
Disaster Recognition and Classification Based on Improved ResNet-50 Neural Network



Abstract
1. Introduction
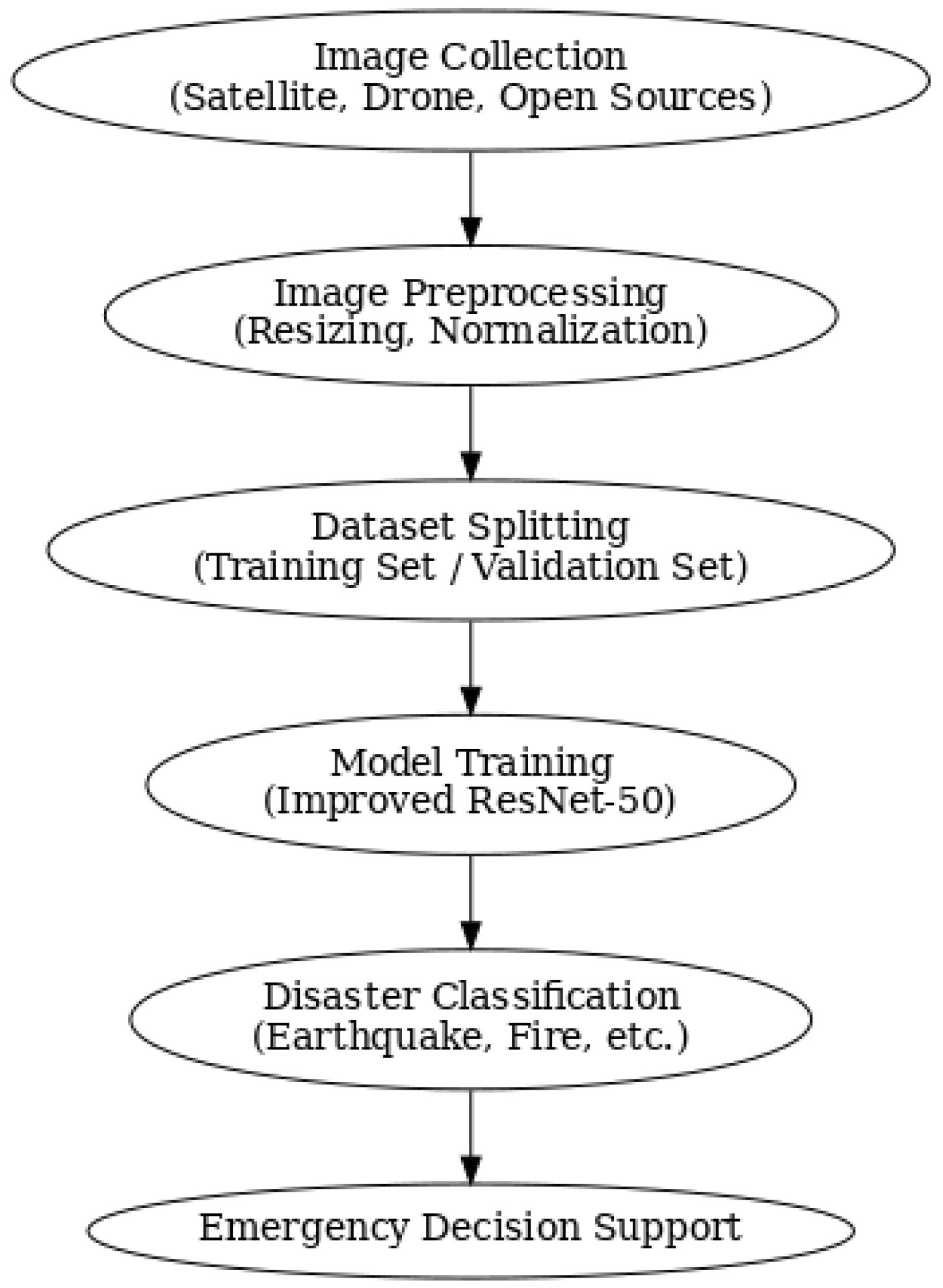
2. Materials and Methods
