
A Comparative Analysis of Student Performance Prediction: Evaluating Optimized Deep Learning Ensembles Against Semi-Supervised Feature Selection-Based Models


Abstract
1. Introduction
2. Related Work
3. Proposed Methodology
3.1. Research Goal and Motivation
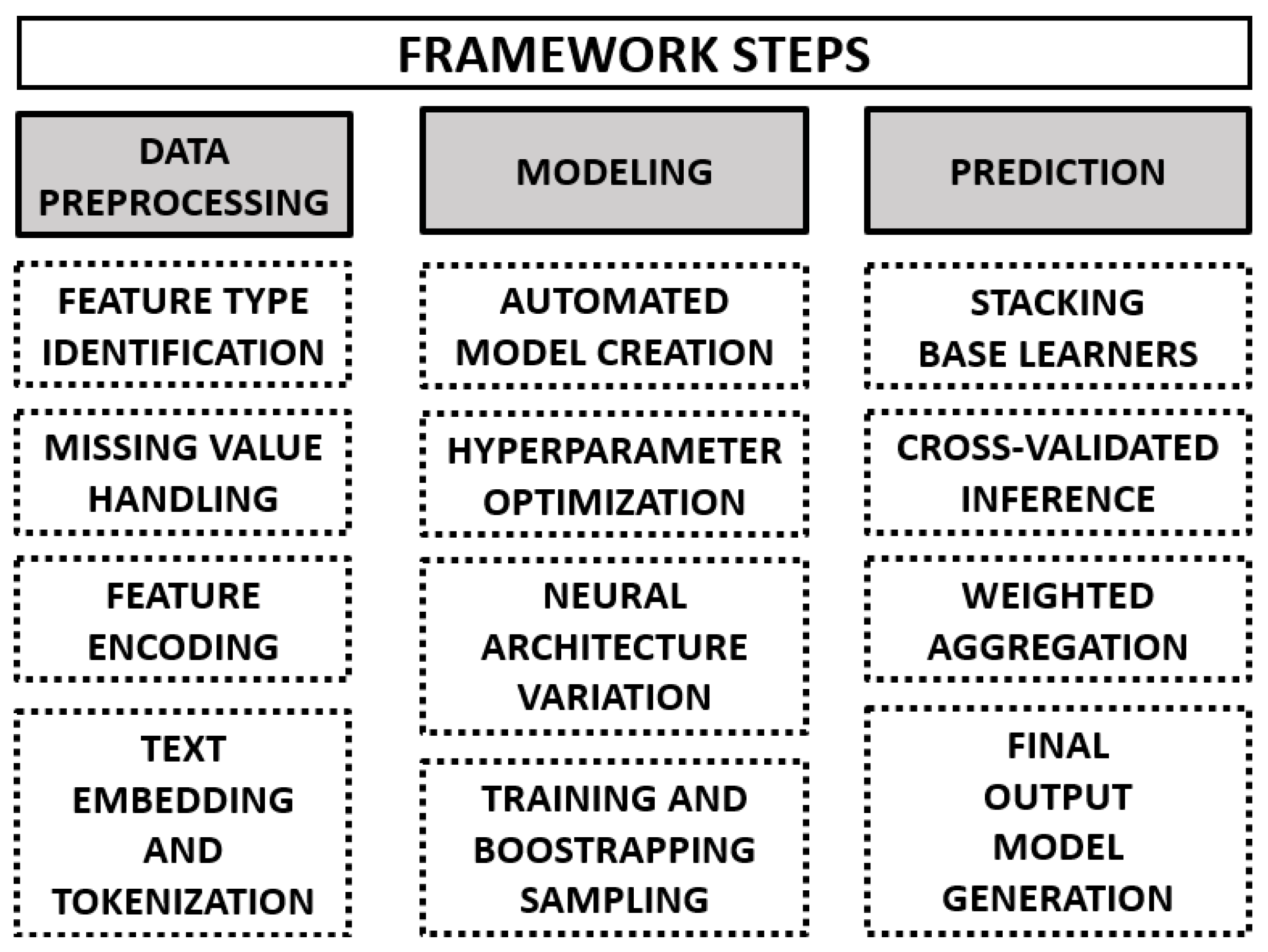
3.2. Automated Deep Learning with AutoGluon
3.2.1. Data Preprocessing
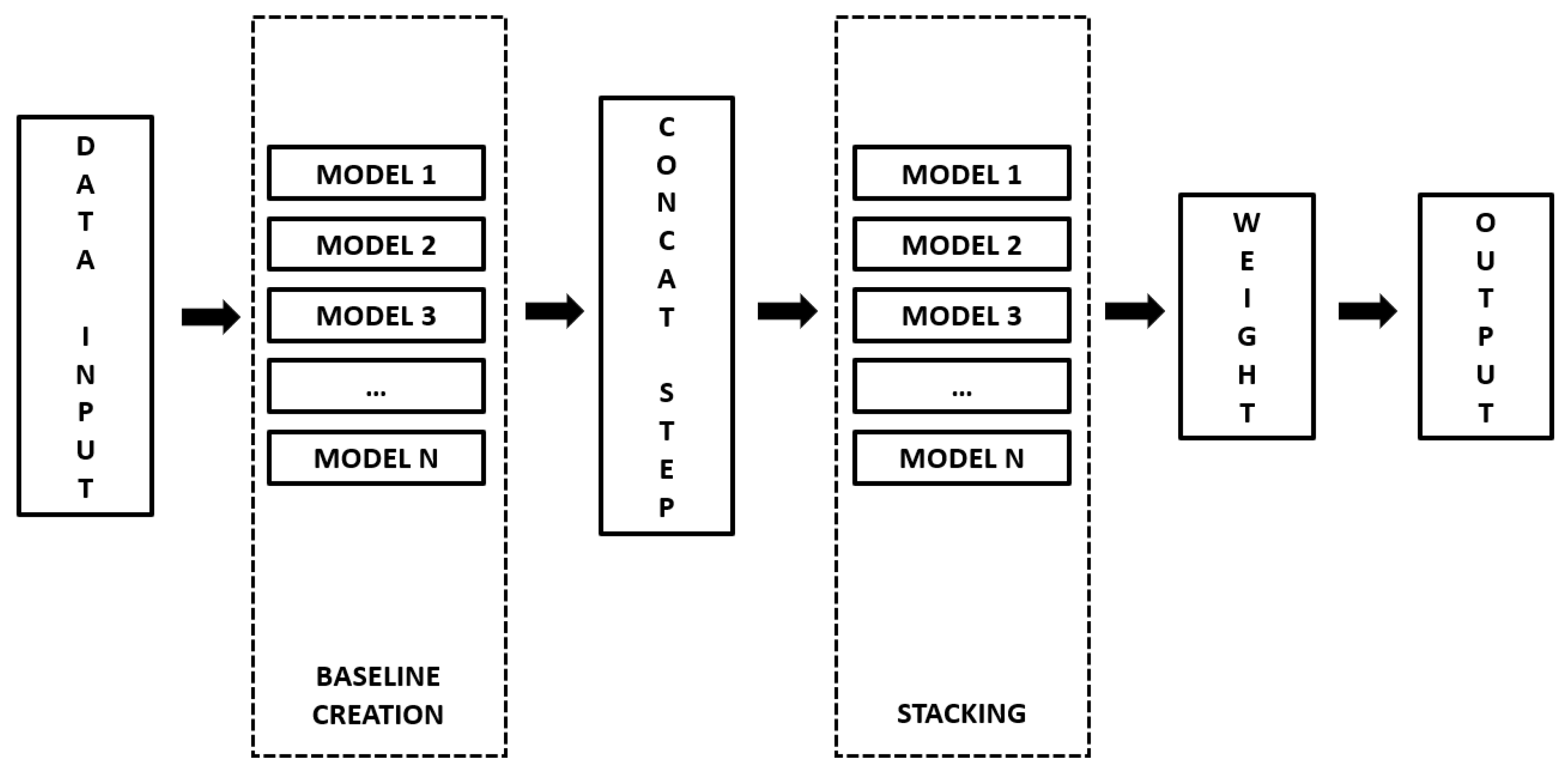
3.2.2. Modeling and Ensemble of Deep Neural Networks
3.2.3. Prediction Step
3.2.4. Evaluation Metrics
