
Large Language Model Based Intelligent Fault Information Retrieval System for New Energy Vehicles



Abstract
1. Introduction
- Proposing an innovative electric vehicle fault information retrieval system that integrates large-scale language models and KGs, capable of efficiently managing diverse and fragmented fault data;
- Developing a knowledge graph covering 122 different fault categories and using the ChatGLM3-6B model to promote efficient extraction and reasoning of fault knowledge;
- Creating a fault diagnosis system based on RAG technology that provides accurate fault cause analysis and offers feasible solution recommendations.
2. Current Trends and Functional Requirements Analysis of Intelligent Fault Information Retrieval Systems for NEVs
2.1. Global Research Trends
2.1.1. Fault Diagnosis and Information Retrieval Systems Research Trends
2.1.2. Knowledge Graphs and Generative Language Models Research Trends
- (1)
- Generative Language Models
- (2)
- Knowledge Graphs and Applications
- (3)
- The Combination of Generative Language Models and KGs
2.2. Functional Requirements of Intelligent Fault Information Retrieval Systems for NEVs
- (1)
- Basic user needs: This includes understanding the aspects of NEV-related fault knowledge that different users prioritize; whether they have reliable methods and resources for obtaining information on NEV usage, maintenance, and upkeep; their preferred channels for accessing information when faults occur and the reliability of these channels, such as whether they can help users promptly identify and locate issues; users’ needs for rapid fault diagnosis tools and their trust in maintenance suggestions. Additionally, it investigates the performance of existing NEV mobile applications and automotive apps in meeting users’ daily fault information retrieval needs and whether these platforms and applications can provide users with fast and convenient services.
- (2)
- User preferences for fault information retrieval: For example, whether users prefer using search engines to find possible fault causes and solutions; their awareness of and specific requirements for professional intelligent search systems; whether traditional automotive fault diagnosis systems are difficult to use or require high technical expertise; the common challenges users face in accessing NEVs fault data; and their systematic needs for fault information retrieval.
- (3)
- Requirements for system functionality: Whether existing fault diagnosis expert systems can provide rapid analysis of fault information for different NEVs; whether they meet the needs of users who lack professional knowledge; whether the knowledge base of NEVs faults within these systems is comprehensive; whether existing automotive mobile applications support fault consultation and provide problem-solving suggestions; whether these applications present NEVs faults and solutions in an intuitive and user-friendly way; and whether the system platforms suffer from issues such as overly complicated interfaces, inefficiency in responding to user inquiries, or low responsiveness that negatively impact the user experience.
- (1)
- The user interfaces of existing automotive fault diagnosis expert systems are overly complex and crude, and there is limited information specifically related to NEVs.
- (2)
- Most systems are unable to conduct precise reasoning and analysis of automotive faults. The fault diagnosis technology they rely on requires a large amount of fault data to establish signal features or model parameters. For the vast variety of NEVS currently available, this is difficult to achieve under current conditions. Moreover, it is challenging to unify fault data for different models of NEVs. While knowledge-based reasoning methods do not require extensive fault data, they also face certain difficulties. For example, they can only perform fault detection within the scope of existing knowledge, and acquiring new knowledge is challenging, with incomplete representation of knowledge being another issue.
- (3)
- Existing automotive fault diagnosis systems are cumbersome to operate. Each vehicle model requires individual analysis, and the interfaces of both client applications and web pages are disorganized and cluttered.
- (1)
- Data acquisition: Intelligent methods should be used to construct a dataset specifically focused on the domain of NEV faults; additionally, a large amount of unstructured and semi-structured data scattered across different sources and literature should be systematically integrated.
- (2)
- Knowledge database layer: Current fault diagnosis expert systems based on fault tree analysis methods lack quick and convenient maintenance and knowledge acquisition capabilities; automotive-related websites and applications, such as Autohome and DCar, provide users with basic data like vehicle configuration parameters but fail to deliver sufficient data to comprehensively integrate knowledge in the field of NEVs. Therefore, it is necessary to construct databases and presentation methods tailored to the characteristics of NEV knowledge data. This process should involve maintaining data by model, based on common fault types and phenomena, to ultimately form a comprehensive knowledge set for NEVs faults.
