Payload-Based Traffic Classification Using Multi-Layer LSTM in Software Defined Networks †




Abstract
1. Introduction
2. Related Work
3. Proposed SDN Architecture for Deep Learning-Based Traffic Classification
4. Data Preprocessing
Learning Data Generation
5. Deep Learning Models
5.1. The Multi-Layer LSTM Architecture
5.2. The CNN and LSTM Combination Network Model Architecture
6. Model Tuning
Multi-Layer LSTM and CNN + LSTM Model Tuning
- (16,000, 30, 36), (16,000, 30, 64), (16,000, 30, 256), and (16,000, 30, 1024) for 30 packets in a flow
- (16,000, 60, 36), (16,000, 60, 64), (16,000, 60, 256), and (16,000, 60, 1024) for 60 packets in a flow
- (16,000, 100, 36), (16,000, 100, 64), (16,000, 100, 256), and (16,000, 100, 1024) for 100 packets in a flow
7. Experimental Evaluation
7.1. Experimental Environment
7.2. Performance Metrics
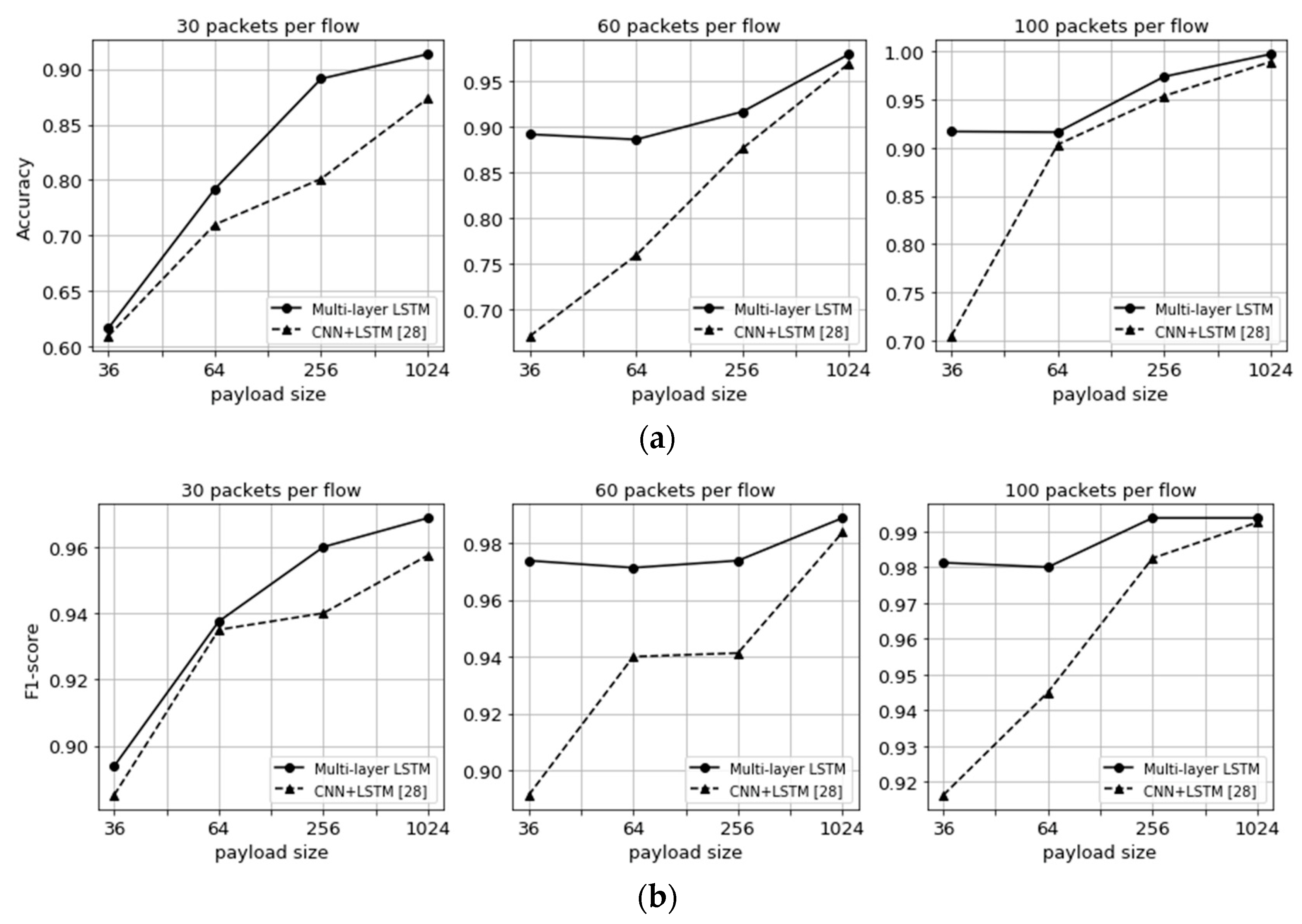
7.3. Experimental Results
8. Discussion: Flow Classifier in SDN
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gupta, P.; McKeown, N. Algorithms for packet classification. IEEE Netw. Mag. Glob. Internetwork. 2001, 15, 24–32. [Google Scholar] [CrossRef]
- Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A comprehensive survey on machine learning for networking: Evolution. J. Internet Serv. Appl. 2018, 9, 16. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Shabtai, A.; Guarnizo, J.D.; Ochoa, M.; Tippenhauer, N.O.; Elovici, Y. Profiliot: A machine learning approach for IoT device identification based on network traffic analysis. In Proceedings of the SAC’17 Symposium on Applied Computing, Marrakech, Morocco, 3–7 April 2017; pp. 506–509. [Google Scholar]
- Li, L.; Kianmehr, K. Internet traffic classification based on associative classifiers. In Proceedings of the 2012 IEEE International Conference on Cyber Technology in Automation, Control. and Intelligent Systems (CYBER), Bangkok, Thailand, 27–31 May 2012; pp. 263–268. [Google Scholar]
- Li, F.; Kakhki, A.M.; Choffnes, D.; Gill, P.; Mislove, A. Classifiers unclassified: An efficient approach to revealing IP traffic classification rules. In Proceedings of the 2016 Internet Measurement Conference, ser. IMC’16, Santa Monica, CA, USA, 28–30 October 2016; pp. 239–245. [Google Scholar]
- Nguyen, T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Udrea, O.; Lumezanu, C.; Foster, J.S. Rule-based static analysis of network protocol implementations. Inf. Comput. 2008, 206, 130–157. [Google Scholar] [CrossRef]
- Breslau, L.; Zhang, Y.; Paxson, V.; Shenker, S. On the characteristics and origins of internet flow rates. In Proceedings of the 2002 Conference on Applications, Las Vegas, NV, USA, 24–27 June 2002; pp. 309–322. [Google Scholar]
- Lan, K.; Heidemann, J. On the Correlation of Internet Flow Characteristics; Technical Report ISI-TR-574; USC/Information Sciences Institute: Los Angeles, CA, USA, 2003. [Google Scholar]
- Zhang, J.; Xiang, Y.; Wang, Y.; Zhou, W.; Xiang, Y.; Guan, Y. Network Traffic Classification Using Correlation Information. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 104–117. [Google Scholar] [CrossRef]
- Risso, F.; Baldi, M.; Morandi, O.; Baldini, A.; Monclus, P. Lightweight, Payload-Based Traffic Classification: An Experimental Evaluation. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 5869–5875. [Google Scholar]
