1. Introduction
Data clustering or segmentation is an active research topic in data mining, signal processing and unsupervised learning [
1,
2]. In practice, many data are generated from a space which has intrinsic subspace structure, i.e., the space is composed of union of multiple subspaces. In this case, it is necessary to exploit and reveal the subspace structure, and so different subspace clustering methods were proposed in recent years [
3,
4]. In all of the subspace clustering methods, the spectral clustering methods based on the affinity matrix of data are considered to have good prospects. The typical methods are the Sparse Subspace Clustering (SSC) [
5] and the Low Rank Representation (LRR) methods [
6]. The key problems of the subspace spectral clustering are how to find the proper data representation and how to construct the affinity or similarity matrix of the data for spectral clustering. In SSC and LRR methods, the original data are firstly represented by the self expression model with sparse or low-rank constraints. Then the affinity matrix is constructed from the representation coefficients. Using the affinity matrix as input, the final clustering results can be obtained by common spectral clustering algorithms, such as K-means or NCut methods.
It is critical for the spectral subspace clustering methods to construct a proper affinity matrix; one should exploit the data intrinsic properties to form necessary regularization for the data representation model. Based on the assumption that the data sample could only be represented by the samples coming from the same subspace it belongs to, SSC adds sparse constraint onto the representation coefficients matrix by
norm [
7]. However, the sparse constraint in SSC is an individual constraint for each datum representation. There is no consideration of correlation among the data. For this purpose, LRR adds the holistic constraint of low rank onto the representation coefficients matrix by using nuclear norm
, which has been proved to be more helpful to reveal the subspace structure of the data drawn from the true multiple subspaces combined space [
6].
Although SSC and LRR clustering methods have shown good clustering performance, the data representation is just formulated by sparse or low rank constraints. The other properties of the data or its representation are not well exploited. For example, in the real world, many high dimensional data are often considered to reside in low-dimensional manifolds space and to have non-linear geometrical structure. The sparse manifold clustering and embedding method [
8] showed that introducing the local manifold structure can enhance the clustering performance for the data with non-linear property. However, the basic LRR and SSC methods do not take into account this manifold structure for high dimensional data. As a result, some non-linear metric related properties within data may be corrupted in the procedure of clustering. Observing that, numerous researchers have revised the basic SSC and LRR methods to model the data intrinsic properties by introducing extra constraint or regularization. Zheng et al. [
9] proposed a graph regularized sparse coding method to obtain data sparse representations with the constraint of local manifold structure. Gao et al. [
10] proposed two types of Laplacian regularizer by incorporating a similarity preserving term into the sparse representation model. Cai et al. [
11] developed a graph-based approach for non-negative matrix factorization in order to represent the naive geometric structure in data. He et al. [
12] proposed a Laplacian regularized Gaussian mixture model for data clustering by exploiting the probability distribution of the intrinsic manifold structure of data. Incorporating manifold regularization, Zhang et al. [
13] proposed a novel low rank matrix factorization model for data representation. Hu et al. [
14] proposed a SMooth Representation (SMR) model to enforce grouping effect in the data representation model. Liu et al. [
15] proposed a Laplacian regularized LRR (LapLRR) to enhance low-rank subspace clustering by utilizing manifold property of data. Peng at el. [
16] improved the low-rank representation via sparse manifold adaption for semi-supervised learning. Yin et al. [
17] proposed a Non-negative Sparse Laplacian regularized LRR model (NSLLRR) to improve the performance of LRR. Recently, Wang et al. [
18] proposed a LRR model on Grassmann manifold with Laplacian graph constraint. Yin et al. [
19] proposed an adaptive way to construct the affinity matrix for eliminating the interference of noise in data. Except for the above Laplacian graph constraints, other constraints like the block-diagonal form of the affinity matrix [
20,
21,
22] and the covariance of the data [
23] are also exploited to improve subspace clustering performance.