- (3)
- Technical methods: Current automotive fault diagnosis technologies are unable to perform precise reasoning and analysis for NEV faults, as they rely heavily on large amounts of fault data to establish signal features or model parameters, which is difficult to achieve given the relatively short time NEVs have existed and their diverse range of models. Although knowledge-based reasoning methods do not require extensive fault data, they have limitations, such as their inability to detect faults beyond the existing knowledge base, difficulties in acquiring new knowledge, and incomplete knowledge representation. To address these challenges, it is necessary to employ artificial intelligence, expert system methods, and knowledge graph technologies, such as RAG for LLMs, Prompt engineering [31,32], fine-tuning of LLMs [33], BERT classification algorithms, Cypher query language, front-end visualization, and API streaming for LLMs. Through the systematic integration of these technologies, an intelligent fault diagnosis and analysis platform for NEVs can be established.
- (4)
- System presentation: Traditional fault diagnosis expert systems have relatively simple user interface designs, while existing automotive website platforms suffer from overly complex and cluttered page information, with their main content dominated by conventional automobiles and related data. Additionally, pages designed for user feedback on fault issues are poorly structured, making information retrieval difficult. To resolve these issues, new technologies should be implemented, such as the Flask framework combined with visualization techniques, to develop a fault data retrieval system specifically for NEVs. This system should enable intuitive visualization of the NEV faults knowledge graph, providing users with a more user-friendly and convenient service for fault diagnosis and information retrieval.
3. System Design of Intelligent Retrieval of Fault Information
3.1. The Logical Structure Design of the Fault Data Retrieval System