3.3. Experimental Procedure
4. Data Collection
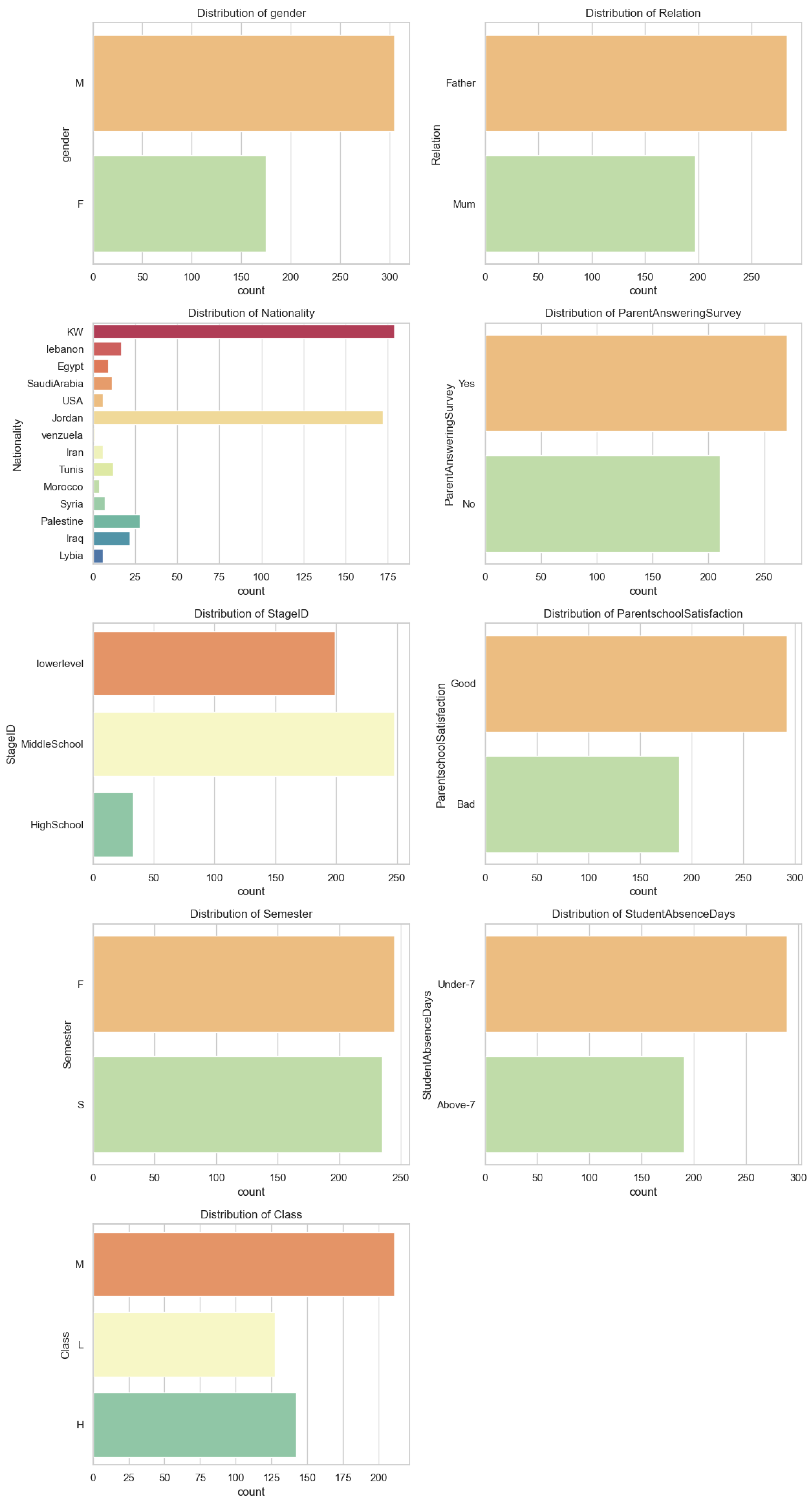
- Demographic features: attributes such as gender, NationaliTy, PlaceofBirth, StageID, Relation, and ParentAnsweringSurvey describe students’ personal backgrounds and social contexts.
