Prediction of Preoperative Blood Preparation for Orthopedic Surgery Patients: A Supervised Learning Approach


 ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Source
2.2. Variable Definition and Selection
2.3. Investigated Classification Techniques
2.4. Experimental Setup and Performance Measure
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Larocque, B.; Brien, W.F.; Gilbert, K. The utility and prediction of allogeneic blood transfusion use in orthopedic surgery. Transfus. Med. Rev. 1999, 13, 124–131. [Google Scholar] [CrossRef]
- Shander, A.; Hofmann, A.; Isbister, J.; Van Aken, H. Patient blood management—The new frontier. Best Pract. Res. Clin. Anaesthesiol. 2013, 27, 5–10. [Google Scholar] [CrossRef] [PubMed]
- Salido, J.A.; Marín, L.A.; Gómez, L.A.; Zorrilla, P.; Martínez, C. Preoperative hemoglobin levels and the need for transfusion after prosthetic hip and knee surgery analysis of predictive factors. J. Bone Jt. Surg. 2002, 84, 216–220. [Google Scholar] [CrossRef]
- Hillyer, C.; Hillyer, K.L.; Strobl, F.; Jefferies, L.; Silberstein, L. (Eds.) Handbook of Transfusion Medicine; Academic Press: New York, NY, USA, 2001. [Google Scholar]
- Rinehart, J.B.; Lee, T.C.; Kaneshiro, K.; Tran, M.H.; Sun, C.; Kain, Z.N. Perioperative blood ordering optimization process using information from an anesthesia information management system. Transfusion 2016, 56, 938–945. [Google Scholar] [CrossRef] [PubMed]
- Woodrum, C.L.; Wisniewski, M.; Triulzi, D.J.; Waters, J.H.; Alarcon, L.H.; Yazer, M.H. The effects of a data driven maximum surgical blood ordering schedule on preoperative blood ordering practices. Hematology 2017, 22, 571–577. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.K.; Trethewey, D.; Brousseau, P.; Sadek, I. Creation of a maximum surgical blood ordering schedule via novel low-overhead database method. Transfusion 2008, 48, 2268–2269. [Google Scholar] [PubMed]
- Barr, P.J.; Donnelly, M.; Cardwell, C.; Alam, S.S.; Morris, K.; Parker, M.; Bailie, K.E.M. Drivers of transfusion decision making and quality of the evidence in orthopedic surgery: A systematic review of the literature. Transfus. Med. Rev. 2011, 25, 304–316. [Google Scholar] [CrossRef] [PubMed]
- Guerin, S.; Collins, C.; Kapoor, H.; McClean, I.; Collins, D. Blood transfusion requirement prediction in patients undergoing primary total hip and knee arthroplasty. Transfus. Med. 2007, 17, 37–43. [Google Scholar] [CrossRef] [PubMed]
