
A Comparative Analysis of the Usability of Consumer Graphics Cards for Deep Learning in the Aspects of Inland Navigational Signs Detection for Vision Systems


Abstract
1. Introduction
- Consumer-grade GPUs: high-end GPUs are not always available or necessary for medium-sized research labs, small and medium-sized companies, or individuals developing real-time systems.
- There is a lack of practical multi-criteria analysis that systematically compares consumer card GPUs along multiple dimensions (performance, cost of entry, power consumption, and broader compatibility), which are critical factors in real system solutions. This is especially true for methodologies that make a lasting contribution to the post-comparison process of graphics cards.
- Requirements for specific applications: many of the existing comparisons are not directly applicable to real-time or near-real-time tasks, where both the speed of conversion and energy efficiency are most important (e.g., USV-type autonomus navigation systems).
- Methodological contribution: We introduce a multi-criteria framework to objectively evaluate GPUs using 21 different characteristics, including performance in the learning and inference phases and energy efficiency. The framework provides a repeatable and robust approach that others can adapt and extend to different tasks or hardware configurations.
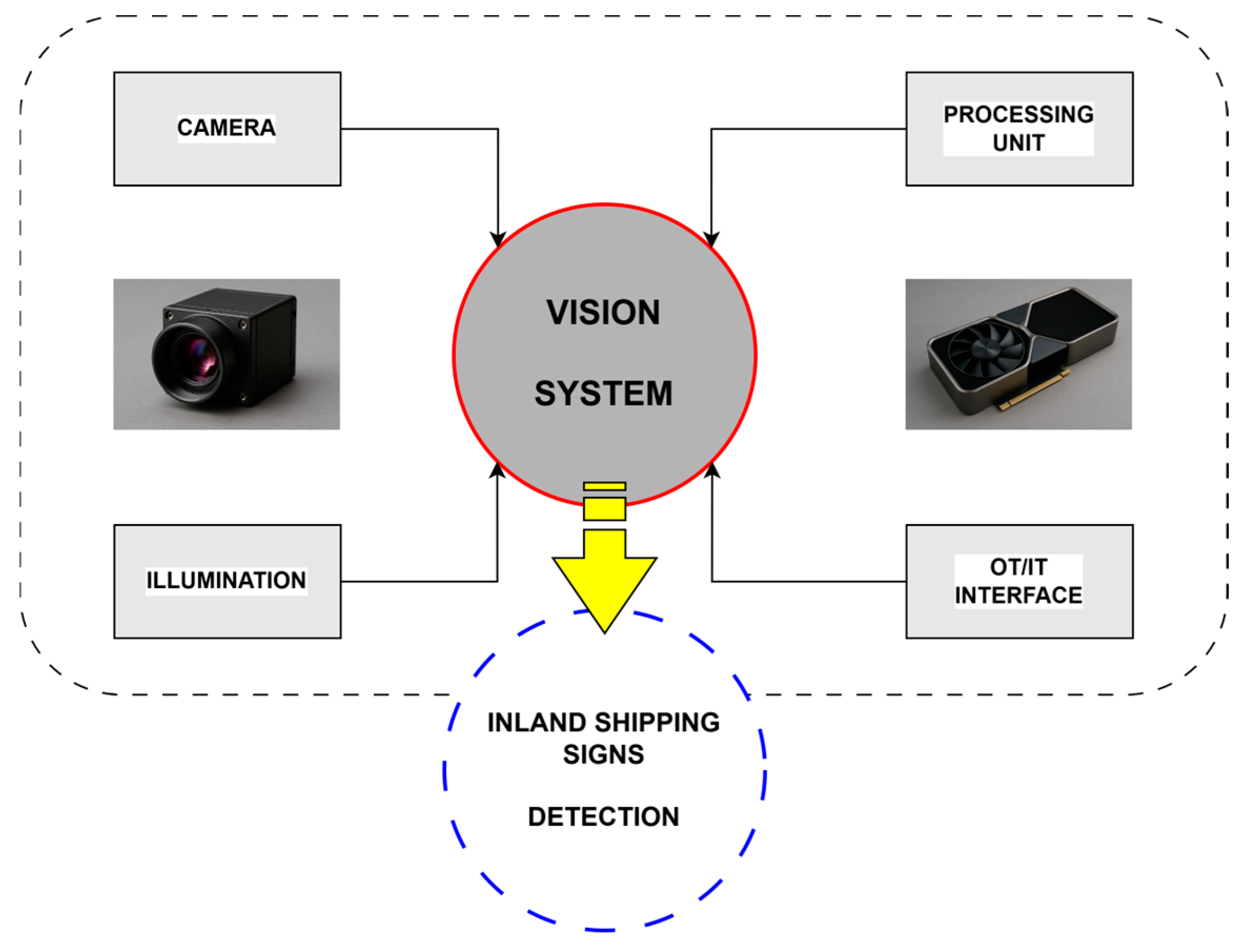
- Application to inland navigation: We demonstrate the practical utility of our approach by applying it to the detection of navigational marks in inland navigation. Although navigational sign detection serves as a case study, the methodology and findings can be generalized to many real-time image-based tasks where timely and efficient processing is crucial.
