Abstract
Foreign object detection on coal mine conveyor belts is crucial for ensuring operational safety and efficiency. However, applying deep learning to this task is challenging due to variations in camera perspectives, which alter the appearance of foreign objects and their surrounding environment, thereby hindering model generalization. Despite these viewpoint changes, certain core characteristics of foreign objects remain consistent. Specifically, (1) foreign objects must be located on the conveyor belt, and (2) their surroundings are predominantly coal, rather than other objects. To leverage these stable features, we propose the Camera-Adaptive Foreign Object Detection (CAFOD) model, designed to improve cross-camera generalization. CAFOD incorporates three main strategies: (1) Multi-View Data Augmentation (MVDA) simulates viewpoint variations during training, enabling the model to learn robust, viewpoint-invariant features; (2) Context Feature Perception (CFP) integrates local coal background information to reduce false detections outside the conveyor belt; and (3) Conveyor Belt Area Loss (CBAL) enforces explicit attention to the conveyor belt region, minimizing background interference. We evaluate CAFOD on a dataset collected from real coal mines using three distinct cameras. Experimental results demonstrate that CAFOD outperforms State-of-the-Art object detection methods, achieving superior accuracy and robustness across varying camera perspectives.
1. Introduction
Coal mining operations heavily rely on conveyor belt systems to transport coal from extraction sites to storage or processing facilities, ensuring efficiency and productivity in the industry [1,2]. However, foreign objects such as rocks, coal gangue, tools, and broken equipment parts can accumulate on the conveyor belt due to various factors, including operational mishandling or mechanical failures. These foreign objects pose significant risks, potentially causing equipment damage, operational disruptions, and severe safety hazards [3]. Therefore, accurate and efficient foreign object detection is critical to ensuring safe and smooth coal transportation [4,5].
Recent advances in deep learning-based object detection have shown remarkable success across diverse domains, including optical remote sensing images [6], autonomous driving [7], and vehicle recognition [8,9]. However, applying these techniques to foreign object detection on coal conveyor belts remains challenging due to the unique environmental conditions and variations in camera perspectives.
One primary challenge arises from the substantial variations in camera perspectives across different working environments, as shown in Figure 1. Changes in viewpoint can alter the appearance of both foreign objects and their backgrounds, making it difficult for a model to adapt effectively to new unseen camera perspectives. Traditional deep learning models often experience significant performance degradation when applied to images from different angles. Fine-tuning the model on new camera data is a common approach, but collecting and annotating data across multiple coal mining sites is both labor-intensive and costly. Moreover, existing models are prone to false detection, especially when background elements outside the conveyor belt are mistakenly classified as foreign objects. These challenges highlight the need for a more robust detection approach that effectively addresses viewpoint variations and improves adaptability across different cameras.

Figure 1.
Viewpoint variations in different cameras. Conveyor belt images of cameras in different scenes have large background differences, which is the main reason affecting the generalization of camera-adaptability.
In response to these challenges, we propose the Camera-Adaptive Foreign Object Detection (CAFOD) model, specifically designed to enhance generalization across diverse camera perspectives. CAFOD is built on two key observations: (1) foreign objects must lie on the conveyor belt, and (2) their immediate surroundings are predominantly coal. Based on these insights, CAFOD integrates multiple strategies to achieve robust and efficient performance. First, we introduce Multi-View Data Augmentation (MVDA) to simulate a wide range of camera viewpoints during training, enabling the model to learn view-invariant features. We then incorporate Context Feature Perception (CFP) to leverage local coal-background information, reducing the likelihood of false detections in non-coal regions. Additionally, we propose a Conveyor Belt Area Loss (CBAL), which enforces explicit attention to the conveyor belt region, minimizing background interference. Finally, we integrate Varifocal Loss (VFL) [10], allowing the model to adaptively reweight challenging samples and improve the detection of small or visually similar foreign objects. These coordinated methods enable CAFOD to successfully handle viewpoint variability and achieve high detection accuracy in real coal conveyor belt environments.
Through these enhancements, CAFOD can improve model generalization across different camera perspectives, effectively addressing the limitations of conventional deep learning-based object detection methods. The key contributions of this work are summarized as follows:
- We introduce a novel approach to camera-adaptive foreign object detection that enhances generalization across varying camera perspectives without requiring extensive retraining, through viewpoint data augmentation, background feature enhancement, and belt area constraint.
- We incorporate Context Feature Perception (CFP) and Conveyor Belt Area Loss (CBAL) to enhance scene understanding. CFP helps the model focus on the coal background surrounding foreign objects, reducing false detections in non-coal areas, while CBAL explicitly guides attention to the conveyor belt region, minimizing background interference.
- Extensive experiments on real-world coal mine datasets demonstrate that CAFOD outperforms State-of-the-Art detection models in terms of accuracy and cross-camera adaptability, highlighting its robustness across diverse viewpoints and challenging real-world conditions.
