
Estimation of River Velocity and Discharge Based on Video Images and Deep Learning


Abstract
1. Introduction
2. Theory and Methods
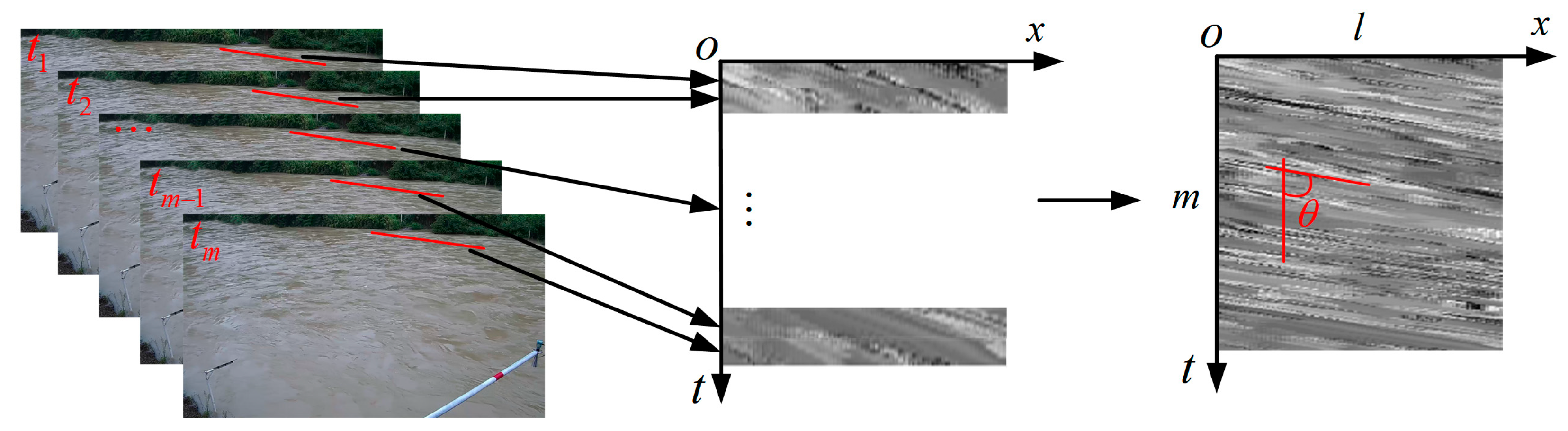
2.1. Generation of Space-Time Images
2.2. Construction of Datasets
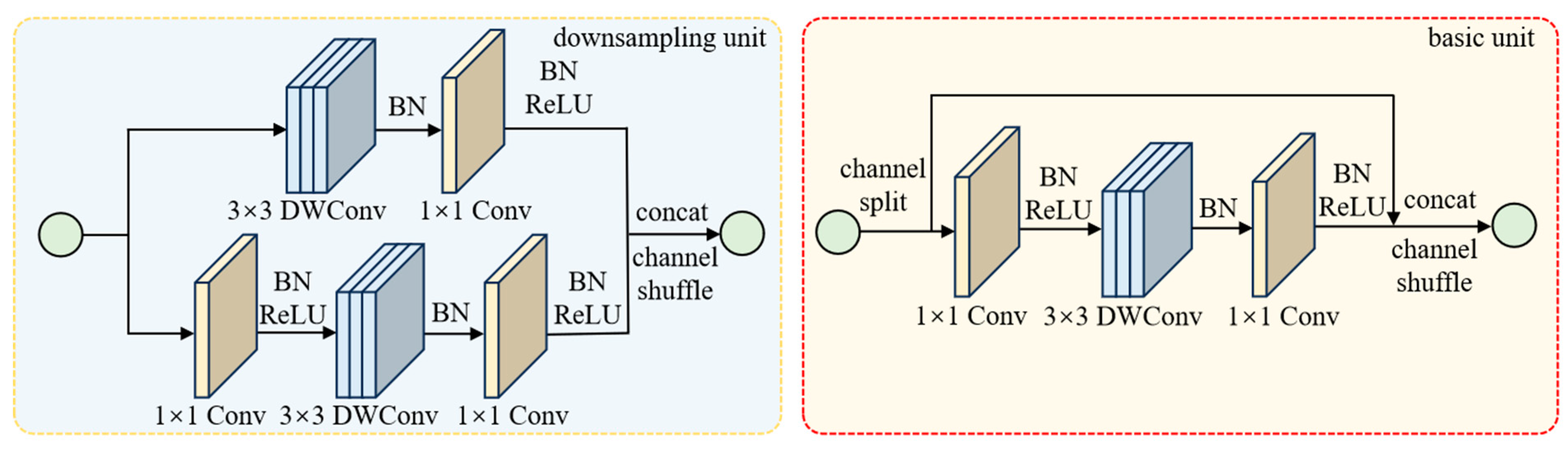
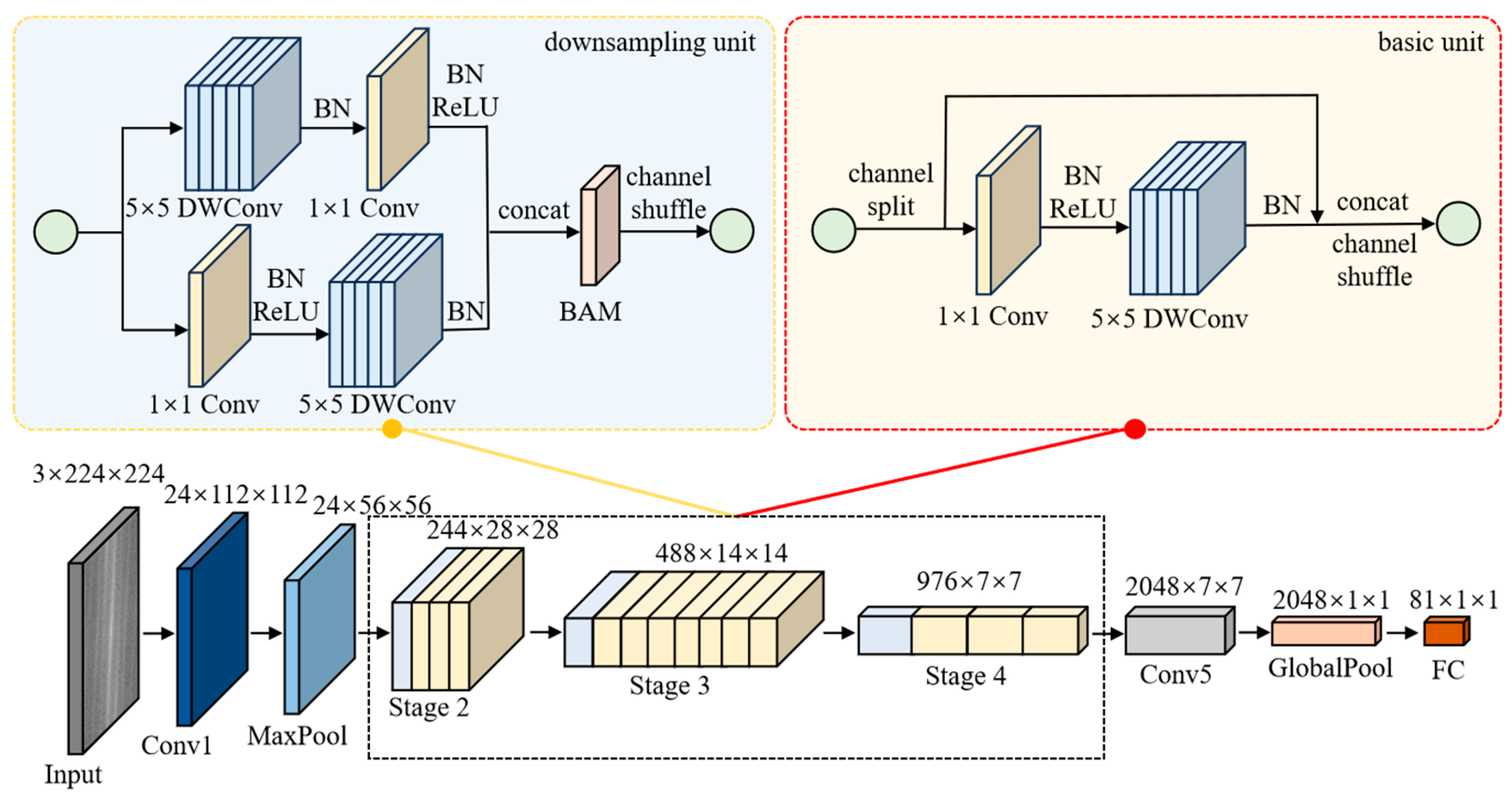
2.3. Structure of ShuffleNetV2
2.4. Improvement of ShuffleNetV2
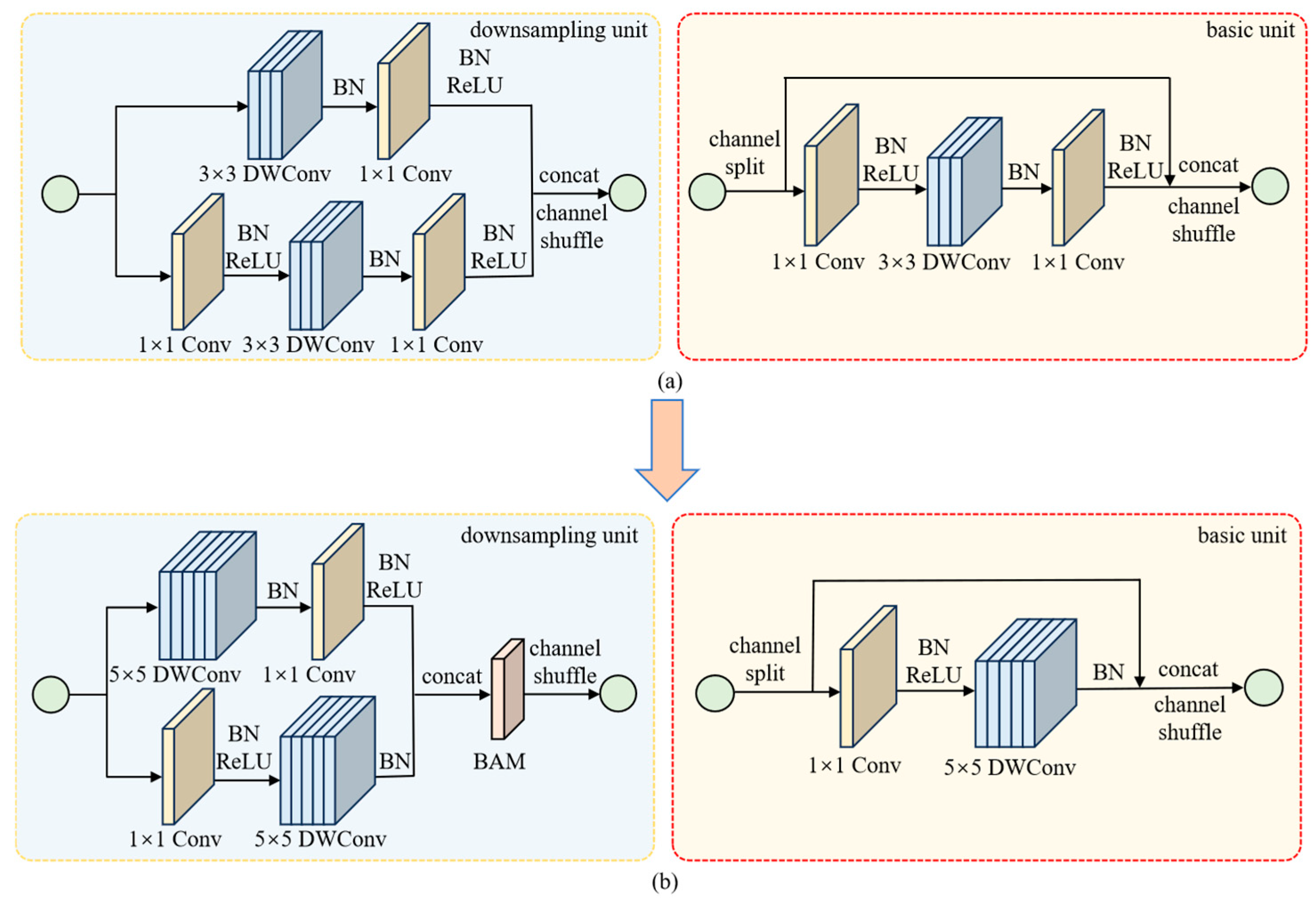
2.4.1. Delete the Second Convolution and Enlarge DWConv Kernel Size
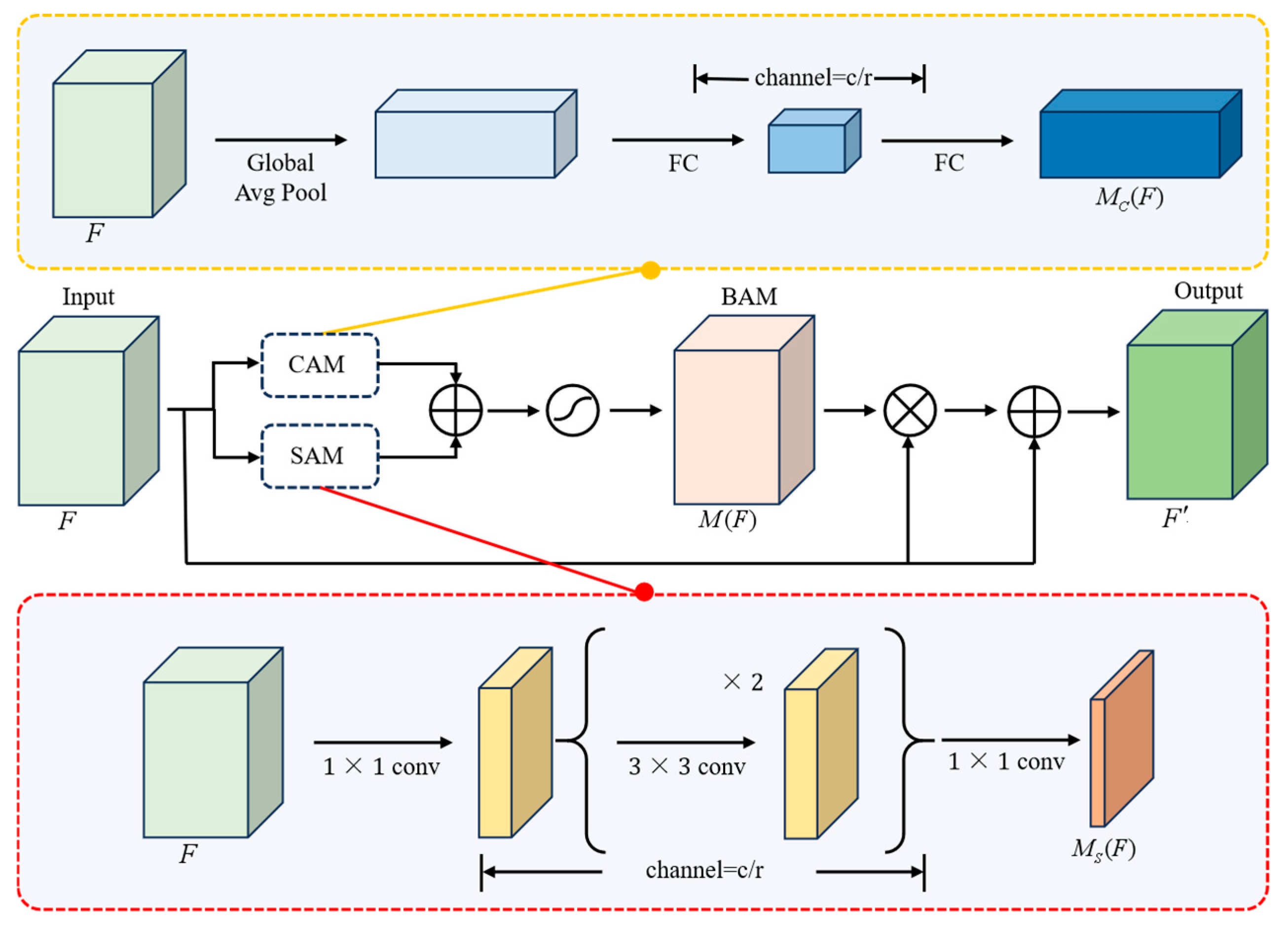
2.4.2. Bottleneck Attention Module (BAM)
2.5. Camera Calibration
2.6. Calculation of River Velocity and Discharge
3. Results and Discussion
3.1. Model Training
3.2. Model Performance Comparison
3.2.1. Comparison of ShuffleNetV2 Series Models
3.2.2. Ablation Experiment
3.2.3. Comparison of Different Network Models
3.3. Experiments in the Measurement of River Velocity and Discharge
3.3.1. Experiment in an Artificially Repaired River
3.3.2. Experiment in Natural Rivers
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ju, Z. Research on River Velocity Measurement Based on Video and Image Recognition. Master’s Thesis, Zhejiang University of Technology, Hangzhou, China, 2018. [Google Scholar]
- Kimiaghalam, N.; Goharrokhi, M.; Clark, S.P. Assessment of wide river characteristics using an acoustic Doppler current profiler. J. Hydrol. Eng. 2016, 21, 06016012. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, Z.; Yan, X.; Wang, H.; Wang, X. Advances of Non-contact Instruments and Techniques for Open-channel Flow Measurements. Water Resour. Inform. 2013, 3, 37–44. [Google Scholar]
- Yang, D.; Shao, G.; Hu, W.; Liu, G.; Liang, J.; Wang, H.; Xu, C. Review of image-based river surface velocimetry research. J. Zhejiang Univ. Sci. 2021, 55, 1752–1763. [Google Scholar]