2.1. Dataset Preparation
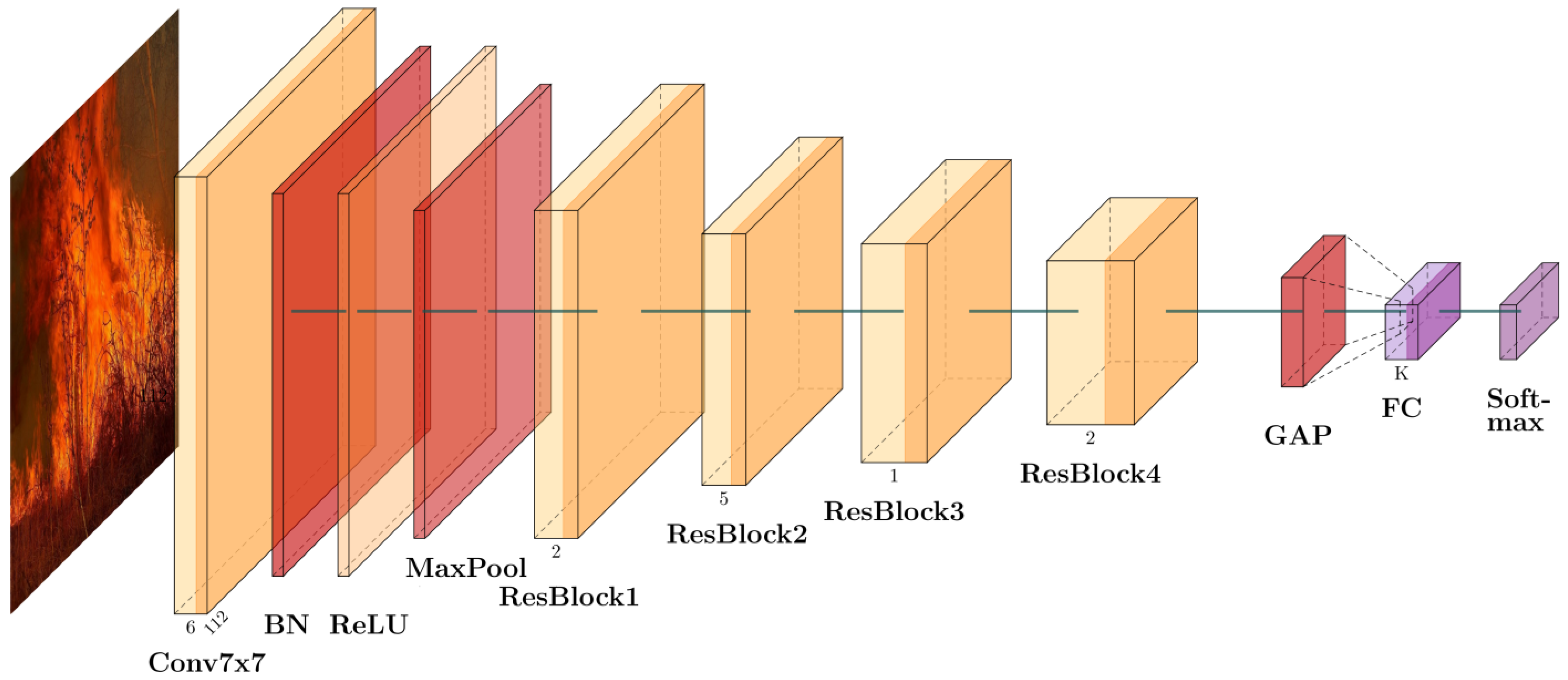
2.2. Model Architecture Design
2.2.1. Construction of the Initial Convolutional Layer
2.2.2. Residual Module Design
