
ShadeNet: Innovating Shade House Detection via High-Resolution Remote Sensing and Semantic Segmentation



Abstract
1. Introduction
- The lack of datasets, as there is currently no publicly available semantic segmentation dataset for shade houses, and high-quality datasets are essential for training deep learning models.
- The low extraction accuracy, which is partly due to the concentrated distribution of shade houses, as farmers maximize land use, resulting in a high number and density of shade houses in the study area. Additionally, the dark appearance of shade houses often leads to confusion with black PMFs, roads, building shadows, and dark water bodies, causing diverse features to be present in high-resolution remote sensing imagery. This poses significant challenges for the accurate extraction of shade houses.
- We have constructed the first dedicated semantic segmentation dataset for shade houses. We collected six optical remote sensing images from Google Earth, each with a resolution of 38,656 × 34,048 pixels, covering the period from 2021 to 2023, and spanning all four seasons. The data were annotated using SAM-Tool (https://github.com/facebookresearch/segment-anything, accessed on 24 March 2025), resulting in a dataset containing 4101 image patches of size 512 × 512 pixels. This dataset provides essential data support for subsequent research.
- We propose ShadeNet, a novel method for detecting shade houses using high-resolution remote sensing imagery and semantic segmentation. ShadeNet integrates the Swin Transformer [17] and Mask2Former [18] frameworks, and is enhanced by the Global-Channel and Local-Spatial Attention (GCLSA) module. This architecture significantly improves multi-scale feature extraction and global feature capture, thereby enhancing extraction accuracy. Notably, this study represents the first application of combining Swin Transformer [17] with Mask2Former [18] for the remote sensing extraction task of PCGs, demonstrating the potential of this combination in remote sensing object extraction tasks with complex backgrounds.
2. Related Works
- The lack of publicly available datasets for shade houses, despite the critical need for high-quality data to train deep learning models.
- The limited receptive fields of traditional CNNs, which restrict their ability to capture sufficient contextual information, thereby reducing extraction accuracy.
- The poor generalization ability of existing models, particularly when applied to diverse backgrounds, with suboptimal extraction accuracy in non-farmland environments.
- The high misclassification rate in complex scenarios, where shade houses are frequently confused with visually similar objects such as roads, building shadows, dark-colored vegetation, and dark-colored water bodies.
3. Materials and Methods
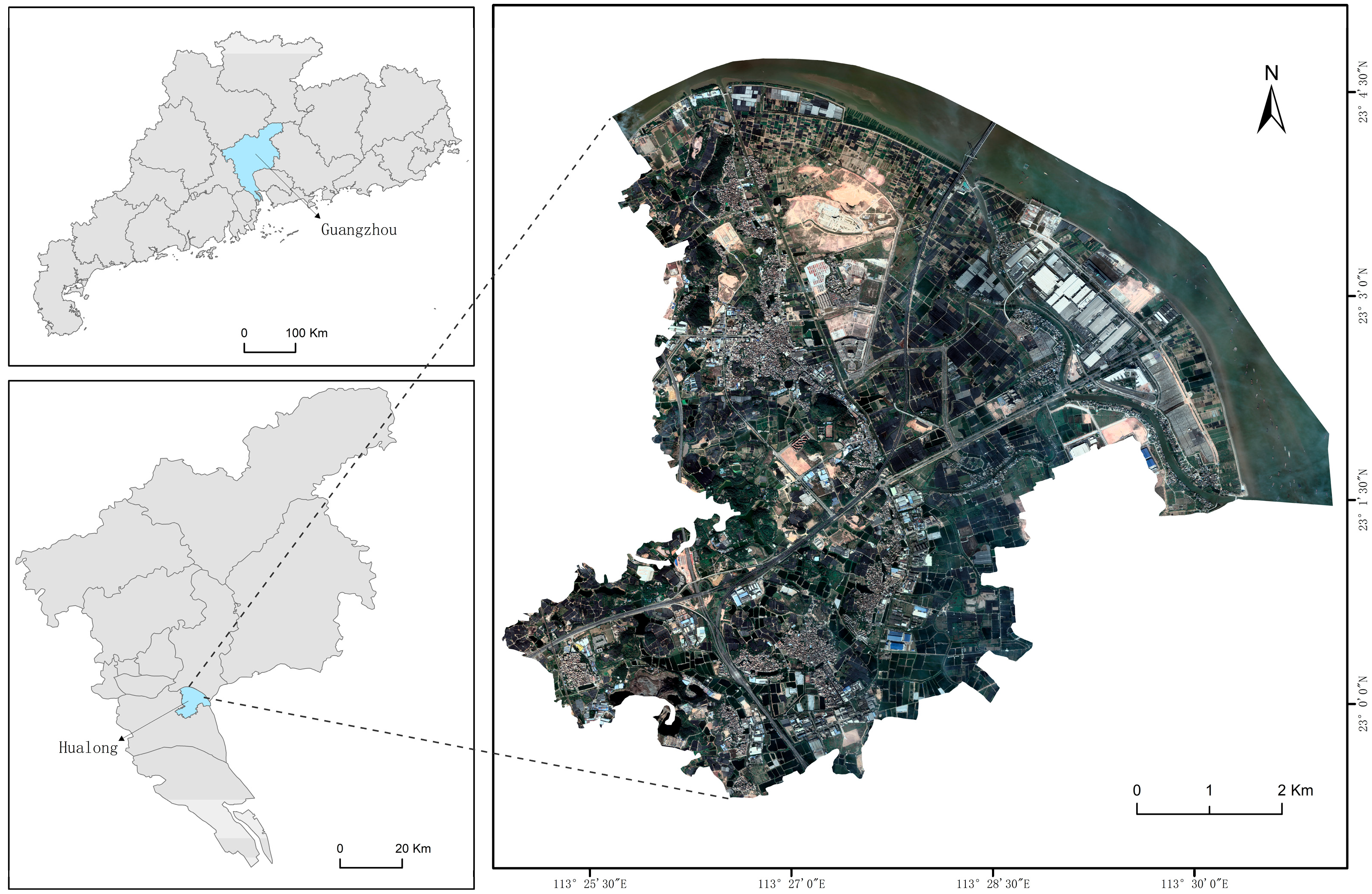
3.1. Study Area and Construction of High-Quality Shade House Semantic Segmentation Dataset
3.1.1. Hualong Town and Its Diversified Shade House Samples
3.1.2. The Two Types of Shade Houses Extracted in This Study
- Shade facilities erected above open-ground seedbeds, characterized by the installation of shade nets over a steel frame structure, with open sides on both sides of the structure. From a top–down view, the overall structure is flat, with no obvious arching.
