

Simulation-Guided Path Optimization for Resolving Interlocked Hook-Shaped Components




Abstract
1. Introduction
- A motion-planning framework for optimizing trajectories to separate interlocked hook-shaped components in a pick-and-place task.
- Real-world experimental results demonstrating that the proposed framework improves the success rate of the separating subtask compared to the industrial baseline.
2. Related Works
3. Preliminaries
3.1. Notation
3.2. Path Integral Optimization
3.3. Spline Representation
4. Our Approach
4.1. Problem Formulation
4.2. Modeling Interlocking
4.3. Sampling-Based Optimization
4.3.1. Sampling Noise
4.3.2. Warm-Starting
4.3.3. Cost Terms
4.4. Framework Pipeline
| Algorithm 1: Framework for separating subtask |
 |
5. Results
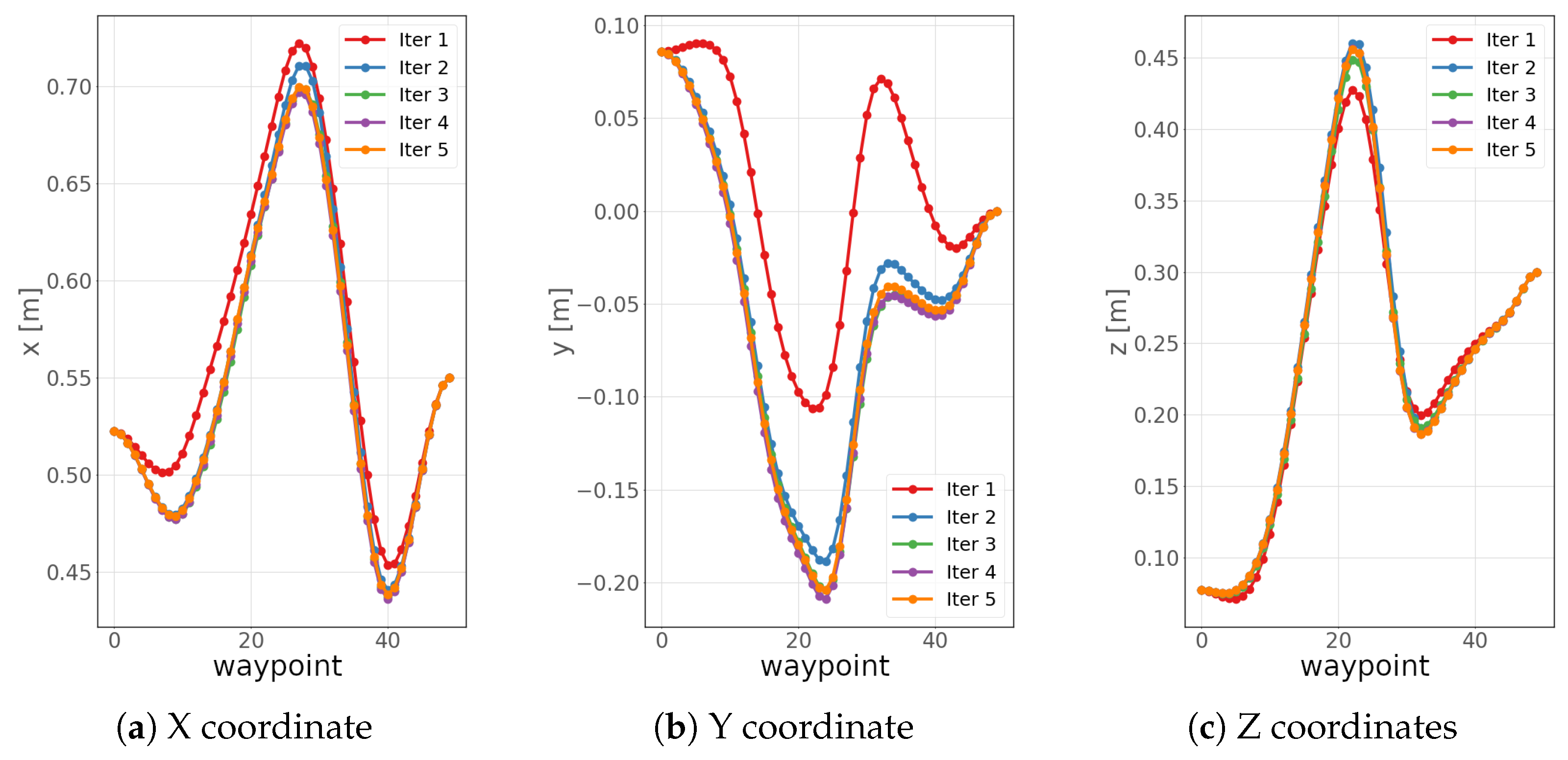
5.1. Experimental Setup
5.2. Real-World Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schulman, J.; Duan, Y.; Ho, J.; Lee, A.; Awwal, I.; Bradlow, H.; Pan, J.; Patil, S.; Goldberg, K.; Abbeel, P. Motion planning with sequential convex optimization and convex collision checking. Int. J. Robot. Res. 2014, 33, 1251–1270. [Google Scholar] [CrossRef]
- Kalakrishnan, M.; Chitta, S.; Theodorou, E.; Pastor, P.; Schaal, S. STOMP: Stochastic trajectory optimization for motion planning. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 4569–4574. [Google Scholar]
- Jankowski, J.; Racca, M.; Calinon, S. From key positions to optimal basis functions for probabilistic adaptive control. IEEE Robot. Autom. Lett. 2022, 7, 3242–3249. [Google Scholar] [CrossRef]
- Jankowski, J.; Brudermüller, L.; Hawes, N.; Calinon, S. Vp-sto: Via-point-based stochastic trajectory optimization for reactive robot behavior. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 10125–10131. [Google Scholar]
- Pezzato, C.; Salmi, C.; Spahn, M.; Trevisan, E.; Alonso-Mora, J.; Corbato, C.H. Sampling-based model predictive control leveraging parallelizable physics simulations. arXiv 2023, arXiv:2307.09105. [Google Scholar] [CrossRef]
- Kingston, Z.; Moll, M.; Kavraki, L.E. Sampling-based methods for motion planning with constraints. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 159–185. [Google Scholar] [CrossRef]
- Kavraki, L.E.; Svestka, P.; Latombe, J.C.; Overmars, M.H. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Trans. Robot. Autom. 1996, 12, 566–580. [Google Scholar] [CrossRef]
