1. Introduction
Strengthening the education of couplet culture can help preserve traditional Chinese culture and improve students’ language abilities and esthetic standards while also fostering social cohesion and promoting the international dissemination of Chinese culture. The Chinese couplet, composed of a pair of two sentences (i.e., an antecedent and a subsequent clause), is a classical literary form that has been prevalent in China for over a thousand years. This enduring tradition is rooted in deep cultural reasons and, in turn, reflects various aspects of Chinese traditional culture.
However, creating a couplet is a challenging task. First, in terms of form, couplets are characterized by their dueling pattern, where the antecedent and subsequent clauses must correspond one-to-one and adhere to strict rules across multiple dimensions, including tone, length, word usage, and even syntax. Second, in terms of content, couplets are short but highly expressive, conveying the author’s thoughts, emotions, or various meanings within a limited number of words. These characteristics make personalized couplet creation particularly difficult, typically achievable only by couplet experts. As a result, the number of young people interested in couplets has been steadily decreasing, and in some cases, has been maintained at a very small quantity. A survey of Chinese primary school students shows that 90% of them cannot even distinguish between upper and lower couplets, let alone create couplets [
1]. Therefore, personalized Chinese couplet (PCc) generation holds significant practical value and poses a considerable challenge, especially for the education and transmission of Chinese traditional culture.
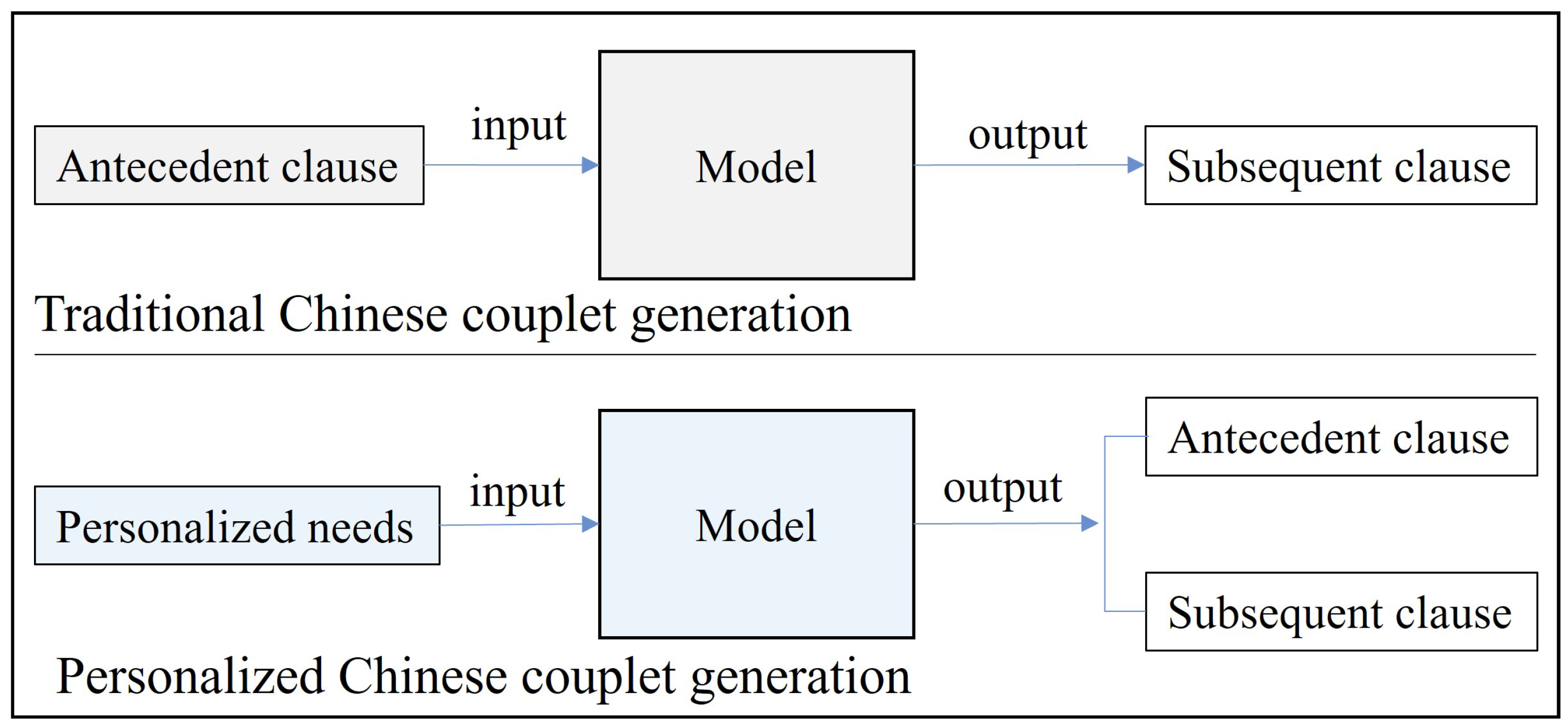
Current research on the Chinese couplet generation is predominantly non-personalized, lacking engagement and appeal. The difference between the traditional Chinese couplet generation and the PCc generation can be described in
Figure 1. The most common paradigm of traditional couplet generation adopts an encoder–decoder neural network architecture [
2,
3], framing the task as a Sequence-to-Sequence problem where the subsequent clause is generated based on the antecedent clause. Recently, most studies have leveraged attention mechanisms and Transformer architectures [
4] to capture the correspondence between the antecedent and subsequent clauses [
5,
6]. Additionally, some researchers have introduced fine-grained syntactic information or auxiliary data to enhance the quality of generated couplets [
7,
8]. While these approaches have achieved satisfactory results in the traditional couplet generation, they are limited in their ability to personalize the couplets and can only generate a subsequent clause in an end-to-end manner based on the antecedent clause. On the one hand, the end-to-end nature of these methods limits their practical application. High-quality antecedent clauses are typically only available in curated datasets or written by couplet experts. Ordinary users often lack the ability to create suitable antecedent clauses, which makes traditional couplet generation methods impractical for educational purposes. On the other hand, the inability to personalize the couplets—such as controlling their form and content—results in low user engagement and reduces the practical value of the generated couplets. This erosion of creative motivation directly conflicts with the couplets’ core esthetic and literary principles. The resulting participation deficit creates substantial barriers to community participation and cultural transmission.