- Kadar, A.; Chechik, O.; Steinberg, E.; Reider, E.; Sternheim, A. Predicting the need for blood transfusion in patients with hip fractures. Int. Orthop. 2013, 37, 693–700. [Google Scholar] [CrossRef] [PubMed]
- Pavesi, M.; Inghilleri, G.; Albano, G.; Ricci, C.; Gaeta, M.; Randelli, F. A predictive model to reduce allogenic transfusions in primary total hip arthroplasty. Transfus. Apher. Sci. 2011, 45, 265–268. [Google Scholar] [CrossRef] [PubMed]
- Schumer, R.A.; Chae, J.S.; Markert, R.J.; Sprott, D.; Crosby, L.A. Predicting transfusion in shoulder arthroplasty. J. Shoulder Elb. Surg. 2010, 19, 91–96. [Google Scholar] [CrossRef] [PubMed]
- Inghilleri, G. Prediction of transfusion requirements in surgical patients: A review. Transfus. Altern. Transfus. Med. 2010, 11, 10–19. [Google Scholar] [CrossRef]
- Abdel, M.P.; Morrey, B.F. Implications of revision total elbow arthroplasty on blood transfusion. J. Shoulder Elb. Surg. 2010, 19, 190–195. [Google Scholar] [CrossRef] [PubMed]
- Lošťák, J.; Galo, J.; Mlčůchová, D. Multivariate Analysis of Blood Loss during Primary Total Hip or Knee Arthroplasty. Acta Chir. Orthop. Traumatol. Cech. 2012, 80, 219–225. [Google Scholar]
- Huang, F.; Wu, D.; Ma, G.; Yin, Z.; Wang, Q. The use of tranexamic acid to reduce blood loss and transfusion in major orthopedic surgery: A meta-analysis. J. Surg. Res. 2014, 186, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.G.; Chen, W.P.; Wu, L.D. Effectiveness and safety of tranexamic acid in reducing blood loss in total knee arthroplasty: A meta-analysis. J. Bone Jt. Surg. 2012, 94, 1153–1159. [Google Scholar] [CrossRef] [PubMed]
- Walczak, S.; Scharf, J.E. Reducing surgical patient costs through use of an artificial neural network to predict transfusion requirements. Decis. Support Syst. 2000, 30, 125–138. [Google Scholar] [CrossRef]
- Ahmadi, S.; Lawrence, T.M.; Sahota, S.; Schleck, C.D.; Harmsen, W.S.; Cofield, R.H.; Sperling, J.W. The incidence and risk factors for blood transfusion in revision shoulder arthroplasty: Our institution’s experience and review of the literature. J. Shoulder Elb. Surg. 2014, 23, 43–48. [Google Scholar] [CrossRef] [PubMed]
- Fosco, M.; Di Fiore, M. Factors predicting blood transfusion in different surgical procedures for degenerative spine disease. Eur. Rev. Med. Pharmacol. Sci. 2012, 16, 1853–1888. [Google Scholar] [PubMed]
- Hardy, J.C.; Hung, M.; Snow, B.J.; Martin, C.L.; Tashjian, R.Z.; Burks, R.T.; Greis, P.E. Blood transfusion associated with shoulder arthroplasty. J. Shoulder Elb. Surg. 2013, 22, 233–239. [Google Scholar] [CrossRef] [PubMed]
