



Research on the Method of Crop Pest and Disease Recognition Based on the Improved YOLOv7-U-Net Combined Network


Abstract
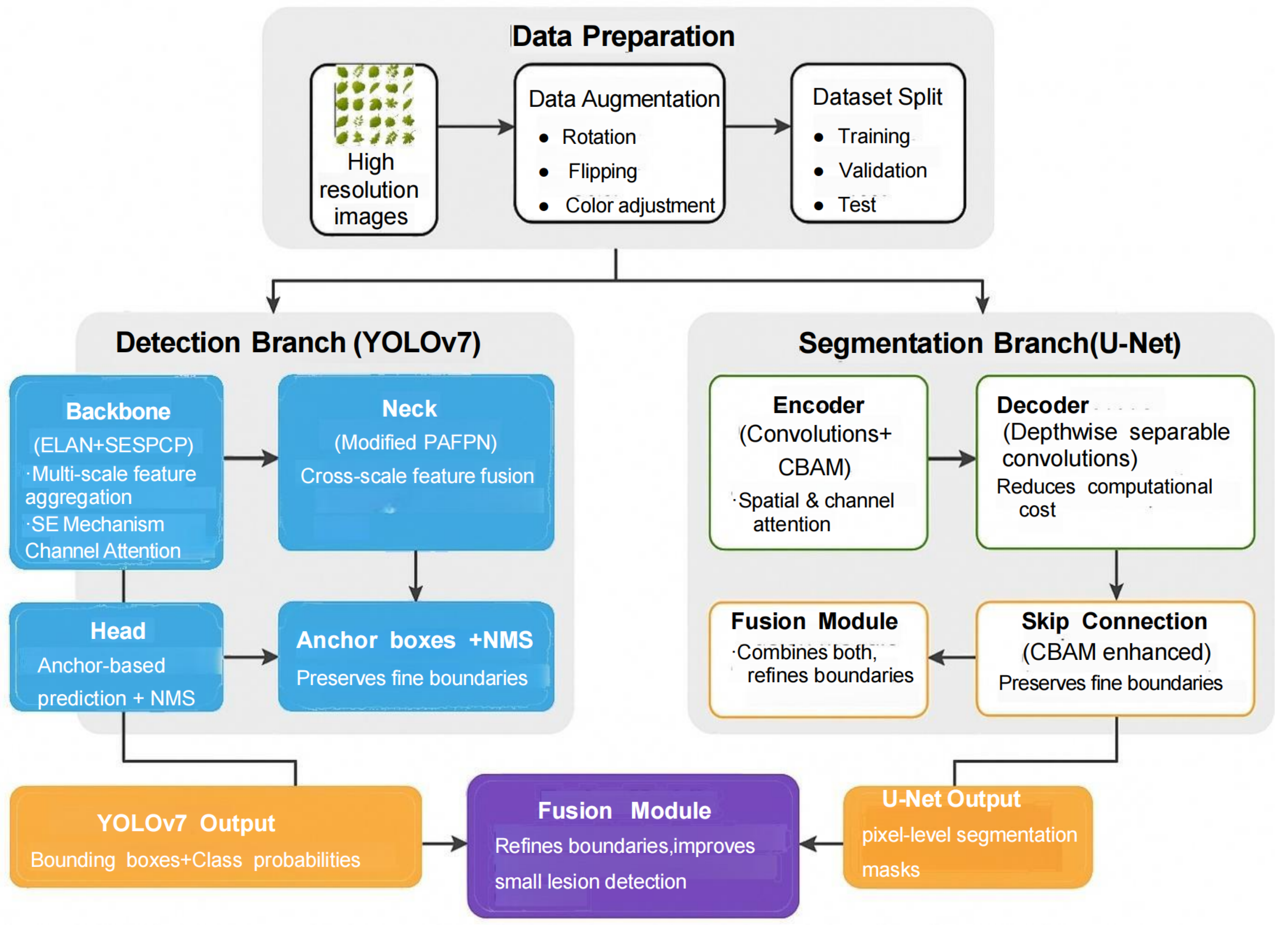
1. Introduction
2. YOLOv7 Network and Improvement Methods
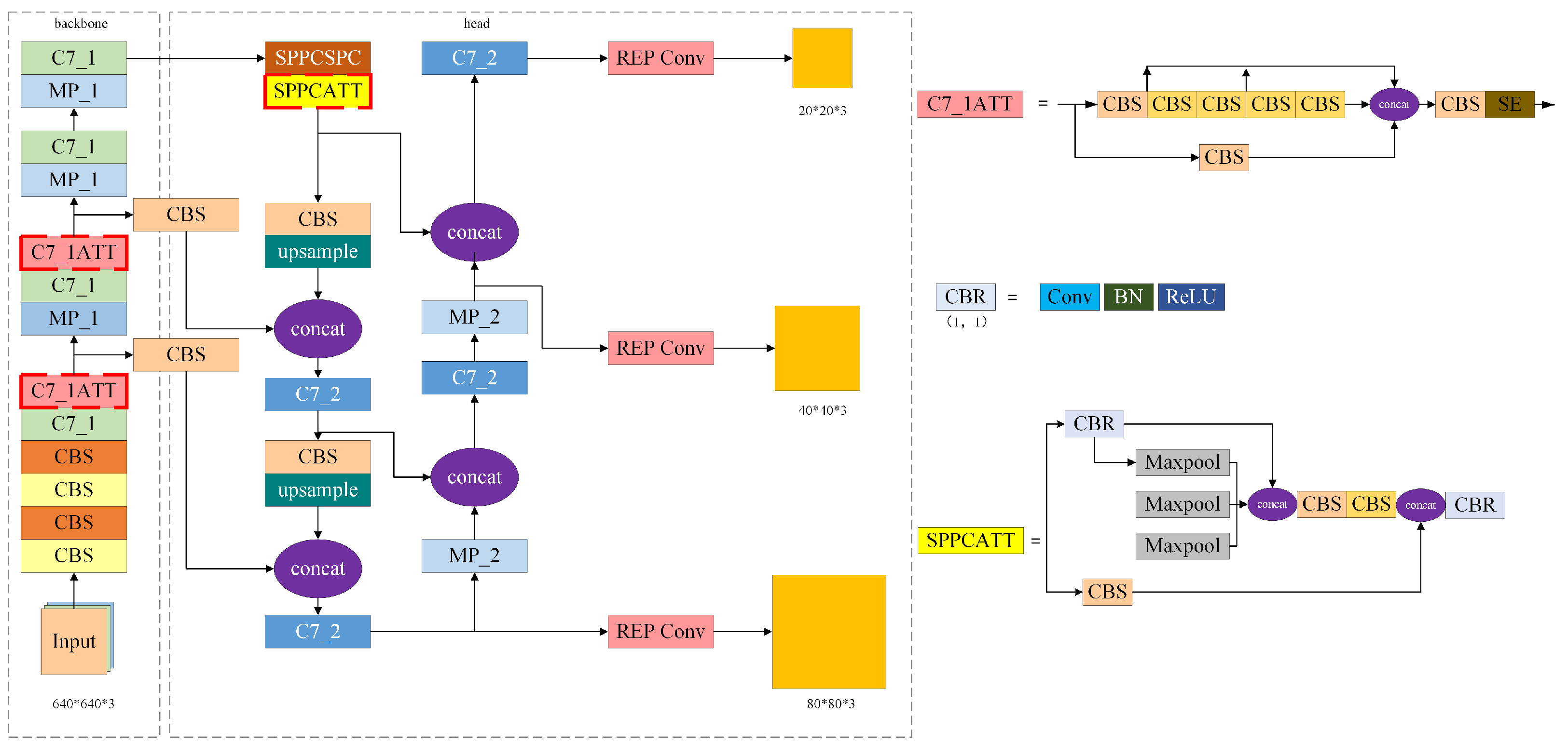
2.1. YOLOv7 Model Structure
2.2. SE Block
2.3. Improved YOLOv7 Structure
3. U-Net Model and Network Structure Improvement
3.1. U-Net Model Structure
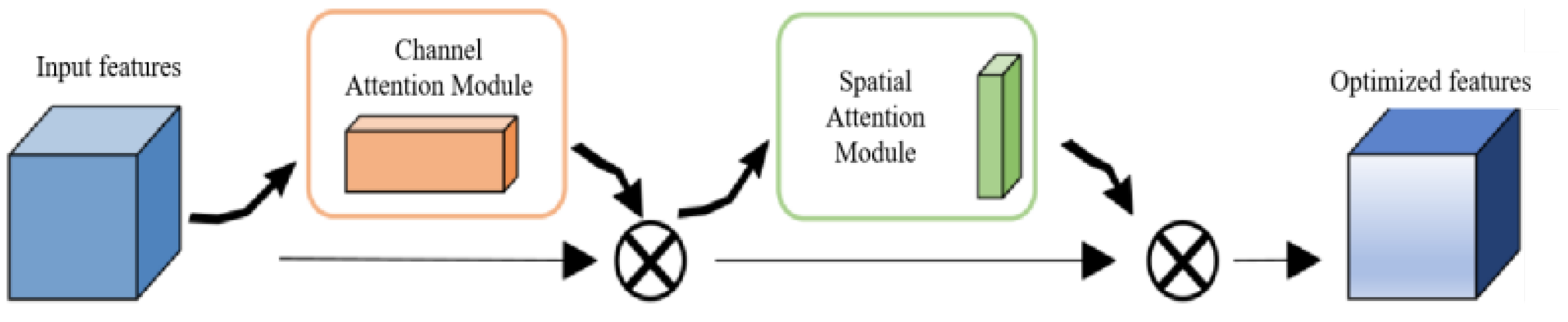
3.2. CBAM Attention Mechanism
3.3. Improved U-Net Model Structure
4. Experiments and Analysis of Results
4.1. Experimental Setup
4.2. Dataset Construction and Preprocessing
4.3. Evaluation Metrics
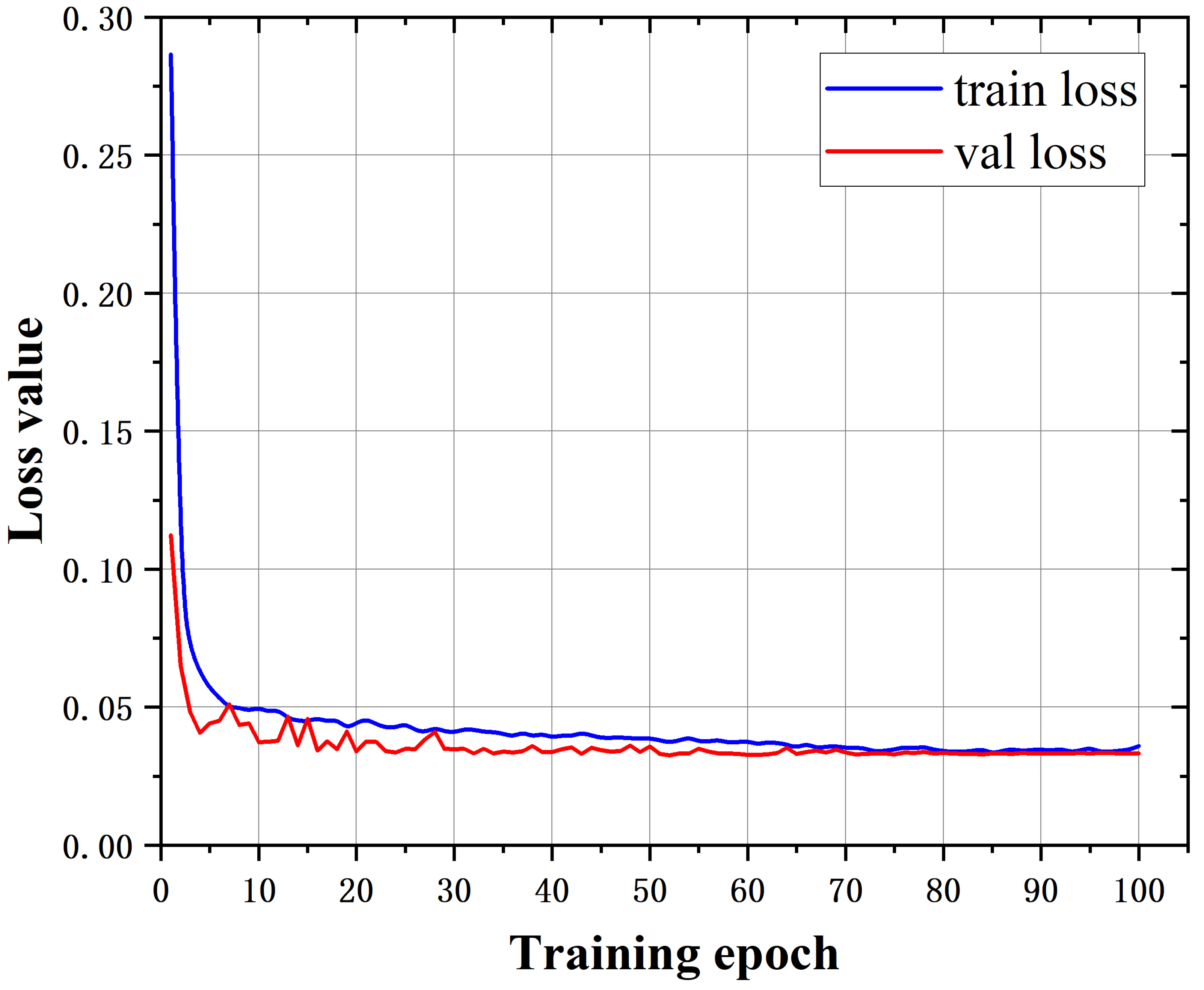
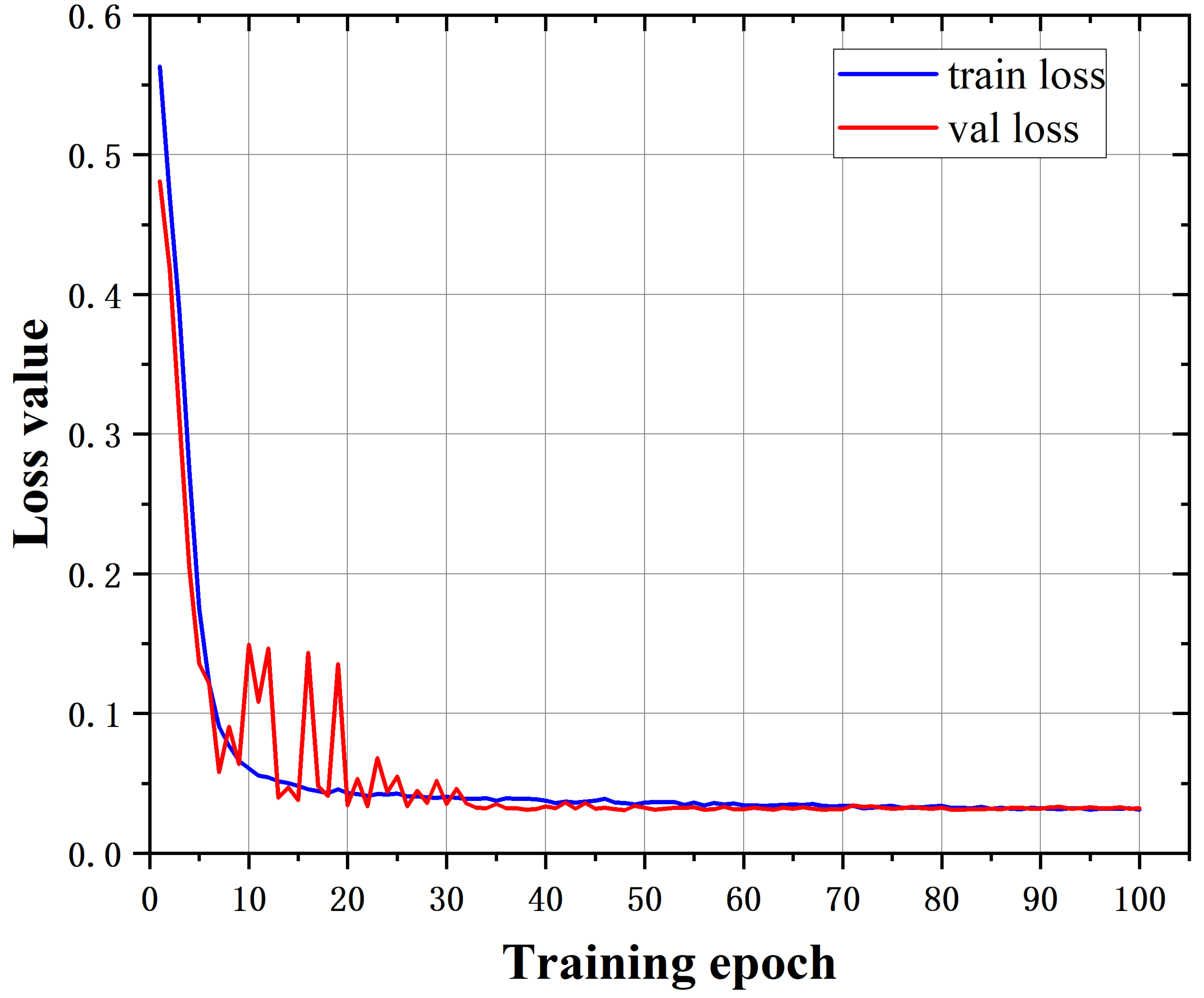
4.4. Ablation Studies
4.5. Comparative Experiments
4.6. Field Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, J.; Wang, R.; Yang, L.; Lv, X.; Yang, Z.; Zhang, K.; Zhou, C.; Li, P.; Wang, Z.; Abdullah, A.; et al. Quantitative Estimation of Wheat Stripe Rust Disease Index Using Unmanned Aerial Vehicle Hyperspectral Imagery and Innovative Vegetation Indices. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4406111. [Google Scholar] [CrossRef]
