This study aims to analyze image data and combine various models to calculate the nutritional content of food and provide subsequent dietary recommendations.
Through the following process, the system can accurately identify food categories and provide detailed nutritional content and practical dietary advice to support users in achieving a healthier diet. This research methodology integrates advanced image processing techniques and artificial intelligence algorithms, demonstrating efficient and practical performance in real-world applications.
3.1. Food Image Classification
Contrastive learning [
23,
24,
25,
26] has increasingly become a mainstream method in deep learning in recent years, and it is used for learning meaningful representations. The core idea of this learning framework is that semantically related concepts should have similar representations, while non-related concepts should have different representations. Contrastive learning was initially used mainly for self-supervised image representation learning [
23,
26] and has gradually expanded to the linguistic fields [
24,
25]. Recent studies have further leveraged contrastive training to integrate different communication modalities, such as vision and language, audio and language, etc. These models learn the concepts of other modalities and optimize their proximity in a shared abstract space.
CLIP [
5] is a multimodal neural network that combines vision and language, and it is trained through a contrastive learning method specifically designed to associate visual concepts with corresponding textual descriptions. The model includes an image encoder and a text encoder, which map image and text representations into the same vector space, training the model to bring related images and descriptions closer together in this space. However, although CLIP performs well in general tasks, it requires further fine tuning and optimization for specific domain applications, such as food classification. This study aims to develop and evaluate a pre-trained model specifically designed for the food domain—NutritionCLIP—through contrastive learning.
This section focuses on improving the accuracy of the food classification model by fine tuning the CLIP model. This process involves specific training of the image and text encoder to optimize their ability to process data in the food domain.