2. Related Work
2.1. Object Detection Models
Many studies use deep learning techniques to detect foreign objects on coal conveyor belts. YOLOv8s-GSC [11] proposed a lightweight real-time coal gangue detection model using YOLOv8s, integrating GhostNet and a coordinate attention mechanism to enhance efficiency. Pu et al. [12] designed a specialized CNN to classify coal and gangue images by incorporating dilated convolutions to enlarge the receptive field without increasing the computational burden. This enhanced the network’s ability to capture multi-scale information. Gao et al. [13] developed a fully convolutional U-Net-based architecture for coal and gangue segmentation, leveraging skip connections to retain spatial information during down-sampling. Hu et al. [14] proposed a method for foreign object detection method for coal mine conveyor belts based on EfficientNetV2. This method improves the attention mechanism and loss function to enhance the expression ability of MBConv and Fused-MBConv for image features and the adaptability of the model to complex data distributions and task requirements. Li et al. [15] proposed coordinate attention (CA) to enhance the location information of foreign objects in the detection of foreign objects on conveyor belts, and improved the loss function to balance the detection accuracy and detection efficiency. Ling et al. [16], aiming at the problems of slow speed and excessive parameters in the deep learning-based detection methods for foreign objects on conveyor belts, proposed a more lightweight detection method based on Yolov8n, which significantly reduced the number of model parameters and complexity. Although these methods have improved foreign object detection in the coal industry, it is still challenging when dealing with the variability of real-world conditions. Most models are trained in controlled environments, reducing their robustness under different camera background settings.
In the field of object detection, O2F [17] and AutoAssign [18] improve detection performance by optimizing label matching and dynamically adjusting label allocation. CEASC [19] and AFPN [20] enhance feature quality through multi-stage fusion and global context enrichment. VarifocalNet [10] and CentripetalNet [21] introduce Intersection-over-Union (IoU)-aware loss and center keypoint mechanisms to enhance confidence and accuracy. Sparss-RCNN [22] uses sparse convolution instead of traditional convolution operation to extract the features of large-scale targets. Xie et al. [23], aiming at the deficiencies of unsupervised pre-training methods in image classification, abandoned the contrastive learning for global and local images by conducting multi-level detection of the representations in the intermediate layers of the model, which improved the detection and classification performance. Y Hong et al. [24] in response to the dim lighting environment in the underground for the task of detecting foreign objects on conveyor belts, effectively enhanced the low-light environment. Moreover, they optimized feature extraction through a lightweight dynamic group module network, and ultimately significantly improved the accuracy and real-time performance of detecting foreign objects on conveyor belts. These methods, however, also suffer from camera adaptability issues. A trained model often shows a significant performance drop when inferring images from new cameras. However, Chen et al. [25] proposed a general method for generalized object detection in the underwater domain. By extracting domain-invariant features from the source domain and guiding the deep feature mining in a self-supervised learning manner, they achieved good detection results. In the proposed CAFOD model, we use data augmentation and belt area constraints to enhance camera adaptability and minimize background interference, improving the model’s generalization across different cameras.
2.2. Detection Transformer
Facebook introduced Detection Transformer (DETR) [26], an end-to-end object detection network that eliminates the need for non-maximum suppression and anchor-based priors, simplifying the overall detection framework. The model directly predicts bounding boxes and classes and treats detection as a global set-based prediction problem through bipartite matching. However, its convergence speed is slow and its performance on small objects is poor. To address these issues, Deformable DETR [27] introduces sparse attention mechanisms and multi-scale feature aggregation, enhancing convergence speed and small object detection.
Subsequently, it showed its great potential in industry. For example, FE-DETR [28] enhanced foreign object detection in textile X-ray images by introducing a multi-scale feature encoding module based on the DETR architecture. Furthermore, MPEND [29] advanced wood veneer defect identification through a positional encoding network that leverages multi-scale feature maps, showcasing the versatility of DETR in various industrial applications. Therefore, we used the Deformable DETR as a baseline model to explore its ability to detect foreign objects on the conveyor belt.
2.3. Semantic Feature Fusion
Semantic feature fusion has gained significant attention in object detection due to its ability to enhance model robustness in complex environments. For instance, LGCNet [30] designed a “multi-branch” structure to learn the multi-level representation of remote sensing images that enhances perception in complex backgrounds. Chen et al. [31] incorporated semantic information into the detection framework through joint training of scene segmentation and object detection, effectively reducing false positives. Similarly, context transformer [32] leveraged transformers to model dependencies between objects and backgrounds, showing particular effectiveness in urban street scenes.
The above methods utilize context feature information in complex environments to improve the robustness of object detection in specific scenarios. In foreign object detection on coal conveyor belts, the background outside the conveyor belt area significantly impacts the performance of the foreign object detection model. Inspired by contextual feature fusion, we integrate the surrounding context features of potential foreign objects to reduce the model’s false detection of the background outside the conveyor belt area.
3. Methodology
This section begins by defining the problem of foreign object detection on coal conveyor belts. We then provide an overview of the proposed method, followed by detailed descriptions of four key modules. Finally, we present the overall loss function used to train the model.
3.1. Problem Definition
Given in a training image set , where represents input images, C is the number of channels, H and W are the height and width of the images. Each image is associated with a bounding box , which defines the coordinates of a foreign object. Here, and represent the coordinates of the top-left corner of the bounding box, and and represent the width and height of the bounding box, respectively. Additionally, a label is provided, indicating the class of the foreign object. The goal is to train a model using the training set , predict the bounding boxes and object classes for images, when given a test set . The aim is to ensure that the predicted bounding boxes closely match the actual , and the predicted class matches the true class . Images of new cameras will be used as test data, testing the model’s camera adaptability.