- Academic features: variables like GradeID, SectionID, Topic, and Semester represent academic contexts and settings in which student learning occurs.
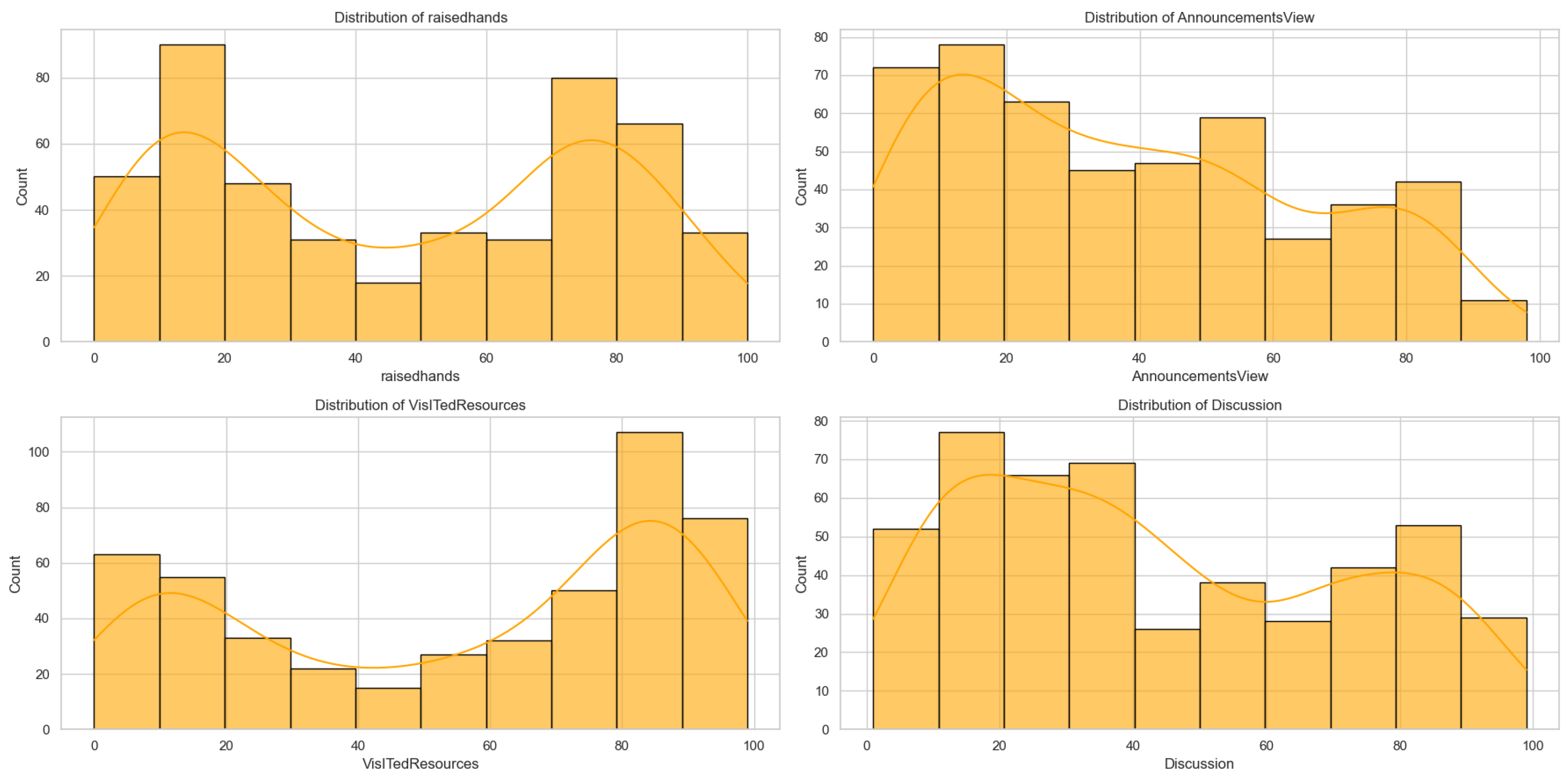
- Behavioral features: engagement indicators, including Raisedhands, VisitedResources, AnnouncementsView, and Discussion, quantify the extent and type of student interactions within the LMS.