- LaValle, S.M. Planning Algorithms; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Ratliff, N.; Zucker, M.; Bagnell, J.A.; Srinivasa, S. CHOMP: Gradient optimization techniques for efficient motion planning. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 489–494. [Google Scholar]
- Marcucci, T.; Petersen, M.; von Wrangel, D.; Tedrake, R. Motion planning around obstacles with convex optimization. Sci. Robot. 2023, 8, eadf7843. [Google Scholar] [CrossRef] [PubMed]
- Williams, G.; Drews, P.; Goldfain, B.; Rehg, J.M.; Theodorou, E.A. Aggressive driving with model predictive path integral control. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1433–1440. [Google Scholar]
- Williams, G.; Wagener, N.; Goldfain, B.; Drews, P.; Rehg, J.M.; Boots, B.; Theodorou, E.A. Information theoretic mpc for model-based reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1714–1721. [Google Scholar]
- Pinneri, C.; Sawant, S.; Blaes, S.; Achterhold, J.; Stueckler, J.; Rolinek, M.; Martius, G. Sample-efficient cross-entropy method for real-time planning. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 1049–1065. [Google Scholar]
- Bhardwaj, M.; Sundaralingam, B.; Mousavian, A.; Ratliff, N.D.; Fox, D.; Ramos, F.; Boots, B. Storm: An integrated framework for fast joint-space model-predictive control for reactive manipulation. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 750–759. [Google Scholar]
- Hansen, N. The CMA evolution strategy: A tutorial. arXiv 2016, arXiv:1604.00772. [Google Scholar]
- Kappen, H.J. An introduction to stochastic control theory, path integrals and reinforcement learning. In AIP Conference Proceedings; American Institute of Physics: College Park, MD, USA, 2007; Volume 887, pp. 149–181. [Google Scholar]
- Theodorou, E.; Buchli, J.; Schaal, S. Learning policy improvements with path integrals. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 828–835. [Google Scholar]
- Stulp, F.; Sigaud, O. Path integral policy improvement with covariance matrix adaptation. arXiv 2012, arXiv:1206.4621. [Google Scholar]
- Chebotar, Y.; Kalakrishnan, M.; Yahya, A.; Li, A.; Schaal, S.; Levine, S. Path integral guided policy search. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3381–3388. [Google Scholar]
- Howell, T.; Gileadi, N.; Tunyasuvunakool, S.; Zakka, K.; Erez, T.; Tassa, Y. Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo. arXiv 2022, arXiv:2212.00541. [Google Scholar] [CrossRef]