3.2. Overview of the Method
As described in Section 1, the key to camera-adaptive foreign object detection lies in addressing viewpoint variations and leveraging stable context cues on the conveyor belt. We introduce four additional modules Multi-View Data Augmentation (MVDA), Context Feature Perception (CFP), Conveyor Belt Area Loss (CBAL), and Varifocal Loss (VFL) [10]—on top of Deformable DETR [27], as shown in Figure 2.
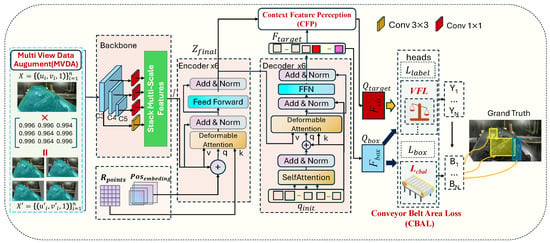
Figure 2.
Overview of CAFOD: Deformable DETR Enhanced with MVDA (Viewpoint Invariance), CFP (Context Awareness), CBAL (Belt Focus), and VFL (Accuracy Improvement) modules.
The Deformable DETR mainly includes backbone, encoder, decoder, and prediction heads. The backbone processes the raw image X and generates multi-scale features I using a ResNet50 architecture. The encoder utilizes the multi-head self-attention mechanism to enhance the feature representation and outputs . The decoder integrates query information to refine the targets’ location and category . The prediction heads are used to predict both location and category.
These introduced four modules are each integrated at different stages of the pipeline to improve the network’s robustness to camera perspective changes, enhance context-based discrimination, focus on belt-region targets, and boost prediction accuracy. Firstly, we apply the MVDA model on image , generating an augmented sample set to improve the model robustness to camera view changing. Secondly, all foreign objects should be enclosed by coals (on the conveyor belt). Thus, we add the surrounding features of the potential foreign objects to reject the false detection outside the conveyor belt area by the CFP model. Thirdly, we design a CBAL to enforce the model’s focus on the belt area and reduce interference from irrelevant objects outside the conveyor belt area. The labeling work is light as we only need to label the belt area per camera, extra. Finally, we add Varifocal Loss to obtain more accurate results.
3.3. Multi-View Data Augmentation
Due to the difficulty in collecting foreign object data on coal conveyor belts. We apply various geometric transformations [33] to simulate different camera angles and enhance the model’s generalization ability, as shown in Figure 3.
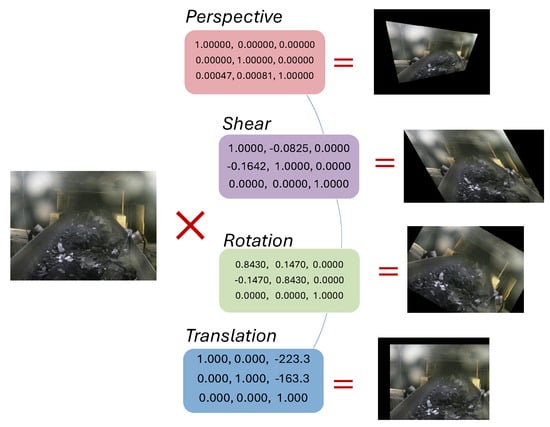
Figure 3.
Multi-view data augmentation simulates the perspective changes of different cameras. The data augmentation can provide more differentiated features from different angles to improve the model’s adaptability to different cameras.
We define four main transformation matrices. They are perspective P, scaling S, rotation R, and translation T, shown in Equation (1). P represents the perspective transformation matrix, controlling the perspective effects in the x and y directions, with parameters and randomly generated in a range. S is the shearing transformation matrix, where and define the shearing strengths along the respective axes. R represents the rotation transformation matrix, responsible for rotating the image by an angle , where . T represents the translation transformation matrix, which shifts the image in the x and y directions. The translation distances and are randomly generated within of the image width (w) and height (h). We combine these transformation matrices to form a total transformation matrix , in Equation (2).
The expression refers to applying the affine transformation to each pixel coordinate of the image individually, rather than performing a direct matrix multiplication on the entire image. and are the transformed image and the corresponding bounding box. Applying the transformation to each image in the dataset D, we obtain the enhanced dataset , providing the model with more differentiated features from different perspectives and improving the model’s adaptability to multiple cameras.
3.4. Context Feature Perception
In coal mine environments, significant differences in conveyor belt backgrounds across various camera perspectives, along with noise factors such as light, dust, or water vapor, make it challenging to distinguish between foreground objects (foreign objects on the conveyor belt) and background objects (foreign objects outside the conveyor belt). As a result, models tend to misclassify background elements as foreign objects, leading to obvious false detection.
To address this issue, we propose the Context Feature Perception (CFP) module, as shown in Figure 4. The key insight is that foreign objects on the conveyor belt should be surrounded by coal. This stable context feature allows the model to differentiate between relevant foreign objects on the belt and irrelevant objects in the background. By integrating coal features surrounding potential foreign objects into the detection process, the model can better capture contextual cues, thereby improving its ability to distinguish targets on the conveyor belt from background noise. To implement CFP, we first enlarge the predicted target bounding box by a factor of 1.2, then, subtract the original bounding box area to obtain a surrounding context region. This context region mask is applied to the encoder’s output feature map to extract coal-related background features. Finally, we fuse these context features with the target features, yielding a context-aware representation that highlights foreign objects on the conveyor belt while suppressing irrelevant backgrounds. The detailed process is described as follows.