- Bernaille, L.; Teixeira, R.; Salamatian, K. Early application identification. In Proceedings of the 2006 CoNEXT’06 ACM CoNEXT Conference, Arlington, VA, USA, 6–11 November 2006; p. 6. [Google Scholar]
- Erman, J.; Mahanti, A.; Arlitt, M.; Williamson, C. Identifying and discriminating between web and peer-to-peer traffic in the network core. In Proceedings of the 16th International Conference, Banff, AB, Canada, 8–12 May 2007; pp. 883–892. [Google Scholar]
- Haffner, P.; Sen, S.; Spatscheck, O.; Wang, D. ACAS: Automated construction of application signatures. In Proceedings of the 2005 ACM SIGCOMM Workshop on Mining network Data, Philadelphia, PA, USA, 26 August 2005. [Google Scholar]
- Zander, S.; Nguyen, T.; Armitage, G. Automated traffic classification and application identification using machine learning. In Proceedings of the IEEE Conference on Local Computer Networks 30th Anniversary (LCN’05)l, Sydney, New South Wales, Australia, 17 November 2005; pp. 250–257. [Google Scholar]
- Finsterbusch, M.; Richter, C.; Rocha, E.; Muller, J.-A.; Hanssgen, K. A Survey of Payload-Based Traffic Classification Approaches. IEEE Commun. Surv. Tutor. 2014, 16, 1135–1156. [Google Scholar] [CrossRef]
- Shafiq, M.; Yu, X.; Wang, D. Network traffic classification using machine learning algorithms. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2018; Volume 686, pp. 621–627. [Google Scholar]
- Singh, H. Performance Analysis of Unsupervised Machine Learning Techniques for Network Traffic Classification. In Proceedings of the 2015 Fifth International Conference on Advanced Computing & Communication Technologies, Washington, DC, USA, 20–21 February 2015; pp. 401–404. [Google Scholar]
- Huang, H.; Li, P.; Guo, S. Traffic scheduling for deep packet inspection in software-defined networks. Concurr. Comput. Pract. Exp. 2017, 29, e3967. [Google Scholar] [CrossRef]
- Huang, H.; Guo, S.; Li, P.; Ye, B.; Stojmenovic, I. Joint Optimization of Rule Placement and Traffic Engineering for QoS Provisioning in Software Defined Network. IEEE Trans. Comput. 2015, 64, 3488–3499. [Google Scholar] [CrossRef]
- Parsaei, M.R.; Sobouti, M.J.; Khayami, S.R.; Javidan, R. Network Traffic Classification using Machine Learning Techniques over Software Defined Networks. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 220–225. [Google Scholar]
- Yu, C.; Lan, J.; Xie, J.; Hu, Y. QoS-aware Traffic Classification Architecture Using Machine Learning and Deep Packet Inspection in SDNs. Procedia Comput. Sci. 2018, 131, 1209–1216. [Google Scholar] [CrossRef]
- Amaral, P.; Dinis, J.; Pinto, P.; Bernardo, L.; Tavares, J.; Mamede, H.S.; Henrique, S.M. Machine Learning in Software Defined Networks: Data Collection and Traffic Classification. In Proceedings of the 2016 IEEE 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–5. [Google Scholar]
- Ayyub Qazi, Z.; Lee, J.; Jin, T.; Bellala, G.; Arndt, M.; Noubir, G. Application-Awareness in SDN. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 487–488. [Google Scholar] [CrossRef]
