Abstract
Object detection in low-light environments is often hampered by unfavorable factors such as low brightness, low contrast, and noise, which lead to issues like missed detections and false positives. To address these challenges, this paper proposes a low-light object detection algorithm named Dark-YOLO, which dynamically extracts features. First, an adaptive image enhancement module is introduced to restore image information and enrich feature details. Second, the spatial feature pyramid module is improved by incorporating cross-overlapping average pooling and max pooling to extract salient features while retaining global and local information. Then, a dynamic feature extraction module is designed, which combines partial convolution with a parameter-free attention mechanism, allowing the model to flexibly capture critical and effective information from the image. Finally, a dimension reciprocal attention module is introduced to ensure the model can comprehensively consider various features within the image. Experimental results show that the proposed model achieves an mAP@50 of 71.3% and an mAP@50-95 of 44.2% on the real-world low-light dataset ExDark, demonstrating that Dark-YOLO effectively detects objects under low-light conditions. Furthermore, facial recognition in dark environments is a particularly challenging task. Dark-YOLO demonstrates outstanding performance on the DarkFace dataset, achieving an mAP@50 of 49.1% and an mAP@50-95 of 21.9%, further validating its effectiveness for face detection under complex low-light conditions.
1. Introduction
In the expansive field of computer vision, object detection has emerged as a cornerstone research focus, achieving remarkable progress in recent years and garnering significant attention. This technology has found widespread applications across numerous domains, including vehicle-assisted driving [1,2], security surveillance [3,4], pedestrian detection [5,6,7], industrial quality control [8], and assistive technologies for the visually impaired [9]. The practical deployment of object detection systems is heavily influenced by the quality of illumination in their operating environments. Under optimal lighting conditions—characterized by an abundance of photons and uniform illumination distribution—object features become distinctly discernible. This clarity enables a clear differentiation between the foreground (objects of interest) and the background, thereby providing favorable conditions for accurate object detection tasks. However, in low-light scenarios, such as nighttime or dimly lit environments, the photon count is significantly reduced, resulting in diminished contrast and inadequate brightness, which complicates the identification of objects and facial features [10]. Furthermore, the increased presence of noise and interference in low-light conditions exacerbates the challenges faced by object detection systems. These factors undermine the performance of existing object detection algorithms, rendering them less capable of consistently and accurately identifying objects, often failing to meet expected levels of detection accuracy and reliability. This limitation poses a substantial barrier to advancements in critical fields such as security surveillance, autonomous driving, and intelligent transportation systems [11,12]. Consequently, research into object detection under low-light conditions is of paramount importance, as it addresses these challenges and further propels the development of this technology. By developing robust and accurate object detection methods that perform effectively in low-light environments, the scope of this technology’s applications can be broadened, contributing significantly to domains that rely on dependable object detection.
In the field of low-light object detection, deep learning methods can be divided into the following two categories based on whether candidate boxes are generated: two-stage algorithms and one-stage algorithms. Two-stage algorithms, such as Faster R-CNN (Faster Region Convolutional Network) [13], first generate potential regions and then refine recognition. Although they achieve high accuracy, their processing speed is limited. Wang et al. [14] proposed an object detection algorithm for nighttime environments that combines DCGAN with Faster R-CNN, incorporating a feature fusion module and a multi-scale pooling module to enhance detection performance under low-light conditions. Xu et al. [15] combined deformable convolutional networks with Faster R-CNN, employing perceptual boundary localization to achieve more accurate position learning of objects, thereby improving detection performance in dim environments.
One-stage algorithms, such as SSD [16] and the YOLO series [17,18,19,20], perform detection directly, omitting the candidate box generation step. This leads to faster detection but demands a more comprehensive feature extraction process. Qin et al. [21] proposed the DE-YOLO framework, which integrates DENet and YOLOv3 into a unified enhancement-detection system. However, the independent processing by the two networks in the framework may prevent the full utilization of enhanced image details during feature extraction. Cui et al. [22] proposed a self-supervised method for low-light object detection using a multi-task autoencoder transformation model. Nevertheless, the accuracy of self-supervised learning can be compromised when sufficient contextual information is unavailable, particularly in low-light environments where the absence of contextual details further affects detection accuracy. Zou et al. [23] optimized the backbone network of YOLOv5 and applied RetinexNet for data augmentation to improve occluded object detection, but RetinexNet’s image enhancement performance required manual parameter adjustments to achieve optimal results. Wang et al. [24] introduced an enhancement strategy combining block matching with three-dimensional filtering, effectively improving the signal-to-noise ratio in nighttime images. However, the approach did not fully address the limitations of convolutional neural networks in capturing global information.
To address the aforementioned challenges, researchers have proposed a variety of solutions. For instance, Hong et al. [25] introduced a framework called YOLA, which enhances object detection performance in low-light conditions by learning illumination-invariant features via the Lambertian image formation model. While this approach leverages inter-channel and spatial relationships to handle diverse lighting, it underemphasizes the integration of global contextual information, critical for resolving ambiguities in low-contrast scenes where object-background boundaries blur. Hashmi et al. [26] developed the FeatEnHancer module, employing hierarchical multi-scale feature fusion guided by task-specific losses and multi-head attention. Although effective for cross-scale feature integration, this method relies on parameterized attention mechanisms that may overlook lightweight and dynamic feature selection tailored to low-light sparsity, potentially compromising efficiency in resource-constrained scenarios. Yin et al. [27] proposed PE-YOLO, integrating a Pyramid Enhancement Network (PENet) with YOLOv3 to decompose images into Laplacian pyramid components for detail enhancement. However, the static pooling strategy in their feature pyramid risks losing fine-grained local details, especially problematic in low-light environments where texture and edge information are already degraded. Ding et al. [28] introduced SDNIA-YOLO to enhance YOLO robustness under extreme weather via Neural Style Transfer (NST)-synthesized images. While this boosts generalization to adversarial conditions, it lacks a dedicated mechanism to address the unique challenge of low-light illumination, such as noise amplification and uneven brightness, which require more than just style adaptation. Liu et al. [29] proposed IA-YOLO with a Differentiable Image Processing (DIP) module to adapt to varying weather. However, the independent operation of the DIP module and detection network may hinder seamless fusion of enhanced features, as demonstrated in Qin et al.’s [21] earlier work, where parallel processing limited feature utilization efficiency. Han et al. [30] developed 3L-YOLO, a lightweight model that avoids explicit image enhancement by introducing switchable atrous convolution. While this reduces computational load, it overlooks the critical role of preprocessing in restoring lost low-light details—an omission that becomes pronounced in extremely dark environments with minimal initial information. Bhattacharya et al. [31] presented D2BGAN for unsupervised low-light-to-bright image conversion, effective against motion blur and noise in driving scenes. Yet, the separation of image enhancement and detection as distinct stages may not optimize end-to-end feature learning, limiting the model’s ability to prioritize task-relevant details during enhancement. Zhang et al. [32] proposed NUDN for nighttime domain adaptation via knowledge distillation, reducing costs for small objects. However, this approach does not explicitly model the reciprocal relationship between spatial and channel-wise features—a key deficit in low-light scenarios where cross-dimensional dependencies (e.g., channel-wise contrast and spatial structure) are critical for accurate detection. Wang et al. [33] improved YOLOv5 with DK_YOLOv5, incorporating enhancement algorithms and attention mechanisms. While effective, the sequential integration of modules may lead to suboptimal information flow, as each component (enhancement, attention, detection) operates in isolation rather than dynamically reinforcing one another. Li et al. [34] introduced YOLO_GD with cross-layer fusion and dual-layer spatial attention, mitigating inter-layer information loss. However, the spatial-only attention mechanism struggles to capture long-range dependencies across channels, which are essential for reconstructing color and texture in low-light images where channel correlations weaken. Zhao et al. [35] enhanced YOLOv7 with agile hybrid convolutions and deformable attention, improving edge extraction. Yet, the lack of a unified framework to balance local detail extraction (e.g., edges) and global context (e.g., object layout) remains an issue amplified in low-light scenes where both types of information are degraded but interdependent. Mei et al. [36] developed GOI-YOLO with group convolutions to isolate edge interference, enhancing efficiency. However, the exclusive focus on spatial feature grouping neglects the potential of channel-wise attention to recover low-light spectral information, such as restoring discriminative color features muted by insufficient illumination. Abu Awwad et al. [5] proposed multi-stage image enhancement for anomaly detection in smart cities, reducing false positives. Nevertheless, the static enhancement pipeline does not adapt to diverse low-light sub-scenarios (e.g., near-infrared vs. visible light), limiting its generality across illumination conditions.
