
Enhancing Software Quality with AI: A Transformer-Based Approach for Code Smell Detection



Abstract
1. Introduction
2. Literature Review
2.1. Traditional Machine-Learning Techniques
2.2. Deep Learning and Code Representation
2.3. Transformer Models in Code Analysis
2.4. Recent Transformer-Based Models for Code Analysis
2.5. Novel Architectures for Code Smell Detection
3. Methodology
3.1. Data Preparation
- Data cleaning: We cleaned the dataset by replacing missing values in numerical data with the median of the corresponding feature. This prevented the loss of information while training the models.
- Normalization: We normalized all features using the min–max scaling method so that the feature values range between 0 and 1. This normalization was done to have features with large magnitudes not to take the center stage in modeling.
- Feature selection: Features with a Pearson correlation coefficient > 0.2 of the target labels were chosen. This approach eliminated noise and retained features most likely to contain smell indicators.
- Train test split: in the current study, the stratified sampling procedure was employed to divide the collected dataset into training and testing sets in a proportion of 4:1, respectively, and the class distribution in both partitions was balanced.
Code Smells Considered
3.2. Model Architectures
3.2.1. Hyperparameter Sensitivity Analysis for Model Architecture
3.2.2. Observations on Hyperparameter Sensitivity Analysis
3.2.3. Classical Machine-Learning Models
- Logistic regression (LR): the most basic linear model that can be used to solve machine-learning binary classification problems [39].
- Support vector machine (SVM): deployed using a kernel function that extends the MLP architecture for radial basis function to address non-linear decision boundaries [41].
- Decision trees (DT): contain easily impartible rules for defining large classes [41].
- Gradient boosting (GB): An open-source machine-learning approach for addressing complicated interactions in feature sets using a collection of weak learners [45].
3.2.4. Transformer-Based Architectures
- Feature-Aware BERT (FABERT): This model tokenizes features and their values (e.g., “LOC: 100”) and embeds them using feature-specific embeddings. The resulting token embeddings are passed through a BERT encoder, and the [CLS] token embedding is used for classification.
- Hierarchical BERT: This model groups features into categories (e.g., code metrics, cognitive metrics) and processes each group independently using a separate BERT encoder. The outputs from all encoders are concatenated and passed through a classification head to model hierarchical relationships [20].
- Relation-Aware BERT (RABERT): RABERT augments BERT’s self-attention mechanism with relational embeddings that explicitly model dependencies between features (e.g., the relationship between LOC and volume). This allows the model to capture interdependencies more effectively.
3.2.5. Relational Embeddings for Code Smell Detection
Mathematical Formulation
Pseudocode for Relation-Aware Self-Attention
| Algorithm 1: Relation-Aware Self-Attention |
| 1: #Input: 2: #X: Input feature matrix (batch_size x seq_length x d_model) 3: #W_Q, W_K, W_V: Learned projection matrices for Q, K, V respectively 4: #R: Relation embedding tensor (seq_length x seq_length x d_relation) 5: #Scale: Scaling factor = sqrt(d_k) 6: def relation_aware_self_attention(X, W_Q, W_K, W_V, R): 7: #Project the input matrix X to queries, keys, and values 8: Q = X @ W_Q # shape: (batch_size, seq_length, d_k) 9: K = X @ W_K # shape: (batch_size, seq_length, d_k) 10: V = X @ W_V # shape: (batch_size, seq_length, d_v) 11: # Initialize the attention score matrix 12: batch_size, seq_length, _ = Q.shape 13: scores = zeros((batch_size, seq_length, seq_length)) 14: # Compute attention scores with relational embeddings 15: for b in range(batch_size): 16: for i in range(seq_length): 17: for j in range(seq_length): 18: # Standard dot-product attention term 19: standard_score = dot(Q[b, i], K[b, j]) 20: # Relational term: Assume a projection function (e.g., linear mapping) is applied to r_ij 21: # Here, r_proj could be a learned projection of the relation embedding to the same dimension as d_k. 22: r_proj = project_relation(R[i, j]) 23: relation_score = dot(Q[b, i], r_proj) 24: # Combine the scores and apply scaling 25: scores[b, i, j] = (standard_score + relation_score)/Scale 26: # Compute attention weights using softmax 27: attention_weights = softmax(scores, axis = −1) 28: # Calculate the final output as a weighted sum of the value vectors 29: output = zeros((batch_size, seq_length, V.shape[−1])) 30: for b in range(batch_size): 31: for i in range(seq_length): 32: for j in range(seq_length): 33: output[b, i] += attention_weights[b, i, j] * V[b, j] 34: return output |
3.2.6. Discussion
3.3. Training Configuration
- Batch Size: 16;
- Sequence Length: 128 tokens;
- Learning Rate: 2 × 10−5, optimized using the AdamW optimizer [44];
- Epochs: 10, with early stopping based on validation performance.
3.4. Evaluation Metrics Used in Model Architrecture
- Accuracy: accuracy is defined as the ratio of all correct predictions (both true positives and true negatives) to the total number of predictions made.