3.1.1. The Integration of Fault Diagnosis Technology
- (1)
- Fault Tree Analysis
- (2)
- Fault Diagnosis Expert System
- (3)
- Integration of Fault Tree Analysis and Fault Diagnosis Expert System
3.1.2. The Logical Integration of Large Language Models and Knowledge Graphs
3.2. The Framework Design of the Fault Data Retrieval System
3.2.1. Large Language Models Module
- (1)
- Data acquisition and preprocessing
- (2)
- Model training
- (3)
- Model evaluation
3.2.2. Knowledge Graphs Module
- (1)
- Knowledge modeling
- (2)
- Knowledge extraction
- (3)
- Knowledge storage
3.2.3. Integrated Reasoning Module
- (1)
- Fault classification
- (2)
- Information retrieval
- (3)
- Fault reasoning
4. Results
4.1. Data Acquisition and Preprocessing
4.2. New Energy Vehicles Fault Model Training
4.2.1. New Energy Vehicle Fault Knowledge Model Training
- (1)
- P-Tuning V2 fine-tuning
- (2)
- LoRA fine-tuning
- (3)
- Experiment and results analysis
4.2.2. New Energy Vehicle Fault Classification Model Training
4.3. Knowledge Extraction
4.3.1. Named Entity Extraction in the Domain of NEV Faults
4.3.2. Knowledge Reuse and Substitution in the Domain of NEV Faults
4.4. System Development Technology
4.5. System Demonstration and Testing
4.5.1. System Presentation
4.5.2. System Testing
5. Discussion
5.1. Knowledge Graph and Fine-Tuning of Large Language Models
5.2. Discussion on Fault Data Retrieval and System Interaction
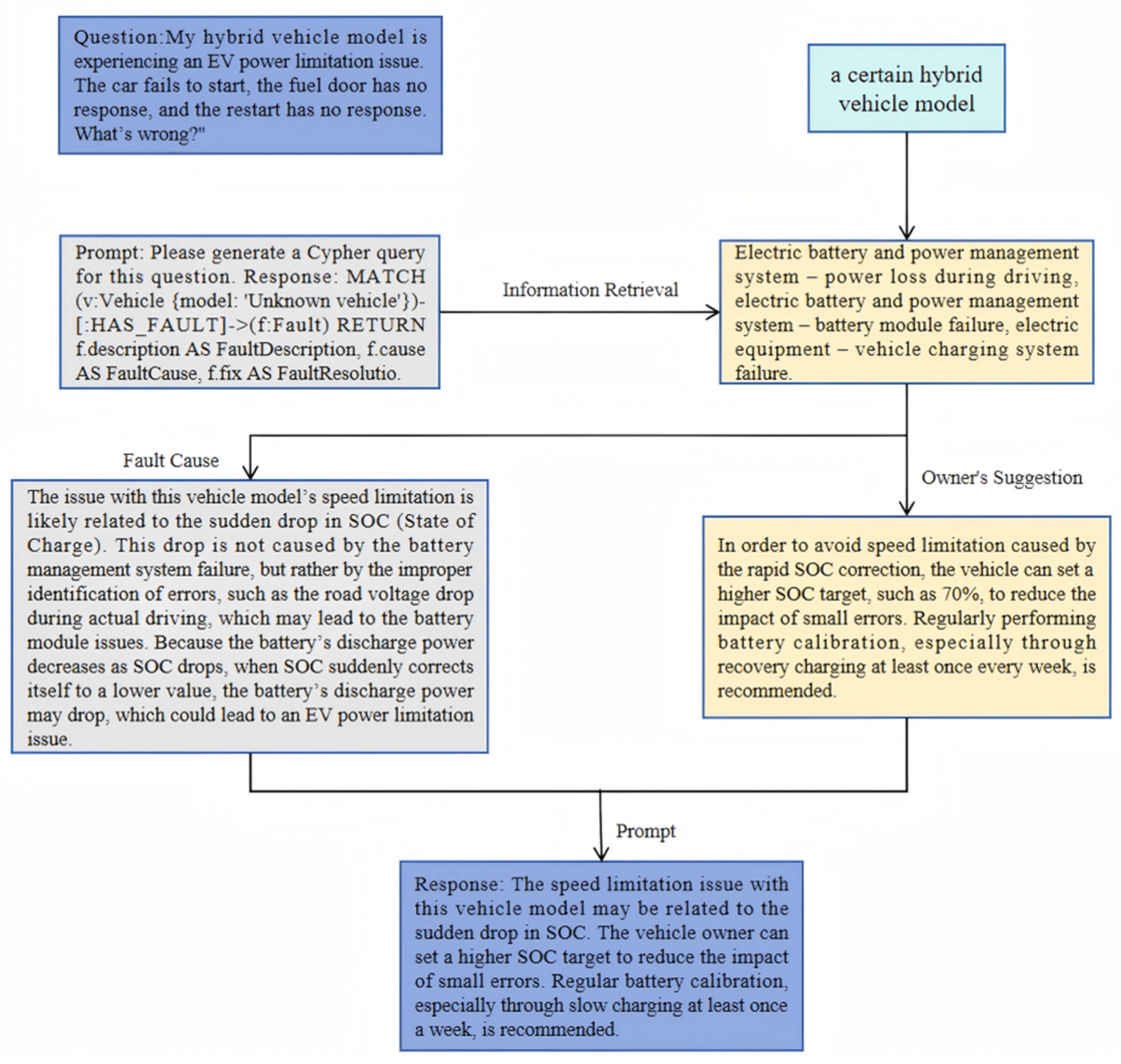
5.2.1. The Process of Intelligent Retrieval of Fault Information of NEVs
5.2.2. Elaboration of the System Information Interaction Flow’s Framework
6. Conclusions and Prospects
- (1)
- Enhancing fault data retrieval—Improving entity extraction, fault categorization, and relational identification, and optimizing graph-based retrieval processes.
- (2)
- Automating knowledge graph updates—Leveraging generative models to enable real-time knowledge graph construction and updates, ensuring data relevance and accuracy.