- Shade facilities erected above PCGs are characterized by the installation of shade nets on the outside of the PCGs. Sometimes, to enhance the shading effect, shade nets are placed both inside and outside the plastic film of the PCGs, and the sides of the structure are enclosed. From a top–down view, the overall structure is arched.

3.1.3. Construction of the Shade House Dataset
3.2. ShadeNet: A Novel Approach to High-Precision Shade House Extraction
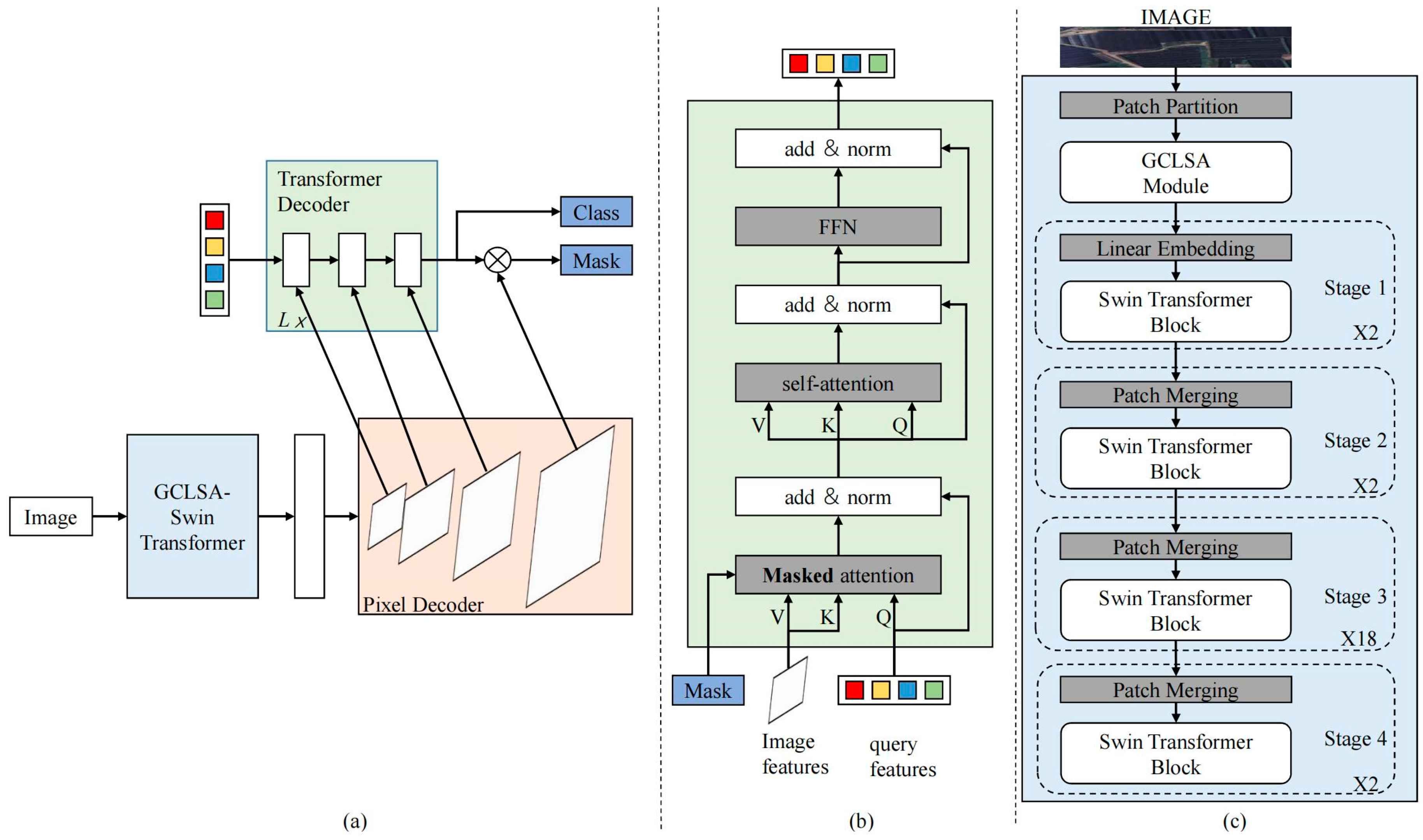
3.2.1. Overall Architecture of ShadeNet
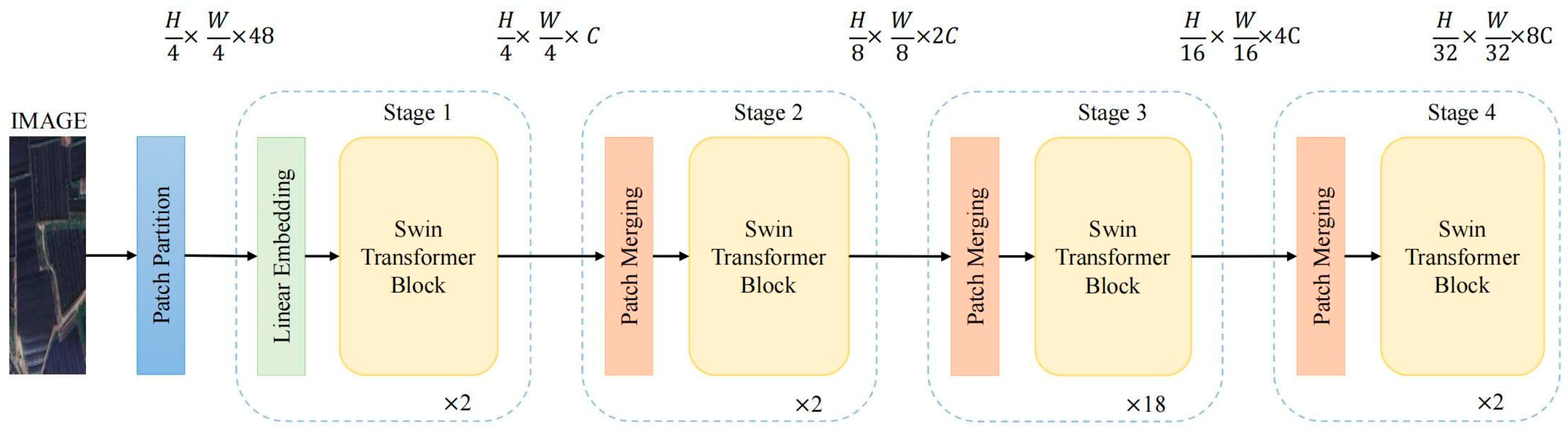