Although the aforementioned studies have mitigated some of the challenges associated with object detection in low-light conditions, several unresolved issues persist: (1) Insufficient integration of spatial-local and channel-global information, (2) static feature extraction mechanisms ill-suited to low-light sparsity, and (3) insufficient emphasis on the importance of contextual information. However, existing methodologies in the realm of low-light object detection predominantly concentrate on enhancing the detection performance of individual objects, often neglecting the importance of contextual information. These methodologies primarily rely on image processing techniques, such as denoising, contrast enhancement, and edge detection, to improve the visibility and detectability of objects in low-light scenarios. Despite the advancements made in these techniques, the lack of emphasis on contextual information limits the overall performance and accuracy of low-light object detection systems. Secondly, the capacity to extract local detail features from images captured in low-illumination environments remains insufficient. Local detail features are crucial for accurately identifying and classifying objects within an image. However, in low-light conditions, the reduction in photon count and the increase in noise levels result in blurred and distorted images, making it difficult to extract reliable local detail features.
To address these challenges, this paper, Dark-YOLO, addresses these by designing a unified framework where adaptive enhancement, dynamic feature selection, and reciprocal attention mechanisms enable collaborative optimization, ensuring robust performance under complex low-light constraints. The main contributions of this paper are as follows:
(1) We introduce two complementary attention mechanisms. One is SimAM in the Partial Convolutional Spatial Module (PSM), which applies pixel-level focused attention to key features, enabling the model to prioritize critical local information. The other is the Dimensional Reciprocal Attention Module (D-RAMiT), which models global-local relationships through bidirectional spatial-channel attention, integrating long-range dependencies across spatial layouts and channel correlations. Together, they enhance the model’s perception of contextual information in low-light scenarios by explicitly defining “contextual information” into two complementary dimensions: global context and local context. The global context is captured by D-RAMiT’s Spatial Self-Attention (SPSA), which encodes the overall image layout (such as the relative positions of objects) to understand scene-level structure and spatial dependencies. The local context is preserved through the cross-overlapping pooling of the Cross-Spatial Pyramid Pooling Feature (CSPPF) and the partial convolution of PSM. These operations mitigate noise and retain spatial hierarchies, thus preserving fine-grained details like edges and textures that degrade under low-light conditions. SimAM dynamically ranks the importance of local features to focus on discriminative pixels, while D-RAMiT constructs global contextual representations by modeling the interdependencies between spatial locations and channel dimensions. The synergy of the two forms a “multi-attention framework” that balances the prioritization of local details and the modeling of global context, enabling robust feature learning in challenging low-light environments.
(2) The proposed method introduces SCINet, an image enhancement module that cascades multiple illumination learning blocks. Each block is designed to learn and correct specific aspects of the image’s illumination. This cascading structure enables the network to progressively refine illumination information, restoring finer details in low-light images and enriching feature representation.
(3) An enhanced spatial feature pyramid module, termed CSPPF, is proposed. This module utilizes cross-overlapping average pooling and max pooling to minimize the loss of local information in the image, thereby improving the retention of critical spatial details. Max pooling captures salient edges (robust to noise), while average pooling retains global brightness gradients; their combination mitigates the detail loss caused by traditional single pooling in low-contrast images.
(4) A dynamic feature extraction module, PSM, is introduced. By integrating selective information from partial convolution with a parameter-free attention mechanism, PSM enhances the network’s feature extraction capacity and strengthens its object localization capability. In low-light images, partial convolution (PConv) ignores invalid/noisy pixels in the receptive field, reducing interference from corrupted data, while SimAM directs attention to rare valid features.
(5) The method employs Dimension Reciprocal Attention Module (D-RAMiT), a dimension reciprocal attention module, which computes self-attention in parallel along both spatial and channel dimensions. This establishes long-range relationships between pixels, ensuring comprehensive utilization of both local and global information, and ultimately boosting the network’s object detection accuracy in low-light conditions. In dim scenes, local features are sparse and ambiguous; D-RAMiT’s spatial self-attention (SPSA) recovers fine-grained details, while channel self-attention (CHSA) models inter-channel dependencies, enabling the model to infer object identities from limited local cues using global scene statistics.
The remainder of this paper is organized as follows. In Section 2, the specific implementation details of Dark-YOLO will be presented. Subsequently, Section 3 will discuss the experimental results of Dark-YOLO, including a variety of ablation studies and comparisons with different algorithms on the ExDark and DarkFace datasets, highlighting the advantages and robustness of Dark-YOLO. Finally, Section 4 will provide the conclusion, summarizing Dark-YOLO, elucidating its strengths, and addressing its limitations along with potential improvements and future enhancements.
2. Method
2.1. Network Architecture
Our baseline architecture is YOLOv8, which is widely adopted in object detection tasks due to its balance between accuracy and inference speed. The Dark-YOLO detection network is composed of three main modules: the Backbone, the Neck, and the Detection Head. The Backbone consists of an adaptive image enhancement module (SCI), multiple convolutional modules (Conv), a dynamic convolutional feature localization module (PSM), and a Cross-Spatial Pyramid Pooling module (CSPPF). The SCI module is responsible for enhancing the quality of low-light images, restoring image details, and enriching the feature information of the images. The PSM module utilizes partial convolution to dynamically extract image features, combined with a parameter-free attention mechanism to enhance the localization ability of the detection targets, thereby enabling the model to focus on the critical parts of the image. The CSPPF module employs a cross-use of max pooling layers and average pooling layers, where max pooling extracts the most salient features from the feature maps, and average pooling retains the overall local information, helping to mitigate the problem of local information loss in low-light images. In the Neck section, a combination of Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) is used to enhance the model’s multi-scale feature representation capabilities. The Neck also introduces the Dimension Reciprocal Attention Module (D-RAMiT), which mixes attention across both spatial and channel dimensions, addressing the issue of the model focusing only on either local or global features. SimAM in PSM applies pixel-level focused attention to key features. D-RAMiT models the global-local relationships through bidirectional spatial-channel attention. Together, they enhance the context-awareness ability in low-light scenarios. SimAM is used for prioritizing local features, while D-RAMiT is used for global context modeling, forming a multi-attention framework. The Detection Head is composed of several convolutional layers and activation functions. The convolutional layers are used to process the feature maps output from the Neck to extract more advanced features, while the activation functions introduce non-linearity to improve the feature representation capability. The overall structure of the Dark-YOLO network is illustrated in Figure 1.