During the dataset processing stage, as described in
Section 4.2.1, we divide the datasets into three parts: training set, validation set, and testing set. Each image is converted into a fixed-size tensor and standardized to improve data consistency. Next, using ViT [
21] as the image encoder, these standardized images are transformed into feature vectors
. For text processing, considering the specific requirements of regional languages, Chinese-RoBERTa-wwm-large [
53,
54] is chosen as the text encoder to handle Chinese inputs and convert the text into feature vectors
.
After data feature processing, contrastive learning is used to learn the associations of image–text pairs in different batches. Since the embedded vectors in CLIP are high-dimensional and focus on the similarity between vectors, cosine similarity [
55] is selected as the measure. The primary calculation method is as follows:
where
and
are the image and text embedding vectors, respectively, and
and
represent their norms.
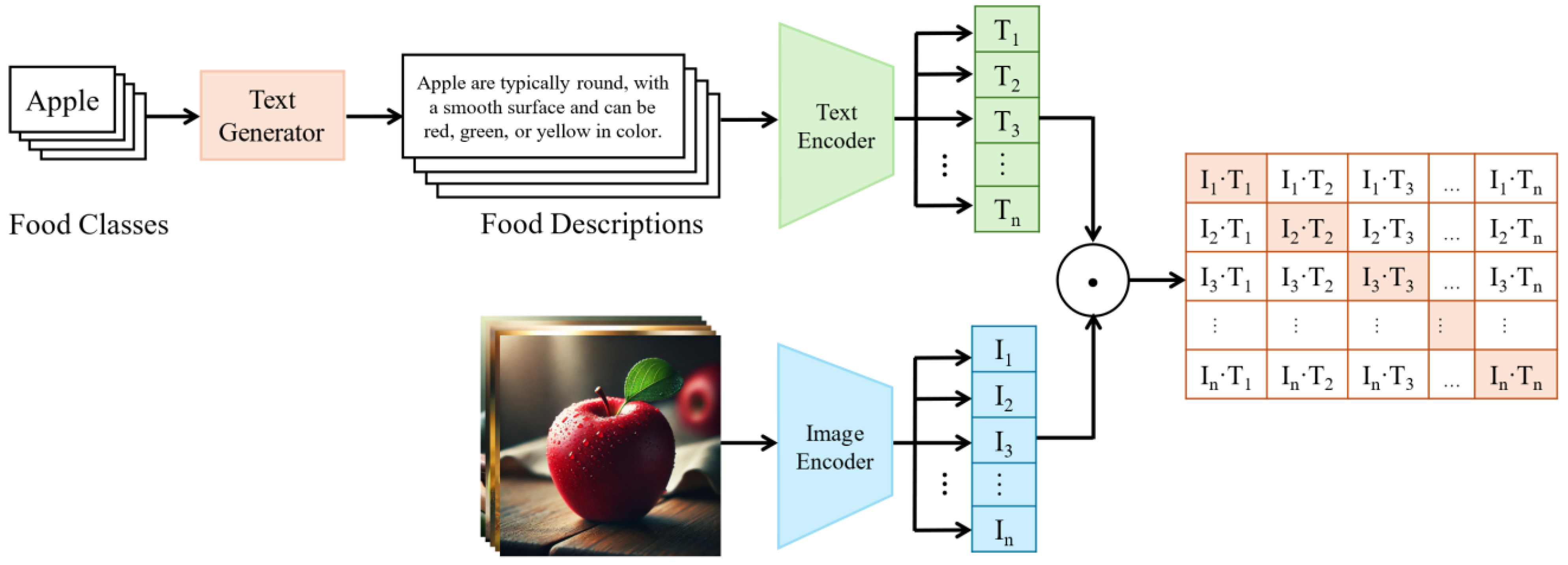
For each batch of
pairs of images and texts
, CLIP calculates a similarity matrix of size
, where each element’s similarity
represents the cosine similarity between the
image embedding vector and the
text embedding vector. Each row of this similarity matrix represents the similarities between an image embedding vector and all text embedding vectors, and each column represents the similarities between a text embedding vector and all image embedding vectors, as shown in
Figure 3.
Next, the model is trained based on contrastive loss, maximizing the similarity between matching image and text pairs and minimizing the similarity between non-matching pairs. The calculation method is as follows:
where
is the number of samples and
is a margin hyperparameter.
indicates whether it is a matching pair. If
and
are matching, then
; otherwise,
.
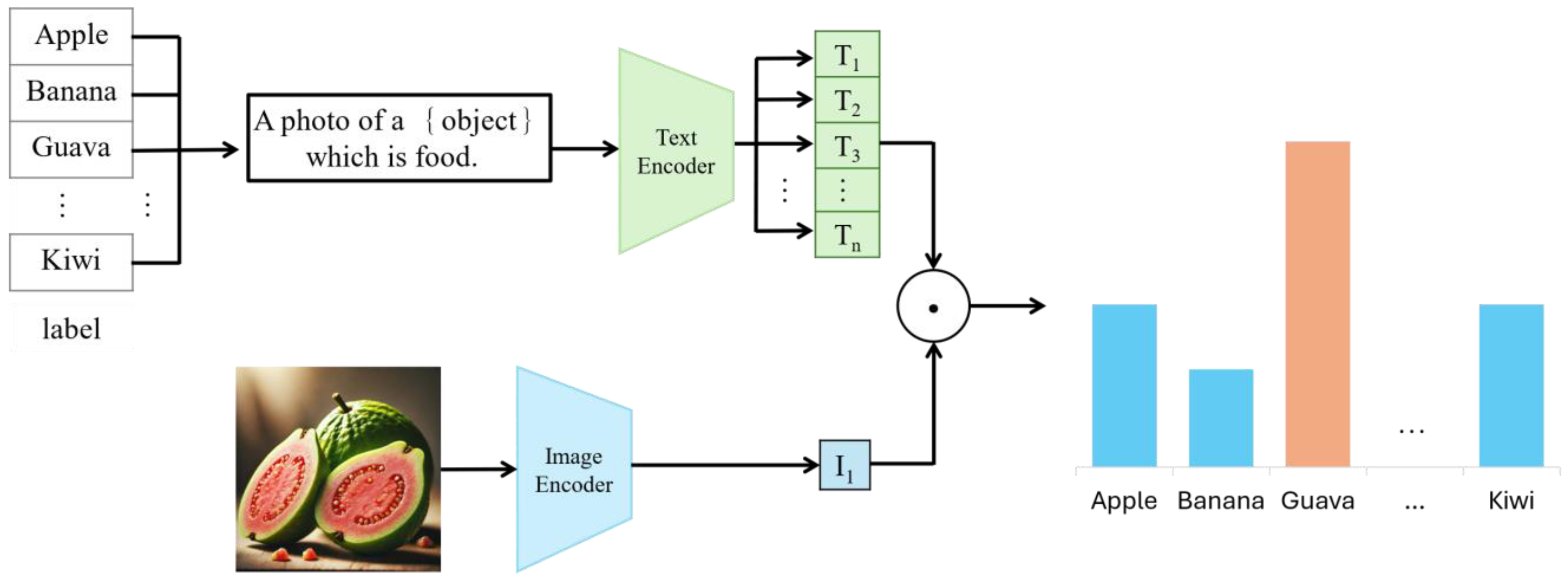
Finally, cross-entropy loss is used to classify and predict each image as the correct food category. The calculation method is as follows:
where
represents the actual label, usually a one-hot vector indicating that sample
belongs to a specific category.