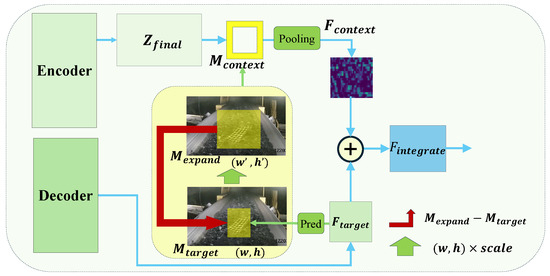
Figure 4.
Context feature perception module. Integrates potential foreign object features with surrounding coal features to enhance the model’s ability to distinguish between foreground objects (foreign objects on the conveyor belt) and background objects (foreign objects outside the conveyor belt). The Encoder and Decoder are defined in Deformable DETR.
First, the decoder outputs a target feature map with the bounding box , where and represent the coordinates of the center of the bounding box, w denotes the width and h denotes the height of the bounding box. To capture contextual information, the bounding box is enlarged by a (set to 1.2) to produce an expanded bounding box with and , by Equation (5).
Then, based on and , we can create two masks, and , to cover the two bounding box. By subtracting these two masks, as shown in Equation (6), a surrounding mas, k , can be obtained, representing the area between and .
Next, the mask is applied element-wise to the feature map , extracting context features around potential foreign objects to provide valuable context for the object classifier.
Finally, we integrate these context features with the target features as shown in Equation (8). The potential target features , enriched with contextual information, are fed into the classifier for the categorization task. By associating foreign object targets with the coal characteristics in their surroundings, the method enhances the context feature correlation for foreign object detection on the conveyor belt and aids in eliminating false detection of foreign objects outside the conveyor belt.
3.5. Conveyor Belt Area Loss
A key observation is that relevant foreign objects on the conveyor belt must lie within the belt region. If a predicted box appears outside this region, it is more likely to be a false detection. To address this, we introduce the Conveyor Belt Area Loss (CBAL), which penalizes detections lying outside the conveyor belt and rejects obvious false detections that fall outside the belt area, as shown in Figure 5. By incorporating this geometric constraint into training, the model gains a more robust understanding of the conveyor belt context and improves its adaptability to different camera viewpoints.
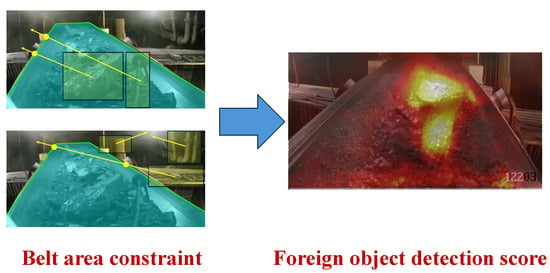
Figure 5.
CBAL enforces the focus on the conveyor belt region by penalizing predictions outside the defined belt area. Here, the large coal and iron bar on the belt are detected, while the three background boxes are ignored as they lie outside the polygon.
Firstly, we manually annotate the conveyor belt area, , from different camera perspectives,
where represent the vertices of the conveyor belt polygon. Next, we use the polygon area to evaluate whether the center points of the predicted bounding boxes fall within the conveyor belt area. Specifically, we calculate the number of intersection between a horizontal ray emitted from each prediction box center and the boundary of the polygon [34], as shown in Equation (10).
where represents a function to determine whether a number is positive or negative. The parity of indicates the positional relationship of the prediction box concerning the conveyor belt area. Specifically, when is odd, the prediction box j is located within the conveyor belt area, and when is even, the prediction box is outside the belt.
Subsequently, we compute the loss for predictions outside the conveyor belt area using the loss defined in Equation (12).
where m represents the total number of prediction boxes. The loss minimizes the number of prediction boxes incorrectly positioned outside the conveyor belt, as shown in Figure 5. When all prediction boxes are correctly placed within the conveyor belt area, the loss value becomes zero, indicating optimal performance. The analysis of error types and loss curves in Section 4 demonstrates that this module can reduce false detections of background regions outside the conveyor belt area, enhancing both the detection accuracy and the model’s generalization ability.
3.6. Varifocal Loss
Varifocal Loss, VFL [10], can alleviate and reduce false positives by dynamically adjusting the weights of positive and negative samples and the focal factor, as shown in Equation (13).
where p denotes the predicted IoU score, and q represents the target score. For foreground points, q is defined as the IoU between the predicted bounding box and its ground truth, whereas for background points, q is set to 0. is the weight balancing factor for negative samples, and is the focusing factor, which adjusts the emphasis on samples with varying confidence levels. VFL reduces the impact of negative examples using a scaling factor , and balances the contributions of positive and negative examples, fine-tuning their relative importance. Positive examples , retain their full contribution, with their impact weighted by the target q. Higher ground truth IoU values increase their influence, focusing training on high-quality positives that improve average precision (AP).
