An Efficient Neural Network for Shape from Focus with Weight Passing Method




Abstract
1. Introduction
2. Related Work
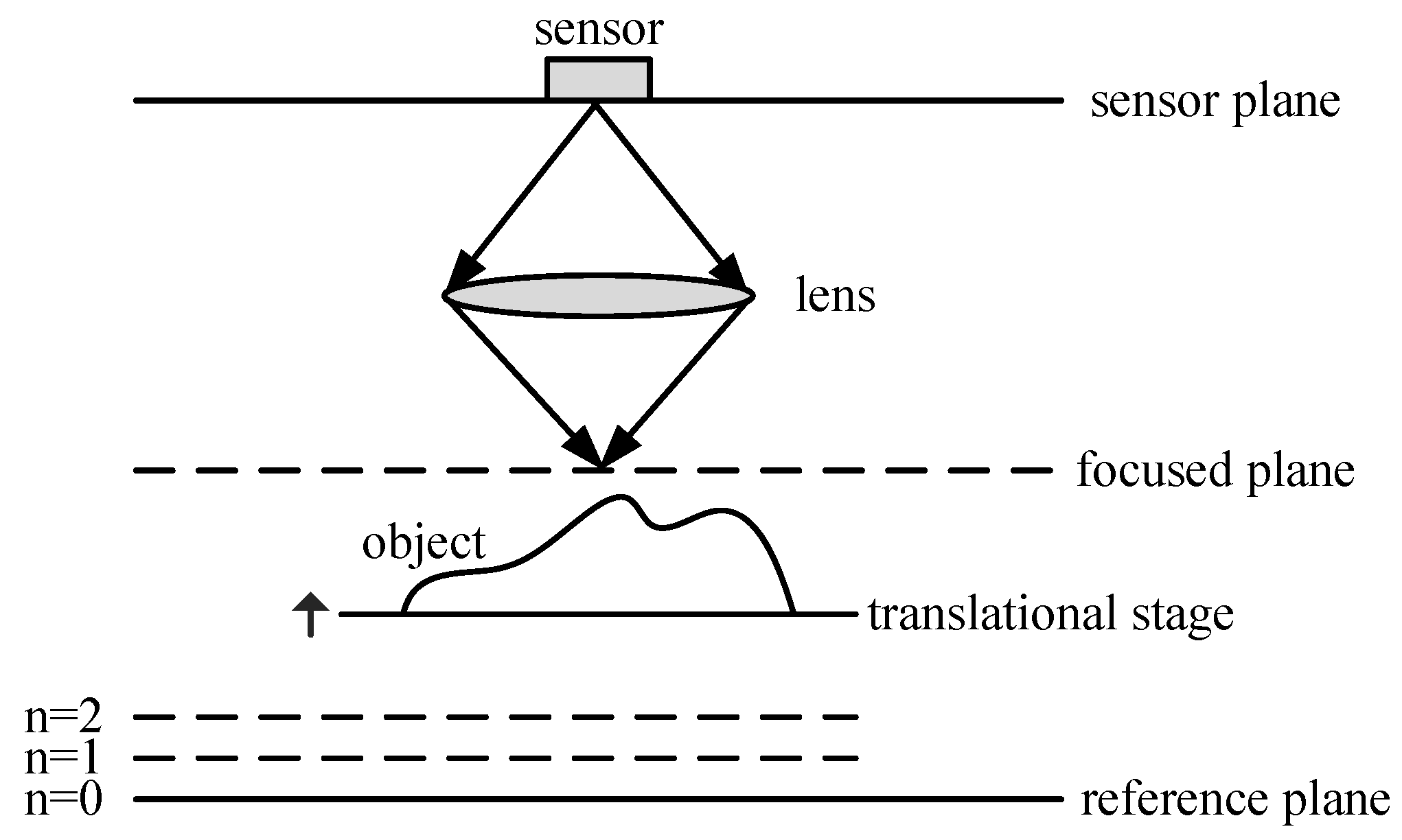
3. Neural Network for SFF
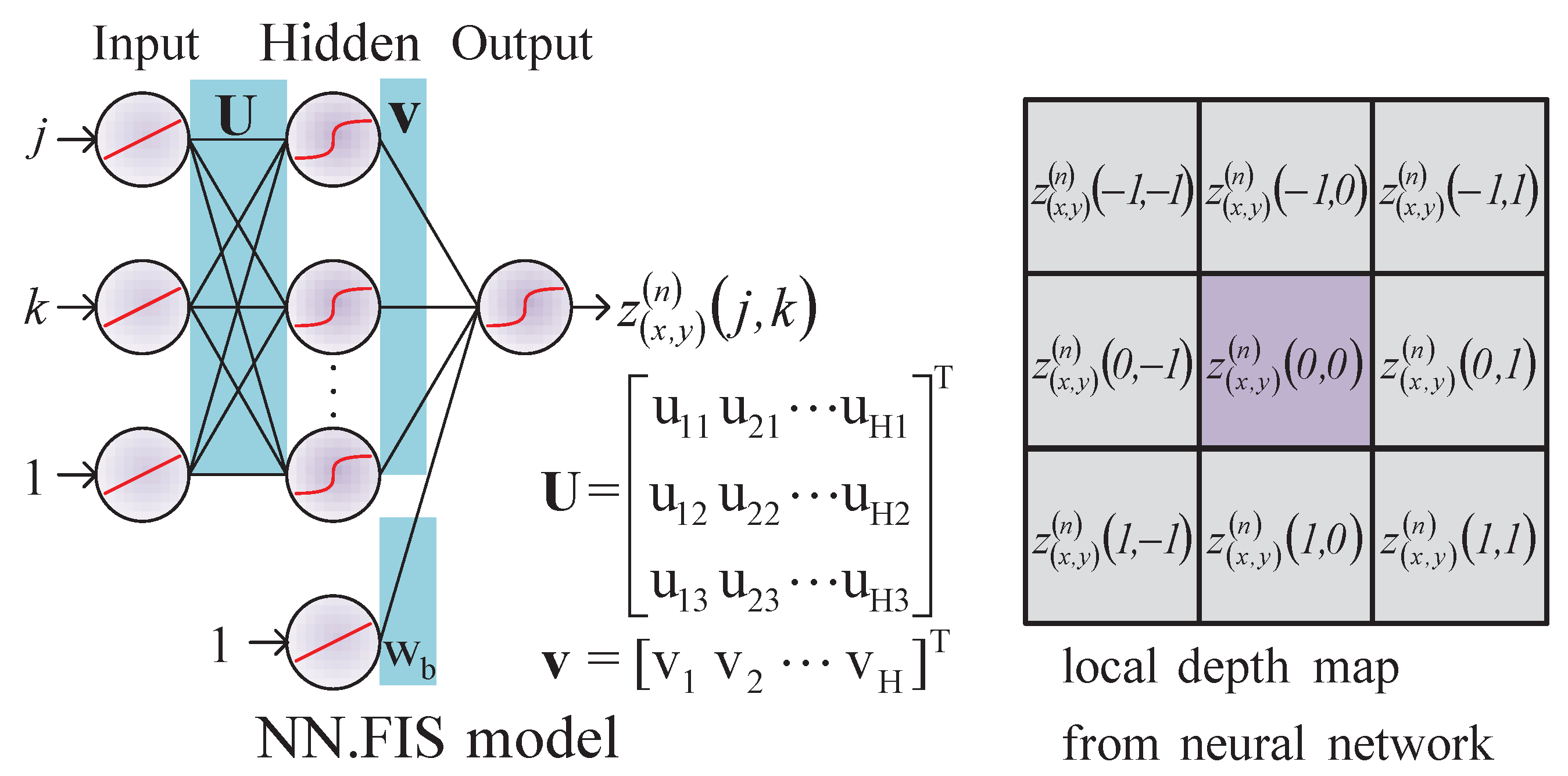
3.1. Neural Network Model over FIS
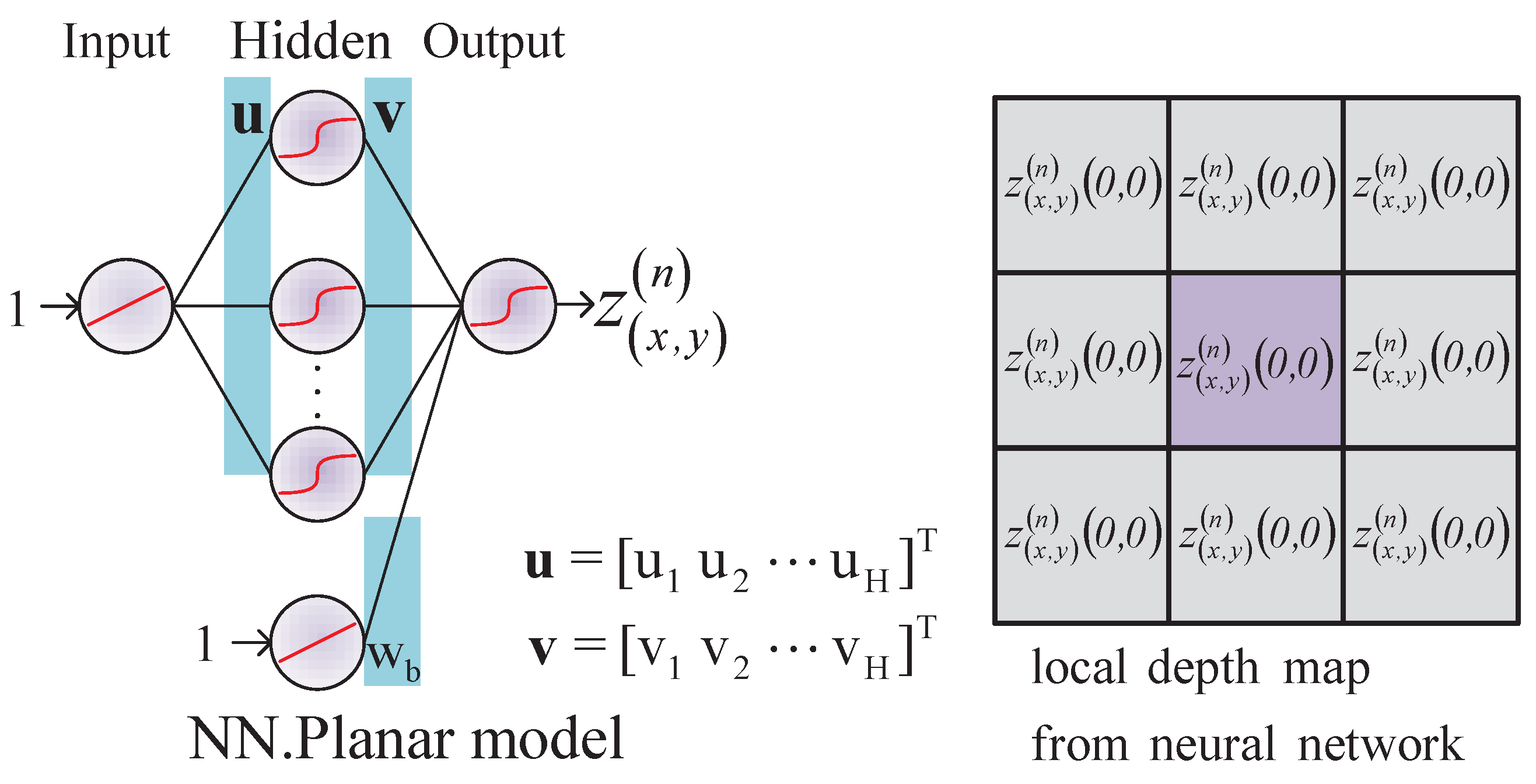
3.2. Proposed Model
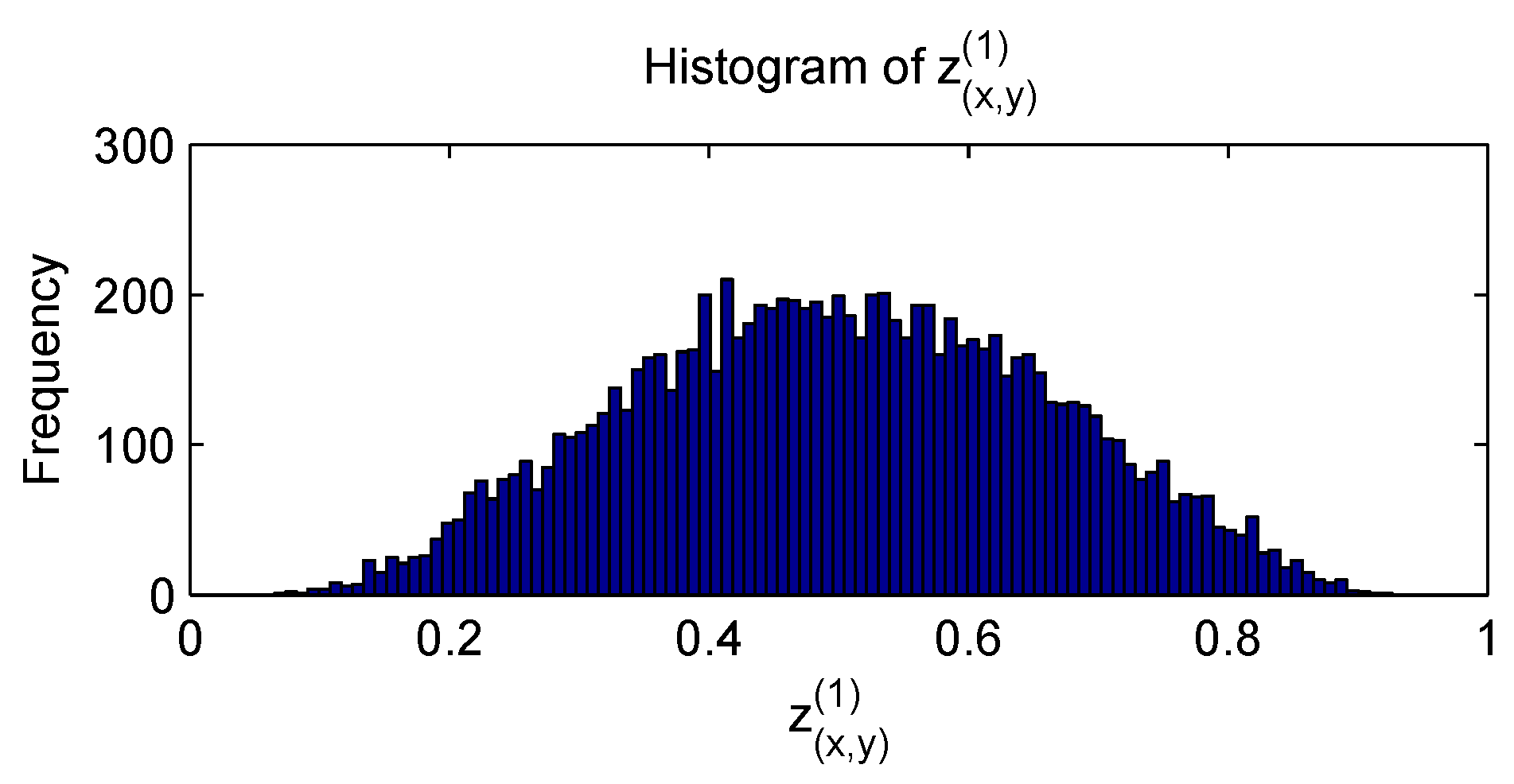
4. Initial Weight Setting
4.1. RS Initial Weight Setting Method
| Algorithm 1. Random Setting method. |
|
4.2. Proposed WP Method
| Algorithm 2. Weight Passing method. |
|
5. Experiments
5.1. Experimental Setup
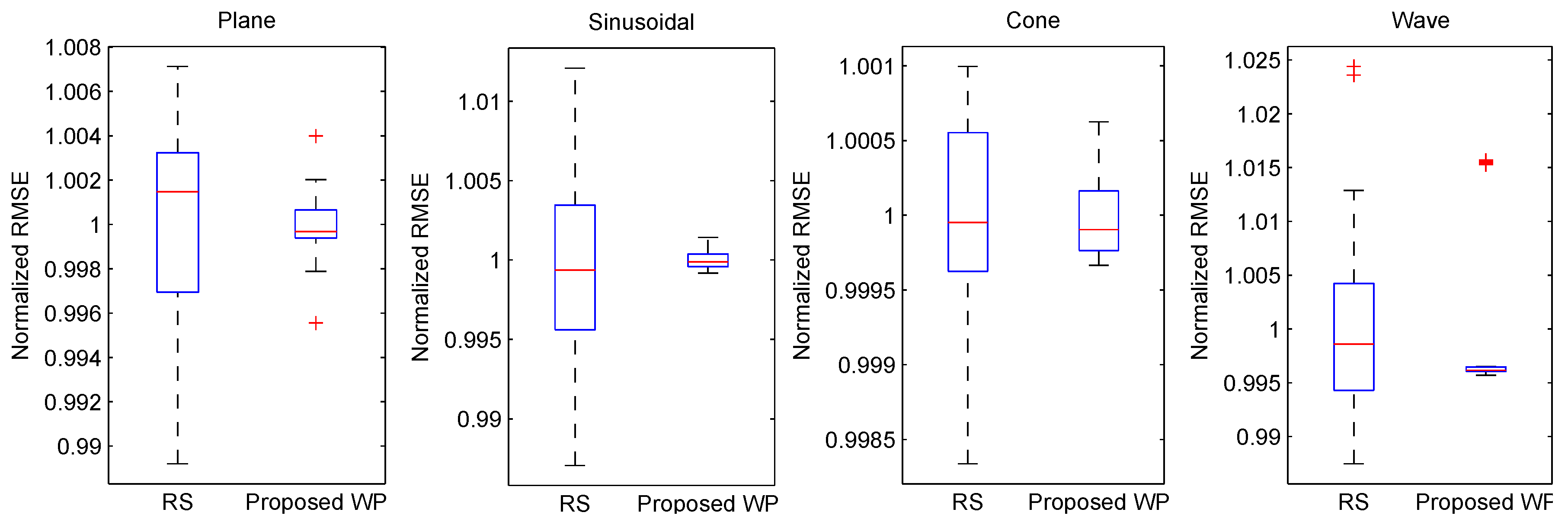
5.2. Quantitative Analysis
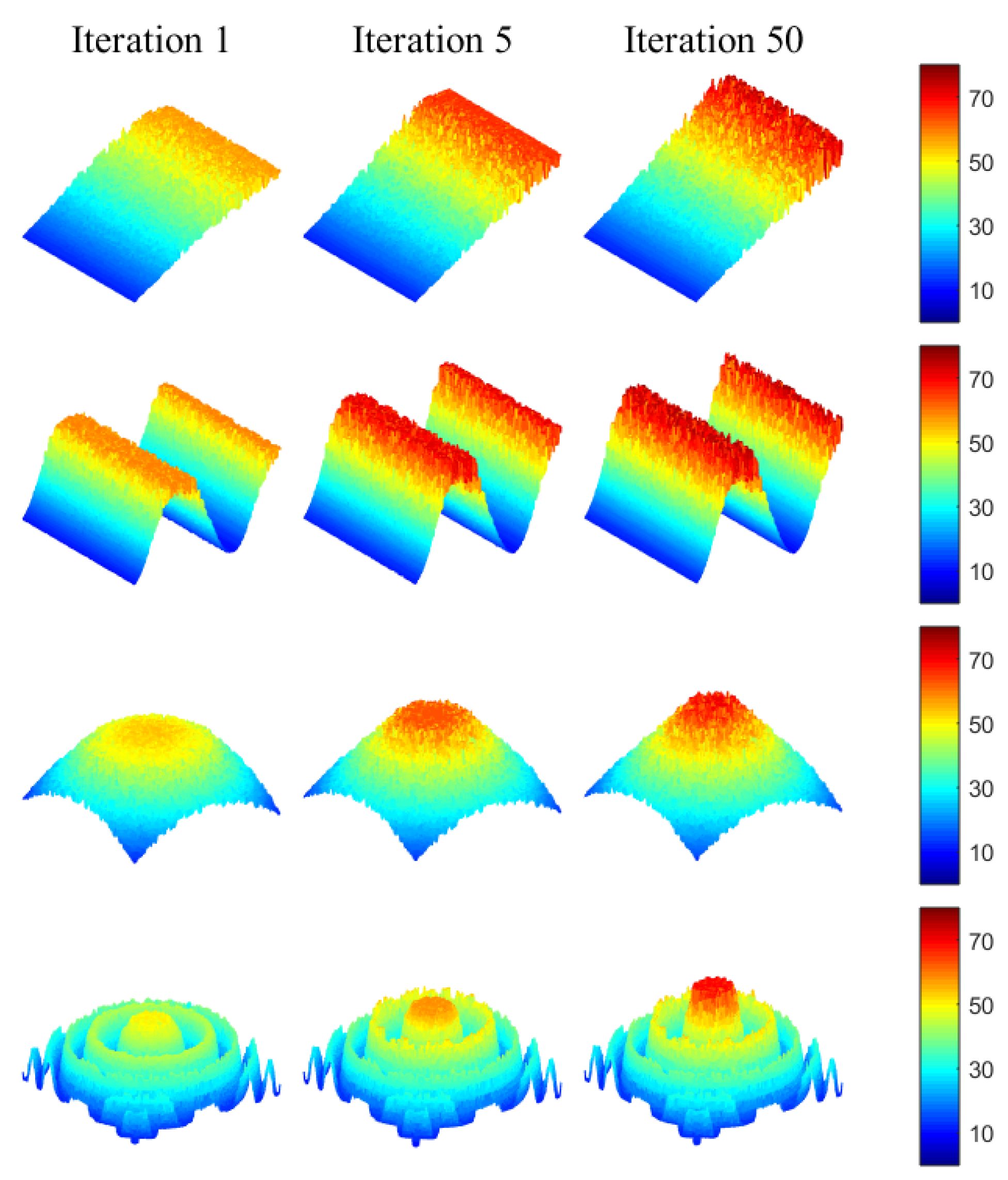
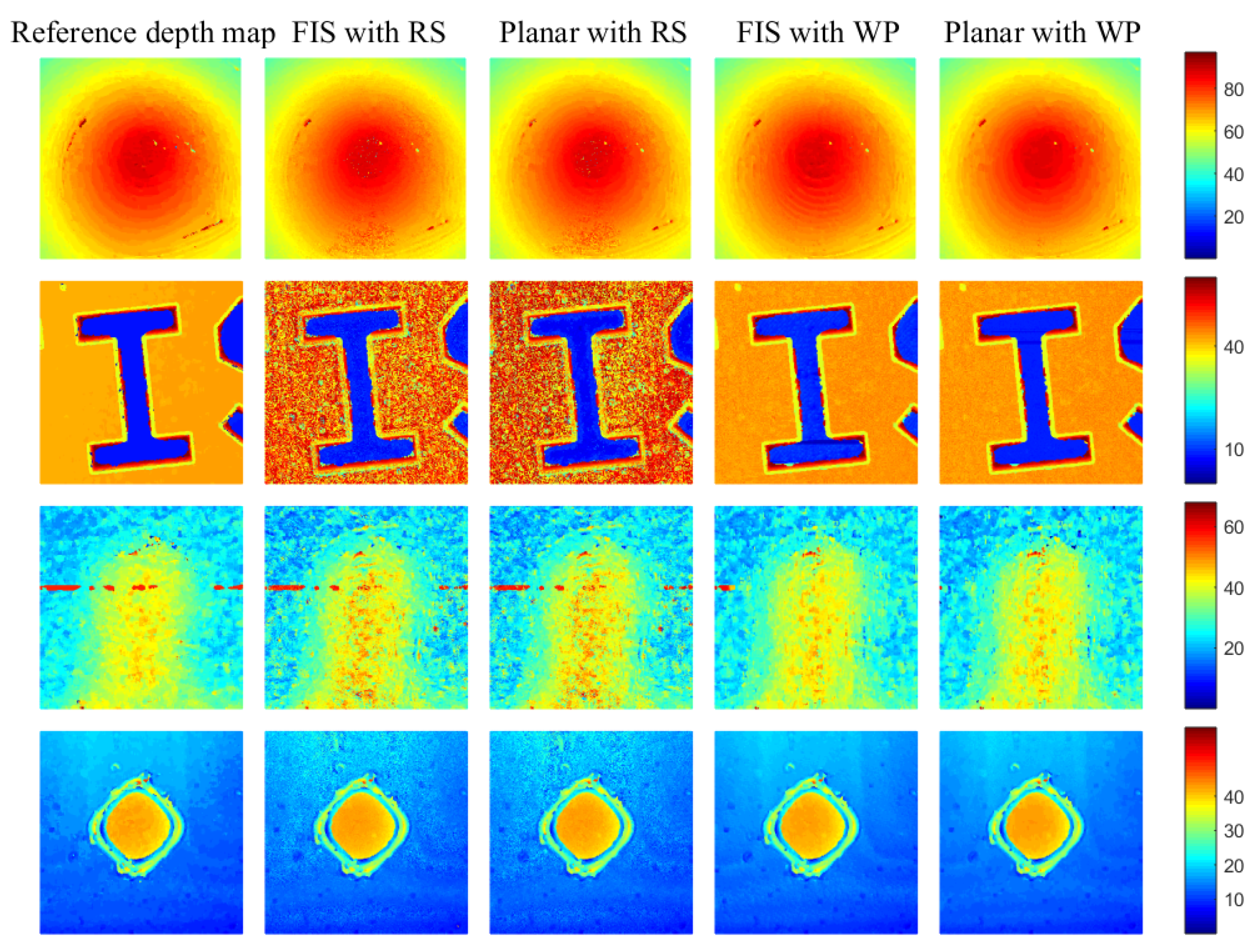
5.3. Qualitative Analysis