is the predicted probability. Fine tuning the model can be used for zero-shot classification of food categories, as shown in
Figure 4.
3.2. Food Volume Measurement
After food classification, the next step is to calculate the volume of the food. Using the method from E-Volume [
7], MVSNet [
33] generates depth maps of the image scene. These depth maps are then converted into scene point clouds using a point cloud generator, allowing for object segmentation and an accurate food volume estimation.
First, the food 3D models from the NutritionVerse3D [
56] dataset are rendered onto a plane using Blender to generate precise scene image data, as shown in
Figure 5.
After generating scene data from different angles, the E-Volume architecture is used for volume prediction. MVSNet is used to produce depth maps of the scene. The generation method involves capturing multiple images of the scene from different perspectives with each image , where and are the height and width of the image, respectively. The input images are then passed through an eight-layer CNN for feature extraction to obtain deep features. A differentiable homography transformation is used to warp the features extracted from different viewpoints into a standard reference frame, forming a three-dimensional cost volume . This cost volume integrates information from all input images to facilitate accurate depth estimation. A multi-scale 3D CNN is then used to regularize the cost volume, generating probability volumes from which depth maps are inferred. The final depth map is obtained using the soft margin operation, calculating the probability-weighted sum of depth hypotheses.
Once the depth maps are generated, the depth value of each pixel and the camera’s intrinsic parameters are used to reproject each pixel from the depth map into 3D space, forming a dense point cloud for each viewpoint. The transformation process is as follows:
where
represents the corresponding point in 3D space,
is the depth value,
are the pixel coordinates in the image, and
is the camera intrinsic matrix.
To segment the scene and object and obtain the point cloud of the food object, a segmentation mask generated for each viewpoint is used to crop the point cloud, removing parts that do not belong to the food. This results in an object point cloud containing only the food items.
Finally, this object point cloud is processed through convolutional layers and batch normalization for feature extraction. Max pooling is used to obtain a global feature vector, capturing the overall geometric shape of the food item. This global feature vector is then fed into a fully connected layer, outputting the estimated volume of the food item through a single-channel output, as shown in
Figure 6.
3.3. Nutrient Calculation
After estimating the food volume in
Section 3.2, our system retrieves the corresponding density information from the INFOODS Density Database maintained by the United Nations Food and Agriculture Organization (FAO). The total weight of the food is obtained by applying the density values to the previously calculated volumes.
Once the weight of each food item is determined, we use an established nutrition database to estimate the nutritional content of the food. These databases include the Food Composition Database, integrated by the Ministry of Health and Welfare of Taiwan, and the International Network of Food Data Systems (INFOODS), maintained by the FAO. We extract basic nutritional information from these resources: calories, protein, fat, and carbohydrates. This allows the system to provide accurate nutritional values for the foods.
3.4. Nutritional Advisory System
In our system, to deploy a large language model on mobile devices for providing personalized dietary advice and answering user nutrition-related questions, we have used Meta’s Llama 3 (Large Language Model Meta AI) as the core large language model to optimize performance.
We fine tuned Llama 3 using publicly available datasets such as alpaca_gpt4_en, alpaca_gpt4_zh, Animal-nutrition-alpaca, and Animal-nutrition-new-alpaca. These datasets include basic knowledge and nutrition-related datasets to ensure a diversity of information, and some prompting phrases are added to train the model.
