2.1. Robotic Learning from Gestures
The robot was programmed to imitate human gestures by implementing a motion learning algorithm called “Dynamic movement primitive with Gaussian mixture regression” (DMP with GMR). A dynamic movement primitive (DMP) is a generalized gesture with specific position goals and end points joined in a sequence to create a scalable movement based on an original demonstration. Robots utilize DMPs to reproduce core movements in variable settings—for example, when the distance or pathway between the start and end goal changes. This is also referred to as “motion learning”.
Equation (1) is the basis from which all motion learning controls are developed [
10]. It is a proportional-derivative (PD) control signal, separated into three first order equations, modified to produce a custom trajectory.
is a spring damper system, where y refers to the system state,
refers to the goal state, and
refers to the velocity of the system. The constant variables
α and
β are gains, and
τ represents temporal scaling. A
τ value between 0 and 1 slows the reproduction rate, whereas a
τ value greater than 1 increases the speed. The forcing function
f(
x) allows the algorithm to create a specific trajectory, rather than taking the shortest path from the start to end goals. This is multiplied by
x, the diminishing gate, which restrains the boundaries of the trajectory in order to reach the proper end goal [
11]. Equation (1) determines a DMP in one dimension. To generate multi-dimensional movement reproductions, the equation’s forcing function is made phase dependent instead of time dependent and is run multiple times with concurrent phases.
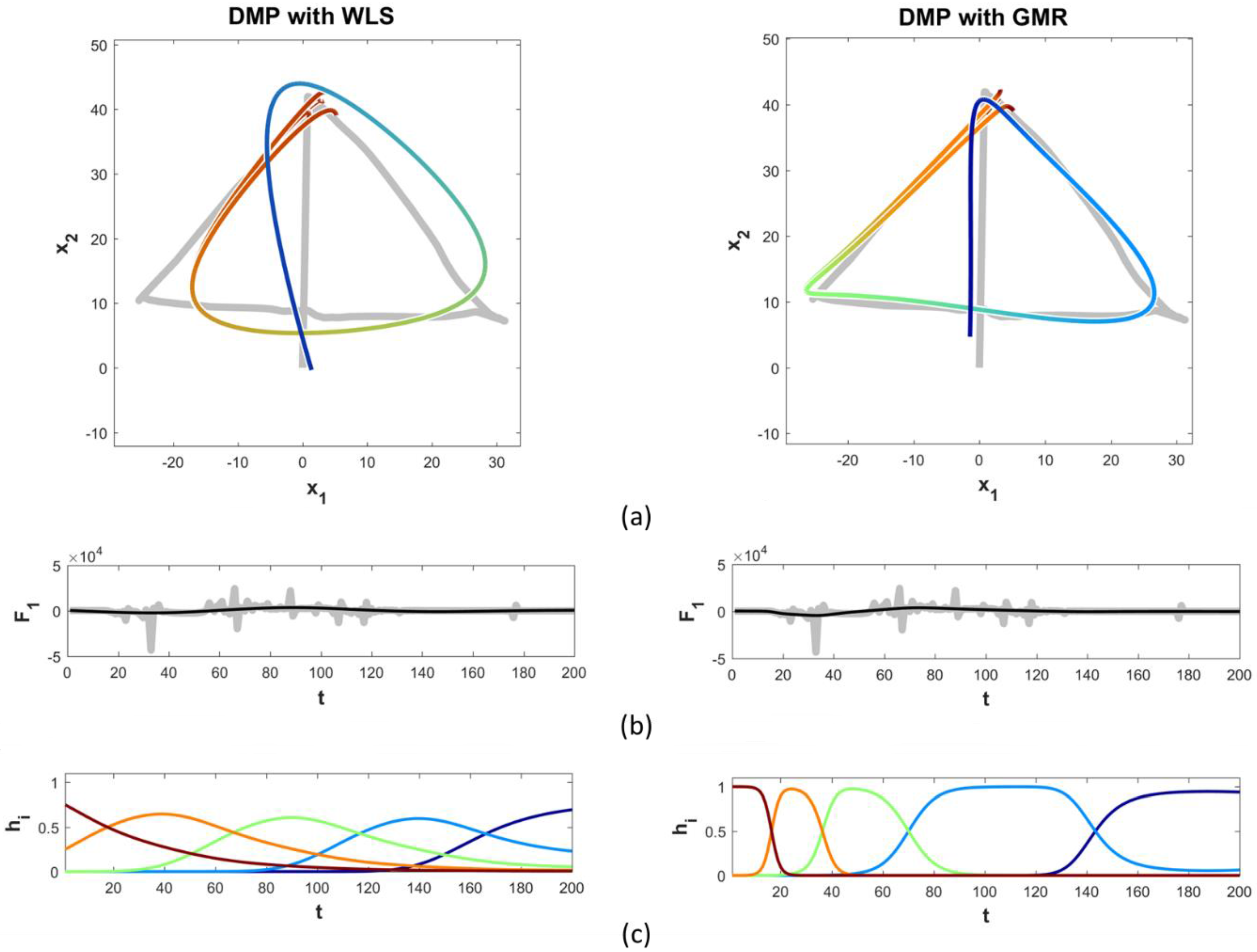
Multiple variations of motion learning algorithms were compared to determine which would be appropriate for humanoid robotic movements. Most differences in motion learning algorithms lie in how the forcing function is calculated. Forcing functions redirect the trajectory into specific movement reproductions through activation states, also referred to as activation weights. For standard DMP techniques, such as DMP with weighted least squares (WLS), the duration, position, and intensity of the activation weights are preset equidistant throughout the execution of the movement reproduction. For DMP with Gaussian mixture regression (GMR), rather than an equal distribution, the activation states are placed at key points that define the trajectory, which the algorithm identifies during learning [
11]. The results of our comparison of WLS and GMR learning algorithms can be seen in
Figure 1.