In spite of obtaining improvement by utilizing the non-linear property hiding in the high dimensional data, most of the current methods justly represent this non-linear property by the Laplacian graph constructed directly from the similarity of the raw data under Euclidean distance, which is hard to fulfill modeling the intrinsic manifold structure. Additionally, these methods are easily biased by the noise and outliers existing in the raw data. Facing these problems, we think that the manifold learning methods, such as Local Linear Embedding (LLE) [
24], Isomap [
25] and Laplacian Eigenmaps (LE) [
26], etc. give a possible solution, as they adopt a data-driven manner to learn and represent the non-linear structure of data and show robustness to noise or outliers. So we try to integrate manifold learning methods and the subspace clustering methods, and construct a subspace clustering method for high dimensional data based on manifold learning. Here, we adopt the classic LLE manifold learning method to learn the non-linear structure in the data and embed it into SSC and LRR subspace clustering procedure, thus we propose two new subspace clustering methods, namely LLE-SSC and LLE-LRR. The main contributions of this paper are listed as follows:
A new framework of clustering is constructed by integrating the manifold learning methods with subspace clustering methods.
Instead of building the Laplacian graph from the raw data, the manifold learning method, LLE, is adopted to reveal the non-linear property of the data for clustering, and this strategy is considered superior in dealing with noise and outliers.
To solve the complicated optimization problem involved in the proposed LLE-SSC and LLE-LRR models, an efficient algorithm is determined as the solution.
The rest of the paper is organized as follows. In
Section 2, we summarize the SSC and LRR subspace clustering methods and review the related works of our model. In
Section 3, our proposed models, LLE-SSC and LLE-LRR, are described in detail and their solutions are given. In
Section 4, the performance of the proposed method is evaluated on several public datasets. Finally, conclusions and future work are provided in
Section 5.
2. Related Works
Our work is based on the classic SSC and LRR subspace methods, which make impressive progression and have state of the art clustering performance. In the following, we give a review of these two methods and discuss some related subspace clustering works.
The SSC and LRR subspace clustering methods are typical spectral clustering methods, which generally have two steps to implement clustering. First, the raw data are represented over a dictionary for obtaining the data representation coefficients and constructing the affinity matrix; Second, based on the affinity matrix, the clustering is implemented by using common spectral clustering methods, e.g., K-mean or NCut. As the dictionary training procedure usually has a high cost of computation for large datasets, an alternative scheme is to use the data itself as the dictionary, known as the self-expression property of data [
5]. The first step in SSC and LRR is the core step as the affinity matrix has significant influence for the clustering result. So, many works focus on constructing an optimal affinity matrix by exploiting different constraints or regularizations. In SSC and LRR methods, the sparse and low rank constraints are added for the data representation matrix, respectively.
For convenience, we denote the data for clustering by
, which are assumed being generated from
k subspaces, i.e.,
s.t.
and
,
,
. The objective of subspace clustering is to find the proper subspace for each datum. For this purpose, SSC implements clustering by representing the data as the sparse coefficients. The original SSC model is usually formulated as follows [
5]:
where
is the sparse representation coefficient matrix and
is the weight to balance the data self representation error and the sparse representation term.
In SSC, the sparse constraint is just applied for the coefficient of each datum. However, the correlation among the whole dataset or its sparse representation coefficients are not described. Based on this observation, to further reveal the holistic sparsity of the data, LRR proposed using low rank constraint for the coefficient matrix. Additionally, to solve the NP-hard optimization problem with low rank constraint, the nuclear norm
is generally used to replace the low rank constraint. Thus the LRR model can be formulated as the following optimization model [
6]:
where
norm is used to obtain robustness for noises and outliers.