- Pinto Garcı́a, V. Assessment of perioperative blood transfusion in cardiac surgery using administrative data. Transfus. Sci. 2000, 23, 75–81. [Google Scholar] [CrossRef]
- Van Klei, W.A.; Moons, K.G.M.; Leyssius, A.T.R.; Knape, J.T.A.; Rutten, C.L.G.; Grobbee, D.E. A reduction in type and screen: Preoperative prediction of RBC transfusions in surgery procedures with intermediate transfusion risks. Br. J. Anaesth. 2001, 87, 250–257. [Google Scholar] [CrossRef] [PubMed]
- Quijada, J.L.; Hurtado, P.; de Lamo, J. Factors that increase the risk of blood transfusion in patients with hip fractures. Revista Española de Cirugía Ortopédica y Traumatología (English Edition) 2011, 55, 35–38. [Google Scholar] [CrossRef]
- Mathai, K.M.; Kang, J.D.; Donaldson, W.F.; Lee, J.Y.; Buffington, C.W. Prediction of blood loss during surgery on the lumbar spine with the patient supported prone on the Jackson table. Spine J. 2012, 12, 1103–1110. [Google Scholar] [CrossRef] [PubMed]
- Browne, J.A.; Adib, F.; Brown, T.E.; Novicoff, W.M. Transfusion rates are increasing following total hip arthroplasty: Risk factors and outcomes. J. Arthroplast. 2013, 28, 34–37. [Google Scholar] [CrossRef] [PubMed]
- Jiawei, H.; Kamber, M. Data Mining: Concepts and Techniques; Morgan Kaufmann: San Francisco, CA, USA, 2001. [Google Scholar]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kennedy, R.L.; Lee, Y.; Van Roy, B.; Reed, C.D.; Lippmann, R.P. Solving Data Mining Problems through Pattern Recognition; Prentice Hall PTR: Indianapolis, IN, USA, 1997. [Google Scholar]
- Cabena, P.; Hadjinian, P.; Stadler, R.; Verhees, J.; Zanasi, A. Discovering Data Mining: From Concept to Implementation; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 16–18 November 1992; pp. 343–348. [Google Scholar]
- Pola, E.; Papaleo, P.; Santoliquido, A.; Gasparini, G.; Aulisa, L.; Santis, E.D. Clinical factors associated with an increased risk of perioperative blood transfusion in nonanemic patients undergoing total hip arthroplasty. J. Bone Jt. Surg. Am. 2004, 86, 57–61. [Google Scholar] [CrossRef]
- Dillon, M.F.; Collins, D.; Rice, J.; Murphy, P.G.; Nicholson, P.; Elwaine, J.M. Preoperative characteristics identify patients with hip fractures at risk of transfusion. Clin. Orthop. Relat. Res. 2005, 439, 201–206. [Google Scholar] [CrossRef] [PubMed]
- Nuttall, G.A.; Horlocker, T.T.; Santrach, P.J.; Oliver, W.C.; Dekutoski, M.B.; Bryant, S. Predictors of blood transfusion in spinal instrumentation and fusion surgery. Spine 2000, 25, 596–601. [Google Scholar] [CrossRef] [PubMed]