- Adrian, R.J. Scattering particle characteristics and their effect on pulsed laser measurements of fluid flow: Speckle velocimetry vs particle image velocimetry. Appl. Opt. 1984, 23, 1690–1691. [Google Scholar] [CrossRef] [PubMed]
- Fujita, I.; Muste, M.; Kruger, A. Large-scale particle image velocimetry for flow analysis in hydraulic engineering applications. J. Hydraul. Res. 1998, 36, 397–414. [Google Scholar] [CrossRef]
- Khalid, M.; Pénard, L.; Mémin, E. Optical flow for image-based river velocity estimation. Flow Meas. Instrum. 2019, 65, 110–121. [Google Scholar] [CrossRef]
- Fujita, I.; Tsubaki, R. A Novel Free-Surface Velocity Measurement Method Using Spatio-Temporal Images. In Proceedings of the 2002 Hydraulic Measurements and Experimental Method Specialty Conference, Estes Park, CO, USA, 28 July–1 August 2002; pp. 1–7. [Google Scholar]
- Fujita, I.; Watanabe, H.; Tsubaki, R. Development of a non-intrusive and efficient flow monitoring technique: The space-time image Velocimetry (STIV). Int. J. River Basin Manag. 2007, 5, 105–114. [Google Scholar] [CrossRef]
- Fujita, I.; Notoya, Y.; Tani, K.; Tateguchi, S. Efficient and accurate estimation of water surface velocity in STIV. Environ. Fluid Mech. 2019, 19, 1363–1378. [Google Scholar] [CrossRef]
- Zhen, Z.; Huabao, L.; Yang, Z.; Jian, H. Design and evaluation of an FFT-based space-time image velocimetry (STIV) for time-averaged velocity measurement. In Proceedings of the 2019 14th IEEE International Conference on Electronic Measurement & Instruments, Changsha, China, 1–3 November 2019; pp. 503–514. [Google Scholar]