- Sundaralingam, B.; Hari, S.K.S.; Fishman, A.; Garrett, C.; Van Wyk, K.; Blukis, V.; Millane, A.; Oleynikova, H.; Handa, A.; Ramos, F.; et al. curobo: Parallelized collision-free minimum-jerk robot motion generation. arXiv 2023, arXiv:2310.17274. [Google Scholar]
- Makoviychuk, V.; Wawrzyniak, L.; Guo, Y.; Lu, M.; Storey, K.; Macklin, M.; Hoeller, D.; Rudin, N.; Allshire, A.; Handa, A.; et al. Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv 2021, arXiv:2108.10470. [Google Scholar]
- Corke, P.; Haviland, J. Not your grandmother’s toolbox–the Robotics Toolbox reinvented for Python. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11357–11363. [Google Scholar]
- Franzese, G.; Mészáros, A.; Peternel, L.; Kober, J. ILoSA: Interactive learning of stiffness and attractors. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 7778–7785. [Google Scholar]
- Photoneo. Photoneo. Your Partner in 3D Vision and Automation. 2025. Available online: https://www.photoneo.com/ (accessed on 23 January 2025).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Success Rate [%] | Computational Time | |
|---|---|---|---|
| 5 Iterations [s] | 1 Iteration [ms] | ||
| Our | 80 | 2.090 ± 0.003 | 417.2 ± 0.2 |
| Demo 1 | 30 | - | - |
| Demo 2 | 30 | - | - |
| Demo 3 | 50 | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Merva, T.; Sincak, P.J.; Rakay, R.; Varga, M.; Kelemen, M.; Virgala, I. Simulation-Guided Path Optimization for Resolving Interlocked Hook-Shaped Components. Appl. Sci. 2025, 15, 4944. https://doi.org/10.3390/app15094944
Merva T, Sincak PJ, Rakay R, Varga M, Kelemen M, Virgala I. Simulation-Guided Path Optimization for Resolving Interlocked Hook-Shaped Components. Applied Sciences. 2025; 15(9):4944. https://doi.org/10.3390/app15094944
Chicago/Turabian StyleMerva, Tomas, Peter Jan Sincak, Robert Rakay, Martin Varga, Michal Kelemen, and Ivan Virgala. 2025. "Simulation-Guided Path Optimization for Resolving Interlocked Hook-Shaped Components" Applied Sciences 15, no. 9: 4944. https://doi.org/10.3390/app15094944
APA StyleMerva, T., Sincak, P. J., Rakay, R., Varga, M., Kelemen, M., & Virgala, I. (2025). Simulation-Guided Path Optimization for Resolving Interlocked Hook-Shaped Components. Applied Sciences, 15(9), 4944. https://doi.org/10.3390/app15094944