- Precision: precision focuses specifically on the model’s performance on the predicted positive instances.
- Recall: a fraction of true positives among all actual positives, reflecting the model’s sensitivity to identifying all instances of the target class.
- F1-Score: the harmonic mean of precision and recall, balancing these two metrics.
4. Experimental Setup
4.1. Dataset Overview
4.2. Column Names
4.3. Dataset Sources
4.4. Selection Criteria
- Class size and complexity: only classes with at least 50 lines of code (LOC) were included, ensuring that trivial classes were excluded.
- Metric completeness: classes missing essential metrics (e.g., Halstead measures) were excluded.
- Code smell labeling: The large class smell was identified using predefined thresholds for LOC, cognitive complexity, and Halstead volume, based on industry best practices and prior research.
- Manual validation: a subset (10%) of the dataset was manually reviewed by software engineers to verify correctness of labels.
4.5. Preprocessing
5. Results
5.1. Baseline Models
5.2. Transformer-Based Models
5.3. Per-Class Performance Evaluation
5.4. Statistical Validation
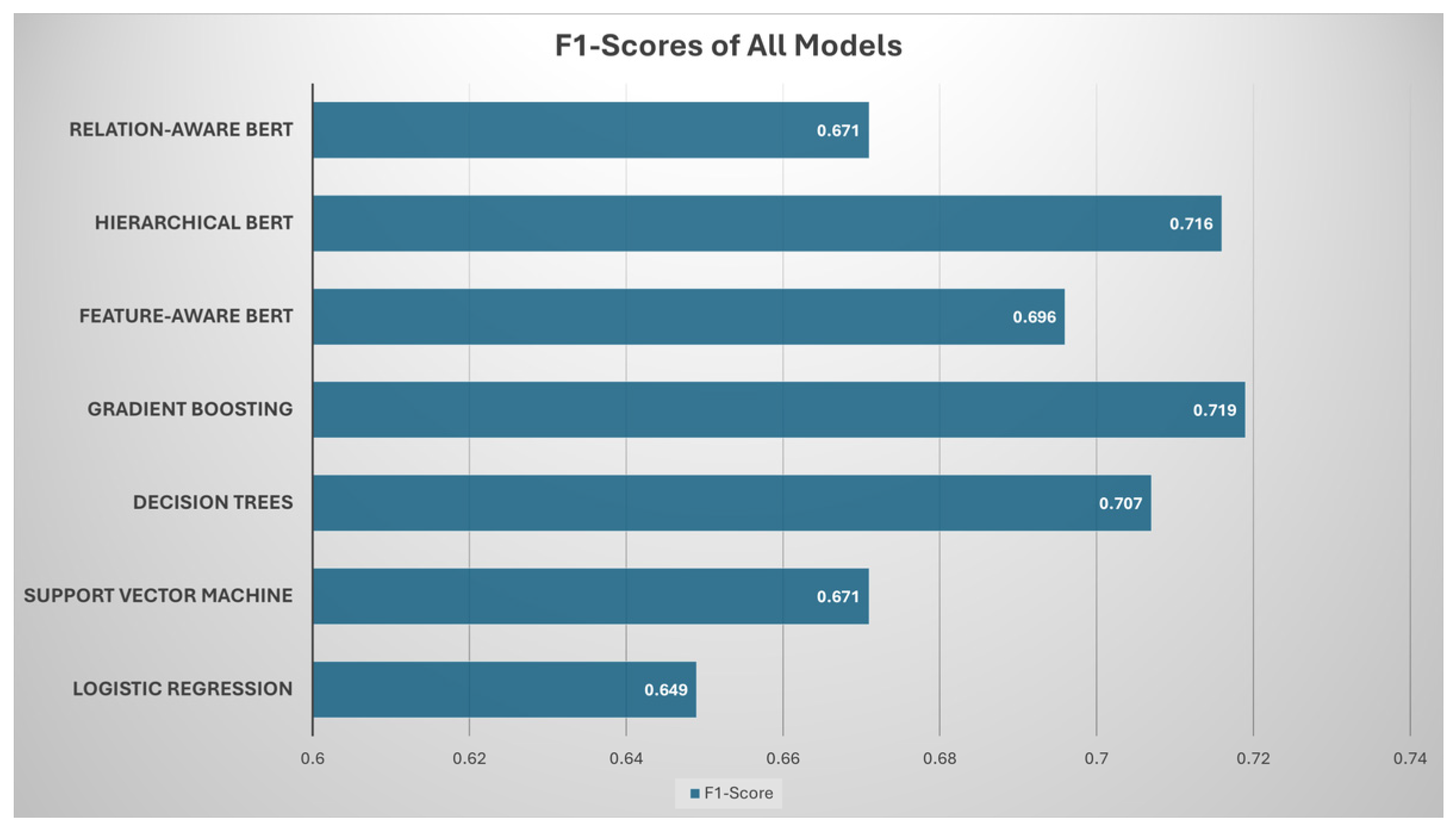
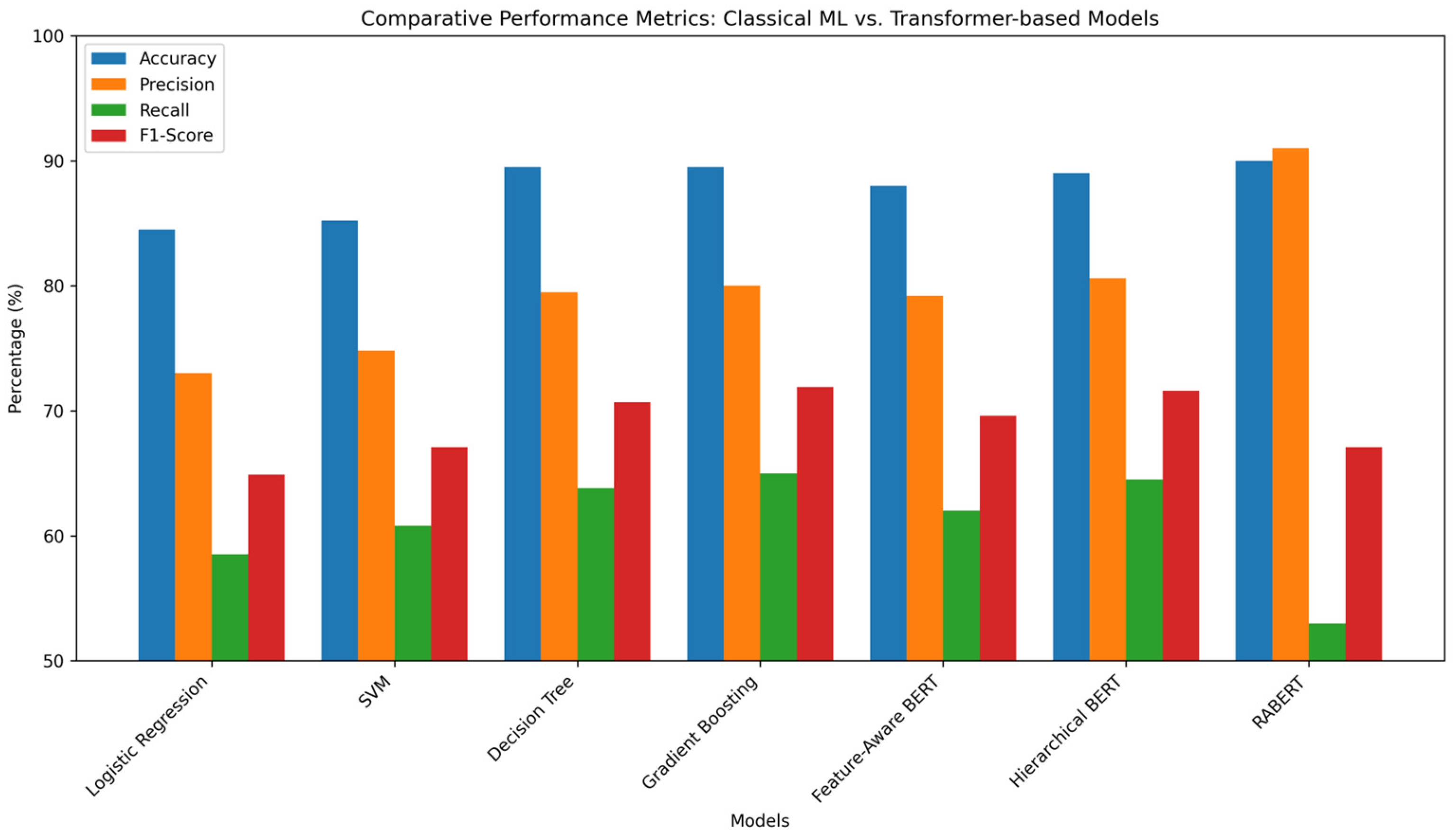
5.5. Comparative Analysis
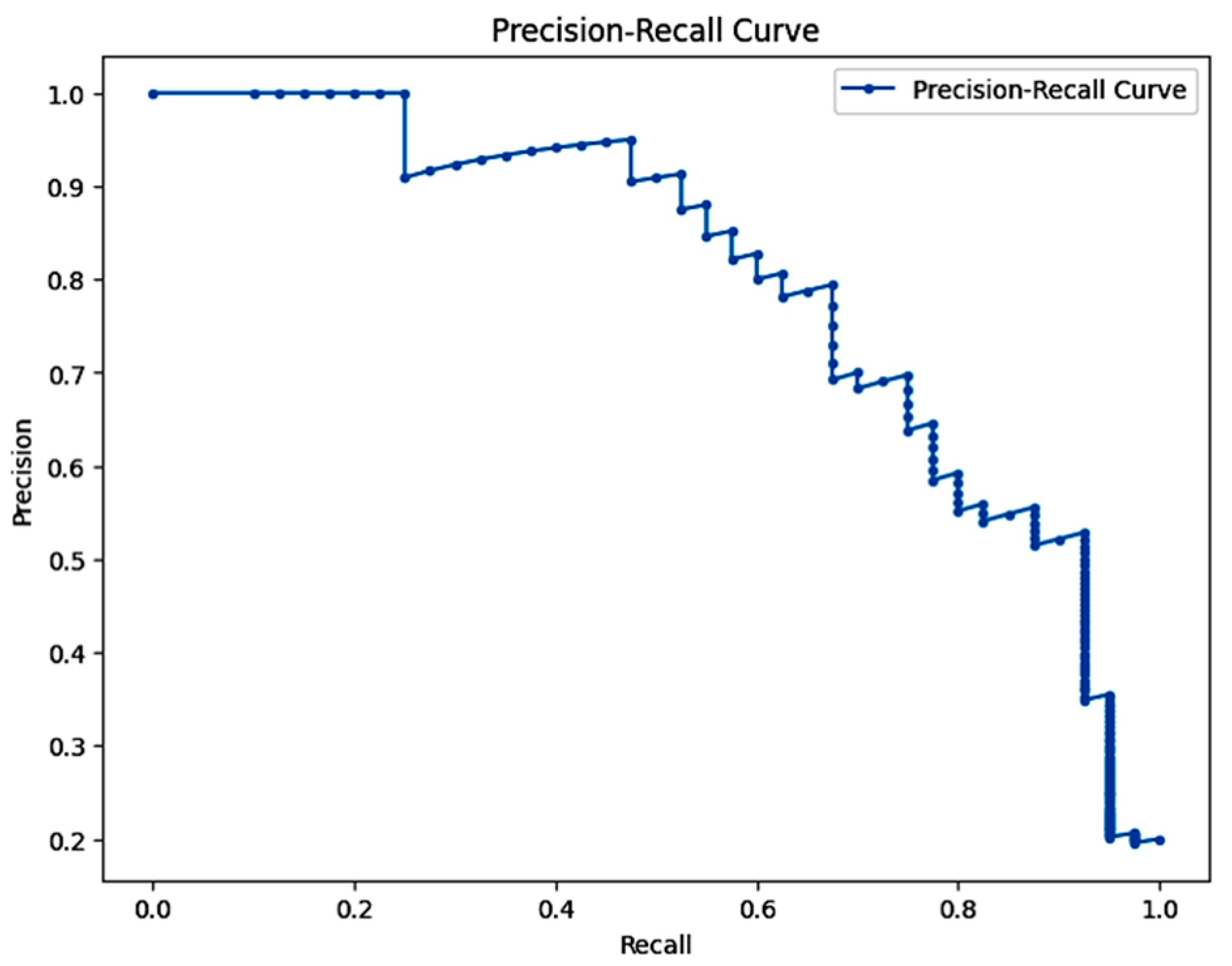
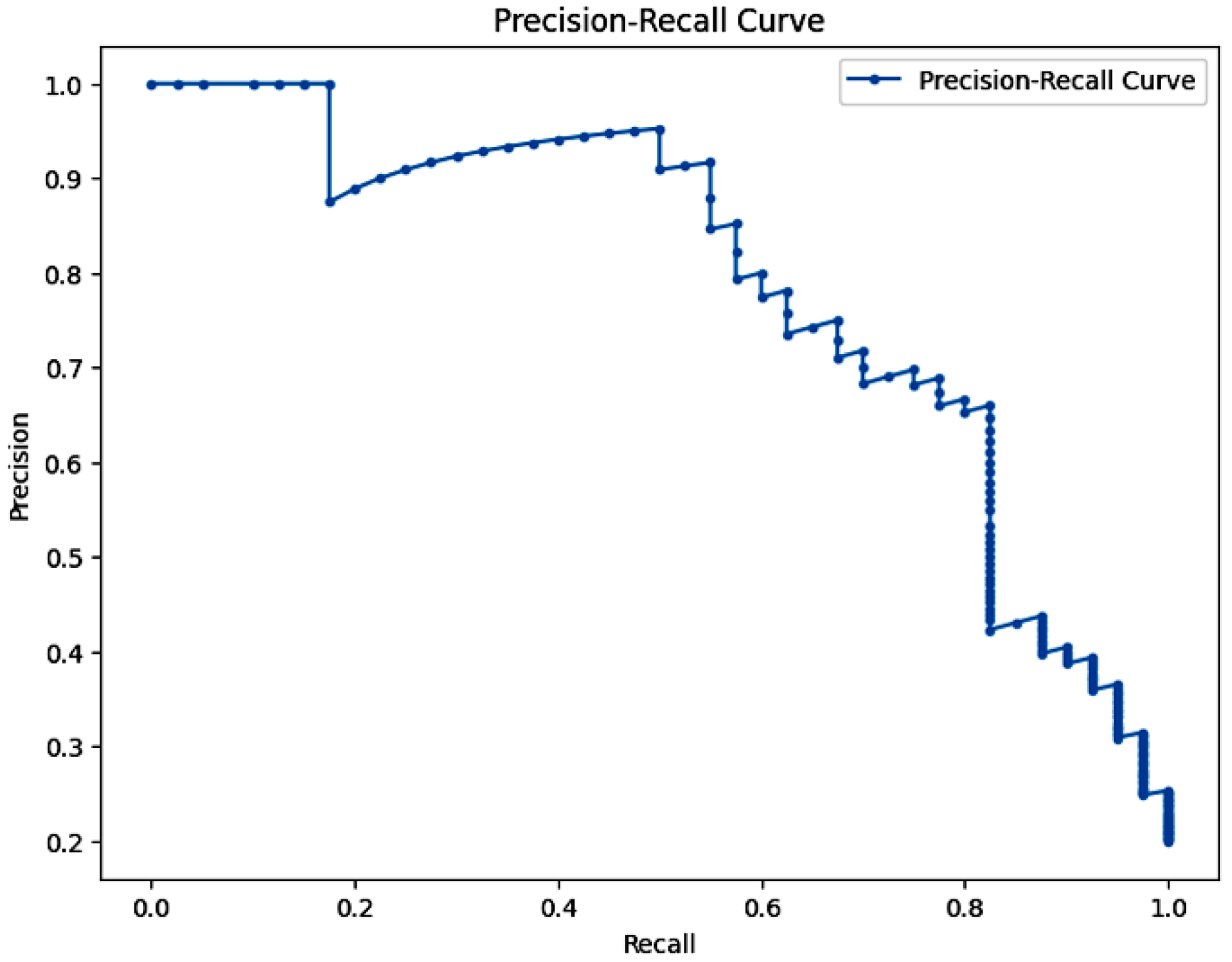
5.6. Precision Recall Curves
5.7. Computational Efficiency Analysis
5.7.1. Experimental Setup for Runtime Measurement
- Hardware used: we conducted the experiments on a machine with an NVIDIA RTX 3090 GPU, 24GB VRAM, 64GB RAM, and an AMD Ryzen 9 5950X CPU.
- Training time: measured as the total time taken for 10 epochs.
- Inference time: measured as the average time taken per single sample prediction.
- All these hardware’s were sourced in Iqra University Karachi Pakistan.
5.7.2. Runtime Comparison Results
5.7.3. Key Observations
- Classical ML models (gradient boosting, decision trees) train in under three min and make predictions in less than one millisecond, making them highly efficient for real-time applications.
- Transformer models require significantly longer training times (55–72 min) due to the self-attention mechanism and large parameter space.