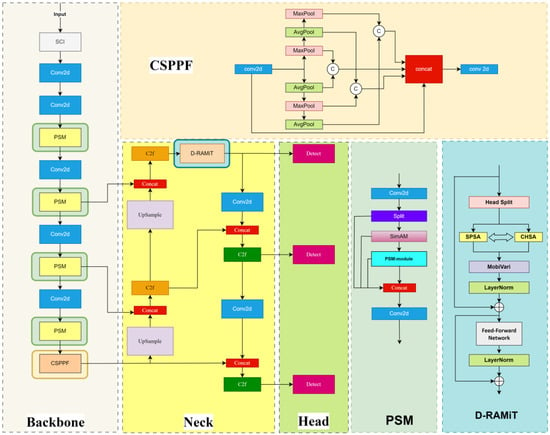
Figure 1.
Structure diagram of Dark-YOLO model. The baseline model for Dark-YOLO is YOLOv8. The Dark-YOLO detection network is composed of three main components: Backbone, Neck, and Head. The Backbone utilizes the SCI, PSM, and CSPPF modules to enhance the quality of low-light images and extract key features. The Neck integrates a combination of Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) to achieve multi-scale feature representation. It also employs the D-RAMiT module to fuse spatial and channel features, enhancing the model’s ability to perceive both local and global features. The Head leverages convolutional layers and activation functions to further extract high-level features. The PSM module employs partial convolution along with an attention mechanism to focus on and extract critical features. The CSPPF module extracts and fuses features by employing a cross-overlapping strategy involving multiple max pooling layers and average pooling layers. The Spatial Self-Attention (SPSA) of D-RAMiT restores fine-grained details, while the Channel Self-Attention (CHSA) models inter-channel dependencies. This allows the model to infer object identities from limited local cues by leveraging global scene statistics.
2.2. Low-Light Image Enhancement Module (SCINet)
Images captured under low-light conditions often suffer from reduced photon count, leading to an overall decline in image quality and the blurring of image features. To address this issue, we introduce an adaptive image enhancement network, SCINet. SCINet follows an unsupervised training paradigm and serves as a real-time enhancement network. The entire architecture consists of two primary components: an Illumination Estimation module and a Self-Calibrated Module [37]. Cascaded illumination learning blocks dynamically estimate the illumination distribution through a Self-Calibrated Module, aiming to restore brightness uniformity and improve the image signal-to-noise ratio in low-light scenarios. The structure of SCINet is illustrated in Figure 2.
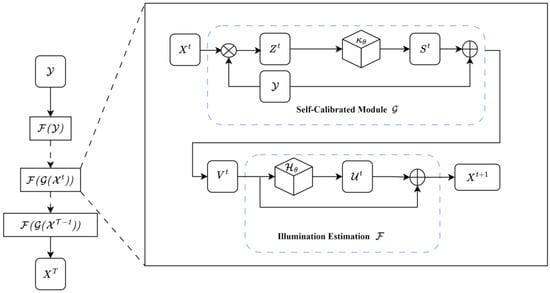
Figure 2.
Structure diagram of the SCI model. The SCI module consists of an Illumination Estimation Module and a Self-Calibrated Module. The output of the Self-Calibrated Module is added to the original low-light input and serves as the input for the next stage of illumination estimation.
The Illumination Estimation process is a critical part of the SCI framework, involving the estimation of light intensity within an image, which aims to ensure consistency among the outputs generated by multiple cascaded basic blocks (i.e., illumination estimation modules). This estimation is performed either in grayscale or in specific channels after color space conversion. The objective of Illumination Estimation is to provide the necessary information for subsequent image enhancement, facilitating adjustments to image brightness and contrast. The Self-Calibrated Module is designed to support the learning process of illumination estimation. By employing a weight-sharing mechanism during the training phase, this module helps accelerate convergence. Within the SCINet framework, the output of the Self-Calibrated Module is added to the original input after each iteration and used as input for the subsequent illumination estimation. This process forms a feedback loop, as detailed in Equations (1)–(3). Among them, is the illumination-estimation processing function for the -th stage; is the self-calibrated module for calibrating the input of the -th stage. represents the illumination estimation result at the -th stage; is the input low-illumination image; is obtained by performing element-wise division between and , reflecting the difference between the current illumination estimation and the input image; is the transformation function in the self-calibrated module; is the calibration signal generated after the transformation function processes ; is the output of the self-calibrated module; is the transformation function in the illumination estimation module; is the residual term generated after the transformation function processes ; is the illumination estimation result at the -th stage.
2.3. Spatial Feature Pyramid Module (CSPPF)
To address the severe loss of local information in low-light images, we propose a Cross-Spatial Pyramid Pooling Feature (CSPPF) module. This structure employs an overlapping pooling strategy that combines average pooling layers and max pooling layers. Max pooling captures prominent edges, while average pooling preserves the global brightness gradient. The combination of the two mitigates the issue of detail loss in low-contrast images that occurs with traditional single pooling methods, avoiding the detail blurring caused by single pooling. Specifically, one pathway consists of two max pooling layers and one average pooling layer in series, while the other pathway consists of two average pooling layers and one max pooling layer in series. The output of each pathway is concatenated to form the final output. The detailed calculation process is depicted in the corresponding Equations (4)–(8), where concat1, concat2, and concat3 represent the concatenation of the features from the max pooling and average pooling layers, respectively.
The use of this cross-overlapping pooling structure facilitates smoother transitions during the pooling process, thereby mitigating the abrupt changes caused by excessive pooling and enabling the extraction of more local information [38]. The designed structure of the spatial feature pyramid module is illustrated in Figure 3.
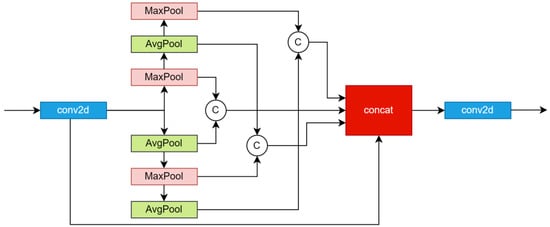
Figure 3.
Structure diagram of the CSPPF model. The CSPPF module consists of two parallel pathways: one pathway includes two max pooling layers followed by an average pooling layer in series, while the other pathway includes two average pooling layers followed by a max pooling layer. By employing parallel max pooling and average pooling operations, the module extracts important features at different hierarchical levels. These extracted features are then concatenated and further processed by a convolutional layer. This approach enhances feature diversity, making it particularly effective for extracting key information from complex backgrounds.
2.4. Dynamic Feature Extraction Module (PSM)
Traditional convolutional networks assume that the input image contains complete and uniformly distributed information. However, under low-light conditions, this assumption no longer holds due to the presence of increased noise, reduced contrast, and the loss of fine details. These issues lead to incomplete image features, which in turn adversely affect the model’s accuracy in detecting target objects. To address these challenges, we propose a dynamic feature extraction module (PSM), designed to enhance the model’s ability to extract effective information, particularly from regions where inadequate illumination results in limited useful data availability. In low-light conditions, partial convolution (PConv) processes only valid pixels to reduce noise interference. The SimAM attention mechanism dynamically suppresses irrelevant regions (such as dark backgrounds) and focuses on object contours. The architecture of the PSM module is illustrated in Figure 4.