6. Discussion
7. Conclusions
8. Patents
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, I.H.; Mahmood, M.T.; Choi, T.S. Robust Depth Estimation and Image Fusion Based on Optimal Area Selection. Sensors 2013, 13, 11636–11652. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, M.; Choi, T.S. Application of Three Dimensional Shape from Image Focus in LCD/TFT Displays Manufacturing. IEEE Trans. Consum. Electron. 2007, 53, 1–4. [Google Scholar] [CrossRef]
- Mahmood, M. MRT letter: Guided filtering of image focus volume for 3D shape recovery of microscopic objects. Microsc. Res. Tech. 2014, 77, 959–963. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, M.; Choi, T.S. Nonlinear Approach for Enhancement of Image Focus Volume in Shape from Focus. IEEE Trans. Image Process. 2012, 21, 2866–2873. [Google Scholar] [CrossRef] [PubMed]
- Thelen, A.; Frey, S.; Hirsch, S.; Hering, P. Improvements in Shape-From-Focus for Holographic Reconstructions with Regard to Focus Operators, Neighborhood-Size, and Height Value Interpolation. IEEE Trans. Image Process. 2009, 18, 151–157. [Google Scholar] [CrossRef] [PubMed]
- Tang, H.; Cohen, S.; Price, B.; Schiller, S.; Kutulakos, K.N. Depth from Defocus in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4773–4781. [Google Scholar] [CrossRef]
- Frommer, Y.; Ben-Ari, R.; Kiryati, N. Shape from Focus with Adaptive Focus Measure and High Order Derivatives. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; p. 134. [Google Scholar] [CrossRef]