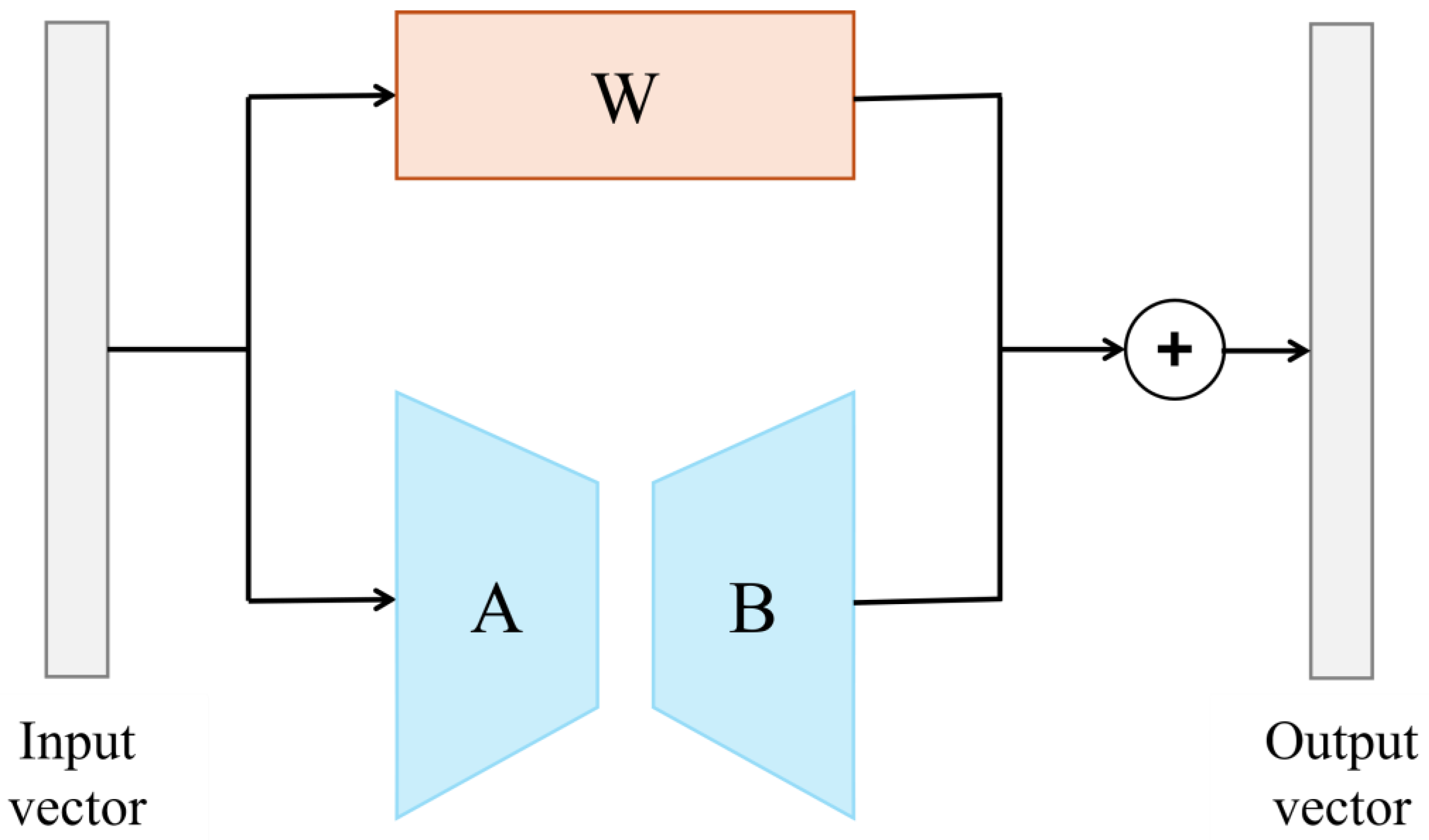
To further enhance the performance of Llama 3 in nutrition question answering and diet recommendation generation, we adopted LoRA (Low-Rank Adaptation) [
57] for model fine tuning. LoRA is an efficient model adaptation technique that aims to achieve effective knowledge transfer by lightweight adjustment of the pre-trained model through low-rank matrix decomposition, as shown in
Figure 7. This involves decomposing the weight matrix of the large pre-trained model into two low-rank matrices, reducing the number of parameters in the adjustment process and making the fine-tuning process lighter and more efficient. This approach retains the original capabilities of the pre-trained model while quickly adapting to new data and tasks, which is particularly beneficial for application scenarios requiring frequent model updates and adjustments.