The forcing function in DMP with GMR causes the algorithm to have more precise movement reproductions than traditional methods. The forcing function is calculated using a series of statistical models. First, a Gaussian Mixture Model (GMM) plots the raw biological motion mathematically, as “data points generated from a mixture of a finite number of Gaussian distributions with unknown parameters” [
12]. Next, an expectation maximization (EM) procedure extracts important features of the GMM, including mixing coefficients, centers, and covariances of the system, to estimate the boundaries of the reproduction trajectory [
13]. This builds the trajectory. Finally, a Gaussian Mixture Regression (GMR) is implemented. This determines the velocity and acceleration with which the trajectory is traversed. GMR is used for each iteration of the system to calculate whether the magnitude of the current activation state is sufficient to maintain the desired trajectory, or whether the system must utilize the next activation state. Due to its superior results during our preliminary comparisons, DMP with GMR was chosen as the motion learning algorithm for this study.
This research brings multiple contributions to the DMP with GMR algorithm. Firstly, it adds angle-based reproduction. The original open-source DMP with GMR code solely performed point-based reproduction. In point-based reproduction, the goal state is a set of specified coordinates in three-dimensional space. The physical arrangement and angles of the robot limbs used to achieve this point are irrelevant. This can lead to unnatural limb positioning. In angle-based reproduction, the goal is for the robot’s end effector angles to match the specified angles, resulting in a pose that mimics the user’s own. We developed the code to produce angle-based replication by modifying the program inputs. The DMP with GMR algorithm plots two inputs, and then attempts to recreate the resulting line graph. Substituting angle inputs for Cartesian coordinate values resulted in angle-based reproduction values, rather than point-based ones.
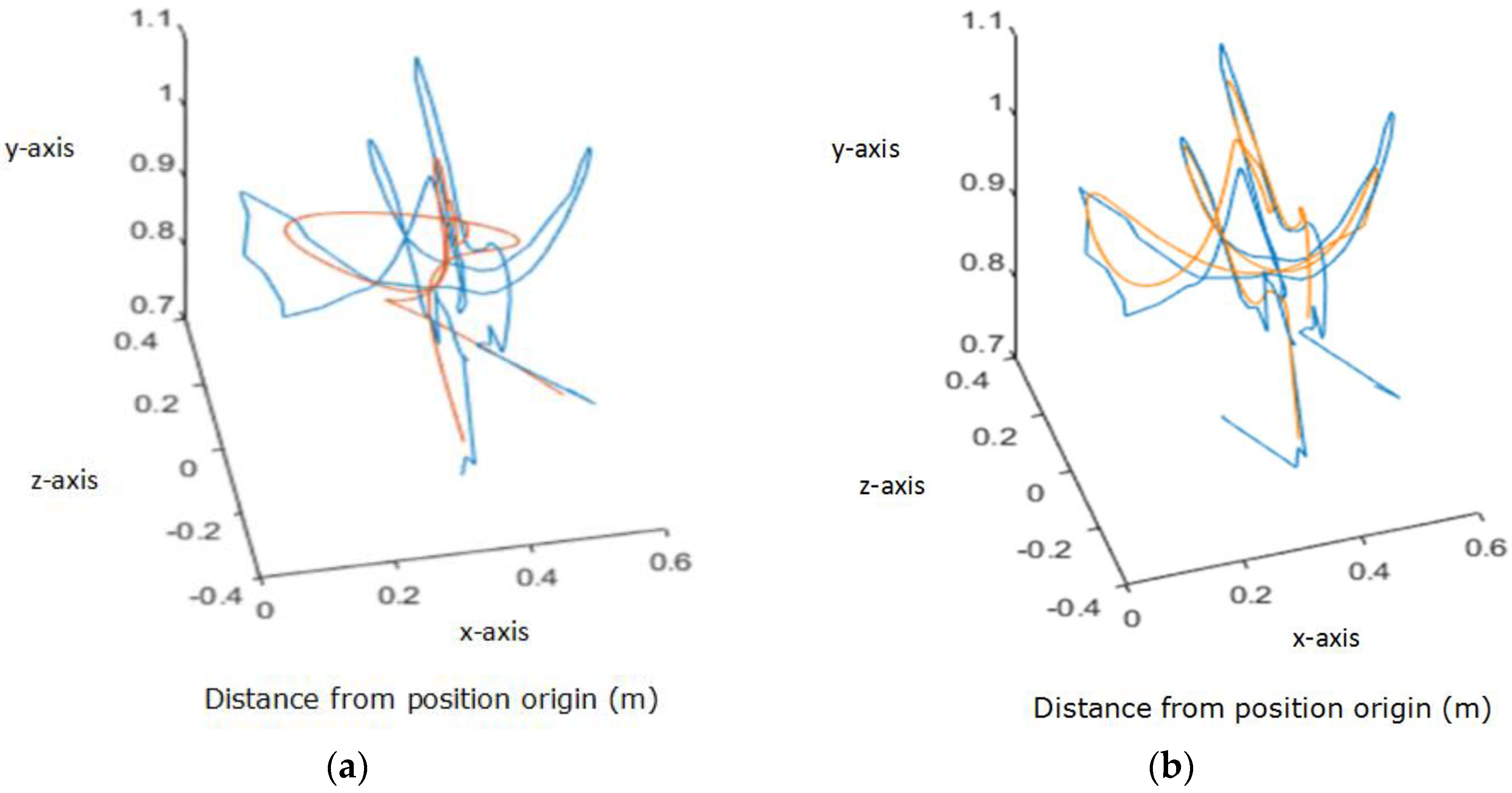
