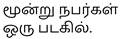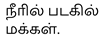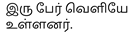1. Introduction
Image captioning, situated at the crossroads of computer vision and natural language processing, represents an intriguing challenge: to create systems capable of understanding and articulating the narrative of a visual scene. This field has undergone a transformative journey with the introduction of deep learning technologies [
1,
2]. In the case of languages with abundant resources like English, image captioning systems have achieved remarkable strides. These systems, powered by extensive annotated datasets and innovative neural network designs, have reached notable levels of precision and coherence [
3,
4]. The prevalent integration of Convolutional Neural Networks (CNNs) for image analysis and Recurrent Neural Networks (RNNs) or transformers for text generation has been central to these advancements. These systems’ capabilities, transforming pixels into comprehensible narratives, have unlocked a spectrum of applications. From aiding visually impaired individuals in perceiving their environment to enhancing user engagement on digital platforms with automated image descriptions, the potential uses are vast and varied. The synergy between extracting key visual elements and integrating them into linguistically and contextually rich descriptions continues to be an active and expanding field of research, pushing the boundaries of what artificial intelligence can achieve.
However, this narrative takes a different turn when considering low-resource languages like Tamil. The challenges here are multifaceted. One primary obstacle is the stark scarcity of extensive, annotated datasets [
5]. Unlike English, where data for image–caption pairs is plentiful and diverse, Tamil faces a dearth of such resources, impeding the development of comprehensive models. Furthermore, the distinctive linguistic attributes of Tamil add layers of complexity to the caption generation process [
6]. These complexities are reflected in the language’s rich morphological structures and varied syntactic arrangements, posing a significant challenge for models predominantly trained on English-centric datasets and rules. As a result, these models often falter in generating fluent and contextually accurate captions in Tamil, highlighting the need for more linguistically and culturally adaptive systems.
In conventional image captioning models, the significance of context is often underplayed. Yet, the ability to contextualize is vital in crafting captions that transcend mere object enumeration and instead narrate a story that encapsulates the essence and interrelations of the elements within an image [
7,
8]. This aspect becomes even more critical in culturally diverse contexts, where images may bear specific connotations or symbolic meanings integral to a culture. Capturing this contextual dimension involves more than recognizing visual elements; it requires an understanding of the setting, the emotional tone, and the cultural nuances associated with the imagery. For instance, a depiction of a festival in Tamil culture might be imbued with unique cultural symbols and references. Neglecting these aspects could lead to captions that fail to capture the image’s core elements and cultural significance.
In response to these challenges, there is a pressing need for models that not only possess visual acuity but also exhibit a deep understanding of cultural and contextual subtleties. Such models should not only recognize and describe visual elements but also weave these elements into a narrative that is culturally resonant and contextually rich, especially for languages like Tamil that are rich in cultural and linguistic diversity. The pursuit of image captioning in low-resource languages like Tamil necessitates a nuanced understanding of the intersection between technology, language, and culture [
9]. While deep learning has undeniably revolutionized the field, its reliance on large datasets poses a significant challenge in these contexts. The scarcity of data in languages such as Tamil is not merely a quantitative issue but also a qualitative one, reflecting a gap in cultural representation and linguistic diversity. This scarcity becomes particularly problematic in the context of neural network training, where the quantity and variety of data significantly influence the model’s accuracy and versatility [
2,
8]. The linguistic complexity of Tamil, with its distinct phonetics, syntax, and semantics, further complicates the scenario. Unlike Indo-European languages, Tamil’s agglutinative nature, where words are formed by joining morphemes, poses unique challenges in language processing. Moreover, the rich cultural backdrop of Tamil, with its vast literary and artistic traditions, adds layers of meaning that standard models might overlook. This cultural richness brings forth images and scenes steeped in local traditions, festivals, and everyday life that are replete with nuances and subtleties. Capturing these elements in captions requires a model that understands not just the visual but also the cultural and emotional context.