The process of fine tuning the model using LoRA can be expressed with the following equations:
where
is the original weight matrix of the pre-trained model,
is the weight matrix after fine tuning, and
and
are low-rank matrices, with
,
, and rank
. This decomposition significantly reduces the number of parameters that must be trained, thereby improving computational efficiency.
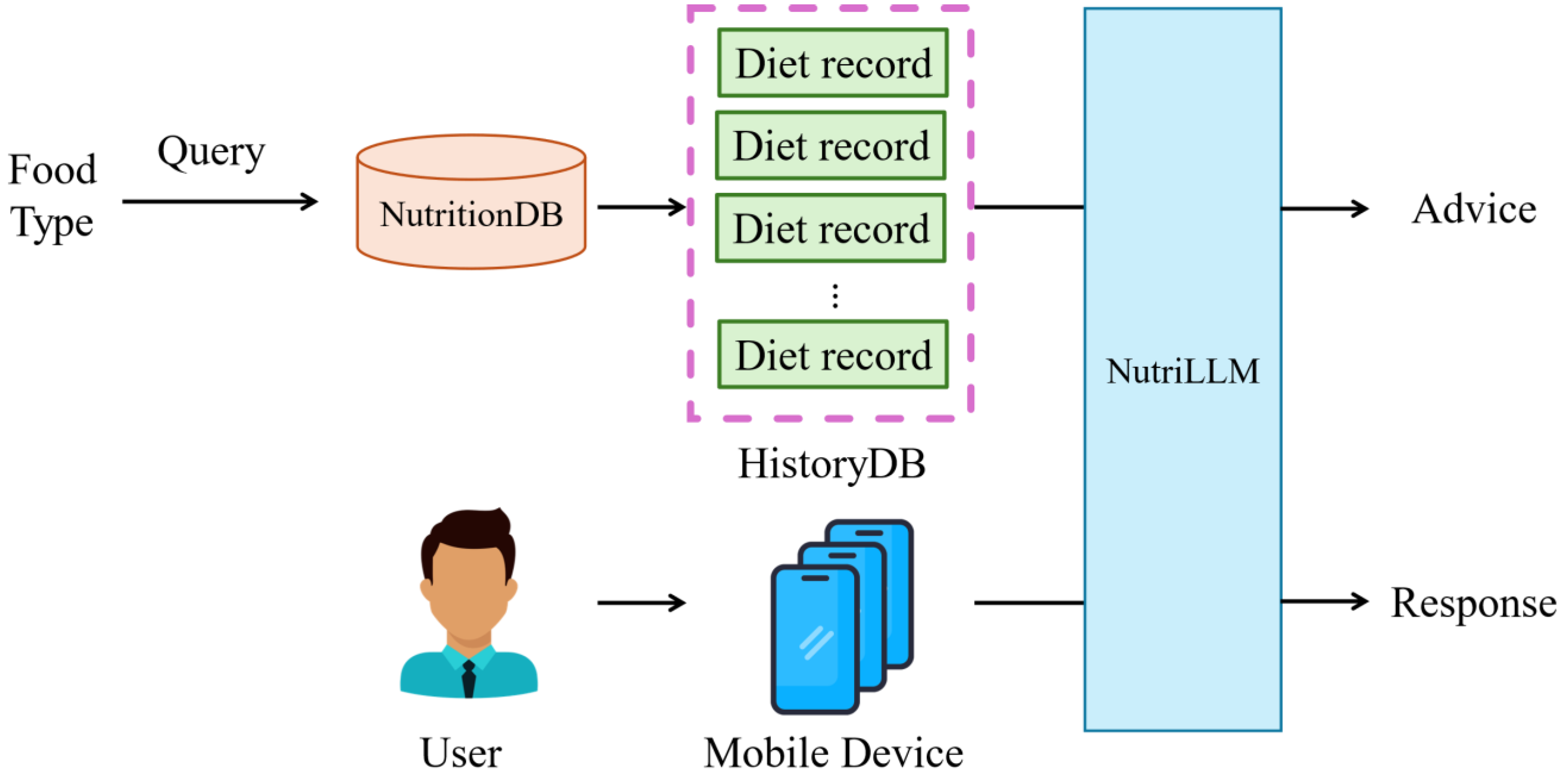
Using this method, we have successfully fine tuned Llama 3 to handle nutrition-related queries and generate personalized dietary recommendations. This enables our system to provide nutritional value calculations for food and offer practical dietary advice based on the user’s personal needs and nutritional records, helping users achieve a healthier eating pattern, as shown in
Figure 8.
