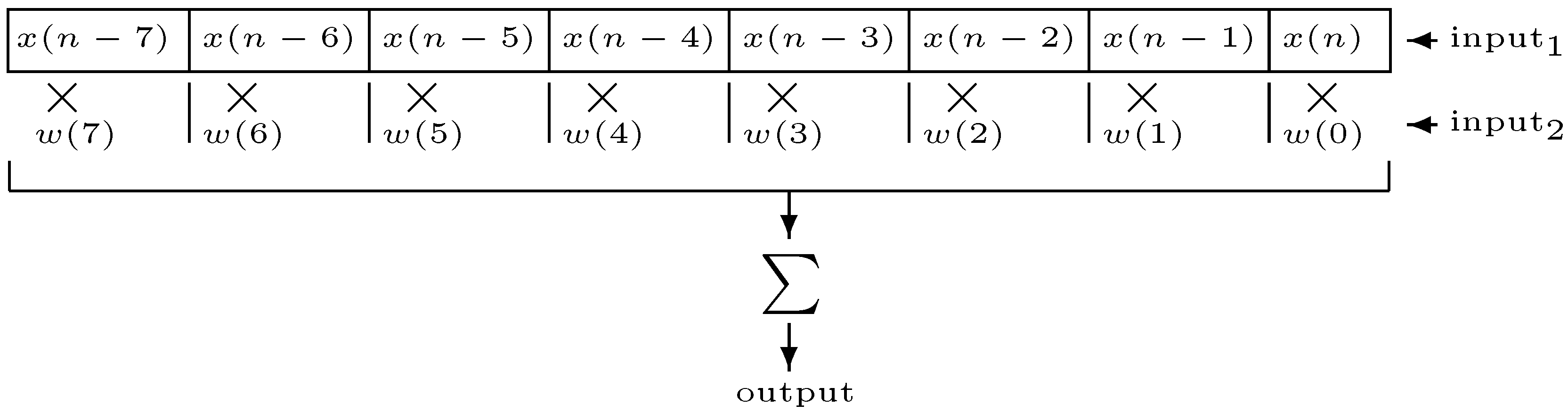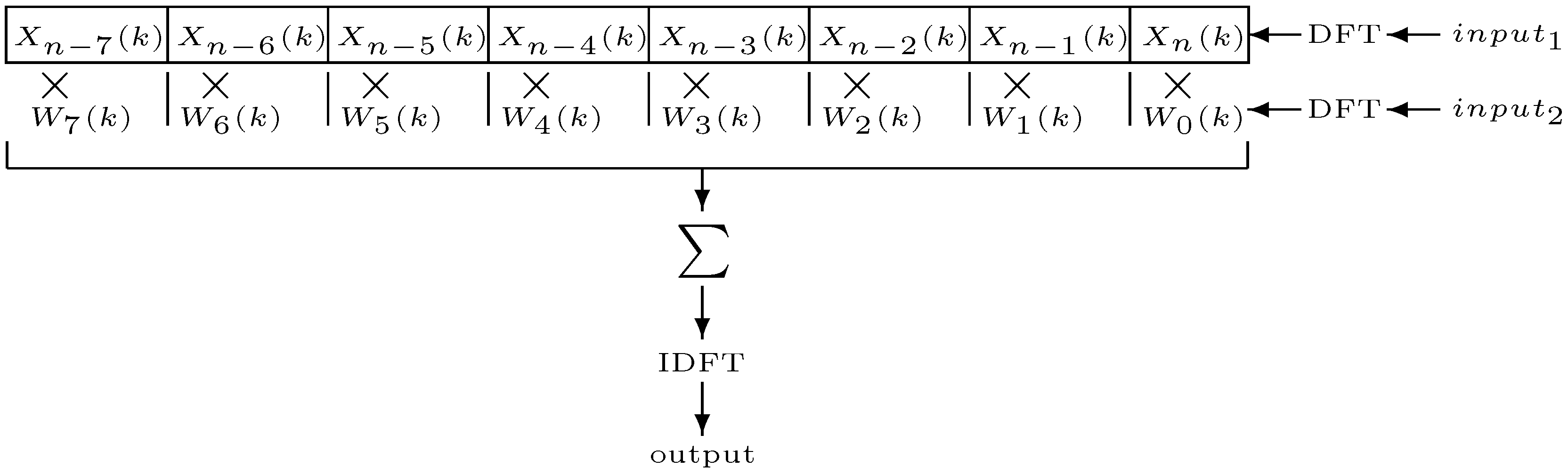2. Time-Varying Finite Impulse Response Filters
A digital finite impulse response filter (FIR) of length
N is defined by the following difference equation [
35]:
where
and
are the input and output signals, respectively, at time
n, and
to
are the scaling coefficients of each copy of the input signal delayed by 0 to
samples (in this text, we will use the convention that a filter with length
N has order
). When these coefficients are unchanging, the filter is a linear time-invariant filter.
For an FIR filter, its set of coefficients also make up the filter
impulse response
, which is the output of the filter when fed with a unit sample signal
, which is 1 for
and 0 elsewhere:
The output signal
can then be expressed as the
convolution of input signal
and impulse response
(convolution is a commutative operation):
The spectrum of the filter impulse response defines its
frequency response, which determines how the filter modifies the input signal amplitudes and phases at different frequencies. A generalised form of this, called the filter
transfer function can be obtained via the
z-transform,
which is a function of the complex variable
z. In the usual case that the filter is of finite length
N, we have:
By setting
and
, we can compute the filter spectrum via the discrete Fourier transform (DFT). This is called the filter
frequency response. The effect of a filter in the spectral domain is defined by the following expression:
and thus it is possible to implement the filter either in time domain as a convolution operation (Equation (
3)) or in the frequency domain as a product of two spectra.
We would like to examine the cases where these coefficients in Equation (
1) are not fixed, which characterizes the filter as time-varying (TV). The most general expression for a TVFIR is defined as follows [
10]:
where we assume that the filter coefficients are drawn each from a digital signal
. In this case, the impulse response will vary over time and thus becomes a function of two time variables,
m and
n, representing time of input signal application and time of observation, respectively:
The output of this filter is defined by the expression
Since the output can only appear after the input is applied (
for
), the impulse response
for
and
. If we then substitute
, we get the convolution
The transfer function also becomes a function of two variables,
z and
n, and assuming causality we get:
The next two sections present two different approaches to time-varying filtering: Dynamic replacement of impulse responses and convolution with continuously varying filters.
3. Dynamic Replacement of Impulse Responses