- Zhao, H.; Chen, H.; Liu, B.; Liu, W.; Xu, C.Y.; Guo, S.; Wang, J. An improvement of the Space-Time Image Velocimetry combined with a new denoising method for estimating river discharge. Flow Meas. Instrum. 2021, 77, 101864. [Google Scholar] [CrossRef]
- Lu, J.; Yang, X.; Wang, J. Velocity Vector Estimation of Two-Dimensional Flow Field Based on STIV. Sensors 2023, 23, 955. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Che, G.; Wang, C.; Yang, X.; Wang, J. River video flow measurement algorithm with space-time image fusion of object tracking and statistical characteristics. Meas. Sci. Technol. 2024, 35, 055301. [Google Scholar] [CrossRef]
- Watanabe, K.; Fujita, I.; Iguchi, M.; Hasegawa, M. Improving Accuracy and Robustness of Space-Time Image Velocimetry (STIV) with Deep Learning. Water 2021, 13, 2079. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Z.; Chen, L.; Meng, J.; Sun, Y.; Cui, W. Surface space-time image velocimetry of river based on residual network. J. Hohai Univ. 2023, 51, 118–128. [Google Scholar]
- Huang, Y.; Chen, H.; Huang, K.; Chen, M.; Wang, J.; Liu, B. Optimization of Space-Time image velocimetry based on deep residual learning. Measurement 2024, 232, 114688. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, H.; Yuan, Z.; Dong, R.; Wang, J. Sensitivity analysis of image filter for space-time image velocimetry in frequency domain. Chin. J. Sci. Instrum. 2022, 43, 43–53. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNetV2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- GB 50179-2015; Code for Liquid Flow Measurement in Open Channels. Beijing China Planning Publishing House: Beijing, China, 2015. (In Chinese)
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Wang, J.; Zhu, R.; Zhang, G.; He, X.; Cai, R. Image Flow Measurement Based on the Combination of Frame Difference and Fast and Dense Optical Flow. Adv. Eng. Sci. 2022, 54, 195–207. [Google Scholar]