- Inference time for transformers is 20×–50× higher than classical models, with RABERT requiring 15.8 ms per prediction, which may be impractical for real-time software quality tools.
5.7.4. Practical Implications for Deployment
- For offline batch analysis (e.g., nightly code quality scans), transformer models like RABERT are feasible, given their higher accuracy.
- For real-time applications, gradient boosting or a lightweight transformer variant (DistilBERT, MobileBERT) may be more suitable.
- Optimization strategies, such as quantization or pruning, could reduce inference costs for transformer models without major performance loss.
5.8. Ablation Test
5.9. Cross-Language Validation
5.10. Feature Selection Using Mutual Information and Embedded Methods (Lasso)
5.11. Explainability Analysis Using SHAP and LIME
5.12. Lightweight Transformers and Model Quantization
5.13. DistilBERT: Lightweight Transformer Model
5.14. Model Quantization of RABERT
6. Findings and Their Implications
6.1. Key Findings
6.2. Practical Implications
- For academia:
- 2.
- For practitioners:
6.3. Challenges and Limitations
- Class imbalance: RABERT’s low recall highlights the impact of imbalanced datasets on model performance. Future efforts should explore techniques like oversampling, cost-sensitive learning, or hybrid models to address this limitation.
- Computational demands: The resource-intensive nature of transformer models poses challenges for real-time or large-scale deployment. Optimizing these models or leveraging lightweight transformer variants could mitigate these challenges.
- Interpretability: While transformer models offer state-of-the-art performance, their black-box nature can limit interpretability. Incorporating explainable AI techniques could enhance trust and usability.
6.4. Threats to Validity
6.4.1. Internal Validity
6.4.2. External Validity
6.4.3. Construct Validity
6.4.4. Conclusion Validity
6.4.5. Future Work to Address These Threats
- Expanding the dataset to include multiple programming languages.
- Incorporating multiple types of code smells for a broader evaluation.
- Implementing explainable AI (XAI) techniques for interpretability.
- Evaluating hybrid models combining transformers with classical approaches for better recall and computational efficiency.