- Angon, P.B.; Mondal, S.; Jahan, I.; Datto, M.; Antu, U.B.; Ayshi, F.J.; Islam, M.S. Integrated pest management (IPM) in agriculture and its role in maintaining ecological balance and biodiversity. Adv. Agric. 2023, 2023, 5546373. [Google Scholar] [CrossRef]
- Rossi, V.; Caffi, T.; Salotti, I.; Fedele, G. Sharing decision-making tools for pest management may foster implementation of Integrated Pest Management. Food Secur. 2023, 15, 1459–1474. [Google Scholar] [CrossRef]
- Ahmed, M.Z.; Hasan, A.; Rubaai, K.; Hasan, K.; Pu, C.; Reed, J.H. Deep Learning Assisted Channel Estimation for Cell-Free Distributed MIMO Networks. In Proceedings of the 19th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Montreal, QC, Canada, 21–23 June 2023; pp. 344–349. [Google Scholar]
- Deng, J.; Zhou, H.; Lv, X.; Yang, L.; Shang, J.; Sun, Q.; Zheng, X.; Zhou, C.; Zhao, B.; Wu, J.; et al. Applying convolutional neural networks for detecting wheat stripe rust transmission centers under complex field conditions using RGB-based high spatial resolution images from UAVs. Comput. Electron. Agric. 2022, 200, 107211. [Google Scholar] [CrossRef]
- Smith, A.B. Transformer-based Multi-scale Feature Aggregation for Crop Disease Detection. Nat. Mach. Intell. 2024, 6, 123–134. [Google Scholar]