- Kroeger, T.; Timofte, R.; Dai, D.; Van Gool, L. Fast optical flow using dense inverse search. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 471–488. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Image Class | Total | ||||
|---|---|---|---|---|---|---|
| Normal | Exposure | Turbulence | Blur | Synthetic | ||
| Train set/sheet | 810 | 810 | 810 | 1620 | 4050 | 8100 |
| Test set/sheet | 162 | 162 | 162 | 324 | 810 | 1620 |
| Total/sheet | 972 | 972 | 972 | 1944 | 4860 | 9720 |
| Model | TOP1/% | TOP5/% | Params/M | FLOPs/G |
|---|---|---|---|---|
| ShuffleNetV2_0.5 | 51.36 | 85.12 | 0.43 | 0.04 |
| ShuffleNetV2_1.0 | 53.09 | 85.86 | 1.35 | 0.16 |
| ShuffleNetV2_1.5 | 55.62 | 87.10 | 2.59 | 0.32 |
| ShuffleNetV2_2.0 | 58.70 | 89.81 | 5.56 | 0.63 |
| Model | Lite_1 × 1 | K_Size = 5 | BAM | TOP1/% | TOP5/% | Param/M | FLOPs/G |
|---|---|---|---|---|---|---|---|
| 0 | 58.70 | 89.81 | 5.56 | 0.63 | |||
| 1 | √ | 60.74 | 90.93 | 4.03 | 0.41 | ||
| 2 | √ | √ | 61.67 | 90.62 | 4.11 | 0.43 | |
| 3 | √ | √ | √ | 64.69 | 90.56 | 4.44 | 0.45 |
| Attention Mechanism | TOP1/% | TOP5/% | Params/M | FLOPs/G |
|---|---|---|---|---|
| - | 61.67 | 90.62 | 4.11 | 0.43 |
| ECA | 60.74 | 89.51 | 4.11 | 0.43 |
| CBAM | 61.17 | 88.64 | 4.42 | 0.43 |
| SE | 62.53 | 88.95 | 4.27 | 0.43 |
| BAM | 64.69 | 90.56 | 4.44 | 0.45 |
| Model | TOP1/% | TOP5/% | Param/M | FLOPs/G |
|---|---|---|---|---|
| ResNet34 | 64.14 | 90.74 | 21.37 | 3.68 |
| DenseNet | 62.35 | 90.00 | 7.04 | 2.90 |
| MobileNetV2 | 58.40 | 89.26 | 2.33 | 0.33 |
| EfficientNetV2 | 62.53 | 90.86 | 20.28 | 2.90 |
| GhostNetV1 | 58.21 | 87.35 | 4.01 | 0.15 |
| ShuffleNetV2 | 58.70 | 89.81 | 5.56 | 0.63 |