2.2.3. Stage-Wise Residual Stacking
2.2.4. Global Feature Aggregation and Classification
2.2.5. Parameter Initialization and Training Strategy
3. Results and Discussion
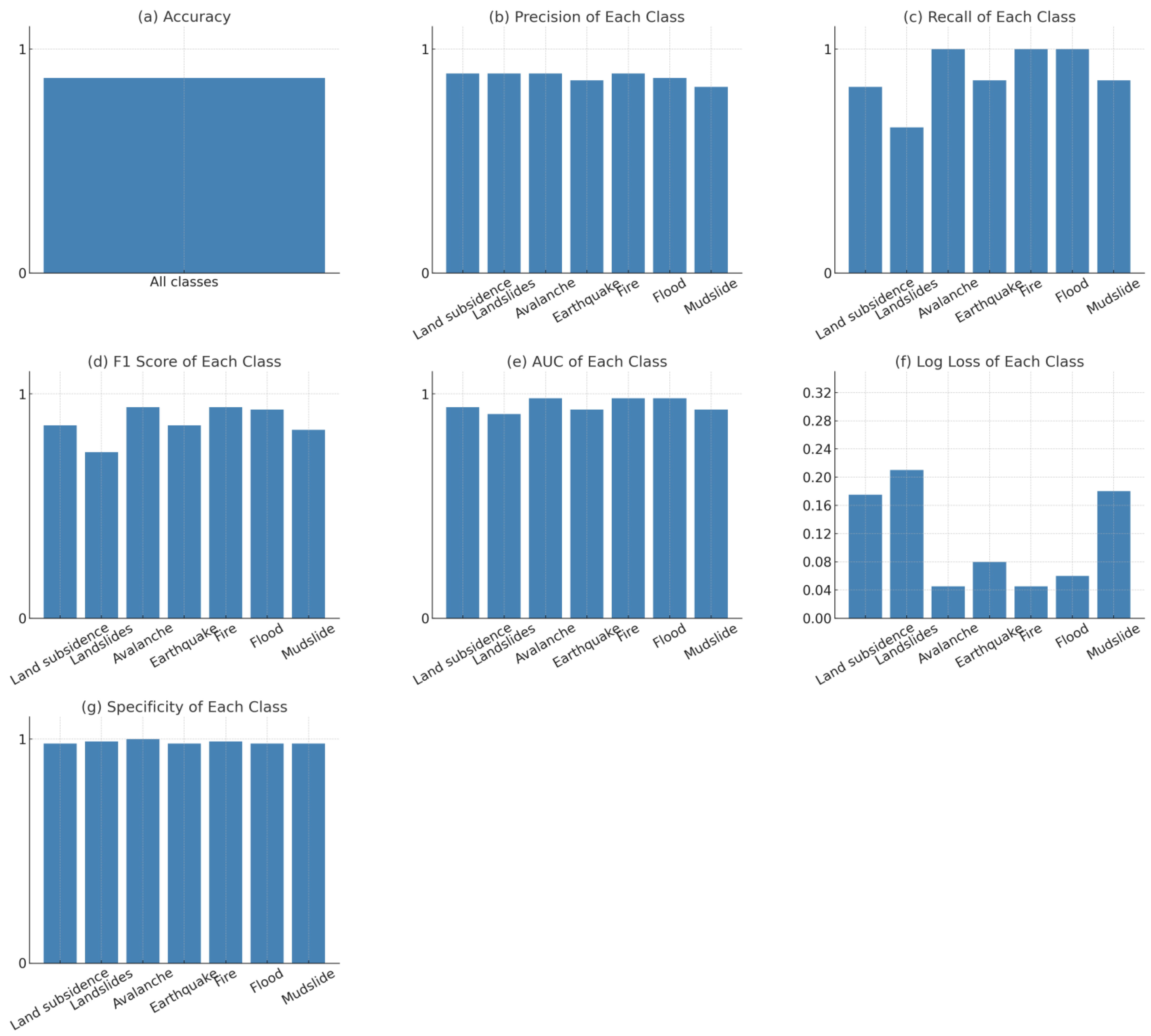
