


Evolutionary Multi-Objective Prompt Learning for Synthetic Text Data Generation with Black-Box Large Language Models



Abstract
1. Introduction
- We introduce a multi-objective evolutionary prompt learning framework for black-box LLM-driven data generation.
- We propose a structured prompt representation and semantic mutation mechanism that preserve linguistic coherence during evolution.
- We empirically demonstrate the effectiveness of the approach on large-scale disaster-related social media data, highlighting its ability to balance semantic preservation and generative diversity.
2. Related Work
2.1. Single-Objective Evolutionary Baselines
2.2. Black-Box Prompt Optimization and Mode Collapse
2.3. Multi-Objective Optimization in NLP
2.4. Metrics for Fidelity and Diversity
2.4.1. Semantic Fidelity
2.4.2. Quantifying Diversity
- Content Diversity: To ensure variation in the generated subjects, metrics like Entity Entropy apply information theory principles [22] to calculate the distribution of Named Entities (persons, locations, organizations). High entropy indicates that the model is generating diverse scenarios rather than recycling generic placeholders or memorized entities.
- Spectral and Geometric Diversity: The current theoretical gold standard is the Vendi Score [23], which calculates the spectral entropy of the similarity matrix to measure effective sample size. Other approaches, like Metric Space Magnitude [24], use algebraic topology to detect “holes” in data coverage.
2.5. Decision Making in Pareto Fronts
3. Preliminaries: The EVOLMD Framework
3.1. Prompt Representation and Agents
- Role (): Defines the persona or perspective (e.g., “As a medical professional”).
- Topic (): Specifies the central subject matter derived from reference data.
- Action (): Dictates the communicative intent.
3.2. Single-Objective Optimization
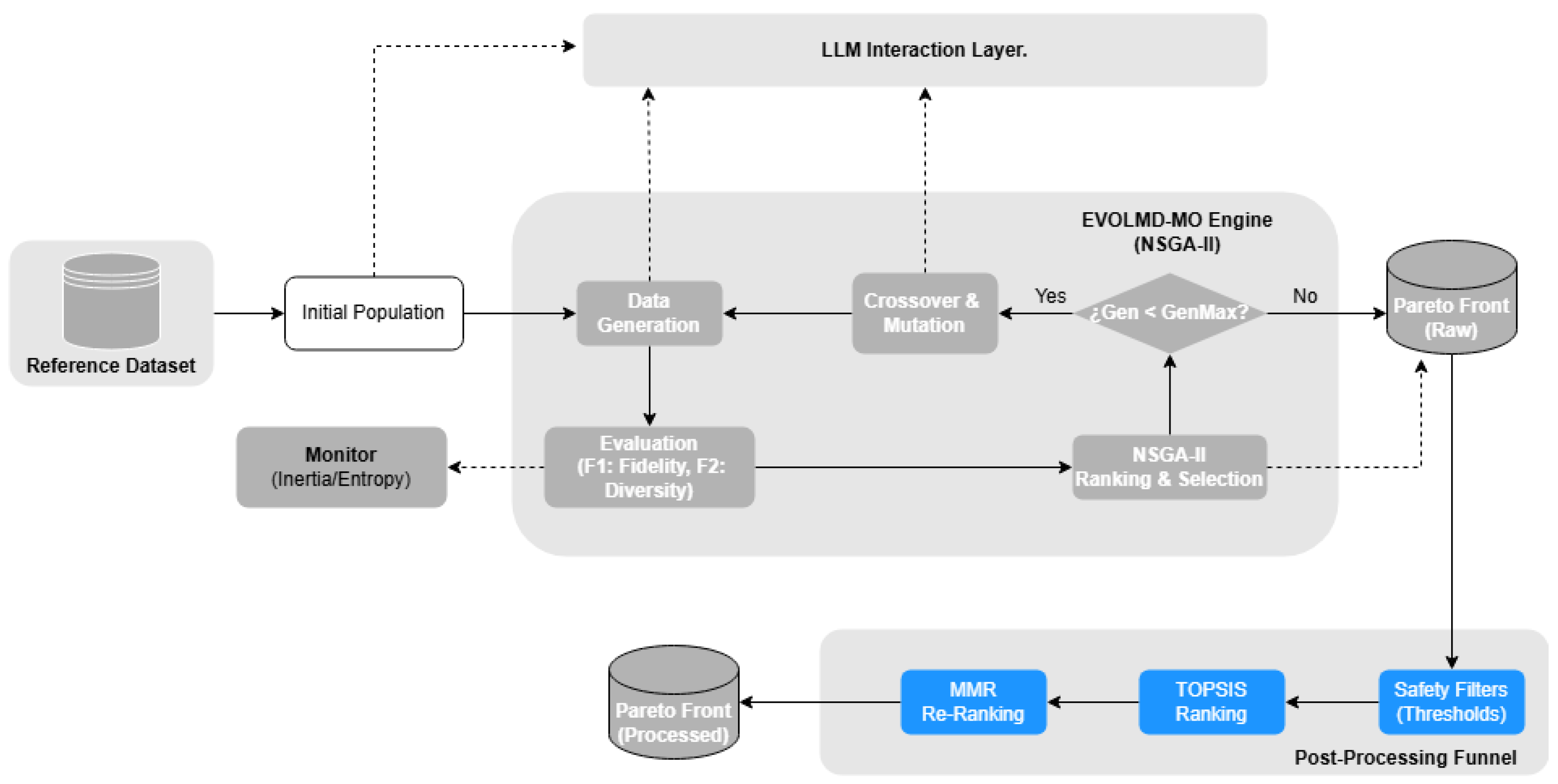
4. Proposed Architecture
4.1. LLM Interaction Layer
- Init Agent: Responsible for creating the initial seed prompts based on the reference dataset.