3.5. Architecture
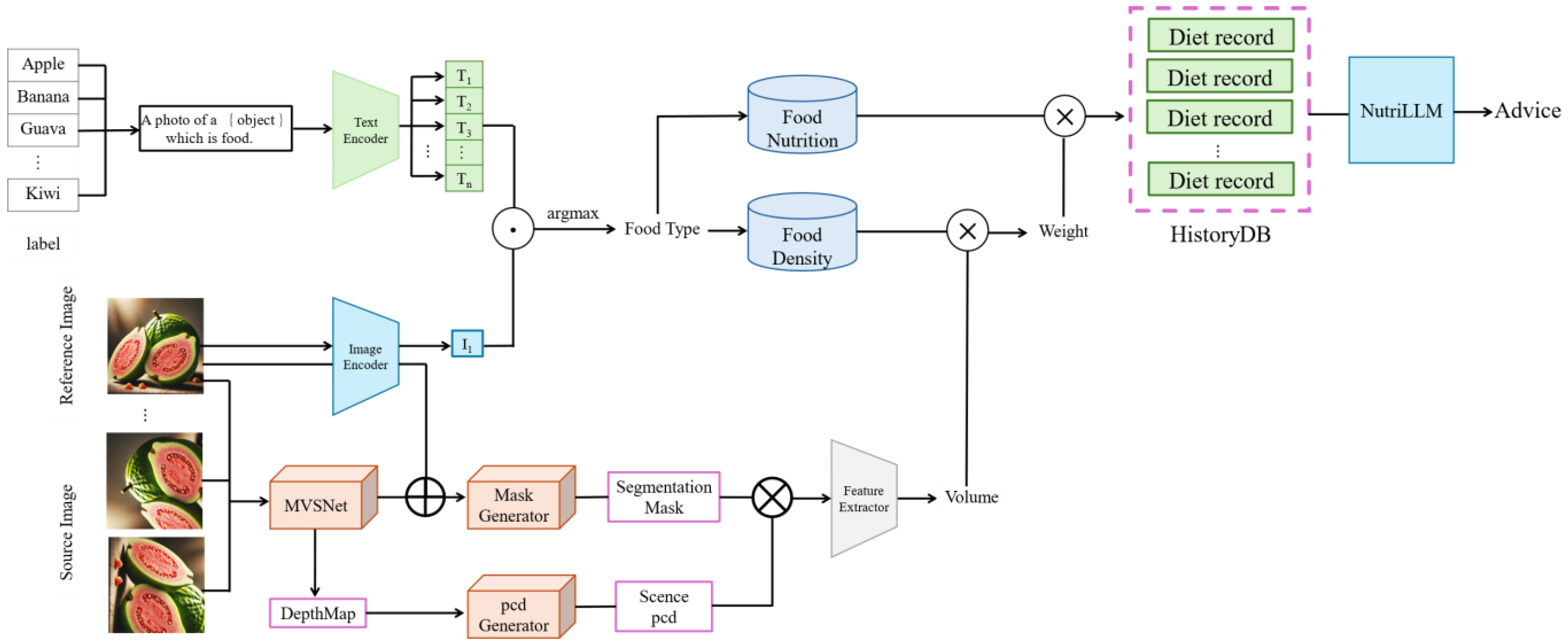
The system integrates multiple advanced multimodal deep learning models into a coherent pipeline to facilitate accurate food classification, volume estimation, nutrient calculation, and personalized dietary recommendations.