This research improved the reproduction accuracy of the algorithm by incorporating trajectory segmentation and fusion. A single user demonstration may contain multiple unique gestures, and therefore contain multiple movement primitives. However, the more primitives, or points within a primitive, are assigned to an activation state, the less accurate the reproduction will be. Additionally, there is not a linear relationship between the number of activation states implemented and the amount of time needed to run the algorithm—it takes longer to run one long segment with 20 activation states than it does to run four short segments with 5 activation states each. Therefore, in order to create the most accurate and time efficient reproduction, a trajectory should be separated into primitives before being processed by the motion learning algorithm. The segments are then rejoined before imitation, resulting in one full-length, higher accuracy reproduction. An example of this improvement to the methodology can be seen below in
Figure 2. The blue original trajectory is roughly 350 points long. On the left is the reproduction (overlaid in orange), created using the motion learning algorithm once on the entire length, using ten activation states. On the right is the reproduction created using the motion learning algorithm on 90 point segments, with a 20 point overlap between segments, also using ten activation states.
Finally, dynamic modulation of the activation state input was added to the DMP with GMR algorithm. In DMP with GMR, activation states are used to map the most drastic changes in system trajectory. The number of activation states needed vary based on the complexity of the trajectory segment presented. If too few states are used, the DMP recreation will be oversimplified beyond recognition. If too many states are used, the system will crash because it has run out of places to utilize the states. Therefore, it is imperative that the motion learning algorithm is equipped with a forcing function that can dynamically modify the number of activation states used for each new trajectory segment. A program was created that adjusts the number of activation states used in recreating a gesture, based on the accuracy of the reproduction. The percent error threshold may be modified by the user. If the reproduction is above the specified percent error, then the motion learning program is rerun with an increased number of activation states. This process is repeated until either the reproduction is within the specified percent error or the number of activation states is 25. This was determined to be the highest number of states that could be utilized before crashing the system.