When evaluating the quality of Chinese couplets, it is essential to balance both literary creativity and linguistic accuracy. Currently, there are two main types of methods used to assess the results of couplet generation. The first type involves automated metrics, such as BLEU [
9] and perplexity scores [
10]. However, BLEU, being based on text similarity, requires a ground truth to compute its score. In the personalized couplet generation, there is no real “truth” since multiple creative couplets can be generated based on the same personalized constraints. Similarly, perplexity scores face the same issue. Since the personalized couplet generation emphasizes cultural creativity and artistic expression, it lacks a single standard answer. Therefore, these automated metrics are not suitable for evaluating personalized couplets. The second type of method involves human evaluation, where a set of predefined criteria is used to rate the generated couplets. While this method can accurately reflect human subjective perception, it has the drawback of having varying results due to individual biases. Furthermore, this approach is time consuming and labor intensive, making it difficult to implement at scale. To the best of our knowledge, previous methods struggle to address the challenges associated with PCc generation and evaluation effectively.
The emergence of Large Language Models (LLMs) has provided new insights for addressing these challenges. Compared to other methods, LLMs have acquired richer knowledge and can understand context. This linguistic comprehension capability is unique and critically important. Especially in artistic creation tasks such as PCcG, other methods (e.g., rule-based systems) can perform well in linguistic structural tasks, but they often lack artistic creativity and flexibility [
11]. Since the introduction of Transformer in 2017, the field of NLP has undergone a significant transformation, with LLMs rising to prominence and becoming a central focus of research. From then on, the pre-training paradigm has gained traction, with BERT [
12] enhancing contextual understanding through masked language modeling, while GPT-3 [
13] demonstrated remarkable capabilities in few-shot and zero-shot learning. After 2020, the continuous expansion of model scale led to improved performance, accompanied by an explosive growth in related products, such as the Qwen series [
14] and the Llama series [
15]. In 2023, the release of GPT-4 [
16] marked a milestone achievement. Through iterative technological advancements and dataset updates, it acquired multimodal capabilities, the ability to process longer contexts, and enhanced safety. Reports indicate that it achieved human-competitive performance across numerous professional and academic benchmarks. By the end of 2024, DeepSeek-V3 [
17] was released. Leveraging the Mixture-of-Experts (MoE) architecture, Multi-head Latent Attention (MLA), and a pioneering auxiliary-loss-free strategy for load balancing, it achieved state-of-the-art performance while significantly reducing training time and inference costs. With advancements in multimodal technology and other innovations, the capabilities of large models are expected to improve further.
In this paper, we propose a personalized Chinese couplet generation and evaluation (PCcGE) framework centered around LLMs. Specifically, we first utilize the Retrieval-Augmented Generation (RAG) [
18] method and design a prompt through prompt engineering to guide the LLM in generating grammatically correct couplets. Second, since there is currently no PCc generation dataset available for fine-tuning LLMs, we construct a custom dataset and employ the Low-Rank Adaptation (LoRA) [
19] method to perform Supervised Fine-Tuning (SFT) on the base model, ensuring that the LLM generates high-quality couplets. Finally, to evaluate the quality of the generated PCcs, we design an LLM-based evaluation scheme, which leverages the LLM’s exceptional language understanding capabilities to produce meaningful and relevant couplet assessments. In our experiments, through comparative analysis and case studies, we demonstrate that our approach can successfully generate personalized Chinese couplets that meet the given requirements and evaluate them effectively. Furthermore, the quality of the generated couplets surpasses that of the base model, exhibiting greater artistic, innovative, and practical value while enhancing user engagement in the couplet creation process. The contributions of this paper are as follows:
A custom dataset tailored for the task of PCc generation is built, and a Chinese couplet generation model is trained.
A framework for PCc generation and evaluation using LLMs is developed, and its effectiveness is validated through experiments. The results show that a 7B model with our generation framework can be compared to the latest DeepSeek-V3 (671B) and ChatGPT-4-turbo (v.2024-04-09).
Through user study, the advantages and limitations of the PCcGE framework is summarized in terms of practicality, effectiveness, and appeal. Additionally, we captured qualitative perspectives from different user groups regarding the current state of couplet creation and the role of PCcGE.
3. The Proposed Framework
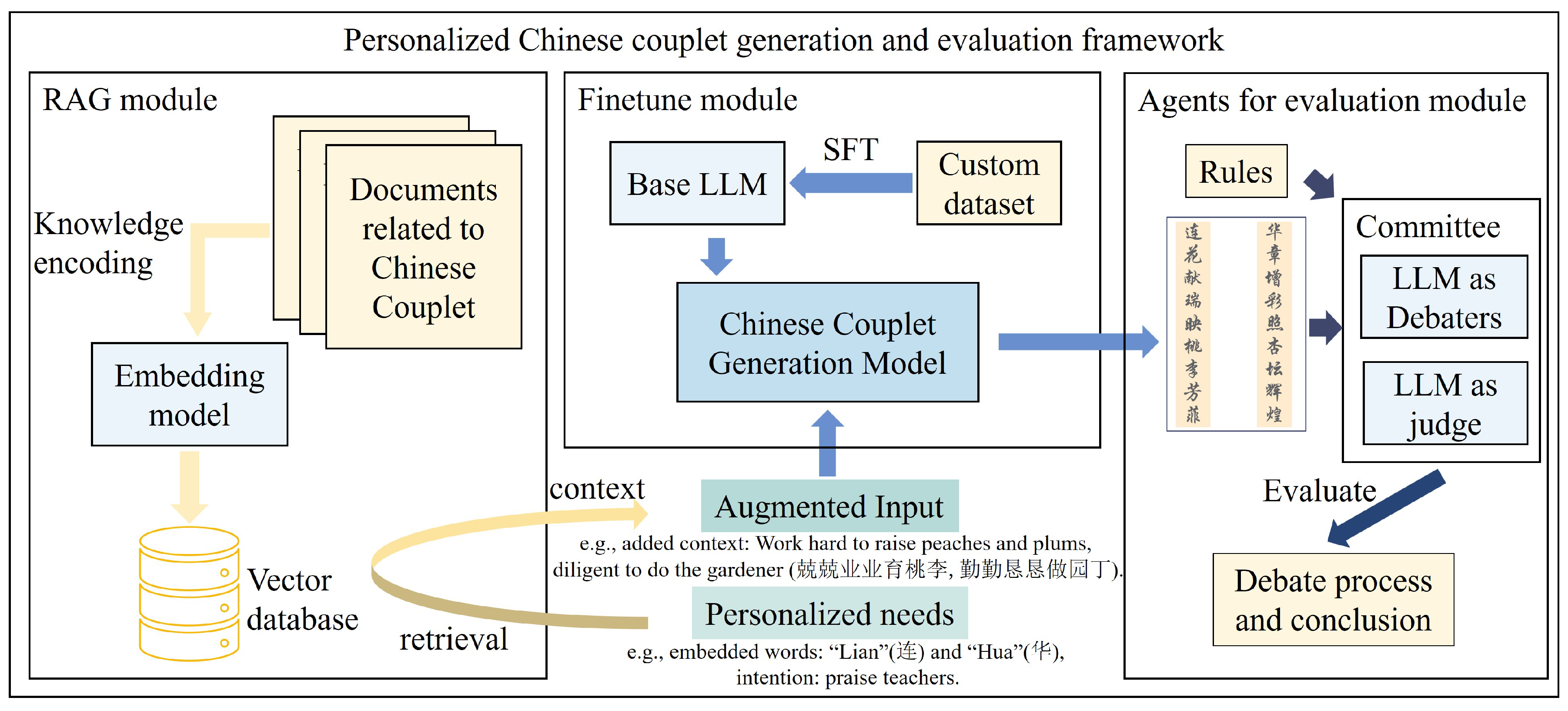
To generate Chinese couplets that meet specific personalized needs and evaluate their quality, we propose a framework centered on LLMs.