We first examine filter impulse responses where the coefficients are not continuously changing, but are replaced at given points in time. This approach was first presented in [
8], but is given a more detailed explanation here. It is related to the superposition strategy suggested by Verhelst and Nilens [
12]: when a filter change is called for, the signal input is disconnected from the currently running filter and applied to the new one. The old filter is left free-running, i.e., the old input samples propagate through the filter, and will eventually die out (for FIR filters after a time period equivalent to the filter length). The outputs of the two filters are added together. The next change adds another filter, and so on. To make this work, a number of filter processes must run in parallel.
Our approach differs from Verhelst and Nilens in that we propose to run all filters in the same filter process, simply by switching the new filter, coefficient by coefficient, into the same filter buffer as the old one. We claim that, for FIR filters, the results produced by the two approaches are equal, but that our approach avoids the added computational cost of computing two or more parallel convolution processes. By exploiting inherent properties of convolution, we also show that we may start convolving with the new filter impulse response in parallel with the generation/recording of it.
As an initial step consider a simple filter of length
N that is switched on at a given time index
:
It should be obvious that inputs
for
will not contribute to the output. If we apply Equation (
10) and once again let
, the first
N samples of convolution output starting at time index
can be written as:
After the sum will be upper limited by . The first output sample, , depends on the first coefficient, only. The second sample, , depends on the first two, and . In general, depends on coefficient only if . Hence, the filter coefficients can be switched in one by one in parallel with the running convolution process.
Now consider the counterpart, a filter of length
N that is switched
off at the same time index
(and for simplicity assume that
, the filter length):
Inputs
for
will not contribute to the output. The first
N samples of convolution output starting at
can be written as:
The first output sample, , does not depend on the first coefficient, . The second sample, , does not depend on the first two, and . In general, does not depend on coefficient if .
The natural extension of these two filters is the combined filter
where the coefficients are replaced at time index
:
The first
N samples of convolution output starting at
must be equal to the sum of the two filters discussed above:
A closer scrutiny reveals that coefficients and do not contribute to the same output sample for any . In fact, the filter coefficients may be replaced with one by one during the transition interval , while the convolution is running. The replacement itself will not introduce output artefacts as long as the coefficients are replaced just in time and in the correct order.
For completeness, we will examine a third filter of length
N where the coefficients are replaced at two different times,
<
:
If the time interval
, then the two transition regions
and
each behave as in Equation (
17). If not, we get a subinterval
of the transition region where all three filters contribute to the output:
Similar to the above, the coefficients , , and do not contribute to the same output sample for any . Hence, several filter replacements may be carried out simultaneously without artefacts. However, the number of coefficients involved in the convolution sum will be limited by the interval as seen in the middle term above, for a total of summands. An alternative view of this filter replacement scheme is that the input signal is split in segments , , and each convolved with just one set of coefficients, , , and , respectively. The output is the sum of contributions from all three filters.
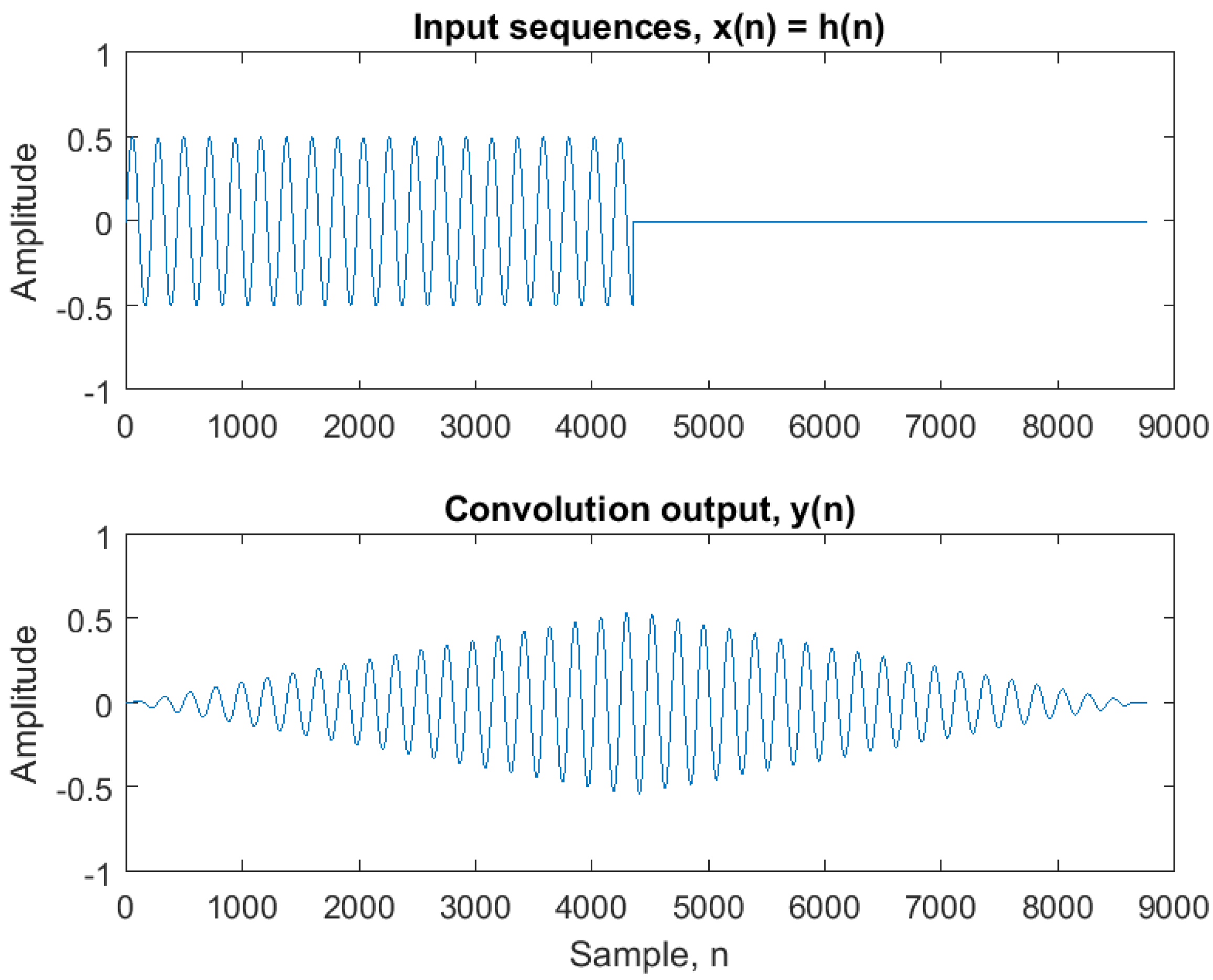
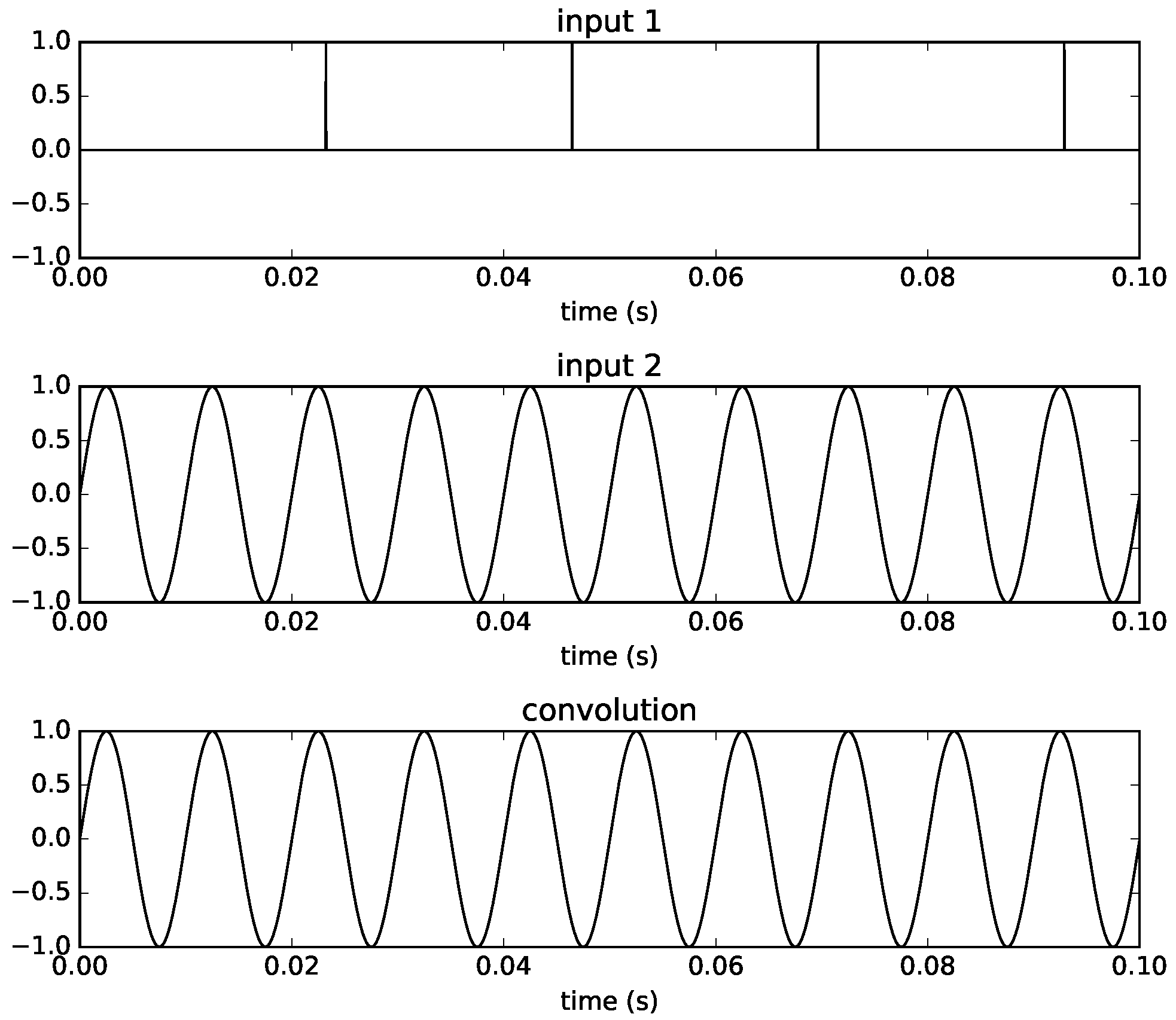
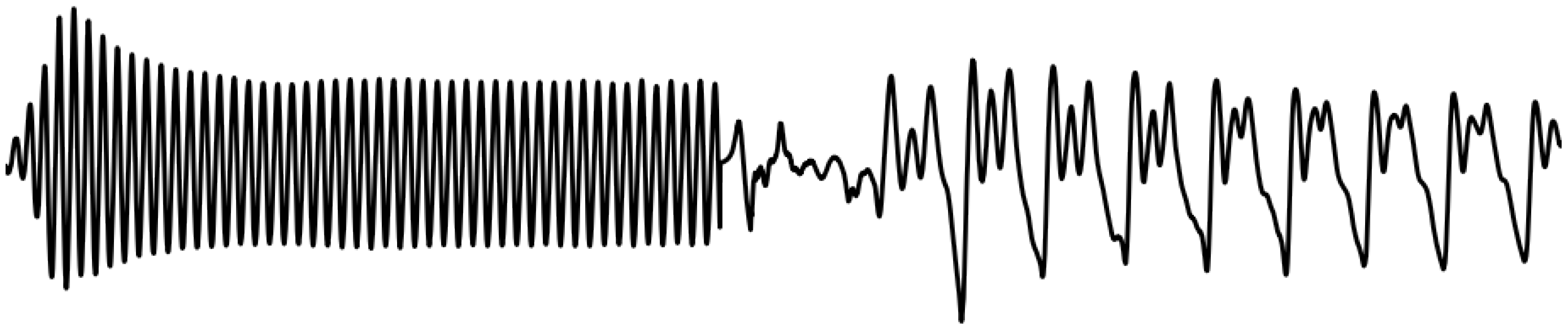
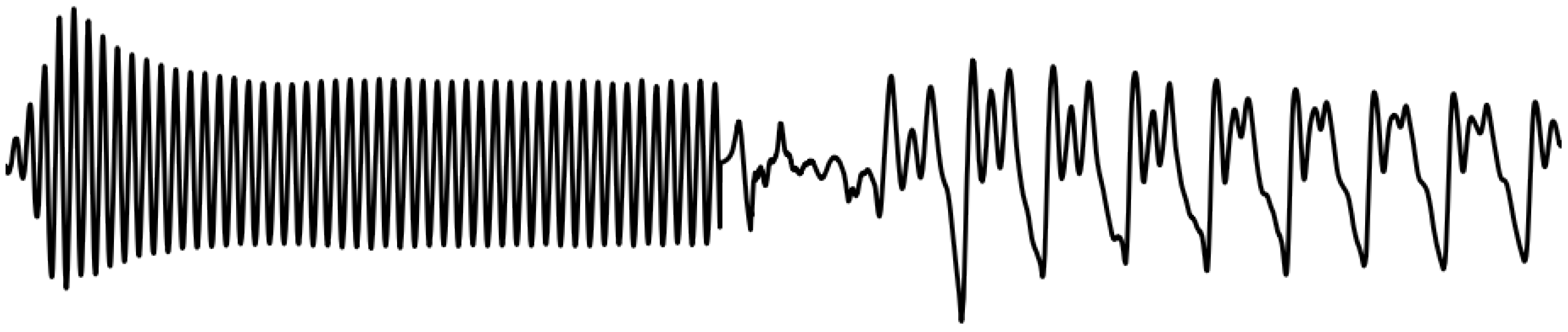
Convolution has by nature a ramp characteristic as exemplified in
Figure 1 where a simple sinusoidal signal time-limited by a rectangular window is convolved with itself (
). When doing a gradual replacement of filter coefficients, this inherent ramp characteristic ensures a smoothly overlapping transition region between the filters
and
.
This technique of stepwise filter replacement outperforms other methods of dynamic filter updates:
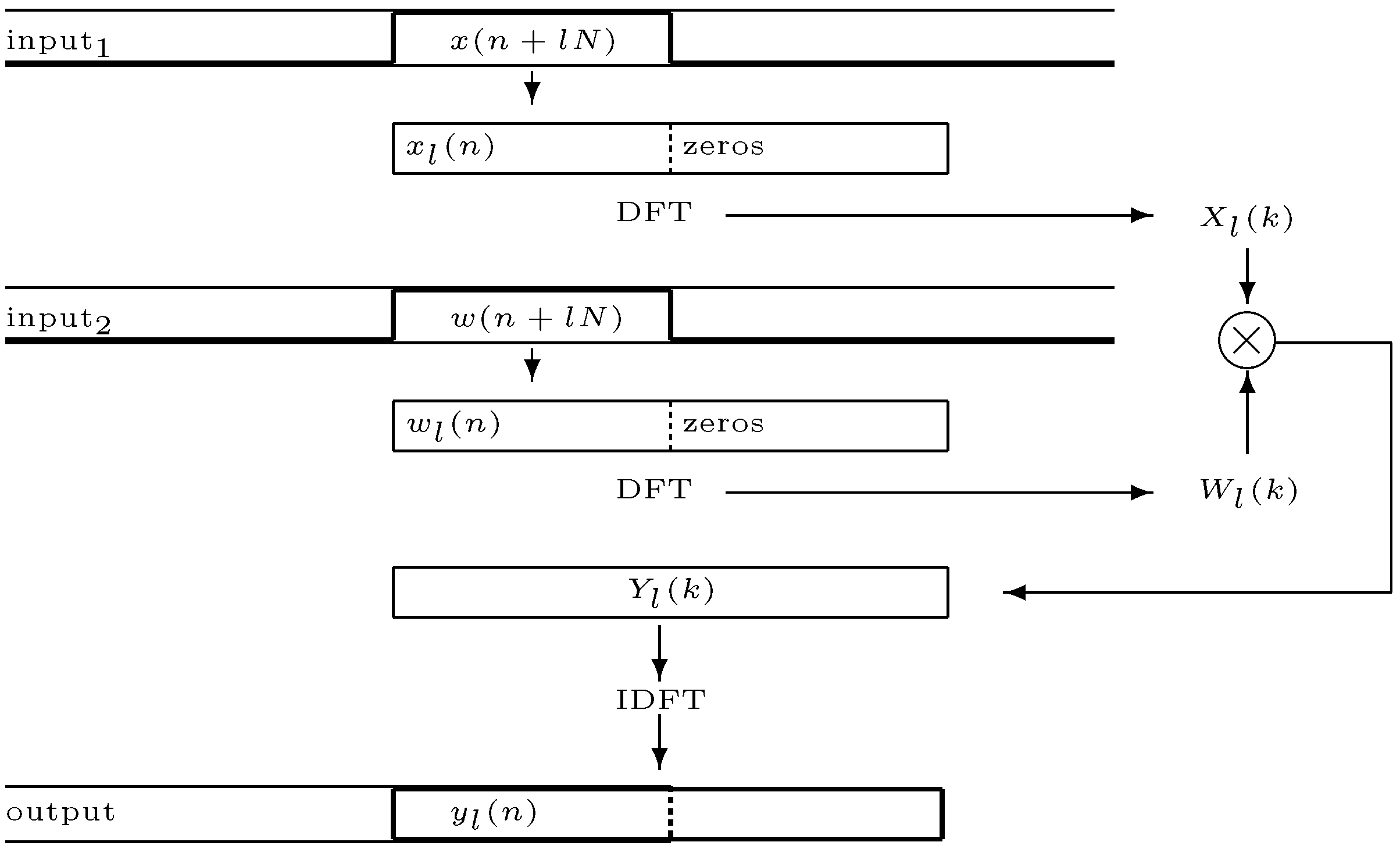
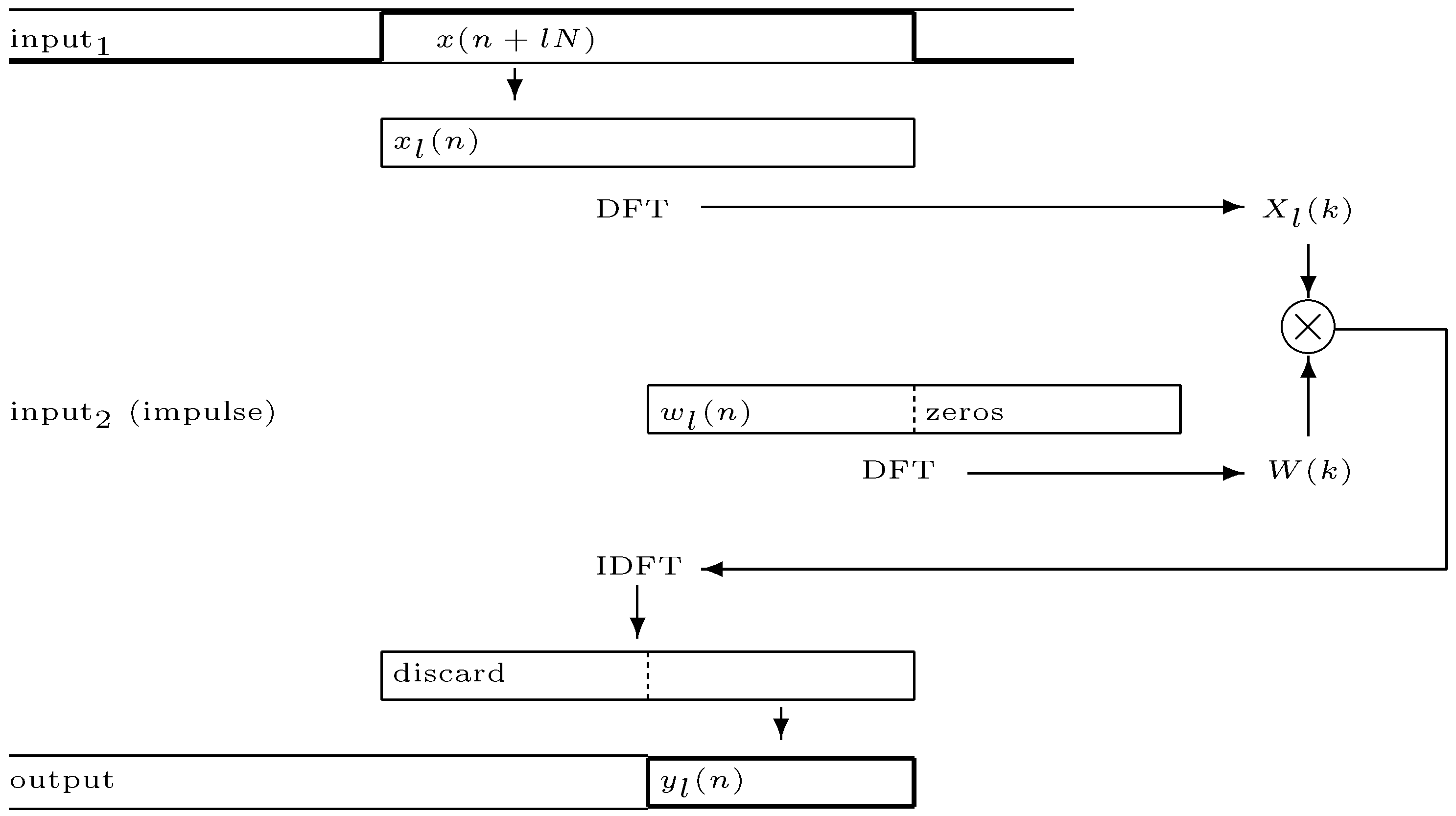
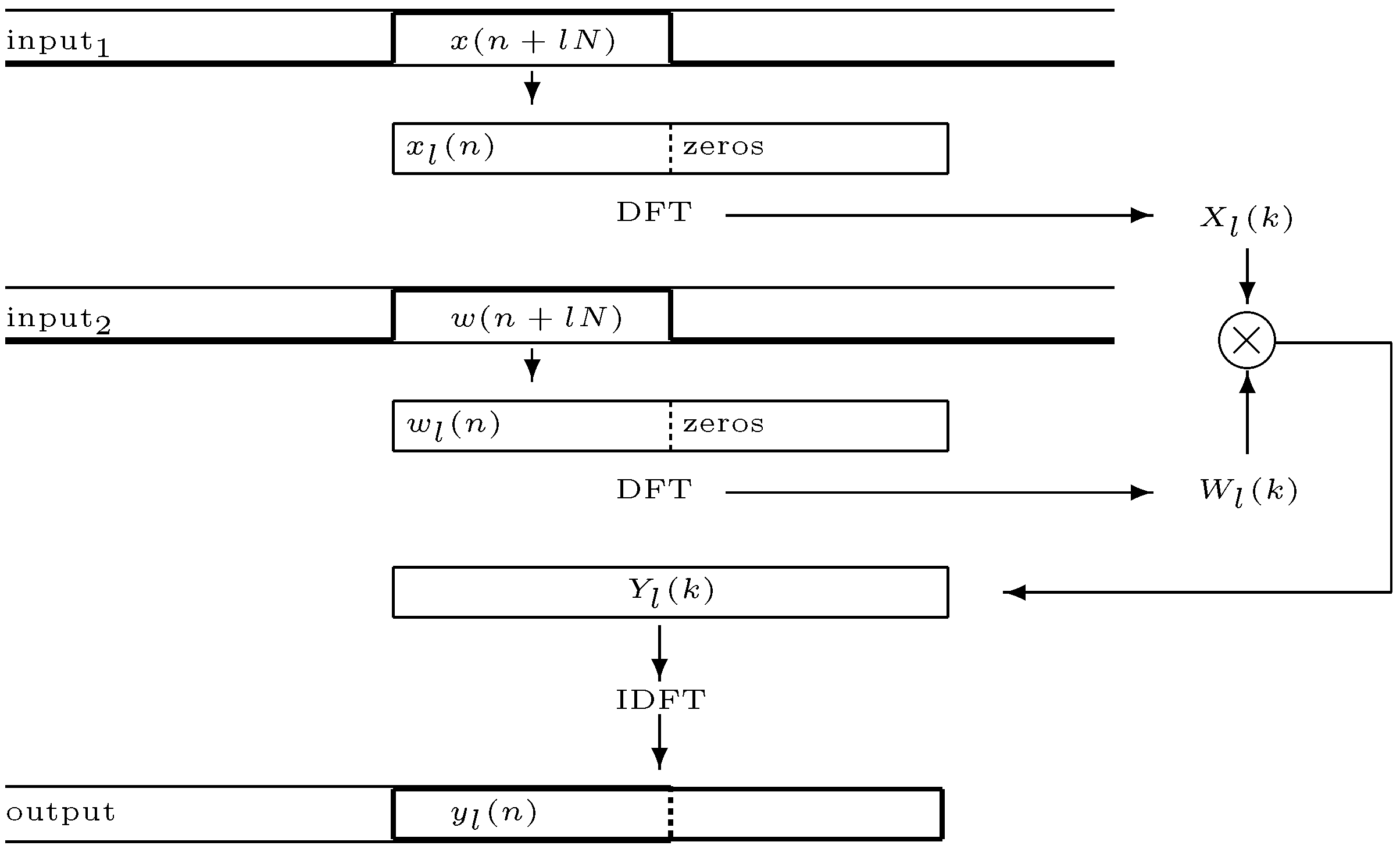
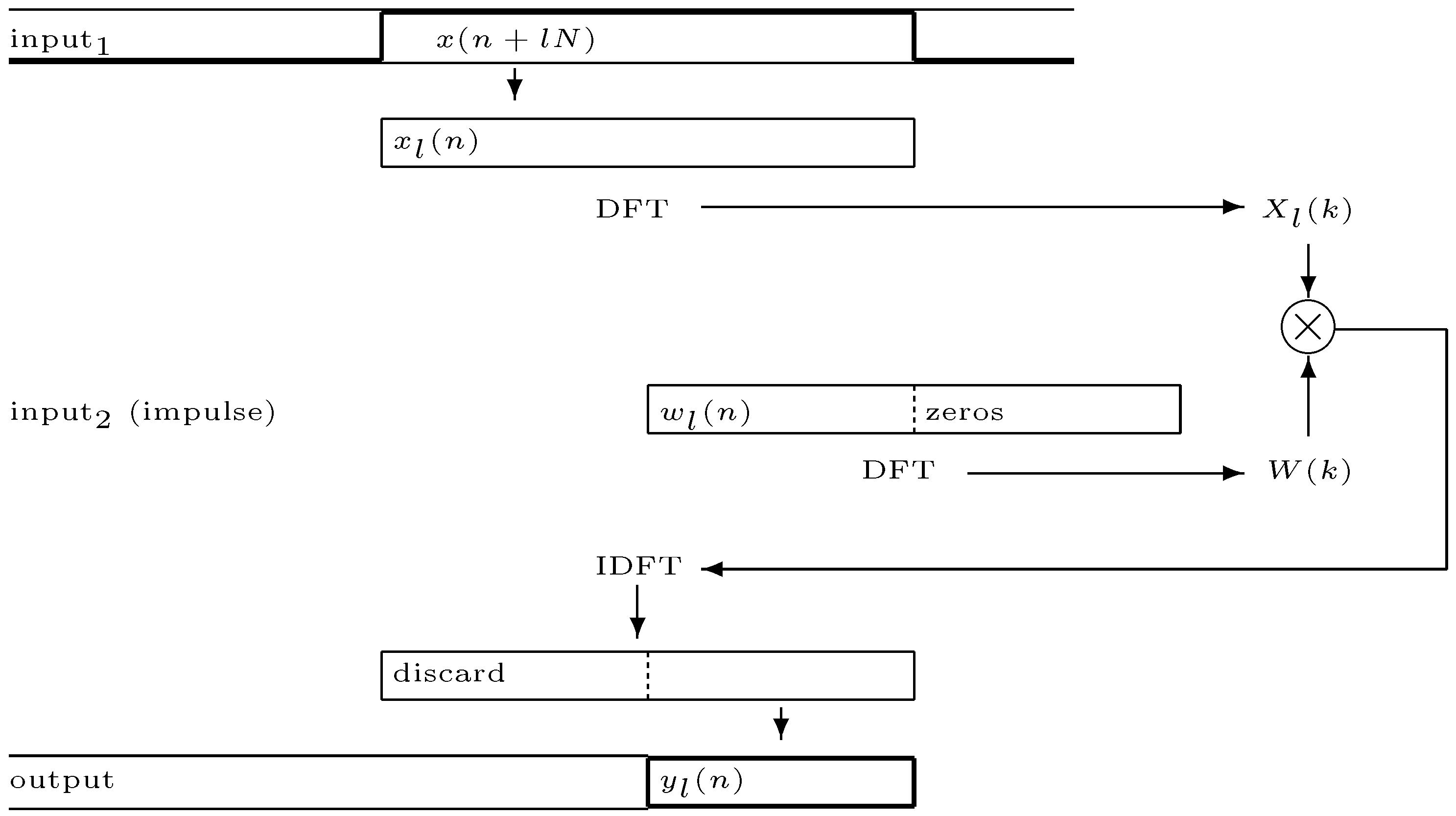
When filter length increases direct convolution in the time-domain is normally replaced with computationally more efficient methods in the frequency domain. A popular approach is
partitioned convolution [
6,
36] where the filter impulse response and the input signal are broken into partitions and the convolution computed as multiplication of these partitions in the frequency domain (more on implementation in
Section 5). The method of stepwise filter replacement still works, but now the
partition is the unit of replacement. Replacement must be initiated at a time index
equal to an integer multiple of the partition length
:
. A latency equal to the partition length
is also introduced.
Example
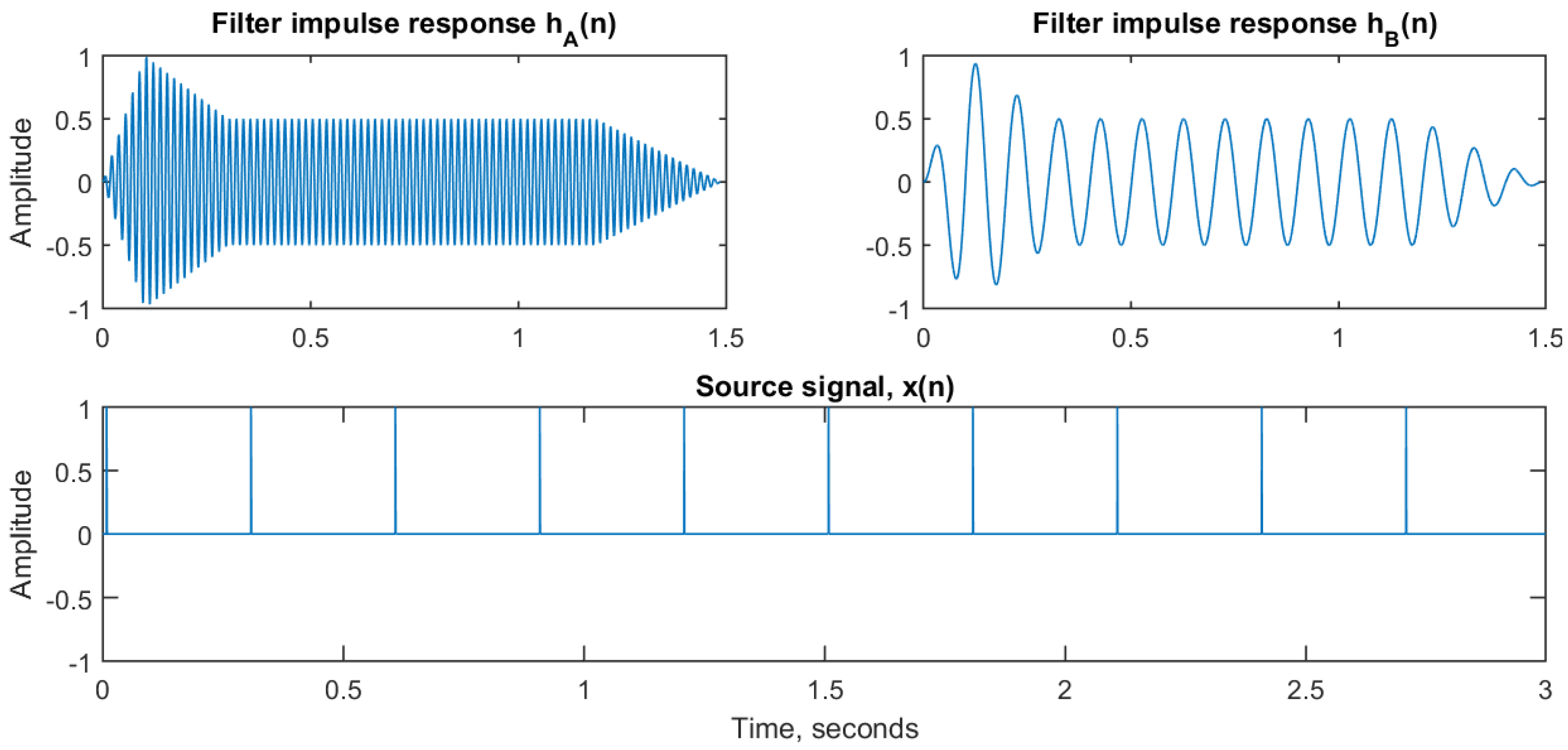
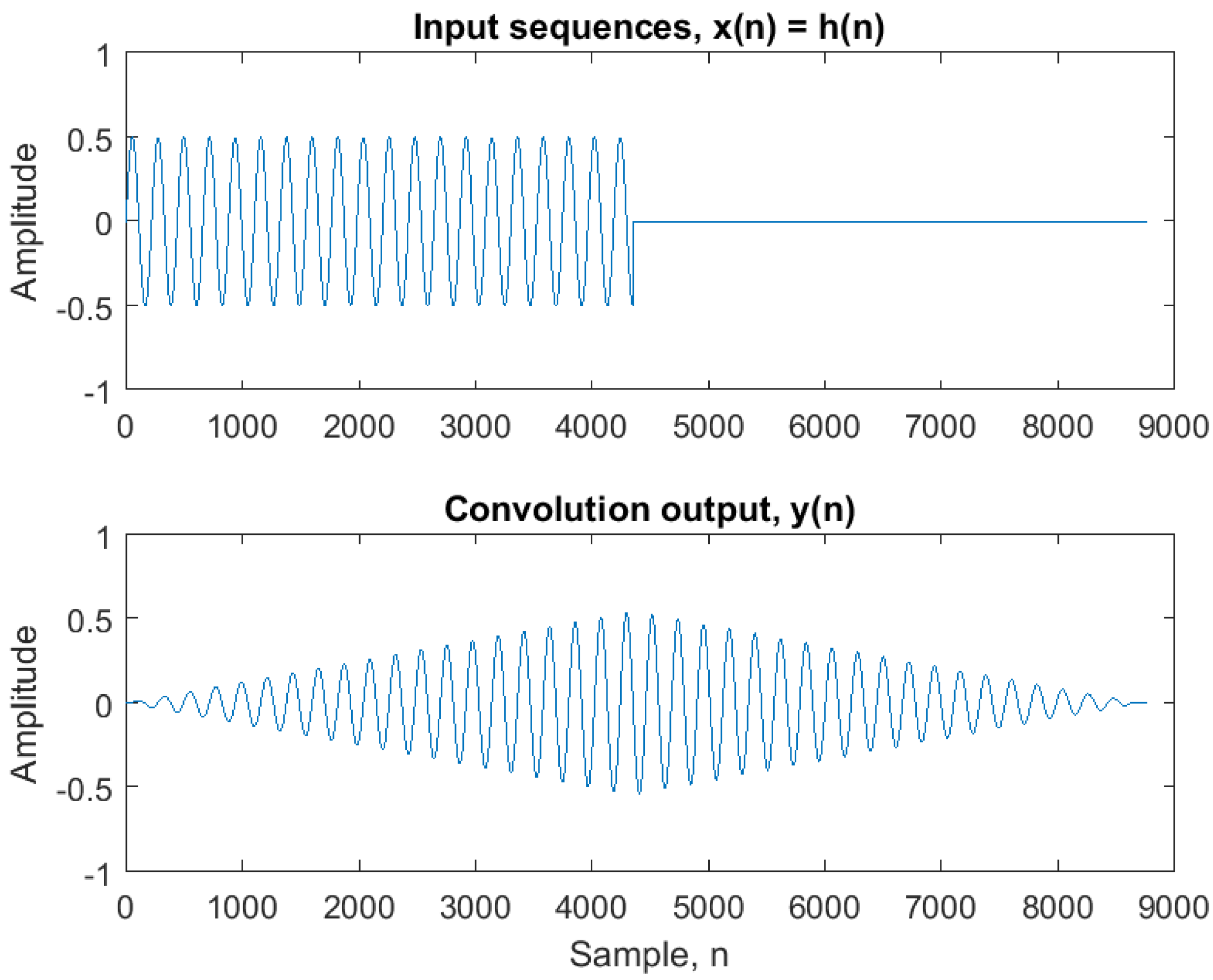
In order to illustrate the behavior of dynamic replacement of filter impulse responses, we present a simple example.