2.2. Robotic Platform
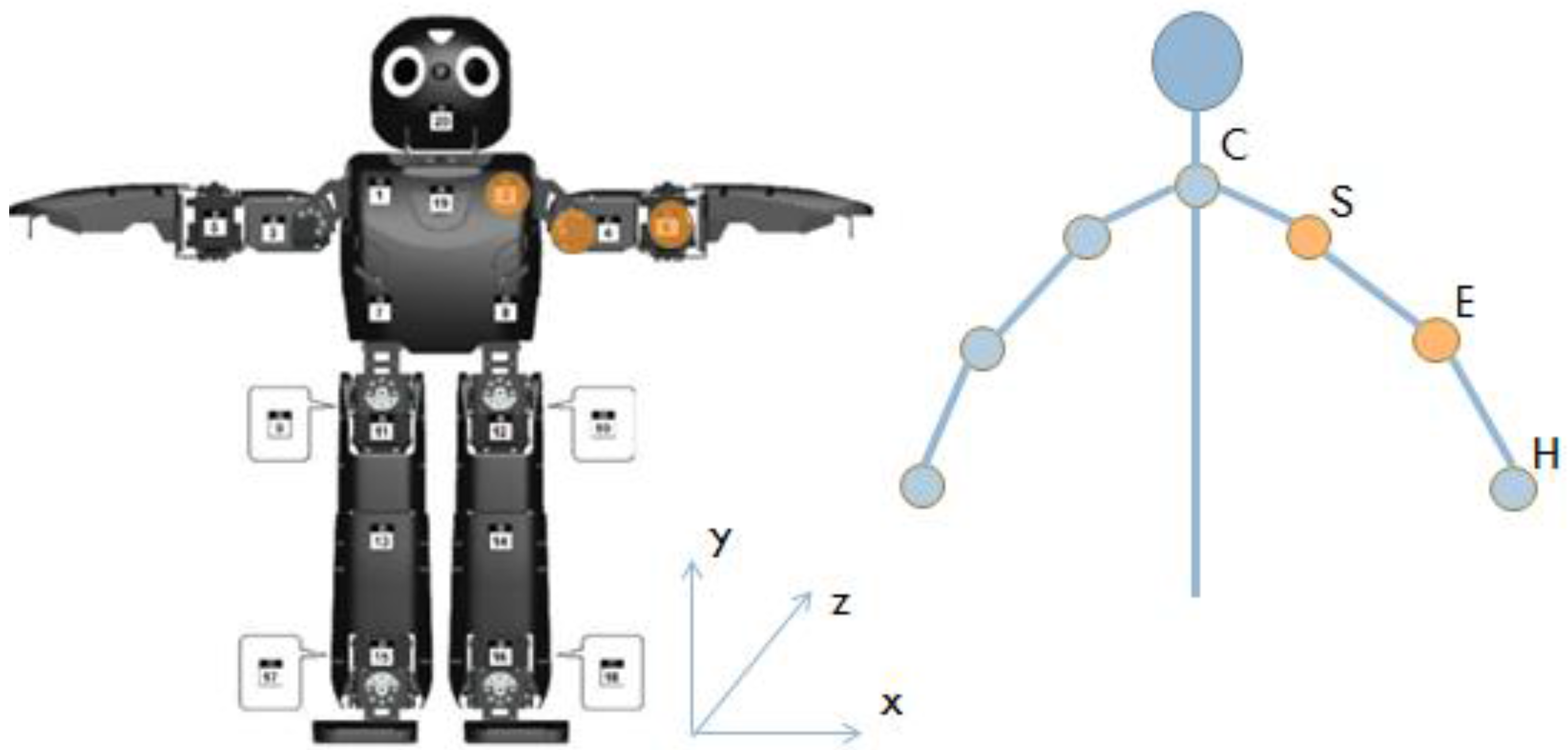
The robotic system chosen for this experiment was ROBOTIS-OP2 (“OP2”), a humanoid robot standing at 17.9 inches (45.45 cm) and weighing 25 pounds. OP2 has proportional–integral–derivative (PID) controllers at 20 different joints, can talk through Text-to-Speech or pre-recorded audio files, and is programmable directly through a Linux operating system (OS). OP2 was chosen as a suitable robotic agent for this experiment due to its small size, friendly humanoid appearance, multimodal feedback source capabilities and computer-sized processing power.
For this experiment, the motion learning reproduction was implemented only in OP2’s arms (shoulders and elbows), as seen in
Figure 3. Reproduction of torso, hip, or leg movement would require additional programming for stabilization, as OP2 does not have the same bodily proportions as a human, and additionally differs in terms of weight distribution. OP2 has two motors in each shoulder. These motors can be set to replicate human shoulder pitch and roll. Manipulating these two planes allows arm yaw to be replicated as well. OP2 has one motor in each elbow, enabling it to match human elbow pitch. However, OP2 lacks the ability to perform the rotational movement of wrist yaw. This means that it cannot reproduce the human movement of rotating the palm from facedown to faceup. However, by replicating the angles of each participant’s shoulder and elbows, the majority of the gesture was able to be articulated. Perhaps because they saw that OP2 had no hands, participants tended to close their fists or generally not flex their hands when demonstrating movements to the robot.