- (3)
- System integration—Incorporating the NEV fault retrieval system with vehicular networking and maintenance decision support systems to create a comprehensive NEV service ecosystem, facilitating data interchange and functional integration.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Standard (GB/T) | Title |
|---|---|---|
| 1 | GB/T 18385-2005 | Electric Vehicle Power Performance |
| 2 | GB/T 18386.1-2021 | Energy Consumption and Range for Light-duty Electric Vehicles |
| 3 | GB/T 18388-2005 | Electric Vehicle Type Testing Regulations |
| 4 | GB/T 24552-2009 | Electric Vehicle Windshield Defogging and Dew Removal |
| 5 | GB/T 28382-2012 | Technical Conditions for Pure Electric Passenger Vehicles |
| 6 | GB/T 36980-2018 | Energy Consumption Rate Limit for Electric Vehicles |
| 7 | GB/T 19750-2005 | Hybrid Electric Vehicle Type Testing Regulations |
| 8 | GB/T 19752-2005 | Hybrid Electric Vehicle Power Performance |
| 9 | GB/T 19753-2021 | Energy Consumption Testing Methods for Hybrid Electric Vehicles |
References
- Khaneghah, M.Z.; Alzayed, M.; Chaoui, H. Fault Detection and Diagnosis of the Electric Motor Drive and Battery System of Electric Vehicles. Machines 2023, 11, 713. [Google Scholar] [CrossRef]
- Lang, W.; Hu, Y.; Gong, C.; Zhang, X.; Xu, H.; Deng, J. Artificial Intelligence-Based Technique for Fault Detection and Diagnosis of EV Motors: A Review. IEEE Trans. Transp. Electrif. 2021, 8, 384–406. [Google Scholar] [CrossRef]
- El-Ghaname, J. Automotive Fault Detection Using Knowledge Graph Embedding. Master’s Thesis, University of Windsor, Windsor, ON, Canada, 2022. [Google Scholar]
- Cong, X.; Zhang, C.; Jiang, J.; Zhang, W.; Jiang, Y.; Zhang, L. A Comprehensive Signal-Based Fault Diagnosis Method for Lithium-Ion Batteries in Electric Vehicles. Energies 2021, 14, 1221. [Google Scholar] [CrossRef]
- Nandi, S.; Toliyat, H.A.; Li, X. Condition Monitoring and Fault Diagnosis of Electrical Motors—A Review. IEEE Trans. Energy Convers. 2005, 20, 719–729. [Google Scholar]
- Ahmad, I.S.; Abubakar, S.; Gambo, F.L.; Gadanya, M.S. A Rule-Based Expert System for Automobile Fault Diagnosis. Int. J. Perceptive Cogn. Comput. 2021, 7, 20–25. [Google Scholar]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N.; Yin, K. A Review of Process Fault Detection and Diagnosis: Part III: Process History Based Methods. Comput. Chem. Eng. 2003, 27, 327–346. [Google Scholar]
- Zhang, Z.; Deng, Y.; Liu, X.; Liao, J. Research on Fault Diagnosis of Rotating Parts Based on Transformer Deep Learning Model. Appl. Sci. 2024, 14, 10095. [Google Scholar] [CrossRef]
- Qiao, Z.; Lei, Y.; Li, N. Applications of Stochastic Resonance to Machinery Fault Detection: A Review and Tutorial. Mech. Syst. Signal Process. 2019, 122, 502–536. [Google Scholar] [CrossRef]
- Xiao, Y.; Han, F.; Ding, Y.; Liu, W. Research on Fault Diagnosis Method of Rapier Loom Based on the Fusion of Expert System and Fault Tree. J. Intell. Fuzzy Syst. 2021, 41, 3429–3441. [Google Scholar]
- Zheng, H.; Wang, R.; Yang, Y.; Yin, J.; Li, Y.; Li, Y.; Xu, M. Cross-Domain Fault Diagnosis Using Knowledge Transfer Strategy: A Review. IEEE Access 2019, 7, 129260–129290. [Google Scholar] [CrossRef]