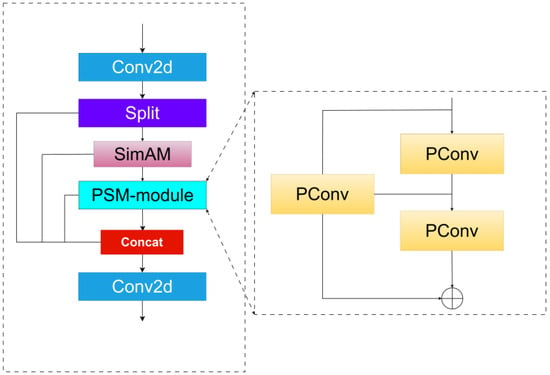
Figure 4.
Structure diagram of the PSM model. The PSM module begins with a two-dimensional convolution to perform initial feature extraction. The extracted feature maps are then split and fed into different branches. The parameter-free attention mechanism, SimAM, is integrated to help the network better focus on important features. Subsequently, a partial convolution module is employed to further refine the features, and finally, a convolutional layer is used to fuse all branches into a unified representation.
PSM integrates a parameter-free attention mechanism with partial convolution. Unlike existing channel/spatial attention modules, the parameter-free attention mechanism of PSM derives 3D attention weights for the feature maps without the need for additional parameters, focusing on neurons containing important information. This mechanism enhances the model’s ability to localize detection targets in low-light environments. The attention weights are computed based on the local self-similarity of the image by evaluating the similarity between pixels, which directs the model’s focus towards the objects of interest [39]. The specific process is defined in Equations (9) and (10), where represents the regularization term, is the th neuron in a single channel of the input feature map, represents the mean of all neurons within a single channel, is the variance of all neurons in the single channel, and is the energy function, which generates attention weights through the sigmoid function.
Partial convolution allows the convolution kernel to operate only on the valid pixels within its receptive field, thereby preventing information distortion caused by invalid or missing data. Given the substantial loss of data in low-light images, partial convolution reduces computational cost, enhances robustness against missing information, and improves feature extraction under low-light conditions. As a novel implementation of partial convolution, it applies the traditional convolution operation to only a small subset of input channels while leaving the remaining channels unchanged, effectively reducing computational load and memory access to some extent [40]. The PConv structure is depicted in Figure 5.
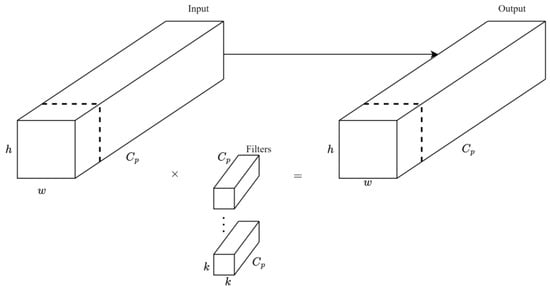
Figure 5.
Structure diagram of the PSM model. Partial convolution is performed only on valid pixels within the receptive field. During the operation, normalization is applied based on the number of valid pixels to maintain the value range of the convolution output.
2.5. Dimension Reciprocal Attention Module (D-RAMiT)
In low-light environments, the local feature information in images is often sparse, and non-uniform illumination can lead to overexposure or underexposure in some regions, further complicating the extraction of local features. As a result, global contextual information becomes critically important. To address this, we introduce the Dimension Reciprocal Attention Module (D-RAMiT) to enhance the model’s ability to capture both global information, such as the overall layout of the image and the relative positioning of objects, as well as local details. D-RAMiT achieves this by establishing long-range pixel-level relationships, enabling the model to perceive the complete layout of the image and the relative positions of different regions. Meanwhile, D-RAMiT enables joint backpropagation of registration errors and detection losses by deeply embedding a reversible attention mechanism into the gradient propagation path of YOLOv8’s neck network, thereby significantly enhancing the capability to capture global contextual information in images. In dim scenes, local features are sparse and ambiguous. The Spatial Self-Attention (SPSA) of D-RAMiT restores fine-grained details, while the Channel Self-Attention (CHSA) models inter-channel dependencies. This allows the model to infer object identities from limited local cues by leveraging global scene statistics. This global information helps the model better understand the image content and compensates, to some extent, for the deficiencies in local detail features [41]. The architecture of the Dimension Reciprocal Attention mechanism is illustrated in Figure 6.
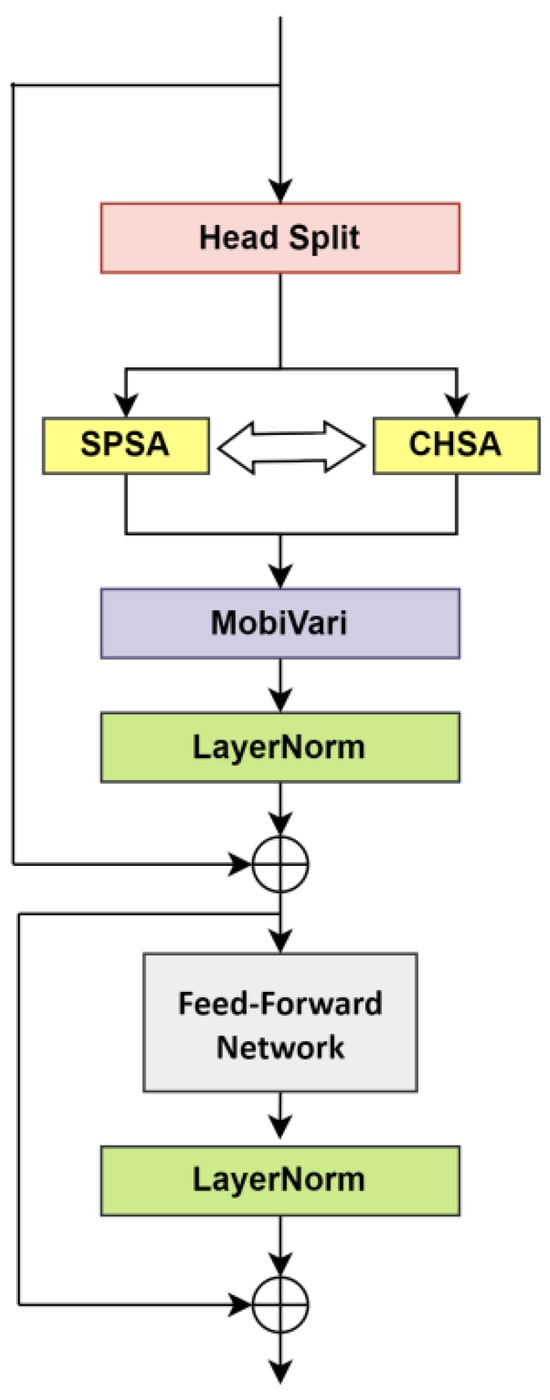
Figure 6.
Structure diagram of D-RAMiT model. The D-RAMiT module first splits the input features through the Head Split operation, and then computes attention along two dimensions using Spatial Self-Attention (SPSA) and Channel Self-Attention (CHSA), respectively. Next, the MobiVari module is applied for feature transformation, enhancing feature representation. Following this, Layer Normalization (LayerNorm) is performed. The features are further processed through a Feed-Forward Network (FFN), followed by another LayerNorm step. Finally, a skip connection is employed to merge the features.
D-RAMiT achieves this through the parallel operation of Spatial Self-Attention (SPSA) and Channel Self-Attention (CHSA) mechanisms. The SPSA mechanism helps capture fine-grained local information within the image, whereas the CHSA mechanism utilizes all pixels along the channel dimension to establish global dependencies. D-RAMiT’s bidirectional reciprocal mechanism allows the attention outcome in one direction to assist the attention process in the other direction, thereby enabling the model to capture both local and global dependencies within the image more effectively. The D-RAMiT structure is mathematically represented in Equation (11).