- Data Agent: Handles the prompt construction and API communication to generate synthetic text.
- Mutation Agent: Supports the evolutionary operators by suggesting semantically similar tokens to introduce variability.
4.2. EVOLMD-MO Engine (NSGA-II)
- Objective 1: Maximizing Fidelity (). We employ SBERT (specifically the all-MiniLM-L6-v2 model) to measure the cosine similarity between the embeddings of the generated text and the reference data . This ensures semantic coherence.Defined as the cosine similarity between the embedding of the generated text and the embedding of the reference text :This transition from the baseline’s standard BERT to SBERT is driven by computational efficiency. Since the multi-objective framework introduces additional algorithmic complexity (specifically for diversity assessment), it is critical to minimize the cost of fidelity evaluation. By reducing the inference overhead for semantic similarity, we offset the computational load of the new components, preventing prohibitive execution times in a system already constrained by the latency bottleneck of LLM queries.
- Objective 2: Maximizing Diversity (). To force the exploration of the search space, we introduce a Global Dissimilarity objective. Unlike local distance metrics, calculates the average cosine distance between an individual and the entire remaining population. This is calculated as the average semantic distance (1 − cosine similarity) between an individual i and all other j individuals in the current population P:This creates global selective pressure against redundancy, penalizing any prompt that closely resembles the population mean.
Genetic Operators and Selection
4.3. Post-Processing Funnel
- 1.
- Safety Filter: Implements a dual-threshold mechanism that defines a valid acceptance window based on the fidelity score. This component automatically rejects candidates classified as semantic hallucinations () or lexical duplicates (). For the experimental validation presented in this study, the lower threshold was set to and the upper threshold to .
- 2.
- TOPSIS Ranking: To automate the final selection and eliminate manual bias—which introduces subjectivity and operational bottlenecks—we implement TOPSIS. This method is selected for its ability to identify the optimal geometric compromise, identifying the individual that best balances both objectives:where and are the Euclidean distances to the ideal positive and negative solutions, respectively. Weights are dynamically calculated using the Entropy Method (, where ). This approach avoids arbitrary human prioritization, allowing the data’s intrinsic variability to determine the relative importance of each objective. Consequently, the selection process becomes fully data-driven, adapting to the specific distribution of the Pareto front in every generation.
- 3.
- MMR Re-ranking: Finally, to construct the final Top-K dataset, we apply Maximal Marginal Relevance (MMR):This iterative method selects candidates that maximize relevance (TOPSIS score) while minimizing similarity to the already selected set. The balance between these two factors is controlled by a tunable diversity parameter (), which governs the penalty for semantic redundancy. For our experiments, we set to prioritize semantic diversity, ensuring the final output covers the broadest possible semantic space and avoids repetition within the post-processed Pareto front.
5. Experiments
5.1. Fidelity Metric Validation
- Reference Text: A complex phrase associated with the group’s theme.
- 4 Candidates: Variations in the reference phrase with different similarity levels (High, Medium-High, Medium-Low, Low/Null).
- Oracle Score: A reference value (0.0 to 1.0) assigned to each candidate, representing the ideal semantic correlation. To ensure an objective and scalable evaluation, we adopt the well-documented LLM-as-a-Judge paradigm [30], employing the Gemini 3 Pro model [31] as an impartial automated oracle to evaluate how related the candidate is to the reference text.
5.2. Semantic Diversity Metrics Evaluation
- 1.
- A Macro-level Analysis to validate if K-Means Inertia correctly measures if the population diversity increases or decreases.
- 2.
- A Micro-level Analysis to verify if the selective pressure favors innovative individuals over redundant ones.