The Microsoft Kinect, a depth camera, was used to track participant movement. A custom graphical user interface (GUI) was developed to utilize depth information from the Kinect to generate a skeletal framework of the participant’s joints for movement reproduction by OP2. Arm joint information was collected and used by the GUI to calculate arm angles. Eight angles were tracked in total—the four left arm angles listed in
Table 1, and their right-side equivalents. These angle variables became inputs into the DMP with GMR motion learning algorithm in MATLAB (Version 2015a, MathWorks, Inc., Natick, MA, USA). New, smoothed, similar angle reproductions were generated by the algorithm from the demonstration data. These values were then converted from degrees into motor actuator positions, which would allow for OP2 to be controlled. The values were outputted to a text file, remotely uploaded into OP2’s directory, and called from our “Emotion Game” program to perform gesture reproduction on command.
The aim of this experiment was to determine whether imitation increased social engagement during human–robot interaction. In order to test this hypothesis, a social situation that prompted interaction first had to be constructed. Therefore, a set of 12 emotion primitives was developed for OP2. Our emotions were chosen based on Russell’s Circumplex Model of Affect. This model breaks emotions down into two axes: arousal, which refers to the energy level present with the emotion, and valence, which indicates whether the emotion is a positive or negative experience. Between these two axes, all levels of emotion can be represented [
14]. The 12 primitives were carefully chosen to display a full range of the emotional spectrum and maximize the chance of eliciting responses from the participant. The robot demonstrated the emotions to participants in the following order: sadness, fear, excitement, disgust, curiosity, pride, anger, embarrassment, surprise, pleasure, frustration, and tiredness. Descriptions of the gesture and phrases used to demonstrate these emotions can be found in
Table A1.
Twelve participants were recruited for the study; 5 female and 7 male, ages 19–30 (mean = 23, standard deviation = 3.55). Two participants self-reported as Asian; 2 as Hispanic, and 8 as Caucasian. All participants self-identified as neurotypically functioning adults. The participants were 6 graduate students and 6 undergraduate students in science, technology, engineering, and math (STEM) subjects. In a user survey, all participants selected either “Agree” or “Strongly Agree” when asked if they considered themselves proficient in “current” technology, such as mobile devices. When prompted whether they had prior experience with robots, the majority of participants chose “Agree” or “Strongly Agree”, with 3 participants instead choosing “Disagree”. All participants were randomly assigned into Control or Experimental groups. The experimental protocol was reviewed and approved by the George Washington University Office of Human Research (OHR) Internal Review Board (IRB) under the IRB Protocol Number 111540. All participants were given a packet containing project IRB approval and their informed consent information prior to data collection.
2.3. Experimental Setup
For the experiment, each participant was directed to an unoccupied room containing a conference table equipped with a video camera, Microsoft Kinect, laptop, OP2, and seating for at least two people. The cords to power the equipment were hidden underneath the table to minimize participant distraction. The experimenter sat adjacent to the participant, with OP2 placed in between them on the table. The Kinect system was initialized and videotaping started. Participants engaged in a two-part “Emotion Game” with OP2. This layout can be seen below, in
Figure 4.
In the first half of the Emotion Game, OP2 introduced itself, using pre-recorded audio and gestures triggered by the experimenter. The participant was prompted by OP2 to perform three gestures: one “exercise” move, one “emotion”, and one “dance” move. To ensure accurate data collection, each participant was asked to stand when demonstrating his or her moves. The angles of the participant’s limbs during these gestures were tracked and recorded by the Kinect. Video footage of each participant’s gestures was recorded to later be compared to the robot’s reenactments. The participant was offered to return to a sitting position after completing the demonstrations.
An interim-survey was completed by each participant after the first half of the emotion game. For each of its three sections, the participant was asked to answer Likert scale questions by assigning a numerical response to each prompt. The numerical scale ranged from 1–5, where “1” equated to “Strongly Disagree” and “5” equated to “Strongly Agree”.
The first section of the interim-survey examined the participant’s interest in and comfort with current and new technology. This was intended to help the experimenter see if self-proclaimed technological expertise and exposure would affect how a participant reacted to OP2. The second section prompted the participant to comment on their initial impression of the robot. These 5 Likert scale questions guided the participant to comment on the appeal of the robot’s demeanor, voice, word choice, and fluidity of movement, as well as whether he or she found the robot intimidating, to identify whether any of these factors were negatively impacting the participant’s interaction. The third section of the interim-survey and the sole section of the forthcoming post-survey both focused on the participant’s interaction with OP2, before and after the second half of the emotion game. The statements prompted the participant about his or her levels of comfort and enjoyment while interacting with the robot. The brief time required to complete the interim-survey allowed the experimenter to seamlessly train the motion learning algorithm for experimental group participants.
