
AASNet: A Novel Image Instance Segmentation Framework for Fine-Grained Fish Recognition via Linear Correlation Attention and Dynamic Adaptive Focal Loss




Abstract
1. Introduction
- We design a novel Agricultural Underwater Image Instance Segmentation Model, AASNet, which integrates detection and segmentation functions. This model is specifically optimized to address the challenges of lighting variations and extreme data imbalance in underwater scenes.
- In AASNet, we introduce the Linear Correlation Attention (LCA) mechanism and a dynamic adaptive loss function. The LCA mechanism captures feature correlations, enhancing the model’s ability to adapt to variations in lighting and complex backgrounds. At the same time, the dynamic adaptive loss function addresses the issue of data imbalance, improving classification accuracy and ensuring that the model maintains high performance across diverse underwater scenarios.
- Our method achieves state-of-the-art performance on the UIIS and USIS datasets, surpassing current mainstream methods in accuracy, parameter efficiency, and inference speed. The experimental results demonstrate that AASNet excels in handling complex underwater scenes, showcasing its superior performance.
2. Related Work
2.1. Vision Instance Segmentation Technology
2.2. Underwater Fish Recognition Technology
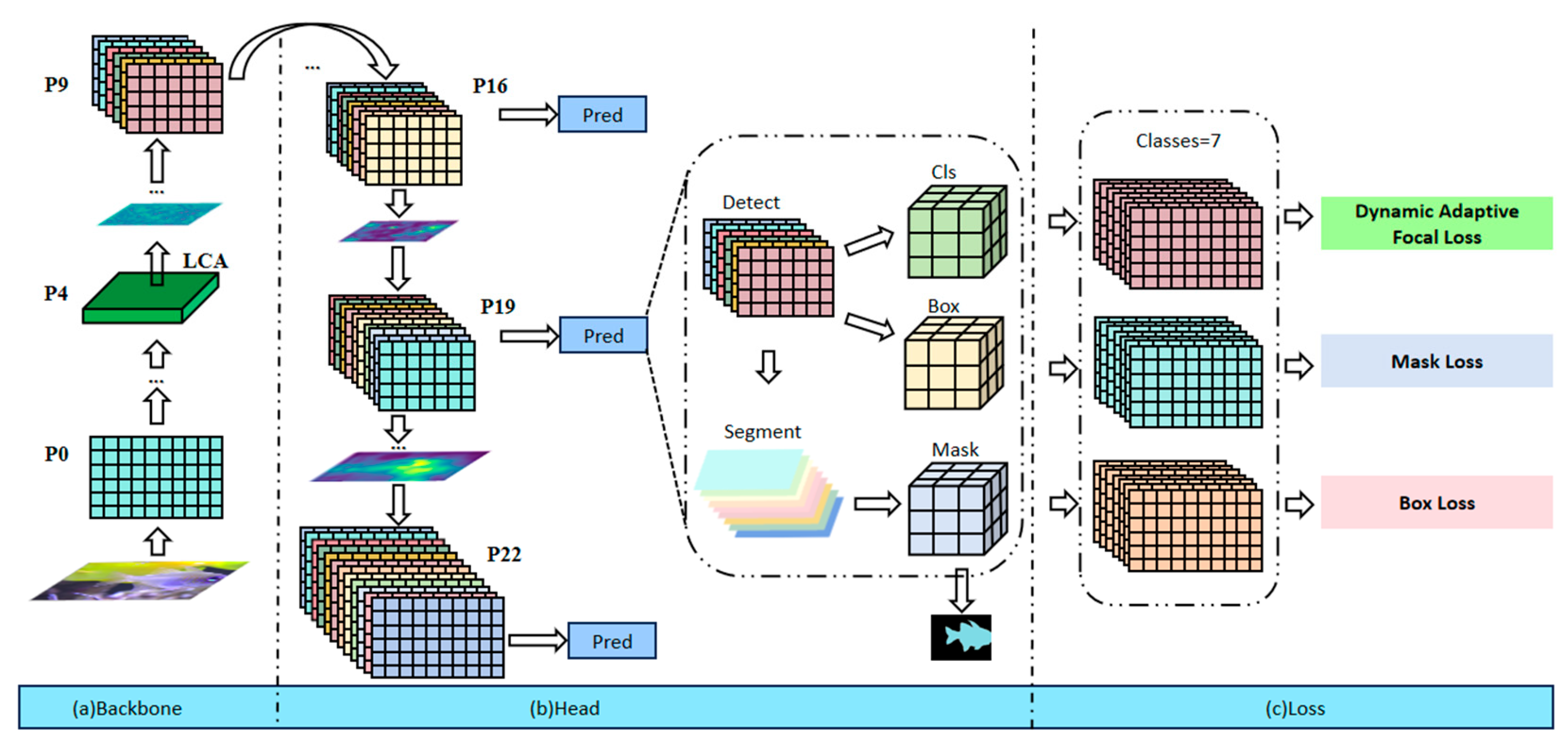
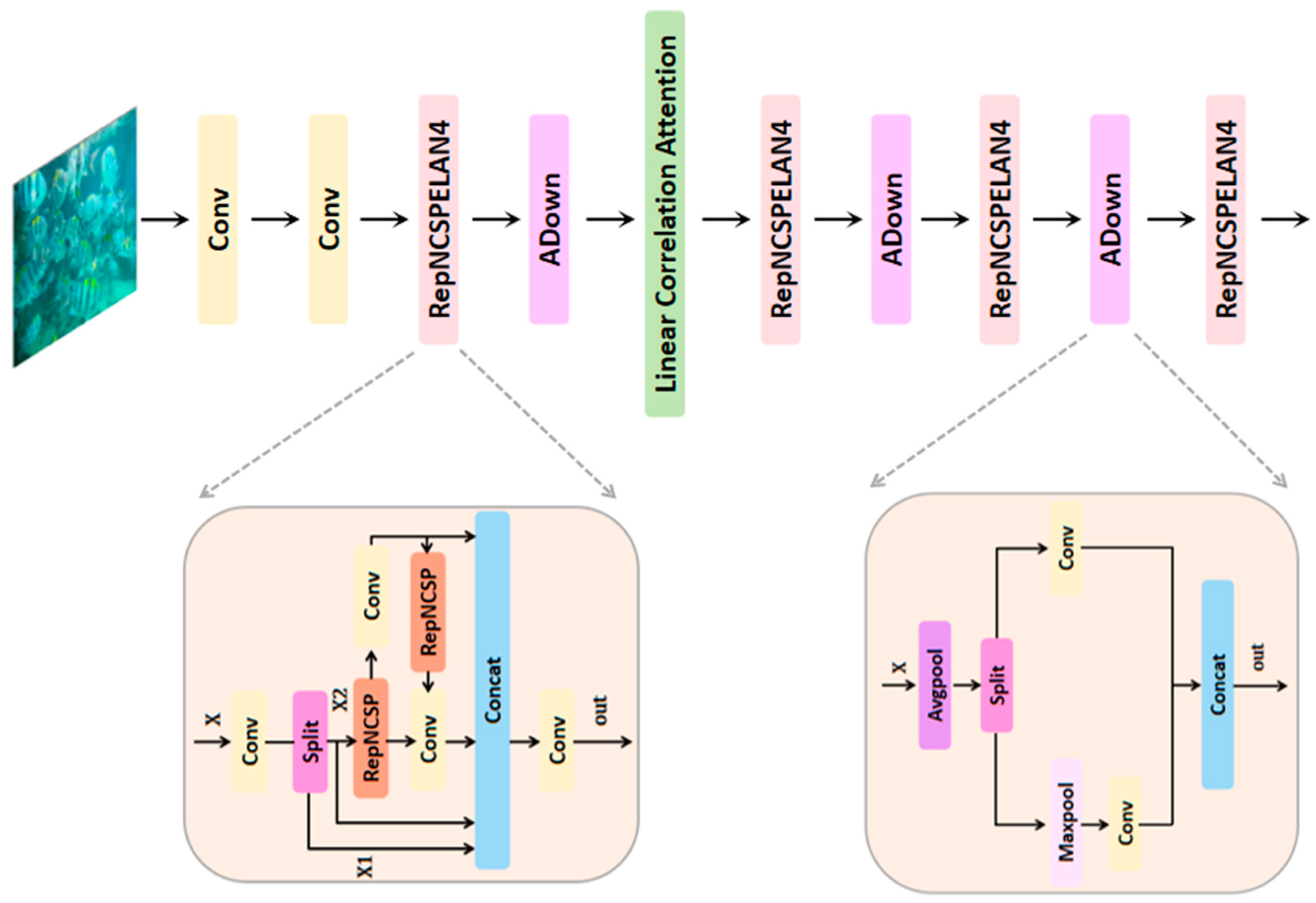
3. Methods
3.1. Preprocessing Techniques
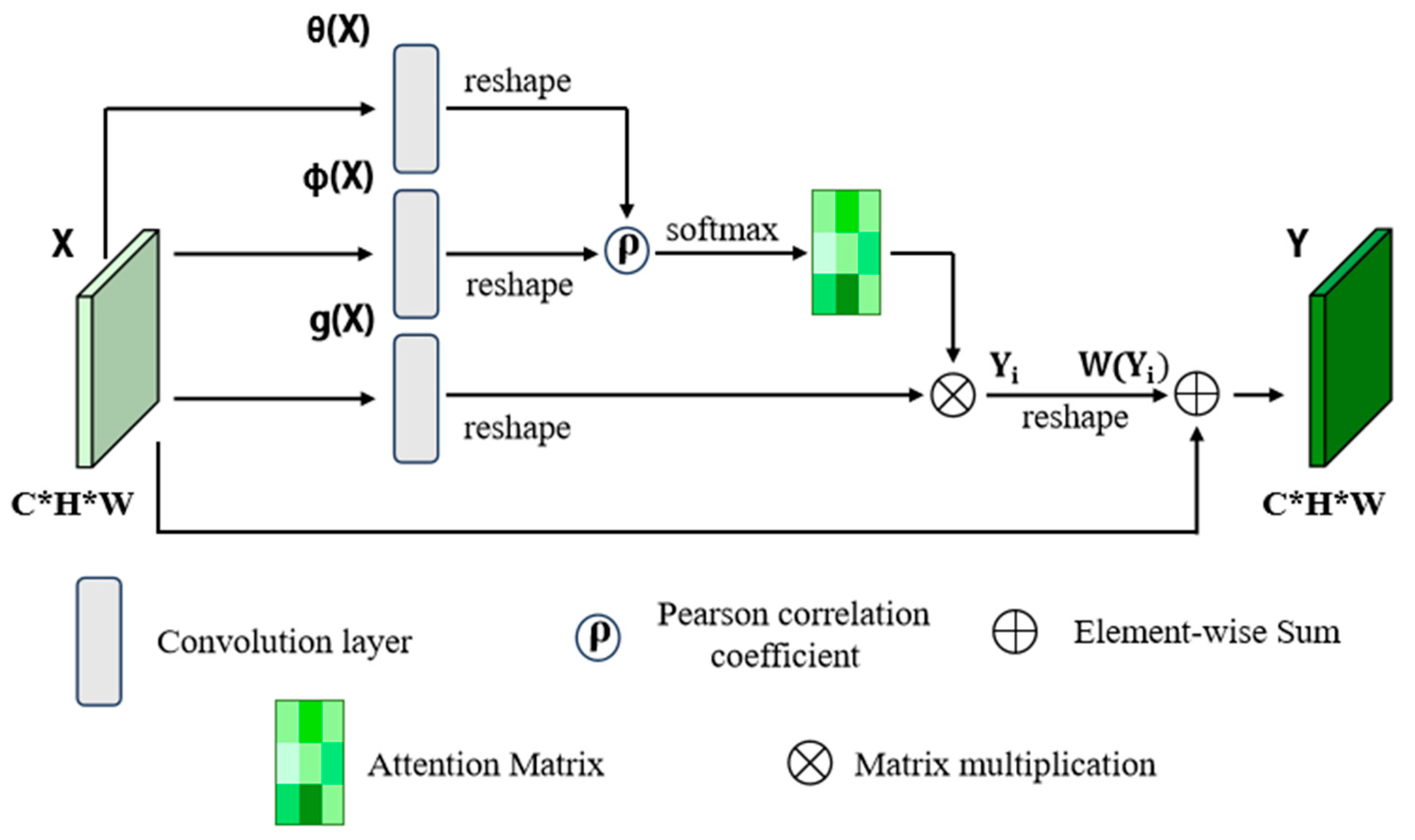
3.2. Linear Correlation Attention Module
3.3. Segmentation Head Module
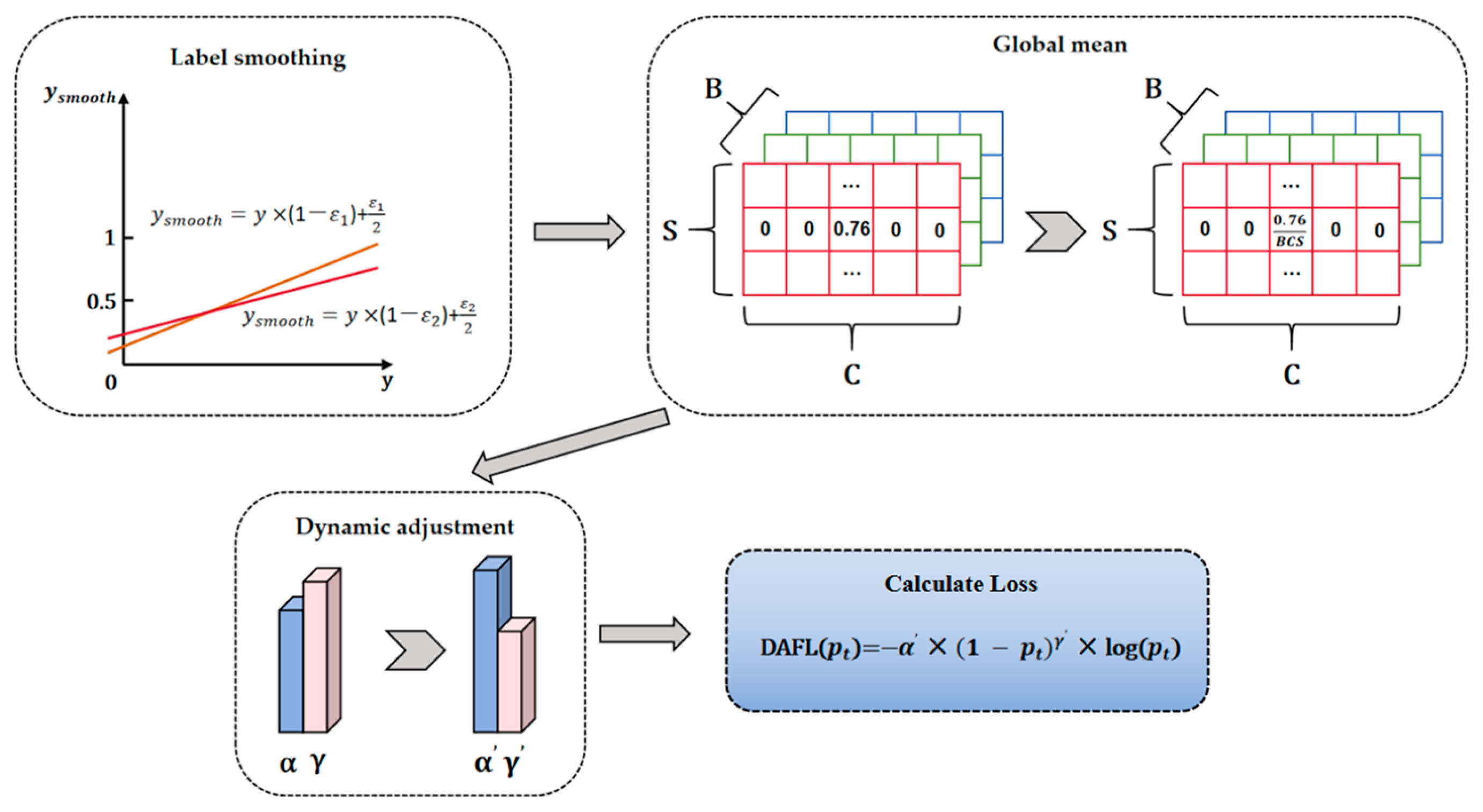
3.4. Dynamic Adaptive Focal Loss
4. Results and Discussion
4.1. Dataset Sources
- (1)
- UIIS dataset: This is the first general underwater image instance segmentation dataset, released in 2023. This dataset includes seven challenging categories, such as fish, divers, reefs, and more. The UIIS dataset consists of 4628 images, divided into training, validation, and test sets with a ratio of 7.4:1.3:1.3. The images in the dataset vary in resolution, including pixel images captured by low-resolution handheld cameras, and pixel images taken by medium- to high-resolution industrial equipment, ensuring diversity and high quality in the dataset. Among the images, fish constitute a significant proportion. For instance, there are 16,749 fish instances annotated in images. These annotations are valuable for fish detection and behavioral analysis in smart fish farming.
- (2)
- USIS10K dataset: This is the first large-scale underwater salient instance segmentation dataset, released in 2024. This dataset contains 10,632 images with pixel-level annotations from various underwater scenes and is divided into training, validation, and test sets with a ratio of 7:1.5:1.5. The dataset includes two types of annotations: single-class annotations, where all labels are marked as foreground, and detailed annotations, with seven sub-categories such as fish, ruins, aquatic plants, etc. In the USIS10K dataset, there are 9663 fish instances annotated. This detailed annotation provides high-quality training resources for tasks such as fish identification, disease detection, and water quality monitoring in smart fish farming. The diversity of fish annotations in the dataset supports both single-category and multi-category segmentation tasks, enhancing the model’s adaptability in complex underwater environments.