5.2.1. Macro-Level Analysis: K-Means Inertia and Entity Entropy
- Mode Collapse (High Redundancy)
- Chaotic Diversity (Irrelevance)
- Ideal Diversity (Faithful and Diverse)
- 1.
- Differentiation: There is a clear numerical gap between the stagnation state (0.15) and diverse states (>0.22), allowing the algorithm to effectively penalize mode collapse.
- 2.
- Interpretation of High Values: The high inertia observed in the “Chaotic” scenario (0.37) confirms that the metric correctly measures semantic breadth. In the context of the Multi-Objective Evolutionary Algorithm (MOEA), high inertia values are desirable as they indicate extensive exploration of the search space.
- 3.
- Role in Optimization: While “Chaotic Diversity” achieves high inertia through irrelevance, the MOEA filters such solutions via the Fidelity objective. Therefore, the inertia metric successfully fulfills its role as a monitoring signal: it accurately quantifies the expansion of the semantic space (assigning higher values to wider spreads) and provides the necessary data for the optimization engine to reward diversification while the fidelity metric simultaneously constrains the search to relevant regions.
5.2.2. Microscopic Analysis: Sensitivity and Selective Pressure
- A Redundant Cluster (): Three variations of the same sentence with high semantic overlap, representing a stagnant lineage. We anticipate these individuals will receive low novelty scores due to the high semantic overlap among them, and their marginal contribution to the group’s diversity is limited, as they add redundancy rather than expanding the semantic search space.
- An Innovative Group (): Two sentences introducing distinct concepts or perspectives, representing desired genetic mutations. These candidates are expected to achieve significantly higher scores compared to the redundant cluster, correlating with their ability to expand the semantic boundaries of the population and mitigate mode collapse.
5.2.3. Macroscopic Scaling Validation on Realistic Populations ()
- 1.
- Absolute Collapse (Identical Clones): A total of 100 mathematically identical copies of a single sentence. This serves as the theoretical ground-truth minimum boundary.
- 2.
- Algorithmic Collapse (Baseline Failure State): A total of 100 texts extracted from the final generation (Gen 100) of the single-objective baseline algorithm. This represents realistic repetitive stagnation and mode collapse.
- 3.
- Structured Diversity (EVOLMD-MO Success State): A total of 100 texts extracted from the final generation (Gen 100) of the proposed multi-objective framework, representing the desired optimization goal.
- 4.
- Organic Diversity (Social Media Corpus): A total of 100 completely random sentences sampled from the original Lamsal dataset. This serves as the theoretical organic maximum benchmark.