Each participant then completed the second half of the Emotion Game. OP2 announced to the participant that it would reciprocate by demonstrating gestures to them. The participant’s job was to identify which emotion the robot was attempting to articulate and display. The order of emotion primitives, listed earlier, appeared random but was kept consistent for all participants. However, OP2 performed an additional “DMP move” after the “curiosity” emotion primitive for experimental group participants. This “DMP move” was a DMP-learned reproduction of one of the participant’s previous gestures from the first half. Experimental group participants were not given forewarning that the robot would include the imitative gesture. The participants’ movements were tracked by the Kinect for posture analysis. Video footage was collected to track changes in emotional state, including mood contagion.
Four dependent variables were tracked to determine where imitation increased social engagement during human–robot interaction: participant posture, facial emotional state, instances of mood contagion, and perception of robot autonomy.
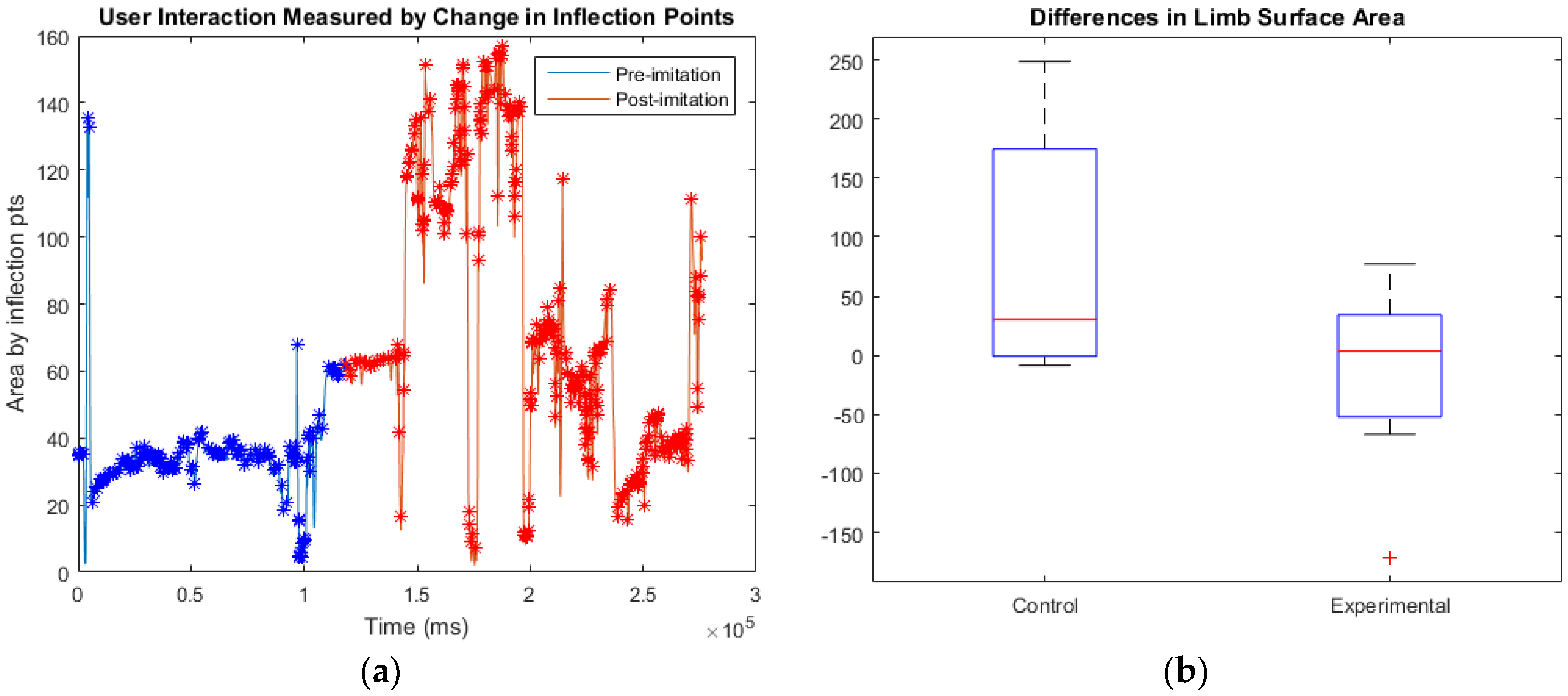
For posture analysis, an algorithm was used to quantify the participants’ interest in OP2 through bodily movement and posture. Using the Kinect skeletal framework GUI, four points on the participant’s body—the left and right shoulders and hands—were digitally connected to form a trapezoid. A large trapezoid area indicated that the participant’s limbs were spaced farther apart, indicating open body posture by leaning back and sitting upright. A smaller area indicated the participant’s limbs were closer together, suggesting the participant was slouching forward. Sitting upright is an indication of engagement, whereas slouching forward indicates the participant is withdrawn and disinterested in the robot’s performance [
15]. The trapezoid areas before and after imitation were compared.