| Improved | 64.69 | 90.56 | 4.44 | 0.45 |
| Points | Starting Distance/(m) | Depth/(m) | Vertical Mean Velocity/(m/s) | Partial Mean Velocity/(m/s) | Partial Area/(m2) | Partial Discharge/(m3/s) |
|---|---|---|---|---|---|---|
| 0 (shore) | ||||||
| 0–2 | 0.52 | 1.22 | 0.59 | |||
| No. 1 | 2 | 0.54 | 0.69 | |||
| 2–4 | 0.83 | 1.01 | 0.84 | |||
| No. 2 | 4 | 0.48 | 0.97 | |||
| 4–6 | 0.97 | 0.96 | 0.93 | |||
| No. 3 | 6 | 0.48 | 0.97 | |||
| 6–8 | 0.97 | 0.99 | 0.96 | |||
| No. 4 | 8 | 0.51 | 0.97 | |||
| 8–10 | 0.92 | 1.02 | 0.94 | |||
| No. 5 | 10 | 0.53 | 0.87 | |||
| 10–12 | 0.75 | 1.18 | 0.89 | |||
| No. 6 | 12 | 0.60 | 0.63 | |||
| 12–14 | 0.66 | 1.28 | 0.85 | |||
| No. 7 | 14 | 0.61 | 0.69 | |||
| 14–16 | 0.64 | 1.16 | 0.74 | |||
| No. 8 | 16 | 0.53 | 0.58 | |||
| 16–18 | 0.55 | 1.05 | 0.58 | |||
| No. 9 | 18 | 0.48 | 0.52 | |||
| 18–20 | 0.46 | 1.01 | 0.47 | |||
| No. 10 | 20 | 0.52 | 0.40 | |||
| 20–23 | 0.30 | 1.24 | 0.37 | |||
| 23 (shore) | ||||||
| Cross–section area/(m2): 12.12 | ||||||
| Discharge/(m3/s): 8.19 | ||||||
| Mean velocity/(m/s): 0.68 | ||||||
| Indicators | Points | Measured Values/(m/s) | Relative Error/(%) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Current Meter | GTM | FFT | FD- DIS-G | New Method | GTM | FFT | FD- DIS-G | New Method | ||
| Vertical mean velocity /(m/s) | No. 1 | 0.69 | 0.60 | 0.75 | 0.05 | 0.81 | 13.04% | 8.70% | 92.75% | 17.39% |
| No. 2 | 0.97 | 0.91 | 1.19 | 0.15 | 1.00 | 6.19% | 22.68% | 84.54% | 3.09% | |
| No. 3 | 0.97 | 0.83 | 1.06 | 0.78 | 1.02 | 14.43% | 8.80% | 19.59% | 5.15% | |
| No. 4 | 0.97 | 0.87 | 1.04 | 1.48 | 0.93 | 10.31% | 7.22% | 52.58% | 4.12% | |
| No. 5 | 0.87 | 0.68 | 0.98 | 1.42 | 0.95 | 21.84% | 12.64% | 63.22% | 9.20% | |
