
EigenScape: A Database of Spatial Acoustic Scene Recordings


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Recording
2.2. Details
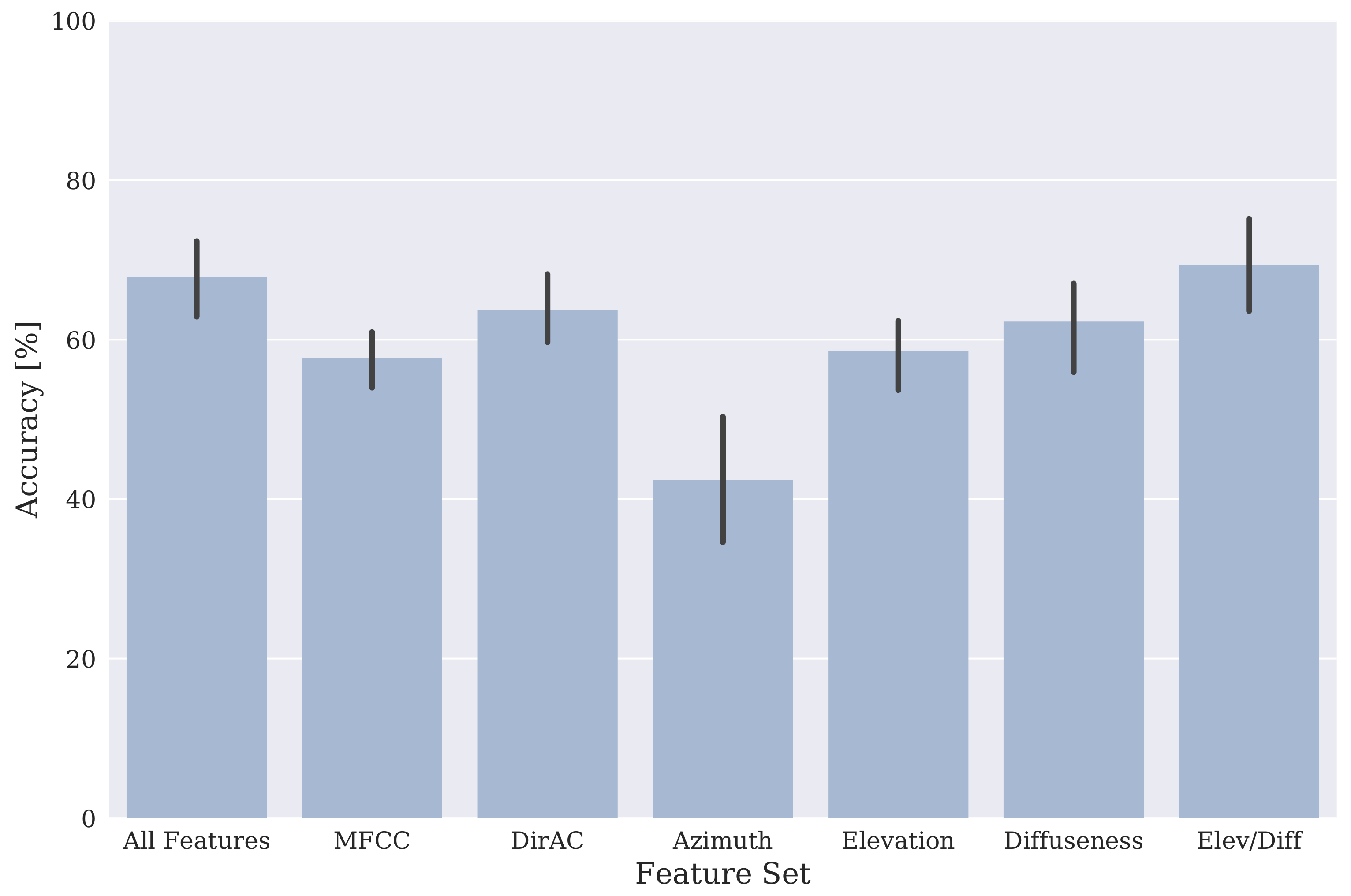
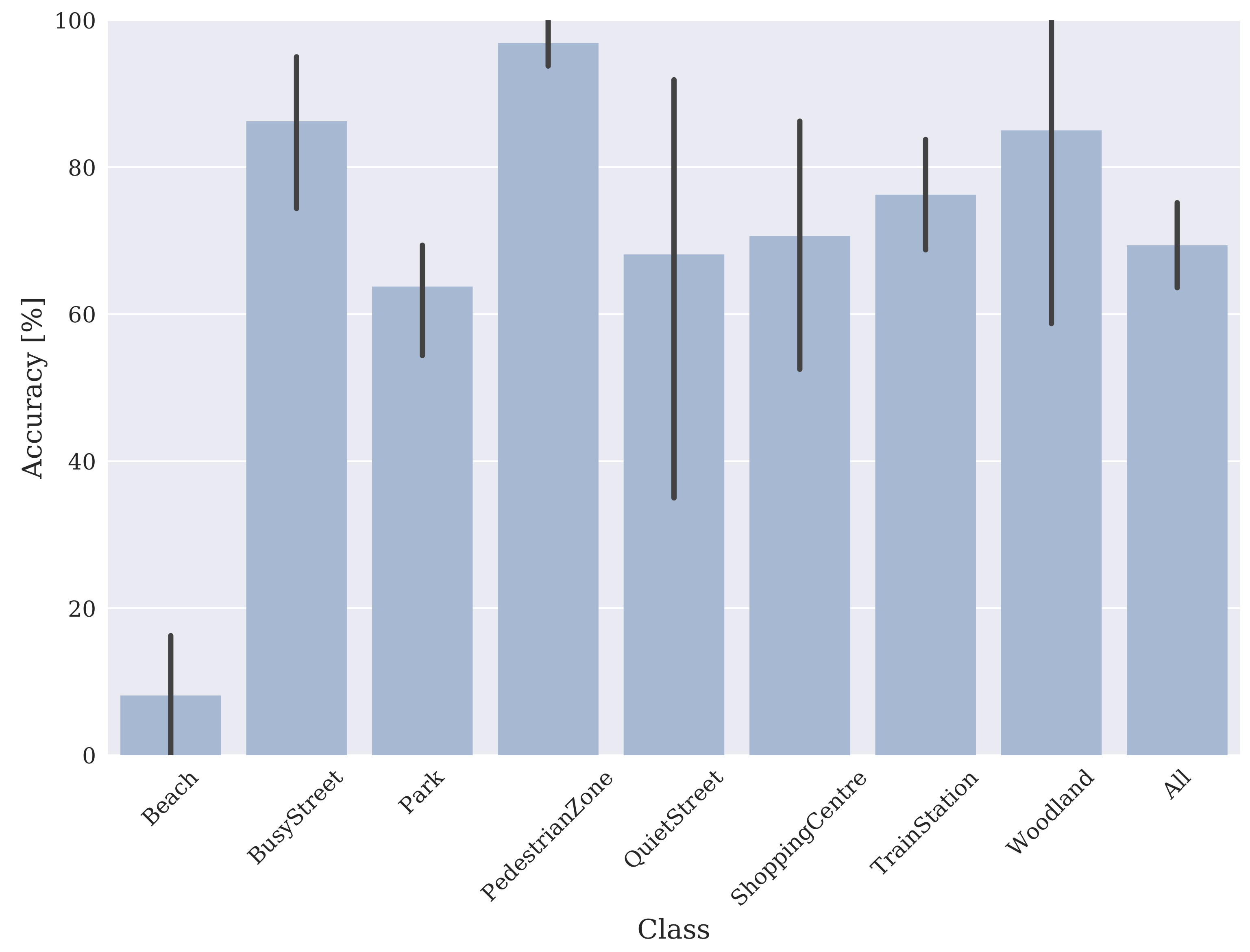
2.3. Baseline Classification
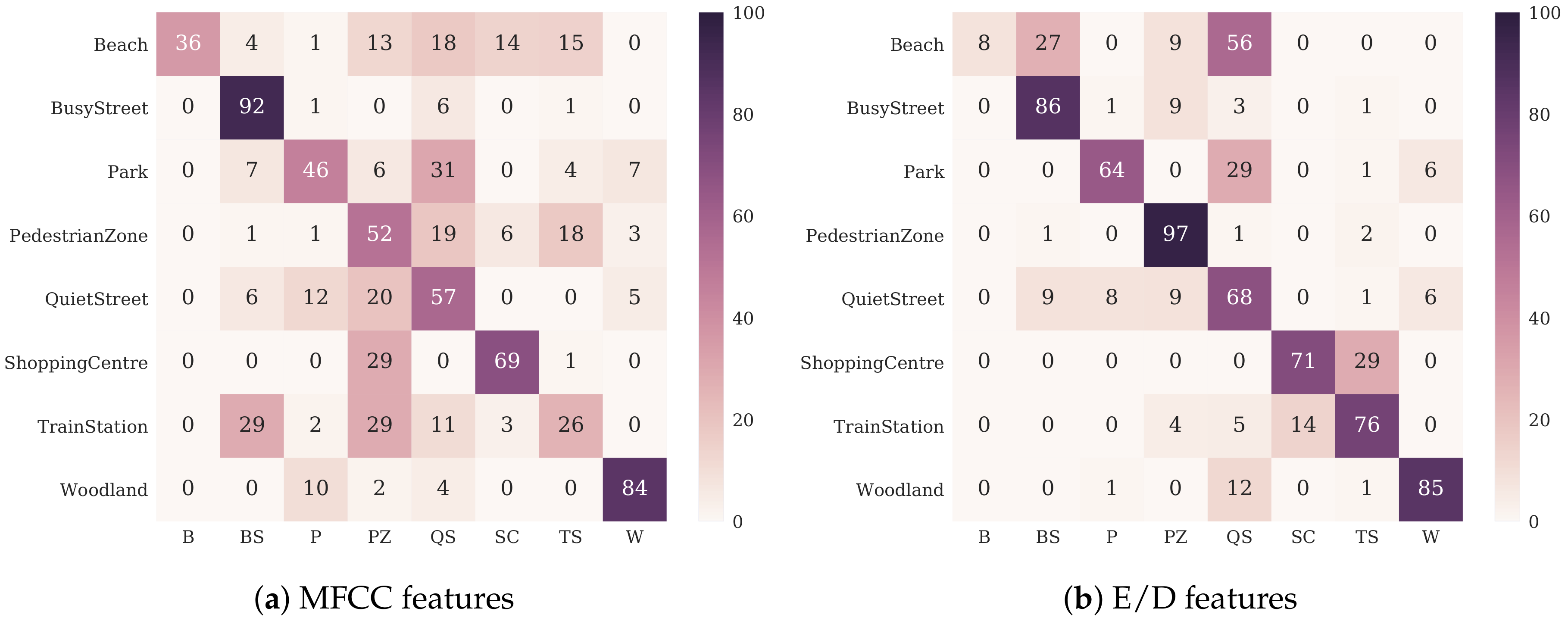
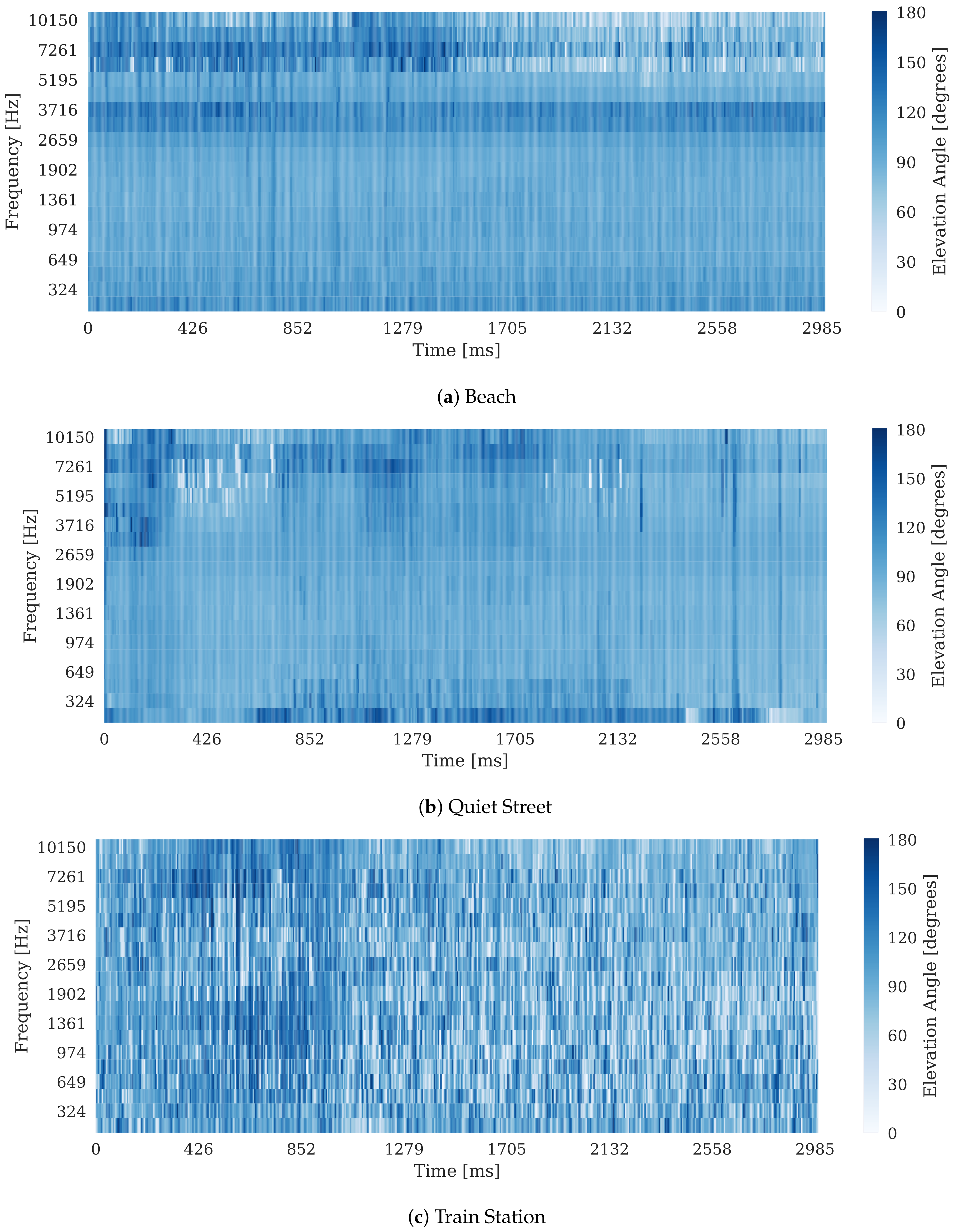
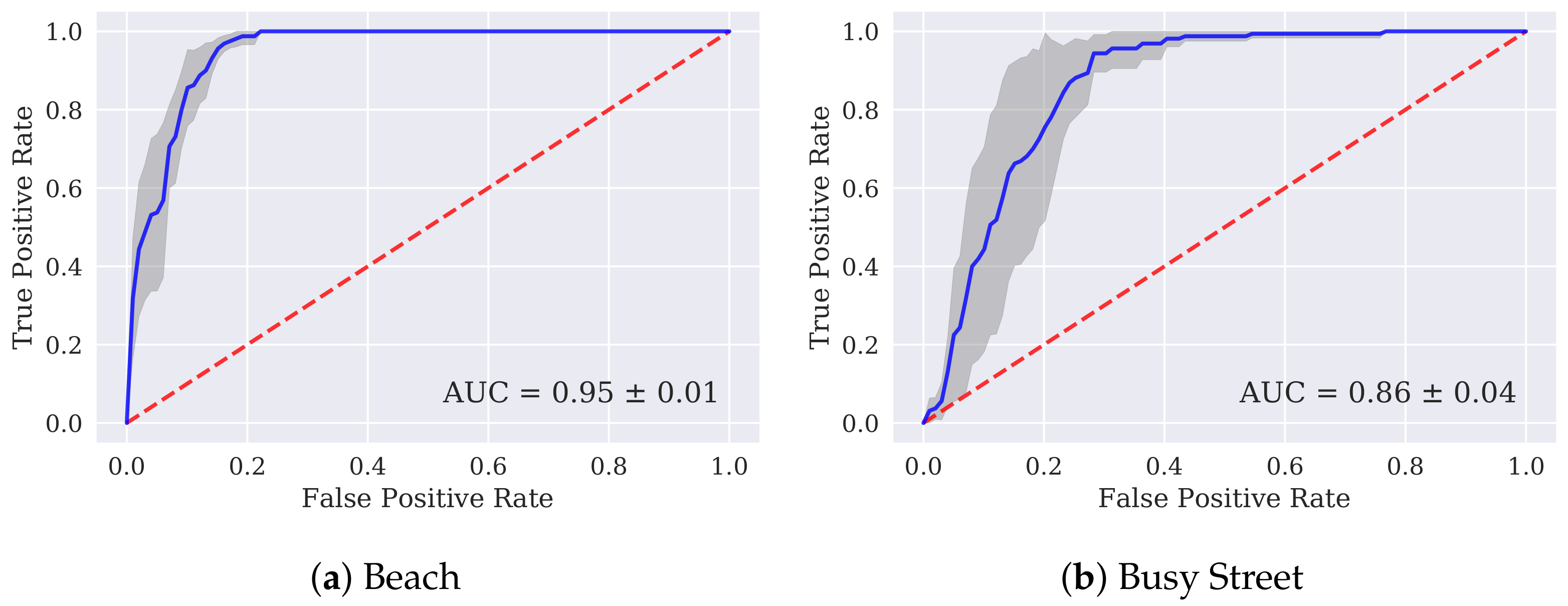
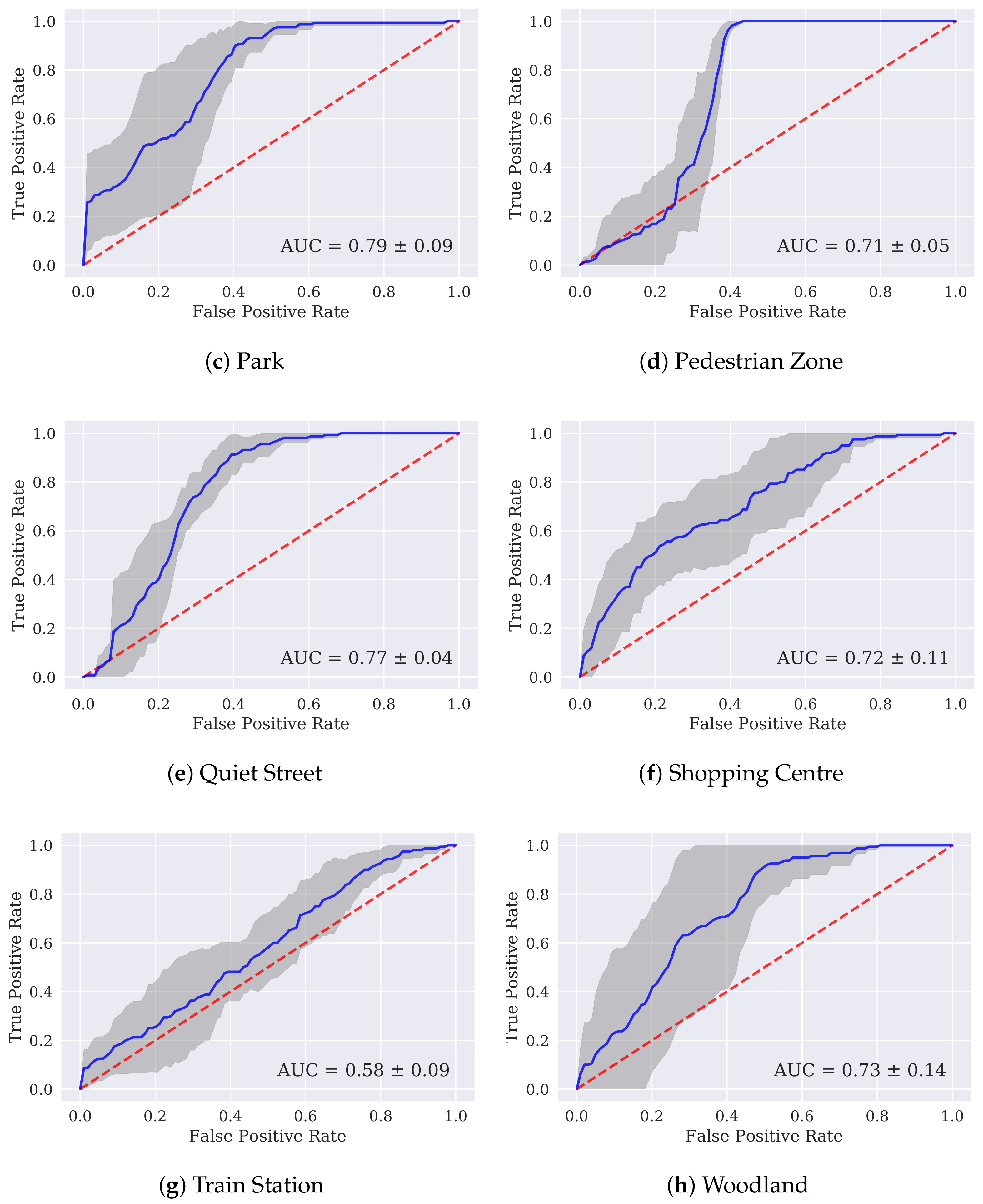
3. Results
4. Discussion