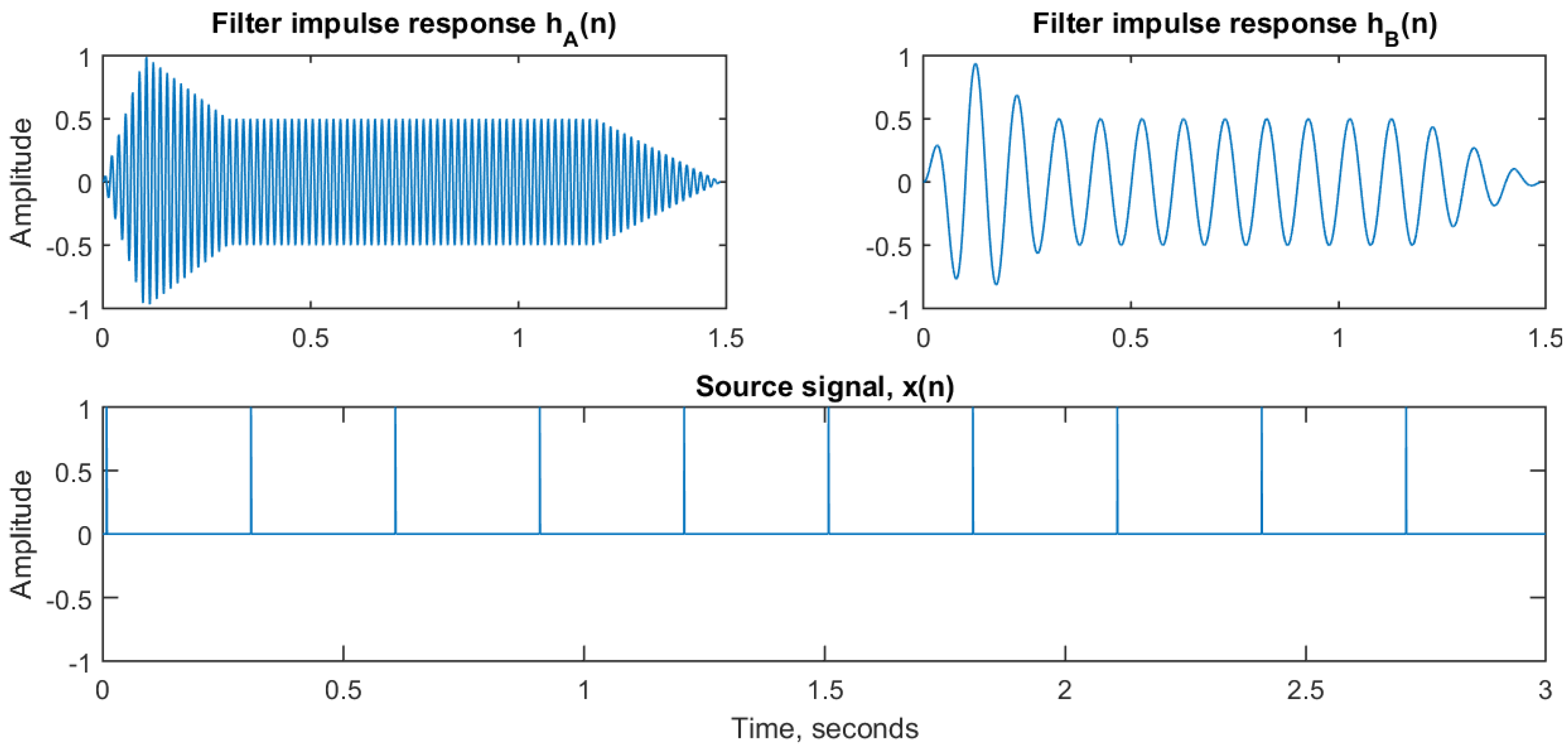
Figure 2 shows the input signals to a convolution process. On top are the two impulse responses
and
. They are both sinusoidal signals of duration 1.5 s sampled at 44,100 Hz and with a frequency of 60 and 10 Hz, respectively. At the bottom is the input signal
, which is an impulse train with pulses at 0.3 s interval, also sampled at 44,100 Hz.
These signals are convolved using partitioned convolution (overlap-add STFT) with partition length = 256 and FFT block size = 512. At time index = 1 s, a switch between the two impulse response filters is performed.
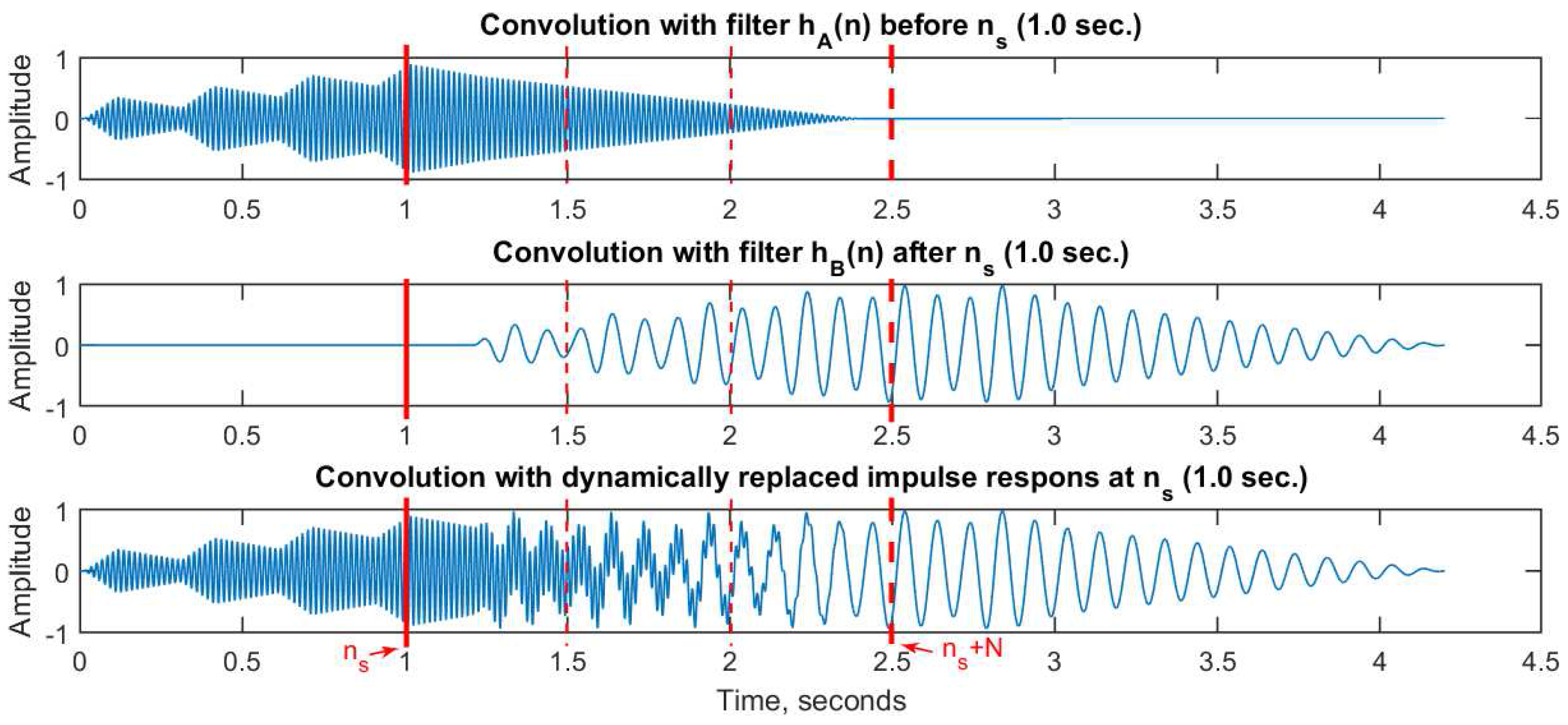
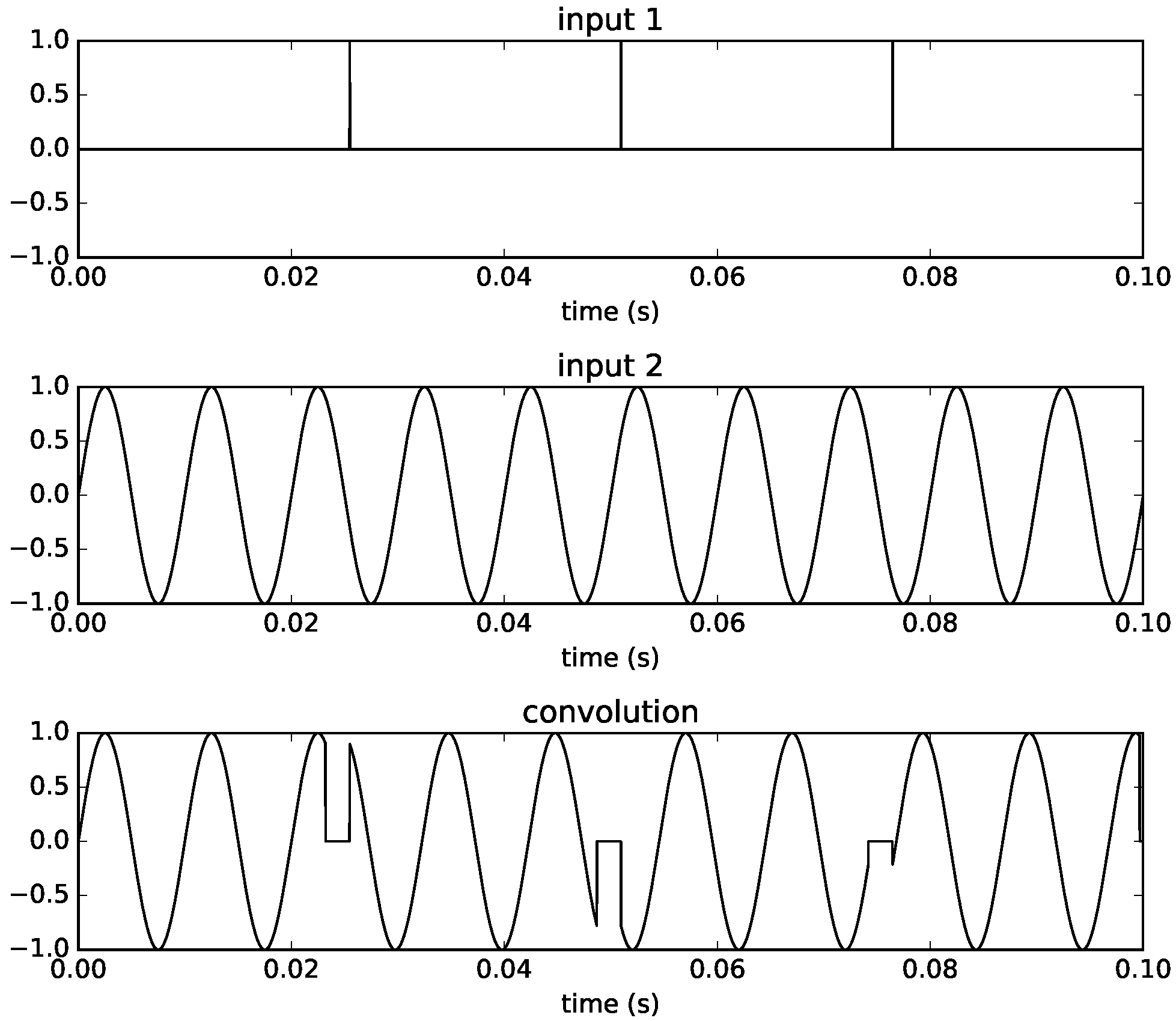
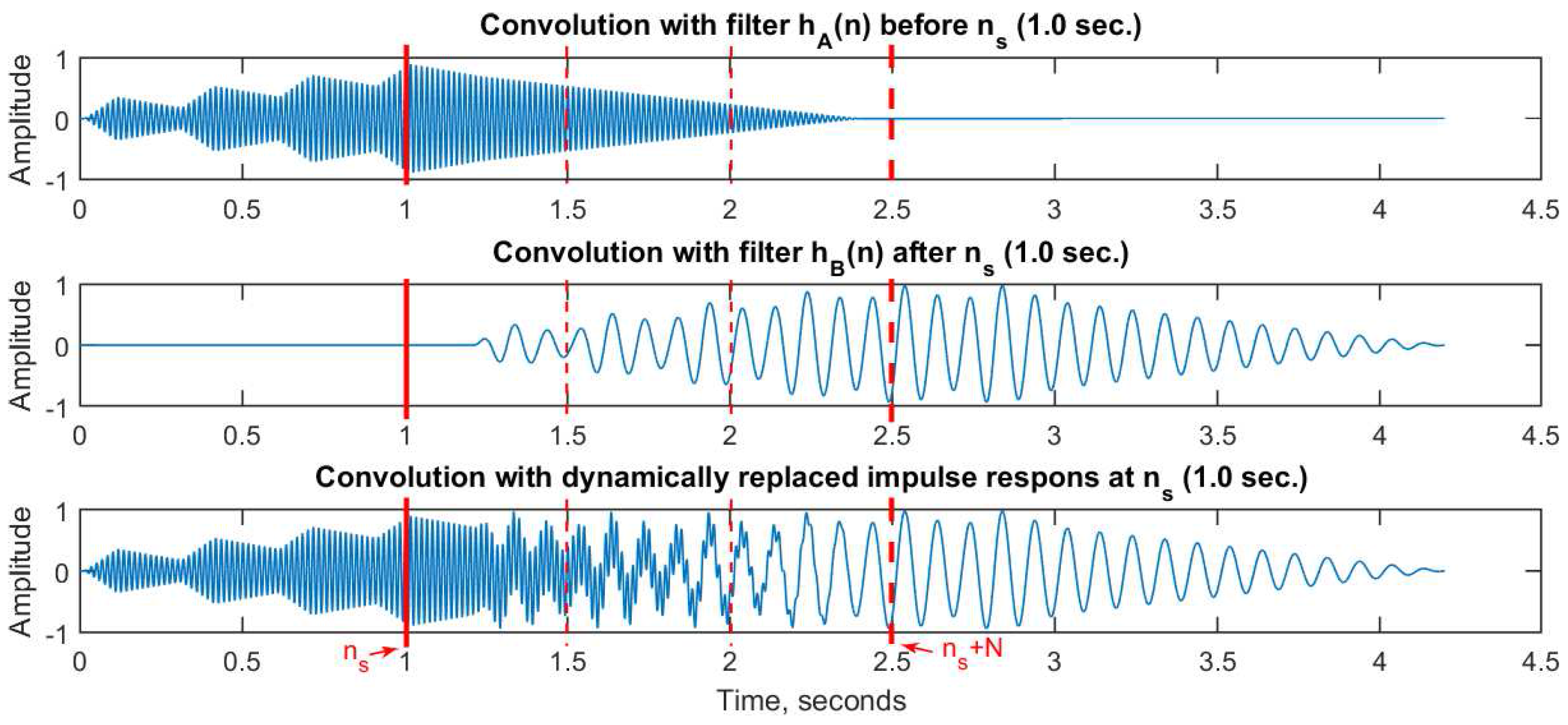
Figure 3 shows the results. At the top is the output from convolving the input signal
with impulse response
, but only up to the time index
. Notice the convolution tail between 1.0 and 2.5 s, equal to the filter length. In the middle is the output from convolving the input signal
with impulse response
starting after the time index
. Finally, at the bottom, we show the output from convolving the input signal
with both filters, such that
is stepwise replaced by
starting at time index
, following the scheme introduced in the previous section. The important thing to note here is that an identical result is achieved if we instead add together the two partial outputs (top and middle).