Figure 2 illustrates the overall architecture of our framework. In general, the workflow is as follows: First, the user provides personalized needs, which in this study include embedded words (i.e., specific characters that must appear in the antecedent and subsequent clauses) and specified creative intent (i.e., the expected meaning or theme of the couplet). Second, using an RAG approach, the framework retrieves the most relevant couplet example from a database based on personalized needs. Third, the personalized needs and the retrieved example are combined into a prompt, which is fed into a Chinese couplet generation model (SFT-enhanced) to generate the final couplet. Finally, a judge committee composed of LLMs evaluates the generated couplets based on predefined external rules. In the following sections, we provide a detailed explanation of each component of the framework.
3.1. RAG Module for Guiding
In terms of structure, while Chinese couplets exhibit symmetry between the antecedent and subsequent clauses, traditional couplet generation methods are rarely troubled by basic structural issues. This is because neural network models can directly mimic the structure of the antecedent clause when generating the subsequent clause, ensuring consistency in character count and structural similarity. However, in the PCcG task, no antecedent clause is provided, which increases the likelihood of generating couplets with structural errors or even violating the fundamental characteristics of couplets.
To address this issue, we guide the model to adhere to the fundamental structural features of couplets using an example-based approach. The specific steps are as follows: first, data collection is performed. We gather a large corpus of couplets to build a Chinese couplet example database, where each entry consists of a complete couplet, with the antecedent and subsequent clauses separated by a space. The resulting database is where represents a complete couplet.
Second, an example is retrieved and provided. A well-chosen example not only offers structural guidance but also provides content-related inspiration during PCcG. To retrieve an optimal example, we use the personalized needs as a query. Employing a RAG method, we search the database for the most relevant entry based on vector similarity, selecting it as the example. The retrieval mechanism is as follows. We employ the same embedding model, which transforms sentences into fixed-length dense vectors (i.e., embeddings) that capture their semantic meaning, to encode both the query and all couplets in the database into a shared vector space. In this space, the distance between vectors reflects the semantic relevance between the query and each candidate couplet. By computing these distances, we can assess the relevance of each couplet to the query. The couplet with the highest relevance is then selected as the retrieval result. The final retrieved example,
, can be represented as follows:
where
represents the similarity between the input requirement
p and the data
.
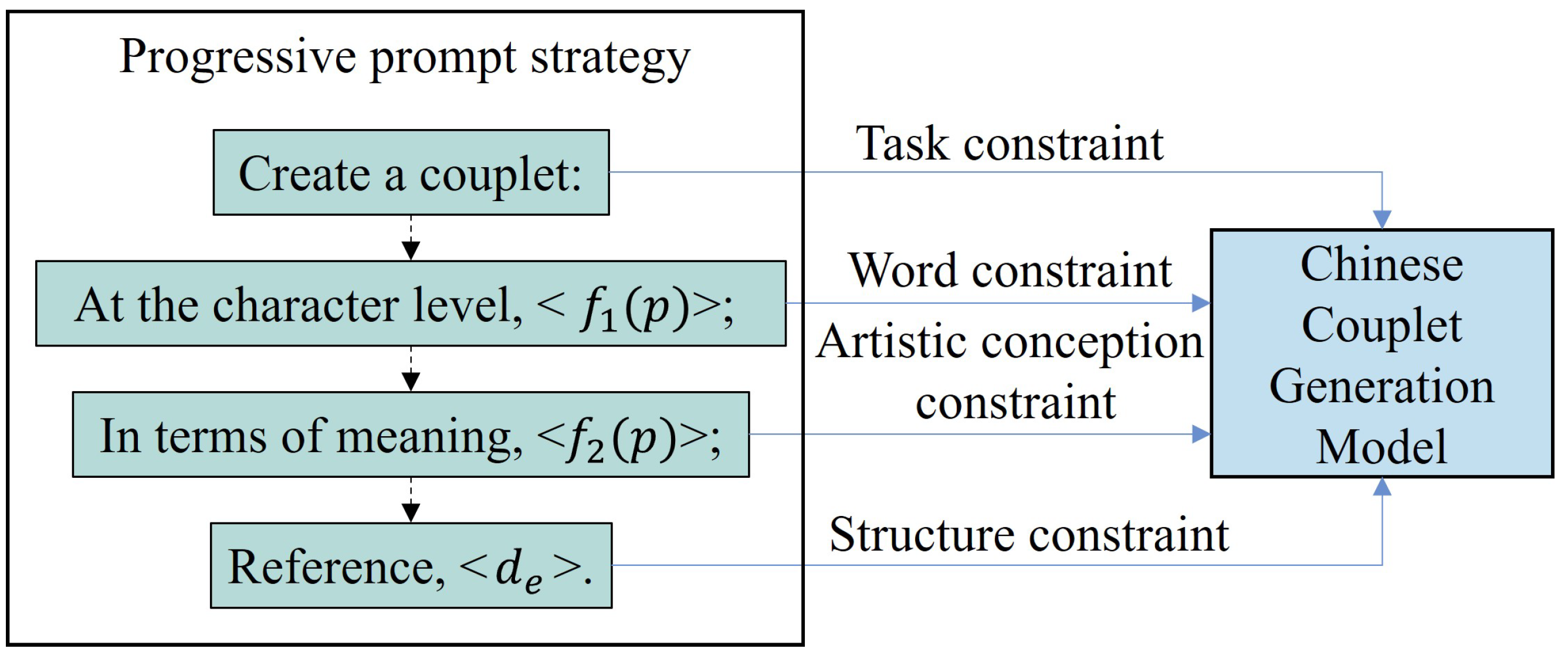
Third, the example is integrated into the prompt. The retrieved example is incorporated as context into the prompt, along with the personalized needs, forming an augmented input. To achieve this, we design a progressive prompt strategy, as shown in
Figure 3, which uses a series of increasingly detailed instructions to guide couplet generation. It leverages prompt engineering principles to guide the model through hierarchical generation of PCc, progressing incrementally from lexical-level to sentence-structure-level constraints. Concurrently, during model fine-tuning, we reinforce the model’s adherence to prompt specifications. This dual approach significantly enhances the model’s capability to accomplish the PCcG task. The structure of the prompt is as follows:
Create a couplet: At the character level, <>; In terms of meaning, <>; Reference, <>.