- Sustained comparison value: Covering devices from three leading GPU manufacturers, AMD, Intel, and Nvidia, our comparison provides a sustainable benchmark for researchers and practitioners seeking consumer-oriented GPU solutions. Because we evaluate factors such as power consumption and compatibility that are not quickly becoming obsolete, our analysis maintains validity beyond mere peak performance metrics.
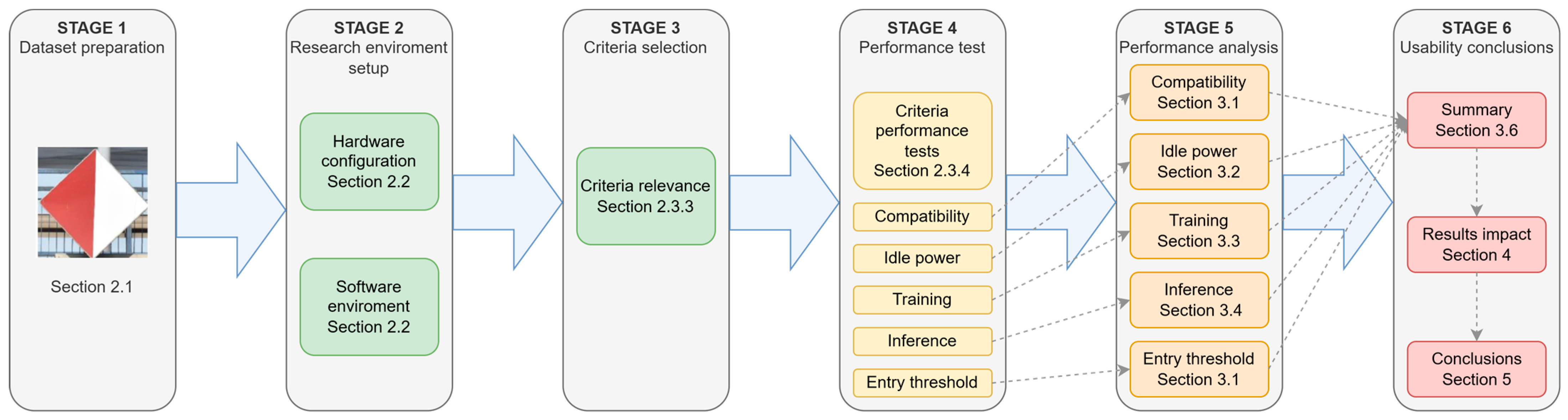
2. Materials and Methods
2.1. Description of the Datasets Used for the Analysis
2.2. Description of the Hardware and Software Platforms on Which the Tests Were Conducted
2.3. Research Methodology
2.3.1. Multi-Criteria Decision-Making Method
2.3.2. Result Normalization Against the Most Efficient Solution
2.3.3. Criteria and Their Relevance in the Context of Comparison
2.3.4. Description of the Criteria Performance Tests
- Compatibility criteria: Compatibility validation was performed based on the available documentation for the framework, and the AI library was designed to work with the graphics card. An attempt was made to run calculations for each of the frameworks to confirm compatibility.
- Idle power criterion: The computer launched the PyCharm Community IDE and the terminal. Then, a tool was run to monitor the status of the graphics card at a frequency of 1 Hz and write to a file. The test was conducted for 10 min, after which the measurement was manually interrupted. The result of the measurement is the average power reported by the monitoring software.
- Learning energy efficiency criteria: Two instances of the terminal were launched; the first activated the virtual Python environment [64] with the necessary libraries installed. Then, a program written in Python was launched, which used the framework to start the learning process. To measure the learning rate, tools built into the framework were used, which return the calculation rate of one epoch of the neural network model’s training. The time used for calculation was the arithmetic average of all epoch times. Training of each neural network model was conducted for 30 epochs. During the learning process, a record of electricity consumption measurement was launched on the second terminal. Energy efficiency was determined according to the following formula:
- 4.
- Inference energy efficiency criteria: The tests were carried out similarly to the learning efficiency tests, with the Python virtual environment running on one terminal for each criterion and the measurement of electricity consumption on the other. The program written in Python was designed to check a test set of photos using an already trained neural network model, determining the time allocated to the inference of each file. In order to minimize the impact of the speed of reading images from a disk, the entire test set was first loaded into RAM, and only then was the processing speed measured. The time used to determine the energy efficiency was the average of all inference times of the test set. Energy efficiency was determined according to the following formula:
- 5.
- The criterion of the technology entry threshold: Based on the list of available graphics card models in the model line of a given manufacturer, the lowest model of the graphics card offered by the manufacturer of the graphics chip was determined. These were AMD Radeon RX 7600 [65], Intel ARC A310 [66], and Nvidia–GeForce RTX 4060 [67]. Then, the price of the cheapest graphics card was determined for these chips using a price comparison website [68].