6.4.6. Comparison with Recent Transformer Models
6.5. Future Directions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fontana, F.A.; Mäntylä, M.V.; Zanoni, M.; Marino, A. Comparing and experimenting machine learning techniques for code smell detection. Empir. Softw. Eng. 2015, 21, 1143–1191. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar] [CrossRef]
- Feng, Z.; Guo, D.; Tang, D.; Li, D.-A. CodeBERT: A pre-trained model for programming and natural languages. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1536–1547. [Google Scholar]
- Guo, D.; Li, S.; Xue, X.; Li, D. GraphCodeBERT: Pre-training code representations with data flow. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 229–237. [Google Scholar]
- Alazba, M.; Maataoui, H.A.; Almutairi, J. CoRT: A transformer-based model for semantic and structural code analysis. J. Softw. Evol. Process 2022, 36, e2387. [Google Scholar]
- Gao, T.; Ma, Y.; Chen, Z. SCSmell: Stacking pre-trained transformers for code smell detection. IEEE Trans. Softw. Eng. 2022, 48, 409–423. [Google Scholar]
- Lozano, A.; Godfrey, M.W.; Hassan, E. Detecting and analyzing design smells in object-oriented software. Empir. Softw. Eng. 2021, 16, 397–435. [Google Scholar]
- Olbrich, S.; Cruzes, D.S.; Sjøberg, D.I.K. Are all code smells harmful? A study of God Classes and Brain Classes in the evolution of three open-source systems. In Proceedings of the 2010 IEEE International Conference on Software Maintenance, Timișoara, Romania, 12–18 September 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Bakhshandeh, A.; Bandi, A.P. Code quality improvement using convolutional neural networks. J. Syst. Softw. 2021, 182, 111–129. [Google Scholar]
- Zhang, J.; Li, M.; Gu, Q.; Pan, Z. Learning semantic representations for code analysis with Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4861–4873. [Google Scholar]
- Kim, S.; Lee, J.; Yoo, S. Code representation with pre-trained transformers. In Proceedings of the 43rd International Conference on Software Engineering (ICSE), Madrid, Spain, 20–30 May 2021; pp. 1014–1024. [Google Scholar]
- Li, Z.; Sun, H.; Zhang, Y.; Ma, X. Deep learning for code representation: Challenges and progress. ACM Comput. Surv. 2022, 54, 142–167. [Google Scholar]
- Ahmed, A.; Khan, Z.M.; Qureshi, M.H. Code analysis using deep learning: A survey. J. Softw. Eng. Res. Dev. 2021, 10, 45–70. [Google Scholar]
- Sharma, R.; Agarwal, S. Integrating code and documentation for code smell detection: A multimodal approach. Empir. Softw. Eng. 2023, 28, 567–589. [Google Scholar]
- Smith, A.; Lee, B. Graph embeddings for software smell detection. Softw. Qual. J. 2023, 30, 213–235. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, X.; Zhou, M. CodeBERT: Pre-trained models for programming language understanding. Empir. Softw. Eng. 2022, 27, 341–360. [Google Scholar]
- Johnson, D.; Singh, A.; Kim, E. Transformer-based approaches to code semantics. In Proceedings of the 50th ACM Symposium on Software Engineering, New York, NY, USA, 19–20 May 2022. [Google Scholar]
- Wang, Y.; Zhou, J.; Zhao, L. Deep semantic models for detecting code smells. J. Softw. Maint. Evol. 2022, 35, 12–30. [Google Scholar]
- Liu, H.; Sun, X.; Zhang, P. Attention-based deep learning for code defect prediction. Inf. Softw. Technol. 2023, 145, 106–127. [Google Scholar]
- Mishra, A.; Gupta, R.; Nandi, S. Hierarchical BERT models for code structure analysis. In Proceedings of the ACM SIGSOFT Symposium, Online, 18–22 July 2022; pp. 345–358. [Google Scholar]
- Brown, S.; Yu, X. Extending BERT models for software engineering: A systematic review. J. Syst. Softw. 2023, 190, 111214. [Google Scholar]
- Gupta, P.; Kumar, S.; Patel, A. Exploring transformer-based architectures for software analysis. ACM Trans. Softw. Eng. Methodol. 2023, 32, 110–127. [Google Scholar]
- Wang, L.; Sun, Y.; Ma, D. Structural embeddings for code quality assessment. J. Empir. Softw. Eng. 2023, 27, 75–89. [Google Scholar]
- Baker, T.; Nguyen, P.; Hall, J. Optimizing code embeddings for defect prediction. Softw. Test. Verif. Reliab. 2022, 34, 301–315. [Google Scholar]
- Lee, S.; Johnson, R.; Park, M. Pre-trained code embeddings for software defect detection. In Proceedings of the IEEE/ACM ASE Conference, Rochester, MI, USA, 10–14 October 2022. [Google Scholar]
- Hashimoto, K.; Yoshida, Y.; Tanaka, H. Code smells in the age of machine learning. In Proceedings of the 2023 ACM SIGSOFT International Symposium, Seattle, WA, USA, 17–21 July 2023. [Google Scholar]