Where the
and
represent the related personalized features extracted from
p.
Figure 3.
Illustration of progressive prompt strategy. The RAG is always used to provide related context for generating an answer; however, here, we use RAG not to provide a context, but to find a reference couplet to guide the model to follow the norms and structure of couplets, which enhances the formal correctness and structural diversity of couplets.
Figure 3.
Illustration of progressive prompt strategy. The RAG is always used to provide related context for generating an answer; however, here, we use RAG not to provide a context, but to find a reference couplet to guide the model to follow the norms and structure of couplets, which enhances the formal correctness and structural diversity of couplets.
3.2. Chinese Couplet Generation Model
Pre-trained LLMs demonstrate strong language understanding capabilities, enabling them to perform well across a wide range of NLP tasks. However, for specialized tasks with unique requirements, such as PCcG, their performance is often suboptimal. A common solution to this problem is supervised fine-tuning (SFT), which involves refining the model using a task-specific dataset. However, SFT for LLMs requires a dataset in a conversational format, which differs from traditional end-to-end neural network datasets. This discrepancy means that no existing dataset is directly suitable for PCcG.
To address this gap, we first constructed a PCcG dataset that incorporates embedded words and specified creative intent. We then used this dataset to SFT the base model. For dataset construction, we proposed a method to transform traditional couplet datasets into a conversational format. First, data collection: We utilized the large corpus of couplets in the RAG module’s database as the source data.
Second, designing a dialogue template: Since conversational training data are required, we designed a dialogue template. The structure of this template is as follows:
User: Create a couplet: At the character level, <>; In terms of meaning, <>; Reference, <>.
LLM: <original Chinese couplet>.
Where we populate the and slots with personalized needs, including detailed embedded words and overall creative intent. The slot is filled with the example retrieved through RAG, while the original couplet is used as the response.
Third, extracting embedded words. Since embedded words can appear in any position within the couplet and are not necessarily placed symmetrically, we design a method to randomly select one word each from the antecedent and subsequent clauses of a cleaned couplet (with all punctuation removed) as the embedded words.
Fourth, obtaining creative intent. As it is impractical to have experts manually analyze the creative intent of a large corpus of couplets, we use an LLM as an analysis agent to infer creative intent automatically. The process of deriving the creative intent for each couplet is as follows. Instead of directly prompting the model to produce the creative intent, we first guide it to conduct a holistic analysis of the couplet. The initial prompt used is as follows: “Analyze all aspects of the couplet, which must include the creative intention and provide the result”. For each couplet, we repeat this analysis three times independently using the same prompt. Then, we use the following integration prompt: “Integrated multiple analysis results summarize the creative intention of the couplet” to let the model summarize the creative intent based on the previously generated analyses. In terms of implementation, we developed a loop function that automates this process for each couplet. The content of each prompt is dynamically filled with the target couplet and the corresponding multiple analysis results. Our overall idea is to allow the model to generate multiple interpretations and then synthesize them into a more stable and consistent creative intent. This approach reduces randomness and enhances consistency to some extent.
Finally, the processed data are populated into the template and converted into a conversational format. Additionally, when training the base model, we employ the LoRA method. Specifically, suppose the weight matrix of each layer of the chosen LLM is denoted as W. LoRA introduces low-rank matrices A and B to update W as follows:
During the training process, LoRA only updates the matrices
A and
B. Its training process can be expressed as follows:
where
is the cross-entropy loss function and
and
are regularization terms for the increment matrices, using the Frobenius norm to prevent overfitting.
Next, we will prove the effect of the Frobenius norm. Let
denote the linear transformation of the incremental parameters in the network. The Lipschitz constant of the transformation is determined by the largest singular value of the matrix, denoted as follows:
By the definition of the Frobenius norm, we have the following:
By the properties of matrix norms, we obtain the following:
As the regularization term in the loss function is denoted by
, and the optimization process minimizes the loss, this term will eventually be bounded above by a constant
K that depends on
; that is,
Combining the arithmetic-geometric mean inequality and Equation (
7), we obtain the following:
According to Equations (
6) and (
8), it follows that
Based on Equations (
4), (
5) and (
9), we obtain the following:
This proves that by constraining the Frobenius norms of
A and
B, we indirectly bound the maximum singular value of
, thereby controlling the Lipschitz constant of the layer transformation.
Full-parameter fine-tuning often risks overwriting the model’s pre-existing knowledge, which can degrade its foundational performance. In contrast, LoRA only requires training on incremental parameter matrices, allowing the model’s base performance to remain intact while enhancing its capability in the PCcG task.