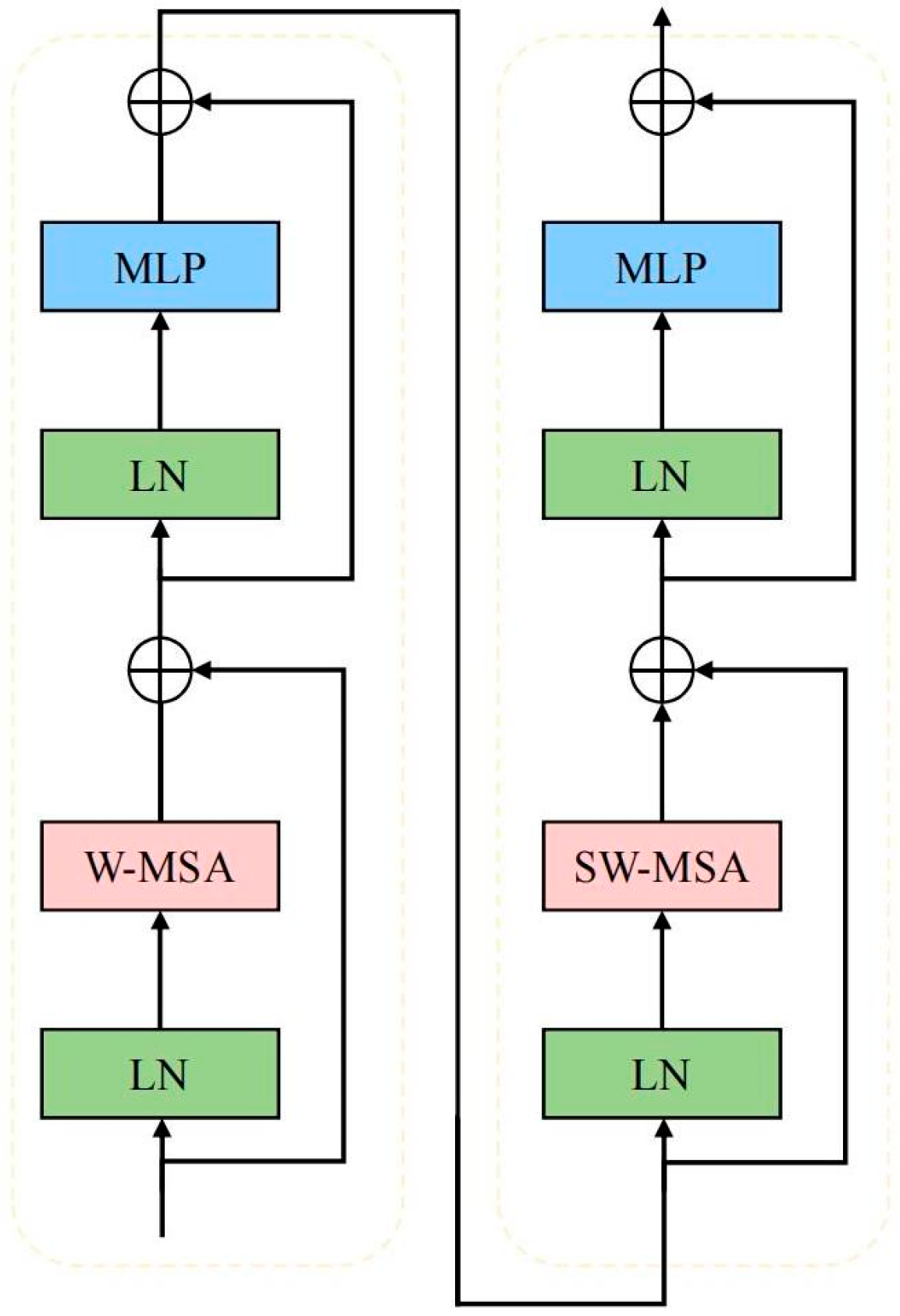
3.2.2. Backbone of ShadeNet: Swin Transformer
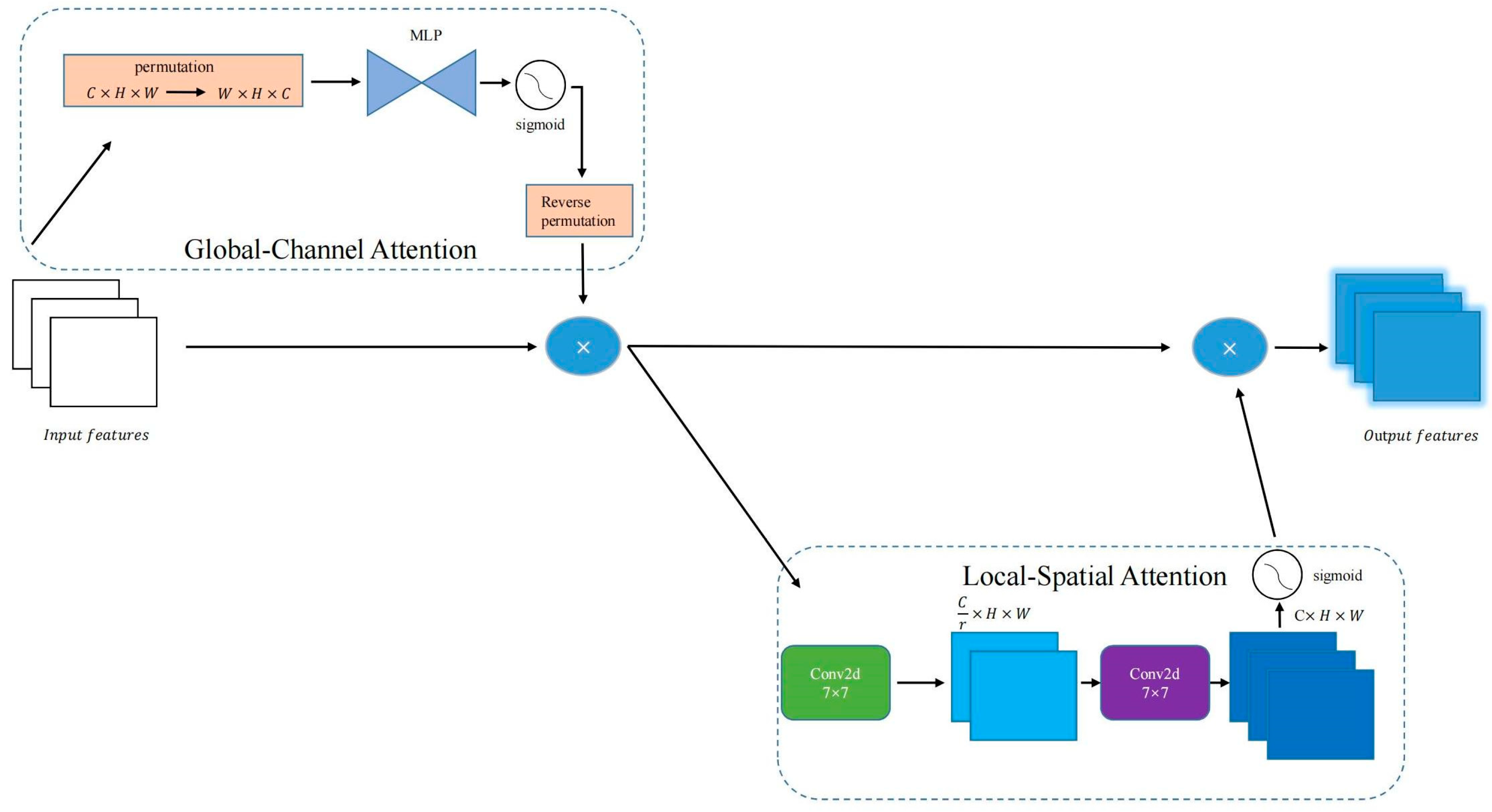
3.2.3. GCLSA Module: Enhancing Shade House Extraction with Global-Channel and Local-Spatial Attention
4. Experiments and Results
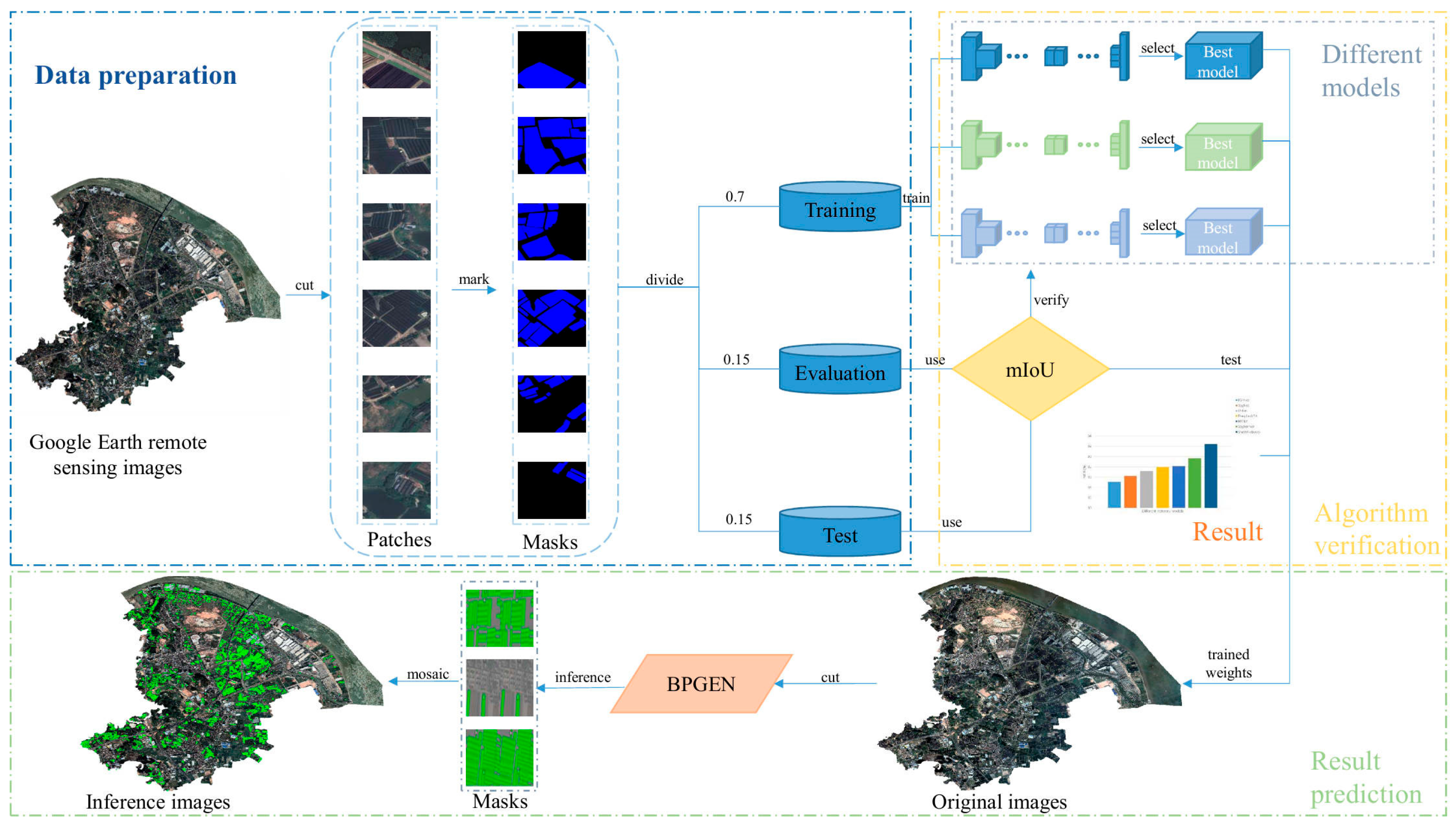
4.1. The Overall Process of Extracting Shade Houses
- In the data preparation phase, we manually annotated the downloaded high-resolution remote sensing images through visual interpretation, storing the annotation results as binary grayscale images. Subsequently, the images were cropped, and the dataset was divided as described in Section 3.1.3.
- In the algorithm validation phase, the mean Intersection over Union (mIoU, %) was used as the evaluation metric to assess the accuracy of each model. The best accuracy weight file for each model was selected through the validation set and then evaluated on the test set. The specific details of the model training settings are described in Section 4.3.
- In the result prediction phase, we divided the original images into several image patches, input the trained weight files into the ShadeNet, and obtained the predicted masks. The mask images of all image patches were then stitched together using geographic coordinates, ultimately producing the shade house extraction result for the designated area of the original image.
4.2. Accuracy Evaluation Metric: mIoU
4.3. Experimental Setup
- CrossEntropyLoss, used for classification tasks, with a loss weight of 2.0 and mean reduction.
- DiceLoss, with a loss weight of 5.0, used to better handle class imbalance, especially when target objects are small or imbalanced.
- MaskLoss, also based on CrossEntropyLoss, with a loss weight of 5.0, used for precise pixel classification.