3.7. The Overall Loss
Combining CBAL, VFL, and the regression loss and classification loss of object detection, the overall loss function of the CAFOD model is defined in Equation (14).
where, represents the target classification loss, computed by the cross-entropy [35]. The target location regression loss, , consists of both the L1 loss [36] and the generalized IoU loss [37]. Additionally, accounts for specific spatial constraints of the conveyor belt region, and is used to balance the impact of false positive samples. Together, these components form the overall loss for the CAFOD model.
4. Experiments
This section evaluates the performance of the proposed CAFOD. The experiments include camera-adaptive performance analysis, object detection performance comparisons, ablation studies, and model complexity analysis.
4.1. Datasets
We collected and processed conveyor belt images from three cameras with different backgrounds, as shown in Figure 1. The dataset consists of four categories of foreign objects: big coal, wood, iron bars, and iron mesh, as shown in Figure 6. The dataset contains a total of 4449 samples and is divided into training () and testing () sets, as shown in Table 1. Specifically, we have merged the data from the three cameras, as shown in Table 1, and adopted a random division method to randomly allocate all samples to the training set and the test set at a ratio of 70% and 30%.

Figure 6.
Four types of foreign objects on coal conveyor belts: big coal, wood, iron bars, and iron mesh.

Table 1.
Dataset Statistics.
4.2. Baselines
To evaluate the proposed method’s performance in foreign object detection on coal conveyor belts, we selected several baseline models known for their innovative optimizations in detection accuracy and robustness. These models have made significant contributions to the field of object detection.
- AutoAssign (2020) [18] adopted a differentiable label assignment mechanism, dynamically adjusting the label assignment strategy during training to improve the effectiveness and robustness of object detection.
- Sparse-RCNN (2021) [22] introduced learnable proposals, reducing the number of candidate boxes while maintaining high efficiency in object detection, enabling end-to-end training and inference.
- Deformable DETR [27] incorporated a deformable attention mechanism to greatly reduce the computational complexity of Transformer and enhance detection capabilities for objects at different scales.
- VarifocalNet (2021) [10] mainly introduced an IoU-aware loss function, improving the model’s performance in predicting the confidence of candidate boxes and thus enhancing the accuracy and stability of object detection.
- CentripetalNet (2020) [21] utilized high-quality keypoints at the center of objects to achieve more accurate object detection, especially in keypoint detection and object localization.
- O2F [17] proposed a “one-to-one” label assignment strategy, which dynamically adjusts the number of labels for each prediction, optimizing the label matching process and significantly improving the accuracy and robustness of end-to-end object detection.
- CEASC [19] introduced the Adaptive Sparse Convolutional Network (ASCN), combined with a global context enhancement module, which greatly accelerated and improved the speed and accuracy of object detection.
- AFPN [20] presented the Asymptotic Feature Pyramid Network (AFPN), which gradually fuses feature pyramids in stages to enhance feature representation quality and improve object detection performance, with a significant boost in small object detection.
4.3. Experimental Settings
Experiments are conducted using NVIDIA Tesla V100, Cuda 12.0, and Pytorch 2.0.0. The proposed CAFOD and baselines are trained and tested with a learning rate of 0.002 and a batch size of 16. We use AP50 and mAP50 as main metrics to evaluate their performance on foreign object detection [38]. AP50 represents the average precision for a single category when the IoU threshold is set to 0.5, while mAP50 is the mean of AP50 values across all categories [39,40].
4.4. Camera Adaptability Evaluation
We conducted a cross-camera detection to assess the model’s generalization in new camera coal mine environments. Specifically, we trained the model using images taken by Camera 1, and performed inference on images by Camera 2, Camera 3, and all the cameras (the entire dataset). The experimental results are summarized in Table 2. In the table, “Impr” refers to the performance improvement of our model over Deformable DETR, while “Mean Impr” indicates the improvement of our model relative to the average performance of all baseline models.
Table 2.
Camera Adaptability Performance Comparison (measured by mAP50).
The results show that all baseline models achieve good precision on the subset of Camera 1. However, due to the significant differences between the backgrounds of other cameras and the training data, the detection performance on these images drops sharply. This indicates that the baseline models have weak generalization ability in view of new camera scenes.
However, as shown in Table 2, our proposed method outperforms other methods in terms of camera adaptability. The second-to-last row highlights the performance improvements achieved by our method over the Deformable DETR. Specifically, the improvement for Camera 2 and Camera 3 is notably higher compared to Camera 1, demonstrating the enhanced ability of our model to adapt to different camera perspectives. The last row of the table compares the average performance of our method against all other methods. Again, our method shows superior performance in terms of camera adaptability, confirming the effectiveness of the proposed strategy in improving the model’s ability to generalize across different camera perspectives.
4.5. General Detection Performance Evaluation
We evaluate the detection performance of the proposed CAFOD model under general settings, where the testing images originate from the same cameras used in the training phase. The results, summarized in Table 3, are reported in AP50 for each object category (Big coal, Wood, Iron bars, Iron mesh) and mAP50 for overall detection performance. The results demonstrate that CAFOD achieves the highest mAP50 score of 80.39, outperforming all baseline models. This improvement highlights the effectiveness of the proposed modules in enhancing Deformable DETR, enabling it to achieve State-of-the-Art performance in the coal mine conveyor belt foreign object detection task.