3.3. Agent Debate for Evaluating
In traditional couplet generation tasks, the goal is merely to generate a subsequent clause based on a given antecedent clause. So, they can use the existing subsequent clauses as ground truth in the dataset to calculate metrics like BLEU and perplexity scores. Additionally, human evaluation is often employed, assessing the syntactic and semantic alignment of antecedent and subsequent clauses based on their structural patterns and meanings, respectively. However, in the task of PCcG, no ground truth exists, since it is an open question. Human evaluation is prone to subjective bias and is difficult to implement effectively.
Inspired by the Multi-Agent Debate (MAD) framework [
41] that leverages debate, a fundamental characteristic of human problem solving, to encourage divergent thinking in LLMs, in this study, we extend MAD and use external evaluation rules to analyze and evaluate the couplets. This approach not only meets the creativity demands of this task but also avoids the biases inherent in human evaluation, offering a more objective and valuable assessment.
Our debate process can be represented by
Figure 4. First, we set multiple LLMs as debater agents and one LLM as a judge agent to form a committee. Second, we set the rules depending on the evaluation goal. If we want to obtain a more valuable debate and analysis process, we will set the rules as “Comparing two couplets, tit for tat, objective, and give reasons”. Third, deciding which couplet is better is relative. We provide two couplets. Then, different aspects of them will be evaluated by a specific debater through a comparative method, and the judge will consider all the debater’s arguments and conclude.
Specifically, in the debate process, all debaters participate in the discussion of a specific aspect of the couplets. The LLM assigned to that aspect initiates the topic, after which all LLMs take turns to present their viewpoints. Finally, the initiating LLM is responsible for summarizing the strengths and weaknesses of the couplets concerning that specific aspect. It is important to note that the summary is comparative and limited to the assigned aspect only. Once all aspect-specific summaries are completed, the role of the judge is to integrate the information provided by all debaters and generate a final overall assessment. The more intense and comprehensive the debate, the more informative the process becomes, thereby offering stronger support for the judge’s final decision. This multi-perspective debate and summarization framework helps to enhance both the accuracy and consistency of the final evaluation. The prompt for debaters is as follows:
Please compare and analyze the advantages and disadvantages of the following two couplets in terms of <aspect>: <couplet1>, <couplet2>, and give reasons.
where the <
> is the evaluation direction that the LLM is responsible for. The prompt for the judge is as follow:
<debaters’ output>. Please synthesize the above opinions and give a conclusion indicating which couplet is better.
where the <
debaters’ output> is the output of all debaters.
4. Experiment and Result
4.1. Experimental Design
The experiment consists of four parts. First part: To evaluate the effectiveness of the PCc generation method, we designed a controlled experiment with two groups. The first group uses a 7B parameter base model without our framework, the second group uses the same base model but with our proposed framework, and the third group uses two of the latest models, DeepSeek-V3 (671B) and GPT-4-turbo, without our framework. We performed a comparative analysis to assess the effectiveness of our method under identical personalized needs. For the prompt, we use the same base prompt mentioned in
Section 3.1 to generate couplets with all models. The difference is that our framework utilizes the RAG module to guide the model, so in the prompt,
will be filled.
Second part: This part aims to validate the effectiveness of our evaluation method and further demonstrate our generation approach. We conduct a controlled experiment by selecting the couplets generated in the first part and then evaluating them using our agent debate method.
Third part: To quantitatively analyze and prove that the quality of couplets generated by our method is optimal, we conducted a questionnaire survey and performed Analysis of Variance (ANOVA) and LSD (Least Significant Difference) post facto tests according to the statistical data.
Fourth part: In addition to validating the method’s practicability and effectiveness, we also explore its role in couplet education. We first developed a user-friendly system based on our framework. Subsequently, we recruited participants and asked them to use the system to generate couplets based on their needs. Finally, participants were asked to provide their opinions on the generation process and feedback on the quality of the generated couplets.
4.2. Implementation Details
We run all experiments on a single Tesla T4 GPU. In the RAG module, we select jina-embeddings-v2-base-zh [
42] as the text embedding model and use cosine similarity to measure the similarity between the query and sentence vectors in the database. In the fine-tuning module, we use Unsloth to perform SFT on Qwen2.5-7B [
43], with the parameter settings shown in
Table 1. The training process employs LoRA, and its parameter settings are presented in
Table 2. The dataset contains about 742 k entries, each formatted as a standard GPT-style conversation. We sampled 300 k items from the dataset to fine-tune our model.
4.3. Couplet Generation
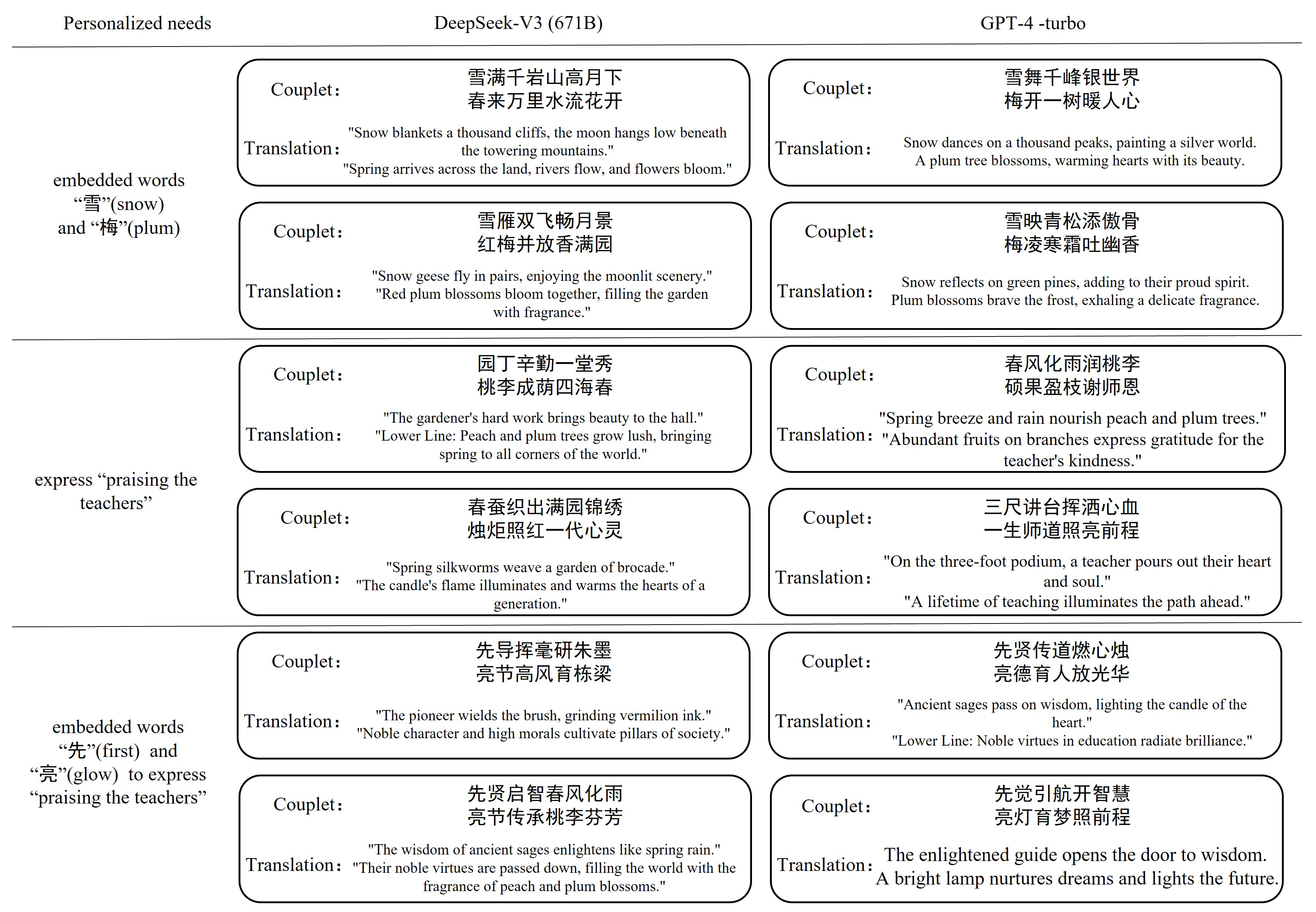
In the PCcG framework, we have constructed a progressive prompt that requires only the input of personalized needs, such as the embedded words or the creative intent of the couplet, following the specified format. To evaluate the framework, we created various combinations of personalized needs and generated three pairs of couplets under each combination using different methods.