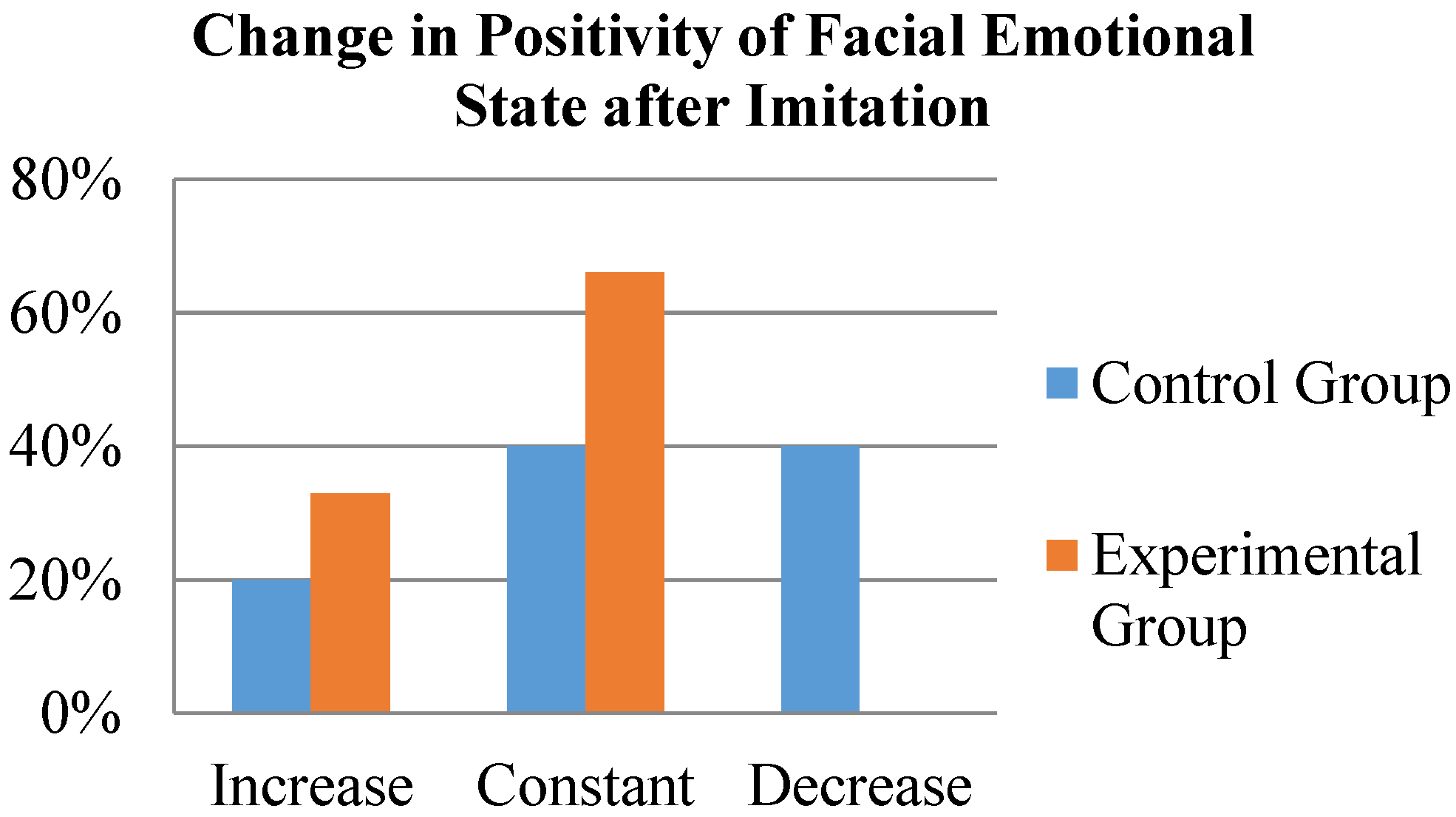
For facial emotional state, the user’s facial reactions to the various emotion primitives of the second half of the game were tracked using video footage. Smiling is a universal way to signal a positive emotional state, or a response to a particularly pleasing interaction. Unique instances of emoting, separate from the participant’s neutral expression, were recorded.