In Equation (11), MobiVari refers to a variant of MobileNet V2. Specifically, MobiVari replaces the ReLU6 activation function in MobileNet V2 with the LeakyReLU activation function. Moreover, the residual connection of MobileNet V2 is modified. When the number of channels generated by PWConv (pointwise convolution) differs from the input channel number, the residual connection of PWConv is omitted. Additionally, the first convolution in MobileNet V2 is replaced by a group convolution to reduce the number of parameters and computational costs. The structure of MobiVari is depicted in Figure 7.
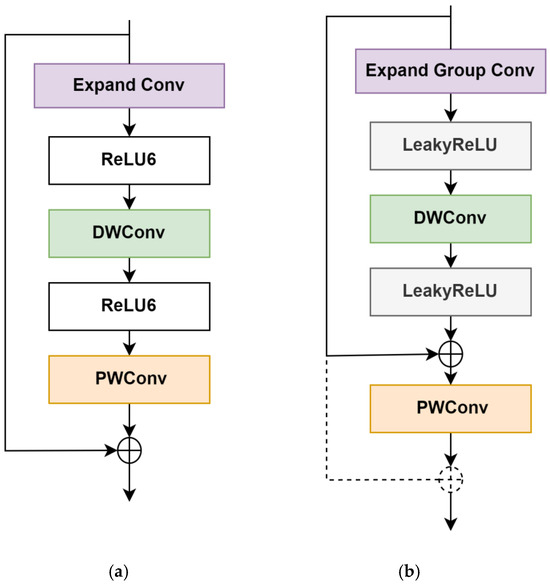
Figure 7.
Structure diagram of MobileNet V2 and MobiVari model. (a) The MobileNet V2 network structure performs feature extraction and reconstruction using expansion convolutions, depthwise convolutions, and pointwise convolutions, with ReLU6 used for activation and nonlinear mapping. (b) The MobiVari network structure replaces the standard expansion convolutions with grouped convolutions and substitutes the activation function with LeakyReLU. These modifications further reduce computational cost while better preserving feature information.
3. Experiment
3.1. Dataset and Experimental Setup
To evaluate the performance of the proposed enhanced model, we utilized the publicly available ExDark dataset [42], which is specifically designed for object detection and image enhancement research in low-light conditions. The ExDark dataset comprises 7363 low-light images captured across 10 distinct lighting scenarios, ranging from extremely dark to dimly lit environments, and encompasses 12 object classes. For our experiments, the dataset was randomly split into training, validation, and testing sets using two different ratios: 8:1:1 and 6:2:2. Additionally, to assess the robustness of the improved network, we employed the publicly available Dark-Face dataset [43]. All training, validation, and testing procedures in this study were conducted using these datasets.
For this experiment, we utilized a Linux-based operating system with an NVIDIA A40 GPU. The experiments were implemented using Python 3.8, and the deep learning framework adopted was PyTorch 2.0, with CUDA version 11.4. The model was trained for 200 epochs. To ensure fairness in comparison, all experiments were conducted under identical experimental conditions and training parameters. The specific training hyperparameters are shown in Table 1.

Table 1.
Hyperparameter Settings for Model Training.
3.2. Evaluation Metrics
The evaluation metrics employed in this study encompass Floating Point Operations (FLOPs), mean Average Precision (mAP), model size, and parameter count. A lower FLOPs value signifies reduced computational complexity of the algorithm, while a higher mAP value reflects improved detection accuracy. Additionally, we adopt Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) as the primary metrics for assessing image enhancement performance. PSNR is utilized to evaluate pixel-level differences between images by calculating the Mean Squared Error (MSE) between the original and processed images, thereby assessing image quality. A higher PSNR value indicates smaller differences between the images and superior restoration quality. SSIM, on the other hand, is an image quality assessment metric that considers luminance, contrast, and structural features, emphasizing the similarity of structural information and reflecting perceptual image quality. SSIM values closer to 1 denote higher image quality.
3.3. Adaptive Image Enhancement Module Experiment
To validate the superiority of the SCINet image enhancement network in low-illumination detection scenarios, experiments were conducted on the ExDark dataset. Specifically, various deep learning-based image enhancement networks were integrated into the backbone of YOLOv8n, and their parameter counts and mean Average Precision (mAP@0.5) were evaluated. The experimental results are presented in Table 2. In these experiments, the YOLOv8n model was combined with image enhancement networks, including Zero-DCE [44], RUAS [45], and SCINet [46], and subjected to end-to-end training. Compared to the baseline YOLOv8n model, all enhanced models exhibited improvements in mAP@0.5 (%). Notably, the integration of the SCINet network into YOLOv8n yielded the most significant enhancement, with mAP@0.5 increasing by 1.8%. The detailed results are shown in Table 2.
Table 2.
Comparison Experiment of Low-Light Enhancement Network.
In the study of low-light image enhancement, different image enhancement networks exhibit distinct characteristics and advantages. To provide a more intuitive evaluation of their performance under low-illumination conditions, four image enhancement networks, namely Zero-DCE, RUAS, EnlightenGAN, and SCINet, were assessed. The specific results are presented in Table 3. Experimental results on the same dataset demonstrate that SCINet outperforms the other methods in terms of both PSNR and SSIM metrics.
Table 3.
Comparison of Image Quality Metrics for Enhancement Network.
We conducted experiments on both the original ExDark dataset and the enhanced version of the ExDark dataset, training for 200 epochs each. Feature maps from training results under extremely low-light conditions were extracted for visualization analysis, as shown in Figure 8. The experimental results indicate that the enhanced images exhibit more complex and detailed features compared to the original images, demonstrating that the adaptive image enhancement module effectively enriches the information content of the images.

Figure 8.
(a) The original image exhibits insufficient contrast between bright and dark areas, resulting in significant loss of detailed information. (b) The corresponding feature map of the original image shows low contrast, with unclear object edges and contours. The boundaries between the target and the background are blurred, making it difficult to distinguish between different objects. (c) The image, after processing by the adaptive enhancement module, shows a strong contrast between the target and the background, with a rich sense of depth. (d) The feature map of the enhanced image presents clear edges and contours of the targets, enabling effective differentiation of various objects.
3.4. Illumination Range Effectiveness Experiment
To validate the effectiveness of Dark-YOLO under varying illumination conditions, this study adjusted image brightness using gamma correction to simulate changes in illumination. The results of the illumination range effectiveness experiment are presented in Table 4. When the gamma value (λ) is 0.5, the image illumination approximates realistic daytime brightness, achieving the best detection performance with an mAP@0.5 of 72.6. When λ is 2.0, the image illumination resembles extremely dark real-world conditions, and the mAP@0.5 drops below 40%, indicating that the method approaches failure at this point. The comparison of image illumination corresponding to different gamma values, with detailed results, is shown in Figure 9.
Table 4.
mAP@0.5 Results for Dark-YOLO Under Varying Gamma Values.

Figure 9.
Illumination Comparison of Images with Different Gamma Values. (a) Gamma = 0.5, Image representing bright illumination similar to daytime conditions. (b) Gamma = 1.0, Image with standard illumination. (c) Gamma = 1.5, Image depicting reduced illumination. (d) Gamma = 2.0, Image simulating extremely dark conditions.