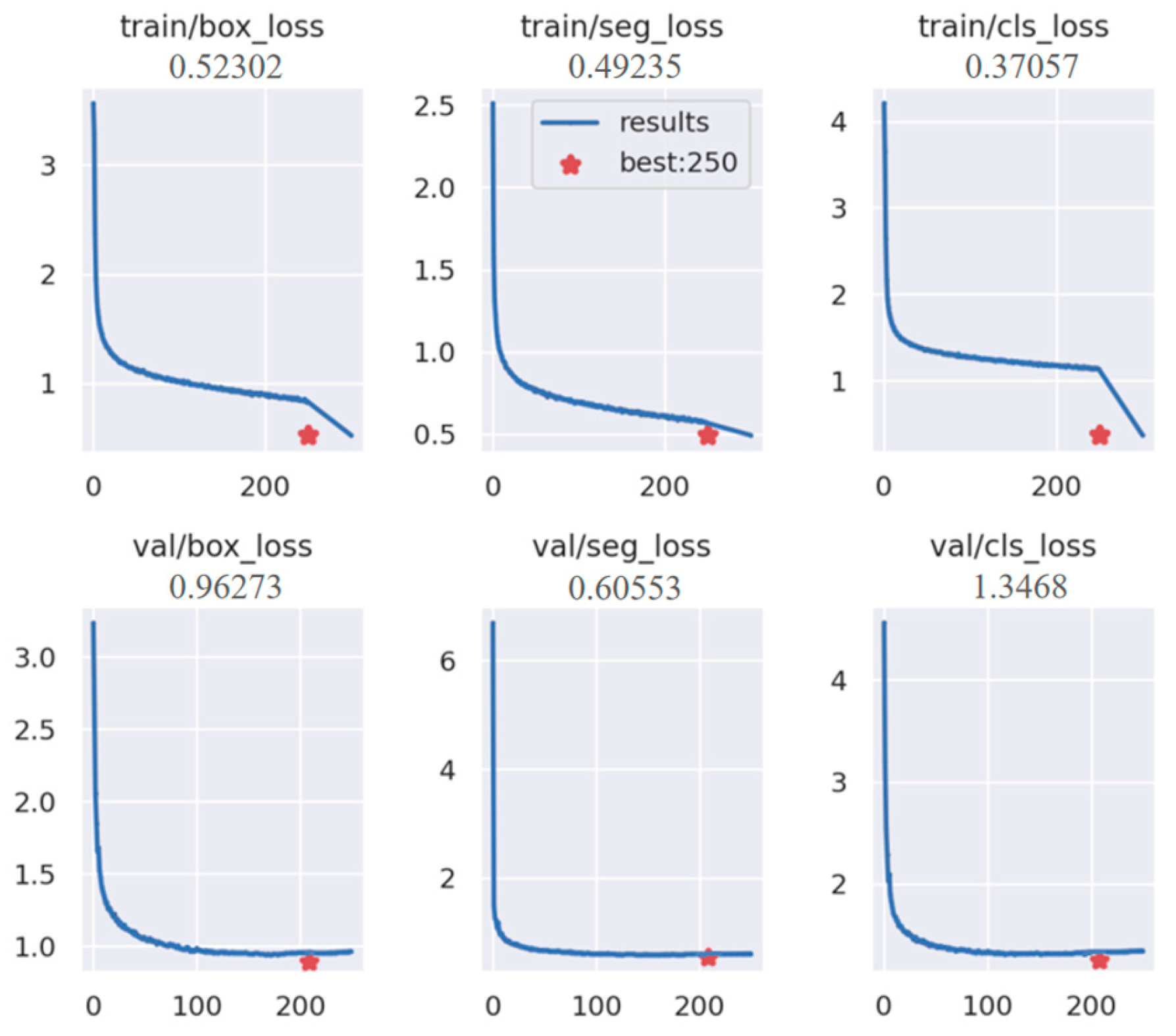
4.2. Evaluation Metric and Details
4.3. Comparative Experimental Results
- (1)
- Performance on UIIS: We present the results of our method on the UIIS underwater image instance segmentation dataset and compare them with other popular instance segmentation methods. As shown in Table 1, our proposed method achieves a new state-of-the-art on UIIS with an mAP score of 31.7, surpassing USIS-SAM by 2.3 points. In terms of AP50 and AP75, our method exceeds USIS-SAM by 4.5 points and 2.8 points, respectively. This indicates that our approach provides better underwater instance segmentation with higher localization accuracy. Additionally, the AASNet model has a parameter count of 27.84 M, demonstrating exceptional performance in real-time underwater instance segmentation tasks. We conduct tests on an NVIDIA P40 GPU with a batch size of 12, where the model achieves an inference time of only 28.9 milliseconds when processing 640 × 640 resolution images. In comparison, the WaterMask [8] model has a parameter count of 66.55 M, with an inference time of 180.5 milliseconds under the same configuration. Clearly, AASNet offers significant advantages in computational efficiency.