- Zhao, Z.-X.; Wu, X.-P.; Wang, Y.-X. Research on knowledge graph-based question and answer system for crop pests and diseases. J. Intell. Agric. Equip. 2024, 5, 39–50. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Geudtner, D.; Tossaint, M.; Davidson, M.; Torres, R. Copernicus Sentinel-1 Next Generation Mission. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 874–876. [Google Scholar]
- Hu, T.; Du, J.; Yan, K.; Dong, W.; Zhang, J.; Wang, J.; Xie, C. Causality-inspired crop pest recognition based on Decoupled Feature Learning. Pest Manag. Sci. 2024, 80, 5832–5842. [Google Scholar] [CrossRef] [PubMed]
- Li, A.-Q.; Ma, L.; Yu, H.-L.; Zhang, H.-B. Research on the classification of typical crops in remote sensing images by improved U-Net algorithm. Infrared Laser Eng. 2022, 51, 20210868. [Google Scholar]
- Ferro, M.V.; Sørensen, C.G.; Catania, P. Comparison of different computer vision methods for vineyard canopy detection using UAV multispectral images. Comput. Electron. Agric. 2024, 225, 109277. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018. [Google Scholar]
- Si, C.; Huang, Z.; Jiang, Y.; Liu, Z. FreeU: Free Lunch in Diffusion U-Net. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 4733–4743. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar]