- Pei, J.; Hong, P.; Li, D. Virtual Network Function Selection and Chaining Based on Deep Learning in SDN and NFV-Enabled Networks. In Proceedings of the 2018 IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Yan, J.; Yuan, J. A Survey of Traffic Classification in Software Defined Networks. In Proceedings of the 2018 1st IEEE International Conference on Hot Information-Centric Networking (HotICN), Shenzhen, China, 15–17 August 2018; pp. 200–206. [Google Scholar]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the 2017 International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Network Traffic Classifier with Convolutional and Recurrent Neural Networks for Internet of Things. IEEE Access 2017, 5, 18042–18050. [Google Scholar] [CrossRef]
- Lim, H.-K.; Kim, J.-B.; Heo, J.-S.; Kim, K.; Hong, Y.-G.; Han, Y.-H. Packet-based Network Traffic Classification Using Deep Learning. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 46–51. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Qingqing, Z.; Yong, L.; Zhichao, W.; Jielin, P.; Yonghong, Y. The application of convolutional neural network in speech recognition. Microcomput. Appl. 2014, 3, 39–42. [Google Scholar]
- Hatcher, W.G.; Yu, W. A Survey of Deep Learning: Platforms, Applications and Emerging Research Trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Carela-Español, V.; Bujlow, T.; Barlet-Ros, P. Is Our Ground-Truth for Traffic Classification Reliable? In Proceedings of the Computer Vision—ACCV 2018, Perth, Australia, 2–6 December 2018; Volume 8362, pp. 98–108. [Google Scholar]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Vanderplas, J. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the 14th IJCAI’95 International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; Volume 2, pp. 1137–1143. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and f-measure to ROC, informedness, markedness & correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Michiel, H.; Benjamin, S. Training and Analysing Deep Recurrent Neural Networks. In Proceedings of the 26th Neural Information Processing Systems, Lake Tahoe, Nevada, 5–10 December 2013; pp. 190–198. [Google Scholar]
- Pascanu, R.; Gulcehre, C.; Cho, K.H.; Bengio, Y. How to Construct Deep Recurrent Neural Networks. arXiv 2014, arXiv:1312.6026. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter Values | |
|---|---|
| output size | {64, 128, 256} |
| kernel initializer | {normal, uniform, glorot_uniform} |
| recurrent initializer | {normal, uniform, glorot_uniform} |
| dropout rate | {0.0, 0.2, 0.3, 0.4} |
| output activation type | {tanh, relu, softmax} |
| optimization type | {adam, rmsprop} |
| batch size | {1, 10, 100} |
| Hyper-Parameter Values | |
|---|---|
| number of filters | payload size/2 |
| kernel size | {3 × 3, 5 × 5, 7 × 7} |
| kernel initializer | {normal, uniform, glorot_uniform} |
| output size | {64, 128, 256} |
| recurrent initializer | {normal, uniform, glorot_uniform} |
| dropout rate | {0.0, 0.2, 0.3, 0.4} |
| output activation type | {tanh, relu, softmax} |
| optimization type | {adam, rmsprop} |
| batch size | {1, 10, 100} |
| Payload Size and Number of Packets per Flow | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 36 | 64 | 256 | 1024 | |||||||||
| 30 | 60 | 100 | 30 | 60 | 100 | 30 | 60 | 100 | 30 | 60 | 100 | |
| output size | 128 | 128 | 64 | 256 | 128 | 64 | 256 | 128 | 128 | 128 | 128 | 64 |
| kernel initializer | U | U | U | U | U | U | U | U | G | G | G | G |