The introduction of the Dynamic Context-Aware Transformer (DCAT) aims to bridge these gaps. By integrating cutting-edge techniques like Vision Transformers and Generative Pre-trained Transformers, DCAT is designed to capture both the visual fidelity and the contextual depth required for effective image captioning in Tamil. The model’s architecture, incorporating dynamic attention mechanisms and a novel Context Embedding Layer, is tailored to navigate the intricate interplay between visual cues and linguistic expression inherent to Tamil. The significance of this research extends beyond technological innovation; it touches on the broader themes of cultural representation and language preservation. By focusing on a low-resource language, this work contributes to the democratization of AI technologies, ensuring that the benefits of advancements in image captioning are not limited to a handful of widely spoken languages but are accessible to a more diverse global audience. This endeavor is not just about building a more accurate or efficient system; it is about creating technology that understands and respects the linguistic and cultural diversity of its users.
As we continue to explore the realms of artificial intelligence and machine learning, the need to integrate these technologies with humanistic considerations becomes increasingly paramount. DCAT represents a step in this direction, aiming to create a system that is not only technically proficient but also culturally aware and linguistically inclusive. This research, therefore, is not just a contribution to the field of computer vision or natural language processing; it is a testament to the potential of AI to bridge gaps between technology and the rich tapestry of human languages and cultures.
Objectives of the Paper
The main objectives of this research paper are outlined as follows:
To conduct a comprehensive background study and present an enlightening literature review focusing on the advancements and challenges in the field of image captioning, particularly emphasizing the context of low-resource languages like Tamil.
To propose a novel methodology, titled “Dynamic Context-Aware Transformer (DCAT)”, aimed at addressing the unique challenges of image captioning in Tamil. The novelty of DCAT lies in its integration of the Vision Transformer (ViT) and the Generative Pre-trained Transformer (GPT-3) with a specialized Context Embedding Layer, offering a unique approach to capture both the visual and contextual nuances of images.
To rigorously test and validate the proposed DCAT methodology using various performance metrics such as BLEU score, METEOR score, Contextual Accuracy (CA), and a Composite Evaluation Score (CES), which collectively assess linguistic accuracy, contextual relevance, and overall effectiveness.
To compare and contrast the performance of DCAT with existing state-of-the-art techniques in image captioning, such as Neural Image Captioning (NIC), Up-Down Attention, and Object-Semantics Aligned Pre-training (Oscar), providing a clear benchmark of its advancements and contributions to the field.
The rest of the paper is organized as follows:
Section 2 discusses the related works in the field of image captioning and contextual modeling.
Section 3 discusses the materials and methods used in this reserach.
Section 4 details the proposed methodology, including the system model, architecture, and workflow of the DCAT model.
Section 5 presents the experimental setup, evaluation metrics, and result analysis. Finally,
Section 6 concludes the paper and suggests avenues for future research.
2. Literature Review
Early work in image captioning primarily focused on reference-based methods. Mao et al. [
1] innovatively redefined reference-based image captioning by incorporating reference images to enhance caption uniqueness. Their approach led to significantly more distinctive captions, marking a key advancement in generating unique and contextually relevant descriptions. Wu et al. [
3] developed a generative model for learning transferable perturbations in image captioning. Their work introduced novel loss functions, enabling the creation of adversarial examples that effectively generalized across various models, a significant step in understanding and improving the robustness of captioning systems. Pan et al. [
4] introduced the BTO-Net, utilizing object sequences as top-down signals in image captioning. This innovative combination of bottom-up and LSTM-based object inference significantly improved performance on the COCO benchmark, demonstrating a nuanced understanding of object relationships in images.
Deb et al. [
6] developed “Oboyob”, a Bengali image-captioning engine, focusing on generating semantically rich captions. Their work effectively tackled the linguistic complexities of Bengali, enhancing the scope of language-specific captioning tools. Arora et al. [
5] proposed a hybrid model that blends neural image captioning with the k-Nearest Neighbor approach. This model represents a significant leap in integrating traditional machine learning with modern deep learning techniques, offering a novel perspective on image captioning methodologies. Hossain et al. [
2] provided an extensive survey of deep learning applications in image captioning. Their comprehensive review covers a range of techniques, evaluating their strengths, limitations, and performances, thereby offering a valuable resource for researchers in the field.