The above SSC and LRR models only use sparse and low rank constraint to the data coefficients, while the other data intrinsic property, such as the non-linear structure of high dimensional data, is not considered. To reveal the non-linear property of high dimensional data, some researchers proposed to use the Laplacian graph constraint to model the local manifold structure of the data. The SMR method [
14] enforces the grouping effect on the data representation matrix by using Laplacian graph constraint as follows:
where
is the data self representation, and
is the Laplacian graph matrix generally constructed from the local neighbours of each data sample. For example, from the local neighbourhood with
K nearest neighbours of each data sample, a weight matrix
can be constructed with the element
defined as follows:
where
denotes the set of
K nearest neighbors of
. From the weight matrix
, it is easy to get its Laplacian matrix
with the following element:
The Laplacian matrix is looked at as a graph which represents the pairwise relation of the data. Intuitively, if two data points
and
are close in the intrinsic geometry of raw data, their data representations should preserve this property. So it is natural to combine the sparse in (
1) or low rank constraint in (
2) with the Laplacian graph constraint in (
3) to obtain new clustering models. Thus, the LapLRR method [
15] presented a manifold regularization for LRR characterized by adopting the Laplacian graph constraint as follows:
where
demands the elements of
being nonnegative.
Considered that there usually exist noise and outliers in the raw data, the NSLLRR method [
17] adopted sparse constraints both for the data reconstruction error and the data representation. Additionally, the method exploits the Laplacian matrix construction methods in different cases, which results a hyper Laplacian matrix even when the data sampling is insufficient. The NSLLRR model is shown as follows:
where
is the hyper Laplacian matrix and
,
and
are penalty parameters for balancing the regularization terms.
In the above methods, the Laplacian graph constraint is generally constructed from the raw data samples under certain metric, which is easily interfered by the outliers or noise exiting in the original dataset. In this paper, we adopt a new strategy by using the manifold learning method to learn the underlining non-linear structure of the data and use the learned relation of the data to regularize the sparse and low rank representations. The manifold learning methods have been proved successful in representation of high dimensional data and robust to noise [
24,
25], thus it is considered more suitable to reveal the non-linear property of high dimensional data for clustering, and expected to obtain better clustering performance. In the following section, we will give the proposed methods in detail.
4. Experiments
To evaluate the performance of the proposed methods, we implement clustering experiments on several public databases. Firstly, to test the proposed clustering methods in an ideal situation, we use a dataset with true subspace structure for clustering. Here, the synthetic dataset in [
31] is adopted, which can be regarded as the baseline dataset for the subspace clustering methods. Then we test the proposed clustering methods on several real world datasets, including the Extended Yale B face dataset [
32], the handwritten digit dataset of United States Postal Service (USPS) [
33], the image dataset of COIL20 [
34] and the motion track dataset, Hopkins155 [
35], which are considered challenging for clustering as there is too much variety in these datasets.
The proposed methods, LLE-SSC and LLE-LRR, are compared with several related subspace methods, including the classic SSC and LRR methods, which are considered the baseline methods in subspace clustering methods. Additionally, the proposed methods are also compared with several variations of SSC and LRR, including SMR [
14], LapLRR [
15] and NSLLRR [
17], which introduced other constraints for the data representation, like Laplacian graph, to improve the clustering performance. We summarize the metrics of the data representation error, the constraints for the data representation and the methods for constructing the Laplacian matrix in the related methods and our methods in
Table 1.
To evaluate the performance of these clustering methods, the Subspace Clustering Error (SCE) defined in [
31] is adopted as the measurement with the following form:
where “num.misclssified points” represents the number of misclassified samples, and “total num.of points” is the number of total samples.
There are two parameters which should be set in the proposed LLE-SSC and LLE-LRR methods. However, for the balancing parameters in optimization models, few effective methods are available to obtain the optimal value, as it is generally dependent on the specific datasets. So to get the proper values of these parameters, we adopt a tuning method based on a set of pre-experiments. Concretely, we change the values of these parameters in an estimated range, and for each selected value, we implement some clustering experiments. By comparing the clustering results with different values of these parameters, we can get the favorable values, though they may be not the global optimal values. In the following experiments, we will report the parameters setting for each dataset. The parameters of the compared methods are set as the same as the recommended setting in the original paper or tuned manually based on some pre-experiments similar to the above setting of ours.