3. Results
3.1. Framework Compatibility
3.1.1. Nvidia Card Compatibility
3.1.2. AMD Card Compatibility
3.1.3. Intel Card Compatibility
3.2. Measurement of Idle Power
3.3. Training Energy Efficiency
3.4. Inference Energy Efficiency
3.5. Technology Entry Threshold
3.6. Compilation of Standardized Results for Measuring the Performance of the Criteria
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AMD | Advanced Micro Devices |
| API | Application Programming Interface |
| ATX | Advanced Technology eXtended |
| CPU | Central Processing Unit |
| CUDA | Compute Unified Device Architecture |
| CuDNN | CUDA Deep Neural Network library |
| E | Energy Efficiency of Inference |
| ep | Epoch (one complete pass through the entire training dataset during the model training process) |
| FP64 | Floating Point 64 |
| GB | Gigabyte |
| GPU | Graphics Processing Unit |
| HIP | Heterogeneous Computer Interface for Portability |
| HPC | High-Performance Computing |
| Hz | Hertz |
| IDE | Integrated Development Environment |
| IPEX | Intel® Extension for PyTorch |
| kj | Kilojoule |
| ms | Millisecond |
| MSI | Micro-Star International |
| NPU | Neural Processing Unit |
| ONNX | Open Neural Network Exchange |
| PLN | Polish Zloty |
| RAM | Random Access Memory |
| ROCm | Radeon Open Compute |
| s | Second |
| SciKit | Scientific toolkit |
| T | Time in seconds |
| TB | Terabyte |
| TBP | Total Board Power |
| TGP | Total Graphics Power |
| VRAM | Video Random Access Memory |
| W | Watt |
| WSM | Weighted Scoring Method |
| XMX | Xe Matrix eXtensions |
References
- You, L.; Xiao, S.; Peng, Q.; Claramunt, C.; Han, X.; Guan, Z.; Zhang, J. ST-Seq2Seq: A Spatio-Temporal Feature-Optimized Seq2Seq Model for Short-Term Vessel Trajectory Prediction. IEEE Access 2020, 8, 218565–218574. [Google Scholar] [CrossRef]
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M.; Jennings, P.; Mouzakitis, A. Deep Learning-Based Vehicle Behavior Prediction for Autonomous Driving Applications: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 33–47. [Google Scholar] [CrossRef]
- Azimi, S.; Salokannel, J.; Lafond, S.; Lilius, J.; Salokorpi, M.; Porres, I. A Survey of Machine Learning Approaches for Surface Maritime Navigation. 2020. Available online: http://hdl.handle.net/2117/329714 (accessed on 12 February 2025).
- Donandt, K.; Böttger, K.; Söffker, D. Short-Term Inland Vessel Trajectory Prediction with Encoder-Decoder Models. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 974–979. [Google Scholar] [CrossRef]
- Agorku, G.; Hernandez, S.; Falquez, M.; Poddar, S.; Amankwah-Nkyi, K. Traffic Cameras to Detect Inland Waterway Barge Traffic: An Application of Machine Learning, Computer Vision and Pattern Recognition. arXiv 2024, arXiv:2401.03070. [Google Scholar]
- Hart, F.; Okhrin, O.; Treiber, M. Vessel-Following Model for Inland Waterways Based on Deep Reinforcement Learning. Ocean. Eng. 2023, 281, 114679. [Google Scholar] [CrossRef]
- Vanneste, A.; Vanneste, S.; Vasseur, O.; Janssens, R.; Billast, M.; Anwar, A.; Mets, K.; De Schepper, T.; Mercelis, S.; Hellinckx, P. Safety Aware Autonomous Path Planning Using Model Predictive Reinforcement Learning for Inland Waterways. In Proceedings of the IECON 2022–48th Annual Conference of the IEEE Industrial Electronics Society, Brussels, Belgium, 17–20 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Qiao, Y.; Yin, J.; Wang, W.; Duarte, F.; Yang, J.; Ratti, C. Survey of Deep Learning for Autonomous Surface Vehicles in Marine Environments. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3678–3701. [Google Scholar] [CrossRef]
- SIGNI. European Code for Signs and Signals on Inland Waterways: Resolution No. 90; United Nations: New York, NY, USA, 2018. [Google Scholar]
- Jerzyło, P.; Rekowska, P.; Kujawski, A. Shipping Safety Management on Polish Inland Waterways. Arch. Transp. Syst. Telemat. 2018, 11, 18–22. [Google Scholar]
- Fan, W.; Zhong, Z.; Wang, J.; Xia, Y.; Wu, H.; Wu, Q.; Liu, B. Vessel-Bridge Collisions: Accidents, Analysis, and Protection. China J. Highw. Transp. 2024, 37, 38–66. [Google Scholar]
- Agorku, G.; Hernandez, S.; Falquez, M.; Poddar, S.; Amankwah-Nkyi, K. Real-Time Barge Detection Using Traffic Cameras and Deep Learning on Inland Waterways. Transp. Res. Rec. 2024. [Google Scholar] [CrossRef]