5.3. Comparative Performance
5.3.1. Experimental Setup and Hyperparameters
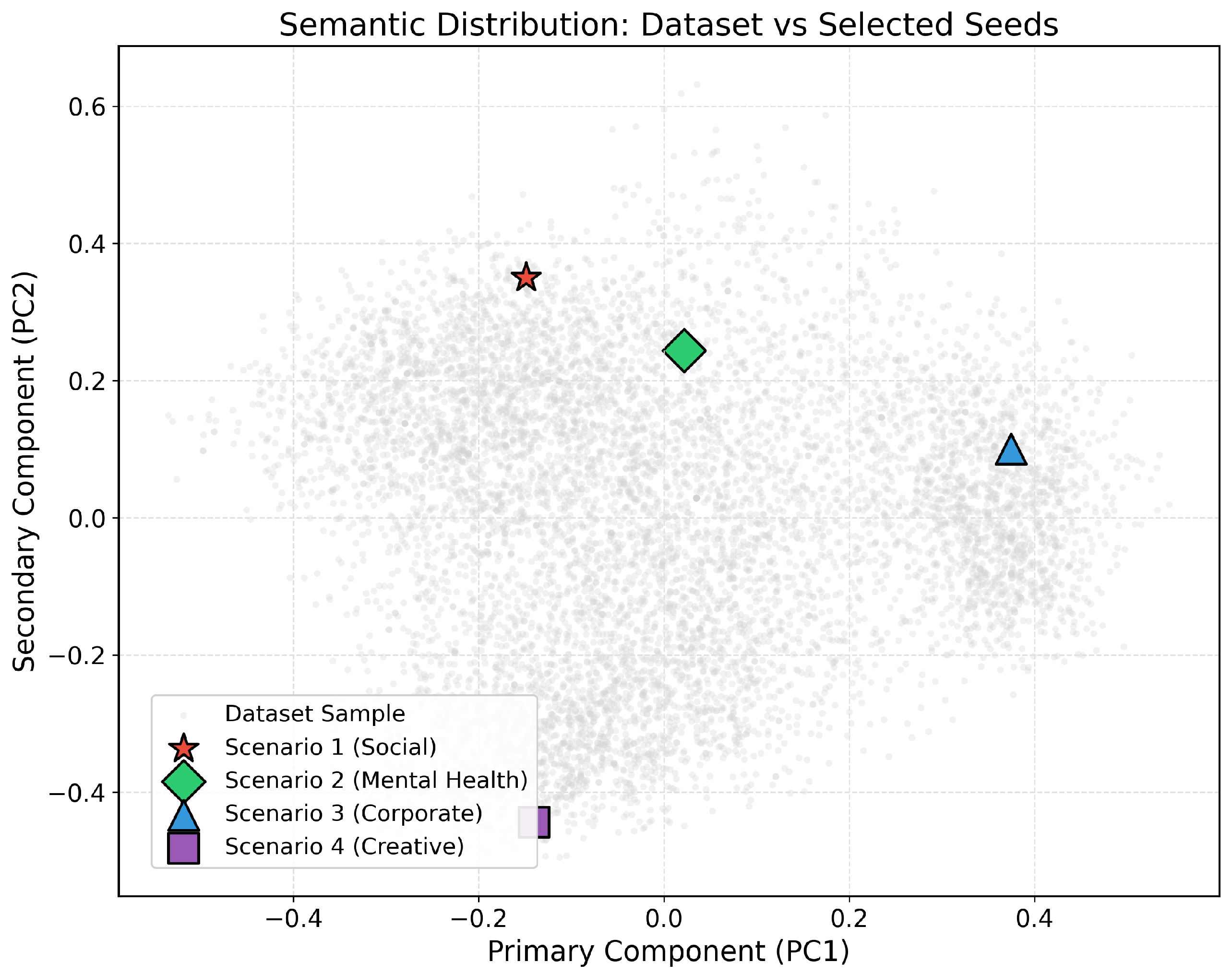
- Reference 1 (Social/Informal Context): “brother just look italy case first few case came 31st jan now italy top the death list corona viruse cases boom very fast medical facility is also not good in south east asia and you have neighbor worst conditions your government be very careful”.
- Reference 2 (Mental Health/Personal): “this quarantine has kicked my depression up a couple notches thanks to my work and routine being void now and im effectively avoiding my phone now bc everyone is nuts sending corona stuff dont blame them but christ the anxiety is driving me up the Wall”.
- Reference 3 (Corporate/Informative): “update our action center has been updated with more information about restaurant shutdowns and disaster financing options for smbs”.
- Reference 4 (Creative/Open-Ended): “why dont youwake me up when corona ends”.
- Independent Runs: Each scenario was evaluated across 3 independent runs for both the Baseline and EVOLMD-MO, using different random seeds for initialization.
- Total Executions: The complete experimental campaign comprises 24 distinct executions (2 Systems × 4 Scenarios × 3 Runs).
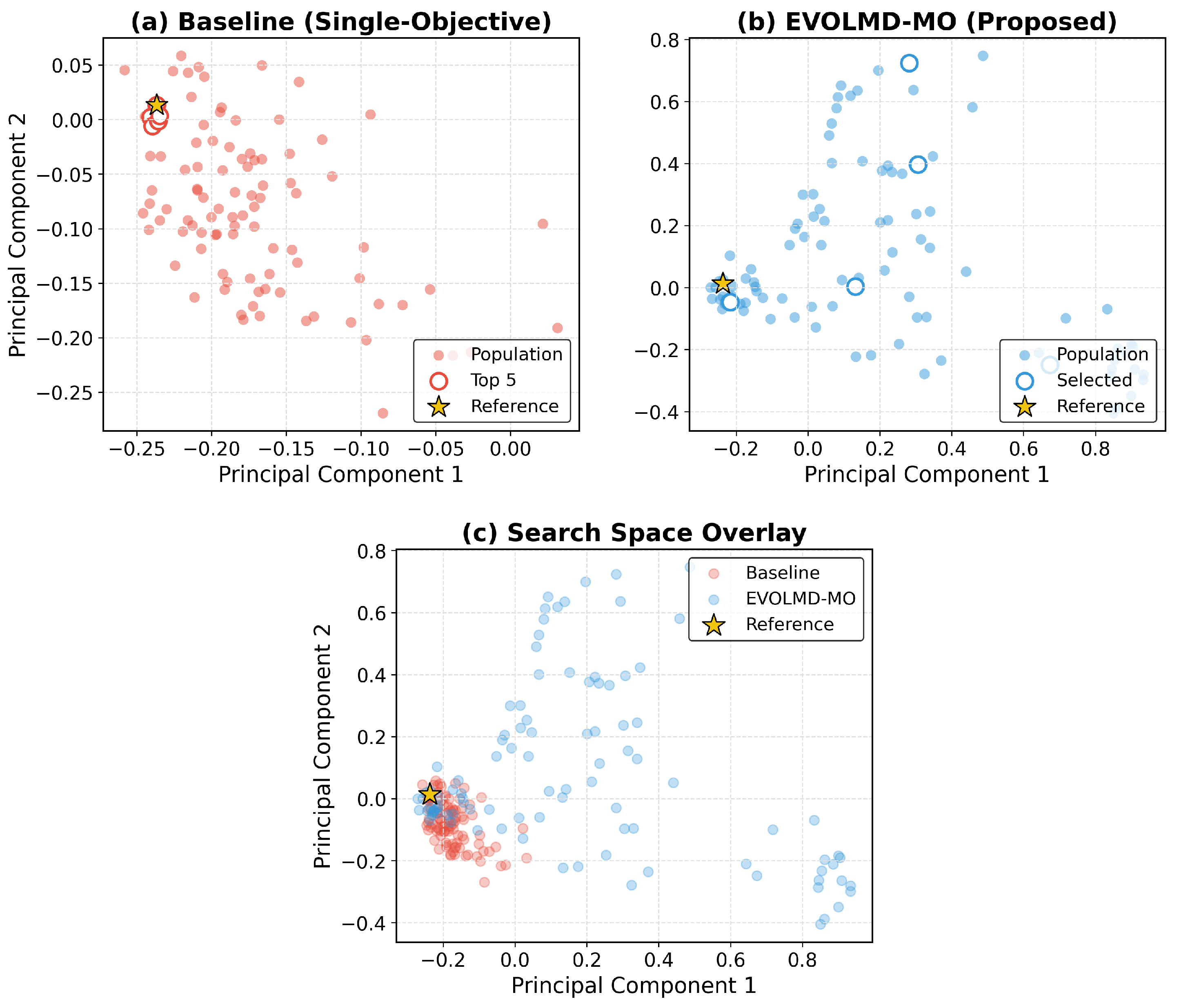
5.3.2. Search Space Visualization
5.3.3. Pareto Front Analysis
5.3.4. Metric Evolution
5.3.5. Runtime Analysis
6. Discussion
6.1. Computational Efficiency as an Enabler for Quality
6.2. Evolutionary Dynamics: From Geometry to Content
6.3. Decision Making and the Fidelity-Diversity Trade-Off
6.4. Robustness to LLM Architecture
6.5. Qualitative Validation: Linguistic Analysis
- Reference Text: “this quarantine has kicked my depression up a couple notches thanks to my work and routine being void now and im effectively avoiding my phone now bc everyone is nuts sending corona stuff dont blame them but christ the anxiety is driving me up the Wall”.
- 1.
- Creativity Gradient: Candidate 1 is a direct high-fidelity paraphrase, while Candidate 2 uses complex metaphors (“swirling vortex of chaos”, “snakes”) to maintain the original emotion by changing the vocabulary.
- 2.
- Mode Collapse Mitigation: The system forces different perspectives, such as that of a first responder (Candidate 3) or an empathetic tone of advice (Candidate 5), avoiding repetition.
- 3.
- Coherence: Despite the high diversity, the majority of sentences maintain grammatical coherence and semantic relevance to the reference topic, validating SBERT as an effective filter. The exception is Candidate 4, which illustrates the semantic drift phenomenon inherent to high-diversity generation—a known edge case that the Pareto framework addresses by empowering the user to apply a stricter fidelity threshold to exclude such outliers from the final dataset.
6.6. Computational Cost and Real-World Feasibility