| No. 6 | 0.63 | 0.53 | 0.53 | 1.26 | 0.74 | 15.87% | 15.87% | 100.00% | 17.46% | |
| No. 7 | 0.69 | 0.68 | 0.56 | 1.00 | 0.56 | 1.45% | 18.84% | 44.93% | 18.84% | |
| No. 8 | 0.58 | 0.65 | 0.51 | 0.90 | 0.51 | 12.07% | 12.07% | 55.17% | 12.07% | |
| No. 9 | 0.52 | 0.37 | 0.73 | 0.88 | 0.47 | 28.85% | 40.38% | 69.23% | 9.62% | |
| No. 10 | 0.40 | 0.24 | 0.64 | 0.60 | 0.44 | 40.00% | 60.00% | 50.00% | 10.00% | |
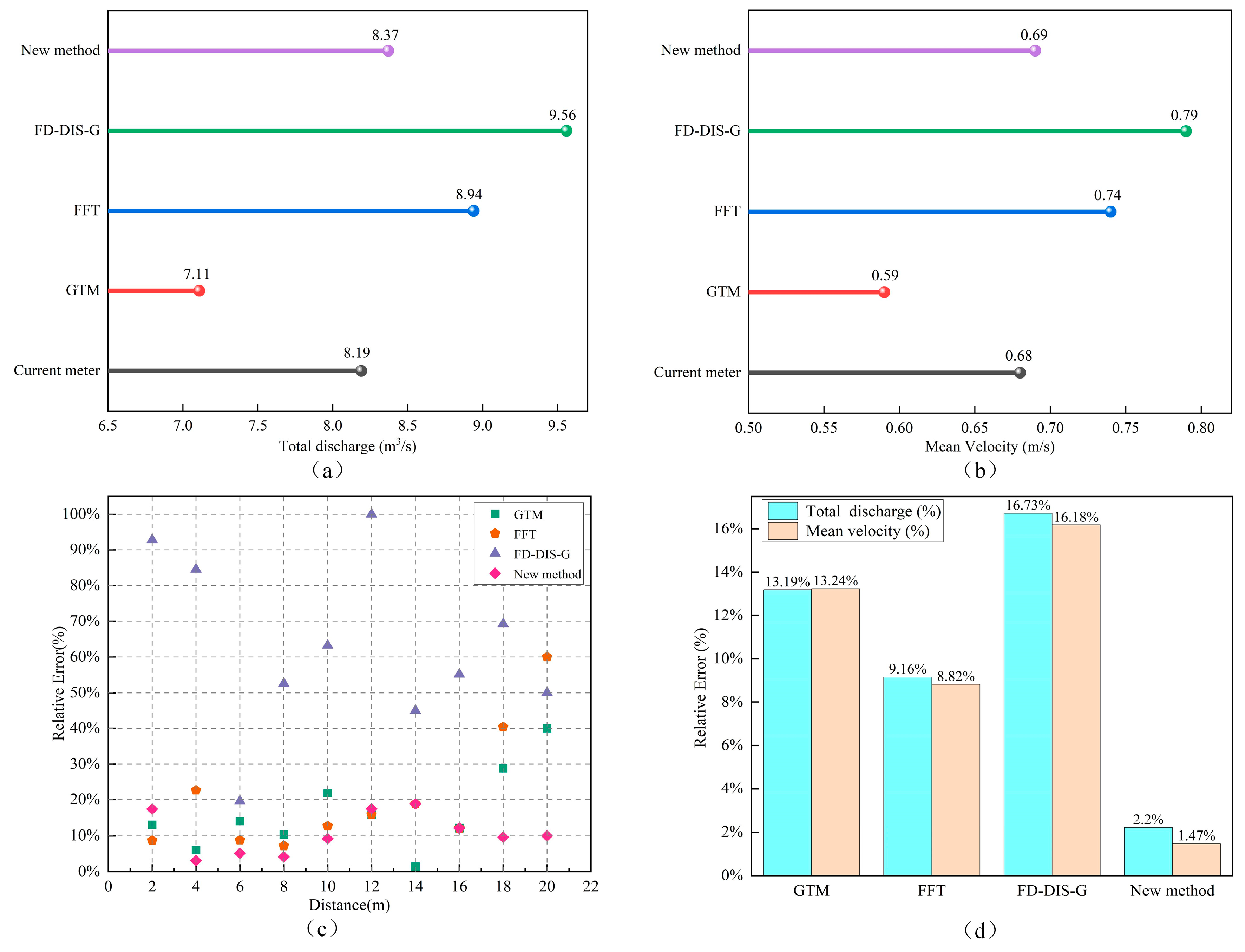
| Discharge/(m3/s) | 8.19 | 7.11 | 8.94 | 9.56 | 8.37 | 13.19% | 9.16% | 16.73% | 2.20% | |
| Mean velocity/(m/s) | 0.68 | 0.59 | 0.74 | 0.79 | 0.69 | 13.24% | 8.82% | 16.18% | 1.47% | |
| Points | Starting Distance/(m) | Depth/(m) | Vertical Mean Velocity/(m/s) | Partial Mean Velocity/(m/s) | Partial Area/(m2) | Partial Discharge/(m3/s) |
|---|---|---|---|---|---|---|
| 23.6 (shore) | ||||||
| 30–35 | 0.88 | 32.8 | 28.9 | |||
| No. 1 | 35 | 4.46 | 1.25 | |||
| 35–40 | 1.32 | 23.9 | 31.5 | |||
| No. 2 | 40 | 5.10 | 1.38 | |||
| 40–45 | 1.36 | 25.0 | 34.0 | |||
| No. 3 | 45 | 4.97 | 1.34 | |||
| 45–50 | 1.18 | 25.5 | 30.1 | |||
| No. 4 | 50 | 5.30 | 1.03 | |||
| 50–55 | 0.98 | 27.5 | 27.0 | |||
| No. 5 | 55 | 5.70 | 0.94 | |||
| 55–57 | 0.75 | 10.4 | 7.80 | |||
| 57 (shore) | ||||||
| Cross-section area/(m2): 145.00 | ||||||
| Discharge/(m3/s): 159.00 | ||||||
| Mean velocity/(m/s): 1.10 | ||||||
| Indicators | Points | Measured Values/(m/s) | Relative Error/(%) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Current Meter | GTM | FFT | FD- DIS-G | New Method | GTM | FFT | FD- DIS-G | New Method | ||
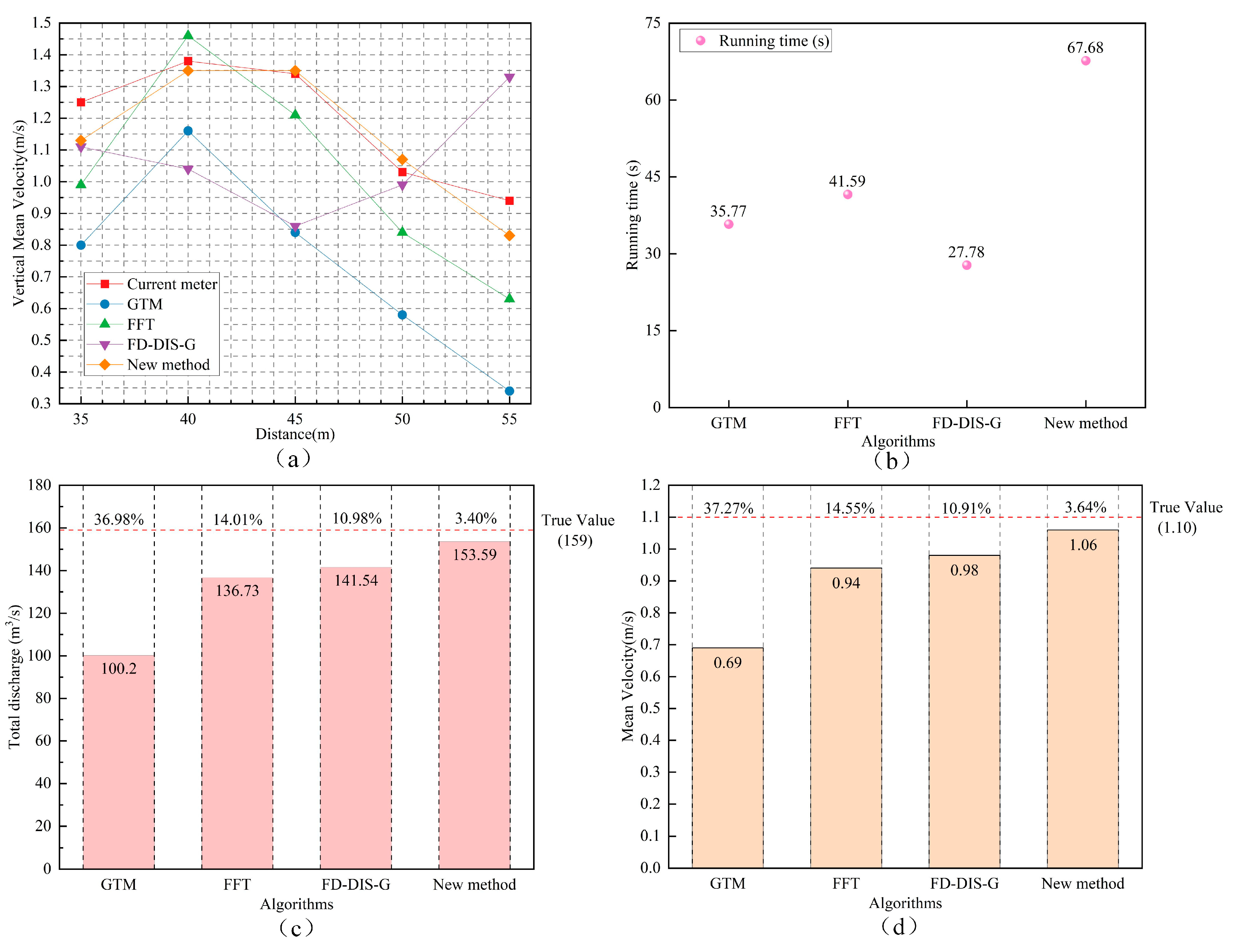
| Vertical mean velocity/(m/s) | No. 1 | 1.25 | 0.80 | 0.99 | 1.11 | 1.13 | 36.00% | 20.80% | 11.20% | 9.60% |