- Wawrzyniak, N.; Stateczny, A. Automatic Watercraft Recognition and Identification on Water Areas Covered by Video Monitoring as Extension for Sea and River Traffic Supervision Systems. Pol. Marit. Res. 2018, 25, 5–13. [Google Scholar] [CrossRef]
- Restrepo-Arias, J.F.; Branch-Bedoya, J.W.; Zapata-Cortes, J.A.; Paipa-Sanabria, E.G.; Garnica-López, M.A. Industry 4.0 Technologies Applied to Inland Waterway Transport: Systematic Literature Review. Sensors 2022, 22, 3708. [Google Scholar] [CrossRef]
- Wawrzyniak, N.; Hyla, T.; Popik, A. Vessel Detection and Tracking Method Based on Video Surveillance. Sensors 2019, 19, 5230. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Hu, Y.; Ji, H.; Zhang, M.; Yu, Q. A Deep Learning Method for Ship Detection and Traffic Monitoring in an Offshore Wind Farm Area. J. Mar. Sci. Eng. 2023, 11, 1259. [Google Scholar] [CrossRef]
- Li, J.; Sun, J.; Li, X.; Yang, Y.; Jiang, X.; Li, R. LFLD-CLbased NET: A Curriculum-Learning-Based Deep Learning Network with Leap-Forward-Learning-Decay for Ship Detection. J. Mar. Sci. Eng. 2023, 11, 1388. [Google Scholar] [CrossRef]
- Liu, B.; Wang, S.Z.; Xie, Z.X.; Zhao, J.S.; Li, M.F. Ship Recognition and Tracking System for Intelligent Ship Based on Deep Learning Framework. TransNav Int. J. Mar. Navig. Saf. Sea Transp. 2019, 13, 699–705. [Google Scholar] [CrossRef]
- Shi, K.; He, S.; Shi, Z.; Chen, A.; Xiong, Z.; Chen, J.; Luo, J. Radar and Camera Fusion for Object Detection and Tracking: A Comprehensive Survey. arXiv 2024, arXiv:2410.19872. [Google Scholar]
- Wei, P.; Cagle, L.; Reza, T.; Ball, J.; Gafford, J. LiDAR and Camera Detection Fusion in a Real-Time Industrial Multi-Sensor Collision Avoidance System. Electronics 2018, 7, 84. [Google Scholar] [CrossRef]
- Hoehner, F.; Langenohl, V.; Akyol, S.; el Moctar, O.; Schellin, T.E. Object Detection and Tracking in Maritime Environments in Case of Person-Overboard Scenarios: An Overview. J. Mar. Sci. Eng. 2024, 12, 2038. [Google Scholar] [CrossRef]
- Rodríguez-Gonzales, J.L.; Niquin-Jaimes, J.; Paiva-Peredo, E. Comparison of Algorithms for the Detection of Marine Vessels with Machine Vision. Int. J. Electr. Comput. Eng. 2024, 14, 6332–6338. [Google Scholar] [CrossRef]
- Heller, D.; Rizk, M.; Douguet, R.; Baghdadi, A.; Diguet, J.-P. Marine Objects Detection Using Deep Learning on Embedded Edge Devices. In Proceedings of the RSP 2022, Shanghai, China, 13 October 2022; IEEE: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Folarin, A.; Munin-Doce, A.; Ferreno-Gonzalez, S.; Ciriano-Palacios, J.M.; Diaz-Casas, V. Real Time Vessel Detection Model Using Deep Learning Algorithms for Controlling a Barrier System. J. Mar. Sci. Eng. 2024, 12, 1363. [Google Scholar] [CrossRef]
- Alhattab, Y.A.; Abidin, Z.B.Z.; Faizabadi, A.R.; Zaki, H.F.M.; Ibrahim, A.I. Integration of Stereo Vision and MOOS-IvP for Enhanced Obstacle Detection and Navigation in Unmanned Surface Vehicles. IEEE Access 2023, 11, 128932–128956. [Google Scholar] [CrossRef]
- Hao, G.; Xiao, W.; Huang, L.; Chen, J.; Zhang, K.; Chen, Y. The Analysis of Intelligent Functions Required for Inland Ships. J. Mar. Sci. Eng. 2024, 12, 836. [Google Scholar] [CrossRef]
- Li, Y.; Hu, Y.; Rigo, P.; Lefler, F.E.; Zhao, G. (Eds.) Proceedings of PIANC Smart Rivers 2022: Green Waterways and Sustainable Navigations; Lecture Notes in Civil Engineering; Springer: Singapore, 2023; Volume 264. [Google Scholar] [CrossRef]
- Hammedi, W. Smart River: Towards Efficient Cooperative Autonomous Inland Navigation. Ph.D. Thesis, Université Bourgogne Franche-Comté, Besançon, France, 2022. Available online: https://theses.hal.science/tel-03614827 (accessed on 12 February 2025).
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Sharma, O. Deep Challenges Associated with Deep Learning. In Proceedings of the International Conference on Machine Learning, Big Data, Cloud and Parallel Computing: Trends, Perspectives and Prospects (COMITCon 2019), Faridabad, India, 14–16 February 2019; pp. 72–75. [Google Scholar] [CrossRef]
- Tsimenidis, S. Limitations of Deep Neural Networks: A Discussion of G. Marcus’ Critical Appraisal of Deep Learning. arXiv 2020, arXiv:2012.15754. [Google Scholar] [CrossRef]
- Nia, V.P.; Zhang, G.; Kobyzev, I.; Metel, M.R.; Li, X.; Sun, K.; Hemati, S.; Asgharian, M.; Kong, L.; Liu, W.; et al. Mathematical Challenges in Deep Learning. arXiv 2023, arXiv:2303.15464. Available online: http://arxiv.org/abs/2303.15464 (accessed on 12 February 2025).