- (2)
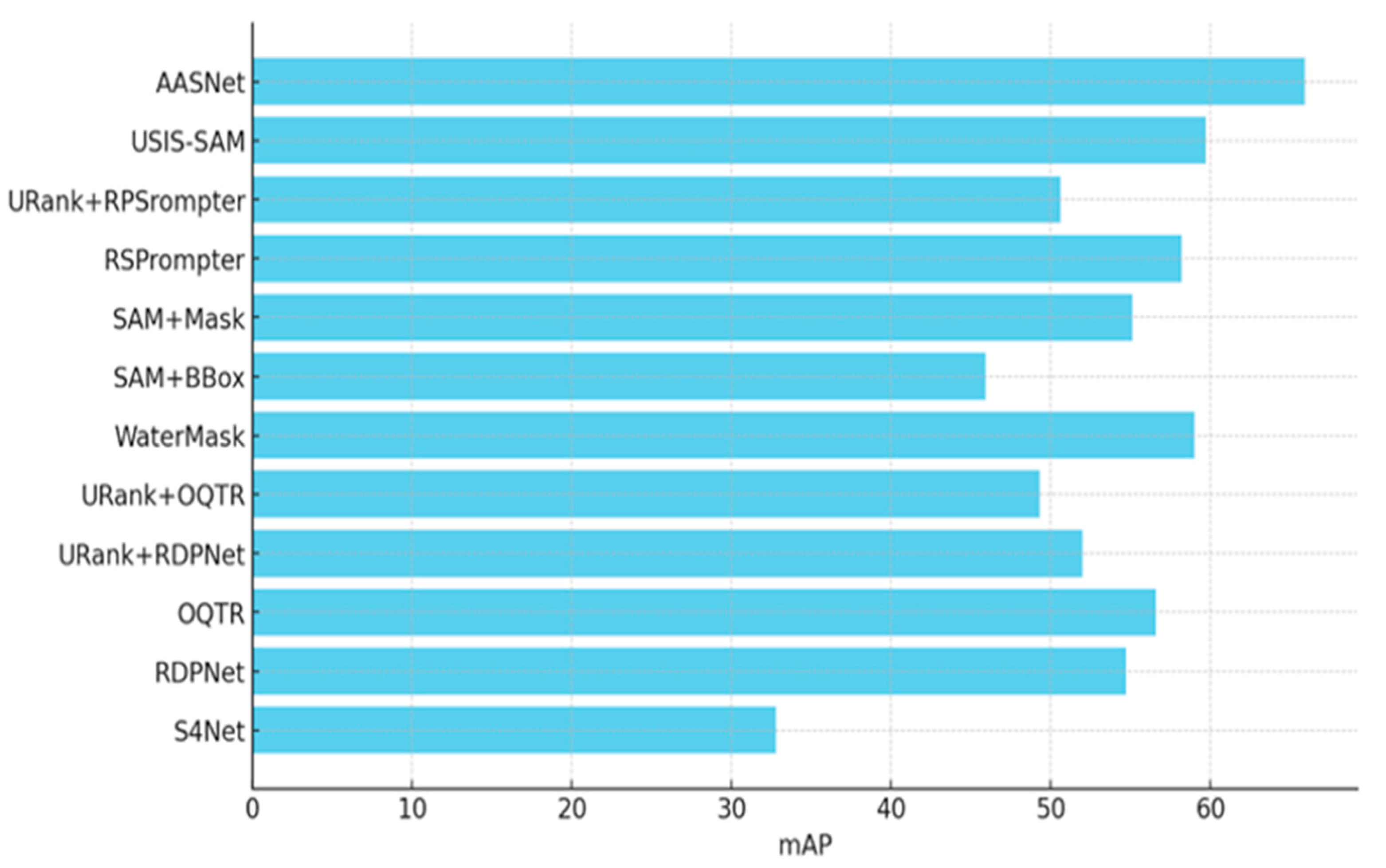
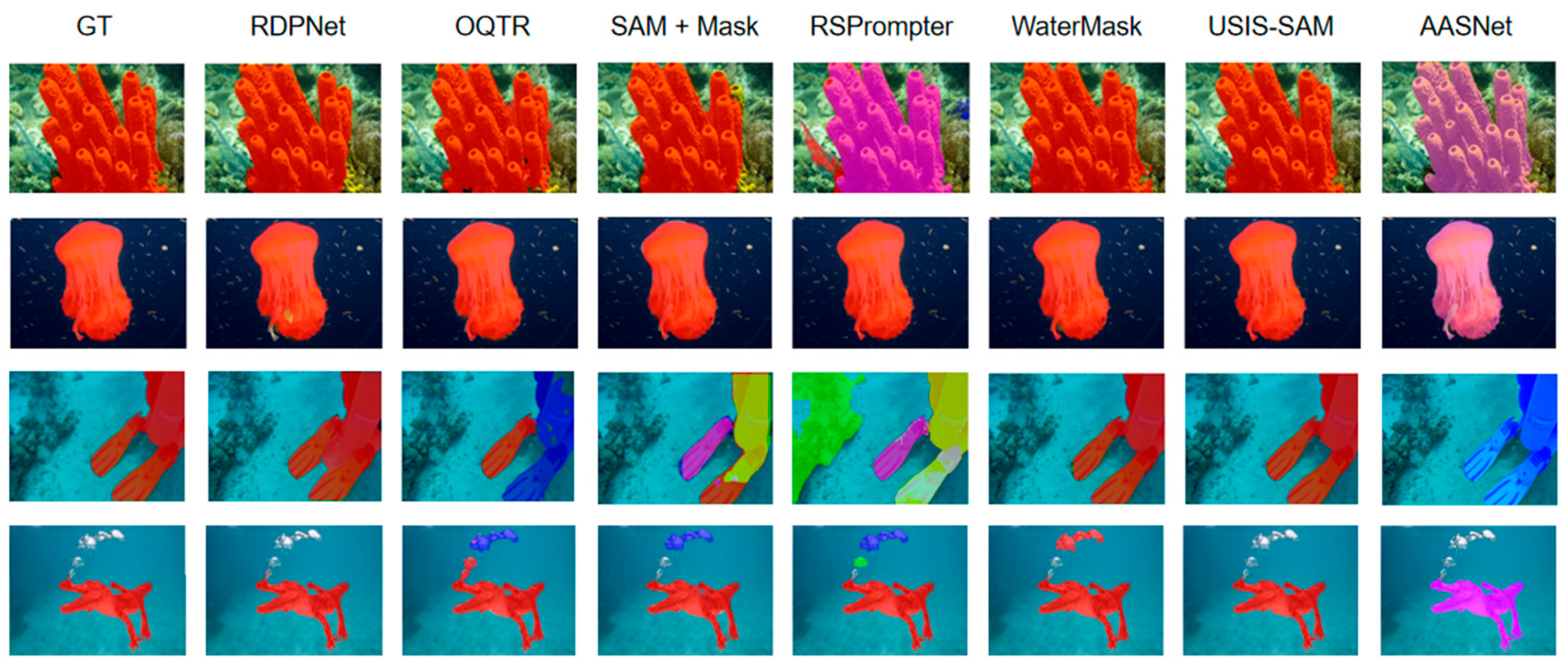
- Performance on USIS10K: Table 2 shows the performance comparison with state-of-the-art methods. The results of the histogram visualization of the average accuracy of each advanced method are shown in Figure 8. The experimental results demonstrate that our model performs better when the data volume is expanded. Our method achieves an mAP that is 4.6 points higher than USIS-SAM under multi-label annotations and 6.2 points higher under single-label annotations. In both annotation settings, AP50 and AP75 also reach optimal values, further proving the effectiveness of our approach.