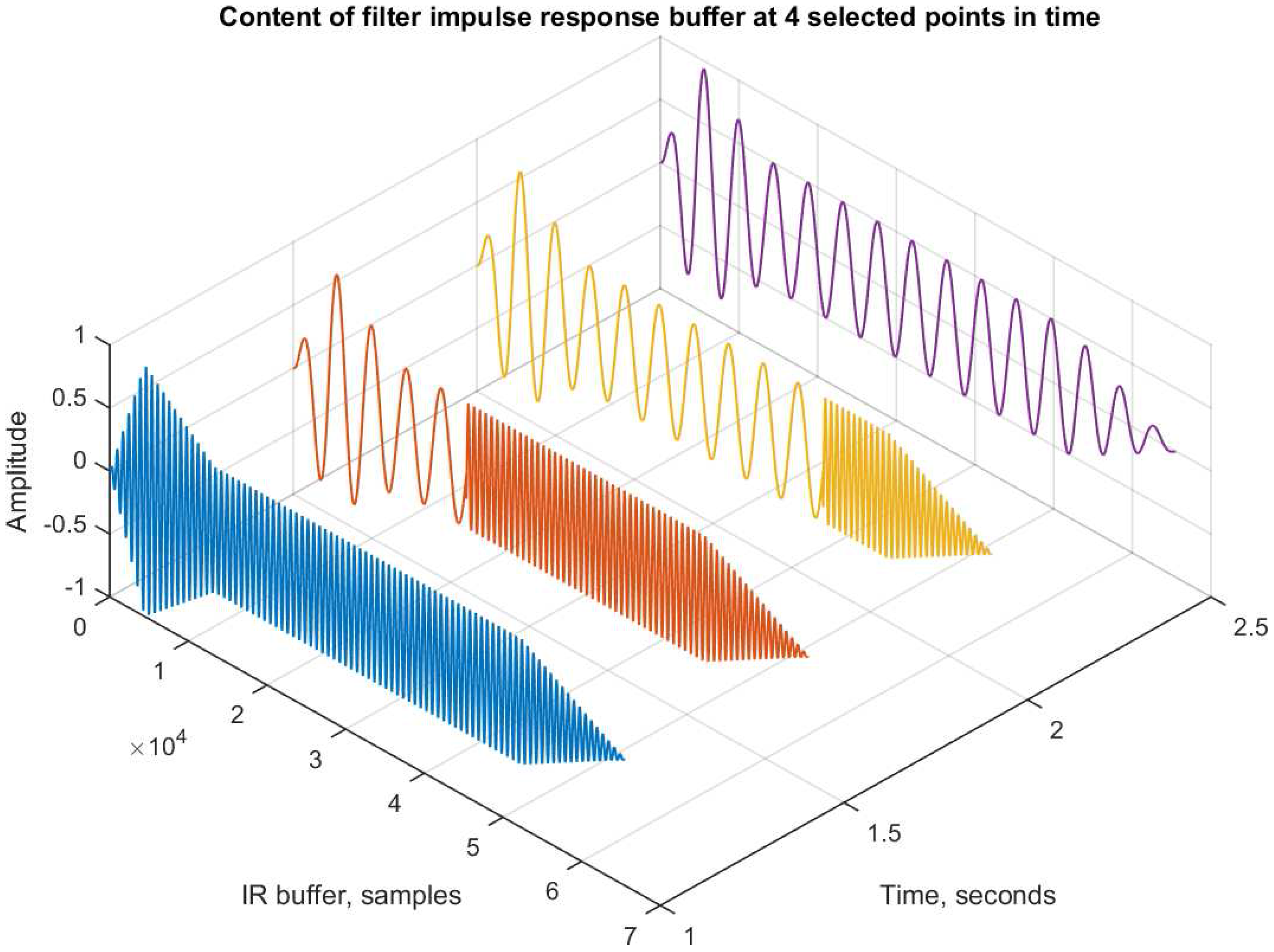
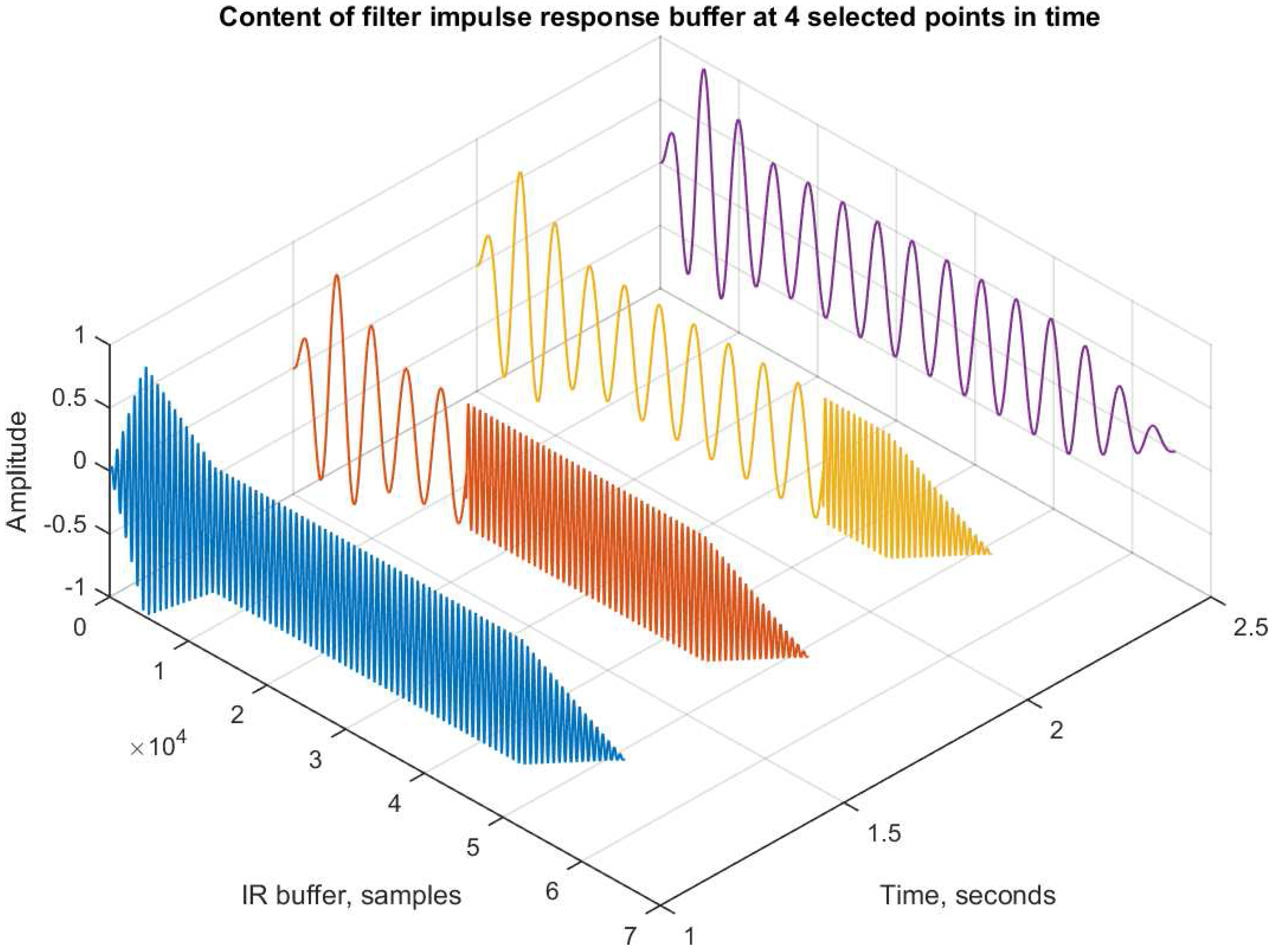
The convolution process is working on a single impulse response buffer. During the filter transition, the buffer will contain parts of both the filters
and
.
Figure 4 illustrates the content of the buffer at four different points in time. Just before transition (
= 1 s), the buffer is entirely filled with impulse response
. During the transition (1.5 and 2.0 s), we notice how the buffer is gradually filled with impulse response
, starting from sample 0. After the transition (
= 2.5 s), the buffer is entirely filled with impulse response
.
There are noticeable discontinuities in the buffer content during transition, but it is important to realize that each of these buffer snapshots will be multiplied with the input to produce a single output sample. They are not temporal objects per se. As mentioned earlier, the method is equivalent to segmenting the input signal at the time : any input , convolves with filter only. Any input , convolves with filter only.
4. Time-Varying Convolution
Time-varying filters whose coefficients are changing at audio rates, as is the case here, have many applications in music [
13,
37,
38]. In particular, some significant attention has been dedicated to infinite impulse response types that whose coefficients are modulated by a periodic signals [
39,
40,
41,
42]. These filters tend to be of lower order (first or second order), which have equivalent longer forms made up of two sections arranged in series, a TVFIR and a fixed-coefficient IIR [
41]. It has also been shown that the most significant part of the effect of these filters is contained in the TVFIR component.
The case we will examine here presents a TVFIR whose coefficients are taken from an arbitrary input waveform, segmented by the filter length
N. This is formally defined by employing the sequence
as the set of
N filter coefficients starting at a given time index
n:
This expression involves future values of
and needs to be adapted so that we can calculate the signal
based solely on the current and past values of the inputs. Furthermore, if we are to calculate successive values of
, the following expression should apply:
from which we should note that the complete set of
N filter coefficients will differ only by one value as the current time index
n increments by one. If we compare the first
N samples of
and
, we will observe that they share
values. To get the
N coefficients
, we only need to discard
, shift all samples by one position to the left, and replace the last sample of the sequence by a new value
. We can do this efficiently by applying a circular shift in the coefficients based on the filter size and current time. In this scenario, a set of
N coefficient functions
can be defined as
where each one of the coefficients will change only once every
N samples, as the signal
is taken in by the filter. They will hold their values until a their update time is due. Using this set of coefficients
as defined in Equation (
22), the TVFIR filter expression becomes (assuming that
,
, and
for
)
which defines what in this paper we call
time-varying convolution (to distinguish it from the more general forms of TVFIR filters, even though in the other cases the convolution is actually also time varying). In this scenario, we are interpreting an arbitrary input signal of length
N as an impulse response, and allow it to vary on a sample-by-sample basis. The resulting set of coefficients
, derived from
, is completely replaced every
N samples. There is, in fact, no particular distinction between the two inputs to the system (
and
), and we may wish to view either as the “filtered” signal or the “impulse response”. Taking one of these, e.g.,
, as the filter coefficients, we can determine the filter frequency response for an input
from the filter transfer function, which has to be determined at every sample. This becomes then a function of two variables, frequency
k and time
n, and can be evaluated by taking its DFT at every
N samples:
where
is the result of applying a rectangular window of length
N to
, localised at time index
, with
l a non-negative integer, and
. Equally, we can take the input signal DFT,
with
similarly defined. The time-varying spectrum of the output of this filter is defined by
The resulting spectrum is therefore a sample-by-sample multiplication of the short-time input spectra. The convolution waveform can be obtained by applying an inverse DFT of size . Therefore, as in the time invariant case, the filter can be implemented either in the time domain with a tapped delay line or in the frequency domain using the fast Fourier transform (FFT).
The time-varying convolution effect is a type of cross-synthesis of two input signals. It tends to emphasise their common components and suppress the ones that are absent in one of them. The size of the filter will have an important role in the extent of this cross-synthesis effect and the amount of time smearing that results. As with this class of spectral processes, there is a trade-off between precise localisation in time and frequency. With shorter filter sizes, the filtering effect is not as distinct, but there is a better time definition in the output. With longer lengths, we observe more of the typical cross-synthesis aspects, but the filter will react more slowly to changes in the input signals.
4.1. Fixing Coefficients
A variation on the time-varying convolution method can be developed by allowing coefficients to be fixed for a certain amount of time. Since there is no particular distinction between the two input signals, it is possible for either of these two to be kept static at any given time. More formally, under these conditions, a given
coefficient update can be described by
where
d is a non-negative integer that depends on how long
is being kept static. If the input signal is varying, we can take that
. Generally, we can assume that the if signal is held for one full filter period (defined as
N samples), then
. Under these conditions,
d would be determined by how many periods the set of coefficients has been static. However, in practice, we can have a more complex sample-by-sample switching that could hold certain coefficients static, while allow others to be updated. In this case, the analysis is not so simple. In an extreme modulation example, we can have coefficients that alternate between delays of
and
samples (
c and
d integer and >0). Again, since there is no distinction between
and
in terms of their function in the cross-synthesis process, similar observations apply to the updating of the input signal samples. If we implement sample-by-sample update switches to each input, then we allow a whole range of signal “freezing” effects. Of course, depending on the size of the filter, different results might apply. For example, if we have a long filter, freezing one of the signals will create a short loop that will be applied over and over again to the other input. If the frozen signal is a genuine impulse response, say of a given space, this will work as an ordinary linear time-invariant (LTI) convolution operation. Thus, the TVFIR principles might be applied as a means of switching between different impulse responses. Smooth cross-fading can be implemented as a way of moving from one fixed FIR filter to another using the ideas developed here.