3.5. Contrast Range Effectiveness Experiment
To validate the effectiveness of Dark-YOLO under varying contrast conditions, this study adjusted image contrast using a linear transformation. The results of the contrast range effectiveness experiment are presented in Table 5. When the contrast scaling factor (α) is 1.0, the image contrast remains unchanged and consistent with the original image, achieving the best detection performance with an mAP@0.5 of 71.3. When the contrast scaling factor (α) is 0.3, the image illumination approaches extremely dark real-world conditions, and the mAP@0.5 drops below 40%, indicating that the method approaches failure at this point. A visualization of image contrast corresponding to different contrast scaling factor (α) values and examples are shown in Figure 10.
Table 5.
mAP@0.5 Results for Dark-YOLO Under Varying Contrast Scaling Factors.

Figure 10.
Visualization of image contrast for different contrast scaling factor (α) values. (a) α = 0.4, Image with significantly reduced contrast. (b) α = 0.6, Image with moderately reduced contrast. (c) α = 0.8, Image with slightly reduced contrast. (d) α = 1.0, Image with original contrast.
3.6. PSM Effectiveness Ablation Experiment
To validate the effectiveness of the proposed PSM (Pyramid Spatial Modulation) in enhancing the performance of object detection models under low-illumination conditions, this study conducted a comparative analysis by incorporating SimAM, PConv, and PSM into the baseline model. The experimental results are presented in Table 6. As shown in Table 6, PSM achieves higher mAP@0.5 and mAP@0.5:0.95 values compared to the other methods, demonstrating that the PSM module effectively improves the performance of the YOLOv8 network.
Table 6.
PSM Effectiveness Ablation Experiment.
3.7. CSPPF Effectiveness Comparison Experiment
In this section, the effectiveness of the proposed CSPPF (Cross-Stage Pyramid Pooling Fusion) was validated through experiments. The enhanced ExDark image dataset was used to train and evaluate SPPF, ASPP, SPPFCSPC, BasicRFB, and CSPPF. The experimental results are summarized in Table 7. As indicated in Table 7, CSPPF outperforms other network structures in terms of both mAP@0.5 and mAP@0.5:0.95, confirming that the CSPPF structure enhances the performance of the YOLOv8 network.
Table 7.
CSPPF Effectiveness Comparison Experiment.
3.8. Hyperparameter Sensitivity Analysis Experiment
To investigate the impact of the hyperparameter batch size on network performance, this experiment evaluated three batch size settings—4, 8, and 16—and analyzed their effects on the results. The data analysis is presented in Table 8. As shown in Table 8, the mAP@0.5 values obtained with different batch sizes in the improved network consistently surpass those of the unmodified network, indicating enhanced training stability in the proposed model.
Table 8.
Batch Size Sensitivity Analysis.
3.9. Ablation Study
To validate the effectiveness of each module in the Dark-YOLO algorithm for object detection in low-light scenarios, a series of ablation experiments were conducted based on the YOLOv8 network on the ExDark dataset. These experiments aimed to evaluate the contribution of each module to the overall performance of the detection algorithm. In this study, SCI, CSPPF, PSM, and D-RAMiT are abbreviated as S, C, P, and D, respectively. The evaluation metrics included mAP@0.5, mAP@0.5:0.95, model computational complexity (FLOPs), and parameter count, to assess the effectiveness of these four improvements. The results of the ablation experiments are presented in Table 9.
Table 9.
Ablation experiments on the ExDark dataset for the effect of each of our modules on the object detection model.
Initially, the baseline YOLOv8n model was tested, achieving an mAP@0.5 of 68.3% and an mAP@0.5:0.95 of 42.7%. Subsequently, the SCINet module was introduced, resulting in an increase of 0.3% in mAP@0.5 and an increase of 0.8% in mAP@0.5:0.95, indicating that the inclusion of the SCI module enriched the information content in low-light images. Next, the CSPPF module replaced the original SPPF module, leading to an increase in mAP@0.5 to 69.7% and an improvement in mAP@0.5:0.95 to 43.2% based on the results of the second configuration. This demonstrates that incorporating CSPPF enhances the model’s ability to extract local features from images. Further improvements were made by adding the PSM module to the second, fourth, sixth, and eighth layers of the backbone network. Based on the sixth configuration, this addition resulted in a further increase of 0.5% in mAP@0.5, a reduction in model size by 0.54 MB, a reduction in computational complexity (GFLOPs) by 14.6%, and a decrease in parameter count by 12.8%. These results suggest that the PSM module enables the algorithm to focus more effectively on key feature information with fewer computational resources, thereby enhancing feature extraction capabilities. Finally, the D-RAMiT module was added, resulting in an mAP@0.5 increase to 71.3% and an mAP@0.5:0.95 increase to 44.2% based on the fourth configuration. This indicates that the addition of the Dimension Reciprocal Attention Module enables the model to simultaneously focus on both local and global information in the image.
The ablation study demonstrates that each of the proposed modules contributes effectively to the improvement of the algorithm’s performance, and their combined use yields even better results. These enhancements not only strengthen the feature extraction and contextual information propagation capabilities of the algorithm but also improve its attention to target features and localization accuracy.
3.10. Comparative Experiment
To evaluate the superiority of the proposed low-illumination object detection algorithm, Dark-YOLO, comparative experiments were conducted against mainstream state-of-the-art (SOTA) algorithms, SOTA algorithms enhanced with the SCINet image enhancement network, and classic low-illumination detection methods, including ZERO-DCE (ZERO-DCE + YOLOv3), IA-YOLO, IAT (Illumination-Adaptive Transformer), and LOL-YOLO. These comparisons were performed on the ExDark dataset with splits of 8:1:1 and 6:2:2, as well as the Dark-Face dataset. The results are summarized in Table 10, Table 11, and Table 12.
Table 10.
Comparative Experiment on ExDark dataset (8:1:1).
Table 11.
Comparative Experiment on ExDark dataset (6:2:2).
Table 12.
Comparative Experiment on Dark-Face dataset.
From Table 10, it is evident that on the ExDark (8:1:1) dataset, the proposed algorithm Dark-YOLO outperforms other object detection methods, achieving mAP@0.5 and mAP@0.5:0.95 values of 71.3% and 44.2%, respectively. The proposed model has a parameter count of 2.744971 × 106, a computational complexity of 7.5 GFLOPS, and a model size of 5.7 MB. While these metrics reflect an increase in model size, computational complexity, and parameter count compared to YOLOv5n, the proposed method offers a substantial improvement in average detection accuracy. This demonstrates that the proposed algorithm not only delivers superior performance but also maintains high computational efficiency, enabling effective operation under constrained computational resources. Specifically, Dark-YOLO achieves the highest mAP@0.5 among all models, outperforming the second-best SCI + YOLOv5n by 1.2%, while maintaining a model complexity comparable to YOLOv5n. Compared to mainstream object detection algorithms such as SSD, YOLOv3-tiny, YOLOv5n, YOLOv8n, YOLOv9, YOLOv10n, and YOLOf, Dark-YOLO improves mAP@0.5 by 16.5%, 12.1%, 2.3%, 3.0%, 12.4%, and 15.8%, respectively. Against algorithms incorporating the SCINet enhancement network, including YOLOv11n, RTDETR, MobileNetv3, and YOLOv5n, Dark-YOLO enhances mAP@0.5 by 3.0%, 2.7%, 8.2%, and 1.2%, respectively. When compared to classic low-light enhancement algorithms like ZERO-DCE, IA-YOLO, and IAT, Dark-YOLO boosts mAP@0.5 by 3.3%, 3.5%, and 4.8%, respectively.