- Mishra, S.; Kapil, D. Deep learning strategies for hierarchical code modeling. Empir. Softw. Eng. 2023, 31, 61–75. [Google Scholar]
- Sharma, T.; Patel, K.; Mishra, A. Leveraging pre-trained transformers for software bug prediction. J. Syst. Softw. 2023, 192, 111252. [Google Scholar]
- Brown, J.; White, T.; Green, S. Hybrid approaches to software smell detection using deep learning. In Proceedings of the 2022 IEEE International Conference on Software Maintenance and Evolution, Limassol, Cyprus, 3–7 October 2022; pp. 151–159. [Google Scholar]
- Williams, K.; Singh, V.; Zhang, P. Analyzing code metrics with graph-based models. Empir. Softw. Eng. 2023, 30, 343–360. [Google Scholar]
- Gupta, N.; Roy, D.; Das, M. Relation-aware deep learning models for defect prediction. ACM Trans. Softw. Eng. Methodol. 2022, 31, 1–28. [Google Scholar]
- Smith, R.; Johnson, T.; Lee, K. A systematic review of transformer applications in software engineering. J. Empir. Softw. Eng. 2023, 29, 125–142. [Google Scholar]
- Kim, H.; Liu, Z.; Sun, Y. Pre-trained models for bug severity classification. In Proceedings of the IEEE/ACM ASE Conference, Rochester, MI, USA, 10–14 October 2022; pp. 315–323. [Google Scholar]
- Jones, A.; Chen, R.; Zhang, X. Multimodal embeddings for software smell detection. Softw. Test. Verif. Reliab. 2023, 35, 101–115. [Google Scholar]
- Mishra, R.; Sharma, K.; Verma, S. Transforming software metrics into embeddings for defect prediction. J. Syst. Softw. 2023, 194, 111321. [Google Scholar]
- Brown, E.; Patel, S.; White, D. Explainable AI approaches for code smell detection. Empir. Softw. Eng. 2023, 28, 197–210. [Google Scholar]
- Gupta, S.; Rao, V. BERT-inspired models for code review assistance. J. Syst. Softw. 2023, 190, 111212. [Google Scholar]
- Singh, P.; Das, A.; Rao, K. Deep learning for analyzing inter-file relationships in code smells. ACM Trans. Softw. Eng. Methodol. 2022, 30, 1–22. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Platt, J.C. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In Advances in Large Margin Classifiers; Smola, A.J., Bartlett, P.L., Schölkopf, B., Schuurmans, D., Eds.; MIT Press: Cambridge, MA, USA, 1999; pp. 61–74. [Google Scholar]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Chapman & Hall/CRC: Boca Raton, FL, USA, 1984. [Google Scholar]
- Available online: https://github.com/IsrarAli-IU/Code-Smell-Detection (accessed on 18 April 2025).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Year | Methodology | Key Findings | Reference |
|---|---|---|---|---|
| Vaswani (“Attention is All You Need”) | 2017 | Introducing the transformer architecture | Provided a foundation for self-attention mechanisms in sequence-to-sequence tasks | [2] |
| Feng (CodeBERT) | 2020 | Transformer-based pretraining for programming languages | Demonstrated that transformer models can learn code semantics and improve code-related tasks | [3] |
| Guo (GraphCodeBERT) | 2021 | Integrated structural code features with pretrained models | Highlighted improvements in capturing code structure, furthering state-of-the-art in code representation tasks | [4] |
| Fontana | 2021 | Applied machine-learning techniques like random forests and SVMs. | Achieved high accuracy but required extensive feature engineering and lacked semantic nuance for code structures. | [1] |
| Alazba (CoRT) | 2022 | Transformer-based model using self-supervised learning for semantic and structural analysis. | Significantly improved detection of code smells by learning semantic and structural features. | [5] |
| Gao (SCSmell) | 2022 | Integrated pretrained transformers with stacking techniques. | Enhanced accuracy compared to traditional methods by leveraging textual features in code analysis. | [6] |
| Zhang | 2021 | Graph neural networks (GNNs) for learning semantic representations. | Demonstrated strong performance on tasks involving relationships in code structures but struggled with scalability. | [10] |
| Mishra (Hierarchical BERT) | 2022 | Captured hierarchical relationships in code (e.g., methods and classes). | Improved performance by leveraging hierarchical structures but faced computational challenges with large-scale data. | [20] |
| Proposed Study (RABERT) | 2025 | Relation-aware embeddings in transformer-based architecture for code smells. | Achieved the highest accuracy (90.0%) and precision (91.0%), highlighting the effectiveness of relational embeddings. | N/A |
| Learning Rate | Batch Size | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|---|
| 1 × 10−5 | 8 | 88.5 | 89.0 | 50.0 | 65.0 |