Table 3.
Overall Performance Comparisons (measured by AP50/mAP50).
Comparing the overall performance of the baselines, we can make the following key observations: (1) Models focusing on learnable and deformable proposals, such as Sparse-RCNN (73.10) and Deformable DETR (74.76), fail to achieve high accuracy in the complex coal mine conveyor belt environment. While these models effectively reduce the number of candidate boxes, they struggle with background clutter, leading to a drop in detection performance. This highlights the challenge posed by complex, non-uniform backgrounds in foreign object detection tasks. (2) Methods optimizing label assignment strategies, such as AutoAssign (75.45) and O2F (74.82), achieve better performance than Sparse-RCNN. This suggests that improving classification label assignment contributes to performance gains. Similarly, VarifocalNet (75.26) enhances classification confidence through its IoU-aware loss function, further validating that optimizing the classification head can yield improvements. (3) As foreign objects must be located on the conveyor belt, integrating contextual features from the surrounding coal can enhance detection accuracy. Models like CentripetalNet (76.61) and AFPN (77.42) improve representation learning by utilizing high-quality keypoints and hierarchical feature fusion, respectively. These enhancements allow them to integrate surrounding object features, leading to performance gains. However, CEASC (74.25), which incorporates a global context module, does not achieve as much improvement. This may be due to excessive inclusion of features outside the conveyor belt region, diluting the focus on relevant foreign object regions.
4.6. Ablation Study
In the ablation study, we compare CAFOD with four methods to demonstrate the contribution of each module: method A is the basic Deformable DETR. Method B is the baseline with MVDA. Method C is method B with CFP, and method D is CAFOD without VFL.
4.6.1. Detection Performance
Table 4 lists the performance of the method A–D and CAFOD. The results in each column are similar to Table 3. As the modules are progressively added to the baseline, the performance shows an increasing improvement, indicating that all four modules contribute positively to the proposed CAFOD. Each module plays a key role and their combined effect leads to the observed performance, with experiment results presented in Table 4.
Table 4.
Ablation Experiment (measured by AP50/mAP50).
Specifically, the results show that the MVDA, CFP, CBAL, and VFL modules can significantly improve the detection effect of the model on different foreign objects, respectively. Method B improves the detection performance of big coal and iron meshes by introducing MVDA. Method C, with the help of CFP, associates coal with foreign objects through context feature integration, improving the model’s recognition of potential foreign objects and thus enhancing the detection performance of various targets. Method D uses a penalty-driven strategy to penalize predictions outside the conveyor belt area, improving the model’s focus on the conveyor belt area. In particular, it reduces the influence of targets outside the conveyor belt area, bringing significant gains to the detection performance of iron meshes. Finally, CAFOD introduces VFL, combining the category and location scores of predicted targets, dynamically adjusting the sample loss weights, and further improving the overall performance of the model.
4.6.2. Analysis of Error Type
We introduced a TIDE evaluator [41] that analyzes different error types to assess the contribution of each module to the CAFOD’s performance. The error types in Figure 7 are:
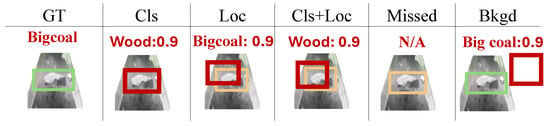
Figure 7.
Examples of TIDE error types. The red box is the prediction box, and the green box is GT (ground truth), marked with the prediction type and confidence score.
- Classification error (Cls): , but the classification is wrong;
- Localization error (Loc): the classification is right, but ;
- Both Cls and Loc error (Cls + Loc): and misclassified;
- Missed GT error (Missed): all undetected ground truth except Cls Error and Loc Error;
- Background error (Bkgd): for all ground truths .
The results of different error types on the entire dataset are reported in Table 5. It shows that all errors decrease with the modules added to method A, consistent with the results in Table 4. Specifically, method enables the model to learn more diverse features and have more accurate predictions of target locations, reducing Cls and Loc. Method C integrates foreign objects with their context features, decreasing Missed and Bkgd. Method D enhances the feature activation intensity of the conveyor belt area and brings location and category gains to the main model. Furthermore, it reduces the false detections of targets outside the conveyor belt area, decreasing various indicators. Finally, VFL dynamically adjusts the loss weights and enhances the loss weights of difficult samples during training, improving the model’s classification and localization capabilities and reducing Cls and Loc.
Table 5.
Ablation Results on Different Error Type.
4.6.3. Feature Map Visualization
We visualized the feature maps in Figure 8 to demonstrate the contribution of the CFP module. Compare the heat map of method A with and without CFP, we can find that: method A shows less clear boundaries, and the background also shows a higher intensity, while the heat map of CAFOD focuses better on the foreign objects on the conveyor belt, despite the complex background and the noises. The reason is that the CFP module captured the features around potential foreign objects and learned the correlation between foreign objects and their surrounding features.

Figure 8.
Feature map visualization.
4.7. Model Complexity Analysis
Foreign object detection in coal mines requires a balance between detection accuracy and computational efficiency. To evaluate this, we compare CAFOD with baseline models in terms of parameter size, GPU, and RAM usage, and computation time during training and inference, as shown in Table 6. All models were trained on the same dataset using an Intel Xeon E5-2666 v3 CPU, 20 GB RAM, and an NVIDIA Tesla V100 GPU (32 GB).