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| MIR | Music Information Retrieval |
| DCASE | Detection and Classification of Acoustic Scenes and Events |
| ASC | Acoustic Scene Classification |
| AED | Acoustic Event Detection |
| MFCC | Mel-Frequency Cepstral Coefficients |
| DOA | Direction of Arrival |
| DirAC | Directional Audio Coding |
| GMM | Gaussian Mixture Model |
| E/D | Elevation/Diffuseness |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
References
- Wang, D. Computation Auditory Scene Analysis: Principles, Algorithms and Applications; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Cherry, C. On Human Communication: A Review, a Survey, and a Criticism; MIT Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Raś, Z. Advances in Music Information Retrieval; Springer-Verlag: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- The Magic that Makes Spotify’S Discover Weekly Playlists So Damn Good. Available online: https://qz.com/571007/the-magic-that-makes-spotifys-discover-weekly-playlists-so-damn-good/ (accessed on 18 September 2017).
- Stowell, D.; Giannoulis, D.; Benetos, E.; Lagrange, M.; Plumbley, M.D. Detection and Classification of Acoustic Scenes and Events. IEEE Trans. Multimed. 2015, 17, 1733–1746. [Google Scholar] [CrossRef]
- Barchiesi, D.; Giannoulis, D.; Stowell, D.; Plumbley, M.D. Acoustic Scene Classification: Classifying environments from the sounds they produce. IEEE Signal Process. Mag. 2015, 32, 16–34. [Google Scholar] [CrossRef]
- Adavanne, S.; Parascandolo, G.; Pertilä, P.; Heittola, T.; Virtanen, T. Sound Event Detection in Multisource Environments Using Spatial and Harmonic Features. In Proceedings of the Detection and Classification of Acoustic Scenes and Events, Budapest, Hungary, 3 September 2016. [Google Scholar]
- Eghbal-Zadeh, H.; Lehner, B.; Dorfer, M.; Widmer, G. CP-JKU Submissions for DCASE-2016: A Hybrid Approach Using Binaural I-Vectors and Deep Convolutional Neural Networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events, Budapest, Hungary, 3 September 2016. [Google Scholar]
- Nogueira, W.; Roma, G.; Herrera, P. Sound Scene Identification Based on MFCC, Binaural Features and a Support Vector Machine Classifier; Technical Report; IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events; IEEE: Piscataway, NJ, USA, 2013; Available online: http://c4dm.eecs.qmul.ac.uk/sceneseventschallenge/abstracts/SC/NR1.pdf (Accessed on 6 January 2017).