Figure 5 presents the results between the base model and our framework.
Figure 6 presents the results of the two latest models under the same conditions.
Compared to other models, our approach demonstrates greater flexibility and appropriateness in handling embedded words. The couplets generated by other models tend to embed the specified words in the same position in both clauses, often placing them as the first word of each clause. This pattern is unreasonable. We hypothesize that the base model’s logic for generating couplets with embedded words is as follows: it takes the given words, places them as the first word of the antecedent and subsequent clauses, and then generates the rest of the couplet by inferring forward. This process aligns with the Next Sentence Prediction (NSP) task used during the model’s training. While the base model technically fulfills the needs of embedded words, it inadvertently adds an implicit constraint that the embedded words must appear in the first position, significantly limiting the diversity of the couplets and failing to meet practical needs. In contrast, our model avoids this issue, allowing embedded words to appear in various positions, which better aligns with real-world requirements. For example, in
Figure 5 and
Figure 6, when the personalized need is “embedded words 雪 (snow) and 梅 (plum)”, all methods place these words in the first of the two clauses and each clause just consists of a single part, except for ours, which places the words more flexibly (i.e., in the middle of the couplet) and each clause can be made up of three parts. It is more flexible, complex, and elegant.
In terms of creative intent personalization, our model exhibits greater diversity in both word choice and sentence structure, aligning more closely with the creative essence of couplet composition. Observations reveal that the couplets generated by the base model exhibit high redundancy in word choice, often repeating words like “春” (spring) in the antecedent clauses. The sentence structures are also monotonous, typically producing simple couplets without punctuation. We hypothesize that this is due to the base model’s lack of specialized knowledge about couplet structures, causing it to favor common and straightforward patterns. While the couplets generated by the base model satisfy the creative intent requirements on a basic level, they lack the artistic diversity and creativity essential for couplet composition. In contrast, our approach generates a more diverse vocabulary and demonstrates greater creativity in sentence structures.
Overall, our model outperforms the base model in both embedded words and creative intent personalization. It not only satisfies the specified personalized needs but also generates higher quality couplets. Observations show that our model incorporates more advanced couplet composition techniques, such as numerical symmetry, where “一” (one) corresponds to “万” (ten thousand), and personification, where “春作赋” means that spring writes verse. Conversely, other models continue to struggle with issues related to the appropriateness of embedded word placement and the lack of creativity, as mentioned earlier.
In summary, when using our framework for PCcG, the couplets not only fulfill personalized needs but also demonstrate enhanced artistry and creativity. Moreover, we outperform the latest models, which require tens of times more hardware resources.
4.4. Couplet Evaluation
In couplet evaluation, we present empirical results using Qwen2.5-72B, Llama-3-70B, DeepSeek-V3, and GPT-3.5 as the debaters and DeepSeek-R1 as the judge. All LLMs are called by the official API. Each debater participates in the debate across all aspects but is responsible for summarizing only one specific aspect. This assignment follows the same order as shown in
Figure 7. For example, Qwen2.5-72B is responsible for the artistic conception aspect and is marked as Debater 1 accordingly.
By observing the reasoning process of the agents in
Figure 7, we find that the analysis is well-structured and supported by logical arguments, making it highly informative and valuable. This demonstrates the effectiveness of our evaluation method. The agent’s coherent reasoning ensures that its conclusions are highly reliable. Furthermore, in the empirical cases above, the agent’s reasoning results provide additional evidence for the effectiveness of our personalized couplet generation method. For example, in debate2’s response, it presents the debaters’ analytical conclusions regarding clauses’ structure and grammatical frameworks, including a systematic evaluation of each couplet’s strengths and limitations. It gives the reason why the second couplet is better with explanations down to the word. This makes the analysis results more readable and logical.
This approach enables a more equitable analysis and comparison, thereby enhancing the creators’ comprehension of couplets. By synthesizing multi-agent evaluations from diverse perspectives, the method yields more reliable results. Moreover, the textual debate process offers greater pedagogical value than a mere numerical score, serving as a valuable reference for learning and secondary creation.
4.5. Quantitative Analysis
To quantitatively test whether there are significant differences in quality between couplets generated by the four methods, we conducted an ANOVA. We distributed 70 online questionnaires, which contained six of the same questions but with different couplets. The initial task was written as follows: “Please refer to the personalized needs and rank the couplets in descending order of quality”. Since each set of couplets is generated using four different methods, corresponding scores of 4, 3, 2, and 1 were assigned (where 4 represents the highest quality and 1 the lowest).