4.2. Test Signals
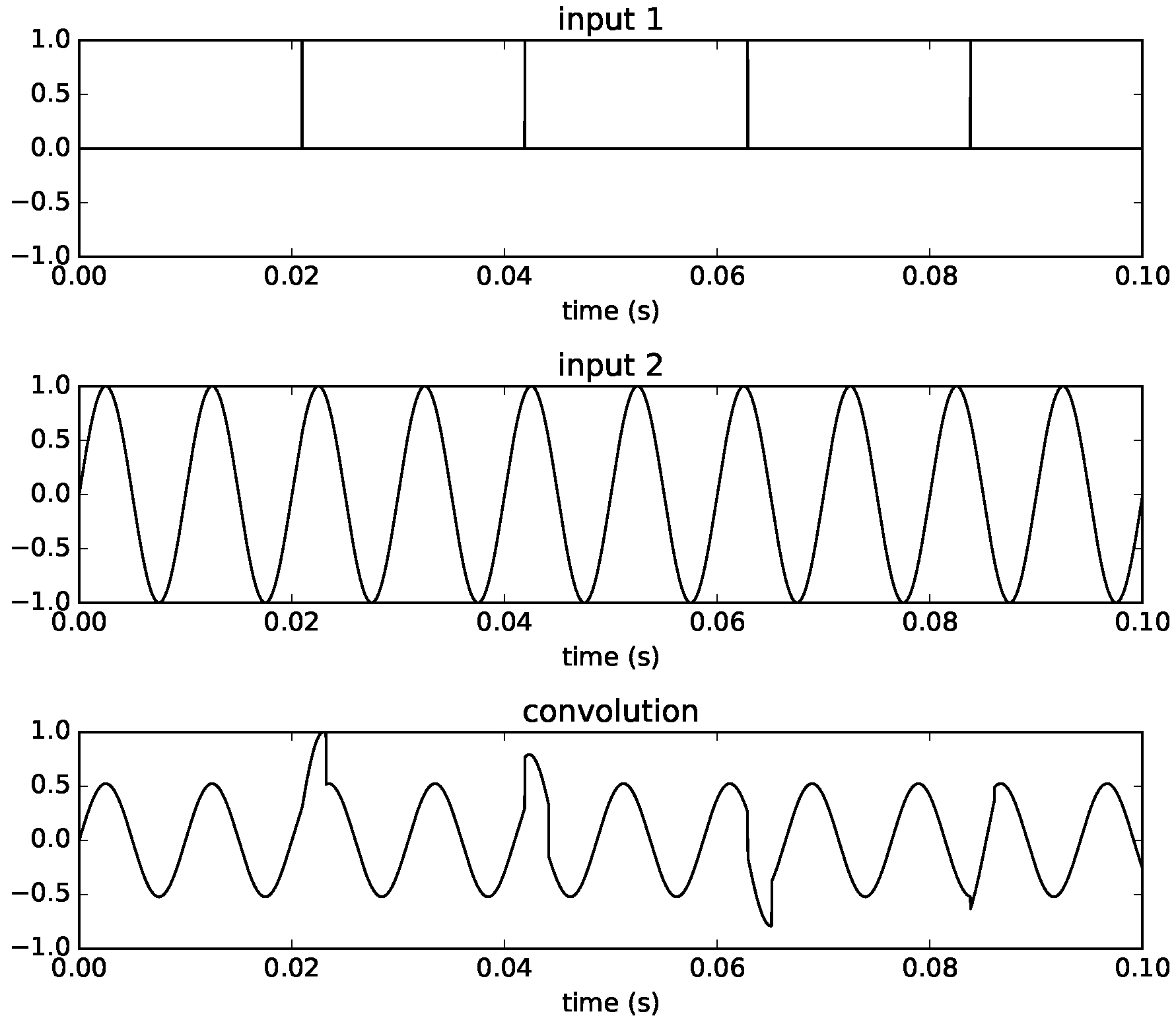
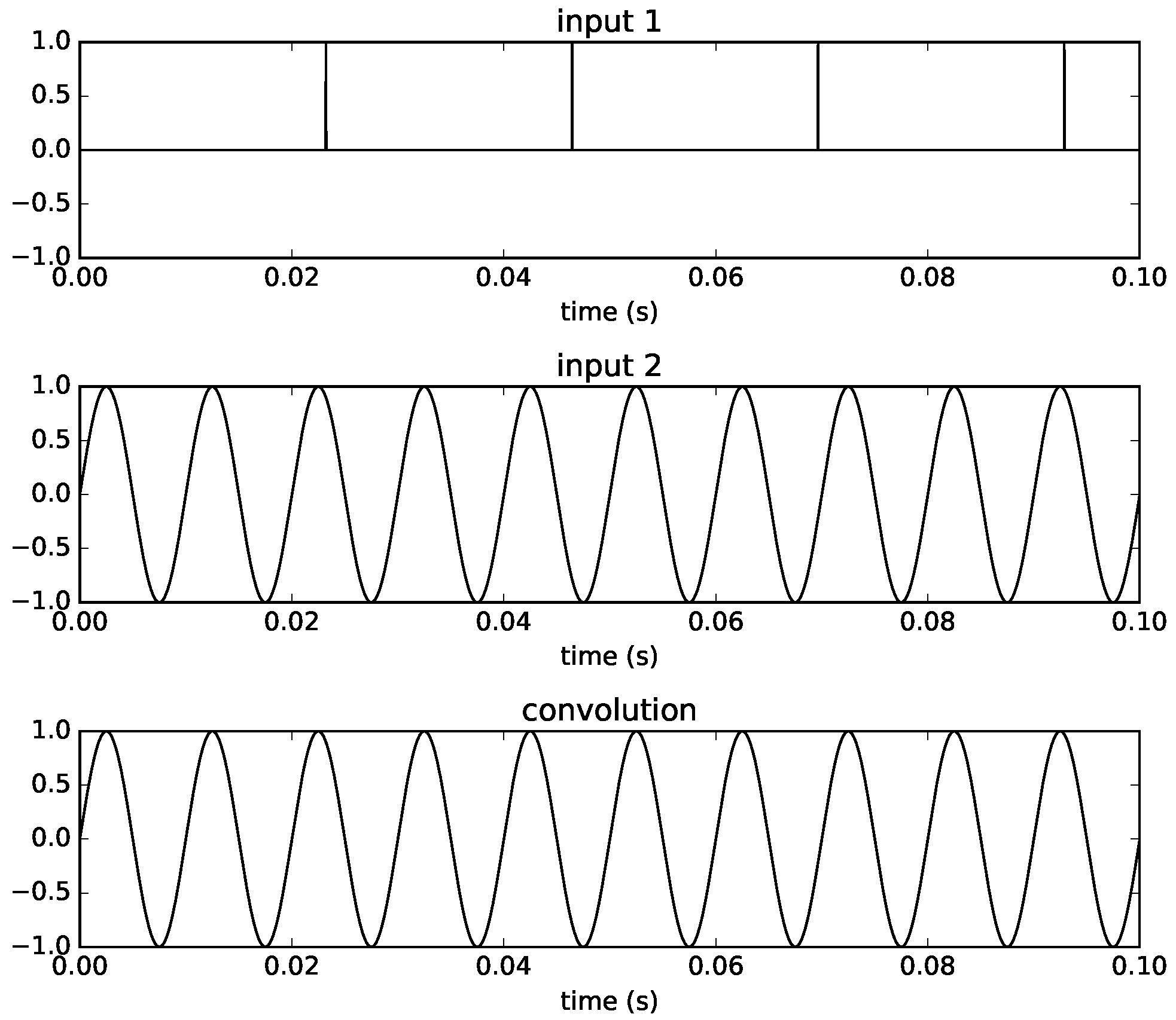
To illustrate some characteristics of time-varying convolution, we look at some cases of time-varying convolution using test signals as inputs. In the first example, we use a pulse train with a frequency of
Hz and a sine wave with frequency of 100 Hz using a filter size equal to 1024 samples. This is shown in
Figure 5, where we can see that with a pulse at the start of each new filter, the waveform is reconstructed perfectly. This is of course equivalent to having a fixed IR consisting of a unit sample at the start.
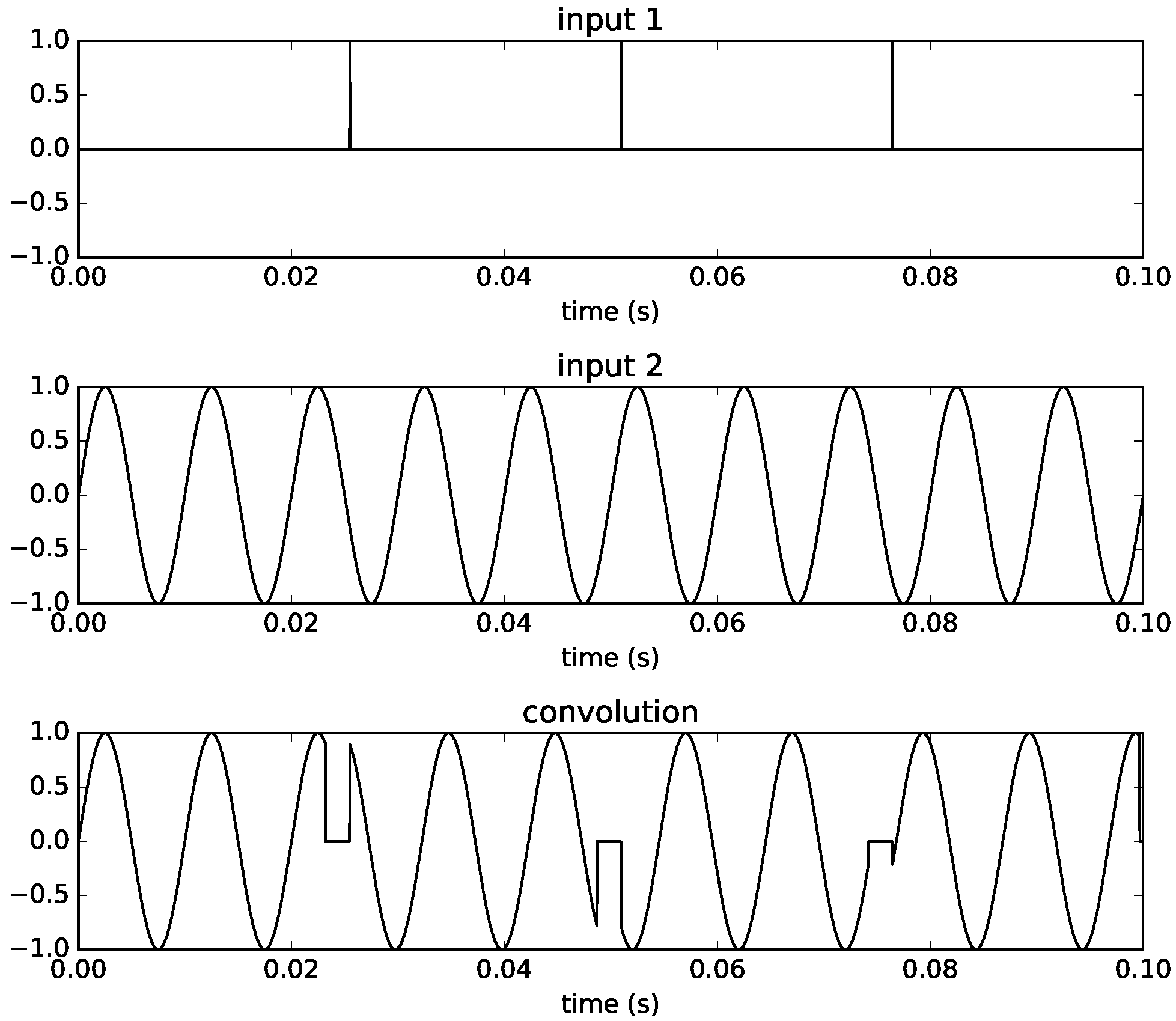
In the second example (
Figure 6), we decrease the pulse train frequency to
Hz and now the impulses are spaced by 100 more samples than one filter length. The output then contains zeros at these samples, and the sine wave is shifted in time by 100 samples, as the impulse localises the start of the sinusoid at its corresponding time. We can see how the result is that a gap is inserted in the signal.
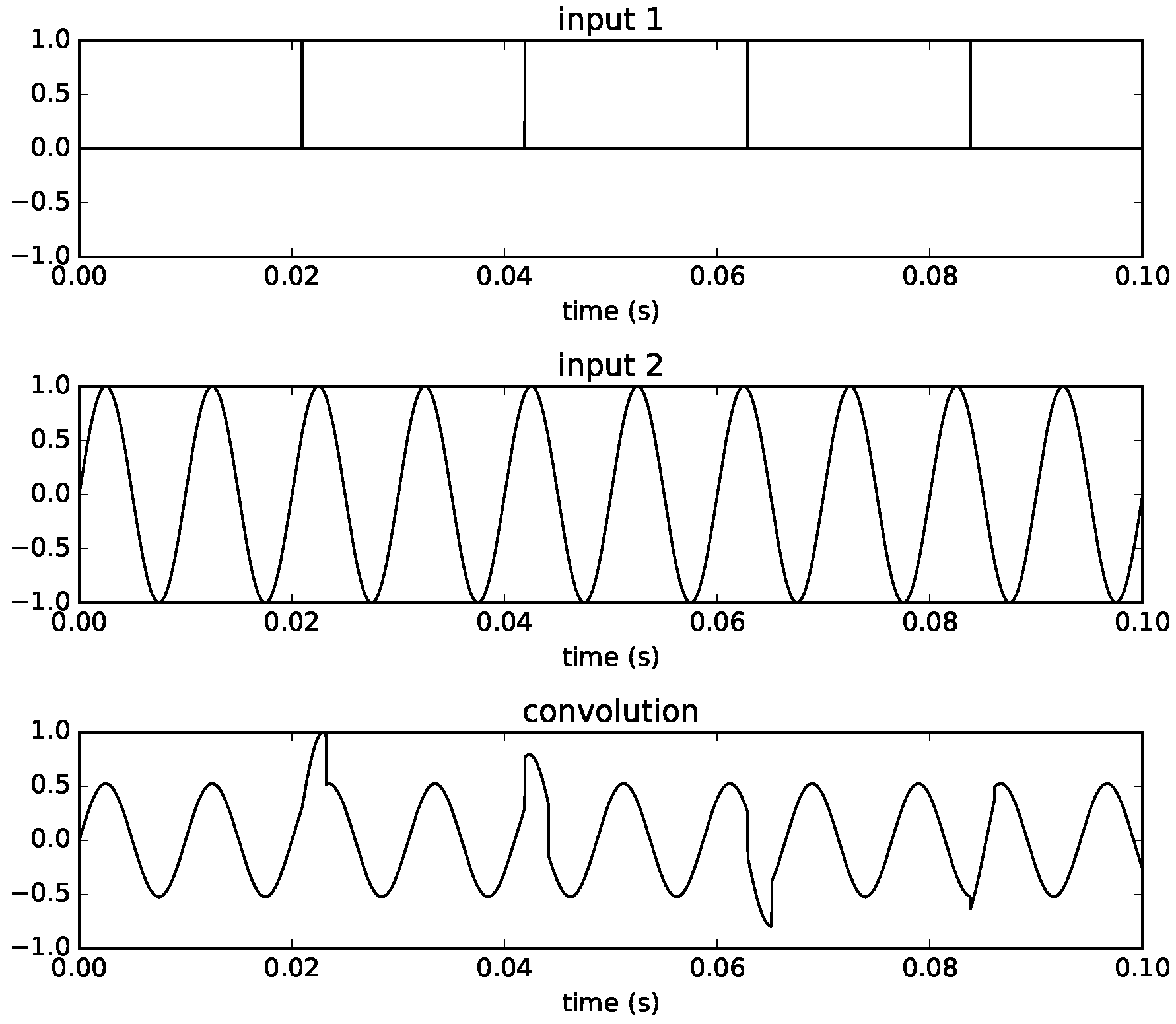
The final example in
Figure 7 shows the converse of this. If we increase the frequency to
Hz, now a new sinusoid is added to the signal before the previous one has completed its
N samples. The effect is to distort the waveform shape at the points where there is an overlap. The distortion appears because the impulses do not coincide with the beginning of the waveform and the waveform itself does not complete full cycles in one filter length.