6.7. Ethical Considerations and Risk Mitigation
6.8. Limitations and Downstream Validation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hidalgo, N.; Wladdimiro, D.; Rosas, E. Self-adaptive processing graph with operator fission for elastic stream processing. J. Syst. Softw. 2017, 127, 205–216. [Google Scholar] [CrossRef]
- Russo Russo, G.; Cardellini, V.; Lo Presti, F. Hierarchical auto-scaling policies for data stream processing on heterogeneous resources. ACM Trans. Auton. Adapt. Syst. 2023, 18, 1–44. [Google Scholar] [CrossRef]
- Russo, G.R.; D’Alessandro, E.; Cardellini, V.; Presti, F.L. Towards a Multi-Armed Bandit Approach for Adaptive Load Balancing in Function-as-a-Service Systems. In Proceedings of the 2024 IEEE International Conference on Autonomic Computing and Self-Organizing Systems Companion (ACSOS-C), Aarhus, Denmark, 16–20 September 2024; pp. 103–108. [Google Scholar]
- Wladdimiro, D.; Arantes, L.; Sens, P.; Hidalgo, N. PA-SPS: A predictive adaptive approach for an elastic stream processing system. J. Parallel Distrib. Comput. 2024, 192, 104940. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan, R.L., IV; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Stroudsburg, PA, USA, 2020. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021. [Google Scholar]
- Fernando, C.; Banarse, D.; Michalewski, H.; Osindero, S.; Rocktäschel, T. PromptBreeder: Self-Referential Self-Improvement Via Prompt Evolution. arXiv 2023, arXiv:2309.16797. [Google Scholar]
- Guo, Q.; Wang, R.; Wang, J.; Li, B.; He, K.; Tan, X.; Bian, J.; Zheng, Y. EvoPrompt: Connecting Large Language Models with Evolutionary Algorithms for Prompt Engineering. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Hidalgo, N.; Saez, P.; Meneses, N.; Reyes, V.; Rosas, E. Prompt’s Evolution for Language Model-Driven Data Generation. Appl. Sci. 2025, 15, 12911. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, H.; Liu, Z.; Gu, B.; Chang, Y. ZO-PoG: Collaborative Discrete-Continuous Black-Box Prompt Learning for Language Models. In Proceedings of the International Conference on Learning Representations (ICLR), Singapore, 24–28 April 2025. [Google Scholar]
- Zhang, J.; Yu, S.; Chong, D.; Sicilia, A.; Tomz, M.; Manning, C.; Shi, W. Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity. arXiv 2025, arXiv:2510.01171. [Google Scholar] [CrossRef]
- Yang, K.; Liu, Z.; Xie, Q.; Huang, J.; Zhang, T.; Ananiadou, S. MetaAligner: Towards Generalizable Multi-Objective Alignment of Language Models. Adv. Neural Inf. Process. Syst. 2024, 37, 34453–34486. [Google Scholar]
- Zhao, G.; Yoon, B.J.; Park, G.; Jha, S.; Yoo, S.; Qian, X. Pareto Prompt Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), Singapore, 24–28 April 2025. [Google Scholar]