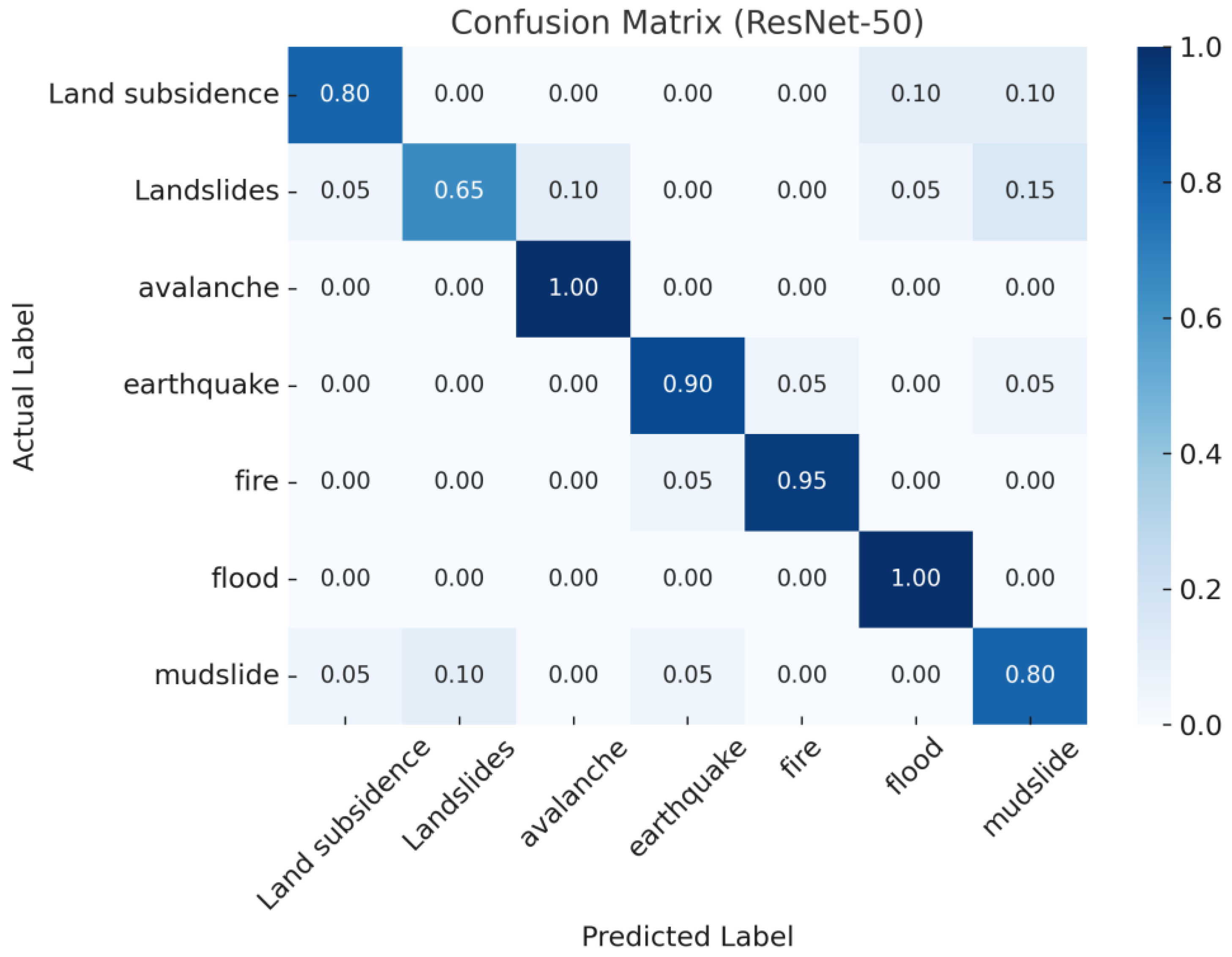
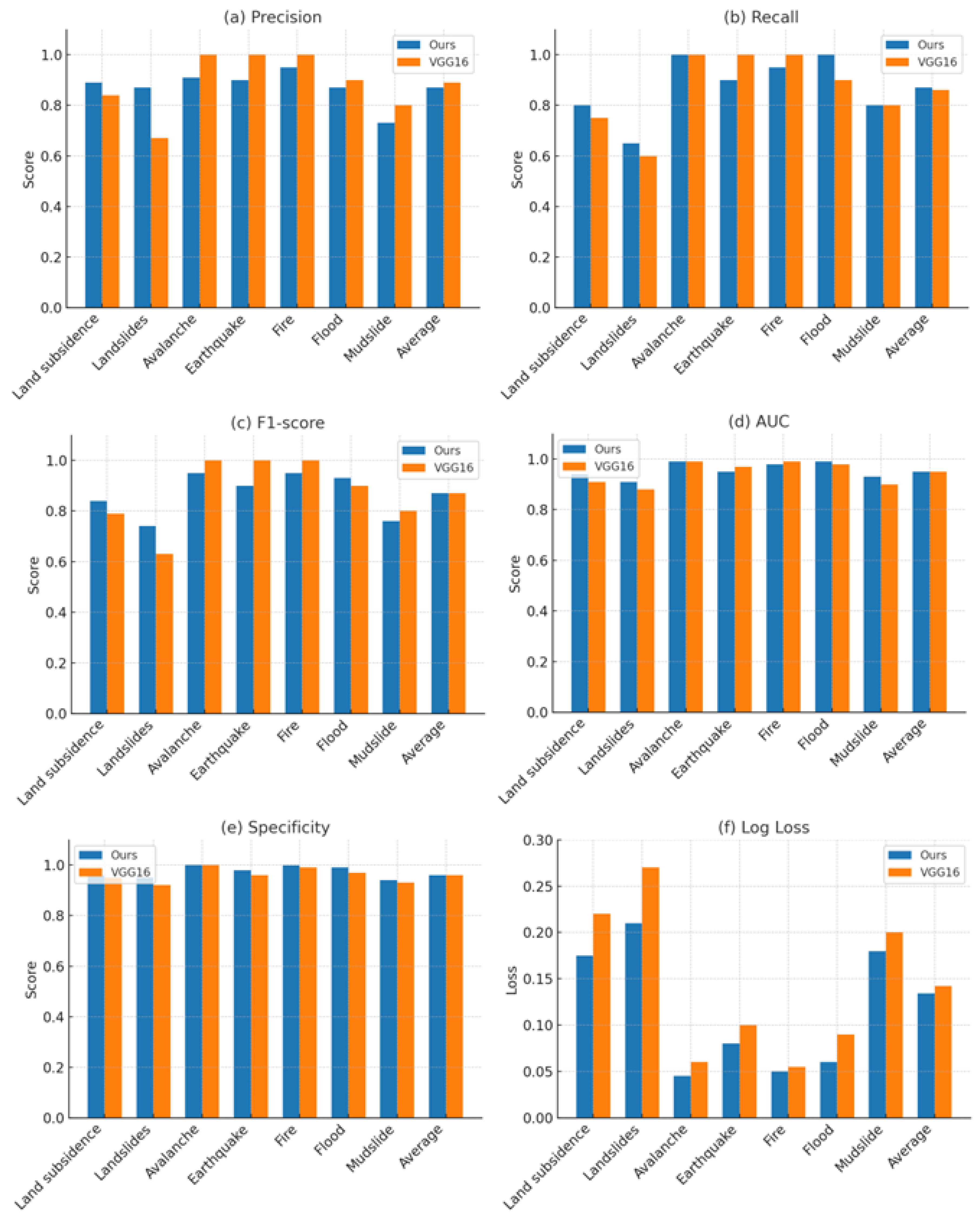
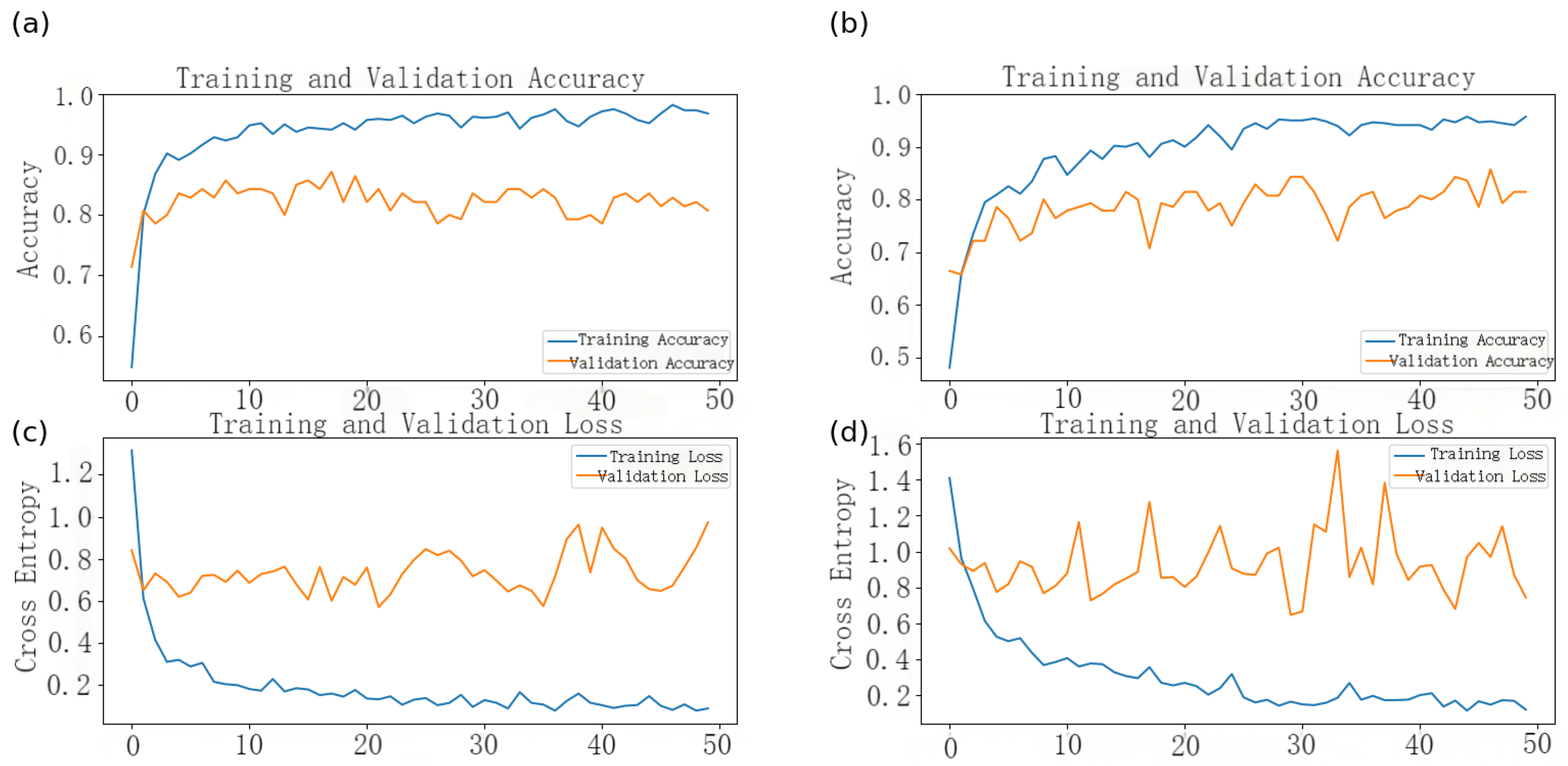
3.1. Evaluation of Model Classification Performance
3.2. Model Performance Comparison
3.3. Practical Deployment of the Disaster Classification System
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Intergovernmental Panel on Climate Change. Climate Change 2023: Synthesis Report. Summary for Policymakers. 2023. Available online: https://www.ipcc.ch/report/ar6/syr/downloads/report/IPCC_AR6_SYR_SPM.pdf (accessed on 1 March 2025).