5. Results
5.1. Cross-Validation Results
5.2. Statistical Significance of Performance Differences
6. Conclusions and Future Work
6.1. Limitations and Future Directions
6.2. Sustainability Considerations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| ANN | artificial neural network |
| AutoML | Automated Machine Learning |
| CV | cross-validation |
| DL | Deep Learning |
| DP | D’Agostino–Pearson (Test) |
| DNN | deep neural network |
| EDM | Educational Data Mining |
| FPR | False Positive Rate |
| LMS | Learning Management System |
| ML | machine learning |
| ROC-AUC | Receiver Operating Characteristic Area Under the Curve |
| SSL | semi-supervised learning |
| TPR | True Positive Rate |
| XAI | Explainable Artificial Intelligence |
| xAPI | Experience API |
References
- Romero, C.; Ventura, S. Educational Data Mining: A Review of the State of the Art. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Bakhshinategh, B.; Zaiane, O.R.; Elatia, S.; Ipperciel, D. Educational data mining applications and tasks: A survey of the last 10 years. Educ. Inf. Technol. 2018, 23, 537–553. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Data Mining in Education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 12–27. [Google Scholar] [CrossRef]
- Moral-Sánchez, S.N.; Ruiz Rey, F.J.; Cebrián-de-la Serna, M. Analysis of artificial intelligence chatbots and satisfaction for learning in mathematics education. Int. J. Educ. Res. Innov. 2023, 20, 1–14. [Google Scholar] [CrossRef]
- Ahmed, M.R.; Tahid, S.; Mitu, N.A.; Kundu, P.; Yeasmin, S. A comprehensive analysis on undergraduate student academic performance using feature selection techniques on classification algorithms. In Proceedings of the International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–6. [Google Scholar]
- Zhu, X. Semi-Supervised Learning Literature Survey; Technical Report 1530; University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer: Cham, Switzerland, 2019. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. Automl: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. Adv. Neural Inf. Process. Syst. (NeurIPS) 2015, 28, 2962–2970. [Google Scholar]
- Vanschoren, J. Meta-Learning: A Survey. arXiv 2018, arXiv:1810.03548. [Google Scholar]
- Amrieh, E.A.; Hamtini, T.; Aljarah, I. Preprocessing and analyzing educational data set using X-API for improving student’s performance. In Proceedings of the 2015 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies, Amman, Jordan, 3–5 November 2015. [Google Scholar]
- Kevan, J.M.; Ryan, P.R. Experience API: Flexible, Decentralized and Activity-Centric Data Collection. Technol. Knowl. Learn. 2016, 21, 143–149. [Google Scholar] [CrossRef]
- Yu, S.; Cai, Y.; Pan, B.; Leung, M.F. Semi-Supervised Feature Selection of Educational Data Mining for Student Performance Analysis. Electronics 2024, 13, 659. [Google Scholar] [CrossRef]
- Cornillez, E.E.C. Modeling the Relationship among Digital Demographic Characteristics, Digital Literacy, and Academic Performance of Mathematics Major Students in an Online Learning Environment. Int. J. Educ. Res. Innov. 2024, 21, 1–23. [Google Scholar] [CrossRef]
- Nouira, A.; Cheniti-Belcadhi, L.; Braham, R. An ontology-based framework of assessment analytics for massive learning. Comput. Appl. Eng. Educ. 2019, 27, 1427–1440. [Google Scholar] [CrossRef]
- Hazim, L.R.; Abdullah, W.D. Characteristics of data mining by classification educational dataset to improve student’s evaluation. J. Eng. 2021, 16, 2825–2844. [Google Scholar]