- Menchaca Resendiz, Y.; Klinger, R. MOPO: Multi-objective prompt optimization for affective text generation. In Proceedings of the 31st International Conference on Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2025; pp. 5588–5606. [Google Scholar]
- Baumann, J.; Kramer, O. Evolutionary Multi-Objective Optimization of Large Language Model Prompts for Balancing Sentiments. In Applications of Evolutionary Computation. EvoApplications 2024; Springer: Cham, Switzerland, 2024. [Google Scholar]
- Deniz, A.; Angin, M.; Angin, P. Evolutionary Multiobjective Feature Selection for Sentiment Analysis. IEEE Access 2021, 9, 142982–142996. [Google Scholar] [CrossRef]
- Leung, M.F.; Wang, J. A collaborative neurodynamic approach to multiobjective optimization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5738–5748. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3982–3992. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A Diversity-Promoting Objective Function for Neural Conversation Models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 110–119. [Google Scholar]
- Tevet, G.; Berant, J. Evaluating the Evaluation of Diversity in Natural Language Generation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 326–346. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Friedman, D.; Dieng, A.B. The Vendi Score: A Diversity Evaluation Metric for Machine Learning. Trans. Mach. Learn. Res. 2023. Available online: https://www.scopus.com/inward/record.uri?eid=2-s2.0-86000643949&partnerID=40&md5=b49386c3214dc96c83717ba286a41b0a (accessed on 1 April 2026).
- Limbeck, K.; Andreeva, R.; Sarkar, R.; Rieck, B. Metric Space Magnitude for Evaluating the Diversity of Latent Representations. Adv. Neural Inf. Process. Syst. 2024, 37, 123911–123953. [Google Scholar]
- Zhu, Y.; Zhang, H.; Wu, B.; Li, J.; Zheng, Z.; Zhao, P.; Chen, L.; Bian, Y. Measuring Diversity in Synthetic Datasets. arXiv 2025, arXiv:2502.08512. [Google Scholar] [CrossRef]
- Taherdoost, H.; Madanchian, M. Multi-Criteria Decision Making (MCDM) Methods and Concepts. Encyclopedia 2023, 3, 77–87. [Google Scholar] [CrossRef]
- Merkepçi, H. Impact of the Objective Attribute Weighting on Five Popular Multicriteria Decision-Making Methods: An Empirical Study. Eskiseh. Tech. Univ. J. Sci. Technol. A—Appl. Sci. Eng. 2024, 25, 456–470. [Google Scholar] [CrossRef]
- Carbonell, J.; Goldstein, J. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; pp. 335–336. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zheng, L.; Chiang, W.L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.; et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Adv. Neural Inf. Process. Syst. 2023, 36, 46595–46623. [Google Scholar]
- Google. Gemini 3 Pro: A Multimodal Language Model. Version Used as the Automated Evaluator (LLM-as-a-Judge). 2025. Available online: https://deepmind.google/technologies/gemini/ (accessed on 1 January 2026).