- Mel Frequency Cepstral Coefficient (MFCC) Tutorial. Available online: http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/ (accessed on 18 September 2017).
- Brown, A.L. Soundscapes and environmental noise management. Noise Control Eng. J. 2010, 58, 493–500. [Google Scholar] [CrossRef]
- Bunting, O.; Stammers, J.; Chesmore, D.; Bouzid, O.; Tian, G.Y.; Karatsovis, C.; Dyne, S. Instrument for Soundscape Recognition, Identification and Evaluation (ISRIE): Technology and Practical Uses. In Proceedings of the EuroNoise, Edinburgh, UK, 26–28 October 2009. [Google Scholar]
- Bunting, O.; Chesmore, D. Time frequency source separation and direction of arrival estimation in a 3D soundscape environment. Appl. Acoust. 2013, 74, 264–268. [Google Scholar] [CrossRef]
- International Standards Organisation. ISO 12913-1:2014—Acoustics—Soundscape—Part 1: Definition and Conceptual Framework; International Standards Organisation: Geneva, Switzerland, 2014. [Google Scholar]
- Davies, W.J.; Bruce, N.S.; Murphy, J.E. Soundscape Reproduction and Synthesis. Acta Acust. United Acust. 2014, 100, 285–292. [Google Scholar] [CrossRef]
- Guastavino, C.; Katz, B.F.; Polack, J.D.; Levitin, D.J.; Dubois, D. Ecological Validity of Soundscape Reproduction. Acta Acust. United Acust. 2005, 91, 333–341. [Google Scholar]
- Liu, J.; Kang, J.; Behm, H.; Luo, T. Effects of landscape on soundscape perception: Soundwalks in city parks. Landsc. Urban Plan. 2014, 123, 30–40. [Google Scholar] [CrossRef]
- Axelsson, Ö.; Nilsson, M.E.; Berglund, B. A principal components model of soundscape perception. J. Acoust. Soc. Am. 2010, 128, 2836–2846. [Google Scholar] [CrossRef] [PubMed]
- Harriet, S.; Murphy, D.T. Auralisation of an Urban Soundscape. Acta Acust. United Acust. 2015, 101, 798–810. [Google Scholar] [CrossRef]
- Lundén, P.; Axelsson, Ö.; Hurtig, M. On urban soundscape mapping: A computer can predict the outcome of soundscape assessments. In Proceedings of the Internoise, Hamburg, Germany, 21–24 August 2016; pp. 4725–4732. [Google Scholar]
- Aletta, F.; Kang, J.; Axelsson, Ö. Soundscape descriptors and a conceptual framework for developing predictive soundscape models. Landsc. Urban Plan. 2016, 149, 65–74. [Google Scholar] [CrossRef]
- Bunting, O. Sparse Seperation of Sources in 3D Soundscapes. Ph.D. Thesis, University of York, York, UK, 2010. [Google Scholar]
- Aucouturier, J.J.; Defreville, B.; Pachet, F. The Bag-of-frames Approach to Audio Pattern Recognition: A Sufficient Model for Urban Soundscapes But Not For Polyphonic Music. J. Acous. Soc. Am. 2007, 122, 881–891. [Google Scholar] [CrossRef] [PubMed]
- Lagrange, M.; Lafay, G. The bag-of-frames approach: A not so sufficient model for urban soundscapes. J. Acoust. Soc. Am. 2015, 128. [Google Scholar] [CrossRef] [PubMed]
- Mesaros, A.; Heittola, T.; Virtanen, T. TUT Database for Acoustic Scene Classification and Sound Event Detection. In Proceedings of the 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 28 August–2 September 2016. [Google Scholar]
- Joachim Thiemann, N.I.; Vincent, E. The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings. In Proceedings of the Meetings on Acoustics, Montreal, QC, Canada, 2–7 June 2013; Volume 19. [Google Scholar]
- MH Acoustics. em32 Eigenmike® Microphone Array Release Notes; MH Acoustics: Summit, NJ, USA, 2013. [Google Scholar]