Xu et al. [
7] presented a detailed review of deep image captioning methods, discussing emerging trends and future challenges. Their analysis provides a thorough understanding of the evolution of image captioning methods and points towards potential future advancements in the field. Mishra et al. [
8] proposed a unique GPT-2-based framework for image captioning in Hindi, integrating object detection with transformer architecture. This approach not only demonstrated promising results in generating accurate Hindi captions but also addressed the challenges of captioning in low-resource languages.
Sharma et al. [
10] offered a comprehensive survey on image captioning techniques, tracing the evolution of various methods and providing insights into the field’s development. This work stands as a valuable reference for understanding the progression and current state of image captioning technologies. Liu et al. [
11] surveyed deep neural network-based image captioning methods, contributing significantly to the understanding of how deep learning has been applied and adapted for this task. Their work highlights both progress and challenges in the field, offering a nuanced view of the current landscape.
Singh et al. [
12] conducted a comparative study of machine learning-based image captioning models, providing a critical analysis of various approaches’ strengths and weaknesses. This comparative perspective is crucial for understanding the diverse methodologies within the field. Suresh et al. [
13] examined encoder–decoder models in image captioning, focusing on the combination of CNN and RNN architectures. Their study offers insights into the efficiency and effectiveness of these models, contributing to a deeper understanding of architectural choices in image captioning.
Yu et al. [
14] explored automated testing methods for image captioning systems, proposing methodologies to ensure system reliability. This work addresses a crucial aspect of image captioning technology, emphasizing the importance of robust testing and evaluation. Lyu et al. [
15] developed an end-to-end image captioning model based on reduced feature maps of deep learners pre-trained for object detection, streamlining the captioning process and leading to more efficient image understanding. Stefanini et al. [
16] surveyed deep learning-based image captioning, offering a comprehensive overview of methodologies and their evolution. Their work presents a valuable compilation of state-of-the-art techniques and directions for future research in the field.
Lian et al. [
17] introduced a cross-modification attention-based model for image captioning, enhancing the process by dynamically modifying attention mechanisms. This novel approach contributes to a more nuanced understanding and generation of image captions. Parvin et al. [
18] proposed a transformer-based local–global guidance system for image captioning, an innovative method that improved captioning accuracy by incorporating both local and global contextual cues. Hu et al. [
19] developed the MAENet, a multi-head association attention enhancement network, which significantly contributed to completing intra-modal interaction in image captioning. This work enhances the model’s ability to understand and describe complex images.
Zeng et al. [
20] introduced the Progressive Tree-Structured Prototype Network for end-to-end image captioning, representing a significant advancement in developing efficient and accurate captioning systems. Wang et al. [
21] explored dynamic-balanced double-attention fusion for image captioning, an approach that led to improved accuracy and context-awareness in caption generation. This method balances attention mechanisms in a novel way, enhancing the quality of generated captions. Mishra et al. [
22] proposed a dynamic convolution-based encoder–decoder framework for image captioning in Hindi, advancing the field in handling low-resource languages. Their method focused on Hindi caption generation and demonstrated the effectiveness of dynamic convolution in image encoding.
Wu et al. [
23] examined the improvement of low-resource captioning via multi-objective optimization. Their work addressed the unique challenges of captioning in low-resource languages by exploiting both triplet and paired datasets, representing a significant contribution to the field. Roy and PK [
24] developed a deep ensemble network for sentiment analysis in bilingual low-resource languages, addressing the challenges of sentiment analysis in languages like Kannada and Malayalam. This approach fills a significant gap in the field by developing models that can handle the complexities of low-resource languages.