- Jafari, S.; Shahbazi, Z.; Byun, Y.-C.; Lee, S.-J. Lithium-Ion Battery Estimation in Online Framework Using Extreme Gradient Boosting Machine Learning Approach. Mathematics 2022, 10, 888. [Google Scholar] [CrossRef]
- Xia, Z.; Ye, F.; Dai, M.; Zhang, Z. Real-Time Fault Detection and Process Control Based on Multi-Channel Sensor Data Fusion. Int. J. Adv. Manuf. Technol. 2021, 115, 795–806. [Google Scholar] [CrossRef]
- Du, C.; Li, W.; Rong, Y.; Li, F.; Yu, F.; Zeng, X. Research on the Application of Artificial Intelligence Method in Automobile Engine Fault Diagnosis. Eng. Res. Express 2021, 3, 026002. [Google Scholar] [CrossRef]
- Liu, H.; Song, X.; Zhang, F. Fault Diagnosis of New Energy Vehicles Based on Improved Machine Learning. Soft Comput. 2021, 25, 12091–12106. [Google Scholar] [CrossRef]
- Gong, C.-S.A.; Su, C.-H.S.; Chen, Y.-H.; Guu, D.-Y. How to Implement Automotive Fault Diagnosis Using Artificial Intelligence Scheme. Micromachines 2022, 13, 1380. [Google Scholar] [CrossRef] [PubMed]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in BERTology: What We Know about How BERT Works. Trans. Assoc. Comput. Linguist. 2021, 8, 842–866. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Dalal, A.-A.; Cai, Z.; Al-qaness, M.A.; Alawamy, E.A.; Alalimi, A. ETR: Enhancing Transformation Reduction for Reducing Dimensionality and Classification Complexity in Hyperspectral Images. Expert Syst. Appl. 2023, 213, 118971. [Google Scholar]
- McCann, B.; Keskar, N.S.; Xiong, C.; Socher, R. The Natural Language Decathlon: Multitask Learning as Question Answering. arXiv 2018, arXiv:180608730. [Google Scholar]
- Wang, J.; Wang, C.; Luo, F.; Tan, C.; Qiu, M.; Yang, F.; Shi, Q.; Huang, S.; Gao, M. Towards Unified Prompt Tuning for Few-Shot Text Classification. arXiv 2022, arXiv:220505313. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://openai.com/research/language-unsupervised (accessed on 26 February 2025).
- Nori, H.; King, N.; McKinney, S.M.; Carignan, D.; Horvitz, E. Capabilities of Gpt-4 on Medical Challenge Problems. arXiv 2023, arXiv:230313375. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. Gpt-4 Technical Report. arXiv 2023, arXiv:230308774. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef]
- Bi, Z.; Chen, J.; Jiang, Y.; Xiong, F.; Guo, W.; Chen, H.; Zhang, N. Codekgc: Code Language Model for Generative Knowledge Graph Construction. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024, 23, 45. [Google Scholar] [CrossRef]
- Liang, W.; Yuksekgonul, M.; Mao, Y.; Wu, E.; Zou, J. GPT Detectors Are Biased against Non-Native English Writers. Patterns 2023, 4, 100779. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Li, X.; Zhao, R.; Chia, Y.K.; Ding, B.; Joty, S.; Poria, S.; Bing, L. Chain-of-Knowledge: Grounding Large Language Models via Dynamic Knowledge Adapting over Heterogeneous Sources. arXiv 2024, arXiv:2305.13269. [Google Scholar]
- Sun, J.; Xu, C.; Tang, L.; Wang, S.; Lin, C.; Gong, Y.; Ni, L.M.; Shum, H.-Y.; Guo, J. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. arXiv 2023, arXiv:230707697. [Google Scholar]
- Gao, A. Prompt Engineering for Large Language Models. 2023. Available online: https://ssrn.com/abstract=4504303 (accessed on 26 February 2025).