- Suwajanakorn, S.; Hernandez, C.; Seitz, S.M. Depth from focus with your mobile phone. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3497–3506. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; Available online: https://www.springer.com/us/book/9780387310732 (accessed on 13 September 2018).
- Asif, M.; Choi, T.S. Shape from focus using multilayer feedforward neural networks. IEEE Trans. Image Process. 2001, 10, 1670–1675. [Google Scholar] [CrossRef] [PubMed]
- Malik, A.S.; Choi, T.S. Consideration of illumination effects and optimization of window size for accurate calculation of depth map for 3D shape recovery. Pattern Recognit. 2007, 40, 154–170. [Google Scholar] [CrossRef]
- Pertuz, S.; Puig, D.; Garcia, M.A. Analysis of focus measure operators for shape-from-focus. Pattern Recognit. 2013, 46, 1415–1432. [Google Scholar] [CrossRef]
- Huang, W.; Jing, Z. Evaluation of focus measures in multi-focus image fusion. Pattern Recognit. Lett. 2007, 28, 493–500. [Google Scholar] [CrossRef]
- Ahmad, M.; Choi, T.S. A heuristic approach for finding best focused shape. IEEE Trans. Circuits Syst. Video Technol. 2005, 15, 566–574. [Google Scholar] [CrossRef]
- Boshtayeva, M.; Hafner, D.; Weickert, J. A focus fusion framework with anisotropic depth map smoothing. Pattern Recognit. 2015, 48, 3310–3323. [Google Scholar] [CrossRef]
- Hariharan, R.; Rajagopalan, A. Shape-From-Focus by Tensor Voting. IEEE Trans. Image Process. 2012, 21, 3323–3328. [Google Scholar] [CrossRef] [PubMed]
- Tseng, C.Y.; Wang, S.J. Shape-From-Focus Depth Reconstruction with a Spatial Consistency Model. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 2063–2076. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; de Silva, V.; Langford, J.C. A Global Geometric Framework for Nonlinear Dimensionality Reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Shlens, J. A Tutorial on Principal Component Analysis. arXiv, 2014; arXiv:1404.1100. [Google Scholar]
- Borg, I.; Groenen, P.J.; Mair, P. Applied Multidimensional Scaling and Unfolding, 2nd ed.; Springer: New York, NY, USA, 2018; Available online: https://www.springer.com/gb/book/9783319734705 (accessed on 13 September 2018).