4.4. Ablation Experiment and Result
- The ablation experiment of the backbone network. The Mask2Former model [18] with ResNet [40] as the backbone is selected as the baseline model. This choice is justified by the following two points: (1) ResNet [40], as a classic convolutional neural network architecture, has been extensively studied and validated in the semantic segmentation field, especially in combination with Transformer decoders. It is widely used in benchmark solutions such as CMNeXt [42] and Mask-RCNN [43]; (2) by keeping the decoder structure unchanged and only replacing the backbone network, the impact of the Swin Transformer’s [17] unique hierarchical attention mechanism and long-range dependency modeling capabilities on segmentation performance can be effectively isolated.
- The validation experiment of the GCLSA Module. The GCLSA module is introduced in the improved model based on the Swin Transformer to quantitatively analyze its contribution to enhancing the model’s ability to learn contextual information. The experiment employs a controlled variable approach, keeping other hyperparameters consistent and comparing performance by activating and deactivating the GCLSA module.
- The baseline model with ResNet as the backbone achieves an mIoU of 89.21%, which is consistent with the benchmark performance of similar studies under the Mask2Former framework [18], thereby validating the reliability of the experimental setup.
- After adopting the Swin Transformer backbone, the model’s mIoU improves to 90.05%, indicating that the self-attention mechanism architecture, which incorporates a sliding window attention, significantly enhances the feature representation capability compared to traditional convolutional structures.
- After introducing the GCLSA module, the model’s performance significantly improves to 92.42%, which validates that the GCLSA module, by reinforcing the attention to interrelations, effectively enhances the model’s ability to capture global contextual information.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mIOU (%) |
|---|---|
| ResNet Backbone (Baseline) | 89.21 |
| Swin Transformer Backbone | 90.05 |
| Swin Transformer Backbone + GCLSA Module(our) | 92.42 |
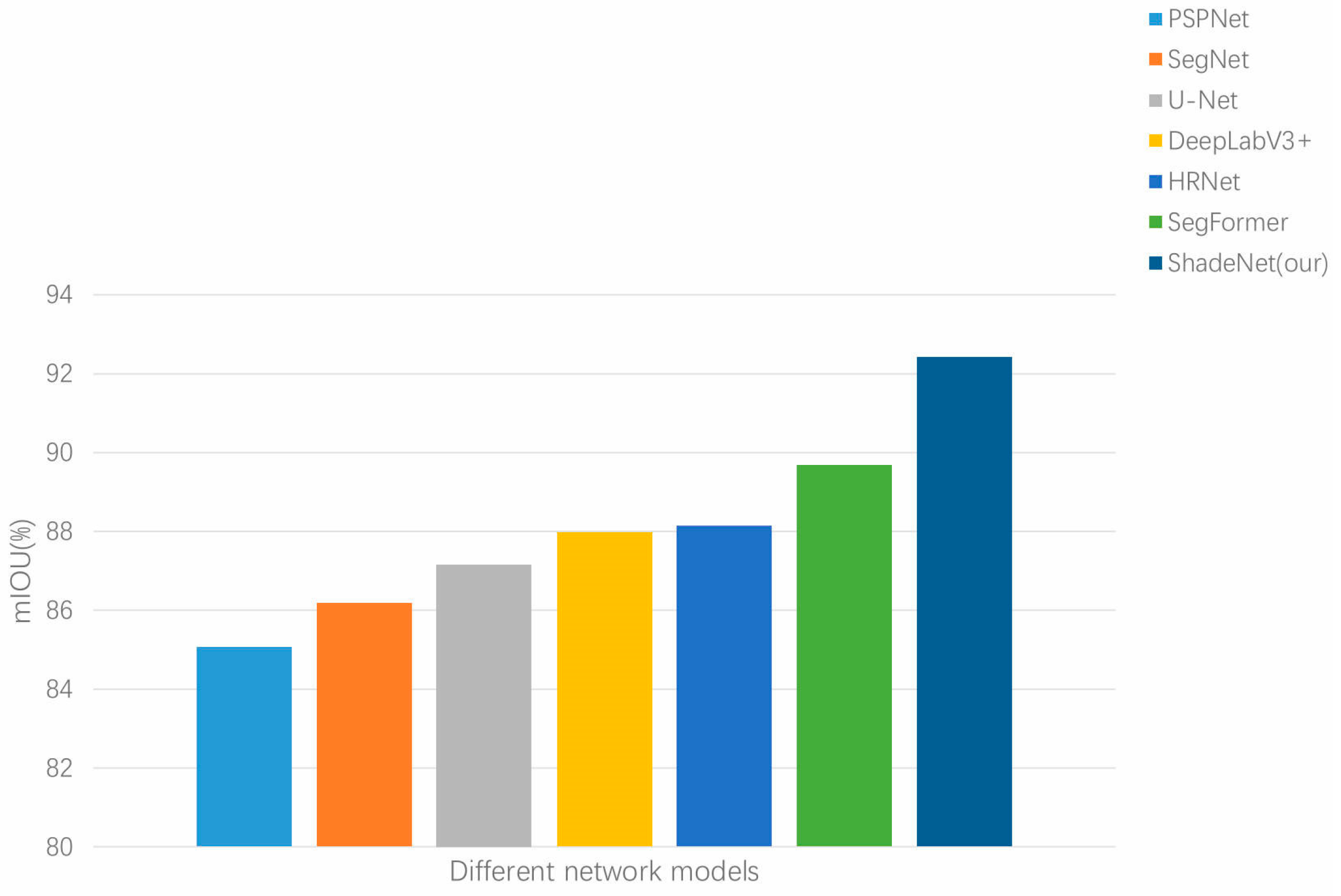
4.5. Comparative Experiment and Results
5. Discussion
5.1. Advantages
5.2. Limitations and Future Perspectives
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Veettil, B.K.; Van, D.D.; Quang, N.X.; Hoai, P.N. Remote Sensing of Plastic-Covered Greenhouses and Plastic-Mulched Farmlands: Current Trends and Future Perspectives. Land. Degrad. Dev. 2023, 34, 591–609. [Google Scholar] [CrossRef]
- Jiménez-Lao, R.; Aguilar, F.J.; Nemmaoui, A.; Aguilar, M.A. Remote Sensing of Agricultural Greenhouses and Plastic-Mulched Farmland: An Analysis of Worldwide Research. Remote Sens. 2020, 12, 2649. [Google Scholar] [CrossRef]
- AGROVOC: Shade Houses. Available online: https://agrovoc.fao.org/browse/agrovoc/en/page/c_91cf9ea0 (accessed on 15 January 2025).