- Lamsal, R. Coronavirus (COVID-19) Tweets Dataset. 2020. Available online: https://ieee-dataport.org/open-access/coronavirus-covid-19-tweets-dataset (accessed on 1 December 2025).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agent | System Prompt | User Prompt |
|---|---|---|
| Init Agent | You are an AI prompt engineer. Create one high-quality prompt aligned with the reference text, role, and topic. | Reference text: {ref} Role: {role} Topic: {topic} |
| Data Agent | You are an AI text generator. Produce ONE short output text that resembles the reference in style and tone, but adapted to the given role, topic, and keywords. | Ref: {ref} Role: {role} Topic: {topic} Keywords: {kws} Prompt: {prompt} |
| Mutation * | You are a creative AI assistant. Perform a MUTATION by selecting a creative and semantically valid synonym for the given word. | Context: {role, topic, kws} Parameter: {param} Word: {original} Options: {synonyms} |
| Reference (Ref): | |||
|---|---|---|---|
| Inflation has reached a 40-year high, causing the central bank to raise interest rates aggressively. | |||
| Candidates | Oracle | SBERT | BERT |
| The central bank is raising interest rates aggressively because inflation hit a 40-year peak. | 0.97 | 0.94 | 0.85 |
| Prices are rising fast, so the bank is making it more expensive to borrow money. | 0.80 | 0.52 | 0.62 |
| The stock market is volatile due to uncertainty in global markets. | 0.30 | 0.20 | 0.54 |
| Basketball is a popular sport in the United States. | 0.00 | 0.17 | 0.42 |
| Similarity Level | SBERT MAE | BERTScore MAE | Best Performance |
|---|---|---|---|
| High (Reference) | 0.0806 | 0.1818 | SBERT |
| Medium-High (Paraphrase) | 0.1517 | 0.1424 | Tie (Slight BERT) |
| Medium-Low (Contextual) | 0.1013 | 0.1730 | SBERT |
| Low (Noise) | 0.0497 | 0.3659 | SBERT |
| Quality Tier (Oracle) | Mean () | Std Dev () | Min | Max |
|---|---|---|---|---|
| 1. High (Ref Paraphrase) | 0.8564 | 0.0712 | 0.68 | 0.94 |
| 2. Med-High (Coherent) | 0.5298 | 0.1049 | 0.38 | 0.76 |
| 3. Med-Low (Tangential) | 0.2203 | 0.0911 | 0.06 | 0.44 |
| 4. Low (Noise/Hallucination) | 0.0331 | 0.0653 | −0.08 | 0.18 |
| Metric | Total Time (s) | Speedup Factor |
|---|---|---|
| BERTScore (Baseline) | 32.2673 | 1.0× |
| SBERT (Proposed) | 0.9430 | 34.22× |
| Generated Text |
|---|
|
| Generated Text |
|---|
|
| Generated Text |
|---|
|
| Scenario | Global Inertia | Detected State |
|---|---|---|
| Mode Collapse | 0.1539 | High Redundancy |
| Coherent Diversity | 0.2225 | Moderate Dispersion |
| Chaotic Diversity | 0.3732 | High Dispersion |
| Type | Candidate Text (Truncated) | Novelty |
|---|---|---|
| Redundant | Artificial Intelligence is transforming industries… | 0.4033 |
| Redundant | Industries are being transformed by AI automation… | 0.3802 |
| Redundant | The transformation of industries is driven by AI… | 0.4133 |
| Innovative | Machine learning models require vast amounts of data… | 0.6702 |
| Innovative | Ethical concerns about AI bias are growing among… | 0.6120 |
| Parameter | Value | Description |
|---|---|---|
| Population Size (N) | 100 | Number of individuals per generation. |
| Number of Generations | 100 | Total iterations of the evolutionary process. |
| Crossover Probability () | 0.8 | Genetic recombination rate (80%). |
| Mutation Probability () | 0.05 | Random variation rate (5%). |
| Lower Threshold () | 0.20 | Filtering boundary for hallucinations. |
| Upper Threshold () | 0.95 | Filtering boundary for lexical duplicates. |
| Diversity Weight () | 0.35 | MMR parameter for semantic redundancy. |
| Final Selection (K) | 5 | Number of solutions returned to the user. |
| Scenario | Single-Objective Baseline | EVOLMD-MO | ||
|---|---|---|---|---|
| Hypervolume (HV) | Spacing (SP) | Hypervolume (HV) | Spacing (SP) | |
| 1 | 0.1557 | 0.0126 | 0.6906 | 0.0124 |
| 2 | 0.1920 | 0.0160 | 0.6055 | 0.0099 |
| 3 | 0.1325 | 0.0079 | 0.7274 | 0.0095 |
| 4 | 0.3165 | 0.0214 | 0.5897 | 0.0105 |
| Scenario | Single-Objective Baseline | EVOLMD-MO | ||
|---|---|---|---|---|