- Cao, L.; Chua, K.; Chong, W.; Lee, H.; Gu, Q. A comparison of PCA, KPCA and ICA for dimensionality reduction in support vector machine. Neurocomputing 2003, 55, 321–336. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Niyogi, P. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal Deep Learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning (ICML’11), Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 689–696. [Google Scholar]
- Mousas, C.; Anagnostopoulos, C.N. Learning Motion Features for Example-Based Finger Motion Estimation for Virtual Characters. 3D Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Nam, J.; Herrera, J.; Slaney, M.; Smith, J. Learning Sparse Feature Representations for Music Annotation and Retrieval. In Proceedings of the 2012 International Society for Music Information Retrieval (ISMIR), Porto, Portugal, 8–12 October 2012; pp. 565–570. [Google Scholar]
- Asif, M. Shape from Focus Using Multilayer Feedforward Neural Networks. Master’s Thesis, Gwangju Institute of Science and Technology, Gwangju, Korea, 1999. [Google Scholar]
- Pertuz, S. Defocus Simulation. Available online: https://kr.mathworks.com/matlabcentral/fileexchange/55095-defocus-simulation (accessed on 12 September 2018).
- Favaro, P.; Soatto, S.; Burger, M.; Osher, S.J. Shape from Defocus via Diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 518–531. [Google Scholar] [CrossRef] [PubMed]
- Holden, D.; Komura, T.; Saito, J. Phase-functioned Neural Networks for Character Control. ACM Trans. Graph. 2017, 36, 42. [Google Scholar] [CrossRef]
- Mousas, C.; Newbury, P.; Anagnostopoulos, C.N. Evaluating the Covariance Matrix Constraints for Data-driven Statistical Human Motion Reconstruction. In Proceedings of the 30th Spring Conference on Computer Graphics (SCCG’14), Smolenice, Slovakia, 28–30 May 2014; ACM: New York, NY, USA, 2014; pp. 99–106. [Google Scholar] [CrossRef]
- Mousas, C.; Newbury, P.; Anagnostopoulos, C.N. Data-Driven Motion Reconstruction Using Local Regression Models. In Artificial Intelligence Applications and Innovations, Proceedings of the 10th IFIP International Conference on Artificial Intelligence Applications and Innovations (AIAI), Rhodes, Greece, September 2014; Iliadis, L., Maglogiannis, I., Papadopoulos, H., Eds.; Part 8: Image—Video Processing; Springer: Berlin/Heidelberg, Germany, 2014; Volume AICT-436, pp. 364–374. Available online: https://hal.inria.fr/IFIP-AICT-436/hal-01391338 (accessed on 13 September 2018). [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Cheron, G.; Laptev, I.; Schmid, C. P-CNN: Pose-based CNN Features for Action Recognition. arXiv, 2015; arXiv:1506.03607. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Penn, G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4277–4280. [Google Scholar]