- Mohawesh, O.; Albalasmeh, A.; Deb, S.; Singh, S.; Simpson, C.; AlKafaween, N.; Mahadeen, A. Effect of Colored Shading Nets on the Growth and Water Use Efficiency of Sweet Pepper Grown under Semi-Arid Conditions. HortTechnology 2021, 32, 21–27. [Google Scholar] [CrossRef]
- Food and Agriculture Organization of the United Nations. Available online: https://www.fao.org/americas/news/news-detail/FAO-and-IICA-Partnering-to-Build-Climate-Resilience-During-the-Pandemic/en (accessed on 15 January 2025).
- Wu, C.F.; Deng, J.S.; Wang, K.; Ma, L.G.; Tahmassebi, A.R.S. Object-Based Classification Approach for Greenhouse Mapping Using Landsat-8 Imagery. Int. J. Agric. Biol. Eng. 2016, 9, 79–88. [Google Scholar]
- Zhang, X. Research on Algorithms for Agricultural Greenhouses Extraction from High-Resolution Remote Sensing Imagery Based on Deep Learning. Master’s Thesis, University of Chinese Academy of Sciences, Beijing, China, 2022. [Google Scholar]
- Feng, Q.; Niu, B.; Chen, B.; Ren, Y.; Zhu, D.; Yang, J.; Liu, J.; Ou, C.; Li, B. Mapping of Plastic Greenhouses and Mulching Films from Very High Resolution Remote Sensing Imagery Based on a Dilated and Non-Local Convolutional Neural Network. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102441. [Google Scholar] [CrossRef]
- Picuno, P.; Tortora, A.; Capobianco, R.L. Analysis of Plasticulture Landscapes in Southern Italy through Remote Sensing and Solid Modelling Techniques. Landsc. Urban Plan. 2011, 100, 45–56. [Google Scholar] [CrossRef]
- Feng, S.; Lu, H.; Liu, Y. The Occurrence of Microplastics in Farmland and Grassland Soils in the Qinghai-Tibet Plateau: Different Land Use and Mulching Time in Facility Agriculture. Environ. Pollut. 2021, 279, 116939. [Google Scholar] [CrossRef]
- Niu, B.; Feng, Q.; Su, S.; Yang, Z.; Zhang, S.; Liu, S.; Wang, J.; Yang, J.; Gong, J. Semantic Segmentation for Plastic-Covered Greenhouses and Plastic-Mulched Farmlands from VHR Imagery. Int. J. Digit. Earth 2023, 16, 4553–4572. [Google Scholar] [CrossRef]
- Huang, D. Extraction and Accuracy Analysis of “Greenhouse Houses” Based on POI Data and Satellite Remote Sensing Images. In Proceedings of the 2024 5th International Conference on Geology, Mapping and Remote Sensing (ICGMRS), Wuhan, China, 12–14 April 2024; pp. 178–181. [Google Scholar]
- Guo, J. Research on Remote Sensing Extraction Method of Agricultural Plastic Greenhouse in Large-scale Complex Environments. Master’s Thesis, Yunnan Normal University, Kunming, China, 2024. [Google Scholar]
- Nemmaoui, A.; Aguilar, M.A.; Aguilar, F.J.; Novelli, A.; García Lorca, A. Greenhouse Crop Identification from Multi-Temporal Multi-Sensor Satellite Imagery Using Object-Based Approach: A Case Study from Almería (Spain). Remote Sens. 2018, 10, 1751. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, L.; Chen, D.; Li, W. Remote Sensing Extraction Method of Agricultural Greenhouse Based on an Improved U-Net Model. J. Univ. Chin. Acad. Sci. 2024, 41, 375–386. [Google Scholar]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021), Virtual, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-Attention Mask Transformer for Universal Image Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 1280–1289. [Google Scholar]
- Aggarwal, A. A Geospatial Approach to Monitoring Land Use and Land Cover Dynamics: A Review. In Proceedings of the International Conference on Materials for Energy Storage and Conservation, Singapore, 23–24 August 2022; pp. 63–71. [Google Scholar]
- Zhang, X.; Cheng, B.; Liang, C.; Wang, G. Edge-Guided Dual-Stream Network for Plastic Greenhouse Extraction From Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–21. [Google Scholar] [CrossRef]
- Ji, L.; Zhang, L.; Shen, Y.; Li, X.; Liu, W.; Chai, Q.; Zhang, R.; Chen, D. Object-Based Mapping of Plastic Greenhouses with Scattered Distribution in Complex Land Cover Using Landsat 8 OLI Images: A Case Study in Xuzhou, China. J. Indian Soc. Remote Sens. 2020, 48, 287–303. [Google Scholar] [CrossRef]