- United Nations Development Programme. Innovation in Disaster Management: Harnessing Technology to Build Resilience; UNDP: 2024. Available online: https://www.undp.org/sites/g/files/zskgke326/files/2024-03/innovation_in_disaster_management_web_final_compressed.pdf (accessed on 1 March 2025).
- Zhou, L.; Wu, X.; Xu, Z.; Fujita, H. Emergency decision making for natural disasters: An overview. Int. J. Disaster Risk Reduct. 2018, 27, 567–576. [Google Scholar] [CrossRef]
- Su, W.; Chen, L.; Gao, X. Emergency decision making: A literature review and future directions. Sustainability 2022, 14, 10925. [Google Scholar] [CrossRef]
- Mustafa, A.M.; Agha, R.; Ghazalat, L.; Sha’ban, T. Natural disasters detection using explainable deep learning. Intell. Syst. Appl. 2024, 23, 200430. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Halder, R.K.; Uddin, M.N.; Uddin, M.A.; Aryal, S.; Khraisat, A. Enhancing K-nearest neighbor algorithm: A comprehensive review and performance analysis of modifications. J. Big Data 2024, 11, 113. [Google Scholar] [CrossRef]
- Mienye, I.D.; Jere, N. A survey of decision trees: Concepts, algorithms, and applications. IEEE Access 2024, 12, 86716–86727. [Google Scholar] [CrossRef]
- Alam, F.; Ofli, F.; Imran, M.; Meier, P. MEDIC: A multi-task learning dataset for disaster image classification. Neural Comput. Appl. 2023, 35, 2609–2632. [Google Scholar] [CrossRef]
- Benson, V.; Ecker, A. Assessing out-of-domain generalization for robust building damage detection. arXiv 2020, arXiv:2011.10328. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Dai, Z.; Heckel, R. Channel Normalization in Convolutional Neural Network avoids Vanishing Gradients. arXiv 2019, arXiv:1907.09539. [Google Scholar]
- Shianios, D.; Kolios, P.; Kyrkou, C. DiRecNetV2: A Transformer-Enhanced Network for Aerial Disaster Recognition. arXiv 2024, arXiv:2410.13663. [Google Scholar] [CrossRef]
- Dinani, S.T.; Caragea, D. Disaster Image Classification Using Pre-trained Transformer and Contrastive Learning Models. In Proceedings of the 2023 IEEE 10th International Conference on Data Science and Advanced Analytics (DSAA), Thessaloniki, Greece, 9–13 October 2023; pp. 1–11. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. What is YOLOv5: A deep look into the internal features of the popular object detector. arXiv 2024, arXiv:2407.20892. [Google Scholar]
- Khan, S.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- IBM. What Is Deep Learning? n.d. Available online: https://www.ibm.com/think/topics/deep-learning (accessed on 26 April 2025).
- Zhang, Y.; Wang, J.; Liu, Y.; Rong, L.; Zheng, Q.; Song, D.; Tiwari, P.; Qin, J. A multitask learning model for multimodal sarcasm, sentiment and emotion recognition in conversations. Inf. Fusion 2023, 93, 282–301. [Google Scholar] [CrossRef]
- Eltehewy, R.; Abouelfarag, A.; Saleh, S.N. Efficient classification of imbalanced natural disasters data using deep learning. ISPRS Int. J. Geo-Inf. 2023, 12, 245. [Google Scholar] [CrossRef]
- Babula, M. Disaster Images Dataset (CNN Model). n.d. Kaggle. Available online: https://www.kaggle.com/datasets/mikolajbabula/disaster-images-dataset-cnn-model (accessed on 26 April 2025).