Note that these examples are somewhat contrived. They are used to illustrate the process of time-varying convolution in a simple way, and are unlikely to arise in practical musical applications of the process. Thus, we need not infer that the quality of cross-synthesis results will be impaired due to the obvious discontinuities seen in the some of the outputs in these examples. However, they are indicative of the fact that the result of the process is very much dependent on the types of inputs as well as the filter lengths employed.
6. Applications and Use Cases
The two different convolution techniques described above has been used as the basis for two live processing instruments. The instruments are software based and designed to be used with live performers, convolving the sound produced by one musician with the sound produced by another. The instruments are packaged in the form of software plugins in the VST (Virtual Studio Technology (VST) is a software interface that integrates software audio synthesizer and effect plugins with audio editors and recording systems.) plugin format, compiled using the Cabbage [
47] framework. Source code for the plugins is available at [
48]). This work has been done in the context of a larger research project on crossadaptive audio processing [
7], wherein these convolution techniques can be said to form a subset of a larger collection of techniques investigated. The aims of the crossadaptive research forms the motivation for the design of the instruments, and thus it is appropriate to describe these briefly before we move on. It is noteworthy that the work with the application has been done in the context of artistic research, following methods of artistic exploration rather than scientific methods. This means that there have been more of a focus on exploring the unknown potential for creative use of these techniques than there has been on testing explicit hypotheses. Thus, there is not a quantifiable verification of test results, but rather an investigation of some application examples expected to prove useful in our artistic work. Intervention into regular and habitual interaction patterns between musicians is one of the core aspects of the research. More specifically, the project aims to develop and explore various techniques of signal interaction between musical performers, such that
the actions of one can influence
the sound of the other. This is expected to stir up the habitual interaction patterns between experienced musicians, and thus facilitating novel ways of playing together, enabling new forms of music to emerge. Some of the crossadaptive methods will be intuitive and immediately engaging, others might pose significant challenges for the performers. In many cases, the musical output will not be immediately appealing, as the performers are given an unfamiliar context and unfamiliar tools and instruments. We do still very much rely on their performative experience to solve these challenges, and the instruments are designed to be as playable as possible within the scope and aims outlined. The crossadaptive project includes a wide range of signal interaction models, many based on feature extraction (signal analysis) and mapping the extracted features onto parametric controls of sonic manipulation by means of digital effects processing [
49]. Those models of signal interaction has the advantage that any feature can be mapped to any sonic modulation; however, all mappings between features and modulations are also artificial. It is not straightforward to create a set of mappings that is as rich and intuitive to the performer as, for example, the relationship between physical gestures and sonic output of an acoustic instrument.
The convolution techniques that are the focus of this article provide a special case in this regard, as the features of the sound itself contains all aspects of modulation over the other sound. The nuances of the sound to be convolved can be multidimensional and immensely expressive in its features. Still, the performer can use his or her experience in relating the instrumental gestures to the nuances of this sound, which in turn constitute the filter coefficients. Thus, there is a high degree of control intimacy, it is intuitive for the performer to relate performative gestures to sonic output, and, with convolution, the sonic output itself is what modulates the other sound. Relating to the recording of an impulse response is as easy and intuitive for the musician as it is to relate to other kinds of live sampling. These are features of the convolution technique that makes it especially interesting in the context of the crossadaptive performance research. At the same time, the direct and performative live use of convolution techniques also opens the way for a faster and more intuitive exploration of the creative potential of convolution as an expressive sound design tool.
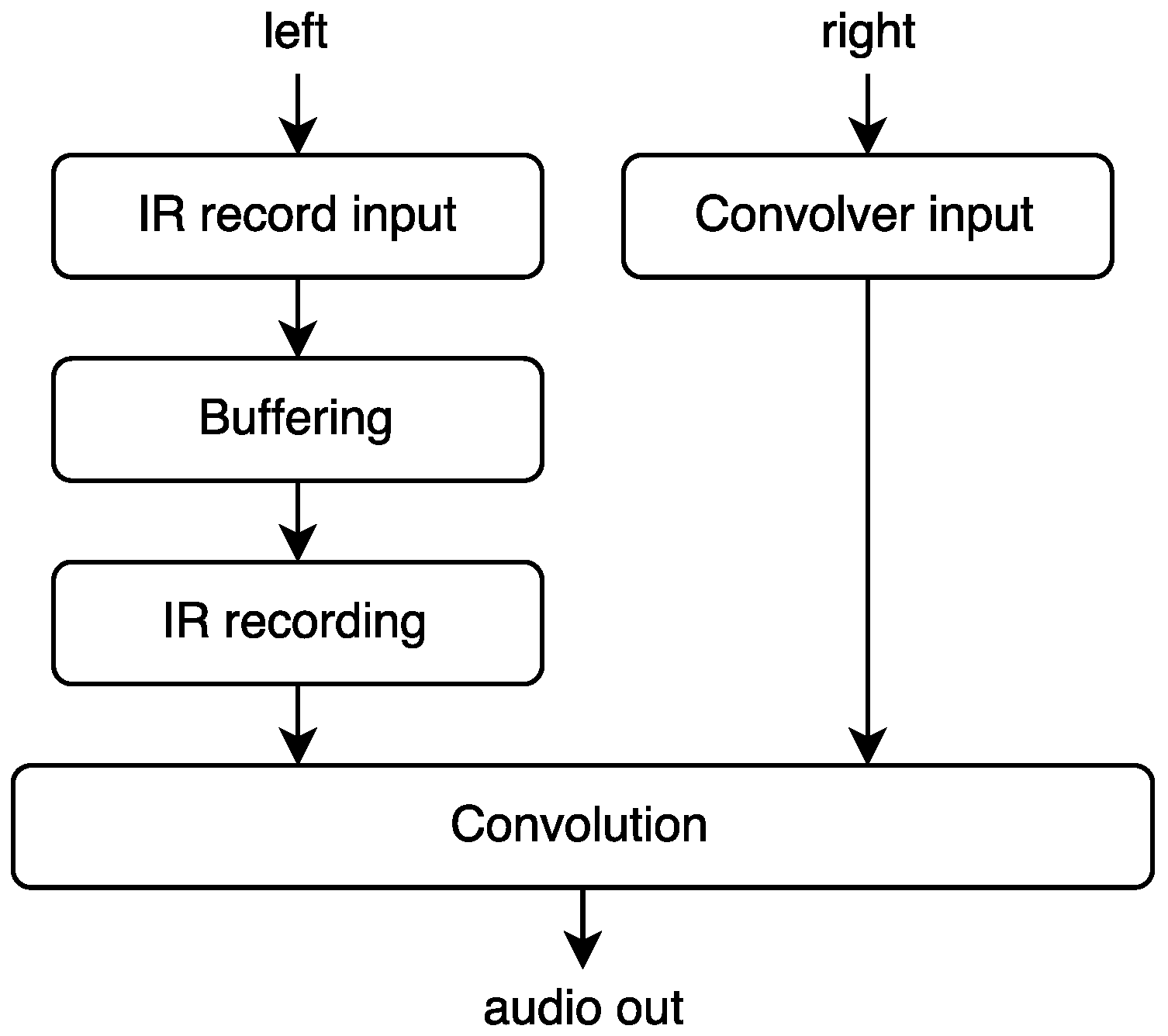
6.1. Liveconvolver
This instrument is designed for convolution of two live signals, but we have retained the concept of viewing one of the signals as an impulse response. This also allows us to retain an analogy with live sampling techniques, as the recording of the impulse response is indeed a form of live capture. The instrument is based on the
liveconv opcode as described in
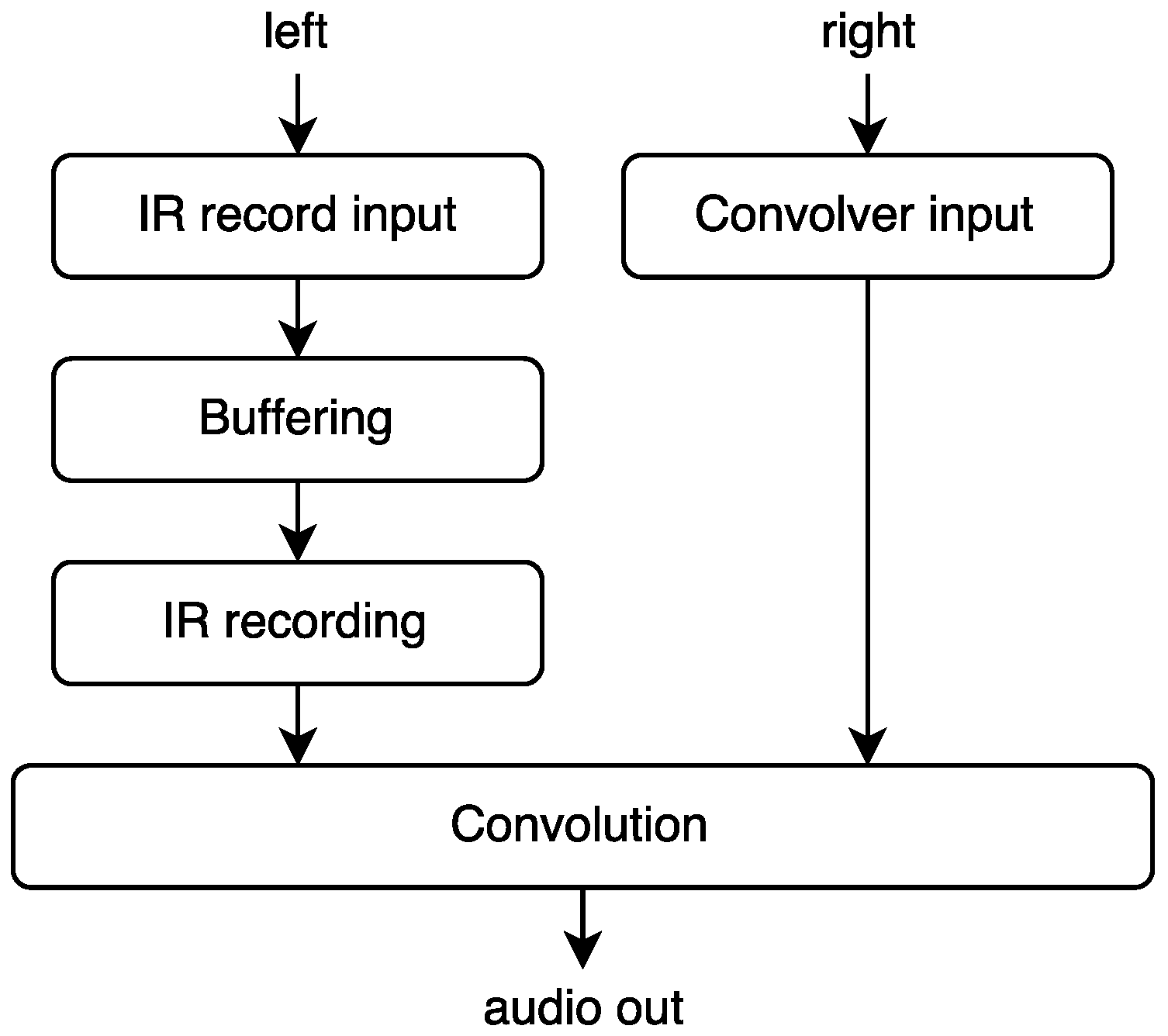
Section 5.4.1. The overall signal flow is shown in
Figure 12. The audio on the IR record input channel is continuously written to a circular buffer. When we want to replace the current IR, we read from this buffer and replace the IR partition by partition as described under
Section 3. The main reason for the circular buffer is to enable transformation (for example time reversal or pitch modification) of the audio before making the IR. If the pitch and direction of the input is not modified, then the extra buffering layer does not impose any extra latency to the process.
The single most important control of this processing instrument is the trigger for
when to replace the IR. This can be done manually via the GUI (Graphical User Interface), see
Figure 13, but, for practical reasons, we commonly use an external physical controller or pedal trigger mapped to this switch. One of the musicians then has control over
when the IR is updated and
how long the new IR will be. In addition to the manual control, this function can also be automatically controlled by means of transient detection or simply set to a periodic update triggered by a metronome. The manual trigger method controlled by an external pedal has been by far the most common use in our experiments.
In addition to the IR record trigger, we have added controls for highpass and lowpass filtering to enable quick adjustments to the spectral profile. When convolving two live signals, the output sound will have a tremendous dynamic range (due to the multiplication of the dynamics of each input sound) and also it will often have a quite unbalanced spectrum (spectral overlap in the two input sounds will be amplified while everything else will be highly attenuated). For this reason, some very coarse and effective controls are needed to shape the output spectrum in a live setting. The described filter controls allows such containment in a convenient manner. Due to the inherent danger of excessive resonances when recording the IR in the same room as the convolver effect is being used, we utilize a simple audio feedback prevention technique (shifting the output spectrum by a few Hz [
50] by means of single sideband modulation). This helps in avoiding feedback, but can also be perceived as a subtle detuning. The amount of frequency shift can be adjusted, and, as such, there is a way to minimize the detuning amount for a given performance situation.