- Patterson, D.A.; Hennessy, J.L. Computer Architecture: A Quantitative Approach, 5th ed.; Morgan Kaufmann: Waltham, MA, USA, 2012. [Google Scholar]
- Owens, J.D.; Houston, M.; Luebke, D.; Green, S.; Stone, J.E.; Phillips, J.C. GPU Computing. Proc. IEEE 2008, 96, 879–899. [Google Scholar] [CrossRef]
- McClure, N. TensorFlow Machine Learning Cookbook; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. arXiv 2016, arXiv:1605.08695. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Manakitsa, N.; Maraslidis, G.S.; Moysis, L.; Fragulis, G.F. A Review of Machine Learning and Deep Learning for Object Detection, Semantic Segmentation, and Human Action Recognition in Machine and Robotic Vision. Technologies 2024, 12, 15. [Google Scholar] [CrossRef]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]
- Shi, S.; Wang, Q.; Chu, X. Performance Modeling and Evaluation of Distributed Deep Learning Frameworks on GPUs. arXiv 2016, arXiv:1711.05979. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, Y.; Yoo, S.; Hoisie, A. Performance Analysis of Deep Learning Workloads on Leading-edge Systems. In Proceedings of the 2019 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS), Denver, CO, USA, 18 November 2019; pp. 103–113. [Google Scholar] [CrossRef]
- Markidis, S.; Chien, S.W.D.; Laure, E.; Peng, I.B.; Vetter, J.S. NVIDIA Tensor Core Programmability. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Vancouver, BC, Canada, 21–25 May 2018; pp. 522–531. [Google Scholar] [CrossRef]
- Otterness, N.; Anderson, J.H. AMD GPUs as an Alternative to NVIDIA for Supporting Real-Time Workloads. Leibniz Int. Proc. Inform. 2020, pp. 12:1–12:23. Available online: https://www.cs.unc.edu/~anderson/papers/ecrts20a.pdf (accessed on 12 January 2025).
- You, Y.; Zhang, Z.; Hsieh, C.-J.; Demmel, J.; Keutzer, K. ImageNet Training in Minutes. In Proceedings of the 47th International Conference on Parallel Processing (ICPP), Eugene, OR, USA, 13–16 August 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Gyawali, D. Comparative Analysis of CPU and GPU Profiling for Deep Learning Models. arXiv 2023, arXiv:2309.02521. [Google Scholar]
- Pallipuram, V.K.; Bhuiyan, M.; Smith, M.C. A Comparative Study of GPU Programming Models and Architectures Using Neural Networks. J. Supercomput. 2012, 61, 673–718. [Google Scholar] [CrossRef]
- Jadhav, A.; Sonar, R. Analytic Hierarchy Process (AHP), Weighted Scoring Method (WSM), and Hybrid Knowledge Based System (HKBS) for Software Selection: A Comparative Study. In Proceedings of the 2nd International Conference on Emerging Trends in Engineering and Technology (ICETET 2009), Nagpur, India, 16–18 December 2009; IEEE: Piscataway, NJ, USA; pp. 991–997. [Google Scholar] [CrossRef]
- Sapkota, R.; Qureshi, R.; Flores-Calero, M.; Badgujar, C.; Nepal, U.; Poulose, A.; Zeno, P.; Vaddevolu, U.B.P.; Khan, S.; Shoman, M.; et al. YOLO11 to Its Genesis: A Decadal and Comprehensive Review of The You Only Look Once (YOLO) Series. arXiv 2025, arXiv:2406.19407v5. [Google Scholar]
- Valve Corporation. Steam Hardware Survey 2024. Available online: https://store.steampowered.com/hwsurvey/ (accessed on 15 November 2024).
- Advanced Micro Devices, Inc. AMD RX 7900XT Datasheet. Available online: https://www.amd.com/en/products/graphics/desktops/radeon/7000-series/amd-radeon-rx-7900xt.html (accessed on 11 February 2025).
- Intel Corporation. Intel ARC A750 Graphics Datasheet. Available online: https://www.intel.com/content/www/us/en/products/sku/227954/intel-arc-a750-graphics/specifications.html (accessed on 11 February 2025).
- Nvidia Corporation. Nvidia ADA GPU Architecture Whitepaper, v2.1. Available online: https://images.nvidia.com/aem-dam/Solutions/Data-Center/l4/nvidia-ada-gpu-architecture-whitepaper-v2.1.pdf (accessed on 11 February 2025).
- Advanced Micro Devices, Inc. ROCm Library Compatibility Matrix. Available online: https://rocm.docs.amd.com/en/docs-6.2.2/compatibility/compatibility-matrix.html (accessed on 11 February 2025).
- Nvidia Corporation. CUDA Installation Guide for Linux. Available online: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/ (accessed on 11 February 2025).
- Intel Corporation. Intel ARC A750 Graphics Driver Support. Available online: https://www.intel.com/content/www/us/en/products/sku/227954/intel-arc-a750-graphics/downloads.html (accessed on 11 February 2025).