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2023, 55, 195. [Google Scholar] [CrossRef]
- Wang, J.; Yin, W.; Gao, J. Cases Integration System for Fault Diagnosis of CNC Machine Tools Based on Knowledge Graph. Acad. J. Sci. Technol. 2023, 5, 273–281. [Google Scholar] [CrossRef]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:220607682. [Google Scholar]
- Hamad, K.; Kaya, M. A Detailed Analysis of Optical Character Recognition Technology. Int. J. Appl. Math. Electron. Comput. 2016, 244–249. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.-Y. Rouge: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol. 2024, 15, 39. [Google Scholar] [CrossRef]
- Hao, X.; Ji, Z.; Li, X.; Yin, L.; Liu, L.; Sun, M.; Liu, Q.; Yang, R. Construction and Application of a Knowledge Graph. Remote Sens. 2021, 13, 2511. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; D’amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge Graphs. ACM Comput. Surv. 2022, 54, 71. [Google Scholar] [CrossRef]
- Jiang, X.-J.; Zhou, W.; Hou, J. Construction of Fault Diagnosis System for Control Rod Drive Mechanism Based on Knowledge Graph and Bayesian Inference. Nucl. Sci. Tech. 2023, 34, 21. [Google Scholar] [CrossRef]
- Deng, J.; Wang, T.; Wang, Z.; Zhou, J.; Cheng, L. Research on Event Logic Knowledge Graph Construction Method of Robot Transmission System Fault Diagnosis. IEEE Access 2022, 10, 17656–17673. [Google Scholar] [CrossRef]
- Wang, H.; Qin, K.; Zakari, R.Y.; Lu, G.; Yin, J. Deep Neural Network-Based Relation Extraction: An Overview. Neural Comput. Appl. 2022, 34, 4781–4801. [Google Scholar]
- Ding, N.; Qin, Y.; Yang, G.; Wei, F.; Yang, Z.; Su, Y.; Hu, S.; Chen, Y.; Chan, C.-M.; Chen, W.; et al. Parameter-Efficient Fine-Tuning of Large-Scale Pre-Trained Language Models. Nat. Mach. Intell. 2023, 5, 220–235. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey. ACM Comput. Surv. 2023, 56, 30. [Google Scholar] [CrossRef]
- Chai, C.P. Comparison of Text Preprocessing Methods. Nat. Lang. Eng. 2023, 29, 509–553. [Google Scholar] [CrossRef]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.L.; Du, Z.; Yang, Z.; Tang, J. P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-Tuning Universally across Scales and Tasks. arXiv 2021, arXiv:211007602. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-Rank Adaptation of Large Language Models. ICLR 2022, 1, 3. [Google Scholar]
- Chen, H.; Shi, N.; Chen, L.; Lee, R. Enhancing Educational Q&A Systems Using a Chaotic Fuzzy Logic-Augmented Large Language Model. Front. Artif. Intell. 2024, 7, 1404940. [Google Scholar]















| Method | Core Focus | Limitation | Reference Examples |
|---|---|---|---|
| Pure LLM Reasoning | Using the idea of linking, LLMs can solve some reasoning problems | Difficult to handle professional knowledge-intensive reasoning and complex reasoning tasks [28] | ChatGPT4.0, ChatGPT3.5, ChatGLM, Wenxin-Yiyan, etc. |
| LLM⊕KG | Large models play various roles, through querying knowledge in KG to enhance reasoning capabilities, enabling the addition of external knowledge into the model | Embedding LLM into KG limits its interpretability and introduces complexity when updating the knowledge base | Li et al. used LLM to generate SPARQL queries for KGs, and the main subject of the study is to complete KGs [29] |
| LLM⊗KG | Cooperation between KG and LLM, enabling knowledge graph completion and reasoning through both LLM and KG integration | Needing to consider the accurate path to knowledge graph completion while integrating external knowledge | Sun et al. used KG/LLM in the beam search algorithm for knowledge reasoning, enabling enhanced path expansion for KG generation [30] |
| Serial Number | Existing Problems in the System | Brief Description | System Requirements | New System Requirements |
|---|---|---|---|---|
| 1 | Information search is inconvenient | The client-side web page refreshes, the interface is not user-friendly, and there is no focus on NEV fault optimization | Customer-side retrieval is complicated, and the interface is inconvenient | The interface should be concise, user-friendly, and able to quickly locate the required functions |