| No. 2 | 1.38 | 1.16 | 1.46 | 1.04 | 1.35 | 15.94% | 5.80% | 24.64% | 2.17% | |
| No. 3 | 1.34 | 0.84 | 1.21 | 0.86 | 1.35 | 37.31% | 9.70% | 35.82% | 0.75% | |
| No. 4 | 1.03 | 0.58 | 0.84 | 0.99 | 1.07 | 43.69% | 18.45% | 3.88% | 3.88% | |
| No. 5 | 0.94 | 0.34 | 0.63 | 1.33 | 0.83 | 63.83% | 32.98% | 41.49% | 11.70% | |
| Discharge/(m3/s) | 159.00 | 100.20 | 136.73 | 141.54 | 153.59 | 36.98% | 14.01% | 10.98% | 3.40% | |
| Mean velocity/(m/s) | 1.10 | 0.69 | 0.94 | 0.98 | 1.06 | 37.27% | 14.55% | 10.91% | 3.64% | |
| Points | Starting Distance/(m) | Depth/(m) | Vertical Mean Velocity/(m/s) | Partial Mean Velocity/(m/s) | Partial Area/(m2) | Partial Discharge/(m3/s) |
|---|---|---|---|---|---|---|
| 18.1 (shore) | ||||||
| 21–24 | 0.32 | 7.13 | 2.28 | |||
| No. 1 | 24 | 2.02 | 0.45 | |||
| 24–28 | 0.70 | 7.72 | 5.40 | |||
| No. 2 | 28 | 1.86 | 0.96 | |||
| 28–32 | 1.12 | 7.84 | 8.78 | |||
| No. 3 | 32 | 2.08 | 1.28 | |||
| 32–36 | 1.34 | 8.04 | 10.80 | |||
| No. 4 | 36 | 1.94 | 1.40 | |||
| 36–40 | 1.39 | 7.60 | 10.60 | |||
| No. 5 | 40 | 1.86 | 1.38 | |||
| 40–44 | 1.38 | 7.36 | 10.20 | |||
| No. 6 | 44 | 1.81 | 1.38 | |||
| 44–48 | 1.36 | 7.24 | 9.85 | |||
| No. 7 | 48 | 1.81 | 1.35 | |||
| 48–52 | 1.38 | 7.36 | 10.20 | |||
| No. 8 | 52 | 1.88 | 1.40 | |||
| 52–56 | 1.30 | 7.76 | 10.10 | |||
| No. 9 | 56 | 2.01 | 1.21 | |||
| 56–60 | 0.92 | 7.68 | 7.07 | |||
| No. 10 | 60 | 1.84 | 0.63 | |||
| 60–63 | 0.44 | 6.63 | 2.92 | |||
| 64.5 (shore) | ||||||
| Cross-section area/(m2): 82.40 | ||||||
| Discharge/(m3/s): 88.20 | ||||||
| Mean velocity/(m/s): 1.07 | ||||||
| Indicators | Points | Measured Values/(m/s) | Relative Error | |||||
|---|---|---|---|---|---|---|---|---|
| Current Meter | GTM | FFT | New Method | GTM | FFT | New Method | ||