- Kwack, J.; Tramm, J.R.; Bertoni, C.; Ghadar, Y.; Homerding, B.; Rangel, E.; Knight, C.; Parker, S. Evaluation of Performance Portability of Applications and Mini-Apps across AMD, Intel and NVIDIA GPUs. In Proceedings of the 2021 International Workshop on Performance, Portability and Productivity in HPC (P3HPC), St. Louis, MO, USA, 14 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 45–56. Available online: https://api.semanticscholar.org/CorpusID:245542693 (accessed on 12 February 2025).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019, arXiv:1801.04381v4. [Google Scholar]
- Geetha, A.S. YOLOv4: A Breakthrough in Real-Time Object Detection. arXiv 2025, arXiv:2502.04161v1. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946v5. [Google Scholar]
- Advanced Micro Devices, Inc. AMD System Management Interface (AMD SMI) Library. Available online: https://github.com/ROCm/amdsmi (accessed on 11 February 2025).
- Intel Corporation. Intel XPU Manager and XPU System Management Interface. Available online: https://github.com/intel/xpumanager (accessed on 11 February 2025).
- Nvidia Corporation. Nvidia System Management Interface Program. Available online: https://docs.nvidia.com/deploy/nvidia-smi/index.html (accessed on 11 February 2025).
- Python Software Foundation. Venv–Creation of Virtual Environments. Available online: https://docs.python.org/3/library/venv.html (accessed on 11 February 2025).
- Advanced Micro Devices, Inc. AMD Radeon Product Lineup. Available online: https://www.amd.com/en/products/graphics/desktops/radeon.html#specifications (accessed on 11 February 2025).
- Intel Corporation. Intel Arc A-Series Graphics Product Lineup. Available online: https://www.intel.com/content/www/us/en/products/details/discrete-gpus/arc/arc-a-series/products.html (accessed on 11 February 2025).
- Nvidia Corporation. Nvidia GeForce RTX 40 Series Product Lineup. Available online: https://www.nvidia.com/en-us/geforce/graphics-cards/40-series/ (accessed on 11 February 2025).
- CENEO.PL. Available online: https://www.ceneo.pl/ (accessed on 11 November 2024).
- Scikit-Learn Developers. Frequently Asked Questions. Available online: https://scikit-learn.org/stable/faq.html#will-you-add-gpu-support (accessed on 12 February 2025).
- Numba. Tools for Using AMD ROCm with Numba. Available online: https://github.com/numba/roctools (accessed on 12 February 2025).
- Unified Acceleration Foundation. Bringing Nvidia and AMD Support to oneAPI. Available online: https://oneapi.io/blog/bringing-nvidia-and-amd-support-to-oneapi/ (accessed on 12 February 2025).
- Advanced Micro Devices, Inc. Numba HIP–Repository Providing ROCm HIP Backend for Numba. Available online: https://github.com/ROCm/numba-hip (accessed on 12 February 2025).
- Intel Corporation. Introduction to the Xe-HPG Architecture. Available online: https://cdrdv2-public.intel.com/758302/introduction-to-the-xe-hpg-architecture-white-paper.pdf (accessed on 12 February 2025).
- Intel Corporation. Intel Extension for PyTorch–GPU-Specific Issues. Available online: https://intel.github.io/intel-extension-for-pytorch/xpu/2.1.10+xpu/tutorials/performance_tuning/known_issues.html (accessed on 12 February 2025).
- Intel Corporation. Intel Extension for TensorFlow–Release Notes. Available online: https://github.com/intel/intel-extension-for-tensorflow/releases (accessed on 12 February 2025).
- The Kernel Development Community. GPU Power/Thermal Controls and Monitoring. Available online: https://docs.kernel.org/gpu/amdgpu/thermal.html (accessed on 12 February 2025).
- Intel Corporation. Intel Core Ultra 9 285K Processor Datasheet. Available online: https://www.intel.com/content/www/us/en/products/sku/241060/intel-core-ultra-9-processor-285k-36m-cache-up-to-5-70-ghz/specifications.html (accessed on 12 February 2025).