Mood contagion occurs when a participant unwittingly switches their mood to match or complement that of the opposing social agent. Instances of mood contagion provide us with another way to quantify the user’s perception of the robot as a social agent, as well as their engagement in the emotion game. Episodes of mood contagion were tracked using video footage.
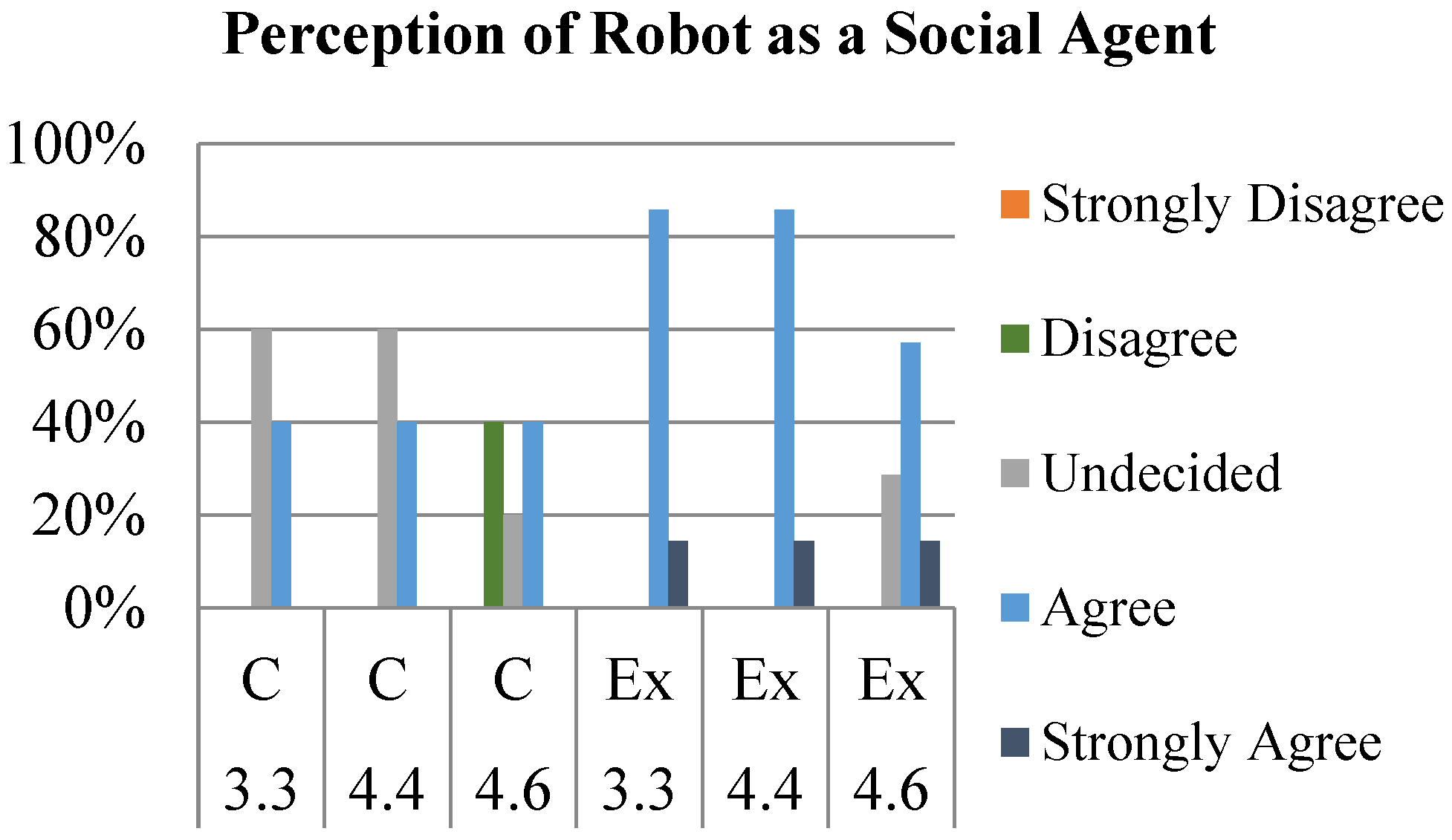
Participants’ perception of robot autonomy was tracked using the results of the interim and post surveys—in particular, questions 3.3, 4.4, and 4.6. These questions were, in order, “The robot pays attention to me” (pre-imitation), “The robot was interacting with me” (post-imitation), and “The robot was paying attention to me” (post-imitation). While OP2 was controlled by the experimenter for this study, it was important to determine whether the robot maintained an appearance of autonomy. By recording the participants’ responses to these questions in particular, we can observe how incorporating the imitation gesture into their interaction improved or reduced the participants’ perception of the robot’s level of autonomy.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