FHA et al. [
25] focused on detecting mixed social media data with Tamil-English code using machine learning techniques. Their study provided an efficient method to detect hate speech, contributing to the field of automated content moderation and demonstrating the effectiveness of machine learning algorithms in this context. Balakrishnan et al. [
26] compared supervised and unsupervised learning approaches for Tamil offensive language detection. Their novel work highlighted the effectiveness of machine learning algorithms in detecting offensive language in low-resourced languages, showing that unsupervised clustering can be more effective than human labeling.
Kumar et al. [
27] worked on English to Tamil multi-modal image captioning translation. Their research bridged the gap between English and Tamil, demonstrating the feasibility of cross-lingual image captioning and representing a significant step in the field of multi-modal translation. Gao et al. [
28] improved image captioning via enhancing dual-side context awareness. Their approach to integrating different context types led to a significant improvement in caption quality, especially in complex scenes, offering a more nuanced understanding of context in image captioning.
Wang et al. [
29] developed an image captioning system with adaptive incremental global context attention. This innovation allowed for more accurate and contextually rich captions, especially in complex scenes, demonstrating the potential of adaptive attention mechanisms in improving the quality of captions. Mishra et al. [
30] proposed a dense image captioning model in Hindi. Their approach leveraged both computer vision and natural language processing to generate localized captions for multiple image regions, addressing the need for dense captioning in low-resource languages.
Rajendran et al. [
31] explored Tamil NLP technologies, outlining the challenges, state of the art, trends, and future scope. Their work provided a comprehensive overview of the advancements and future directions in Tamil language processing, offering valuable insights into the development of NLP technologies for under-resourced languages. V and S [
9] advanced cross-lingual sentiment analysis with their innovative Multi-Stage Deep Learning Architecture (MSDLA), specifically focusing on the Tamil language. Addressing the challenges inherent to low-resource languages, their approach utilized transfer learning from resource-rich languages to overcome the limitations of scarce data and complex linguistic features in Tamil. The model’s efficacy was highlighted by its impressive performance on the Tamil Movie Review dataset, where it achieved notable accuracy, precision, recall, and F1-scores. This research not only marks a significant advancement in sentiment analysis for Tamil but also sets a precedent for developing robust models for other low-resource languages, offering vital insights and methodologies for future explorations in the field.
Existing research in the domain of image captioning has seen substantial advancements, particularly with the introduction of deep learning architectures and attention mechanisms. However, several gaps remain unaddressed. First, most current models lack the ability to dynamically adapt to varying types of images and contexts, which results in captions that may be accurate but are not necessarily contextually rich or meaningful. Second, while there has been some progress in extending image captioning techniques to low-resource languages, these approaches often do not account for the unique linguistic and contextual complexities such languages present. Finally, the computational efficiency of dynamically adaptive models remains a challenge that has not been thoroughly explored.
The proposed DCAT model is designed to bridge these research gaps. By introducing a dynamic context-aware mechanism, it adapts to different types of images and contexts, thereby generating more descriptive and contextually relevant captions. The model is specifically fine-tuned for the Tamil language, addressing the scarcity of research in image captioning for low-resource languages. Furthermore, the proposed DCAT provides a step forward in balancing performance and computational efficiency, opening the door for future optimization strategies.