Performative Roles with Liveconv
One can distinguish two different performative roles in this kind of interplay: One performer is recording an impulse response (IR), and the other musician plays through the filter created by this IR. It is noteworthy that the two signals are mathematically equivalent in convolution, it does not matter if one convolves sound A with sound B or vice versa, the output sound will be the same (A*B). Still, the two roles facilitates quite different modes of performance, different ways of having control over the output sound. The performer recording the IR will have significant control over the spectral and temporal texture generated, while the musician playing through the filter will have control over the timing and energy flow.
Before starting the practical experimentation, the clarity and implications of these roles were not clear to us. Even so, it was clear that the two musicians would have different roles. The practical sessions would always start with a description of the convolution process and an explanation of how it would affect the sound. Then, each of the musicians would be allowed to perform in both roles, with discussions and reflections in between each take. In the vast majority of experiments, the musical performance was freely improvised, and the musicians was told to just play on the sound coming back to them. The aim was simply to see how they would respond to this new sonic environment and the interaction possibilities presented. The spontaneous and intuitive reaction of skilled performers to this unfamiliar performance scenario was expected to produce something interesting. As artistic exploration, we wanted to keep the possible outcomes as open as possible. There are many variables not explicitly controlled in these experiments. First of all, each musician has a different vocabulary of sounds, phrases, musical reaction patterns and such. Then, the sonic potential and performative affordances of the acoustic instrument being played. Since the resulting sound is a combination of two instruments (and usually two performers), the combinations of above variables affects the output greatly—likewise, the degree to which the musicians knew each other musically before the experiment. The performance conditions in terms of acoustic space, microphone selection and placement, how the processed sound is monitored (speakers, headphones, balance between acoustic and processed sound, etc.), and other external conditions would also potentially affect the output in different ways. If the aim had been to do a scientific investigation of particular aspects (of performance, interaction, timbral modulation, other), these variables would need to be controlled. However, as an artistic exploration of a hitherto unavailable technique, we have opted to keep these things open. The explorative process would thus be open to allow building on preliminary results iteratively, and allow creative input from the participants to affect the course of exploration. The most interesting products of the experiments are the audio recording themselves, as non-exhaustive examples of possible musical uses.
Even if we here identify two distinct performative roles, these were not preconceived but became apparent from noticing similarities between experiments with different musicians. Some musicians in our experiments would prefer the role of playing through the filter, perhaps since it can closely resemble the situation where one is playing through any electronic effect (e.g., an artificial reverb). Others would prefer the role of recording the IR, since this allows the real-time design of the spectrotemporal environment for the other musician to play in. This divide has been apparent in all our practical experiments thus far—for more detail, see, for example, project blog notes about sessions in San Diego [
51]). If one, for example, records a single long note as the IR, there is not much to do for the performer playing through the effect other than recreating this tone at different amplitudes. Then, if the impulse response is a series of broadband clicks, this will create a delay pattern and the other musician will have to perform within the musical setting thus constituted.
In spite of the slight imbalance of power, with carefully chosen audio material, both performers can have mutual effect on the output, and the techniques facilitates a closely knitted interplay. In addition, varying the duration of the IR is also an effective way of creating distinctly different sections in an improvisation, and thus can be used to shape formal aspect of the music. Varying the length of the IR also directly affect the power balance between the performative roles: a short IR generally creates a more transparent environment for the other performer to act within. Changing between sustained and percussive sonic material in the IR also has a similar effect, while also retaining a richer image of the temporal activity in the IR recording signal.
We have experimented with the live convolver technique in studio sessions and concerts since early 2017. There have been sessions in San Diego and Los Angeles (see link in [
51] and
Figure 14), Oslo (see link in [
52], and Trondheim (see link in [
53] and
Figure 15).
In addition to the creative potential of spectrotemporal morphing, there are also some clear pitfalls. As mentioned, convolution is a multiplicative process, and thus the dynamic range is very large. In addition, it naturally amplifies common frequencies between the two signals, and attenuates everything else. This leads to an unnaturally loud output when the two musicians play melodic phrases where they happen to use common tones. Many musicians will gravitate towards each other’s sound, as a natural aesthetic impulse, trying to create a sonic weave that unites the two sounds. Doing this with live convolution is often counterproductive, as it creates a spectrum with a few extremely high peaks and little other information.
Another danger with live convolution when played over a P.A. in concert is the feedback potential. In this situation, the room (and the sound system) where the performance happens is convolved with itself, effectively multiplying the feedback potential of the system. The performers can also affect the feedback potential, by developing a sensitivity and understanding of which spectral material is most likely to cause feedback problems. Producing material that plays on the resonances of the room generally will increase the danger of feedback. This is another example of a counterintuitive measure for a music performer, as one would normally try to utilize the affordances of the acoustic environment and play things that resonate well in the performance space.
6.2. TV Convolver
This instrument is designed for convolution of two live signals in a streaming fashion, that is, both signals are treated equally and are continually updated. It is based on the
tvconv opcode, as described in
Section 5.4.2. It has controls for freezing each of the signals (see
Figure 16), that is, bypassing the continuous update of the input buffers. Like the liveconvolver instrument, it also has controls for frequency shift amount (for reduction of feedback potential), highpass and lowpass filtering (for quick adjustment to the output spectrum, see
Section 6.1 for details). In addition, it has controls for adjusting the filter length and fade time. The fade time is used in connection with freezing the filter. Even though
tvconv allows freezing the filter at any time, we have opted to only allow freezing at filter boundaries, and also to facilitate a fade out of the coefficients towards the boundary when freezing is activated. These measures are done to avoid artefacts due to discontinuities in the filter coefficients. When used with relatively long filter lengths (typically 65,536 samples in our experiments, 1.4 s at a sampling rate of 44.1 kHz), discontinuities due to freezing could be clearly audible as clicks in the audio output. Furthermore, freezing the filter at any arbitrary point would potentially reorder the temporal structure of the live signal used for filter coefficients (see
Figure 17 and
Figure 18).
Practical Experiments with Tvconv
The streaming nature of this variant of live convolution allows for a constantly changing effect where both of the signals are treated equally. None of them is considered the impulse response for the other to be filtered through; they are simply convolved with each other, where the time window of the convolution is set by the filter length. This instrument has been used in a studio session in Trondheim in August 2017 ([
53] and
Figure 15), and in several live performances in the weeks and months following the initial studio exploration. Since the two signals are treated equally, there are no technical grounds for assuming different roles for the two performers playing into the effect. This also conforms with our experience.
The effect of tvconv is usually harder to grasp for the performers, compared with the liveconvolver instrument. The interaction between the two signals can be musically counterintuitive. In an improvised musical dialogue, performers will sometimes use a call and response strategy, making a musical statement followed by a pause where other musicians are allowed to respond. With streaming convolution, this is not so productive, since there will be no output unless both input signals are sounding at the same time. Thus, it requires a special performative approach where phrases are interwoven and contrapuntal, with quicker interactions. This manner of simultaneous initiatives could be perceived as aggressive and almost disrespectful in some musical settings, as it might appear as one is trampling all over the other musician’s statements. Negotiating this space of common phrasing very clearly affects the manner in which the musicians can interact, which was one of the objectives of the crossadaptive research project.
Due to the manner in which the filter is updated (see
Section 5.4.2), one may perceive a variable latency when performing with tvconv. The technical latency is not variable, but the perceived latency is. This occurs when the first part of the filter contains low amplitude sounds (or sound that is otherwise low in perceptually distinct features), such that the perceived “attack” of the sound is positioned later in the filter (see
Figure 19). In this case, one might perceive the filter’s response as having a longer latency than the strictly technical latency of the signal processing. As the filter coefficients are continuously updated in a circular buffer, there is no explicit way of ensuring that perceptually prominent features of the input sound is written to the beginning of the filter. Admittedly, one could argue that a circular buffer does not have a
beginning as such, but the way it is used in the convolution process means that it matters
where in this buffer salient features of the input sound is positioned. Thus, the perceptual latency can vary within a maximum period set by the size of the filter.
In addition to the immediate interaction of the streaming convolution, another manner of interaction is enabled by giving each of the performers a physical controller (midi pedal) to freeze each of the two filter buffers. If one buffer is frozen, the other performer can play in a more uninterrupted manner, being convolved through the (now static) filter. They can freely switch between freezing one or the other of the inputs and this enables a playful interaction. If both input buffers are frozen, the convolver will output a steady audio loop of length equal to the filter length. In that case, no input is updated, so the filter output is maintained even if both performers fall silent.
We also have a perceptual latency issue when freezing the filter. Since we in our instrument design have allowed freezing only at filter boundaries (see
Section 6.2), a signal to freeze the filter does not always freeze the last
N seconds (where
N is the filter length). Rather, it will continue updating until the write index reaches the filter boundary and then freeze. The time relation between input sounds and the filter buffer is determinate, but since the filter boundaries are not visible or audible to the performers, the relationship will be perceived as somewhat random. In spite of these slight inconveniences, we have focused on the musical use of the filter in performance.
6.3. Demo Sounds
The main application of our convolution techniques has been for live performance. To allow for additional insight into how the processing techniques affect a given source material, we have made some simple demo sounds. These are available online at [
54]. The same source have been used for both
liveconv and
tvconv, and one example output created for each of these two convolution methods. Due to the parametric nature of the methods, a large number of variations on output sounds could be conceived. These two examples simply aim at showing the techniques in their simplest form.
6.4. Future Work
There are some typical problems in using convolution for creative sound design that are even more emphasized when using it for live performance. These relate to the fact that convolution is a multiplicative process, and as such has a tremendous dynamic range. Moreover, if spectral peaks in the two signals overlap, the output sound will tend to have extreme peaks at corresponding frequencies. One possible solution to this might be utilizing a spectral whitening process as suggested by Donahue [
55], although this has not yet been fully solved for the case of real-time convolution with time-varying impulse responses. Another approach might be to analyze the two input spectra and selectively reduce the amplitude of overlapping peaks, allowing control over resonant peaks without other spectral modifications. Furthermore, the impulse response update methods described in this article could be applied in more traditional manners, like parametric control of convolution reverbs and so on.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
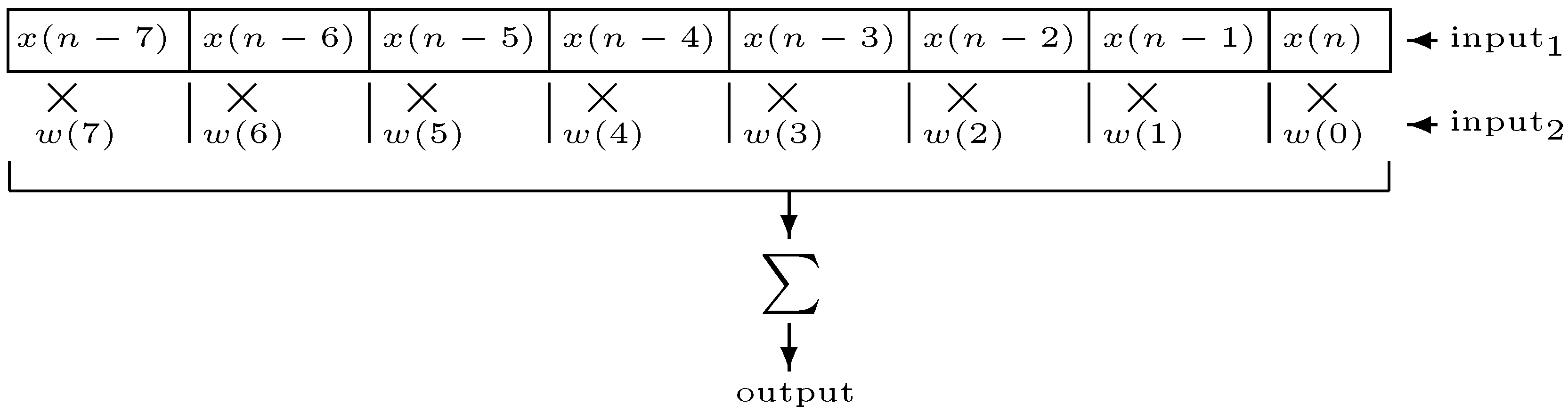{kind=link}
{kind=link}
{kind=link}
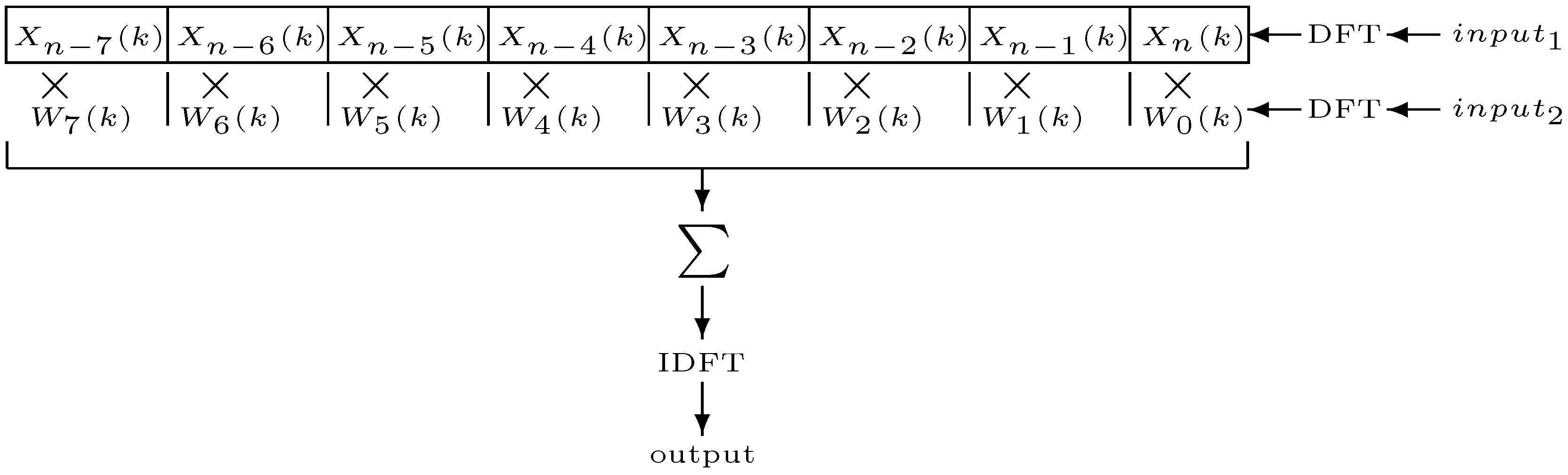{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}