- Van Klei, W.A.; Leyssius, A.T.R.; Grobbee, D.E.; Moons, K.G.M. Identifying patients for blood conservations strategies. Br. J. Surg. 2002, 89, 1176–1182. [Google Scholar] [CrossRef] [PubMed]
- Frish, N.B.; Wessell, N.M.; Charters, M.A.; Yu, S.; Jeffries, J.J.; Silverton, C.D. Predictors and complications of blood transfusion in total hip and knee arthroplasty. J. Arthroplast. 2014, 29, 189–192. [Google Scholar] [CrossRef] [PubMed]
- Roubinian, N.H.; Murphy, E.L.; Swain, B.E.; Gardner, M.N.; Liu, V.; Escobar, G.J. Predicting red blood cell transfusion in hospitalized patients: Role of hemoglobin level, comorbidities, and illness severity. BMC Health Serv. Res. 2014, 14, 213. [Google Scholar] [CrossRef] [PubMed]
- Mesa-Ramos, F.; Mesa-Ramos, M.; Maquieira-Canosa, C.; Carpintero, P. Predictors for blood transfusion following total knee arthroplasty: A prospective randomised study. Acta Orthop. Belg. 2008, 74, 83–89. [Google Scholar] [PubMed]


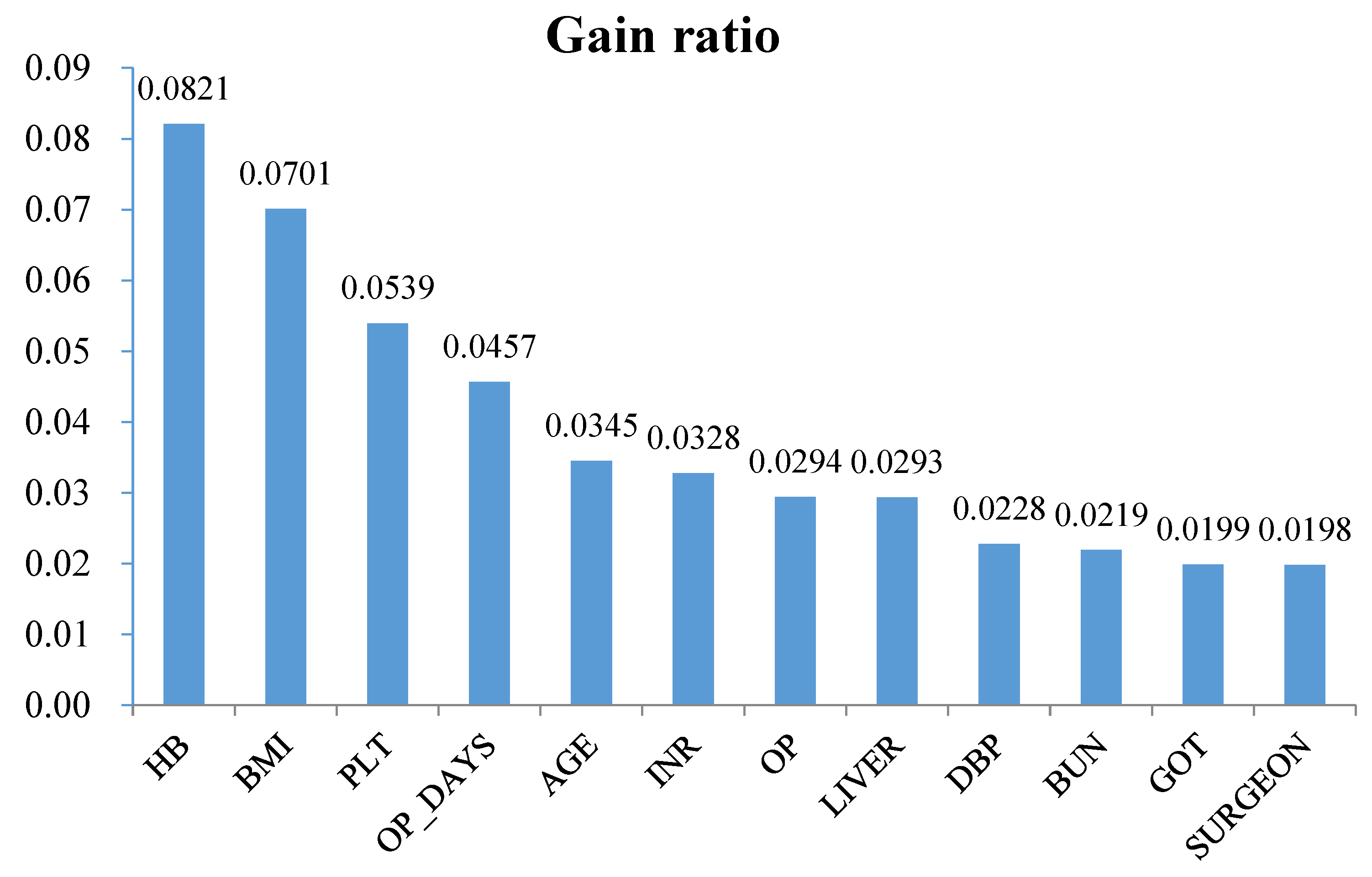{kind=link}
| Category | Variable Name | Definition | Type |
|---|---|---|---|
| Demographic | AGE | Age | Numerical |
| GENDER | Male/Female | Categorical | |
| Body checkup | DBP | Diastolic blood pressure | Numerical |
| SBP | Systolic blood pressure | Numerical | |
| BT | Body temperature | Numerical | |
| HR | Heartbeat rate | Numerical | |
| RR | Respiratory rate | Numerical | |
| BMI | Body mass index (kg/m2) | Numerical | |
| Laboratory | HB | Hemoglobin | Numerical |
| PLT | Platelets | Numerical | |
| INR | International normalized ratio | Numerical | |
| APTT | Activated Partial Thromboplastin Time | Numerical | |
| GOT | Glutamic-pyruvic transaminase | Numerical | |
| GPT | Glutamic-oaa transaminase | Numerical | |
| BUN | Blood urea nitrogen | Numerical | |
| CRT | Creatinine | Numerical | |
| NA | Na | Numerical | |
| K | K | Numerical | |
| GLU | Blood glucose | Numerical | |
| Surgery | SURGEON | Surgeon ID | Categorical |
| OP | Surgery category (ICD-9-CM code) | Categorical | |
| ASA | American Society of Anesthesiologists (ASA) class (ASA I/ASA II/ASA III/ASA IV/ASA V) | Categorical | |
| ANES_TYPE | Anesthesia type (GA-tube/GA-LM/SA/EA) | Categorical | |
| TU | The use of tourniquet (Yes/No) | Categorical | |
| EM_SUR | Emergency surgery (Yes/No) | Categorical | |
| OP_DAYS | (Wait OP days) | Numerical | |
| History | LUNG | Whether the patient had lung disease? (Yes/No) | Categorical |