Table 6.
Model Complexity Comparision.
We can draw the following observations from Table 6. (1) In terms of training efficiency, CAFOD requires 22.4 GB GPU memory and 61,200 s for training, making it one of the more resource-intensive models. However, its training time remains competitive with Sparse-RCNN (64,082 s) and CentripetalNet (79,235 s), which consume similar resources but fail to achieve CAFOD’s superior detection accuracy. The increased computational demand stems from MVDA and CFP, which enhance feature extraction and generalization. (2) In term of inference speed and practical deployment, CAFOD processes an image in 0.2078 s, comparable to Deformable DETR (0.2186 s) and O2F (0.2015 s), while faster than CentripetalNet (0.7804 s) and VarifocalNet (0.6561 s). Although AFPN (0.0510 s) is the fastest, it sacrifices accuracy (77.42 mAP50 vs. 80.39 mAP50 for CAFOD). Moreover, CAFOD’s 1.24 GB GPU memory usage is lower than Sparse-RCNN (9.56 GB) and CentripetalNet (8.74 GB), making it more suitable for deployment on edge devices.
While CAFOD is not the fastest model, it maintains an optimal trade-off between accuracy and efficiency, justifying its computational cost with superior detection performance. This makes it practical for real-world deployment in coal mine conveyor belt monitoring, where high precision is essential alongside reasonable inference speed.
5. Conclusions
In this work, we propose CAFOD, a camera-adaptive foreign object detection model tailored for coal conveyor belts in coal mines. Motivated by the challenge of viewpoint variations and background interference in real-world environments, we introduced four key modules Multi-View Data Augmentation (MVDA), Context Feature Perception (CFP), Conveyor Belt Area Loss (CBAL), and Varifocal Loss (VFL)—to enhance the model’s robustness and generalization across multiple camera perspectives. The introduction of MVDA enables the model to learn viewpoint-invariant features, improving its adaptability to varying camera perspectives. CFP incorporates surrounding coal features to reduce false detections of irrelevant background objects outside the conveyor belt. CBAL enforces the model’s attention on the conveyor belt region, ensuring that detection focuses on targets within the belt area, while VFL enhances the model’s sensitivity to hard samples, improving overall detection accuracy. Extensive experiments on a self-collected dataset from three cameras in real coal mine environments demonstrate that CAFOD significantly outperforms the baseline Deformable DETR and other contemporary methods, especially under cross-camera evaluation settings. Compared with conventional object detection models that do not explicitly address multi-view variability and background interference, CAFOD achieves higher detection precision and superior generalization across different viewpoints. These results highlight the effectiveness and uniqueness of CAFOD in handling practical coal mine detection scenarios. The proposed method offers a promising solution for enhancing production safety and operational efficiency and is particularly suitable for deployment on edge devices in industrial applications.
Author Contributions
Conceptualization, F.P. and X.L.; methodology, F.P.; software, F.P. and K.H.; resources, F.P. and X.L.; writing—original draft preparation, F.P., K.H. and X.L.; writing—review and editing, K.H. and X.L.; funding acquisition, F.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (No. 62276162).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the author.
Acknowledgments
The authors are extremely grateful to other researchers for their valuable contributions to this manuscript. Kai Zhang provided industrial case studies and practical data, enriching the research with real-world insights. Guodong Li and Huiyuan Huang’s meticulous review and editing significantly improved the clarity and coherence of the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Luo, B.; Kou, Z.; Han, C.; Wu, J. A “hardware-friendly” foreign object identification method for belt conveyors based on improved YOLOv8. Appl. Sci. 2023, 13, 11464. [Google Scholar] [CrossRef]
- Shang, D.; Wang, Y.; Yang, Z.; Wang, J.; Liu, Y. Study on comprehensive calibration and image sieving for coal-gangue separation parallel robot. Appl. Sci. 2020, 10, 7059. [Google Scholar] [CrossRef]
- Yang, J.; Peng, J.; Li, Y.; Xie, Q.; Wu, Q.; Wang, J. Gangue Localization and Volume Measurement Based on Adaptive Deep Feature Fusion and Surface Curvature Filter. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, H.; Zhang, Y.; Yu, Y.; Zhou, M. Deep learning-based damage detection of mining conveyor belt. Measurement 2021, 175, 109130. [Google Scholar] [CrossRef]
- Liu, Y.; Miao, C.; Li, X.; Ji, J.; Meng, D.; Wang, Y. A Dynamic Self-Attention-Based Fault Diagnosis Method for Belt Conveyor Idlers. Machines 2023, 11, 216. [Google Scholar] [CrossRef]
- Zhang, R.; Lei, Y. AFGN: Attention Feature Guided Network for object detection in optical remote sensing image. Neurocomputing 2024, 610, 128527. [Google Scholar] [CrossRef]
- Li, Z.; Dong, Y.; Shen, L.; Liu, Y.; Pei, Y.; Yang, H.; Zheng, L.; Ma, J. Development and challenges of object detection: A survey. Neurocomputing 2024, 598, 128102. [Google Scholar] [CrossRef]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; Tang, Z. Bevfusion: A simple and robust lidar-camera fusion framework. Adv. Neural Inf. Process. Syst. 2022, 35, 10421–10434. [Google Scholar]