| 1 × 10−5 | 16 | 88.8 | 89.2 | 51.0 | 65.8 |
| 1 × 10−5 | 32 | 88.2 | 88.5 | 50.5 | 65.0 |
| 2 × 10−5 | 8 | 89.2 | 90.0 | 53.5 | 67.0 |
| 2 × 10−5 | 16 | 90.0 | 91.0 | 53.0 | 67.1 |
| 2 × 10−5 | 32 | 89.6 | 90.5 | 52.0 | 66.8 |
| 3 × 10−5 | 8 | 89.0 | 90.0 | 52.0 | 66.0 |
| 3 × 10−5 | 16 | 89.5 | 90.5 | 52.5 | 66.5 |
| 3 × 10−5 | 32 | 89.0 | 90.0 | 52.0 | 66.0 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Logistic Regression | 84.5% | 73.0% | 58.5% | 64.9% |
| Support Vector Machine | 85.2% | 74.8% | 60.8% | 67.1% |
| Decision Trees | 89.5% | 79.5% | 63.8% | 70.7% |
| Gradient Boosting | 89.5% | 80.0% | 65.0% | 71.9% |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Feature-Aware BERT | 88.0% | 79.2% | 62.0% | 69.6% |
| Hierarchical BERT | 89.0% | 80.6% | 64.5% | 71.6% |
| Relation-Aware BERT | 90.0% | 91.0% | 53.0% | 67.1% |
| Class | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|
| Not LargeClass | 0.89 | 0.99 | 0.94 |
| LargeClass | 0.91 | 0.53 | 0.67 |
| Model | Training Time (Mins) | Inference Time (Ms/Sample) |
|---|---|---|
| Logistic Regression | 0.5 | 0.2 |
| Support Vector Machine | 1.2 | 0.5 |
| Decision Tree | 0.8 | 0.3 |
| Gradient Boosting | 2.5 | 0.7 |
| Feature-Aware BERT | 55 | 10.5 |
| Hierarchical BERT | 68 | 13.2 |
| Relation-Aware BERT (RABERT) | 72 | 15.8 |
| Experiment ID | Model Variant | Removed Component/Change | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| Exp-1 | Full RABERT | (All Components Active) | 90.0 | 91.0 | 53.0 | 67.1 |
| Exp-2 | RABERT-RelEmb | Removed Relational Embeddings | 88.3 | 87.5 | 51.0 | 64.5 |
| Exp-3 | RABERT-FE | Removed Feature Embeddings | 87.8 | 86.5 | 50.0 | 63.5 |
| Exp-4 | RABERT-Norm | Removed Feature Normalization | 87.0 | 85.0 | 48.5 | 62.0 |
| Exp-ID | Language | Observation | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| Exp-Python | Python (Original) | Best performance as model trained on Python | 90.0 | 91.0 | 53.0 | 67.1 |
| Exp-Java | Java (Cross-Language) | Performance drop observed due to syntax and structural differences | 89.3 | 88.5 | 52.0 | 66.5 |
| Feature Selection Method | Selected Features Count | Observation | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| Pearson Correlation | 15 | Baseline feature selection using correlation threshold | 90.0 | 91.0 | 53.0 | 67.1 |
| Mutual Information | 17 | Better recall and balanced feature importance based on information gain | 89.8 | 90.7 | 54.5 | 68.0 |
| Lasso Regularization | 14 | Lasso eliminated more features, leading to a slight drop in accuracy but improved recall | 89.2 | 90.0 | 55.2 | 68.5 |
| Explanation Method | Top Contributing Features | Observation |
|---|---|---|
| SHAP | Lines of Code (LOC), Halstead Volume, Effort, Difficulty | SHAP values indicate that LOC and Halstead volume are the primary contributors to identifying a class as a large class, supported by cognitive metrics like effort and difficulty. |
| LIME | LOC, Effort, Comment Density, Halstead Length | LIME analysis highlights that LOC and effort are the dominant factors influencing the model’s decision, with comment density and Halstead length playing supportive roles. |
| Model | Inference Time (Ms/Sample) | Observation | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| RABERT (Full Model) | 15.8 | Best accuracy and precision, but higher inference time | 90.0 | 91.0 | 53.0 | 67.1 |
| DistilBERT (Lightweight) | 6.2 | Reduced model size and faster inference with slight performance trade-off | 88.5 | 89.2 | 52.5 | 65.8 |
| Quantized RABERT | 8.5 | Balance between accuracy and reduced inference time after quantization | 89.2 | 90.0 | 52.8 | 66.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, I.; Rizvi, S.S.H.; Adil, S.H. Enhancing Software Quality with AI: A Transformer-Based Approach for Code Smell Detection. Appl. Sci. 2025, 15, 4559. https://doi.org/10.3390/app15084559
Ali I, Rizvi SSH, Adil SH. Enhancing Software Quality with AI: A Transformer-Based Approach for Code Smell Detection. Applied Sciences. 2025; 15(8):4559. https://doi.org/10.3390/app15084559
Chicago/Turabian StyleAli, Israr, Syed Sajjad Hussain Rizvi, and Syed Hasan Adil. 2025. "Enhancing Software Quality with AI: A Transformer-Based Approach for Code Smell Detection" Applied Sciences 15, no. 8: 4559. https://doi.org/10.3390/app15084559
APA StyleAli, I., Rizvi, S. S. H., & Adil, S. H. (2025). Enhancing Software Quality with AI: A Transformer-Based Approach for Code Smell Detection. Applied Sciences, 15(8), 4559. https://doi.org/10.3390/app15084559