A total of 57 questionnaires were collected, with 50 valid responses in the final analysis after screening. The result is shown in
Table 3. In the table, the row means the couplet and the average score, the column means generating methods. For the others, we mark ’base model’ as M1, ’base model + ours’ as M2, ’DeepSeek-V3’ as M3, and ’GPT-4-turbo’ as M4. For the couplets, we identify the generated couplets as CE1, CE2, CI1, CI2, CEI1, and CEI2 in the order of each line in
Figure 5 and
Figure 6.
The significance level is set at 0.05. We first conducted a homogeneity of variance test, which yielded a significance level of 0.583 (p > 0.05). This result indicates that the data satisfy the assumption of homogeneity of variance, allowing for the application of one-way analysis of variance (ANOVA).
The ANOVA results demonstrated a highly significant difference among groups (F = 12.261, p < 0.001), suggesting that the quality of couplets generated by the four methods (M1-M4) differs significantly.
Further pairwise comparisons using the LSD post hoc test revealed that method M2 exhibited statistically significant differences compared to method M1 (p < 0.001), method M3 (p = 0.001), and method M4 (p< 0.001), all of which were below the 0.05 threshold. These findings indicate that method M2 significantly outperforms the other three methods (M1, M3, and M4) in terms of couplet quality.
4.6. User Study
To investigate the role of the PCcGE in promoting couplet culture, enhancing user engagement, and its practical utility, we recruited participants and conducted a series of formal experiments. Before the experiment, we had implemented the corresponding system, where participants only needed to input their personalized needs, and the system would generate the corresponding couplets.
Experimental process: First, prior to the experiments, we conducted a pre-survey across four dimensions to understand the extent of the couplet culture’s dissemination and participants’ backgrounds. The questions are shown in
Table 4.
Second, participants were asked to provide their personalized needs based on personal preferences and then use the system to generate four couplets.
Third, after completing the experience, participants filled out a post-survey with questions evaluating the system across five dimensions. The questions are shown in
Table 5.
Participants: Since literary literacy is often correlated with educational background, we recruited 64 participants, including 16 undergraduate students, 16 master’s students, 16 doctoral students, and 16 professors. We label the groups as , , , and , respectively.
Statistical Methods: The surveys were conducted in the form of questionnaires. For the Likert scale questions (measuring degree of agreement or intensity), participants selected the statement that best represented their opinion, with scores assigned from 1 to 5, ranging from weak to strong agreement. For binary questions, a score of 0 was assigned for “No” and 1 for “Yes”. The final score for each dimension was calculated as the mean of the total scores provided by the participants in each group.
As per the experimental process outlined above, the pre-survey and post-survey results are summarized in
Table 6 and
Table 7.
We can ascertain the following from
Table 6: Since couplets are an integral part of Chinese traditional culture, all participants were familiar with the basic characteristics of couplets due to their exposure to them during school education. However, approximately 88% of participants lacked the ability to create couplets. We also found that this ability correlates with the participant’s generation and educational background. Older professors tend to possess some skills of couplet creation, likely due to the prevalence of classical literature like couplets before the 1990s. In contrast, modern younger generations rarely study or create couplets, reflecting a shift in educational focus over time. This generational and educational disparity indicates a lack of couplet creation ability among younger people. Moreover, around 94% of participants had never used a couplet generation system, reflecting the low influence of couplet culture in modern society and the scarcity of enthusiasts. The large gap between interest in creating couplets and the actual ability to do so suggests a pressing need to enhance the influence and accessibility of couplet culture.
We can ascertain the following from
Table 7: (1) Accuracy. All participant groups agreed that the generated couplets performed well in terms of format and basic grammatical rules. (2) Practicality. All groups considered the generated couplets to effectively meet the personalized needs, demonstrating high practical value. (3) Literary Quality. Except for the professor group, other groups rated the generated couplets favorably in terms of structural diversity and content creativity. Further investigation revealed that the professor group found some of the generated couplets’ word choices are not elegant in Chinese and not in line with classical literary esthetics, which reduced their literary quality. This indicates that more literarily sophisticated groups pay closer attention to subtle details in couplets, highlighting the need for further enhancement in literary aspects. (4) Engagement. All groups gave high ratings for engagement. They agreed that by embedding characters and specifying themes in the couplets, they felt a personal connection to the creative outcome, which resulted in a greater sense of achievement and involvement. (5) Attractiveness. All groups indicated that the PCc generation system was highly attractive and that they would be willing to continue using it. They appreciated how the system reduced the difficulty of couplet creation, providing an opportunity for greater participation, which in turn increased their interest in using couplets. Additionally, they saw great value in the system for expressing emotions, conveying blessings, promoting causes, and in educational contexts. In conclusion, the experimental results show that our approach successfully lowers the difficulty of couplet creation while ensuring high practicality. This not only enhances the public’s interest in couplet culture but also contributes to the education and transmission of couplet traditions.
5. Discussion
Referential rules and examples of notable Chinese couplets: First, the generation and evaluation of Chinese couplets follow six fundamental rules, which reflect both structural precision and artistic sophistication: (1) the number of characters must be equal in both lines; (2) the parts of speech at corresponding positions should match, typically involving consistent use of content and function words; (3) the grammatical structure between the upper and lower lines should be as symmetrical as possible; (4) rhythmic pauses during reading must align across the two lines; (5) the tonal patterns should alternate harmoniously, creating a pleasing auditory rhythm; and (6) the thematic content of the two lines should be closely related and mutually reflective. Second, to illustrate these principles, we include several well-known examples. One such couplet is as follows: “In a grain of rice lies the universe; in half a pot, the cosmos boils” (一粒米中藏世界; 半边锅内煮乾坤), expressing the idea that profound truths can be found in simple things and that even small individuals can impact the world. Another example, inscribed at the historic Guangxiao Temple in Taizhou, reads as follows: “Ten years east of the river, ten years west—do not waste your youth; One foot inside the gate, one foot outside—be mindful of every step” (十年河东, 十年河西, 切莫放年华虚度; 一脚门里, 一脚门外, 可晓得脚步留神), reminding us to cherish time and act with awareness. A third couplet features rich repetition and introspection: “Laugh at the past and present, east and west, north and south—after all, laugh at one’s own ignorance; Observe all things—heaven and earth, sun and moon, up and down—and realize the highs and lows of others,” (笑古笑今, 笑东笑西笑南笑北, 笑来笑去, 笑自己原来无知无识; 观事观物, 观天观地观日观月, 观上观下, 观他人总是有高有低) which contains nine “laugh” (笑) in up line and nine “observe” (观) in the down line, emphasizing the balance between understanding the world and reflecting on oneself. These examples demonstrate not only the strict formalism of Chinese couplets but also their powerful capacity for philosophical and emotional expression.