| recurrent initializer | U | U | U | U | U | U | U | G | G | G | G | G |
| dropout rate | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.4 | 0.2 | 0.3 | 0.4 |
| output activation type | S | S | S | S | S | S | S | S | S | S | S | S |
| optimization type | A | A | A | A | A | A | A | R | R | A | R | R |
| batch size | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Payload Size and Number of Packets per Flow | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 36 | 64 | 256 | 1024 | |||||||||
| 30 | 60 | 100 | 30 | 60 | 100 | 30 | 60 | 100 | 30 | 60 | 100 | |
| number of filters | 18 | 18 | 18 | 32 | 32 | 32 | 128 | 128 | 128 | 512 | 512 | 512 |
| kernel size | 3 × 3 | 3 × 3 | 3 × 3 | 3 × 3 | 3 × 3 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 5 × 5 | 7 × 7 | 7 × 7 |
| output size | 64 | 64 | 64 | 256 | 128 | 64 | 256 | 128 | 128 | 128 | 128 | 64 |
| kernel initializer | G | G | G | G | G | U | U | U | G | G | G | G |
| recurrent initializer | N | N | U | U | U | U | U | G | G | G | G | G |
| dropout rate | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.2 | 0.2 | 0.2 | 0.3 | 0.3 |
| output activation type | S | S | S | S | S | S | S | S | S | S | S | S |
| optimization type | A | A | A | A | A | A | A | A | A | A | A | A |
| batch size | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Application Label | Predicted | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RDP | Skype | SSH | BitTorrent | HTTP-Facebook | HTTP-Wikipedia | HTTP-Google | HTTP-Yahoo | Sum | F1-score | ||
| Actual | RDP | 681 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 682 | 1.00 |
| Skype | 0 | 571 | 0 | 11 | 0 | 0 | 0 | 0 | 582 | 1.00 | |
| SSH | 2 | 0 | 670 | 0 | 0 | 0 | 0 | 0 | 672 | 1.00 | |
| BitTorrent | 0 | 2 | 0 | 694 | 0 | 1 | 0 | 0 | 697 | 1.00 | |
| HTTP-Facebook | 0 | 1 | 3 | 0 | 642 | 25 | 1 | 2 | 674 | 0.97 | |
| HTTP-Wikipedia | 0 | 0 | 0 | 0 | 45 | 637 | 1 | 26 | 709 | 0.97 | |
| HTTP-Google | 0 | 0 | 0 | 0 | 26 | 6 | 656 | 0 | 688 | 0.99 | |
| HTTP-Yahoo | 0 | 0 | 0 | 0 | 40 | 57 | 0 | 598 | 695 | 0.98 | |
| Overall F1-score | 0.98 | ||||||||||
| Predictive | |||
|---|---|---|---|
| = 5400 | Positive | Negative | |
| Actual | Positive | 681 (True Positive: TP) | 1 (False Negative: FN) |
| Negative | 2 (False Positive: FP) | 4716 (True Negative: TN) | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, H.-K.; Kim, J.-B.; Kim, K.; Hong, Y.-G.; Han, Y.-H. Payload-Based Traffic Classification Using Multi-Layer LSTM in Software Defined Networks. Appl. Sci. 2019, 9, 2550. https://doi.org/10.3390/app9122550
Lim H-K, Kim J-B, Kim K, Hong Y-G, Han Y-H. Payload-Based Traffic Classification Using Multi-Layer LSTM in Software Defined Networks. Applied Sciences. 2019; 9(12):2550. https://doi.org/10.3390/app9122550
Chicago/Turabian StyleLim, Hyun-Kyo, Ju-Bong Kim, Kwihoon Kim, Yong-Geun Hong, and Youn-Hee Han. 2019. "Payload-Based Traffic Classification Using Multi-Layer LSTM in Software Defined Networks" Applied Sciences 9, no. 12: 2550. https://doi.org/10.3390/app9122550
APA StyleLim, H.-K., Kim, J.-B., Kim, K., Hong, Y.-G., & Han, Y.-H. (2019). Payload-Based Traffic Classification Using Multi-Layer LSTM in Software Defined Networks. Applied Sciences, 9(12), 2550. https://doi.org/10.3390/app9122550