- Al Fanah, M.; Ansari, M.A. Understanding e-learners’ behavior using data mining techniques. In Proceedings of the 2019 International Conference on Big Data, Angeles, CA, USA, 9–12 December 2019. [Google Scholar]
- Mihaescu, M.C.; Popescu, P.S. Review on publicly available datasets for educational data mining. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1403. [Google Scholar] [CrossRef]
- Panda, M.; AlQaheri, H. An education process mining framework: Unveiling meaningful information for understanding students’ learning behavior and improving teaching quality. Information 2022, 13, 29. [Google Scholar] [CrossRef]
- Mohammad, A.S.; Al-Kaltakchi, M.T.S.; Al-Ani, J.A. Comprehensive evaluations of student performance estimation via machine learning. Mathematics 2023, 11, 3153. [Google Scholar] [CrossRef]
- Erickson, N.; Mueller, J.; Deng, H.; Guo, A.; Li, M.; Smola, A.; Zhang, Z. AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data. arXiv 2020, arXiv:2003.06505. [Google Scholar]
- Ferreira, L.; Pilastri, A.; Martins, C.M.; Pires, P.M.; Cortez, P. A comparison of AutoML tools for machine learning, deep learning and XGBoost. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Virtual, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Olson, R.S.; Urbanowicz, R.J.; Andrews, P.C.; Lavender, N.A.; Kidd, L.C.; Moore, J.H. Chapter Automating Biomedical Data Science Through Tree-Based Pipeline Optimization. In Applications of Evolutionary Computation: 19th European Conference, EvoApplications 2016, Porto, Portugal, 30 March–1 April 2016; Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2016; pp. 123–137. [Google Scholar] [CrossRef]
- Le, T.T.; Fu, W.; Moore, J.H. Scaling tree-based automated machine learning to biomedical big data with a feature set selector. Bioinformatics 2020, 36, 250–256. [Google Scholar] [CrossRef] [PubMed]
- Olson, R.S.; Bartley, N.; Urbanowicz, R.J.; Moore, J.H. Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science. In Proceedings of the Genetic and Evolutionary Computation Conference 2016, GECCO ’16, Denver, CO, USA, 20–24 July 2016; pp. 485–492. [Google Scholar] [CrossRef]
- LeDell, E.; Poirier, S. H2O AutoML: Scalable Automatic Machine Learning. In Proceedings of the 7th ICML Workshop on Automated Machine Learning (AutoML), Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Victoria, A.H.; Maragatham, G. Automatic tuning of hyperparameters using Bayesian optimization. Evol. Syst. 2021, 12, 217–223. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Jain, A.; Kumar, A.; Susan, S. Evaluating deep neural network ensembles by majority voting cum meta-learning scheme. In Proceedings of the 3rd International Conference on Advances in Signal Processing and Artificial Intelligence, Porto, Portugal, 17–19 November 2021; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Kim, H.; Kim, H.; Moon, H.; Ahn, H. A weight-adjusted voting algorithm for ensembles of classifiers. J. Korean Stat. Soc. 2011, 40, 437–449. [Google Scholar] [CrossRef]
- West, D.; Dellana, S.; Qian, J. Neural network ensemble strategies for financial decision applications. Comput. Oper. Res. 2005, 32, 2543–2559. [Google Scholar] [CrossRef]
- Zhou, Z.; Wu, J.; Tang, W. Ensembling neural networks: Many could be better than all. Artif. Intell. 2002, 137, 239–263. [Google Scholar] [CrossRef]