4.4. Ablation Results and Analysis
- (1)
- Overall Ablation Study: To analyze the importance of each proposed component, we report the overall ablation study in Table 3. We gradually add the LCA module and Dynamic Adaptive Focal Loss to the YOLOv9 baseline. The results show that the LCA module improves the mAP by 2.4, demonstrating that the LCA module effectively enhances the model’s ability to handle lighting variations and color differences in complex underwater environments, optimizing the consistency of semantic information and thereby improving instance segmentation accuracy. Additionally, Dynamic Adaptive Focal Loss further increases the mAP to 31.7, with simultaneous improvements in the other two metrics, proving that this loss function performs better in classification, thus enhancing overall segmentation accuracy.
- (2)
- Ablation study on Linear Correlation Attention Module: We conduct ablation experiments to evaluate the placement of the LCA module at different levels of the backbone, testing it at None, P1, P2, P3, P4, and P5. As shown in Table 4, placing the module at the P4 layer yields the best results, with mAP increasing by 2.4 to 30.9 and AP50 and AP75 reaching 48.4 and 34.3, respectively. This is because the P4 layer achieves an ideal balance between spatial resolution and semantic information in the feature map. In shallower layers (such as P1 and P2), although the spatial resolution is high, most captured features are low-level, making it difficult to support precise segmentation in complex underwater scenes. In deeper layers (such as P5), while higher-level abstract features are captured, the significant reduction in spatial resolution results in insufficient precision in local feature extraction. The P4 layer occupies a critical intermediate position, effectively capturing advanced levels of abstract features while maintaining sufficient spatial resolution. Therefore, adding the LCA module at the P4 layer enhances the model’s ability to capture semantic features in complex underwater environments. It preserves essential detail and improves segmentation performance, leading to better results when addressing lighting variations, color differences, and complex backgrounds.
- (3)
- Ablation study on Dynamic Adaptive Focal Loss: To analyze the effectiveness of Dynamic Adaptive Focal Loss (DAFL), we present the ablation study on the loss function in Table 5. The results show that introducing label smoothing into Focal Loss improves mAP by 0.3. This suggests that label smoothing enhances the model’s generalization ability, especially for hard-to-classify samples, by reducing overfitting. Additionally, incorporating a dynamic calculation strategy based on the global mean into Focal Loss improves mAP by an additional 0.5. This demonstrates that the method automatically adjusts the model’s focus on hard and easy samples, depending on the class distribution within the current training batch, thereby improving classification accuracy. When both methods are applied together, the model achieves optimal performance. Overall, Dynamic Adaptive Focal Loss significantly boosts the model’s classification ability and robustness, particularly in handling highly imbalanced instance segmentation tasks.
4.5. Extended Experiments and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qin, Q.Y.; Liu, J.Y.; Chen, Y.H.; Wang, X.R.; Chu, T.J. Knowledge Map of the Development Trend of Smart Fisheries in China: A Bibliometric Analysis. Fishes 2024, 9, 258. [Google Scholar] [CrossRef]
- Li, P.; Han, H.; Zhang, S.; Fang, H.; Fan, W.; Zhao, F.; Xu, C. Reviews on the development of digital intelligent fisheries technology in aquaculture. Aquac. Int. 2025, 33, 191. [Google Scholar]
- Wu, Z.; Xiong, M.; Cheng, T.; Dai, Y.; Zhang, S.; Fan, W.; Cui, X. Application Prospects and Challenges of VHF Data Exchange System (VDES) in Smart Fisheries. J. Mar. Sci. Eng. 2025, 13, 250. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Bhat, G.M. A survey on instance segmentation: State of the art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhang, T.; Wei, S.; Ji, S. E2ec: An end-to-end contourbased method for high-quality high-speed instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4443–4452. [Google Scholar]
- Jian, M.; Liu, X.; Luo, H.; Lu, X.; Yu, H.; Dong, J. Underwater image processing and analysis: A review. Signal Process. Image Commun. 2021, 91, 116088. [Google Scholar] [CrossRef]
- Lian, S.; Li, H.; Cong, R.; Li, S.; Zhang, W.; Kwong, S. Watermask: Instance segmentation for underwater imagery. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 1305–1315. [Google Scholar]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. A spatial feature-enhanced attention neural network with high-order pooling representation for application in pest and disease recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Lian, S.; Li, C.; Liu, Z.; Zhang, X.; Yang, L.; Wang, Z.; Li, J. Diving into Underwater: Segment Anything Model Guided Underwater Salient Instance Segmentation and A Large-scale Dataset. In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; pp. 29545–29559. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9799–9808. [Google Scholar]