| Vertical mean velocity/(m/s) | No. 1 | 0.45 | 0.21 | 0.24 | 0.55 | 53.33% | 46.66% | 22.22% |
| No. 2 | 0.96 | 1.20 | 1.23 | 0.70 | 25.00% | 28.13% | 27.08% | |
| No. 3 | 1.28 | 0.88 | 1.25 | 0.97 | 31.25% | 2.34% | 24.22% | |
| No. 4 | 1.40 | 0.85 | 1.23 | 1.13 | 39.29% | 12.14% | 19.29% | |
| No. 5 | 1.38 | 0.78 | 1.20 | 1.21 | 43.48% | 13.04% | 12.32% | |
| No. 6 | 1.38 | 1.46 | 1.22 | 1.23 | 5.80% | 11.59% | 10.87% | |
| No. 7 | 1.35 | 2.04 | 1.22 | 1.22 | 51.11% | 9.63% | 9.63% | |
| No. 8 | 1.40 | 1.05 | 1.32 | 1.37 | 25.00% | 5.71% | 2.14% | |
| No. 9 | 1.21 | 1.23 | 1.08 | 1.43 | 1.65% | 10.74% | 18.18% | |
| No. 10 | 0.63 | 0.42 | 0.52 | 1.29 | 33.33% | 17.46% | 104.76% | |
| Discharge/(m3/s) | 88.20 | 77.02 | 80.69 | 86.11 | 12.68% | 8.51% | 2.37% | |
| Mean velocity/(m/s) | 1.07 | 0.94 | 0.98 | 1.05 | 12.15% | 8.41% | 1.87% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; He, D.; Li, N.; Pu, X.; Jin, J.; Wang, J. Estimation of River Velocity and Discharge Based on Video Images and Deep Learning. Appl. Sci. 2025, 15, 4865. https://doi.org/10.3390/app15094865
Liu R, He D, Li N, Pu X, Jin J, Wang J. Estimation of River Velocity and Discharge Based on Video Images and Deep Learning. Applied Sciences. 2025; 15(9):4865. https://doi.org/10.3390/app15094865
Chicago/Turabian StyleLiu, Ruiting, Dianyi He, Neng Li, Xiaolei Pu, Jianhui Jin, and Jianping Wang. 2025. "Estimation of River Velocity and Discharge Based on Video Images and Deep Learning" Applied Sciences 15, no. 9: 4865. https://doi.org/10.3390/app15094865
APA StyleLiu, R., He, D., Li, N., Pu, X., Jin, J., & Wang, J. (2025). Estimation of River Velocity and Discharge Based on Video Images and Deep Learning. Applied Sciences, 15(9), 4865. https://doi.org/10.3390/app15094865