- Johnson, C.D. Adaptive Attention Mechanisms in U-Net for Hyperspectral Crop Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 56789. [Google Scholar]
- Jia, J.; Lei, R.; Qin, L.; Wei, X. i5mC-DCGA: An improved hybrid network framework based on the CBAM attention mechanism for identifying promoter 5mC sites. BMC Genom. 2024, 25, 242. [Google Scholar] [CrossRef] [PubMed]
- Brown, G.H. Synthetic Data Generation for Small Lesion Detection in Precision Agriculture. Remote Sens. Environ. 2024, 292, 113654. [Google Scholar]
- Wang, E.F. YOLOv8: Scalable Real-Time Object Detection with Dynamic Anchor Optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 678–687. [Google Scholar]
- Davis, J.K. Cross-domain Generalization for Crop Pest Recognition under Variable Lighting. Comput. Electron. Agric. 2023, 208, 107654. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison Dimension | Original YOLOv7 | Modified YOLOv7 |
|---|---|---|
| Channel Processing | Direct channel concatenation | SE self-attention module for adaptive channel weighting |
| Feature Fusion | Standard PAFPN | Enhanced cross-scale connections in PAFPN for small object optimization |
| Attention Mechanism | None | SE module integration in SPPCSPC for minority class focus |
| Structural Innovation | - | 1. SE module embedded in neck for channel recalibration. 2. PAFPN augmented with bidirectional cross-scale links |
| Metric | YOLOv7-Only | U-Net-Only | Combined Model |
|---|---|---|---|
| mAP@0.5 | 95.35% | 91.48% | 96.91% |
| IoU@0.5 | 89.47% | 90.12% | 92.14% |
| Dice Coefficient | - | 88.23% | 91.76% |
| F1-Score (per pixel) | - | 89.58% | 92.45% |
| FPS | 87.48 | 58.32 | 90.41 |
| Recall | 94.73% | 90.25% | 97.31% |
| Arithmetic | P (%) | R (%) | mAP (%) | FPS |
|---|---|---|---|---|
| Faster R-CNN | 83.23 | 54.33 | 55.92 | 14.58 |
| SSD | 84.29 | 26.47 | 48.53 | 23.39 |
| YOLOv5 | 88.65 | 68.36 | 74.96 | 73.72 |
| YOLOX | 93.92 | 94.53 | 93.81 | 85.06 |
| YOLOv7 | 95.11 | 94.73 | 95.35 | 87.48 |
| YOLOv9 | 96.23 | 95.87 | 95.32 | 85.21 |
| YOLOv12 | 96.81 | 96.54 | 96.18 | 82.45 |
| DETR3D | 94.12 | 93.56 | 92.89 | 18.34 |
| Swin Transformer | 95.07 | 94.21 | 93.78 | 22.19 |
| The algorithms in this paper | 97.49 | 97.31 | 96.91 | 90.41 |
| Model | Accuracy | F1-Score | Params | Inference Time (ms) |
|---|---|---|---|---|