- Cheng, B.; Wei, Y.; Shi, H.; Feris, R.S.; Xiong, J.; Huang, T.S. Boundary-preserving Mask R-CNN. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 660–676. [Google Scholar]
- Zhang, Y.; Wu, J.; Li, S.; Liu, H. Self-Balanced R-CNN for Instance Segmentation. J. Vis. Commun. Image Represent. 2022, 82, 103449. [Google Scholar]
- Kong, J.L.; Wang, H.X.; Wang, X.Y.; Jin, X.B.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Kirillov, A.; Levinkov, E.; Andres, B.; Savchynskyy, B.; Schiele, B. InstanceCut: From Edges to Instances with MultiCut. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5008–5017. [Google Scholar]
- Liu, S.; Jia, J.; Fidler, S.; Urtasun, R. SGN: Sequential Grouping Networks for Instance Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3496–3504. [Google Scholar]
- Bai, M.; Urtasun, R. Deep Watershed Transform for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5221–5229. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Zhuang, P.; Wang, Y.; Qiao, Y. Wildfish: A large benchmark for fish recognition in the wild. In Proceedings of the the 26th ACM International Conference on Multimedia, San José, Costa Rica, 22–26 October 2018; pp. 1301–1309. [Google Scholar]
- Islam, M.J.; Edge, C.; Xiao, Y.; Luo, P.; Mehtaz, M.; Morse, C.; Enan, S.S.; Sattar, J. Semantic segmentation of underwater imagery: Dataset and benchmark. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, Nevada, USA, 25–29 October 2020; pp. 1769–1776. [Google Scholar]
- Garcia-D’Urso, N.E.; Galan-Cuenca, A.; Climent-Perez, P.; Saval-Calvo, M.; Azorin-Lopez, J.; Fuster-Guillo, A. Efficient instance segmentation using deep learning for species identification in fish markets. In Proceedings of the International Joint Conference on Neural Networks, Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Imada, A.; Katayama, T.; Song, T.; Shimamoto, T. YOLOX based underwater object detection for inshore aquaculture. In Proceedings of the OCEANS 2022, Hampton Roads, VI, USA, 17–20 October 2022; IEEE: New York, NY, USA, 2022; pp. 1–5. [Google Scholar]
- Li, D.; Yang, Y.; Zhao, S.; Ding, J. Segmentation of underwater fish in complex aquaculture environments using enhanced Soft Attention Mechanism. Environ. Model. Softw. 2024, 181, 106170. [Google Scholar]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Zuo, M. CropDeep: The crop vision dataset for deep-learning-based classification and detection in precision agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed]
- Khudoyberdiev, A.; Jaleel, M.A.; Ullah, I.; Kim, D. Enhanced Water Quality Control Based on Predictive Optimization for Smart Fish Farming. Comput. Mater. Contin. 2023, 75, 5471–5499. [Google Scholar]
- Kaur, G.; Adhikari, N.; Krishnapriya, S.; Wawale, S.G.; Malik, R.Q.; Zamani, A.S.; Perez-Falcon, J.; Osei-Owusu, J. Recent advancements in deep learning frameworks for precision fish farming opportunities, challenges, and applications. J. Food Qual. 2023, 2023, 4399512. [Google Scholar]
- Kong, J.L.; Fan, X.M.; Jin, X.B.; Lin, S.; Zuo, M. A Variational Bayesian Inference-Based En-Decoder Framework for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2023, 25, 2966–2975. [Google Scholar] [CrossRef]
- Kong, J.; Fan, X.; Zuo, M.; Deveci, M.; Jin, X.; Zhong, K. ADCT-Net: Adaptive traffic forecasting neural network via dual-graphic cross-fused transformer. Inf. Fusion 2023, 103, 102122. [Google Scholar] [CrossRef]
- Dong, Z.; Kong, J.; Yan, W.; Wang, X.; Li, H. Multivariable High-Dimension Time-Series Prediction in SIoT via Adaptive Dual-Graph-Attention Encoder-Decoder with Global Bayesian Optimization. IEEE Internet Things J. 2024, 11, 32956–32968. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Li, Z.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.O.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 17721–17732. [Google Scholar]
- Fang, Y.; Yang, S.; Wang, X.; Li, Y.; Fang, C.; Shan, Y.; Feng, B.; Liu, W. Instances as queries. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6910–6919. [Google Scholar]
- Cheng, B.; Misra, I.; Alexander; Schwing, G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Wu, Y.-H.; Liu, Y.; Zhang, L.; Gao, W.; Cheng, M.-M. Regularized densely-connected pyramid network for salient instance segmentation. IEEE Trans. Image Process. 2021, 30, 3897–3907. [Google Scholar] [CrossRef]
- Ke, L.; Danelljan, M.; Li, X.; Tai, Y.-W.; Tang, C.-K.; Yu, F. Mask transfiner for high-quality instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4412–4421. [Google Scholar]