| Avg Fidelity () | Avg Diversity () | Avg Fidelity () | Avg Diversity () | |
| 1 | 0.5040 | 0.1721 | 0.4632 | 0.6524 |
| 2 | 0.5328 | 0.1776 | 0.5321 | 0.6188 |
| 3 | 0.7166 | 0.1108 | 0.4469 | 0.7048 |
| 4 | 0.4610 | 0.3388 | 0.3894 | 0.7414 |
| Scenario | Run | Baseline (s) | EVOLMD-MO (s) | Improvement (%) |
|---|---|---|---|---|
| Scenario 1 | 1 | 30,766 | 29,020 | 5.68% |
| 2 | 29,310 | 24,605 | 16.05% | |
| 3 | 30,708 | 25,244 | 17.79% | |
| Scenario 2 | 1 | 32,683 | 24,590 | 24.76% |
| 2 | 26,568 | 27,416 | −3.19% | |
| 3 | 28,935 | 25,457 | 12.02% | |
| Scenario 3 | 1 | 26,264 | 22,880 | 12.88% |
| 2 | 22,910 | 25,542 | −11.49% | |
| 3 | 23,169 | 24,313 | −4.94% | |
| Scenario 4 | 1 | 23,667 | 21,987 | 7.10% |
| 2 | 27,287 | 23,935 | 12.28% | |
| 3 | 22,923 | 23,325 | −1.75% | |
| Global Average | 27,099 | 24,859 | 8.26% | |
| # | Text Generated by EVOLMD-MO | Fidelity | Diversity |
|---|---|---|---|
| 1 | Quarantining has amplified my depression’s symptoms, as my usual routine and work have been disrupted. The constant stream of corona-related updates on social media is overwhelming, causing me to avoid my phone to mitigate the anxiety. | 0.8429 | 0.5196 |
| 2 | In this swirling vortex of chaos, a city wall once stood tall, now breached by waves of misinformation. False reports writhe like snakes, their hissing whispers fueling fear and anxiety. As an artist, I’m trapped in this digital purgatory, watching the world descend into madness. Frustration and panic seep through my pixels, as vivid colors bleed together, a cityscape mural that mirrors the turmoil within. | 0.2521 | 0.7723 |
| 3 | As a first responder, seeing misinformation spreading like wildfire is concerning me more than the actual virus. Travel restrictions are necessary for our safety, but with false reports of infected areas, it’s hard to know what’s real. Insurance companies need accurate data to provide fair coverage—I worry about the long-term impact on our economy if we can’t trust the information. | 0.3365 | 0.7195 |
| 4 | Quarantine life has me scrambling for reliable info on paw hygiene amidst the chaos. As an online schooler, I’m trying not to lose my mind while keeping Fido’s paws clean. Here are some sanity-saving tips: Wash those paws daily with mild soap and warm water. Dry thoroughly to prevent bacterial growth. Trim nails regularly to avoid dirt accumulation. Sanitize high-touch areas like door handles and toys. | 0.2720 | 0.7578 |
| 5 | I completely understand how you’re feeling right now—it’s like a never-ending nightmare! As someone who’s struggled with depression myself, I know how easy it is to get sucked into the vortex of false reports and misinformation about COVID-19. But here’s the thing: there is hope! By seeking out reliable information from trusted sources, you can start to regain control over your life. Don’t be afraid to reach out to your insurance provider or a mental health professional for support—they’re there to help you through this tough time. | 0.4751 | 0.6808 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Share and Cite
Pastrián, D.; Hidalgo, N.; Reyes, V.; Rosas, E. Evolutionary Multi-Objective Prompt Learning for Synthetic Text Data Generation with Black-Box Large Language Models. Appl. Sci. 2026, 16, 3623. https://doi.org/10.3390/app16083623
Pastrián D, Hidalgo N, Reyes V, Rosas E. Evolutionary Multi-Objective Prompt Learning for Synthetic Text Data Generation with Black-Box Large Language Models. Applied Sciences. 2026; 16(8):3623. https://doi.org/10.3390/app16083623
Chicago/Turabian StylePastrián, Diego, Nicolás Hidalgo, Víctor Reyes, and Erika Rosas. 2026. "Evolutionary Multi-Objective Prompt Learning for Synthetic Text Data Generation with Black-Box Large Language Models" Applied Sciences 16, no. 8: 3623. https://doi.org/10.3390/app16083623
APA StylePastrián, D., Hidalgo, N., Reyes, V., & Rosas, E. (2026). Evolutionary Multi-Objective Prompt Learning for Synthetic Text Data Generation with Black-Box Large Language Models. Applied Sciences, 16(8), 3623. https://doi.org/10.3390/app16083623