| ResNet-50 | 89.23% | 88.47% | 25.6 M | 12.4 |
| VGG-16 | 85.18% | 84.35% | 138.4 M | 21.7 |
| EfficientNet-B3 | 91.56% | 90.82% | 12.3 M | 8.9 |
| YOLOv7 | 94.73% | 93.91% | 37.8 M | 11.4 |
| Combined Model | 96.25% | 95.84% | 52.1 M | 13.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, W.; Du, Z.; Liu, X.; Lu, Z.; Yin, Y. Research on the Method of Crop Pest and Disease Recognition Based on the Improved YOLOv7-U-Net Combined Network. Appl. Sci. 2025, 15, 4864. https://doi.org/10.3390/app15094864
Xiang W, Du Z, Liu X, Lu Z, Yin Y. Research on the Method of Crop Pest and Disease Recognition Based on the Improved YOLOv7-U-Net Combined Network. Applied Sciences. 2025; 15(9):4864. https://doi.org/10.3390/app15094864
Chicago/Turabian StyleXiang, Wenchao, Zitao Du, Xinran Liu, Zehui Lu, and Yuna Yin. 2025. "Research on the Method of Crop Pest and Disease Recognition Based on the Improved YOLOv7-U-Net Combined Network" Applied Sciences 15, no. 9: 4864. https://doi.org/10.3390/app15094864
APA StyleXiang, W., Du, Z., Liu, X., Lu, Z., & Yin, Y. (2025). Research on the Method of Crop Pest and Disease Recognition Based on the Improved YOLOv7-U-Net Combined Network. Applied Sciences, 15(9), 4864. https://doi.org/10.3390/app15094864