On the ExDark (6:2:2) dataset, as shown in Table 11, the mAP of all models generally decreases; for instance, YOLOv5n’s mAP@0.5 drops from 69% to 60.8%, indicating a significant impact of reduced training data on performance. Although YOLOv9 and YOLOv10n show improvements in mAP@0.5, Dark-YOLO still outperforms other models, tying for first place with SCINet-enhanced RTDETR. However, Dark-YOLO’s model size is only 5.7 MB, accounting for just 6.6% of RTDETR’s size. Additionally, across different ExDark splits, Dark-YOLO’s mAP@0.5 fluctuation range (71.3% to 62.2%) is smaller than that of YOLOv5n (69% to 60.8%), demonstrating its stronger adaptability to varying training data sizes.
On the Dark-Face dataset, as shown in Table 12, Dark-YOLO leads in both mAP@0.5 (49.1%) and mAP@0.5:0.95 (21.9%). Although ZERO-DCE’s mAP@0.5 is close to Dark-YOLO’s, its model size (147.4 MB) and parameter count (44.50 M) are over 26 times larger than those of Dark-YOLO, highlighting a significant efficiency disadvantage.
In summary, Dark-YOLO achieves simultaneous improvements in detection accuracy and computational efficiency on both the ExDark and Dark-Face datasets. The experiments demonstrate that Dark-YOLO exhibits superior robustness compared to existing methods under data-scarce conditions (6:2:2 split) and complex low-light scenarios.
3.11. Detection Performance and Visualization Comparison
Figure 11 shows the P-R curves (mAP@0.5) before and after the improvements, illustrating the performance enhancement across all 10 object classes. Detection accuracy improved to varying extents for each class. Notably, the detection accuracy for bicycles, a commonly observed object in nighttime scenarios, increased by 5.4 percentage points compared to the baseline model. Similarly, the detection accuracy for buses improved by 4.5 percentage points, and the detection accuracy for motorbikes improved by 1.4 percentage points. These results demonstrate the effectiveness of the proposed algorithm in improving detection accuracy under low-light conditions at night.
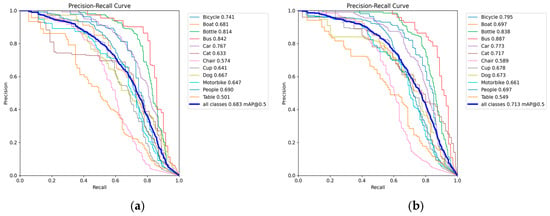
Figure 11.
Comparison of P-R curves before and after improvement (mAP@0.5). (a) Precision-Recall (P-R) curve of the baseline model YOLOv8. (b) Precision-Recall (P-R) curve of the proposed Dark-YOLO.
To provide a more intuitive comparison of the improvements, a visual comparison of the target detection results between the baseline YOLOv8n algorithm and the proposed Dark-YOLO algorithm is presented in Figure 12, using ground truth bounding boxes as the benchmark.

Figure 12.
(a) Labeled images from the ExDark dataset. (b) Results obtained from the baseline YOLOv8n model after training. In the first image, the number of dogs was incorrectly detected; in the second image, a person was mistakenly detected as a dog; and in the third image, a chair was missed during detection. (c) Results obtained from the Dark-YOLO model after training. In all three images, the corresponding targets were accurately detected without any issues of missed or incorrect detections.
Additionally, to further demonstrate the robustness of Dark-YOLO in low-light scenarios, detection performance on the Dark-Face dataset is evaluated, focusing on face detection, a critical task in nighttime surveillance and security applications. Figure 13 illustrates the detection results for faces under challenging low-light conditions. Compared to the baseline YOLOv8n, the improved model performed better in detecting small face targets in a dark environment. This improvement underscores Dark-YOLO’s superior adaptability to low-light face detection tasks, further validating its efficacy across diverse object categories and datasets.

Figure 13.
(a) Labeled face images from the Dark-Face dataset. (b) Detection results from the baseline YOLOv8n model after training, showing missed faces and lower confidence scores in low-light conditions. (c) Detection results from the Dark-YOLO model after training, demonstrating accurate face detection with high confidence scores even in dimly lit scenarios.
4. Conclusions
To address the challenges of low detection accuracy, high miss rates, and inaccurate target localization in low-light object detection, this paper proposes Dark-YOLO, a low-light object detection algorithm based on dynamic feature extraction. Firstly, the SCINet module was used to enhance the quality of low-light images, effectively restoring image details and enriching the feature representation. Secondly, the CSPPF module was designed to facilitate the effective propagation of both global and local image information. Subsequently, a dynamic feature extraction module (PSM) was introduced, incorporating partial convolution and a parameter-free attention mechanism to flexibly capture critical and effective information from the image. Finally, the D-RAMiT module was added to address the issue of the model focusing exclusively on either local or global features. Experiments conducted on the publicly available ExDark low-light dataset demonstrated that the Dark-YOLO algorithm effectively mitigates issues such as poor detection performance, missed detections, false positives, and inaccurate localization under low-light conditions. The experimental results showed that the proposed model achieved a 3.0% improvement in mAP@0.5 and a 2.5% improvement in mAP@0.5:0.95 compared to the baseline. The improved model has a size of 5.7 MB, a computational complexity of 7.5 GFLOPS, and contains 2,744,971 parameters. These results provide strong evidence that the proposed model excels at performing object detection tasks in low-light environments, achieving superior detection performance with relatively low computational resource consumption. Additionally, evaluations on the Dark-Face dataset further validate the robustness of Dark-YOLO in low-light face detection tasks, which are critical for nighttime surveillance and security applications. On this dataset, Dark-YOLO achieves an mAP@0.5 of 49.1%, outperforming the baseline YOLOv8n (mAP@0.5 of 46.8%) by 4.9%, and an mAP@0.5:0.95 of 21.9%, demonstrating its capability to accurately detect faces under challenging illumination conditions with minimal resource overhead.
While Dark-YOLO significantly improves detection performance on datasets with limited data, such as the ExDark (6:2:2) split, its effectiveness on small-sample datasets remains an area for further enhancement. The model’s ability to generalize and perform optimally in scenarios with extremely scarce training data requires additional investigation and optimization.