6. Conclusions and Future Work
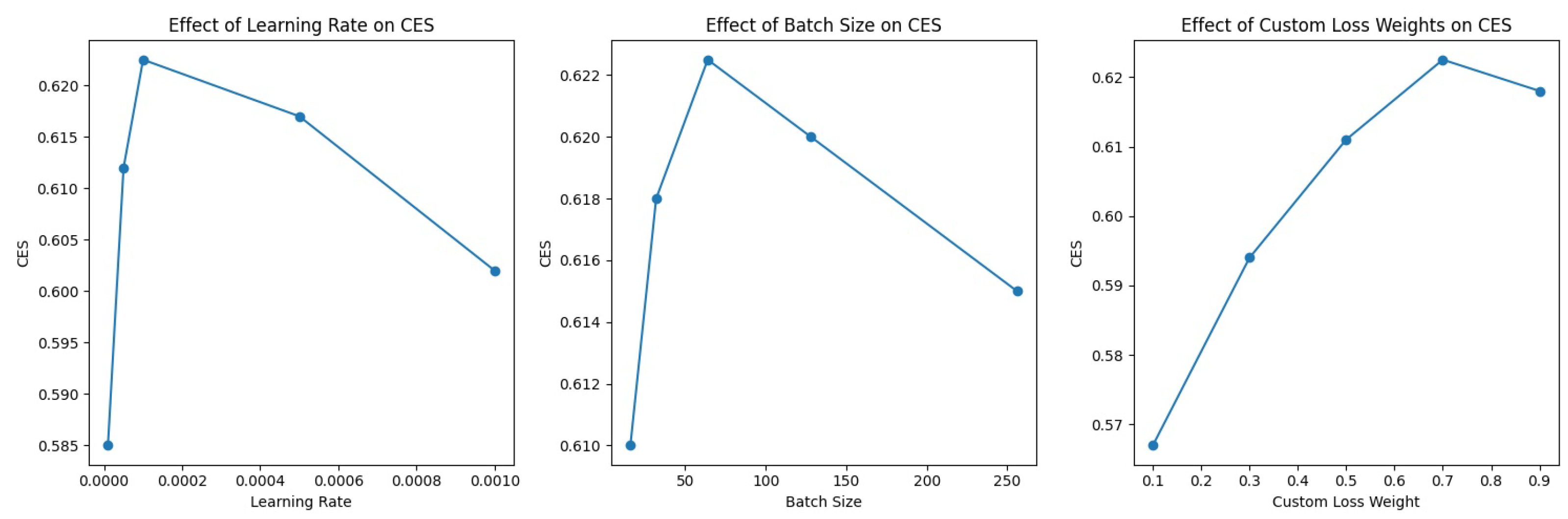
In this research, we proposed the Dynamic Context-Aware Transformer (DCAT), a novel image captioning model tailored for the Tamil language. DCAT distinguishes itself by integrating a Vision Transformer (ViT) as the encoder and a Generative Pre-trained Transformer (GPT-3) as the decoder, bridged effectively by a specialized Context Embedding Layer. This architecture is a significant innovation in addressing the challenges of image captioning in low-resource languages, particularly in handling the intricacies of Tamil. Our experimental results validate the efficacy of DCAT. The model achieves superior performance with a BLEU score of 0.7425, METEOR score of 0.4391, Composite Evaluation Score (CES) of 0.6279, and Contextual Accuracy (CA) of 0.4182 on the Flickr8k dataset. It consistently outperforms existing models in these metrics across diverse datasets, including Flickr30k and MSCOCO. The model’s ability to dynamically model context, both spatially and temporally, underlines its innovative approach. Despite its strengths, DCAT faces limitations in computational intensity and scalability. The model’s complexity demands significant computational resources, posing challenges in terms of efficiency and broader applicability.
Looking ahead, our future work will focus on addressing these limitations. We aim to reduce the computational demands of DCAT without sacrificing its performance. Strategies under consideration include model pruning, quantization, and exploring more efficient architectural designs. Additionally, we plan to extend the model’s capabilities to other languages and multimodal tasks. Applications in video captioning and question-answering represent exciting frontiers for DCAT’s technology. Further research will also tackle the challenges of data biases and model interpretability, ensuring that DCAT not only performs efficiently but also remains fair and understandable in its operations. Through these endeavors, we anticipate making DCAT a more versatile and accessible tool for natural language processing and computer vision tasks, paving the way for broader applications in AI-driven content generation and analysis.


 ,
, 


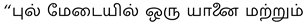
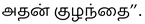
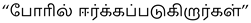 (Poril Eerkkapadugirargal). A more precise translation would be “சண்டையில் ஈடுபடுகின்றன ” (Sandaiyil Eedupaduginrana), which better conveys the playful nature of the dogs’ interaction.