4.1. Synthetic Experiment
In the synthetic experiment, we adopt the similar method in [
31] to produce the data samples for clustering. Firstly, we randomly select five samples from the pure infrared hyper spectral mineral data and form a matrix
. Then we produce a random vector
by using a uniform distribution and obtain a vector by linear combination
. Let the generation of
be repeated 10 times, we can obtain 10 data samples from the subspace
, denoted by
. If we repeat the process of
five times, we finally get a dataset derived from the union of five subspaces, denoted by
, which will be used as the dataset for clustering. To further evaluate the robustness of the proposed methods, we add Gaussian noise onto
with three different magnitudes (10%, 20%, 30%) and so we produce three noisy datasets for clustering experiments. To get stable results, the experiments on different datasets are repeated 50 times with the reproduced
. The minimum, maximum, median and mean clustering errors are recorded for complete evaluation. In the above experiments, the parameters
for LLE-SSC and
for LLE-LRR.
The experimental results are shown in
Table 2. In the noise free case, almost all clustering methods perform well; SSC, SMR, LapLRR and our model LLE-LRR have completely correct results. However, when the noise amplitude increases, the clustering performances of the compared methods decrease rapidly, while that of our methods drops slowly. It is shown that compared with the other methods, our LLE-SSC method has at least 10% improvements in metric of median and at least 8% improvements in metric of mean when the noise level is 30%, which highlights that our methods have good robustness to noise.
For the subspace clustering methods, the constructed affinity matrix is critical for clustering. The ideal affinity matrix will be a block diagonal form. Generally, the closer to the block diagonal form it is, the better the clustering results will be. Therefore, we provide a visual comparison of affinity matrices produced by different methods in case of adding 20% Gaussian noise, as shown in
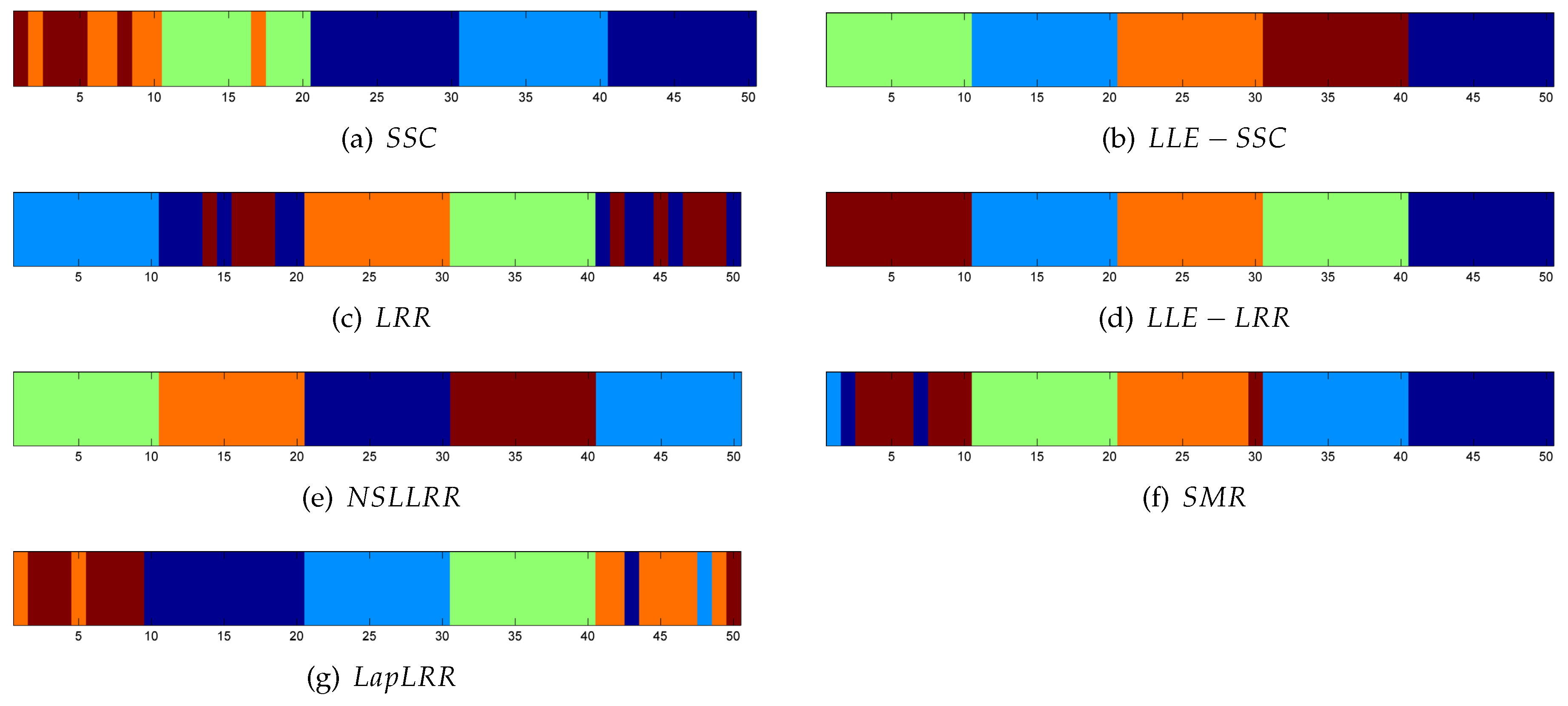
Figure 1. It is observed that our proposed methods, LLE-SSC and LLE-LRR, have affinity matrices closer to block diagonal shape than other methods. Additionally, we further show the clustering results by visualizing the samples of the same class with the same color, as shown in
Figure 2. It is indicted that our methods, LLE-SSC, LLE-LRR and NSLLRR, have the best clustering results.
4.2. Face Clustering on Extended Yale B
To test the proposed LLE-SSC and LLE-LRR methods in more complicated scenarios, we perform clustering experiments on the wildly used face dataset, the Extended Yale B, which has face images of 38 persons captured under different illuminations with each person having 64 front face images. Some samples of the dataset are shown in