Diversity: This research focuses on the personalization of couplets through word embedding and creative intention. While these two aspects are important and commonly used, they represent only part of the potential for personalized couplets. In future work, we plan to explore deeper aspects of couplet personalization, such as grammatical structure, phonetics, and metaphors.
Model scale: In this study, we used a 7B quantized model that can be run on a single Tesla T4 GPU(16GB). Initially, we attempted to use a 0.5B model, but the results indicated that this model was too underpowered. After careful consideration, we selected the 7B quantized model. However, we still found that the 7B model had weak performance in understanding long inputs. Therefore, we speculate that using a 72B or larger model could potentially yield better results for our framework. However, such large models pose practical challenges in real-world applications. Thus, we recommend selecting a suitable model size for the base model based on hardware limitations and application conditions.
Regularization term: The Frobenius norm and spectral norm are two commonly used matrix norms that regularize model complexity from distinct perspectives to prevent overfitting. First, regarding computational complexity, the Frobenius norm is more efficient as it requires no matrix decomposition. Second, in terms of constraint effectiveness, it implicitly promotes a low-rank structure in by compressing the norms of A and B, thereby enhancing model generalization. Third, considering application scenarios, spectral norm constraints are better suited for adversarial training (e.g., GANs) where strong transformations are required. In summary, the Frobenius norm offers three key advantages for our study: (1) computational and training efficiency—there is no need for singular value decomposition, so the training process is faster; (2) implicit low-rank induction—the compression of A and B norms naturally encourages low-rank △W, improving generalization; and (3) training stability—holistic parameter constraint mitigates gradient instability risks inherent in spectral norm approaches. Thus, the Frobenius norm is more appropriate for this study.
Generation: The generated couplets performed well in terms of correctness, practicality, and literary quality. However, there is room for improvement in the details of word choice. We propose refining the generated couplets by using specialized models to replace inappropriate word choices or optimize the couplet structure.
Failure cases: PCcG is fundamentally an open-ended and artistic task, making it difficult to evaluate outputs in terms of creativity or esthetic value. However, structural errors are more tractable and can be explicitly identified. One common failure involves inconsistency in line length. For instance, in a case where the user intended to express praise for snowflakes, the generated couplet was as follows: upper line—Flying petals and clever words welcome early spring (7 characters); lower line—Auspicious clouds and propitious omens bring frequent good news (8 characters). This violates the core principle of symmetry in couplet construction. Such inconsistency often stems from the autoregressive and probabilistic nature of LLMs, which lack explicit mechanisms to enforce output constraints. While the error rate in our system is low (less than 1%) and re-generating is very easy (about 1.5 s), mitigation remains important. Constrained decoding strategies, such as beam search with length restrictions or regularization terms penalizing line-length discrepancies, can further reduce occurrence rates. Another failure mode involves missing embedded words. In one case, the personalized requirement is embedded words: “啊” (ah) and “呃” (uh). The model failed to embed them, yielding the following: A surge of passion cries to the sky, ah; Three cups of tea calm the murmurs (一腔热血呼天啊; 三口清茶反呢喃). This suggests that rare characters may be insufficiently represented in the training data, limiting the model’s ability to condition on them during generation, or it may be that these words are not suitable for creating couplets. Dataset analysis revealed only 36 occurrences of “啊” and 3 of “呃” among 742,130 couplets, confirming this sparsity. To address this, we can augment the training corpus with more examples containing rare or user-specified characters to improve word coverage and related knowledge.
Evaluation: The AI agent’s analysis and evaluation of the couplets performed well in terms of logical consistency and accuracy, proving highly valuable. However, the agent used in this study was not specifically fine-tuned for classical literature, indicating that the further optimization of the evaluation framework could enhance its performance.
User study: Research on different participant groups highlighted that the decline of couplet culture among younger generations is largely due to the high difficulty of couplet creation. Although the beauty and artistry of couplets deeply attract people of various educational backgrounds, changes in the educational environment and the inherent nature of couplets have made it difficult for enthusiasts to create them, which in turn hinders the spread of couplet culture. This underscores the urgent need to use new technologies to lower the creation barrier and enhance the feasibility of integrating couplet culture into education.
Ethical considerations: As is well known, LLMs may generate biased or unethical content when presented with certain inputs. Given that Chinese couplets are concise and may involve abbreviations or obscure meanings of Chinese characters, ethical issues in couplets may be more difficult to detect compared to regular texts. To address this, we can improve the ethical integrity of the base model by refining the training and fine-tuning datasets to reduce unethical data. Additionally, post-processing methods can be used to assess the generated couplets and filter out undesirable results. However, fully resolving this issue or determining the appropriate threshold for filtering remains a significant challenge. Ethical detection for couplets demands a specialized approach that accounts for their unique literary features, including symmetrical structure, hidden-head patterns, and cultural taboos, which collectively shape their distinctive ethical challenges. At the structural level, the system should scan character combinations at key positions (e.g., the first and last characters of each line) to identify potentially sensitive hidden-head content, supported by a comprehensive cultural taboo lexicon covering political, religious, and gender-related terms with clear usage constraints. On the semantic level, emphasis must be placed on analyzing the symmetrical relationship between the paired lines to uncover implicit ethical issues such as gender bias or cultural conflict. In our opinion, a hybrid detection framework is recommended: a rule-based engine for efficiently flagging explicit taboos (e.g., inauspicious words like “Lucifer” or “Damien”) and a fine-tuned language model (e.g., BERT) to detect nuanced violations like metaphors or puns. By incorporating contextual understanding, the system can effectively discern superficially innocuous content that may conceal politically charged subtext, ensuring both detection efficiency and semantic depth through this layered approach.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}