- Rosebrock, A. Detecting Natural Disasters with Keras and Deep Learning. PyImageSearch. 11 November 2019. Available online: https://pyimagesearch.com/2019/11/11/detecting-natural-disasters-with-keras-and-deep-learning/ (accessed on 26 April 2025).
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Xie, T.; Cheng, X.; Wang, X.; Liu, M.; Deng, J.; Zhou, T.; Liu, M. Cut-Thumbnail: A Novel Data Augmentation for Convolutional Neural Network. arXiv 2021, arXiv:2103.05342. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Mahjoubi, M.A.; Lamrani, D.; Saleh, S.; Moutaouakil, W.; Ouhmida, A.; Hamida, S.; Raihani, A. Optimizing ResNet50 Performance Using Stochastic Gradient Descent on MRI Images for Alzheimer’s Disease Classification. Intell.-Based Med. 2025, 11, 100219. [Google Scholar] [CrossRef]
- Rathod, A.; Pariawala, V.; Surana, M.; Saxena, K. Leveraging CNNs and ensemble learning for automated disaster image classification. arXiv 2023, arXiv:2311.13531. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Number of Bottlenecks | Number of Input Channels | Number of Output Channels |
|---|---|---|---|
| 1 | 3 | 64 | 256 |
| 2 | 4 | 256 | 512 |
| 3 | 6 | 512 | 1024 |
| 4 | 3 | 1024 | 2048 |
| Disaster Type | Precision | Recall | F1-Score | AUC | Specificity | Log Loss | Support |
|---|---|---|---|---|---|---|---|
| Land subsidence | 0.89 | 0.80 | 0.84 | 0.94 | 0.96 | 0.175 | 20 |
| Landslides | 0.87 | 0.65 | 0.74 | 0.91 | 0.95 | 0.210 | 20 |
| Avalanche | 0.91 | 1.00 | 0.95 | 0.99 | 1.00 | 0.045 | 20 |
| Earthquake | 0.90 | 0.90 | 0.90 | 0.95 | 0.98 | 0.080 | 20 |
| Fire | 0.95 | 0.95 | 0.95 | 0.98 | 0.998 | 0.050 | 20 |
| Flood | 0.87 | 1.00 | 0.93 | 0.99 | 0.99 | 0.060 | 20 |
| Mudslide | 0.73 | 0.80 | 0.76 | 0.93 | 0.94 | 0.180 | 20 |
| Total/Average | 0.87 | 0.87 | 0.87 | 0.95 | 0.96 | 0.134 | 140 |
| Model | Accuracy |
|---|---|
| ResNet-50 | 0.87 |
| VGG16 | 0.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, L.; Xiao, Z.; Xu, X.; Liu, B. Disaster Recognition and Classification Based on Improved ResNet-50 Neural Network. Appl. Sci. 2025, 15, 5143. https://doi.org/10.3390/app15095143
Wen L, Xiao Z, Xu X, Liu B. Disaster Recognition and Classification Based on Improved ResNet-50 Neural Network. Applied Sciences. 2025; 15(9):5143. https://doi.org/10.3390/app15095143
Chicago/Turabian StyleWen, Lei, Zikai Xiao, Xiaoting Xu, and Bin Liu. 2025. "Disaster Recognition and Classification Based on Improved ResNet-50 Neural Network" Applied Sciences 15, no. 9: 5143. https://doi.org/10.3390/app15095143
APA StyleWen, L., Xiao, Z., Xu, X., & Liu, B. (2025). Disaster Recognition and Classification Based on Improved ResNet-50 Neural Network. Applied Sciences, 15(9), 5143. https://doi.org/10.3390/app15095143