Figure 3. For clustering application, this dataset is considered challenging as there exists too much varsity of illumination, expression and pose. Here, we randomly select
people and each person chooses 32 face images for clustering. All images in our experiment are resized to 32 × 32 pixels. As a result, we obtain the initial sample vectors
. Then we reduce the dimension of these samples to (9 × c) by the Principal Component Analysis (PCA) method according to the similar data processing procedure in [
20]. Based on the dimension reduced datasets, we implement clustering on the selected
c classes. To get a stable result, we repeat the clustering experiments 30 times by re-selecting
c classes of face images and use the mean clustering error as the final results. In the experiment, the parameters
for LLE-SSC and
for LLE-LRR.
The experimental results are reported in
Table 3. It is observed that our methods significantly outperform the other methods in all cases. Both LLE-SSC and LLE-LRR have at least 10% improvements compared to the other methods in terms of the mean error of different number of classes. In addition, our methods have the advantage that the clustering performances decrease little when the number of classes increases. On the contrary, the clustering performances of other methods drop dramatically when the number of classes increases. This demonstrates that the proposed methods have the application potential for clustering large scale datasets.
4.3. Handwritten Digit Clustering on USPS
In this experiment, we test the clustering performance of our methods on the handwritten digit dataset of USPS. In total, this dataset contains 9298 handwritten digit images of “0” through “9”, each of which is in the size of 16 × 16 pixels, with 256 gray levels per pixel. Some sample images are provided in
Figure 4. We represent the digital images as 256-dimensional vectors and randomly select
digits for clustering. For each selected digit, 48 images are randomly picked up. We repeat these clustering tests 30 times for each
c digits and the mean clustering errors are computed. Here the parameters
10,000 for LLE-SSC and
for LLE-LRR.
Table 4 reports the clustering results. It is observed that the proposed methods, LLE-SSC and LLE-LRR, almost outperform the compared methods in all cases. Compared with the experimental results on the Extended Yale B face dataset, the improvement of our methods in this experiment is not significant, which is analysed and explained as the handwritten digits written by different people, having too much diversity both in the shape and texture as shown in
Figure 4.