Figure 9 illustrates the overall architecture and workflow of the proposed nutritional advisory system, highlighting the interactions and data flows between the core modules: NutritionCLIP, E-Volume, nutrient calculation, and NutriLLM.
3.5.1. NutritionCLIP Module
The first stage involves recognizing and classifying the food images provided by the user. We utilize the NutritionCLIP model, specifically fine tuned for food domain tasks based on the CLIP framework. The NutritionCLIP comprises two main components:
An image encoder, which employs a Vision Transformer (ViT) to convert standardized images into meaningful feature vectors III.
A text encoder, which utilizes Chinese-RoBERTa-wwm-large for processing Chinese textual descriptions of food, converting them into textual embedding vectors T.
NutritionCLIP applies a contrastive learning approach, mapping related image–text pairs into a shared semantic space and pushing apart unrelated pairs. Cosine similarity serves as the metric for measuring feature vector similarities. The model optimizes classification accuracy through a combined contrastive loss and cross-entropy loss strategy, ensuring accurate zero-shot food recognition across diverse and previously unseen food categories.
3.5.2. E-Volume Module
Following classification, the system accurately estimates food volume using the E-Volume module, a learning-based multi-view stereo (MVS) approach. The process begins with the data pre-processing stage, leveraging the NutritionVerse3D dataset, which includes the following diverse 3D food models:
The E-Volume volume estimation comprises several sub-components:
MVS body predicts depth maps for each viewpoint through a learning-based MVS approach, using MVSNet as the backbone network to generate robust 3D reconstructions.
Mask predictor conducts semantic segmentation on selected images to produce masks delineating food objects from their surroundings clearly.
Point cloud generator integrates depth information from multiple viewpoints, synthesizing comprehensive scene point clouds.
Object point cloud extraction employs generated segmentation masks to isolate food objects from the scene point cloud, preparing precise input for volume calculation.
Finally, the isolated food object point clouds undergo convolutional neural network processing, extracting global geometric features and producing accurate food volume estimations.
3.5.3. Nutrient Calculation Module
With the food category and volume identified, the system computes the corresponding nutritional information by referencing the following authoritative food density and nutrient databases:
The Food Density Database retrieves density values corresponding to the identified food categories.
The Food Composition Database calculates the nutritional content, including calories, protein, fat, and carbohydrates, based on the determined food weight (derived from density and estimated volume).
The output from this stage generates a detailed nutrient profile, enabling precise dietary tracking and management.
3.5.4. NutriLLM Module
The final module employs a fine-tuned large language model (LLM), NutriLLM, to provide personalized dietary recommendations tailored to individual health goals and historical dietary data. NutriLLM utilizes Meta’s advanced Llama 3 architecture due to its optimized computational and memory efficiency, which is well suited for mobile deployment.
Training Data. NutriLLM undergoes extensive fine tuning with large, publicly available datasets encompassing general nutritional knowledge and targeted nutrition-specific dialogues.
Low-Rank Adaptation (LoRA). Applies LoRA to efficiently fine tune the pre-trained model. LoRA significantly reduces the computational load by decomposing weight matrices into lower-rank components, facilitating rapid and efficient model adaptation.
NutriLLM excels in generating contextually relevant and personalized dietary recommendations, leveraging users’ historical dietary records and current nutritional assessments to provide tailored advice. It supports extensive interactions, effectively parsing user queries and generating coherent nutritional guidance, contributing to a comprehensive dietary management experience.
3.5.5. Integration and Data Flow
These core modules are seamlessly integrated into an automated pipeline as follows:
- 1.
Users upload images of their meals, which are initially processed by NutritionCLIP to determine the food category.
- 2.
The classified images feed into E-Volume for multi-view stereo-based volume estimation, yielding accurate measurements of food quantities.
- 3.
The nutrient calculation module subsequently computes comprehensive nutritional information using authoritative food databases.
- 4.
Finally, NutriLLM synthesizes nutritional data, historical dietary records, and personalized health objectives to deliver actionable dietary recommendations and advice directly to the user.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}