- Ganaie, M.; Hu, M.; Malik, A.; Tanveer, M. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Iqbal, N.; Jamil, H.; Kim, D. An optimized ensemble prediction model using AutoML based on soft voting classifier for network intrusion detection. J. Netw. Comput. Appl. 2023, 212, 103560. [Google Scholar]
- Dietterich, T. Ensemble methods in machine learning. In Multiple Classifier Systems. MCS 2000; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufman: San Francisco, CA, USA, 2016. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press/Addison-Wesley: New York, NY, USA, 1999. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; pp. 1–482. [Google Scholar]
- van Rijsbergen, C.J. Information Retrieval; Butterworth-Heinemann: Oxford, UK, 1979. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Zou, K.H.; O’Malley, A.J.; Mauri, L. Receiver-operating characteristic analysis for evaluating diagnostic tests and predictive models. Circulation 2007, 115, 654–657. [Google Scholar] [CrossRef]
- Student. The probable error of a mean. Biometrika 1908, 6, 1–25. [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Patterson, D.; Gonzalez, J.; Le, Q.V.; Liang, C.; Munguia, L.M.; Rothchild, D.; Dean, J. Carbon Emissions and Large Neural Network Training. arXiv 2021, arXiv:2104.10350. [Google Scholar]
- Xu, C.; Wang, Z.; Qin, J.; Jiang, Y. Energy-Efficient Deep Learning Model Compression: A Survey. Neurocomputing 2021, 461, 173–196. [Google Scholar]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Yu et al. [19] | DL Proposal |
|---|---|---|
| Accuracy | 0.7646 | 0.9548 |
| F-score | 0.6216 | 0.9522 |
| Precision | 0.6165 | 0.9597 |
| Recall | 0.6277 | 0.9492 |
| ROC-AUC | Not Reported | 0.9523 |
| Fold | Accuracy | Precision | Recall | F1-Score | ROC-AUC |
|---|---|---|---|---|---|
| 1 | 0.9433 | 0.9447 | 0.9433 | 0.9726 | 0.9815 |
| 2 | 0.9958 | 0.9448 | 0.9658 | 0.8959 | 0.9581 |
| 3 | 0.9708 | 0.9560 | 0.9008 | 0.8959 | 0.9581 |
| 4 | 0.9400 | 0.9483 | 0.9483 | 0.9483 | 0.9620 |
| 5 | 0.9400 | 0.9600 | 0.9900 | 0.9870 | 0.9696 |
| 6 | 0.9400 | 0.9600 | 0.9900 | 0.9870 | 0.9296 |
| 7 | 0.9400 | 0.9479 | 0.9000 | 0.9466 | 0.9167 |
| 8 | 0.9500 | 0.9989 | 0.9600 | 0.9922 | 0.9802 |
| 9 | 0.9692 | 0.9670 | 0.9692 | 0.9666 | 0.9625 |
| 10 | 0.9733 | 0.9333 | 0.9333 | 0.9333 | 0.9279 |
| Average | 0.9548 | 0.9597 | 0.9492 | 0.9522 | 0.9523 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lagares Rodríguez, J.A.; Díaz-Díaz, N.; Barranco González, C.D. A Comparative Analysis of Student Performance Prediction: Evaluating Optimized Deep Learning Ensembles Against Semi-Supervised Feature Selection-Based Models. Appl. Sci. 2025, 15, 4818. https://doi.org/10.3390/app15094818
Lagares Rodríguez JA, Díaz-Díaz N, Barranco González CD. A Comparative Analysis of Student Performance Prediction: Evaluating Optimized Deep Learning Ensembles Against Semi-Supervised Feature Selection-Based Models. Applied Sciences. 2025; 15(9):4818. https://doi.org/10.3390/app15094818
Chicago/Turabian StyleLagares Rodríguez, Jose Antonio, Norberto Díaz-Díaz, and Carlos David Barranco González. 2025. "A Comparative Analysis of Student Performance Prediction: Evaluating Optimized Deep Learning Ensembles Against Semi-Supervised Feature Selection-Based Models" Applied Sciences 15, no. 9: 4818. https://doi.org/10.3390/app15094818
APA StyleLagares Rodríguez, J. A., Díaz-Díaz, N., & Barranco González, C. D. (2025). A Comparative Analysis of Student Performance Prediction: Evaluating Optimized Deep Learning Ensembles Against Semi-Supervised Feature Selection-Based Models. Applied Sciences, 15(9), 4818. https://doi.org/10.3390/app15094818