| 2 | No specific model for vehicle faults | There is no specific fault diagnosis system for vehicles | Technical method | Needs a fault detection model for vehicle fault diagnosis, providing precise and natural interaction for troubleshooting |
| 3 | Lack of relevant knowledge | NEV fault knowledge is scattered and unorganized | Data acquisition | Needs to organize knowledge on NEVs faults and establish a knowledge base with feedback. |
| 4 | Data resource scarcity | Needs to build a knowledge base for NEV faults | Knowledge base | Needs to build a specialized knowledge base for NEVs with capabilities for easy integration and expert use |
| Method | Category | Accuracy P% | Recall Rate R% | F1 Score % |
|---|---|---|---|---|
| BERT | Braking System Fault | 87.22 | 88.36 | 88.03 |
| Electric Drive System Fault | 85.68 | 86.24 | 85.96 | |
| LSTM | Braking System Fault | 81.14 | 82.59 | 81.86 |
| Electric Drive System Fault | 84.27 | 85.61 | 84.93 | |
| TF-IDF + Naïve Bayes | Braking System Fault | 71.42 | 72.79 | 72.10 |
| Electric Drive System Fault | 66.34 | 71.66 | 68.90 | |
| TF-IDF + Ridge Regression | Braking System Fault | 73.19 | 72.59 | 72.89 |
| Electric Drive System Fault | 77.15 | 79.60 | 78.36 |
| Model Name | Entity Category | Accuracy P% | Recall Rate R% | F1 Score % |
|---|---|---|---|---|
| BERT-BiGRU-CRF | NEV Brand | 78.33 | 66.29 | 71.80 |
| NEV Model | 76.70 | 70.33 | 73.38 | |
| NEV Fault Category | 63.48 | 51.29 | 56.74 | |
| NEV Fault Name | 80.69 | 67.72 | 73.64 | |
| NEV Fault Phenomenon | 52.96 | 31.89 | 39.81 | |
| ChatGLM3-6B In-Context Learning | NEV Brand | 88.64 | 63.28 | 73.84 |
| NEV Model | 81.18 | 68.45 | 74.27 | |
| NEV Fault Category | 75.32 | 62.13 | 68.09 | |
| NEV Fault Name | 89.65 | 65.56 | 75.74 | |
| NEV Fault Phenomenon | 65.74 | 59.12 | 62.25 |
| ID | Domain Term | Synonyms |
|---|---|---|
| 001 | Battery Cell Insulation | Battery Foam Padding |
| 002 | Motor Cover | Front Cover |
| 003 | Motor Rear Cover | End Cap, Transparent Cap |
| 004 | Qin PLUS | Qin PLUS DM-i, Qin PLUS EV |
| … | … | … |
| 217 | Volvo XC60 New Energy | Volvo XC60 RECHARGE |
| Environment | Parameter | Environment | Parameter |
|---|---|---|---|
| Operating System | Windows11 64-bit | Memory | 32 GB |
| CPU | Intel(R) Core (TM) i9-11900H CPU (Santa Clara, CA, USA)@ 2.50 GHz (2502 MHz) | Graphics card | NVIDIA GeForce RTX3070 Laptop GPU 8G GDDR6 |
| Test Items | Operating Procedures | Expected Results | Test Results |
|---|---|---|---|
| User Interface Responsiveness Testing | Accessing the system interface via WEB pages | The system icons, buttons, and other user interface elements are displayed normally, and the user interaction functions are free of obstacles | Pass |
| Type of fault identification | Inputting fault information into the fault classification model in the background | The fault information inputted can be correctly received and parsed by the fault classification model. | Pass |
| Knowledge base search | The data parsed is retrieved from the knowledge base | The knowledge base can successfully retrieve data related to the parsed information | Pass |
| Fault data retrieval and graph visualization function | Submit the fault information after inputting it | The page can stream and analyze the data and display dynamic visual effects of the fault information-related graphs | Pass |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Zhao, Y.; Sun, B.; Wu, Y.; Fu, Z.; Xiao, X. Large Language Model Based Intelligent Fault Information Retrieval System for New Energy Vehicles. Appl. Sci. 2025, 15, 4034. https://doi.org/10.3390/app15074034
Zhang H, Zhao Y, Sun B, Wu Y, Fu Z, Xiao X. Large Language Model Based Intelligent Fault Information Retrieval System for New Energy Vehicles. Applied Sciences. 2025; 15(7):4034. https://doi.org/10.3390/app15074034
Chicago/Turabian StyleZhang, Haiyu, Yinghui Zhao, Boyu Sun, Yaqi Wu, Zetian Fu, and Xinqing Xiao. 2025. "Large Language Model Based Intelligent Fault Information Retrieval System for New Energy Vehicles" Applied Sciences 15, no. 7: 4034. https://doi.org/10.3390/app15074034
APA StyleZhang, H., Zhao, Y., Sun, B., Wu, Y., Fu, Z., & Xiao, X. (2025). Large Language Model Based Intelligent Fault Information Retrieval System for New Energy Vehicles. Applied Sciences, 15(7), 4034. https://doi.org/10.3390/app15074034