Author Contributions
Conceptualization, Y.L. and S.L.; Methodology, Y.L. and S.L.; Software, Y.L.; Validation, L.Z., H.L. and Z.L.; Formal analysis, Y.L. and S.L.; Data curation, L.Z. and H.L.; Writing–original draft, Y.L.; Writing–review & editing, Y.L.; S.L. and H.L.; Supervision, S.L.; Project administration, S.L.; Funding acquisition, S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the sub-project of the Chinese Key Research and Development Program, CARS, specifically the project on micro-mirror scanning excitation and image processing research, Project No.: ZZG0012301.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, Q.; Zhang, D.; Liu, H.; He, Y. KCS-YOLO: An Improved Algorithm for Traffic Light Detection under Low Visibility Conditions. Machines 2024, 12, 557. [Google Scholar] [CrossRef]
- Ye, L.; Wang, D.; Yang, D.; Ma, Z.; Zhang, Q. VELIE: A vehicle-based efficient low-light image enhancement method for intelligent vehicles. Sensors 2024, 24, 1345. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, D.; Cao, Y. Image Quality enhancement with applications to unmanned aerial vehicle obstacle detection. Aerospace 2022, 9, 829. [Google Scholar] [CrossRef]
- Parkavi, K.; Ganguly, A.; Banerjee, A.; Sharma, S.; Kejriwal, K. Enhancing Road Safety: Detection of Animals on Highways During Night. IEEE Access 2025, 13, 2169–3536. [Google Scholar] [CrossRef]
- Abu Awwad, Y.; Rana, O.; Perera, C. Anomaly detection on the edge using smart cameras under low-light conditions. Sesnors 2024, 24, 772. [Google Scholar] [CrossRef] [PubMed]
- Yi, K.; Luo, K.; Chen, T.; Hu, R. An improved YOLOX model and domain transfer strategy for nighttime pedestrian and vehicle detection. Appl. Sci. 2022, 12, 12476. [Google Scholar] [CrossRef]
- Jung, M.; Cho, J. Enhancing Detection of Pedestrians in Low-Light Conditions by Accentuating Gaussian–Sobel Edge Features from Depth Maps. Appl. Sci. 2024, 14, 8326. [Google Scholar] [CrossRef]
- Wang, X.; Gao, J.-S.; Hou, B.-J.; Wang, Z.-S.; Ding, H.-W.; Wang, J. A lightweight modified YOLOX network using coordinate attention mechanism for PCB surface defect detection. IEEE Sens. J. 2022, 22, 20910–20920. [Google Scholar]
- Mukhiddinov, M.; Cho, J. Smart glass system using deep learning for the blind and visually impaired. Electronics 2021, 10, 2756. [Google Scholar] [CrossRef]
- Zheng, N.; Liu, H.; Zhang, Z. Hierarchic Clustering-Based Face Enhancement for Images Captured in Dark Fields. Electronics 2021, 10, 936. [Google Scholar] [CrossRef]
- Bose, S.; Kolekar, M.H.; Nawale, S.; Khut, D. Loltv: A low light two-wheeler violation dataset with anomaly detection technique. IEEE Access 2023, 11, 124951–124961. [Google Scholar] [CrossRef]
- Qu, J.; Liu, R.W.; Gao, Y.; Guo, Y.; Zhu, F.; Wang, F.-Y. Double domain guided real-time low-light image enhancement for ultra-high-definition transportation surveillance. IEEE Trans. Intell. Transp. Syst. 2024, 25, 9550–9562. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wang, K.; Liu, M.Z. Object recognition at night scene based on DCGAN and faster R.-CNN. IEEE Access 2020, 8, 193168–193182. [Google Scholar] [CrossRef]
- Xu, Y.; Chu, K.; Zhang, J. Nighttime Vehicle Detection Algorithm Based on Improved Faster-RCNN. IEEE Access 2023, 12, 19299–19306. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, D.; Reed, S.; Fu, C.-Y.; Berg, C.A. Ssd: Single shot multibox detector. In Proceeding of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Qin, Q.; Chang, K.; Huang, M.; Li, G. DENet: Detection-driven enhancement network for object detection under adverse weather conditions. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 2813–2829. [Google Scholar]
- Cui, Z.; Li, K.; Gu, L.; Su, S.; Gao, P.; Jiang, Z.; Qiao, Y.; Harada, T. You only need 90k parameters to adapt light: A light weight transformer for image enhancement and exposure correction. In Proceedings of the 33rd British Machine Vision Conference 2022 (BMVC 2022), London, UK, 21–24 November 2022. [Google Scholar]
- Zou, Y.; Long, W.; Li, Y.Y.; Liu, S.X. Research on Vehicle Detection Algorithm Based on Low Illumination Environment. Machinery 2022, 49, 66–74. [Google Scholar]
- Wang, J.; Yang, Y.; Yan, H. Image quality enhancement using hybrid attention networks. IET Image Process. 2022, 16, 521–534. [Google Scholar] [CrossRef]
- Hong, M.; Cheng, S.; Huang, H.; Fan, H.; Liu, S. You Only Look Around: Learning Illumination Invariant Feature for Low-light Object Detection. arXiv 2024, arXiv:2410.18398. [Google Scholar]
- Hashmi, K.A.; Kallempudi, G.; Stricker, D.; Afzal, M.Z. Featenhancer: Enhancing hierarchical features for object detection and beyond under low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6725–6735. [Google Scholar]
- Yin, X.; Yu, Z.; Fei, Z.; Lv, W.; Gao, X. Pe-yolo: Pyramid enhancement network for dark object detection. In International Conference on Artificial Neural Networks, Lugano-Viganello, Switzerland, 17–20 September 2023; Springer Nature: Cham, Switzerland, 2023; pp. 163–174. [Google Scholar]
- Ding, Y.; Luo, X. SDNIA-YOLO: A Robust Object Detection Model for Extreme Weather Conditions. arXiv 2024, arXiv:2406.12395. [Google Scholar]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-adaptive YOLO for object detection in adverse weather conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 1792–1800. [Google Scholar]
- Han, Z.; Yue, Z.; Liu, L. 3L-YOLO: A Lightweight Low-Light Object Detection Algorithm. Appl. Sci. 2024, 15, 90. [Google Scholar] [CrossRef]
- Bhattacharya, J.; Modi, S.; Gregorat, L.; Ramponi, G. D2bgan: A dark to bright image conversion model for quality enhancement and analysis tasks without paired supervision. IEEE Access 2022, 10, 57942–57961. [Google Scholar] [CrossRef]
- Zhang, C.; Lee, D. Advancing Nighttime Object Detection through Image Enhancement and Domain Adaptation. Appl. Sci. 2024, 14, 8109. [Google Scholar] [CrossRef]
- Wang, J.; Yang, P.; Liu, Y.; Shang, D.; Hui, X.; Song, J.; Chen, X. Research on improved yolov5 for low-light environment object detection. Electronics 2023, 12, 3089. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Chang, Q.; Wang, Y.; Chen, H. Research on Low-Light Environment Object Detection Algorithm Based on YOLO_GD. Electronics 2024, 13, 3527. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, F.; Zhang, S.; Yang, L.; Zhang, H.; Liu, S.; Liu, Q. Advanced Object Detection in Low-Light Conditions: Enhancements to YOLOv7 Framework. Remote Sens. 2024, 16, 4493. [Google Scholar] [CrossRef]
- Mei, M.; Zhou, Z.; Liu, W.; Ye, Z. GOI-YOLOv8 Grouping Offset and Isolated GiraffeDet Low-Light Target Detection. Sensors 2024, 24, 5787. [Google Scholar] [CrossRef]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Wang, C.; Feng, J. Improving Convolutional Networks with Self-Calibrated Convolutions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10093–10102. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MY, USA, 17–23 July 2021. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar] [CrossRef]
- Choi, H.; Na, C.; Oh, J.; Lee, S.; Kim, J.; Choe, S.; Lee, J.; Kim, T.; Yang, J. Reciprocal Attention Mixing Transformer for Lightweight Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024. [Google Scholar] [CrossRef]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the Exclusively Dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Yang, W.; Yuan, Y.; Ren, W.; Liu, J.; Scheirer, J.W.; Wang, Z. Advancing Image Understanding in Poor Visibility Environments: A Collective Benchmark Study. IEEE Trans. Image Process. 2020, 29, 5737–5752. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1777–1786. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired Unrolling with Cooperative Prior Architecture Search for Low-light Image Enhancement. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 10556–10565. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward Fast, Flexible, and Robust Low-Light Image Enhancement. arXiv 2022, arXiv:2204.10137. [Google Scholar] [CrossRef]
- Jiang, C.; He, X.; Xiang, J. LOL-YOLO: Low-Light Object Detection Incorporating Multiple Attention Mechanisms. Comput. Eng. Appl. 2024, 60, 177–187. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).