- Andrae, A.S.G.; Edler, T. On Global Electricity Usage of Communication Technology: Trends to 2030. Challenges 2015, 6, 117–157. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component Type: | Model: |
|---|---|
| Processor | AMD Ryzen 7 5800X3D |
| CPU cooling | Arctic Liquid Freezer 2 360 |
| Motherboard | MSI MPG B550 Gaming Plus |
| RAM | G.Skill AEGIS 3200 CL16 64 GB–4 × 16 GB |
| Disk | Lexar NM790 2TB |
| Power supply | SeaSonic Focus GX 850 ATX 3.0 |
| Case | Be Quiet! Silent Base 802 |
| Chip Manufacturer: | AMD | Intel | Nvidia |
|---|---|---|---|
| Model name | ASRock Radeon RX 7900XT Phantom Gaming | Intel ARC A750 8 GB Limited Editon | ASUS TUF Gaming GeForce RTX 4090 |
| Chip name | Navi 31 XT | DG2-512 | AD102-300-A1 |
| Architecture | RDNA 3.0 | Xe HPG | Ada Lovelace |
| Number of computer units | 84 (computer units) 5376 (stream processors) | 28 (Xe cores) 448 (Xe vector engines) | 128 (streaming multiprocessors) 16384 (CUDA cores) |
| Number of dedicated AI computer units | 168 (AI accelerators) | 448 (XMX engines) | 512 (Tensor cores) |
| VRAM | 20 GB GDDR6 320 bit | 8 GB GDDR6 256 bit | 24 GB GDDR6X 384 bit |
| VRAM bandwidth | 800 GB/s | 512 GB/s | 1008 GB/s |
| Typical board power (TBP) | 315 W | 225 W | 450 W |
| AMD | Intel | Nvidia | |
|---|---|---|---|
| Graphics driver version | 6.8.5 | 2:2.99.917 | 550.107.02 |
| Framework for running calculations on the GPU | HIP 6.2.41134 | OneAPI 2024.2.1 | CUDA Toolkit 12.4 |
| AI library | ROCm 6.2.2 | OpenVINO 2024.4.0 | CuDNN 8.9.7 |
| AMD | Intel | Nvidia | |
|---|---|---|---|
| ONNX runtime | onnxruntime-rocm 1.19.0 | onnxruntime-openvino 1.19.0 | onnxruntime-gpu 1.19.0 |
| OpenCV | 4.10.0 built with OpenCL 1.2 | 4.10.0 built with OpenVINO 2024.4.0 | 4.10.0 built with CUDA 12.4 & cuDNN 8.9.7 |
| Tensorflow | tensorflow-rocm 2.15.0 | tensorflow 2.15.0 | tensorflow 2.15.0 |
| PyTorch | torch 2.3.0 + rocm6.2.3 | torch 2.3.0 + cxx11.abi | torch 2.3.0 |
| Point Scale | Degree of Compatibility |
|---|---|
| 2 | Full graphics card compatibility is ensured. It was possible to run calculations using hardware acceleration, and no significant usability limitations resulting from the graphics card used were found. |
| 1 | Compatibility is ensured, and it is possible to run calculations using hardware acceleration. Significant limitations in the functionality of a given framework using a given graphics card were found. |
| 0 | It is not compatible with a given GPU, so there is no possibility of running calculations using a framework with hardware acceleration. |
| AMD | Intel | Nvidia | |
|---|---|---|---|
| Pytorch | 2 | 1 | 2 |
| Tensorflow | 2 | 1 | 2 |
| JAX | 2 | 1 | 2 |
| SciKit | 0 | 1 | 2 |
| ONNX | 2 | 1 | 2 |
| OpenCV | 2 | 1 | 2 |
| Numba | 1 | 1 | 2 |
| AMD | Intel | Nvidia | |
|---|---|---|---|
| Power [W] | 13.25 | 33.87 | 5.38 |
| AMD | Intel | Nvidia | AMD | Intel | Nvidia | ||||
|---|---|---|---|---|---|---|---|---|---|
| T [s] | P [W] | T [s] | P [W] | T [S] | P [W] | E [ep/kJ] | E [ep/kJ] | E [ep/kJ] | |
| YOLO 11 PyTorch | 45.33 | 256.50 | 148.03 | 99.64 | 13.33 | 200.02 | 0.09 | 0.07 | 0.37 |
| ResNet50 PyTorch | 129.79 | 259.88 | 912.41 | 105.96 | 54.71 | 305.33 | 0.03 | 0.01 | 0.06 |
| MobileNetV2 Tensorflow | 9.84 | 229.80 | 47.90 | 98.67 | 3.30 | 262.65 | 0.44 | 0.21 | 1.15 |
| ResNet50 Tensorflow | 2.90 | 245.08 | 13.40 | 107.46 | 0.89 | 351.95 | 1.41 | 0.69 | 3.19 |
| AMD | Intel | Nvidia | AMD | Intel | Nvidia | ||||
|---|---|---|---|---|---|---|---|---|---|
| T [ms] | P [W] | T [ms] | P [W] | T [ms] | P [W] | E [im/kJ] | E [im/kJ] | E [im/kJ] | |
| YOLO 11 PyTorch | 8.42 | 243.43 | 19.99 | 106.17 | 6.62 | 118.00 | 487.98 | 471.25 | 1279.52 |
| ResNet50 PyTorch | 5.10 | 193.44 | 11.41 | 97.57 | 4.01 | 84.92 | 1014.09 | 898.14 | 2938.52 |