- Saito, S.; Wei, L.; Hu, L.; Nagano, K.; Li, H. Photorealistic Facial Texture Inference Using Deep Neural Networks. arXiv, 2016; arXiv:1612.00523. [Google Scholar]
- Li, R.; Si, D.; Zeng, T.; Ji, S.; He, J. Deep Convolutional Neural Networks for Detecting Secondary Structures in Protein Density Maps from Cryo-Electron Microscopy. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine, Shenzhen, China, 15–18 December 2016; pp. 41–46. [Google Scholar]
- Li, Z.; Zhou, Y.; Xiao, S.; He, C.; Li, H. Auto-Conditioned LSTM Network for Extended Complex Human Motion Synthesis. arXiv, 2017; arXiv:1707.05363. [Google Scholar]
- Bilmes, J.; Bartels, C. Graphical model architectures for speech recognition. IEEE Signal Process Mag. 2005, 22, 89–100. [Google Scholar] [CrossRef]
- Kim, H.J.; Mahmood, M.T.; Choi, T.S. A Method for Reconstruction 3-D Shapes Using Neural Netwok. Korea Patent 1,018,166,630,000, 2018. Available online: https://doi.org/10.8080/1020160136767 (accessed on 9 January 2018).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
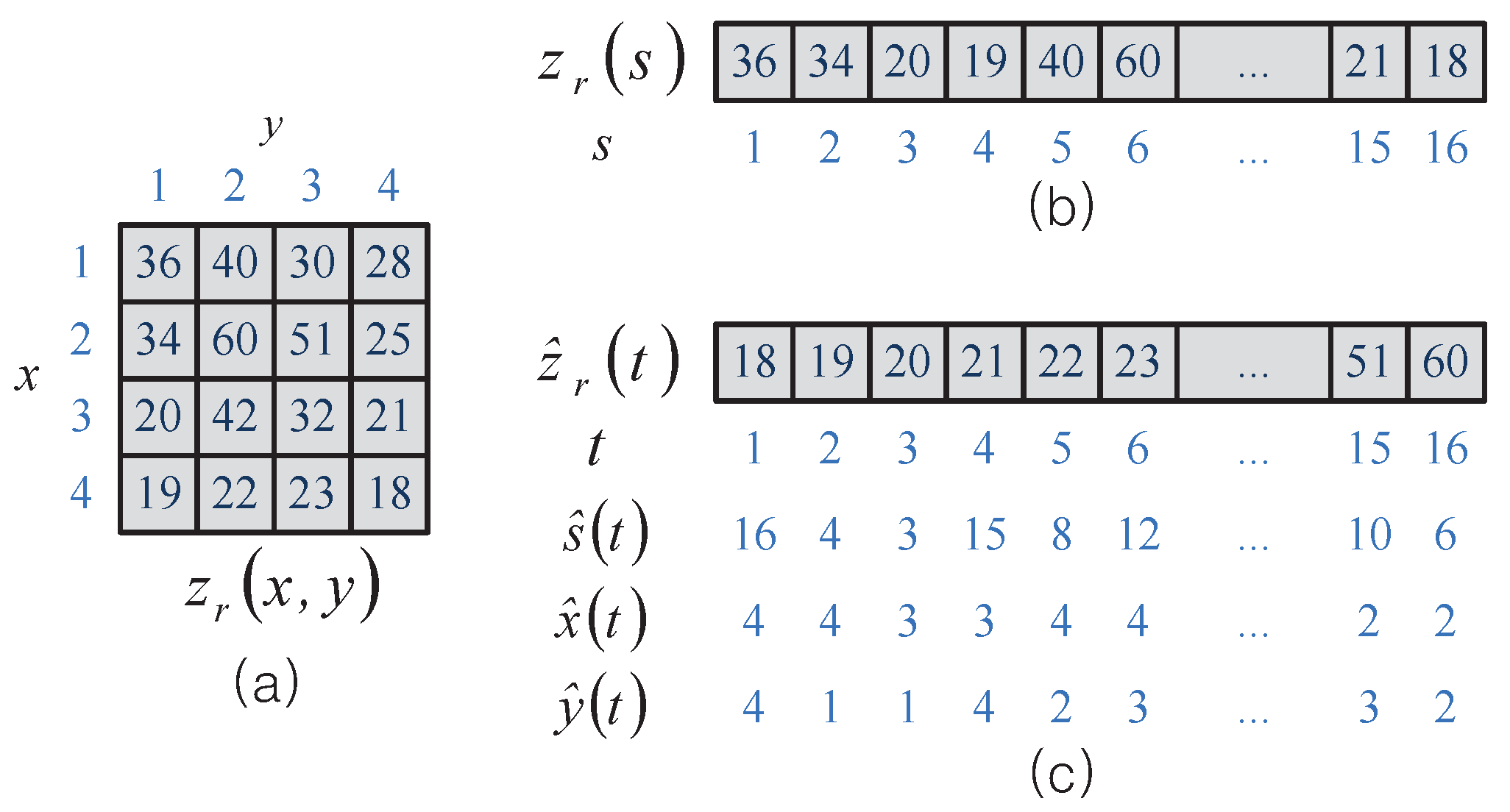{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | SML | GLV | FIS with RS | Planar with RS | FIS with WP | Planar with WP |
|---|---|---|---|---|---|---|
| RMSE (Corr) | RMSE (Corr) | RMSE (Corr) | RMSE (Corr) | RMSE (Corr) | RMSE (Corr) | |
| Plane | 4.589 (0.970) | 3.805 (0.979) | 4.196 (0.972) | 4.073 (0.974) | 3.217 0.985) | 3.215 (0.985) |
| Sinusoidal | 4.649 (0.978) | 3.782 (0.985) | 4.630 (0.977) | 4.505 (0.978) | 3.092 (0.990) | 3.128 (0.990) |
| Cone | 8.548 (0.957) | 8.462 (0.971) | 8.567 (0.967) | 8.503 (0.970) | 8.402 (0.978) | 8.395 (0.978) |
| Wave | 2.824 (0.979) | 2.004 (0.989) | 2.581 (0.981) | 2.366 (0.984) | 1.644 (0.992) | 1.661 (0.992) |
| Object | SML | GLV | FIS with RS | Planar with RS | FIS with WP | Planar with WP |
|---|---|---|---|---|---|---|
| Plane | 17.8 | 24.6 | 15,347.3 | 2837.5 | 12,377.9 | 130.9 |
| Sinusoidal | 17.9 | 24.6 | 18,169.5 | 5336.5 | 12,504.5 | 129.9 |
| Cone | 17.8 | 24.8 | 13,183.0 | 928.4 | 12,922.5 | 135.9 |
| Wave | 17.8 | 24.6 | 13,829.0 | 977.9 | 12,595.6 | 130.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.-J.; Mahmood, M.T.; Choi, T.-S. An Efficient Neural Network for Shape from Focus with Weight Passing Method. Appl. Sci. 2018, 8, 1648. https://doi.org/10.3390/app8091648
Kim H-J, Mahmood MT, Choi T-S. An Efficient Neural Network for Shape from Focus with Weight Passing Method. Applied Sciences. 2018; 8(9):1648. https://doi.org/10.3390/app8091648
Chicago/Turabian StyleKim, Hyo-Jong, Muhammad Tariq Mahmood, and Tae-Sun Choi. 2018. "An Efficient Neural Network for Shape from Focus with Weight Passing Method" Applied Sciences 8, no. 9: 1648. https://doi.org/10.3390/app8091648
APA StyleKim, H.-J., Mahmood, M. T., & Choi, T.-S. (2018). An Efficient Neural Network for Shape from Focus with Weight Passing Method. Applied Sciences, 8(9), 1648. https://doi.org/10.3390/app8091648