4.4. Motion Segmentation on Hopkins155
In this experiment, we implement motion segmentation to find the independent moving rigid objects by their trajectories. In theory, when a rigid object moves in a video, the points of its trajectories will be formulated as a low dimensional subspace. Thus one can find the moving objects by using subspace clustering technique on the tracked trajectories. From this point, we test our clustering methods on the motion benchmark dataset, Hopkins155, which contains three categories of 156 video sequences with each sequence having two or three moving objects, including indoor objects covered by checkerboard texture, outdoor objects like car, and articulated objects like people. The feature points of the objects are extracted and tracked in all the frames. The ground-truth segmentation is also provided in the dataset for comparison purpose. Some sample images of the dataset are provided in
Figure 5. In our experiment, the parameters
10,000 for LLE-SSC and
= 10,000 for LLE-LRR.
As there only two or three classes in the experiment, we only report the clustering results in maximal, mean, median and the standard deviation values, as shown in
Table 5. On the whole, the performances of all clustering methods are quite good as all methods have clustering errors less than 6% in terms of mean. The reason is two fold. The first is that Hopkins155 is a nearly noise-free dataset. The second is that the number of classes is small in this clustering experiment. It is worth noting that our LLE-LRR method has the best result with the mean error of 1.43%.
4.5. Object Image Clustering on COIL20
In this experiment, we test the clustering performance of our methods on the object image dataset of COIL20. The dataset contains 32 × 32 gray scale images of 20 objects. The object images are generally captured at different views. Some sample images of this dataset are provided in
Figure 6. Here we randomly select
objects for clustering. For each selected object, 36 images are randomly picked up. For each value of
c, we run 30 times of clustering by randomly choosing different images for each class and the mean error is reported as the final result. The parameters
for LLE-SSC and
for LLE-LRR.
The clustering results are shown in
Table 6. It is shown that our proposed LLE-SSC and LLE-LRR methods still perform excellently in this experiment. Compared with the other methods, LLE-SSC has better clustering results when the classes number is relatively small, while LLE-LRR has better results when the classes number is large. Particularly, LLE-LRR has the best result of 12.97% in terms of mean error.
5. Conclusions
In this paper, we proposed a new data clustering framework based on manifold learning and subspace clustering. Different from the traditional data subspace methods, which try to utilize the data similarity to construct Laplacian graph constraint for data representation. In the proposed framework, LLE is used to learn the manifold structure hidden in the data. The learned non-linear manifold is taken as a regularization for the subspace clustering methods, SSC and LRR, which results in the proposed LLE-SSC and LLE-LRR clustering methods. To evaluate the proposed clustering methods, we implement several clustering experiments on different types of datasets, such as the synthetic data, face images, handwritten digital images, object images and the motion sequences. The experimental results showed that the proposed methods have good clustering performance compared with related methods on different datasets. Particularly, the proposed methods have two advantages. Firstly, from the results of the experiments on the synthetic data with noise, it is shown that the proposed methods are robust to the noisy data. Secondly, from the clustering results on the Extended Yale B, USPS, COIL20 datasets with the number of the clusters increasing, we can observe that our methods show more stability than the compared methods, which means our methods have the potential for clustering a large scale of datasets. These characteristics make them prospective methods in data clustering.
It is shown that using the manifold learning method to reveal the non-linear property of the data and introducing the learned manifold constraint into subspace clustering methods will improve the data clustering performance. However, in this paper, we only use the common used LLE method to verify this idea by integrating it with the classic subspace clustering methods, SSC and LRR. We believe that the developing manifold learning methods are more helpful in dealing with more complicated data in practice. So one of our future works is to exploit a more suitable manifold learning method and integrate it to improve the data clustering performance. The other future work is to extend our methods by parallel computation technique in order to improve their efficiency and make them practical and suitable for clustering large scale data.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}