| MobileNetV2 Tensorflow | 36.91 | 36.16 | 40.74 | 56.28 | 38.88 | 60.34 | 749.19 | 436.11 | 426.21 |
| ResNet50 Tensorflow | 40.13 | 32.98 | 44.68 | 60.60 | 41.29 | 46.54 | 755.70 | 369.31 | 520.43 |
| YOLO 11 ONNX | 8.18 | 248.33 | 15.61 | 77.63 | 5.68 | 103.00 | 492.14 | 825.01 | 1710.56 |
| ResNet50 ONNX | 3.29 | 267.27 | 10.27 | 80.86 | 2.67 | 151.73 | 1137.19 | 120.69 | 2468.07 |
| YOLO v4 OpenCV | 605.62 | 235.14 | 110.08 | 80.52 | 34.59 | 313.50 | 7.22 | 112.81 | 92.22 |
| EfficientNet B0 OpenCV | 274.75 | 98.42 | 3.35 | 71.66 | 1.48 | 100.00 | 36.98 | 4159.85 | 6773.51 |
| Model | Price [PLN] | VRAM [GB] | AI Compute Units | TGP [W] |
|---|---|---|---|---|
| AMD: Acer Predator BiFrost Radeon RX 7600 | 1049 | 8 | 64 (AI cores) | 165 |
| Intel: ASRock Intel ARC A310 Low Profile | 415 | 4 | 96 (XMX Engines) | 75 |
| Nvidia: MSI GeForce RTX 4060 Ventus 2X Black | 1257 | 8 | 96 (Tensor Cores) | 115 |
| Normalized Performance | Weight | Weighted Performance | |||||
|---|---|---|---|---|---|---|---|
| AMD | Intel | Nvidia | AMD | Intel | Nvidia | ||
| Compatibility | |||||||
| Pytorch | 1.00 | 0.50 | 1.00 | 4.00 | 4.00 | 2.00 | 4.00 |
| Tensorflow | 1.00 | 0.50 | 1.00 | 4.00 | 4.00 | 2.00 | 4.00 |
| JAX | 1.00 | 0.50 | 1.00 | 4.00 | 4.00 | 2.00 | 4.00 |
| SciKit | 0.00 | 0.50 | 1.00 | 4.00 | 0.00 | 2.00 | 4.00 |
| ONNX | 1.00 | 0.50 | 1.00 | 4.00 | 4.00 | 2.00 | 4.00 |
| Opencv | 1.00 | 0.50 | 1.00 | 4.00 | 4.00 | 2.00 | 4.00 |
| Numba | 0.50 | 0.50 | 1.00 | 4.00 | 2.00 | 2.00 | 4.00 |
| Idle Power Draw | 0.41 | 0.16 | 1.00 | 8.00 | 3.25 | 1.27 | 8.00 |
| Training Energy Efficiency | |||||||
| YOLO 11 PyTorch | 0.24 | 0.19 | 1.00 | 6.00 | 1.46 | 1.14 | 6.00 |
| ResNet50 PyTorch | 0.50 | 0.17 | 1.00 | 6.00 | 3.00 | 1.00 | 6.00 |
| MobileNetV2 TensorFlow | 0.38 | 0.18 | 1.00 | 6.00 | 2.30 | 1.10 | 6.00 |
| ResNet50 TensorFlow | 0.44 | 0.22 | 1.00 | 6.00 | 2.65 | 1.30 | 6.00 |
| Inference Energy Efficiency | |||||||
| YOLO 11 PyTorch | 0.38 | 0.37 | 1.00 | 4.00 | 1.53 | 1.47 | 4.00 |
| ResNet50 PyTorch | 0.35 | 0.31 | 1.00 | 4.00 | 1.38 | 1.22 | 4.00 |
| MobileNetV2 Tensorflow | 1.00 | 0.58 | 0.57 | 4.00 | 4.00 | 2.33 | 2.28 |
| ResNet50 Tensorflow | 1.00 | 0.49 | 0.69 | 4.00 | 4.00 | 1.95 | 2.75 |
| YOLO 11 ONNX | 0.29 | 0.48 | 1.00 | 4.00 | 1.15 | 1.93 | 4.00 |
| ResNet50 ONNX | 0.46 | 0.05 | 1.00 | 4.00 | 1.84 | 0.20 | 4.00 |
| YOLO v4 OpenCV | 0.06 | 1.00 | 0.82 | 4.00 | 0.26 | 4.00 | 3.27 |
| EfficientNet B0 OpenCV | 0.01 | 0.61 | 1.00 | 4.00 | 0.02 | 2.46 | 4.00 |
| Technology Entry Threshold | 0.40 | 1.00 | 0.33 | 8.00 | 3.16 | 8.00 | 2.64 |
| Total: | 52.00 | 43.36 | 90.94 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adamski, P.; Lubczonek, J. A Comparative Analysis of the Usability of Consumer Graphics Cards for Deep Learning in the Aspects of Inland Navigational Signs Detection for Vision Systems. Appl. Sci. 2025, 15, 5142. https://doi.org/10.3390/app15095142
Adamski P, Lubczonek J. A Comparative Analysis of the Usability of Consumer Graphics Cards for Deep Learning in the Aspects of Inland Navigational Signs Detection for Vision Systems. Applied Sciences. 2025; 15(9):5142. https://doi.org/10.3390/app15095142
Chicago/Turabian StyleAdamski, Pawel, and Jacek Lubczonek. 2025. "A Comparative Analysis of the Usability of Consumer Graphics Cards for Deep Learning in the Aspects of Inland Navigational Signs Detection for Vision Systems" Applied Sciences 15, no. 9: 5142. https://doi.org/10.3390/app15095142
APA StyleAdamski, P., & Lubczonek, J. (2025). A Comparative Analysis of the Usability of Consumer Graphics Cards for Deep Learning in the Aspects of Inland Navigational Signs Detection for Vision Systems. Applied Sciences, 15(9), 5142. https://doi.org/10.3390/app15095142