(Poril Eerkkapadugirargal). A more precise translation would be “சண்டையில் ஈடுபடுகின்றன ” (Sandaiyil Eedupaduginrana), which better conveys the playful nature of the dogs’ interaction.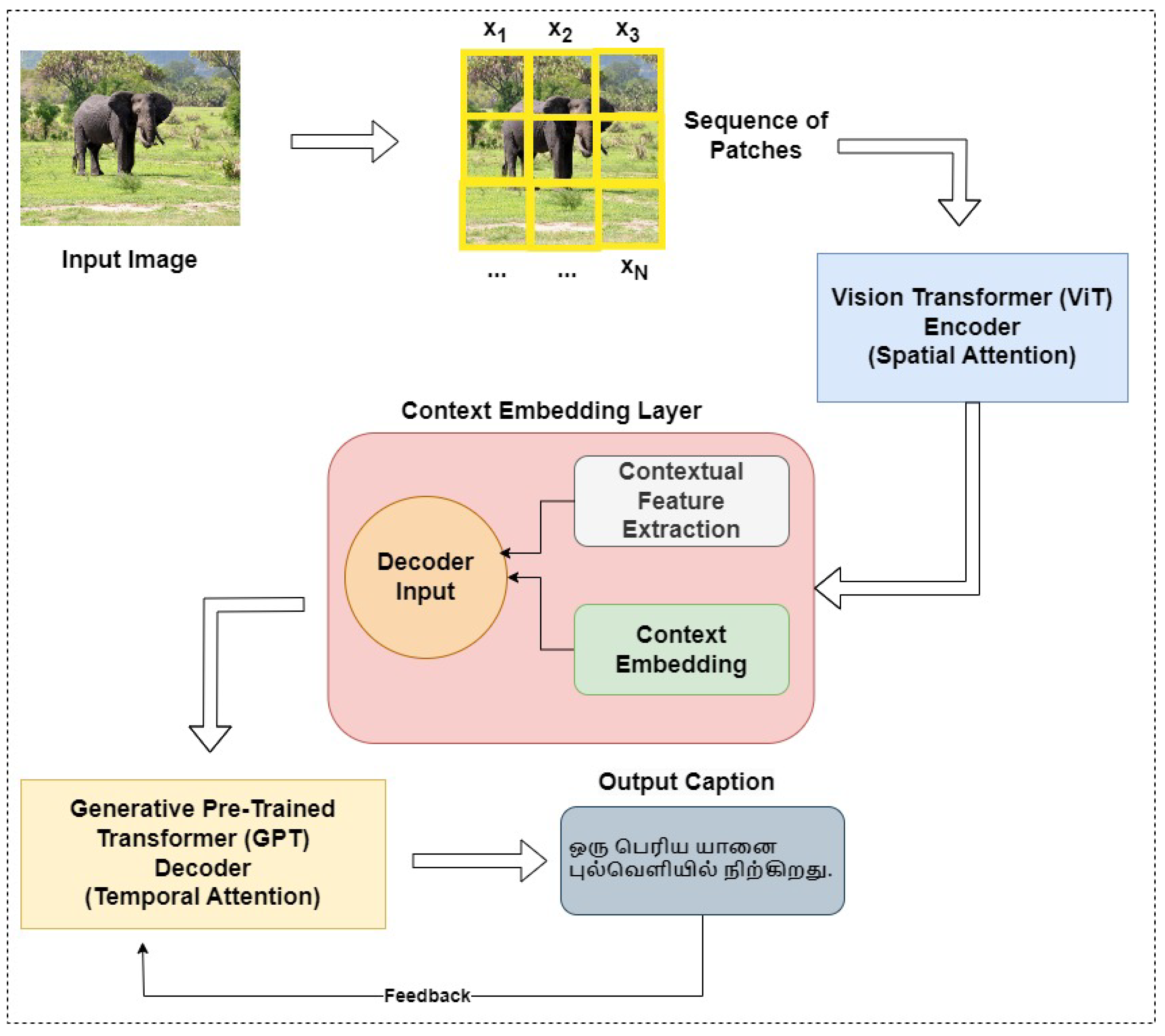



{kind=link}
{kind=link}
{kind=link}
{kind=link}