| CVD | Whether the patient had cardiovascular disease? (Yes/No) | Categorical | |
| DM | Whether the patient had diabetes? (Yes/No) | Categorical | |
| HT | Whether the patient had hypertension? (Yes/No) | Categorical | |
| LIVER | Whether the patient had liver disease? (Yes/No) | Categorical | |
| KIDNEY | Whether the patient had renal disease? (Yes/No) | Categorical | |
| SMOKE | Whether the patient had smoke? (Yes/No) | Categorical | |
| ALCOHOL | Whether the patient had alcohol? (Yes/No) | Categorical | |
| ANTI_COA | Whether the patient had used anticoagulant drug use? (Yes/No) | Categorical |
| Predicted Class | |||
|---|---|---|---|
| Blood Transfusion | No Blood Transfusion | ||
| Actual Class | Blood Transfusion | TP | FN |
| No Blood Transfusion | FP | TN | |
| Classifier | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
| SVM | 70.8% | 78.4% | 62.3% | 70.3% |
| C4.5 | 70.3% | 69.0% | 71.7% | 72.3% |
| CART | 71.1% | 71.4% | 70.7% | 74.1% |
| LGR | 71.8% | 79.2% | 63.7% | 77.4% |
| Classifier | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
| SVM | 71.1% | 76.6% | 64.9% | 70.8% |
| C4.5 | 71.3% | 75.5% | 66.7% | 73.8% |
| CART | 71.8% | 75.6% | 67.5% | 73.9% |
| LGR | 71.7% | 77.7% | 65.1% | 78.3% |
| Classifier | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
| SVM | 71.1% | 78.0% | 63.5% | 70.7% |
| C4.5 | 72.2% | 78.6% | 65.1% | 74.5% |
| CART | 73.1% | 78.1% | 67.5% | 74.3% |
| LGR | 72.2% | 78.4% | 65.4% | 78.7% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, C.-M.; Hung, J.-H.; Hu, Y.-H.; Lee, P.-J.; Shen, C.-C. Prediction of Preoperative Blood Preparation for Orthopedic Surgery Patients: A Supervised Learning Approach. Appl. Sci. 2018, 8, 1559. https://doi.org/10.3390/app8091559
Chang C-M, Hung J-H, Hu Y-H, Lee P-J, Shen C-C. Prediction of Preoperative Blood Preparation for Orthopedic Surgery Patients: A Supervised Learning Approach. Applied Sciences. 2018; 8(9):1559. https://doi.org/10.3390/app8091559
Chicago/Turabian StyleChang, Chia-Mei, Jeng-Hsiu Hung, Ya-Han Hu, Pei-Ju Lee, and Cheng-Che Shen. 2018. "Prediction of Preoperative Blood Preparation for Orthopedic Surgery Patients: A Supervised Learning Approach" Applied Sciences 8, no. 9: 1559. https://doi.org/10.3390/app8091559
APA StyleChang, C.-M., Hung, J.-H., Hu, Y.-H., Lee, P.-J., & Shen, C.-C. (2018). Prediction of Preoperative Blood Preparation for Orthopedic Surgery Patients: A Supervised Learning Approach. Applied Sciences, 8(9), 1559. https://doi.org/10.3390/app8091559