |
| FaceNet | 9.40 | 0.9692 | 6.10 ± 2.2 | 0.9738 | 5.46 ± 1.5 | 0.9870 | 11.67 ± 1.2 | 0.9489 |
| LCNN29 | 9.39 | 0.9737 | 6.34 ± 1.6 | 0.9719 | 6.34 ± 2.1 | 0.9849 | 10.95 ± 1.6 | 0.9536 |
| Multi-fusion CNN | 7.69 | 0.9756 | 8.69 ± 1.1 | 0.9594 | 4.09 ± 2.1 | 0.9913 | 8.63 ± 1.3 | 0.9681 |
| VGG16 | 7.69 | 0.9747 | 7.42 ± 1.7 | 0.9681 | 4.38 ± 1.3 | 0.9892 | 9.43 ± 2.5 | 0.9553 |
| Proposed Network | 5.13 | 0.9882 | 4.35 ± 0.5 | 0.9860 | 3.41 ± 1.8 | 0.9938 | 6.63 ± 1.5 | 0.9818 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tiong, L.C.O.; Lee, Y.; Teoh, A.B.J. Periocular Recognition in the Wild: Implementation of RGB-OCLBCP Dual-Stream CNN. Appl. Sci. 2019, 9, 2709. https://doi.org/10.3390/app9132709
Tiong LCO, Lee Y, Teoh ABJ. Periocular Recognition in the Wild: Implementation of RGB-OCLBCP Dual-Stream CNN. Applied Sciences. 2019; 9(13):2709. https://doi.org/10.3390/app9132709
Chicago/Turabian StyleTiong, Leslie Ching Ow, Yunli Lee, and Andrew Beng Jin Teoh. 2019. "Periocular Recognition in the Wild: Implementation of RGB-OCLBCP Dual-Stream CNN" Applied Sciences 9, no. 13: 2709. https://doi.org/10.3390/app9132709
APA StyleTiong, L. C. O., Lee, Y., & Teoh, A. B. J. (2019). Periocular Recognition in the Wild: Implementation of RGB-OCLBCP Dual-Stream CNN. Applied Sciences, 9(13), 2709. https://doi.org/10.3390/app9132709