- Bates, E.; Gorzel, M.; Ferguson, L.; O’Dwyer, H.; Boland, F.M. Comparing Ambisonic Microphones—Part 1. In Proceedings of the Audio Engineering Society Conference: 2016 AES International Conference on Sound Field Control, Guildford, UK, 18–20 July 2016. [Google Scholar]
- Bates, E.; Dooney, S.; Gorzel, M.; O’Dwyer, H.; Ferguson, L.; Boland, F.M. Comparing Ambisonic Microphones—Part 2. In Proceedings of the 142nd Convention of the Audio Engineering Society, Berlin, Germany, 20–23 May 2017. [Google Scholar]
- MH Acoustics. Eigenbeam Data Specification for Eigenbeams Eigenbeam Data Specification for Eigenbeams Eigenbeam Data Specification for Eigenbeams Eigenbeam Data: Specification for Eigenbeams; MH Acoustics: Summit, NJ, USA, 2016. [Google Scholar]
- Soundfield. ST350 Portable Microphone System User Guide; Soundfield: London, UK, 2008. [Google Scholar]
- Van Grootel, M.W.W.; Andringa, T.C.; Krijnders, J.D. DARES-G1: Database of Annotated Real-world Everyday Sounds. In Proceedings of the NAG/DAGA Meeting, Rotterdam, The Netherlands, 23–26 March 2009. [Google Scholar]
- Samsung Gear 360 Camera. Available online: http://www.samsung.com/us/support/owners/product/gear-360-2016 (accessed on 8 September 2017).
- UK Data Service—Recommended Formats. Available online: https://www.ukdataservice.ac.uk/manage-data/format/recommended-formats (accessed on 11 September 2017).
- Pulkki, V. Directional audio coding in spatial sound reproduction and stereo upmixing. In Proceedings of the AES 28th International Conference, Pitea, Sweden, 30 June–2 July 2006. [Google Scholar]
- Pulkki, V. Spatial Sound Reproduction with Directional Audio Coding. J. Audio Eng. Soc. 2007, 55, 503–516. [Google Scholar]
- Pulkki, V.; Laitinen, M.V.; Vilkamo, J.; Ahonen, J.; Lokki, T.; Pihlajamäki, T. Directional audio coding—Perception-based reproduction of spatial sound. In Proceedings of the International Workshop on the Principle and Applications of Spatial Hearing, Miyagy, Japan, 11–13 November 2009. [Google Scholar]
- Kallinger, M.; Kuech, F.; Shultz-Amling, R.; Galdo, G.D.; Ahonen, J.; Pulkki, V. Analysis and adjustment of planar microphone arrays for application in Directional Audio Coding. In Proceedings of the 124th Convention of the Audio Engineering Society, Amsterdam, The Netherlands, 17–20 May 2008. [Google Scholar]
- Green, M.C.; Murphy, D. Acoustic Scene Classification Using Spatial Features. In Proceedings of the Detection and Classification of Acoustic Scenes and Events, Munich, Germany, 16–17 November 2017. [Google Scholar]







© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Green, M.C.; Murphy, D. EigenScape: A Database of Spatial Acoustic Scene Recordings. Appl. Sci. 2017, 7, 1204. https://doi.org/10.3390/app7111204
Green MC, Murphy D. EigenScape: A Database of Spatial Acoustic Scene Recordings. Applied Sciences. 2017; 7(11):1204. https://doi.org/10.3390/app7111204
Chicago/Turabian StyleGreen, Marc Ciufo, and Damian Murphy. 2017. "EigenScape: A Database of Spatial Acoustic Scene Recordings" Applied Sciences 7, no. 11: 1204. https://doi.org/10.3390/app7111204
APA StyleGreen, M. C., & Murphy, D. (2017). EigenScape: A Database of Spatial Acoustic Scene Recordings. Applied Sciences, 7(11), 1204. https://doi.org/10.3390/app7111204