- Jiang, W.; Luan, Y.; Tang, K.; Wang, L.; Zhang, N.; Chen, H.; Qi, H. Adaptive feature alignment network with noise suppression for cross-domain object detection. Neurocomputing 2025, 614, 128789. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Chen, K.; Du, B.; Wang, Y.; Wang, G.; He, J. The real-time detection method for coal gangue based on YOLOv8s-GSC. J. Real-Time Image Process. 2024, 21, 37. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Szmigiel, A.; Chen, J. Image recognition of coal and coal gangue using a convolutional neural network and transfer learning. Energies 2019, 12, 1735. [Google Scholar] [CrossRef]
- Gao, R.; Sun, Z.; Li, W.; Pei, L.; Hu, Y.; Xiao, L. Automatic Coal and Gangue Segmentation Using U-Net Based Fully Convolutional Networks. Energies 2020, 13, 829. [Google Scholar] [CrossRef]
- Hu, T.; Zhuang, D.; Qiu, J. An EfficientNetv2-based method for coal conveyor belt foreign object detection. Front. Energy Res. 2025, 12, 1444877. [Google Scholar] [CrossRef]
- Li, X.; Li, W.; Qiu, K.; Wang, S.; Zhao, S. Coal mine belt conveyor foreign object detection based on improved yolov8. In Proceedings of the 2023 IEEE 11th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 8–10 December 2023; Volume 11, pp. 209–215. [Google Scholar]
- Ling, J.; Fu, Z.; Yuan, X. Lightweight coal mine conveyor belt foreign object detection based on improved Yolov8n. Sci. Rep. 2025, 15, 10361. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Li, M.; Li, R.; He, C.; Zhang, L. One-to-Few Label Assignment for End-to-End Dense Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7350–7359. [Google Scholar]
- Zhu, B.; Wang, J.; Jiang, Z.; Zong, F.; Liu, S.; Li, Z.; Sun, J. AutoAssign: Differentiable Label Assignment for Dense Object Detection. arXiv 2020. [Google Scholar] [CrossRef]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive Sparse Convolutional Networks with Global Context Enhancement for Faster Object Detection on Drone Images. arXiv 2023. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023; pp. 2184–2189. [Google Scholar] [CrossRef]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. CentripetalNet: Pursuing High-Quality Keypoint Pairs for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Xie, E.; Ding, J.; Wang, W.; Zhan, X.; Xu, H.; Sun, P.; Li, Z.; Luo, P. Detco: Unsupervised contrastive learning for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8392–8401. [Google Scholar]
- Hong, Y.; Wang, L.; Su, J.; Li, Y.; Zhu, B.; Wang, H. Enhanced foreign body detection on coal mine conveyor belts using improved DLEA and lightweight SARC-DETR model. Signal Image Video Process. 2025, 19, 349. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Z.; Qin, H.; Mu, X. Self-supervised domain feature mining for underwater domain generalization object detection. Expert Syst. Appl. 2025, 265, 126023. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable {DETR}: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Ding, J.; Ye, C.; Wang, H.; Huyan, J.; Yang, M.; Li, W. Foreign bodies detector based on detr for high-resolution X-ray images of textiles. IEEE Trans. Instrum. Meas. 2023, 72, 1–10. [Google Scholar] [CrossRef]
- Ge, Y.; Jiang, D.; Sun, L. Wood Veneer Defect Detection Based on Multiscale DETR with Position Encoder Net. Sensors 2023, 23, 4837. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Gao, F.; Sun, H.; Wei, H.; Wang, N.; Yang, B. LGCNet: A local-to-global context-aware feature augmentation network for salient object detection. Inf. Sci. 2022, 584, 399–416. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-Scale Feature Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 431–435. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, Y.; Chen, X.; Liu, J.; Qiao, Y. Context-transformer: Tackling object confusion for few-shot detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, UISA, 7–12 February 2020; Volume 34, pp. 12653–12660. [Google Scholar]
- Weisstein, E.W. Affine Transformation. 2004. Available online: https://mathworld.wolfram.com/ (accessed on 22 April 2025).
- Haines, E. Point in Polygon Strategies. Graph. Gems 1994, 4, 24–46. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On loss functions for deep neural networks in classification. arXiv 2017, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Li, G.; Peng, F.; Wu, Z.; Wang, S.; Xu, R.Y.D. ODCL: An Object Disentanglement and Contrastive Learning Model for Few-Shot Industrial Defect Detection. IEEE Sens. J. 2024, 24, 18568–18577. [Google Scholar] [CrossRef]
- Robertson, S. A new interpretation of average precision. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’08, Singapore, 20–24 July 2008; pp. 689–690. [Google Scholar] [CrossRef]
- Yue, Y.; Finley, T.; Radlinski, F.; Joachims, T. A support vector method for optimizing average precision. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’07, Amsterdam, The Netherlands, 23–27 July 2007; pp. 271–278. [Google Scholar] [CrossRef]
- Bolya, D.; Foley, S.; Hays, J.; Hoffman, J. Tide: A general toolbox for identifying object detection errors. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 558–573. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).