- Balcik, F.B.; Senel, G.; Goksel, C. Greenhouse Mapping Using Object Based Classification and Sentinel-2 Satellite Imagery. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, 16–19 July 2019; pp. 1–5. [Google Scholar]
- Wang, Z.; Zhang, Q.; Qian, J.; Xiao, X. Greenhouse Extraction Based on the Enhanced Water Index–A Case Study in Jiangmen of Guangdong. J. Integr. Technol. 2017, 6, 11–21. [Google Scholar]
- Yang, D.; Chen, J.; Zhou, Y.; Chen, X.; Chen, X.; Cao, X. Mapping Plastic Greenhouse with Medium Spatial Resolution Satellite Data: Development of a New Spectral Index. ISPRS J. Photogramm. Remote Sens. 2017, 128, 47–60. [Google Scholar] [CrossRef]
- Zhang, P.; Du, P.; Guo, S.; Zhang, W.; Tang, P.; Chen, J.; Zheng, H. A Novel Index for Robust and Large-Scale Mapping of Plastic Greenhouse from Sentinel-2 Images. Remote Sens. Environ. 2022, 276, 113042. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, M.; Zhang, Z.; Lei, L.; Wang, X.; Guo, X. Agricultural Greenhouses Detection in High-Resolution Satellite Images Based on Convolutional Neural Networks: Comparison of Faster R-CNN, YOLO v3 and SSD. Sensors 2020, 20, 4938. [Google Scholar] [CrossRef]
- Baghirli, O.; Ibrahimli, I.; Mammadzada, T. Greenhouse Segmentation on High-Resolution Optical Satellite Imagery Using. Deep Learning Techniques. arXiv 2020, arXiv:2007.11222. [Google Scholar]
- Ma, A.; Chen, D.; Zhong, Y.; Zheng, Z.; Zhang, L. National-Scale Greenhouse Mapping for High Spatial Resolution Remote Sensing Imagery Using a Dense Object Dual-Task Deep Learning Framework: A Case Study of China. ISPRS J. Photogramm. Remote Sens. 2021, 181, 279–294. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in Remote Sensing: A Survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Baidu Baike. Huilong Town (A Town in Panyu District, Guangzhou City, Guangdong Province). Available online: https://baike.baidu.com/item/%E5%8C%96%E9%BE%99%E9%95%87/15977 (accessed on 6 December 2024).
- Guangzhou Panyu District People’s Government Portal Website. Available online: http://www.panyu.gov.cn/jgzy/zzfjdbsc/fzqhlzrmzf/zjgk/ (accessed on 6 December 2024).
- Li, Y.; Zhang, J.; Zhang, P.; Xue, Y.; Li, Y.; Chen, C. Estimation of the Planting Area of Panax Notoginseng in Wenshan, Yunnan Based on Sentinel-2 Satellite Remote Sensing Images. J. Yunnan Univ. (Nat. Sci. Ed.) 2022, 44, 89–97. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual, 3–7 May 2021. [Google Scholar]
- Zhang, J.; Liu, R.; Shi, H.; Yang, K.; Reiß, S.; Peng, K.; Fu, H.; Wang, K.; Stiefelhagen, R. Delivering Arbitrary-Modal Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 1136–1145. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, September 8–14, 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Álvarez, J.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 5688–5697. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]






| Confusion Matrix | Predict | ||
|---|---|---|---|
| True | False | ||
| Real | True | TP (True position) | FN (False negative) |
| False | FP (False positive) | TN (True negative) | |
| Model | mIOU (%) |
|---|---|
| PSPNet | 85.05 |
| SegNet | 86.17 |
| U-Net | 87.16 |
| DeepLabV3+ | 87.97 |
| HRNet | 88.14 |
| SegFormer | 89.67 |
| ShadeNet (our) | 92.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Y.; Xu, M.; Dong, W.; Zhang, Q. ShadeNet: Innovating Shade House Detection via High-Resolution Remote Sensing and Semantic Segmentation. Appl. Sci. 2025, 15, 3735. https://doi.org/10.3390/app15073735
Liang Y, Xu M, Dong W, Zhang Q. ShadeNet: Innovating Shade House Detection via High-Resolution Remote Sensing and Semantic Segmentation. Applied Sciences. 2025; 15(7):3735. https://doi.org/10.3390/app15073735
Chicago/Turabian StyleLiang, Yinyu, Minduan Xu, Wuzhou Dong, and Qingling Zhang. 2025. "ShadeNet: Innovating Shade House Detection via High-Resolution Remote Sensing and Semantic Segmentation" Applied Sciences 15, no. 7: 3735. https://doi.org/10.3390/app15073735
APA StyleLiang, Y., Xu, M., Dong, W., & Zhang, Q. (2025). ShadeNet: Innovating Shade House Detection via High-Resolution Remote Sensing and Semantic Segmentation. Applied Sciences, 15(7), 3735. https://doi.org/10.3390/app15073735