- Fan, R.; Cheng, M.-M.; Hou, Q.; Mu, T.-J.; Wang, J.; Hu, S.-M. S4net: Single stage salient-instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Pei, J.; Cheng, T.; Tang, H.; Chen, C. Transformer-based efficient salient instance segmentation networks with orientative query. IEEE Trans. Multimed. 2023, 25, 1964–1978. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment anything. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. Rsprompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model. arXiv 2023, arXiv:2306.16269. [Google Scholar]
- An, Y.; Tan, Y.; Sun, X.; Ferrari, G. Recommender System: A Comprehensive Overview of Technical Challenges and Social Implications. IECE Trans. Sens. Commun. Control. 2024, 1, 30–51. [Google Scholar]
- Ma, H.; Tang, J.; Lv, H.; Chu, W.; Sun, S. Investigation on the Mechanism of Nebulized Droplet Particle Size Impact in Precision Plant Protection. IECE Trans. Intell. Syst. 2024, 1, 102–111. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | mAP | AP50 | AP75 |
|---|---|---|---|---|
| Mask RCNN [5] | ResNet-101 | 23.4 | 40.9 | 25.3 |
| Mask Scoring R-CNN [35] | ResNet-101 | 24.6 | 41.9 | 26.5 |
| Cascade Mask R-CNN [36] | ResNet-101 | 25.5 | 42.8 | 27.8 |
| BMask R-CNN [12] | ResNet-101 | 22.1 | 36.2 | 24.4 |
| Point Rend [11] | ResNet-101 | 25.9 | 43.4 | 27.6 |
| SOLOv2 [37] | ResNet-101 | 24.5 | 40.9 | 25.1 |
| QueryInst [38] | ResNet-101 | 26.0 | 42.8 | 27.3 |
| Mask2Former [39] | ResNet-101 | 25.7 | 38.0 | 27.7 |
| RDPNet [40] | ResNet-101 | 20.6 | 38.7 | 19.4 |
| Mask Transfiner [41] | ResNet-101 | 24.6 | 42.1 | 26.0 |
| WaterMask [8] | ResNet-101 | 27.2 | 43.7 | 29.3 |
| USIS-SAM [10] | ViT-H | 29.4 | 45.0 | 32.3 |
| AASNet | GELAN+LCA | 31.7 | 49.5 | 35.1 |
| Method | Backbone | Class-Agnostic | Multi-Class | ||||
|---|---|---|---|---|---|---|---|
| mAP | AP50 | AP75 | mAP | AP50 | AP75 | ||
| S4Net [42] | ResNet-50 | 32.8 | 64.1 | 27.3 | 23.9 | 43.5 | 24.4 |
| RDPNet [40] | ResNet-50 | 53.8 | 77.8 | 61.9 | 37.9 | 55.3 | 42.7 |
| RDPNet [40] | ResNet-101 | 54.7 | 78.3 | 63.0 | 39.3 | 55.9 | 45.4 |
| OQTR [43] | ResNet-50 | 56.6 | 79.3 | 62.6 | 19.7 | 30.6 | 21.9 |
| URank+RDPNet [40] | ResNet-101 | 52.0 | 77.0 | 62.0 | 35.9 | 52.5 | 41.4 |
| URank+OQTR [43] | ResNet-50 | 49.3 | 74.3 | 56.2 | 32.1 | 44.1 | 23.3 |
| WaterMask [8] | ResNet-50 | 58.3 | 80.2 | 66.5 | 37.7 | 54.0 | 42.5 |
| WaterMask [8] | ResNet-101 | 59.0 | 80.6 | 67.2 | 38.7 | 54.9 | 43.2 |
| SAM+BBox [44] | ViT-H | 45.9 | 65.9 | 52.1 | 26.4 | 38.9 | 29.0 |
| SAM+Mask [44] | ViT-H | 55.1 | 80.2 | 60.9 | 38.5 | 55.4 | 44.8 |
| RSPrompter [45] | ViT-H | 58.2 | 79.9 | 65.9 | 38.0 | 55.0 | 44.6 |
| URank+RPSrompter [45] | ViT-H | 50.6 | 74.4 | 56.6 | 38.5 | 55.0 | 43.3 |
| USIS-SAM [10] | ViT-H | 59.7 | 81.6 | 67.7 | 43.1 | 59.0 | 48.5 |
| AASNet | GELAN+LCA | 65.9 | 86.0 | 73.1 | 47.4 | 62.1 | 52.2 |
| LCA | DAFL | mAP | AP50 | AP75 |
|---|---|---|---|---|
| 28.5 | 45.9 | 31.2 | ||
| ✓ | 30.9 | 48.4 | 34.3 | |
| ✓ | ✓ | 31.7 | 49.5 | 35.1 |
| Position | mAP | AP50 | AP75 |
|---|---|---|---|
| None | 28.5 | 45.9 | 31.2 |
| P1 | 29.5 | 48.2 | 32.2 |
| P2 | 29.6 | 46.1 | 32.5 |
| P3 | 30.6 | 47.7 | 33.8 |
| P4 | 30.9 | 48.4 | 34.3 |
| P5 | 30.5 | 47.6 | 33.6 |
| Label Smoothing | Global Mean | mAP | AP50 | AP75 |
|---|---|---|---|---|
| 30.9 | 48.4 | 34.3 | ||
| ✓ | 31.2 | 48.7 | 34.6 | |
| ✓ | 31.4 | 49.2 | 35.2 |
| Methods | Backbone | APm | APb |
|---|---|---|---|
| Mask R-CNN | Resnet50 | 51.6 | 52.8 |
| TensorMask | Resnet50 | 50.7 | 52.9 |
| CenterMask | Resnet50 | 53.4 | 56.7 |
| BlendMask | Resnet50 | 55.3 | 57.3 |
| MS R-CNN | Resnet50 | 52.3 | 52.9 |
| Bmask R-CNN | Resnet50 | 53.4 | 55.8 |
| Cascade Mask | Swint | 52.4 | 53.0 |
| AASNet (ours) | GELAN+LCA | 59.1 | 62.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, J.; Tang, S.; Feng, J.; Mo, L.; Jin, X. AASNet: A Novel Image Instance Segmentation Framework for Fine-Grained Fish Recognition via Linear Correlation Attention and Dynamic Adaptive Focal Loss. Appl. Sci. 2025, 15, 3986. https://doi.org/10.3390/app15073986
Kong J, Tang S, Feng J, Mo L, Jin X. AASNet: A Novel Image Instance Segmentation Framework for Fine-Grained Fish Recognition via Linear Correlation Attention and Dynamic Adaptive Focal Loss. Applied Sciences. 2025; 15(7):3986. https://doi.org/10.3390/app15073986
Chicago/Turabian StyleKong, Jianlei, Shunong Tang, Jiameng Feng, Lipo Mo, and Xuebo Jin. 2025. "AASNet: A Novel Image Instance Segmentation Framework for Fine-Grained Fish Recognition via Linear Correlation Attention and Dynamic Adaptive Focal Loss" Applied Sciences 15, no. 7: 3986. https://doi.org/10.3390/app15073986
APA StyleKong, J., Tang, S., Feng, J., Mo, L., & Jin, X. (2025). AASNet: A Novel Image Instance Segmentation Framework for Fine-Grained Fish Recognition via Linear Correlation Attention and Dynamic Adaptive Focal Loss. Applied Sciences, 15(7), 3986. https://doi.org/10.3390/app15073986